

ถ้าคุณเคยพยายามสร้างรายชื่อลูกค้าเป้าหมายแบบเจาะจง สำรวจตลาดใหม่ หรือเปรียบเทียบคู่แข่ง คุณคงรู้ว่า Google Maps คือแหล่งข้อมูลชั้นดี แต่ประเด็นคือ ด้วยการค้นหาแบบ “ใกล้ฉัน” มากกว่า 1.5 พันล้านครั้งต่อเดือน และ 76% ของผู้ค้นหาในพื้นที่เข้าไปที่ธุรกิจภายใน 24 ชั่วโมง (thinkwithgoogle.com) ความต้องการข้อมูลธุรกิจที่อัปเดตและอิงตำแหน่งจึงสูงกว่าที่เคย
ไม่ว่าคุณจะอยู่ในสายขาย การตลาด หรือปฏิบัติการ การดึงข้อมูลแบบมีโครงสร้างจาก Google Maps อาจเป็นตัวแปรสำคัญที่ทำให้แตกต่างระหว่างการโทรหาลูกค้าแบบเย็น ๆ กับลีดคุณภาพสูงที่มีโอกาสปิดการขายมากกว่า
ผมใช้เวลาหลายปีกับ SaaS และระบบอัตโนมัติ และได้เห็นกับตาว่าทีมต่าง ๆ ใช้ Python (และตอนนี้รวมถึงเครื่องมือที่ขับเคลื่อนด้วย AI อย่าง Thunderbit) เพื่อเปลี่ยน Google Maps ให้กลายเป็นสินทรัพย์เชิงกลยุทธ์อย่างไร
ในคู่มือนี้ ผมจะอธิบายแบบละเอียดว่าคุณจะดึงข้อมูล Google Maps ด้วย Python ในปี 2026 ได้อย่างไร—ทีละขั้นตอน พร้อมโค้ด เคล็ดลับเรื่องการปฏิบัติตามข้อกำหนด และการเปรียบเทียบกับโซลูชันแบบไม่ต้องเขียนโค้ด ไม่ว่าคุณจะเป็นสาย Python ตัวจริงหรือแค่ต้องการทางลัดที่เร็วที่สุดไปสู่ข้อมูลที่ใช้งานได้จริง บทความนี้เหมาะกับคุณ
การดึงข้อมูล Google Maps ด้วย Python คืออะไร?
เริ่มจากพื้นฐานก่อน: การ ดึงข้อมูล Google Maps ด้วย Python หมายถึงการใช้โปรแกรมดึงข้อมูลธุรกิจ เช่น ชื่อ ที่อยู่ เรตติ้ง รีวิว เบอร์โทร และพิกัด จาก Google Maps เพื่อให้คุณนำไปวิเคราะห์ กรอง และส่งออกไปใช้ในงานธุรกิจได้

มี 2 วิธีหลักในการทำเรื่องนี้:
- Google Maps Places API: วิธีทางการและได้รับอนุญาต ใช้ API key เพื่อสอบถามเซิร์ฟเวอร์ของ Google และรับข้อมูล JSON ที่มีโครงสร้าง วิธีนี้เสถียร คาดเดาได้ และโดยมากสอดคล้องกับข้อกำหนด แต่มีโควตาและค่าใช้จ่าย
- เว็บสแครป HTML: ใช้การควบคุมเบราว์เซอร์อัตโนมัติ (ด้วยเครื่องมืออย่าง Playwright หรือ Selenium) เพื่อโหลด Google Maps ทำการค้นหา และแยกข้อมูลจากหน้าเว็บที่เรนเดอร์แล้ว วิธีนี้ยืดหยุ่นกว่าแต่เปราะบาง—เพราะ Google เปลี่ยนโครงสร้างเว็บบ่อย และการสแครป HTML อาจละเมิดข้อกำหนดของ Google
ฟิลด์ข้อมูลทั่วไปที่คุณดึงได้:
- ชื่อธุรกิจ
- หมวดหมู่/ประเภทธุรกิจ
- ที่อยู่เต็ม (พร้อมเมือง รัฐ รหัสไปรษณีย์ ประเทศ)
- ละติจูดและลองจิจูด
- เบอร์โทร
- URL เว็บไซต์
- เรตติ้งและจำนวนรีวิว
- ระดับราคา
- สถานะธุรกิจ (เปิด/ปิด)
- เวลาทำการ
- Place ID (รหัสเฉพาะของ Google)
- URL ของ Google Maps
ทำไมเรื่องนี้ถึงสำคัญ? เพราะฟิลด์เหล่านี้ขับเคลื่อนทุกอย่าง ตั้งแต่การหาลีด การวางแผนพื้นที่ขาย ไปจนถึงการเปรียบเทียบคู่แข่งและการวิจัยตลาด กุญแจสำคัญคือการเลือกดึงข้อมูลให้ตรงกับเป้าหมายธุรกิจของคุณ—not แค่สแครปแบบสุ่มไปเรื่อย ๆ
ทำไมทีมขายและการตลาดถึงดึงข้อมูลจาก Google Maps ด้วย Python
มาดูกันแบบใช้งานจริง ทำไมในปี 2026 ทีมขายและการตลาดจำนวนมากถึงหมกมุ่นกับข้อมูลจาก Google Maps?
- การหาลีด: สร้างรายชื่อธุรกิจท้องถิ่นแบบเจาะจงมาก พร้อมข้อมูลติดต่อและเรตติ้งสำหรับแคมเปญ outreach
- การวางแผนพื้นที่ขาย: ทำแผนที่เขตการขาย โซนจัดส่ง หรือพื้นที่ให้บริการโดยอิงจากความหนาแน่นและประเภทของธุรกิจจริง
- การติดตามคู่แข่ง: ติดตามตำแหน่ง เรตติ้ง และรีวิวของคู่แข่งในช่วงเวลาต่าง ๆ เพื่อหาทรนด์และโอกาส
- การวิจัยตลาด: วิเคราะห์หมวดหมู่ธุรกิจ เวลาทำการ และความรู้สึกในรีวิว เพื่อช่วยวางกลยุทธ์ go-to-market
- การเลือกทำเล: สำหรับธุรกิจอสังหาริมทรัพย์และค้าปลีก ประเมินทำเลที่เป็นไปได้จากสิ่งอำนวยความสะดวกใกล้เคียง การสัญจร และคู่แข่ง
ผลลัพธ์ในโลกจริง: จาก HubSpot 2025 State of Sales ระบุว่า 92% ขององค์กรขายมีแผนเพิ่มการลงทุนด้าน AI/ข้อมูล และทีมที่ใช้ข้อมูลเชิงพื้นที่แบบเจาะจงมีอัตรา conversion สูงกว่าถึง 8 เท่า เมื่อเทียบกับทีมที่พึ่งพารายชื่อ cold list ทั่วไป (martal.ca) งานวิจัยด้าน lead gen ของแฟรนไชส์หนึ่งพบว่า ทุก ๆ 1 ดอลลาร์ที่ใช้ไปกับรายชื่อลีดจาก Google Maps สร้างรายได้ใหม่ได้ 15 ดอลลาร์
การเชื่อมเป้าหมายธุรกิจกับฟิลด์ใน Google Maps:
| เป้าหมายธุรกิจ | ฟิลด์ที่ต้องใช้จาก Google Maps |
|---|---|
| รายชื่อลีดในพื้นที่ | name, address, phone, website, category |
| การวางแผนพื้นที่ขาย | name, lat/lng, business_status, opening_hours |
| การเปรียบเทียบคู่แข่ง | name, rating, userRatingCount, priceLevel, reviews |
| การเลือกทำเล | category, lat/lng, review density, openingDate |
| อินไซต์จากรีวิว/เมนู | reviews, editorialSummary, photos, types |
| การทำ outreach ผ่านอีเมล/โทรศัพท์ | nationalPhoneNumber, websiteUri (แล้วค่อยเพิ่มข้อมูลเสริมตามต้องการ) |
การตั้งค่า Python Google Maps Scraper: เครื่องมือและข้อกำหนด
ก่อนเริ่มสแครป คุณต้องตั้งค่าสภาพแวดล้อม Python และเตรียมเครื่องมือให้พร้อม นี่คือสิ่งที่คุณต้องมีในปี 2026:
1. ติดตั้ง Python และไลบรารีที่จำเป็น
เวอร์ชัน Python ที่แนะนำ: 3.10 หรือใหม่กว่า
ติดตั้งไลบรารีหลัก:
pip install \
requests==2.33.1 httpx==0.28.1 \
beautifulsoup4==4.14.3 lxml==6.0.3 \
pandas==2.3.3 \
selenium==4.43.0 playwright==1.58.0 \
googlemaps==4.10.0 google-maps-places==0.8.0 \
schedule==1.2.2 APScheduler==3.11.2 \
python-dotenv==1.2.2 tenacity==9.1.4
playwright install chromium
สิ่งที่แต่ละตัวทำ:
requests,httpx: ส่ง HTTP request (เรียก API)beautifulsoup4,lxml: แยกและอ่าน HTML (สำหรับเว็บสแครป)pandas: ทำความสะอาด วิเคราะห์ และส่งออกข้อมูลselenium,playwright: ควบคุมเบราว์เซอร์อัตโนมัติ (สำหรับสแครป HTML)googlemaps,google-maps-places: ไคลเอนต์สำหรับ Google Maps APIschedule,APScheduler: ตั้งเวลารันงานpython-dotenv: โหลด API key อย่างปลอดภัยจากไฟล์.envtenacity: เพิ่มตรรกะการ retry เมื่อเกิดข้อผิดพลาด
2. รับ Google Maps API Key (สำหรับการสแครปแบบใช้ API)
- ไปที่ Google Cloud Console
- สร้างหรือเลือกโปรเจกต์
- เปิดการใช้งาน billing (จำเป็น แม้ใช้ระดับฟรี)
- เปิด “Places API (New)” ใน APIs & Services > Library
- ไปที่ Credentials > Create Credentials > API Key
- จำกัดการใช้ key ให้เฉพาะ API และ IP ที่ต้องการเพื่อความปลอดภัย
- เก็บ API key ไว้ในไฟล์
.env(ห้าม commit ลงโค้ด):
GOOGLE_MAPS_API_KEY=your_actual_api_key_here
หมายเหตุ: ตั้งแต่เดือนมีนาคม 2025 Google ไม่ได้ให้เครดิตฟรีแบบรวม $200/เดือนอีกต่อไปแล้ว แต่จะมีเกณฑ์ใช้ฟรีรายเดือนแยกตาม tier ของแต่ละ API แทน (ดู ราคาทางการ)
วิธีดึงข้อมูลจาก Google Maps ด้วย Python: คู่มือทีละขั้นตอน
มาดูสองแนวทางหลัก—แบบใช้ API และ แบบสแครป HTML—เพื่อให้คุณเลือกวิธีที่เหมาะกับงานของคุณ
แนวทางที่ 1: ใช้ Google Maps Places API (แนะนำ)
ขั้นตอนที่ 1: ติดตั้งและนำเข้าไลบรารีที่จำเป็น
import os
import httpx
import pandas as pd
from dotenv import load_dotenv
ขั้นตอนที่ 2: โหลด API key อย่างปลอดภัย
load_dotenv()
API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]
ขั้นตอนที่ 3: สร้างคำค้นหา
คุณจะใช้ endpoint Text Search เพื่อหาธุรกิจที่ตรงกับเงื่อนไขของคุณ
URL = "https://places.googleapis.com/v1/places:searchText"
FIELD_MASK = ",".join([
"places.id", "places.displayName", "places.formattedAddress",
"places.location", "places.rating", "places.userRatingCount",
"places.priceLevel", "places.types",
"places.nationalPhoneNumber", "places.websiteUri",
"nextPageToken",
])
ขั้นตอนที่ 4: ส่งคำขอ API
def text_search(query, lat, lng, radius=3000, min_rating=4.0):
body = {
"textQuery": query,
"minRating": min_rating, # กรองฝั่งเซิร์ฟเวอร์
"includedType": "restaurant",
"openNow": False,
"pageSize": 20,
"locationBias": {
"circle": {
"center": {"latitude": lat, "longitude": lng},
"radius": radius,
}
},
}
headers = {
"Content-Type": "application/json",
"X-Goog-Api-Key": API_KEY,
"X-Goog-FieldMask": FIELD_MASK, # ต้องใส่เสมอ!
}
r = httpx.post(URL, json=body, headers=headers, timeout=30)
r.raise_for_status()
return r.json()
ขั้นตอนที่ 5: จัดการ pagination และรวบรวมผลลัพธ์
def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
results = []
next_page_token = None
while True:
data = text_search(query, lat, lng, radius, min_rating)
places = data.get('places', [])
results.extend(places)
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
return results
ขั้นตอนที่ 6: ส่งออกข้อมูลด้วย Pandas
df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
df.to_csv("brooklyn_coffee_shops.csv", index=False)
เคล็ดลับสำคัญ:
- ตั้งค่า
X-Goog-FieldMaskเสมอเพื่อคุมค่าใช้จ่าย ถ้าคุณขอรีวิวหรือรูปภาพ ราคาต่อ 1,000 request อาจพุ่งจาก $5 เป็น $25 ได้ (รายละเอียดราคา) - ใช้ตัวกรองฝั่งเซิร์ฟเวอร์ เช่น
minRating,includedType,locationBiasเพื่อไม่ให้เสียเครดิตกับผลลัพธ์ที่ไม่เกี่ยวข้อง - แคชค่า
place_idไว้เพื่อช่วย deduplicate และอัปเดตในอนาคต
แนวทางที่ 2: เว็บสแครป HTML ของ Google Maps (สำหรับใช้งานเชิงศึกษา/ครั้งเดียว)
คำเตือน: Google Maps เป็นเว็บแอปแบบ single-page คุณต้องใช้ browser automation (Playwright หรือ Selenium) และการสแครป HTML อาจละเมิดข้อกำหนดของ Google ควรใช้เพื่อการวิจัย ไม่ใช่งาน production
ขั้นตอนที่ 1: ติดตั้ง Playwright และเปิดเบราว์เซอร์
from playwright.sync_api import sync_playwright
import time, re
def scrape_maps(query, max_results=100):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
ctx = browser.new_context(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
locale="en-US",
)
page = ctx.new_page()
page.goto("https://www.google.com/maps", timeout=60_000)
page.fill("#searchboxinput", query)
page.click('button[aria-label="Search"]')
page.wait_for_selector('div[role="feed"]')
feed = page.locator('div[role="feed"]')
prev = 0
while True:
feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
time.sleep(2)
count = page.locator('div[role="feed"] > div > div[jsaction]').count()
if count == prev or count >= max_results:
break
prev = count
if page.locator("text=You've reached the end of the list").count():
break
rows = []
cards = page.locator('div[role="feed"] > div > div[jsaction]')
for i in range(cards.count()):
c = cards.nth(i)
name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
rating_el = c.locator('span[role="img"]').first
raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
rating = float(m.group(1)) if m else None
reviews = int(m.group(2).replace(",", "")) if m else None
rows.append({"name": name, "rating": rating, "reviews": reviews})
browser.close()
return rows
เคล็ดลับ:
- Google สลับคลาส CSS แบบสุ่มทุกไม่กี่สัปดาห์ ดังนั้นโค้ดนี้อาจต้องอัปเดตเป็นประจำ
- ใช้การหน่วงเวลาที่ดูเป็นมนุษย์ และอย่าสแครปเร็วเกินไปเพื่อลดความเสี่ยงถูกบล็อก
- อย่าพยายามหลีกเลี่ยง CAPTCHA หรือระบบ SearchGuard ของ Google เพราะอาจสร้างความเสี่ยงด้านกฎหมาย
หลีกเลี่ยงการสแครปแบบสุ่ม: วิธีเจาะจงข้อมูลที่คุณต้องการอย่างแม่นยำ
การสแครปทุกอย่างคือสูตรของการเสียเวลาและได้ข้อมูลเกินจำเป็น นี่คือวิธี เจาะเอาเฉพาะข้อมูลที่สำคัญจริง:
- สร้างรายการ URL แบบเจาะจง: ใช้ตัวกรองของ Google Maps เอง (หมวดหมู่ สถานที่ เรตติ้ง เปิดอยู่ตอนนี้) เพื่อคัดกรองผลลัพธ์ก่อนสแครป
- ใช้การจับคู่คำค้น: ค้นหาประเภทธุรกิจหรือคีย์เวิร์ดแบบตรงตัว เช่น “vegan bakery in Austin”
- ตัวกรองตำแหน่ง: ระบุเมือง ย่าน หรือแม้แต่พิกัดกับรัศมีเพื่อความแม่นยำสูง
- การกรองฝั่งเซิร์ฟเวอร์ (API): ใช้
minRating,includedTypeและlocationBiasใน body ของ request - การกรองฝั่งไคลเอนต์ (Python): หลังสแครปเสร็จ ใช้ pandas กรองธุรกิจที่เรตติ้งมากกว่า 4.0 มีรีวิวเกิน 50 รายการ หรืออยู่ในหมวดหมู่ที่กำหนด
ตัวอย่าง: กรองเฉพาะร้านอาหารใน Manhattan ที่มีเรตติ้งสูงกว่า 4.0
df = pd.DataFrame(results)
filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
filtered.to_csv("manhattan_top_restaurants.csv", index=False)
ใช้ไลบรารี Python เพื่อจัดระเบียบและส่งออกข้อมูล Google Maps
เมื่อคุณสแครปข้อมูลมาแล้ว ก็ถึงเวลาทำความสะอาด วิเคราะห์ และส่งออกให้ทีมใช้งาน
ทำความสะอาดและจัดโครงสร้างข้อมูลด้วย Pandas
import pandas as pd
df = pd.read_json("brooklyn_restaurants.json")
df = (
df.dropna(subset=["name", "address"])
.drop_duplicates(subset=["place_id"])
.assign(
name=lambda d: d["name"].str.strip(),
phone=lambda d: d["phone"].astype(str)
.str.replace(r"\D", "", regex=True)
.str.replace(r"^1?(\d{10})$", r"+1\1", regex=True),
rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
user_ratings_total=lambda d: pd.to_numeric(
d["user_ratings_total"], errors="coerce"
).fillna(0).astype("int32"),
)
)
วิเคราะห์และสรุปข้อมูล
ตัวอย่าง: ค่าเฉลี่ยเรตติ้งแยกตามย่าน
by_neighborhood = (
df.groupby("neighborhood", as_index=False)
.agg(avg_rating=("rating", "mean"),
n_places=("place_id", "nunique"),
median_reviews=("user_ratings_total", "median"))
.sort_values("avg_rating", ascending=False)
)
ส่งออกเป็น Excel หรือ CSV
df.to_csv("brooklyn_top.csv", index=False)
df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")
ชุดข้อมูลขนาดใหญ่ใช่ไหม? ใช้รูปแบบ Parquet เพื่อความเร็วและประหยัดพื้นที่:
df.to_parquet("brooklyn_top.parquet", compression="zstd")
Thunderbit: ทางเลือกด้วย AI แทน Python Google Maps Scraper
ถ้าคุณกำลังคิดว่า “นี่ต้องตั้งค่ามากเกินไปสำหรับแค่รายชื่อลีดง่าย ๆ” คุณไม่ได้คิดคนเดียว และนี่แหละคือเหตุผลที่เราสร้าง Thunderbit—เว็บสแครปแบบไม่ต้องเขียนโค้ดที่ขับเคลื่อนด้วย AI ซึ่งทำให้การดึงข้อมูลจาก Google Maps (และอีกมากมาย) ง่ายแค่ไม่กี่คลิก
ทำไมต้อง Thunderbit?
- ไม่ต้องเขียนโค้ดหรือใช้ API key: แค่เปิด Thunderbit Chrome Extension เข้า Google Maps แล้วคลิก “AI Suggest Fields”
- ตรวจจับฟิลด์ด้วย AI: AI ของ Thunderbit อ่านหน้าเว็บและแนะนำคอลัมน์ที่เหมาะสม—ชื่อ ที่อยู่ เรตติ้ง เบอร์โทร เว็บไซต์ และอื่น ๆ
- สแครปหน้าย่อย: อยากเพิ่มข้อมูลจากเว็บไซต์ของแต่ละธุรกิจลงในตารางใช่ไหม Thunderbit เข้าไปดูหน้าย่อยแต่ละหน้าและดึงข้อมูลเสริมให้อัตโนมัติได้
- ส่งออกไป Excel, Google Sheets, Airtable หรือ Notion: ไม่ต้องเสียเวลากับ pandas อีกต่อไป—แค่คลิก “Export” แล้วข้อมูลก็พร้อมให้ทีมใช้งาน
- ตั้งเวลาสแครปได้: ตั้งงานให้รันซ้ำเพื่อติดตามคู่แข่งหรือรีเฟรชรายชื่อลีดโดยอัตโนมัติ
- แทบไม่ต้องดูแลรักษา: AI ของ Thunderbit ปรับตัวตามการเปลี่ยนแปลงของเว็บได้ คุณจึงไม่ต้องคอยแก้สคริปต์ที่พังบ่อย ๆ
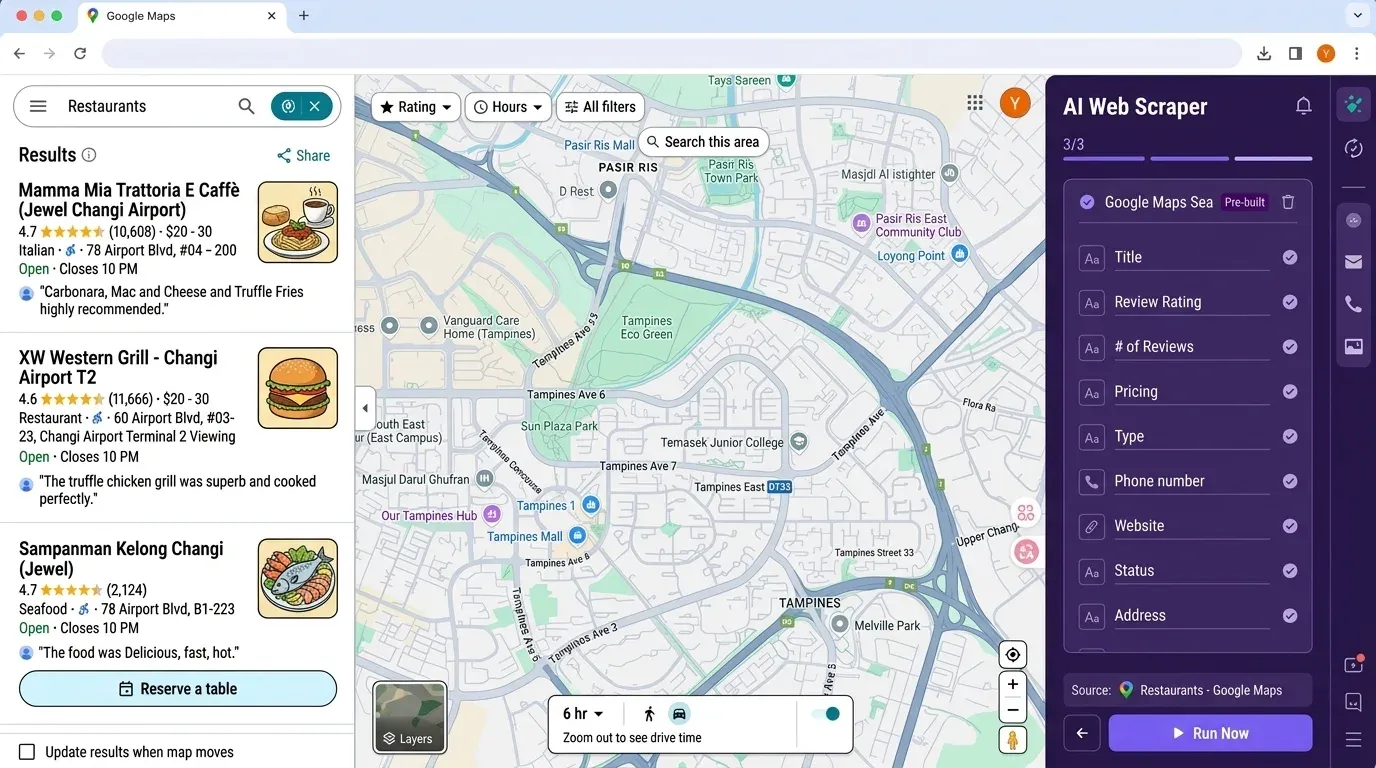
เวิร์กโฟลว์ Thunderbit เทียบกับ Python:
| ขั้นตอน | Python Scraper | Thunderbit |
|---|---|---|
| ติดตั้งเครื่องมือ | 30–60 นาที (Python, pip, libs) | 2 นาที (Chrome Extension) |
| ตั้งค่า API key | 10–30 นาที (Cloud Console) | ไม่ต้องใช้ |
| เลือกฟิลด์ | เขียนโค้ดเอง, field mask | AI Suggest Fields (คลิกครั้งเดียว) |
| ดึงข้อมูล | เขียน/รันสคริปต์, จัดการข้อผิดพลาด | คลิก “Scrape” |
| ส่งออก | pandas ไป CSV/Excel | ส่งออกไป Excel/Sheets/Notion |
| การดูแลรักษา | อัปเดตเองเมื่อเว็บเปลี่ยน | AI ปรับตัวอัตโนมัติ |
โบนัส: Thunderbit ได้รับความไว้วางใจจากผู้ใช้กว่า 30,000 คนทั่วโลก และแพ็กเกจฟรีให้คุณสแครปได้สูงสุด 6 หน้า (หรือ 10 หน้าเมื่อใช้ trial boost) โดยไม่มีค่าใช้จ่าย
การใช้งานอย่างสอดคล้องกับข้อกำหนด: ข้อกำหนดการใช้งานของ Google Maps และจริยธรรมในการสแครป
นี่คือส่วนที่บทความสอน Python จำนวนมากล้าสมัยไปแล้ว สิ่งที่คุณต้องรู้ในปี 2026 คือ:
- ข้อกำหนด Google Maps Platform ToS §3.2.3 ห้ามการสแครป แคช หรือส่งออกข้อมูลนอกเหนือจาก official APIs อย่างเข้มงวด (cloud.google.com) ข้อยกเว้นเดียวคือค่า latitude/longitude สามารถแคชได้ไม่เกิน 30 วัน และ Place IDs เก็บไว้ได้ไม่มีกำหนด
- ผู้ใช้ API ผูกพันตามสัญญา: ถ้าคุณใช้ API key เท่ากับยอมรับข้อกำหนดของ Google แล้ว—แม้คุณจะสแครปเฉพาะข้อมูลสาธารณะก็ตาม
- การหลีกเลี่ยงอุปสรรคทางเทคนิค (CAPTCHA, SearchGuard) ตอนนี้อาจเข้าข่ายละเมิด DMCA §1201 ซึ่งมีโทษทางอาญาได้ (ppc.land)
- GDPR และกฎหมายความเป็นส่วนตัว: หากคุณเก็บข้อมูลส่วนบุคคล (อีเมล เบอร์โทร ชื่อผู้รีวิว) จาก Google Maps คุณต้องมีฐานทางกฎหมายรองรับและต้องรับคำขอลบข้อมูลด้วย กรณีหนึ่ง CNIL ของฝรั่งเศสปรับ KASPR €200,000 ในปี 2024 จากการสแครปข้อมูลติดต่อ LinkedIn (edpb.europa.eu)
- แนวปฏิบัติที่ดี:
- ใช้ Places API เป็นค่าเริ่มต้นเมื่อทำได้
- จำกัดอัตราคำขอ (≤10 QPS สำหรับ API, 1–2 req/s สำหรับการสแครป HTML)
- ห้ามหลีกเลี่ยง CAPTCHA หรือบล็อกทางเทคนิค
- อย่าแจกจ่ายข้อมูลส่วนบุคคลที่สแครปมา
- เคารพคำขอ opt-out และการลบข้อมูล
- ตรวจสอบกฎหมายท้องถิ่นเสมอ—GDPR, CCPA และกฎหมายอื่น ๆ ถูกบังคับใช้อย่างจริงจัง
สรุปสั้น ๆ: ถ้าคุณกังวลเรื่องการปฏิบัติตามข้อกำหนด ให้ยึด API และเก็บข้อมูลให้น้อยที่สุดเท่าที่จำเป็น สำหรับผู้ใช้ธุรกิจส่วนใหญ่ เครื่องมือแบบไม่ต้องเขียนโค้ดอย่าง Thunderbit ช่วยลดความเสี่ยงได้มาก (ไม่ต้องใช้ API key และไม่ต้องกระจายข้อมูลต่อ)
การตั้งเวลาและทำงานอัตโนมัติสำหรับการสแครป Google Maps ด้วย Python
ถ้าคุณต้องการให้ข้อมูลสดอยู่เสมอ—เช่น ติดตามคู่แข่งรายสัปดาห์หรืออัปเดตรายชื่อลีดรายเดือน—ระบบอัตโนมัติก็คือเพื่อนที่ดีที่สุดของคุณ
ตั้งเวลาแบบง่ายด้วย schedule
import schedule, time
from my_scraper import run_job
schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
while True:
schedule.run_pending()
time.sleep(30)
ตั้งเวลาแบบพร้อมใช้งานจริงด้วย APScheduler
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTrigger
sched = BackgroundScheduler(timezone="America/New_York")
sched.add_job(
run_job,
CronTrigger(hour=3, minute=15, jitter=600), # 3:15 น. ± 10 นาที
kwargs={"query": "restaurants in Brooklyn"},
id="brooklyn_daily",
max_instances=1,
coalesce=True,
misfire_grace_time=3600,
)
sched.start()
เคล็ดลับสำหรับการทำงานอัตโนมัติอย่างปลอดภัย
- ใส่ jitter แบบสุ่มในตารางเวลา เพื่อไม่ให้รูปแบบดูคาดเดาได้
- สำหรับการสแครป HTML อย่ารันเกิน 1–2 request ต่อวินาที
- สำหรับการใช้ API ให้เฝ้าดูโควตาและตั้งค่าแจ้งเตือน billing
- บันทึกข้อผิดพลาดเสมอ และเก็บไฟล์ “dead-letter” สำหรับคำขอที่ล้มเหลว
โบนัสจาก Thunderbit: คุณสามารถตั้งเวลาสแครปซ้ำ ๆ ได้โดยตรงใน UI—ไม่ต้องเขียนโค้ด ไม่ต้องตั้ง cron job และไม่ต้องเซ็ตเซิร์ฟเวอร์
ประเด็นสำคัญ: การดึงข้อมูล Google Maps ที่มีประสิทธิภาพ เจาะจง และสอดคล้องกับข้อกำหนด
มาสรุปสาระสำคัญกัน:
- Google Maps คือแหล่งข้อมูลอันดับ 1 สำหรับข้อมูลตำแหน่งธุรกิจ ซึ่งขับเคลื่อนทุกอย่างตั้งแต่ lead gen ไปจนถึงการวิจัยตลาด
- การสแครปด้วย Python ให้ความยืดหยุ่นและควบคุมได้ดี แต่ต้องแลกกับการตั้งค่า การดูแลรักษา และภาระด้าน compliance โดยเฉพาะเมื่อมาตรการต้านบอทและการบังคับใช้กฎหมายของ Google เข้มงวดขึ้น
- การดึงข้อมูลด้วย API คือเส้นทางที่ปลอดภัยและขยายได้มากที่สุด สำหรับทีมส่วนใหญ่ ควรใช้ field mask และตัวกรองฝั่งเซิร์ฟเวอร์เสมอเพื่อคุมค่าใช้จ่าย
- การสแครป HTML เปราะบางและเสี่ยง ใช้เฉพาะงานวิจัยครั้งคราว และห้ามหลีกเลี่ยงอุปสรรคทางเทคนิค
- เจาะจงข้อมูลของคุณ: ใช้ phrase matching, ตัวกรองตำแหน่ง และเวิร์กโฟลว์ด้วย pandas เพื่อดึงเฉพาะสิ่งที่ต้องการ
- Thunderbit คือทางที่เร็วที่สุดสำหรับคนไม่เขียนโค้ด: ขับเคลื่อนด้วย AI, ไม่ต้องตั้งค่า, ส่งออกได้ทันที และมีระบบตั้งเวลาในตัว
- เรื่อง compliance สำคัญมาก: เคารพข้อกำหนดของ Google กฎหมายความเป็นส่วนตัว และ rate limits เพื่อลดความยุ่งยากทางกฎหมาย
สำหรับบทเรียนและเคล็ดลับเพิ่มเติม เข้าไปดู Thunderbit Blog และ ช่อง YouTube ของเรา
คำถามที่พบบ่อย
1. ในปี 2026 การสแครปข้อมูล Google Maps ด้วย Python ถูกกฎหมายไหม?
การสแครป Google Maps ผ่าน official API ทำได้ภายใต้เงื่อนไขของ Google ตราบใดที่คุณเคารพโควตาและไม่แจกจ่ายข้อมูลที่ถูกจำกัดไว้ ส่วนการสแครป HTML ของ Google Maps ถูกห้ามอย่างชัดเจนโดย ToS ของ Google และมีความเสี่ยงทางกฎหมาย โดยเฉพาะถ้าคุณหลีกเลี่ยงอุปสรรคทางเทคนิคหรือเก็บข้อมูลส่วนบุคคลโดยไม่ได้รับความยินยอม ควรตรวจสอบกฎหมายท้องถิ่นเสมอ (GDPR, CCPA ฯลฯ) และยึดแนวปฏิบัติที่ดีเพื่อให้สอดคล้องกับข้อกำหนด
2. ต่างกันอย่างไรระหว่างใช้ Google Maps API กับการสแครป HTML?
API เสถียร ได้รับอนุญาต และออกแบบมาเพื่อการดึงข้อมูลโดยเฉพาะ แต่ต้องใช้ API key และมีโควตาและค่าใช้จ่าย ส่วนการสแครป HTML ใช้ browser automation เพื่อดึงข้อมูลจากหน้าเว็บที่เรนเดอร์แล้ว แต่เปราะบาง (เพราะเว็บเปลี่ยนบ่อย) อาจละเมิดข้อกำหนด และมีความเสี่ยงทางกฎหมายมากกว่า สำหรับงานธุรกิจส่วนใหญ่ แนะนำให้ใช้ API
3. ในปี 2026 การดึงข้อมูลจาก Google Maps ด้วย Python มีค่าใช้จ่ายเท่าไร?
ราคาของ Google Places API คิดตามทุก 1,000 request โดยอยู่ตั้งแต่ $5 (Essentials) ไปจนถึง $25 (Enterprise+Atmosphere) ขึ้นอยู่กับฟิลด์ที่คุณขอ มีโควตาใช้ฟรีรายเดือน (10,000 สำหรับ Essentials, 5,000 สำหรับ Pro, 1,000 สำหรับ Enterprise) แต่ถ้าทำสแครประดับใหญ่ ค่าใช้จ่ายจะสะสมเร็วมาก ควรใช้ field mask และตัวกรองฝั่งเซิร์ฟเวอร์เสมอเพื่อคุมค่าใช้จ่าย
4. Thunderbit เทียบกับ Google Maps scraper ที่สร้างด้วย Python อย่างไร?
Thunderbit คือเว็บสแครปแบบไม่ต้องเขียนโค้ดที่ขับเคลื่อนด้วย AI ให้คุณดึงข้อมูล Google Maps (และอีกมากมาย) ได้โดยไม่ต้องเขียนโปรแกรม ใช้ API key หรือดูแลระบบ เหมาะมากสำหรับทีมขายและการตลาดที่ต้องการส่งออกข้อมูลไปยัง Excel, Google Sheets, Airtable หรือ Notion อย่างรวดเร็วและเชื่อถือได้ ส่วนผู้ใช้สายเทคนิคที่ต้องการตรรกะเฉพาะทาง Python จะยืดหยุ่นกว่า แต่ต้องตั้งค่าและจัดการ compliance มากกว่า
5. จะทำให้การดึงข้อมูล Google Maps เป็นงานอัตโนมัติแบบทำซ้ำได้อย่างไร?
ด้วย Python ให้ใช้ไลบรารีตั้งเวลาอย่าง schedule หรือ APScheduler เพื่อรันสแครปเปอร์เป็นช่วง ๆ ที่กำหนดไว้ (รายวัน รายสัปดาห์ ฯลฯ) เพิ่ม jitter แบบสุ่มเพื่อลดการถูกตรวจจับ และเฝ้าดูโควตา API ของคุณ ส่วน Thunderbit คุณสามารถตั้งเวลาสแครปซ้ำได้โดยตรงใน UI—ไม่ต้องเขียนโค้ดหรือเซ็ตเซิร์ฟเวอร์
พร้อมจะเปลี่ยน Google Maps ให้เป็นพลังพิเศษด้านขายและการตลาดของคุณแล้วหรือยัง? ไม่ว่าคุณจะเป็นสาย Python หรืออยากได้โซลูชันที่เร็วที่สุดแบบไม่ต้องเขียนโค้ด เครื่องมือทั้งหมดก็พร้อมให้ใช้งานแล้วในปี 2026 ลอง Thunderbit เพื่อสแครปด้วย AI แบบทันที หรือจะลงมือเจาะลึกกับ API ก็ได้ ไม่ทางใดก็ทางหนึ่ง ขอให้รายชื่อลีดของคุณสดใหม่ การส่งออกข้อมูลสะอาด และแคมเปญของคุณเต็มไปด้วยลูกค้าในพื้นที่ที่มีโอกาสปิดสูง Happy scraping!
เรียนรู้เพิ่มเติม




