
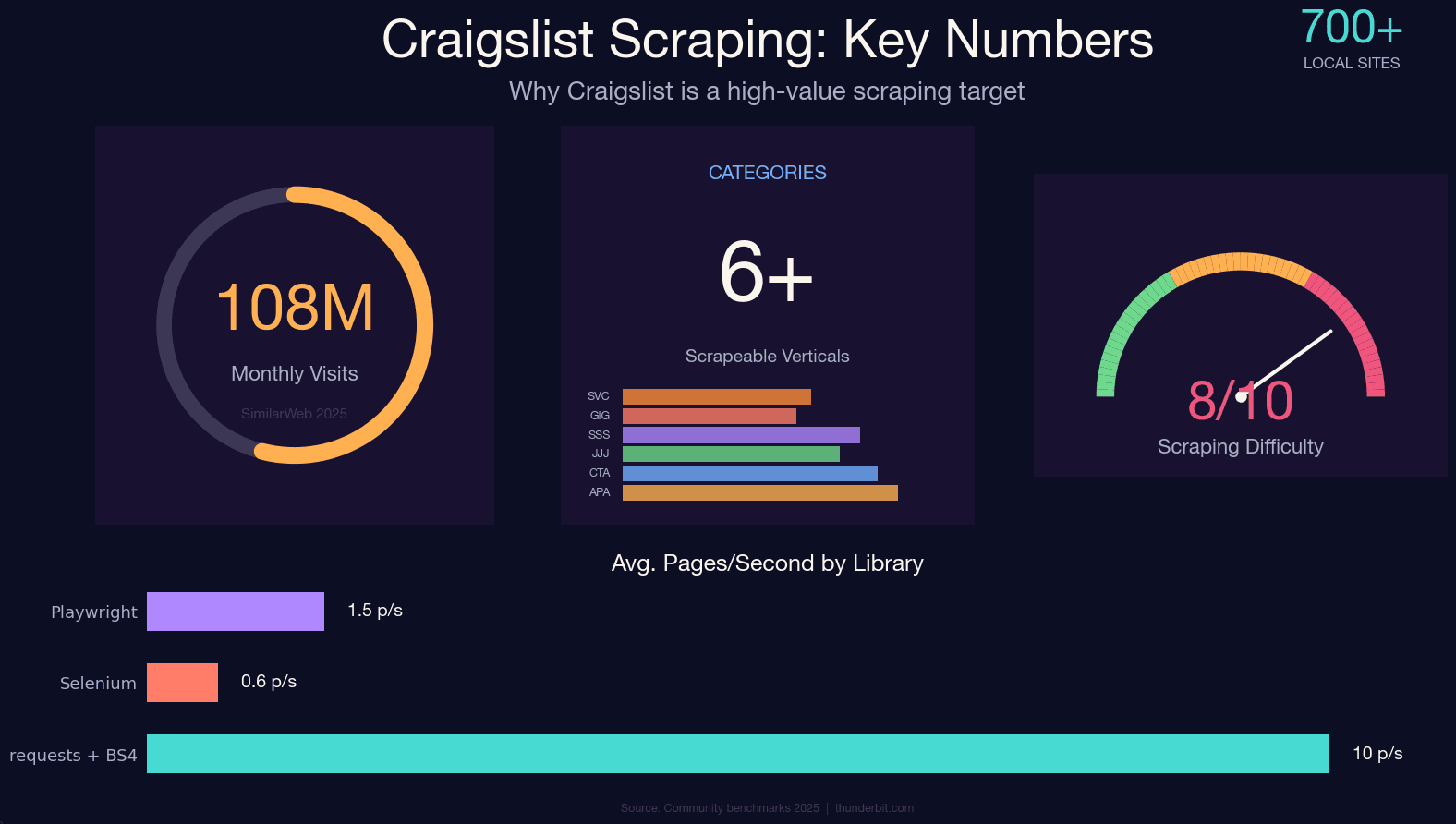
Craigslist ยังคงมีทราฟฟิกราว ๆ จากเว็บไซต์ท้องถิ่นประมาณ 700 แห่ง และก็ยังไม่มี public API ให้ใช้แบบตรง ๆ อยู่ดี ถ้าคุณอยากได้ข้อมูลที่มีโครงสร้างจากประกาศเช่าอพาร์ตเมนต์ รถมือสอง งาน หรือประกาศจ๊อบกิ๊ก การสแครปแทบจะเป็นทางเลือกเดียวที่ใช้งานได้จริง
แต่ระบบกันบอทของ Craigslist นี่ดุเอาเรื่องมาก มันไม่ได้ใช้ Cloudflare หรือ DataDome — แต่ใช้ rate limiter ที่ทำขึ้นเองบน nginx และจูนมานานกว่าทศวรรษ ถ้าส่งคำขอผิดจังหวะ คุณอาจเจอ 403 ตั้งแต่ยังไม่ทันจิบกาแฟแก้วที่สองด้วยซ้ำ ผมใช้เวลาทดสอบหลายวิธีกับแนวป้องกันของ Craigslist พอสมควร และคู่มือนี้ก็คือผลลัพธ์: บทเรียน Python อัปเดตปี 2025 ที่ใช้ได้กับทุกหมวดหมู่ ครอบคลุมวิธีดึง JSON-LD ซึ่งเป็นการอัปเกรดครั้งใหญ่จากไกด์เก่า ๆ กลยุทธ์เลี่ยงแบนแบบตรงไปตรงมา ภาพรวมด้านกฎหมาย และทางเลือกแบบไม่ต้องเขียนโค้ดสำหรับคนที่แค่อยากได้ข้อมูลโดยไม่ต้องแตะบรรทัดโค้ดเลย
การสแครป Craigslist ด้วย Python คืออะไร?
การสแครป Craigslist คือการใช้สคริปต์ Python เข้าไปอ่านหน้า Craigslist แบบอัตโนมัติ แล้วดึงข้อมูลที่มีโครงสร้างที่คุณต้องการ เช่น ชื่อประกาศ ราคา รายละเอียด รูปภาพ ทำเล วันที่โพสต์ แล้วบันทึกออกมาเป็นสเปรดชีต ฐานข้อมูล หรือไฟล์ JSON
Python เป็นภาษายอดนิยมสำหรับงานนี้ เพราะมีไลบรารีให้เลือกครบ ไม่ว่าจะเป็น requests, BeautifulSoup, lxml และ curl_cffi คุณก็สามารถทำ Craigslist scraper ที่ใช้งานได้จริงภายในไม่ถึง 100 บรรทัด ชุมชนนักพัฒนาก็ใหญ่มาก ดังนั้นเมื่อ Craigslist เปลี่ยนอะไรสักอย่าง (ซึ่งมันเปลี่ยนจริง) มักจะมีคนแก้ให้เสร็จแล้ว
สิ่งสำคัญที่ต้องรู้คือ Craigslist ให้ใช้งาน อินเทอร์เฟซแบบเป็นทางการเพียงอย่างเดียวคือ Bulk Posting Interface (BAPI) ซึ่งเป็นแบบเขียนข้อมูลเข้าเท่านั้น ใช้สำหรับผู้ลงประกาศที่ผ่านการอนุมัติและจ่ายเงินเพื่อส่งรายการโพสต์ได้ แต่ไม่ได้ใช้ดึงข้อมูลกลับมา ดังนั้นทุกผลิตภัณฑ์ที่อ้างว่าเป็น “Craigslist API” บนแพลตฟอร์มภายนอก ส่วนใหญ่ก็คือสแครปเปอร์ที่ไม่ได้เป็น endpoint อย่างเป็นทางการ ถ้าคุณต้องการข้อมูลจำนวนมาก คุณก็ต้องสแครป
ทำไมต้องสแครป Craigslist? ตัวอย่างการใช้งานจริง
Craigslist ไม่ได้มีดีแค่หาโซฟามือสอง แต่มันคือชุดข้อมูลขนาดใหญ่ที่อัปเดตตลอดเวลาจากหลายสิบหมวดหมู่ นี่คือกลุ่มคนที่ได้ประโยชน์จริงจากการสแครป:
| กรณีใช้งาน | ใครได้ประโยชน์ | ข้อมูลที่ดึงได้ |
|---|---|---|
| ติดตามราคาอพาร์ตเมนต์และค่าเช่า | นายหน้าอสังหาฯ ผู้เช่า บริษัท PropTech | ราคา, พื้นที่, ห้องนอน, ย่าน, ละติจูด/ลองจิจูด |
| วิเคราะห์ตลาดรถมือสอง | ดีลเลอร์ แอปสำหรับผู้บริโภค นักวิจัย | ราคา, ยี่ห้อ, รุ่น, ปี, เลขไมล์, สภาพ |
| วิจัยตลาดงาน | Recruiter นักเศรษฐศาสตร์แรงงาน นักวิเคราะห์กำลังคน | ชื่อประกาศ, ค่าตอบแทน, ประเภทงาน, วันที่โพสต์ |
| สร้างลีด | ทีมขาย ผู้ให้บริการ | ข้อมูลติดต่อ, ชื่อธุรกิจ, พื้นที่ให้บริการ |
| เปรียบเทียบราคาคู่แข่ง | ผู้ให้บริการในท้องถิ่น ทีมอีคอมเมิร์ซ | ราคาบริการ, คำอธิบาย, พื้นที่ให้บริการ |
ตัวอย่างที่ถูกอ้างถึงบ่อยในงานวิชาการคือ — เป็นประกาศรถมือสองในสหรัฐฯ ราว 500,000 รายการ พร้อมตัวแปร 26 ตัว และถูกนำไปใช้ต่อในงานวิจัยหลายสิบชิ้น รวมถึงงานบน ResearchGate ปี 2024 ที่ศึกษาพลวัตตลาดรถมือสองในสหรัฐฯ กองทุนเฮดจ์ฟันด์ก็เคยซื้อข้อมูลค่าเช่า Craigslist แบบรวมศูนย์ไปใช้วิจัยเทรนด์ค่าเช่า และทีมขายก็สแครปหมวดบริการกับงานกิ๊กเพื่อหาลีดเป็นประจำ
คิดง่าย ๆ คือ ใช้เวลา 8 ชั่วโมงกับการก็อปปี้วางด้วยมือ เทียบกับประมาณ 10 นาทีถ้าคุณมี scraper ที่ทำมาอย่างดี
สแครป Craigslist ด้วย Python: ได้ทุกหมวด ไม่ใช่แค่รถยนต์
ไกด์สแครป Craigslist ที่ผมเจอเกือบทั้งหมดพูดถึงแค่รถขายต่อ ซึ่งก็เหมือนเขียนบทเรียน Google แต่สอนแค่การค้นหารูปภาพ Craigslist มีหลายสิบหมวด และรูปแบบ URL ก็แตกต่างกันไปในแต่ละหมวด
โครงสร้างพื้นฐานจะเป็นแบบนี้: https://{city}.craigslist.org/search/{category_slug}
แค่เปลี่ยนซับโดเมนของเมืองกับ slug คุณก็จะเข้าไปสแครปหมวดอื่นได้ทันที นี่คือตารางอ้างอิงของหมวดหมู่ยอดนิยม (ตรวจสอบแล้วในเดือนเมษายน 2025):
| หมวดหมู่ | URL Slug | ฟิลด์ที่มักดึงได้ |
|---|---|---|
| อพาร์ตเมนต์ / ที่อยู่อาศัย | /search/apa | ราคา, พื้นที่, ห้องนอน, ทำเล, นโยบายสัตว์เลี้ยง |
| รถยนต์และรถบรรทุก | /search/cta | ราคา, ยี่ห้อ, รุ่น, ปี, เลขไมล์ |
| งาน | /search/jjj | ชื่อประกาศ, บริษัท, เงินเดือน, ประเภทการจ้างงาน |
| บริการ | /search/bbb | ชื่อประกาศ, คำอธิบาย, เบอร์โทร, พื้นที่ |
| กิ๊ก | /search/ggg | ชื่อประกาศ, ค่าตอบแทน, วันที่, หมวด |
| ของขายทั่วไป | /search/sss | ชื่อประกาศ, ราคา, สภาพ, ทำเล |
คุณยังสามารถใส่พารามิเตอร์เสริมเพื่อกรองข้อมูลได้ด้วย:
| พารามิเตอร์ | หน้าที่ | ตัวอย่าง |
|---|---|---|
query | คีย์เวิร์ดแบบข้อความเต็ม | ?query=studio |
min_price / max_price | ช่วงราคา | &min_price=1500&max_price=3000 |
hasPic | เฉพาะโพสต์ที่มีรูป | &hasPic=1 |
postedToday | เฉพาะ 24 ชั่วโมงล่าสุด | &postedToday=1 |
sort | การเรียงลำดับ | &sort=priceasc |
s | เลื่อนหน้าสำหรับแบ่งหน้า (120 รายการต่อหน้า) | ?s=120 |
ดังนั้น URL อย่าง https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 ก็จะดึงอพาร์ตเมนต์ในนิวยอร์กที่ราคาอยู่ระหว่าง $1,500 ถึง $3,000 และมีรูปภาพได้เลย scraper ที่ยกตัวอย่างในไกด์นี้ใช้กับทุกหมวดได้เหมือนกัน — แค่เปลี่ยน slug
ตัวเลือก HTML Selector ของ Craigslist ปี 2025: แบบเก่ากับแบบใหม่ (และทางลัดด้วย JSON)
เหตุผลอันดับหนึ่งที่ scraper ของ Craigslist พังคือโครงสร้าง HTML เปลี่ยน ถ้าคุณทำตามไกด์ปี 2022 ที่ให้จับ .result-row หรือ .result-info scraper ของคุณก็แทบจะไปต่อไม่ไหวแล้ว
Craigslist เขียน markup ของผลการค้นหาใหม่ในช่วงปี 2023–2024 ชื่อ class เก่า ๆ ยังอยู่ข้างใน wrapper ใหม่ แต่ถ้าคุณไปจับที่ระดับบนของ DOM ตรง ๆ จะได้ลิสต์ว่างเปล่า นี่คือสิ่งที่เปลี่ยนไป:
| องค์ประกอบ | ตัวเลือกแบบเดิม (ก่อน 2024) | ตัวเลือกปัจจุบัน (2025) |
|---|---|---|
| คอนเทนเนอร์ของรายการ | .result-info | .cl-search-result |
| ลิงก์ชื่อประกาศ | .result-title | .posting-title a |
| ราคา | .result-price | .priceinfo |
| เมตาดาต้า (พื้นที่) | .result-hood | .meta |
แต่มี insight สำคัญกว่านั้น — และนี่คือสิ่งที่แยก scraper แบบอัปเดตปี 2025 ออกจากวิธีอื่นทั้งหมด: คุณไม่จำเป็นต้อง parse HTML เลยสำหรับหน้าผลการค้นหา
ตอนนี้ Craigslist ฝังทุก listing ที่มองเห็นได้ไว้ในแท็ก <script id="ld_searchpage_results"> ในรูป JSON-LD ที่มีโครงสร้าง ช่วง requests.get() ครั้งเดียวก็จะได้ schema.org ItemList ครบทุกประกาศบนหน้า — ทั้งชื่อ ราคา สกุลเงิน ตำแหน่ง URL รูปภาพ และลิงก์ไปหน้ารายละเอียด ไม่ต้อง render JavaScript ไม่ต้องกังวลเรื่อง CSS selector เปลี่ยน
แนวทาง JSON-LD เร็วกว่า เสถียรกว่า และโอกาสพังน้อยกว่ามากเวลาที่ Craigslist ปรับ UI เป็นวิธีที่ repo GitHub ที่ยังดูแลอยู่แทบทั้งหมดใช้ และเป็นวิธีที่เราจะใช้ในบทเรียนด้านล่าง
ข้อควรระวังคือ บล็อก JSON-LD นี้ เช่น อพาร์ตเมนต์ (apa), ของขาย (sss), รถ (cta), ที่อยู่อาศัย (hhh) แต่ในหมวดงาน (jjj), กิ๊ก (ggg), ชุมชน (ccc), และบริการ (bbb) มักไม่มีหรือมีข้อมูลน้อย เพราะ listing เหล่านั้นไม่ได้มี schema.org/Offer เรื่องราคา ถ้าเจอหมวดแบบนั้น ให้กลับไปใช้การ parse HTML จาก .cl-search-result
เลือก Python Stack แบบไหนดี: Requests + BS4, Selenium หรือ Playwright
นี่คือคำถามที่เจอบ่อยในทุกฟอรัมสแครปปิ้ง: “ควรใช้ไลบรารีไหน?” สำหรับ Craigslist คำตอบชัดกว่าหลายเว็บไซต์
| ปัจจัย | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| ความเร็ว | 5–15 หน้า/วินาที (จำกัดด้วยเครือข่าย) | 0.3–1 หน้า/วินาที | 0.5–2 หน้า/วินาที |
| เนื้อหาที่ต้อง render ด้วย JS | ไม่ต้อง | ใช่ | ใช่ |
| หน่วยความจำ | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| ความยากในการติดตั้ง | ต่ำ | ปานกลาง | ปานกลาง |
| ความทนต่อ anti-bot | ต่ำ (ต้องพึ่ง headers/proxy) | ปานกลาง (เบราว์เซอร์จริง) | ปานกลาง-สูง |
| กรณีใช้กับ Craigslist ที่เหมาะ | หน้าผลการค้นหา (JSON-LD) | หน้ารายละเอียดที่มี dynamic content | สแครปจำนวนมากแบบ async |
| ระยะเวลาเรียนรู้ | เริ่มได้ง่าย | ปานกลาง | ปานกลาง |
หน้า Craigslist เป็น server-rendered ทั้งหมด และ JSON-LD blob ก็อยู่ใน HTML ชุดแรกอยู่แล้ว ไม่มี JavaScript challenge ในเส้นทางอ่านข้อมูลเลย scraper ที่ดูแลอยู่บน GitHub สำหรับ Craigslist ทั้งนั้น ไม่มีตัวไหนใช้ Selenium หรือ Playwright เลย นั่นไม่ใช่เรื่องบังเอิญ — เฟรมเวิร์ก automation แบบเบราว์เซอร์จะเพิ่มการใช้หน่วยความจำหลายร้อย MB ช้าลง 10–100 เท่า และทิ้ง fingerprint ที่มองเห็นได้ชัดกว่า โดยไม่ได้ประโยชน์เพิ่ม
คำแนะนำของผม:
- requests + BS4: เริ่มจากตรงนี้ก่อน มันเข้ากันได้พอดีกับวิธีดึง JSON-LD และตอบโจทย์การสแครป Craigslist ได้ถึง 95%
- Selenium: ใช้เฉพาะกรณีต้องโต้ตอบกับ dynamic content บนหน้ารายละเอียดเฉพาะเจาะจง ซึ่งบน Craigslist เจอน้อยมาก
- Playwright: ใช้เมื่อคุณต้องสเกลไปหลายพันหน้าพร้อม async concurrency — แต่พูดตรง ๆ คือคอขวดจริงของ Craigslist คือ rate limiter ไม่ใช่ throughput ของไลบรารีคุณ
ถ้าคุณอยากอ่านการเปรียบเทียบ และสรุป เราได้เขียนแยกไว้ในโพสต์อื่นแล้ว
ทางเลือกแบบไม่ต้องเขียนโค้ด: สแครป Craigslist โดยไม่ต้องใช้ Python
ขอแวะออกนอกเรื่องโค้ดสักนิด — ส่วนนี้สำหรับคนที่ไม่ใช่นักพัฒนาโดยเฉพาะ ไม่ว่าจะเป็นนายหน้าอสังหาฯ ทีมขาย หรือผู้จัดการฝ่ายปฏิบัติการ ถ้าคุณแค่อยากได้ข้อมูลและไม่อยากเขียน Python มีทางที่เร็วกว่านั้น
คือ AI web scraper ที่ทำงานเป็น Chrome extension มันสแครป Craigslist ได้ในประมาณ 2 คลิก โดยไม่ต้องเขียนโค้ด ขั้นตอนการใช้งานมีดังนี้:
- เข้าไปยังหน้าผลการค้นหา Craigslist ใดก็ได้ (อพาร์ตเมนต์ รถ งาน — หมวดไหนก็ได้)
- คลิก "AI Suggest Fields" ใน sidebar ของ Thunderbit ให้ AI อ่านหน้าแล้วเดาคอลัมน์อัตโนมัติ เช่น ชื่อประกาศ ราคา ทำเล และลิงก์
- คลิก "Scrape" — ข้อมูลจะถูกดึงออกมาในไม่กี่วินาที
- ใช้ Subpage Scraping เพื่อเข้าไปยังหน้ารายละเอียดของแต่ละประกาศ และเติมข้อมูลให้ครบ เช่น คำอธิบาย เบอร์โทร รูปภาพ และแอตทริบิวต์ต่าง ๆ
- ส่งออกตรงไปยัง Google Sheets, Excel, Airtable หรือ Notion — ฟรีทั้งหมด
ถ้าคุณต้องทำซ้ำเป็นประจำ เช่น ติดตามราคาอพาร์ตเมนต์ทุกวัน หรือเก็บ snapshot ประกาศงานทุกสัปดาห์ Scheduled Scraper ของ Thunderbit ให้คุณกำหนดตารางเวลาเป็นภาษาธรรมดาได้เลย แล้วระบบจะรันอัตโนมัติ ไม่ต้องตั้ง cron job ไม่ต้องดูแล server
Thunderbit ยังรับมือกับมาตรการ anti-bot ผ่านโหมด Cloud Scraping ทำให้คุณไม่ต้องกังวลเรื่อง rotating proxy หรือการปรับ headers เอง ถ้าอยากลอง ลองติดตั้ง แล้วดูผลเองได้เลย
ถ้าคุณต้องการควบคุมและปรับแต่งทุกอย่างด้วยตัวเอง อ่านขั้นตอน Python ต่อได้เลย
ทีละขั้นตอน: วิธีสแครป Craigslist ด้วย Python (ฉบับเต็ม)
- ระดับความยาก: ปานกลาง
- เวลาที่ใช้: ประมาณ 30 นาที (ตั้งค่า + สแครปรอบแรก)
- สิ่งที่ต้องมี: Python 3.8+, เบราว์เซอร์ Chrome (สำหรับตรวจหน้าเว็บ), เทอร์มินัล
ขั้นตอนที่ 1: ตั้งค่าสภาพแวดล้อม Python
ติดตั้งไลบรารีที่จำเป็น:
1pip install requests beautifulsoup4 lxmllxml เป็นตัวเลือกเสริม แต่ช่วยให้ BeautifulSoup parse เร็วขึ้นอย่างเห็นได้ชัด ถ้าหลังจากนี้คุณเจอปัญหา TLS fingerprinting (จะอธิบายในส่วนเลี่ยงแบน) คุณสามารถติดตั้ง curl_cffi เพิ่มได้:
1pip install curl_cffiชุด import ของคุณจะเป็นแบบนี้:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomตอนนี้คุณก็ควรมี Python environment ที่สะอาดพร้อม dependencies ครบแล้ว
ขั้นตอนที่ 2: สร้าง URL ของ Craigslist สำหรับทุกหมวด
สร้าง URL เป้าหมายแบบไดนามิกโดยใช้ city + category slug + ตัวกรองเสริม:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# ตัวอย่าง: อพาร์ตเมนต์นิวยอร์ก ราคา 1500-3000 ดอลลาร์ พร้อมรูป
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1เปลี่ยน "apa" เป็น "cta" (รถ), "jjj" (งาน), "bbb" (บริการ) หรือ slug อื่นจากตารางด้านบน และเปลี่ยน "newyork" เป็น "sfbay", "chicago", "losangeles" ฯลฯ ได้เลย
ขั้นตอนที่ 3: ดึงหน้าเว็บและแยก JSON ที่ฝังอยู่
ส่ง GET request พร้อม headers ที่เหมาะสม แล้ว parse บล็อก JSON-LD:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}ถ้า tag เป็น None แปลว่าบล็อก JSON-LD ไม่มีในหมวดนั้น — ให้ fallback ไป parse HTML (ดูตาราง selector ข้างต้น) สำหรับอพาร์ตเมนต์ รถ และหมวดของขาย บล็อก JSON-LD จะมีอยู่ค่อนข้างสม่ำเสมอ
ขั้นตอนที่ 4: แปลงข้อมูลประกาศเป็น record ที่มีโครงสร้าง
วนลูปผ่านรายการใน JSON แล้วดึงฟิลด์ที่ต้องการ:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"พบประกาศ {len(listings)} รายการ")คุณน่าจะเห็นอะไรประมาณ “Found 120 listings” (Craigslist แสดงผล 120 รายการต่อหน้า) บางประกาศอาจมีค่า None ในช่อง price ถ้าผู้โพสต์ไม่ได้กรอกไว้ — ให้เตรียมรับมือกรณีนี้ใน logic ต่อไป
ขั้นตอนที่ 5: สแครปหน้ารายละเอียดเพื่อข้อมูลที่ครบกว่า
หน้าผลการค้นหามีแค่ข้อมูลสรุป ถ้าต้องการรายละเอียดเต็ม ๆ แอตทริบิวต์ต่าง ๆ (ห้องนอน พื้นที่ นโยบายสัตว์เลี้ยง) พิกัดละติจูด/ลองจิจูด และรูปภาพ คุณต้องเข้าไปที่ URL รายละเอียดของแต่ละรายการ
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # สำคัญมาก: หน่วงแบบสุ่มเพื่อเลี่ยงแบนtime.sleep(random.uniform(3, 6)) ไม่ใช่ตัวเลือกเสริม ถ้าไม่ใส่ คุณมีโอกาสโดน 403 ภายในไม่กี่สิบ request หน้ารายละเอียดเป็น server-rendered และใช้ selector ที่ค่อนข้างเสถียร (#titletextonly, #postingbody, #map) ซึ่งแทบไม่เปลี่ยนมาตั้งแต่ราวปี 2017 — เป็นไม่กี่อย่างใน Craigslist ที่เชื่อถือได้จริง
ขั้นตอนที่ 6: จัดการ pagination เพื่อดึงผลลัพธ์ทั้งหมด
Craigslist ใช้พารามิเตอร์ offset ?s=120 สำหรับแบ่งหน้า โดยแต่ละหน้ามี 120 รายการ และ offset สูงสุดมักอยู่ที่ 2999
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))อย่าพยายามสแครปเป็นพันหน้าแบบถี่ ๆ Craigslist จำกัดตาม IP และ throughput ที่ยั่งยืนจาก IP เดียวจะอยู่ราว 0.3–0.5 request/วินาที ไม่ว่าคุณจะใช้ไลบรารีไหนก็ตาม เพดานนี้ถูกกำหนดโดย Craigslist ไม่ใช่โดย Python
ขั้นตอนที่ 7: ส่งออกข้อมูล Craigslist เป็น CSV, JSON หรือ Google Sheets
บันทึกผลลัพธ์ของคุณ:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)ถ้าอยากข้ามการเขียนโค้ดส่งออกไปเลย Thunderbit มีการส่งออกฟรีไปยัง Google Sheets, Excel, Airtable หรือ Notion ได้โดยตรงจากเบราว์เซอร์ แต่ถ้าเป็น pipeline ด้วย Python ไฟล์ CSV และ JSON คือรูปแบบมาตรฐาน คุณยังสามารถส่งต่อข้อมูลไปยัง pandas เพื่อวิเคราะห์ หรือเก็บลงฐานข้อมูลด้วย sqlite3 ได้อีกด้วย
วิธีไม่ให้โดนแบนเมื่อสแครป Craigslist ด้วย Python
ไกด์จำนวนมากมักพูดข้ามส่วนนี้ไป Craigslist มีระบบกันบอทที่สร้างเอง ไม่ได้ซื้อสำเร็จรูป และมีรายละเอียดเฉพาะบางอย่างที่ควรรู้

ใช้ Request Header ให้ดูสมจริง
Craigslist ตรวจสอบทั้งลำดับและความครบถ้วนของ headers ถ้าคำขอของคุณไม่มี Sec-Fetch-Dest หรือใช้ User-Agent ที่เก่ามาก ระบบจะจับได้ก่อนที่จะไปถึงเนื้อหา ชุด header แบบ Chrome 120+ เต็มชุด (ตามที่แสดงใน Step 3 ด้านบน) คือขั้นต่ำที่ควรมี ควรสุ่ม User-Agent ตาม session จากสตริง Chrome/Firefox desktop เวอร์ชันล่าสุดประมาณ 5–10 แบบ — แต่อย่าเปลี่ยนกลางเซสชัน เพราะจะดูไม่ธรรมชาติ
การขาด Sec-Fetch-* headers คือสาเหตุที่พบบ่อยที่สุดที่ทำให้ scraper มือใหม่โดนบล็อกทันที
ใส่ดีเลย์แบบสุ่มระหว่างคำขอ
จากความเห็นของชุมชนจากหลายแหล่ง (ScrapingBee, Scraperly, Oxylabs, Multilogin) ค่าที่ลงตัวคือ สุ่ม 2–5 วินาที ระหว่างการดึงหน้าผลการค้นหา และ 3–6 วินาที ระหว่างหน้ารายละเอียด ล็อกเวลาตายตัวจะดูเหมือนบอท ใช้ time.sleep(random.uniform(2, 5)) — อย่าใช้ time.sleep(2) แบบคงที่
ใช้ Proxy แบบหมุนเวียนถ้าสแครปในสเกลใหญ่
Craigslist มักบล็อกช่วง IP ของ AWS, GCP และ Azure ไว้ล่วงหน้า proxy ของดาต้าเซ็นเตอร์หลายครั้งตายตั้งแต่ยังไม่เริ่ม ถ้าคุณจะดึงมากกว่าสองสามร้อยหน้า คุณจะต้องใช้ residential rotating proxies และหมุนทุก 20–30 request ส่วน mobile proxy มีความเสี่ยงในการถูกตรวจจับต่ำสุด แต่ราคาก็อยู่ที่ $8–30/GB
| ประเภท Proxy | ความเสี่ยงถูกตรวจจับบน Craigslist | ราคา (2025) |
|---|---|---|
| ดาต้าเซ็นเตอร์ | สูงมาก — มักโดนบล็อกตั้งแต่ request แรก | $0.50–2/GB |
| Residential แบบหมุนเวียน | ต่ำ — แนะนำ | $5–15/GB |
| Mobile | ต่ำที่สุด | $8–30/GB |
โหมด Cloud Scraping ของ Thunderbit จะจัดการการหมุน proxy ให้โดยอัตโนมัติ ถ้าคุณไม่อยากดูแลส่วนนี้เอง
รับมือ CAPTCHA อย่างสุภาพ
CAPTCHA บน Craigslist พบไม่บ่อยในเส้นทางอ่านข้อมูล — ส่วนใหญ่จะโผล่ใน flow สำหรับโพสต์หรือ reply ถ้าเจอ ให้หยุดอย่างน้อย 60 วินาที เปลี่ยน IP ล้าง cookies และลดความเร็วลง CAPTCHA ที่ขึ้นซ้ำ ๆ เป็นสัญญาณว่าจังหวะของคุณแรงเกินไป ไม่ใช่ปัญหาที่ต้อง brute-force ด้วย solver
เคารพ Rate Limit และทำ Backoff
Craigslist จะตอบ 403 (ไม่ใช่ 429) เมื่อคุณชน rate limit ดังนั้น 403 หมายถึง IP ปัจจุบันถูกใส่ใน deny list แล้ว — อย่าพยายาม retry แบบเดาสุ่ม เปลี่ยน IP เปลี่ยน UA แล้วรอ
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1.5, 3, 6, 12, 24 วินาที
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)อีกทิปหนึ่ง: รายงานจากชุมชนมักบอกว่า ช่วง 2–6 โมงเช้าตามเวลาท้องถิ่นของเมืองเป้าหมาย เป็นช่วงสแครปที่ปลอดภัยที่สุด โดยอัตราการบล็อกจะต่ำกว่าช่วงกลางวันราว 30–40%
TLS Fingerprinting — กับดักที่มองไม่เห็น
ชั้น bot ของ Craigslist ตรวจสอบ TLS ClientHello ด้วย ไลบรารี requests ของ Python (ที่อยู่บน OpenSSL) มี JA3 fingerprint ที่ไม่เหมือนเบราว์เซอร์จริง เมื่อจับ User-Agent ที่ดูดีเข้าคู่กับ TLS fingerprint ที่ไม่ใช่เบราว์เซอร์ ระบบก็ตรวจจับได้ วิธีแก้คือใช้ พร้อม impersonate="chrome124" เพื่อจำลอง handshake แบบ Chrome:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")ถ้าคุณเจอ 403 แบบไม่มีเหตุผล ทั้งที่ใช้ residential IP สะอาดและ headers ถูกต้อง สาเหตุมีโอกาสสูงมากที่จะเป็น TLS fingerprinting
robots.txt, เงื่อนไขการใช้งาน และการสแครปอย่างมีจริยธรรมของ Craigslist
ไกด์ส่วนใหญ่มักข้ามเรื่องนี้ไปเลย หรือใส่ไว้แค่บรรทัดเดียวใน FAQ แต่เมื่อ Craigslist เคยชนะคดี จาก scraper (RadPad, 2017) เรื่องนี้สมควรพูดให้ชัดกว่าหัวข้อเล็ก ๆ
robots.txt ของ Craigslist บอกอะไรจริง ๆ
ไฟล์ สั้นกว่าที่คิด มีบล็อก User-agent: * เพียงบล็อกเดียว และมี path ที่ไม่อนุญาตแค่เจ็ดรายการ:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafทั้งเจ็ดเป็น endpoint แบบโต้ตอบหรือเปลี่ยนสถานะ เช่น reply, flag, suggest, email-a-friend เท่านั้น หน้ารายการ (/search/...) และ URL ของโพสต์แต่ละรายการไม่ได้ถูกห้าม แม้จะไม่มี Crawl-delay กำกับ แต่ Craigslist ก็ยังบังคับพฤติกรรมนี้ผ่านการบล็อก IP อยู่ดี
ซับโดเมนของแต่ละเมืองยังมี sitemap ให้ด้วย เช่น https://newyork.craigslist.org/sitemap/index.xml ซึ่งเป็นเส้นทางทางการที่ใช้ค้นหารายการได้
บรรทัดฐานทางกฎหมาย: คดีที่ควรรู้
Craigslist v. 3Taps (2013, ยอมความ 2015): 3Taps สแครปประกาศจาก Craigslist แล้วนำไปขายต่อ เมื่อ Craigslist ส่งจดหมายให้หยุดและบล็อก IP ของพวกเขา 3Taps ก็อ้อมบล็อกด้วย rotating proxy ศาลวินิจฉัยว่าการหลีกเลี่ยง IP block หลังจากถูกถอนสิทธิ์อย่างชัดเจน ถือว่า “without authorization” ภายใต้ CFAA โดย 3Taps
Meta v. Bright Data (2024): คำตัดสินล่าสุดชี้ว่า TOS ของ Meta ไม่สามารถห้ามการสแครปข้อมูลสาธารณะที่เข้าถึงได้ในขณะล็อกเอาต์ได้ ศาลระบุว่าผู้สแครปที่ไม่ได้ล็อกอินก็ “ยืนอยู่ในฐานะเดียวกับผู้เยี่ยมชม” นี่คือคำวินิจฉัยที่สำคัญที่สุดสำหรับคนสแครปในปี 2024–2025 — ถ้าคุณไม่เคยสร้างบัญชี Craigslist ไม่เคยล็อกอิน และเข้าถึงเฉพาะหน้าที่เปิดให้เห็นสาธารณะ TOS อาจใช้บังคับคุณในฐานะสัญญาไม่ได้
สรุปเชิงปฏิบัติ: ความเสี่ยงภายใต้ CFAA ลดลงมากหลังคดี Van Buren (2021) และ hiQ v. LinkedIn (2022) สำหรับหน้าที่เข้าถึงได้สาธารณะ แต่ข้อเรียกร้องตามกฎหมายรัฐ เช่น trespass-to-chattels และ misappropriation ยังมีอยู่จริง — ซึ่งเป็นตัวที่ทำให้เกิดทั้งการยอมความของ 3Taps และคำพิพากษา $60.5 ล้านของ RadPad
ข้อมูลนี้มีไว้เพื่อให้ทราบ ไม่ใช่คำปรึกษาทางกฎหมาย ถ้าคุณจะสแครป Craigslist เพื่อการค้า ควรปรึกษาทนาย
เช็กลิสต์การสแครปอย่างมีจริยธรรม
- ✅ เคารพ
Disallowทุกบรรทัดใน robots.txt — โดยเฉพาะเจ็ด endpoint สำหรับการกระทำ - ✅ อย่าสแครปเกิน 1,000 หน้าในช่วง 24 ชั่วโมงต่อ IP (TOS ของ Craigslist กำหนดค่าเสียหายไว้ที่ เมื่อเกินเกณฑ์นี้)
- ✅ อยู่ในสถานะล็อกเอาต์ — อย่าสร้างบัญชี Craigslist เพื่อใช้สแครป
- ✅ อย่าหลีกเลี่ยงการแบน IP ด้วย proxy หลังจากถูกบล็อกแบบชัดเจน (นั่นแหละที่ทำให้ 3Taps พัง)
- ✅ ใส่ดีเลย์ระหว่าง request — อย่างน้อย 2–5 วินาที
- ✅ อย่าสแครปข้อมูลติดต่อส่วนบุคคลไปใช้สแปม
- ✅ อย่านำข้อมูลดิบจาก Craigslist ไปเผยแพร่ต่อหรืออ้างว่าเป็นแพลตฟอร์มของตัวเอง
- ✅ ใช้ข้อมูลเพื่อการวิจัย การวิเคราะห์ หรือการใช้งานส่วนตัวที่ถูกต้อง
- ✅ ถ้าทำได้ ให้ใช้ sitemap ที่เผยแพร่ไว้แทนการไล่ crawl แบบ brute-force
- ✅ ลบข้อมูลส่วนบุคคล (PII) เช่น อีเมลและเบอร์โทรออกตั้งแต่ขั้นตอน ingestion ถ้าคุณต้องเก็บข้อมูล
เราเขียนคู่มือเชิงลึกเกี่ยวกับ ไว้ถ้าคุณอยากเห็นภาพรวมเต็ม ๆ
Python vs. No-Code: วิธีไหนเหมาะกับคุณ?
| ปัจจัย | Python (requests + BS4) | Thunderbit (No-Code) |
|---|---|---|
| เวลาติดตั้ง | 30–60 นาที (ติดตั้ง, เขียนโค้ด) | 2 นาที (ติดตั้ง Chrome extension) |
| ทักษะที่ต้องมี | Python ระดับปานกลาง | ไม่มี |
| การปรับแต่ง | ควบคุม logic, fields, flow ได้เต็มที่ | AI ตรวจจับฟิลด์อัตโนมัติ; ผู้ใช้ปรับได้ |
| สเกล | ไม่จำกัด (ถ้ามี proxy, scheduling) | Scheduled Scraper สำหรับงานซ้ำ ๆ |
| การรับมือการแบน | ทำเอง (headers, delays, proxies, TLS) | มีให้ในตัว (Cloud Scraping) |
| ตัวเลือกการส่งออก | CSV, JSON (เขียนโค้ดเอง) | Google Sheets, Excel, Airtable, Notion — ฟรี |
| เหมาะกับใคร | นักพัฒนา, data scientist, pipeline แบบกำหนดเอง | ทีมขาย, นายหน้าอสังหาฯ, ops manager |
ใช้ Python ถ้าคุณต้องการปรับแต่งแบบเต็มรูปแบบ วางแผนจะเชื่อมต่อกับ data pipeline ขนาดใหญ่ หรืออยากเข้าใจว่าเบื้องหลังทำงานอย่างไร ใช้ ถ้าคุณต้องการผลลัพธ์เร็ว โดยไม่ต้องเขียนหรือดูแลโค้ด ทั้งสองแบบใช้ได้หมด ขึ้นอยู่กับ use case ของคุณ และว่าคุณอยากใช้เวลากับ terminal หรือเบราว์เซอร์มากกว่ากัน
สรุป
Craigslist เป็นแหล่งข้อมูลที่อัปเดตตลอดเวลา ครอบคลุมที่อยู่อาศัย รถ งาน บริการ กิ๊ก และอื่น ๆ อีกมาก และเพราะไม่มี public API การสแครปจึงเป็นทางเดียวที่จะได้ข้อมูลที่มีโครงสร้างในสเกลใหญ่ แนวทางที่เวิร์กในปี 2025 คือดึง JSON-LD ที่ฝังอยู่ในผลการค้นหาแทนการพึ่ง CSS selector ที่เปราะบาง ใช้ requests + BeautifulSoup แทน Selenium ใส่ headers ที่สมจริงพร้อม Sec-Fetch-* สุ่มดีเลย์ และใช้ residential proxy ถ้าคุณจะเกินไม่กี่ร้อยหน้า
วิธี JSON-LD คือการอัปเกรดที่ใหญ่ที่สุดจากไกด์เก่า ๆ มันเร็วกว่า ทนต่อการเปลี่ยน layout มากกว่า และไม่ต้อง render JavaScript เลย ถ้าคุณจับคู่กับกลยุทธ์เลี่ยงแบนด้านบน คุณจะหลีก 403 ที่ทำให้สแครปเปอร์ส่วนใหญ่สะดุดได้
ถ้าไม่อยากเขียนโค้ดเลย ก็สแครป Craigslist ได้ทุกหมวดในไม่กี่คลิก แล้วส่งออกไปยังสเปรดชีตหรือฐานข้อมูลที่คุณใช้เป็นประจำได้ตรง ๆ ถ้าอยากเจาะลึกขึ้น คู่มือของเราเรื่อง และ จะช่วยปูพื้นฐานแบบละเอียด
คำถามที่พบบ่อย
การสแครป Craigslist ถูกกฎหมายไหม?
เงื่อนไขการใช้งานของ Craigslist ห้ามการสแครปแบบอัตโนมัติ และมีข้อกำหนดค่าเสียหายแบบกำหนดไว้ล่วงหน้า ($0.25/หน้าเมื่อเกิน 1,000 หน้า/วัน) อย่างไรก็ตาม คำตัดสินของศาลในช่วงหลัง — โดยเฉพาะ Meta v. Bright Data (2024) และ hiQ v. LinkedIn (2022) — ทำให้ความรับผิดภายใต้ CFAA แคบลงสำหรับการสแครปข้อมูลสาธารณะขณะล็อกเอาต์ ถึงอย่างนั้น ความเสี่ยงจากการฟ้องตามกฎหมายรัฐ (เช่น trespass-to-chattels) ยังมีอยู่ โดยเฉพาะเมื่อมีการนำข้อมูลไปเผยแพร่เชิงพาณิชย์ ควรเคารพ robots.txt อยู่ในสถานะล็อกเอาต์ ใส่ดีเลย์ และอย่านำข้อมูลดิบไปกระจายต่อ ข้อมูลนี้เป็นข้อมูลทั่วไป ไม่ใช่คำปรึกษาทางกฎหมาย
Craigslist มี public API ไหม?
ไม่มี Craigslist มีเพียง Bulk Posting Interface (BAPI) แบบเขียนข้อมูลเข้าเท่านั้นสำหรับผู้ลงประกาศที่ได้รับอนุมัติและจ่ายเงิน ไม่มี public read API ไม่มี developer portal และไม่มี tier สำหรับดึงข้อมูลที่ถูกจำกัดด้วย rate limit ผลิตภัณฑ์ที่อ้างว่าเป็น “Craigslist API” บนแพลตฟอร์มอื่น ๆ ส่วนใหญ่คือสแครปเปอร์ที่ไม่ได้เป็นทางการ
ทำไม scraper ของ Craigslist ของฉันถึงพังอยู่เรื่อย ๆ?
แทบทุกครั้งเกิดจากโครงสร้าง HTML เปลี่ยน Craigslist เขียน markup ของผลการค้นหาใหม่ในช่วงปี 2023–2024 และไกด์ที่ยังใช้ selector เก่าอย่าง .result-row หรือ .result-info จึงใช้ไม่ได้แล้ว ให้เปลี่ยนไปใช้วิธีดึง JSON-LD ที่ฝังอยู่ (script#ld_searchpage_results) จะเสถียรกว่ามาก และอย่าลืมตรวจว่า headers ของคุณมี Sec-Fetch-* ครบ เพราะถ้าขาดจะโดนบล็อกทันที
สแครป Craigslist โดยไม่ใช้ Python ได้ไหม?
ได้ Thunderbit AI web scraper Chrome extension ใช้งานได้กับทุกหน้า Craigslist — ไม่ว่าจะเป็นอพาร์ตเมนต์ รถ งาน หรือบริการ คลิก “AI Suggest Fields” เพื่อให้ระบบเดาคอลัมน์อัตโนมัติ คลิก “Scrape” เพื่อดึงข้อมูล แล้วส่งออกไป Google Sheets, Excel, Airtable หรือ Notion ได้ฟรี ไม่ต้องเขียนโค้ด ไม่ต้องตั้งค่า ไม่ต้องจัดการ proxy
ควรสแครป Craigslist บ่อยแค่ไหนถึงจะไม่โดนแบน?
ถ้าใช้ residential IP เดียว ความเร็วที่ยั่งยืนจะอยู่ราว 0.3–0.5 request ต่อวินาที โดยเว้น 2–5 วินาทีแบบสุ่มระหว่างหน้า ควรอยู่ต่ำกว่า 1,000 หน้าต่อ 24 ชั่วโมงต่อ IP เพื่อเลี่ยงทั้งการแบนและเกณฑ์ค่าเสียหายใน TOS ของ Craigslist การสแครปช่วงเวลาคนน้อย (2–6 โมงเช้าตามเวลาท้องถิ่นของเมืองเป้าหมาย) จะช่วยลดอัตราการบล็อกราว 30–40% สำหรับปริมาณที่มากขึ้น ควรหมุน residential proxy ทุก 20–30 request
อ่านเพิ่มเติม