บอกเลยว่า ถ้าผมได้ดอลลาร์ทุกครั้งที่มีคนส่งไฟล์ PDF ที่อัดแน่นไปด้วย “ข้อมูลสำคัญ” มาให้ แล้วคาดหวังให้ผมแปลงมันเป็นสเปรดชีตได้ราวกับใช้เวทมนตร์ ผมคงมีเงินพอซื้อกาแฟได้ทั้งชีวิตเลยล่ะ (แถมอาจจะมี Chrome extension เพิ่มมาอีกหลายตัวด้วย) PDF อยู่รอบตัวเราไปหมด—สัญญาขาย แคตตาล็อกสินค้า งานวิจัย ใบแจ้งหนี้ จะเรียกอะไรก็มีทั้งนั้น แต่พอถึงเวลาจะเอาข้อมูลข้างในไฟล์พวกนี้มา ใช้งานจริง น่ะหรือ? ตรงนั้นแหละที่ความสนุก (อ่านว่า: ปวดหัว) เริ่มขึ้น
ผมเคยผ่านจุดนั้นมาแล้ว—ทั้งก็อปปี้ วาง จัดรูปแบบใหม่ และบางทีก็ยอมแพ้ไปเลยตอนที่ฟอร์แมตพังเละ หรือรูปกับลิงก์หายวับไปกับตา แต่ข่าวดีคือ โลกของการดึงข้อมูลจาก PDF เปลี่ยนไปมาก โดยเฉพาะเมื่อมีเครื่องมือที่ขับเคลื่อนด้วย AI เข้ามา ถ้าคุณเบื่อกับการนั่งคีย์ตัวเลขซ้ำ ๆ เป็นชั่วโมง ๆ หรือหงุดหงิดกับตารางที่พังไม่เป็นท่า คุณมาถูกที่แล้ว มาดำดิ่งสู่โลกของการดึงข้อมูลจาก PDF กันว่า ทำไมมันถึงสำคัญ และเครื่องมืออย่าง ช่วยให้เรื่องนี้ง่ายขึ้นได้อย่างไร (ในที่สุดก็ไม่ต้องทรมานกันแล้ว)
การดึงข้อมูลจาก PDF คืออะไร? เข้าใจพื้นฐานของการแยกข้อมูลจาก PDF
เริ่มแบบง่าย ๆ ก่อน: การดึงข้อมูลจาก PDF ก็คือวิธีพูดหรู ๆ ของคำว่า “เอาข้อมูลที่มีโครงสร้างออกมาจากไฟล์ PDF แบบอัตโนมัติ” นั่นเอง ส่วน เครื่องมือดึงข้อมูลจาก PDF ก็คือเครื่องมือ (ซอฟต์แวร์ ส่วนขยาย หรือบริการ) ที่ดึงสิ่งที่คุณสนใจ—ไม่ว่าจะเป็นข้อความ ตาราง รูปภาพ ลิงก์ หรืออะไรก็ตาม—ออกมาเป็นรูปแบบที่เอาไปใช้งานต่อได้จริง เช่น Excel, Google Sheets หรือฐานข้อมูล
แต่ประเด็นคือ PDF ไม่ได้เหมือนเว็บเพจหรือไฟล์ Excel มันเหมือนเอกสารพิมพ์ดิจิทัลมากกว่า ออกแบบมาให้หน้าตาเหมือนเดิมทุกที่ ไม่ได้ออกแบบมาให้คอมพิวเตอร์แกะง่าย ๆ บางไฟล์มีข้อความที่เลือกได้ บางไฟล์เป็นแค่รูปภาพที่สแกนมา (ซึ่งต้องใช้ OCR—การรู้จำตัวอักษรจากภาพ) และฟอร์แมตก็อาจเละได้สารพัด ดังนั้นการดึงข้อมูลจาก PDF ไม่ใช่แค่การก็อปข้อความออกมา แต่มันคือการถอดรหัสปริศนาที่ประกอบด้วยเลย์เอาต์ ฟอนต์ และบางครั้งรวมถึงเมตาดาต้าที่ซ่อนอยู่ด้วย
แล้วดึงอะไรออกจาก PDF ได้บ้าง?
- ข้อความล้วน (ย่อหน้า หัวข้อ ฯลฯ)
- ตาราง (เช่น งบการเงิน สเปกสินค้า ข้อมูลจากแบบสำรวจ)
- รูปภาพและกราฟิก (กราฟ โลโก้ ลายเซ็นที่สแกนมา)
- ไฮเปอร์ลิงก์และการอ้างอิง (URL ที่ฝังอยู่ การอ้างอิง)
- ข้อมูลจากฟอร์ม (ช่องข้อมูลจากแบบฟอร์มที่กรอกได้)
- เมตาดาตา (ผู้เขียน ชื่อเรื่อง วันที่สร้าง แท็ก)
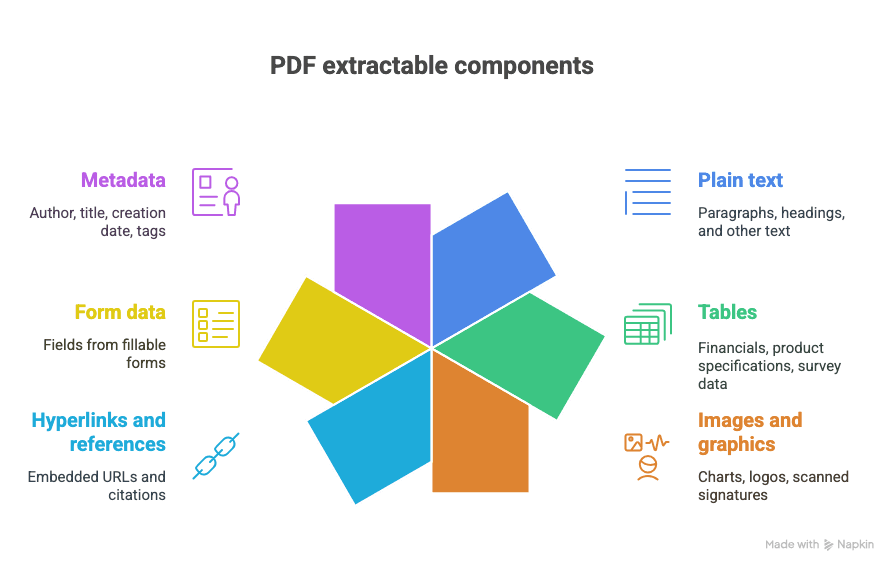
และใช่ บางครั้งทั้งหมดนี้ก็ปนกันอยู่ในเอกสารเดียวแบบวุ่นวายสุด ๆ
ทำไมการดึงข้อมูลจาก PDF ถึงสำคัญ: ตัวอย่างการใช้งานจริงและประโยชน์ต่อธุรกิจ
แล้วทำไมต้องไปดึงข้อมูลจาก PDF ให้ยุ่งยาก? ก็เพราะ ทุกคน ใช้มัน และข้อมูลข้างในมักสำคัญกับธุรกิจมาก นี่คือจุดที่การดึงข้อมูลจาก PDF โดดเด่น:
| กรณีใช้งาน | งานที่ต้องทำด้วยมือ | เมื่อใช้เครื่องมือดึงข้อมูลจาก PDF | ประหยัดเวลาและลดข้อผิดพลาด |
|---|---|---|---|
| ดึงลีดการขาย | ใช้เวลาหลายชั่วโมงก็อปปี้รายชื่อติดต่อจาก PDF ใบเสนอราคาหรืองานอีเวนต์ เสี่ยงพลาดลีด | ดึงลีดทั้งหมดลงสเปรดชีตได้ทันที | เร็วขึ้น 80–90% ผิดพลาดน้อยลง |
| ข้อมูลสินค้าสำหรับอีคอมเมิร์ซ | ใช้เวลาหลายวันกรอกรายละเอียดสินค้าจาก PDF ของซัพพลายเออร์ ฟอร์แมตเละเทะ | ดึงข้อมูลเป็นชุดออกเป็น CSV หรือ Sheets ได้ | ประหยัดเวลาได้มากกว่า 95% ข้อมูลสม่ำเสมอ |
| วิเคราะห์ข้อมูลงานวิจัย | ใช้เวลาหลายสัปดาห์ถอดตารางจากบทความวิชาการ เสี่ยงพิมพ์ผิดสูง | ดึงตาราง เอกสารอ้างอิง และแม้แต่ข้อความจากสแกนได้ | ประหยัดเวลา 80% ความแม่นยำสูงขึ้น |
มาดูตัวเลขกันหน่อย:
- มีการสร้าง ในแต่ละปี
- ใช้ PDF เป็นรูปแบบหลักในการแชร์ข้อมูล
- งานธุรการที่ทำด้วยมือ (เช่น การคีย์ข้อมูลจาก PDF) กินเวลาไปถึง
- เครื่องมืออัตโนมัติช่วยลดอัตราความผิดพลาดจาก
ถ้าคุณอยู่ในสายขาย อีคอมเมิร์ซ หรือวิจัย การทำให้การดึงข้อมูลจาก PDF เป็นอัตโนมัติไม่ใช่แค่ของดีที่มีไว้ก็ดี—แต่มันคือแต้มต่อทางการแข่งขันเลย
วิธีดึงข้อมูลจาก PDF แบบดั้งเดิม: ความท้าทายและข้อจำกัด
เอาตามตรง วิธีเก่า ๆ ในการเอาข้อมูลออกจาก PDF น่ะ…ไม่ค่อยดีเท่าไร นี่คือสิ่งที่พวกเราส่วนใหญ่เคยลอง (และทำไมมันถึงน่าหงุดหงิดสุด ๆ):

1. คัดลอกวางด้วยมือ
- จุดที่เจ็บ: ฟอร์แมตพัง ตารางกลายเป็นกองขยะ รูปภาพกับลิงก์หายไป แล้วสิ่งที่เหลือไว้ให้คุณคือลูกปวดหัว
- ต้นทุนแรงงาน: สูงมาก ถ้ามี PDF 5,000 ไฟล์ ต่อไฟล์ใช้เวลา 1 นาที นั่นคือชีวิตคุณกว่า 80 ชั่วโมงที่ไม่มีวันได้คืน
- อัตราความผิดพลาด: 5–10% พิมพ์ผิด ข้ามแถว ลบข้อมูลโดยไม่ตั้งใจ—เคยมาแล้วทั้งนั้น
2. แปลงเป็น Word/Excel แล้วค่อยมาเก็บงานใหม่
- จุดที่เจ็บ: บางทีใช้ได้กับเอกสารง่าย ๆ แต่เลย์เอาต์หรือ ตารางที่ซับซ้อนจะเละทันที สุดท้ายก็ยังต้องเสียเวลามาเก็บความรกอยู่ดี
- รูปภาพ/ลิงก์: ส่วนใหญ่หายไป
- การดึงแบบเจาะจง: ลืมไปได้เลย—คุณจะได้ทั้งเอกสาร ไม่ใช่แค่สิ่งที่ต้องการ
3. เขียนสคริปต์เอง (Python ฯลฯ)
- จุดที่เจ็บ: คุณต้องเขียนโค้ดได้ (หรือมีคนเขียนให้) PDF รูปแบบใหม่แต่ละแบบแปลว่าต้องปรับสคริปต์ใหม่ทุกครั้ง แล้วถ้าเป็น PDF ที่สแกนมาล่ะ? ก็ขอให้โชคดี
- การดูแลรักษา: สูงมาก ทุกครั้งที่ซัพพลายเออร์เปลี่ยนเทมเพลตใบแจ้งหนี้ สคริปต์คุณก็พัง
- การขยายงาน: ไม่เหมาะกับคนใจไม่แข็ง (หรือคนไม่สายเทคนิค)
4. ตัวแปลงออนไลน์
- จุดที่เจ็บ: ใช้ง่ายสำหรับงานครั้งคราว แต่คุณต้องอัปโหลดเอกสารที่อ่อนไหวไปยังเซิร์ฟเวอร์ของบุคคลที่สาม (สวัสดี ปัญหาด้านคอมพลายแอนซ์) และยังควบคุมสิ่งที่ถูกดึงออกมาได้จำกัด
- ฟอร์แมต: แล้วแต่ดวง บางทีก็เสียเวลามาเก็บงานมากกว่าที่ประหยัดได้
สรุปสั้น ๆ: วิธีแบบเดิมช้า มีโอกาสผิดพลาดสูง และขยายงานไม่ค่อยได้ นี่แหละเหตุผลที่หลายทีมยอม “อยู่กับมันไป” ทั้งที่ต้องแลกกับประสิทธิภาพการทำงานอย่างมหาศาล
โซลูชันสมัยใหม่สำหรับการดึงข้อมูลจาก PDF: จากโค้ดสู่เครื่องมือแบบไม่ต้องเขียนโค้ด
โชคดีที่ตอนนี้เราไม่ต้องติดอยู่ในยุคมืดอีกต่อไปแล้ว ภาพรวมของเครื่องมือดึงข้อมูลจาก PDF ฉลาดขึ้น เร็วขึ้น และใช้งานง่ายขึ้นมาก
1. ไลบรารีสำหรับเขียนโค้ด (สำหรับนักพัฒนา)
- ตัวอย่าง: , ,
- จุดแข็ง: ยืดหยุ่นมาก อัตโนมัติได้กับงานจำนวนมาก ฟรี (โอเพนซอร์ส)
- จุดอ่อน: ใช้เวลาเซ็ตอัปสูง ต้องมีทักษะเขียนโปรแกรม เปราะบาง (พังเมื่อเจอฟอร์แมตใหม่) รองรับ OCR/รูปภาพได้จำกัด
2. ตัวแปลง PDF ออนไลน์
- ตัวอย่าง: , ,
- จุดแข็ง: ไม่ต้องตั้งค่า ใช้ง่ายสำหรับคนไม่สายเทคนิค เหมาะกับงานเล็ก ๆ ที่ต้องทำเร็ว
- จุดอ่อน: ปรับแต่งได้น้อย มีข้อกังวลเรื่องความเป็นส่วนตัว ฟอร์แมตเพี้ยน และมีข้อจำกัดเรื่องขนาดไฟล์/จำนวนหน้า
3. เครื่องมือดึงข้อมูลจาก PDF ที่ขับเคลื่อนด้วย AI
- ตัวอย่าง: , Nanonets, Docparser
- จุดแข็ง: ไม่ต้องเขียนโค้ด รองรับข้อความ/ตาราง/รูปภาพ/ลิงก์ AI ช่วยแนะนำว่าควรดึงอะไร มีโหมดงานแบบเป็นชุด และเชื่อมต่อกับ Sheets/Notion/Airtable ได้
- จุดอ่อน: บางตัวมีข้อจำกัดเรื่องเครดิต/จำนวนหน้า อาจต้องใช้อินเทอร์เน็ต และเอกสารที่ซับซ้อนอาจต้องใช้เวลาคุ้นมือบ้าง
เปรียบเทียบเครื่องมือดึงข้อมูลจาก PDF: แบบไหนเหมาะกับคุณ?
| เครื่องมือ/วิธี | การตั้งค่า | เหมาะกับ | ดึงอะไรได้บ้าง | ปรับแต่งได้ไหม? | ค่าใช้จ่าย |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | ปานกลาง (UI/โค้ด) | ตารางใน PDF | ตาราง | พอประมาณ | ฟรี |
| PDFMiner | ต้องเขียนโค้ด | PDF ที่มีข้อความเยอะ | ข้อความ | ได้ (ผ่านโค้ด) | ฟรี |
| PyPDF2 | ต้องเขียนโค้ด | ข้อความ/เมตาดาตาง่าย ๆ | ข้อความ เมตาดาตา | ได้ (ผ่านโค้ด) | ฟรี |
| Smallpdf/ตัวแปลงออนไลน์ | ไม่มี (ผ่านเว็บ) | แปลงไฟล์แบบเร็ว ๆ | ทั้งเอกสาร (Word/Excel) | ไม่ได้ | ฟรีเมียม |
| Thunderbit | ติดตั้ง 2 คลิก | ผู้ใช้ธุรกิจ ทีมงาน | ข้อความ ตาราง รูปภาพ ลิงก์ | ได้ (ผ่านพรอมป์ AI) | ฟรีเมียม ($16.5/เดือนสำหรับ Pro) |
มารู้จัก Thunderbit: ส่วนขยาย Chrome สำหรับดึงข้อมูลจาก PDF ด้วย AI
ต่อไปมาคุยกันถึงเครื่องมือที่ทำให้ชีวิตผม (และชีวิตของคนทำงานธุรกิจอีกเยอะ) ง่ายขึ้นมาก:
อะไรทำให้ Thunderbit แตกต่าง?
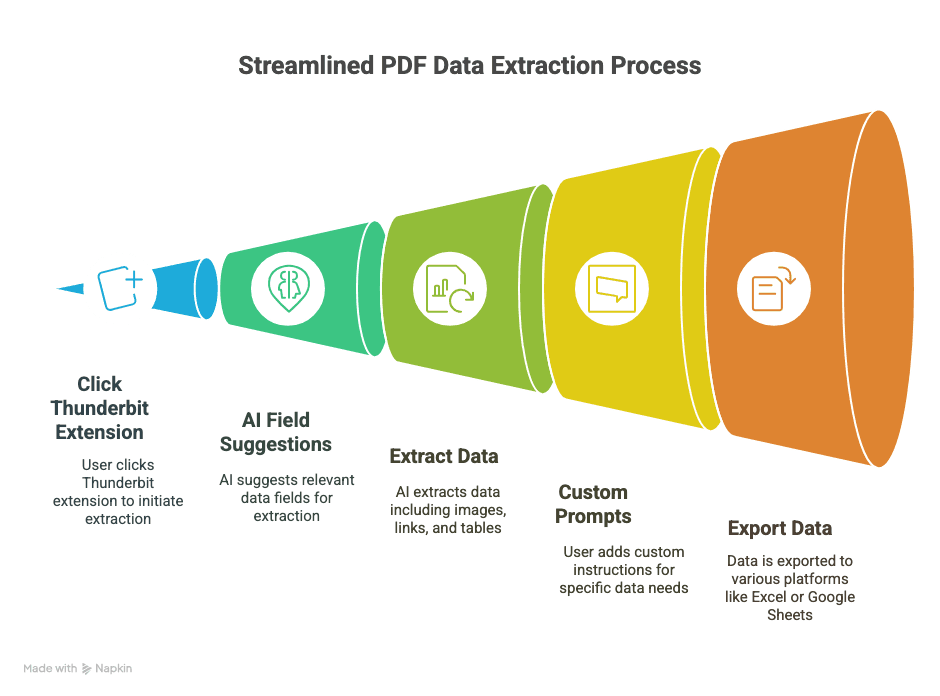
- ดึงข้อมูลใน 2 คลิก: เปิด PDF ใน Chrome คลิกส่วนขยาย Thunderbit แล้วปล่อยให้ AI ทำที่เหลือ
- คำแนะนำฟิลด์ด้วย AI: ฟีเจอร์ “AI Suggest Fields” ของ Thunderbit จะอ่าน PDF ของคุณแล้วแนะนำคอลัมน์ที่น่าจะต้องใช้ (เช่น “ชื่อ”, “อีเมล”, “ราคา” ฯลฯ)
- รองรับรูปภาพ ลิงก์ และตาราง: ไม่ได้มีแค่ข้อความธรรมดา—Thunderbit ดึงรูปภาพ ไฮเปอร์ลิงก์ และทำ OCR กับเอกสารสแกนได้ด้วย
- พรอมป์แบบกำหนดเอง: ถ้าต้องการแค่เบอร์โทรหรือสเปกสินค้า ก็ใส่คำสั่งเฉพาะ แล้ว Thunderbit จะโฟกัสแค่นั้น
- ส่งออกได้ทุกที่: ส่งข้อมูลตรงไปยัง Excel, Google Sheets, Airtable หรือ Notion ได้เลย ไม่ต้องมานั่งปวดหัวกับ CSV อีก
- ดึงข้อมูลแบบเป็นชุดและดึงจากซับเพจ: มีรายการ PDF หรือลิงก์จำนวนมาก? Thunderbit จัดการทั้งหมดได้ในรอบเดียว
- ความน่าเชื่อถือระดับงานธุรกิจ: ออกแบบมาเพื่อความแม่นยำ ความเป็นส่วนตัว และเวิร์กโฟลว์ใช้งานจริง
สั้น ๆ ก็คือ มันเหมือนมีเด็กฝึกงานดิจิทัลที่ ชอบ ทำงานคีย์ข้อมูลจริง ๆ (และไม่เคยเหนื่อย)
วิธีดึงข้อมูลจาก PDF ด้วย Thunderbit แบบทีละขั้นตอน
พร้อมดูแล้วหรือยังว่ามันง่ายแค่ไหน? นี่คือวิธีที่ผมใช้ Thunderbit เพื่อเปลี่ยน PDF ให้กลายเป็นข้อมูลที่มีโครงสร้างและใช้งานได้จริง:
1. ติดตั้ง Thunderbit
- ดาวน์โหลด
- สมัครใช้งาน (ใช้บัญชี Google หรืออีเมล—ใช้เวลาแค่ไม่กี่วินาที)
2. เปิด PDF ใน Chrome
- เปิด PDF จากลิงก์บนเว็บ หรือจะลากไฟล์ PDF ในเครื่องมาวางในแท็บ Chrome ก็ได้
3. เปิด Thunderbit บน PDF
- คลิกไอคอน Thunderbit บนแถบเครื่องมือของเบราว์เซอร์
- เลือก “AI Web Scraper”—Thunderbit จะตรวจจับว่าเป็น PDF แล้วพร้อมทำงานทันที
4. ปล่อยให้ AI แนะนำฟิลด์
- คลิก “AI Suggest Columns”
- AI ของ Thunderbit จะสแกน PDF และแนะนำคอลัมน์ต่าง ๆ (เช่น “วันที่”, “จำนวนเงิน”, “ชื่อผู้ติดต่อ” ฯลฯ)
- ดูตัวอย่างข้อมูลที่ดึงออกมาได้ในรูปแบบตารางภายในส่วนขยายได้เลย
5. ปรับแต่งตามต้องการ
- เปลี่ยนชื่อคอลัมน์ ลบสิ่งที่ไม่ต้องการ หรือเพิ่มคอลัมน์เอง (เช่น “ระยะเวลารับประกัน” หรือ “URL สินค้า”)
- ถ้าเป็นข้อมูลที่ซับซ้อน ให้เลือกข้อความใน PDF เพื่อสอน AI ว่าคุณต้องการอะไร
6. เลือกรูปแบบการส่งออก
- เลือก CSV, Google Sheets, Airtable หรือ Notion
- อนุญาตให้ Thunderbit เชื่อมต่อ (ตั้งค่าแค่ครั้งเดียว)
7. ดึงข้อมูลและส่งออก
- กด “Scrape” หรือ “Export”
- Thunderbit จะประมวลผล PDF แล้วส่งข้อมูลไปยังที่ที่คุณต้องการ—ปกติใช้เวลาเพียงไม่กี่วินาที
แค่นั้นเอง ไม่ต้องเขียนโค้ด ไม่ต้องคัดลอกวาง ไม่ต้องดราม่า
เคล็ดลับสำหรับการดึงข้อมูลจาก PDF ให้แม่นยำด้วย Thunderbit
- ตรวจฟิลด์ที่ AI แนะนำ: AI ฉลาดก็จริง แต่การเหลือบดูเร็ว ๆ จะช่วยให้แน่ใจว่าคุณได้สิ่งที่ต้องการครบ
- จัดการตารางที่ซับซ้อน: ถ้าเป็นตารางหลายหน้าหรือฟอร์แมตแปลก ๆ ให้ใช้พรีวิวเพื่อดูจุดผิดพลาดและปรับคอลัมน์ตามต้องการ
- ดึงรูปภาพ/ลิงก์: อย่าลืมใส่ฟิลด์พวกนี้ถ้า PDF ของคุณมี Thunderbit ดึงได้เหมือนกัน
- PDF ที่สแกนมา: OCR ในตัวของ Thunderbit ใช้งานได้ดี แต่ยิ่งสแกนชัด ผลลัพธ์ก็ยิ่งดี
- พรอมป์แบบกำหนดเอง: อยากได้แค่อีเมลหรือเบอร์โทร? ใส่พรอมป์อย่าง “ดึงที่อยู่อีเมลทั้งหมด” แล้ว Thunderbit จะโฟกัสเฉพาะสิ่งนั้น
การดึงข้อมูลจาก PDF ขั้นสูง: ดึงรูปภาพ ลิงก์ และข้อมูลแบบกำหนดเอง
Thunderbit ไม่ได้มีดีแค่ข้อความธรรมดา นี่คือสิ่งที่คุณดึงออกจาก PDF ได้มากขึ้นอีก:
- รูปภาพ: ดึงโลโก้ กราฟ หรือกราฟิกที่ฝังอยู่ได้ Thunderbit ยังอ่านข้อความในรูปภาพผ่าน OCR ได้ด้วย
- ไฮเปอร์ลิงก์: ดึง URL หรือการอ้างอิงทั้งหมดออกมา—เหมาะมากสำหรับงานวิจัยหรือเรซูเม่
- ชนิดข้อมูลแบบกำหนดเอง: ใช้พรอมป์ AI เพื่อดึงเฉพาะสิ่งที่คุณต้องการ (เช่น “หาตัว SKU ของสินค้าทั้งหมดและราคาของแต่ละรายการ”)
- สรุปและจัดหมวดหมู่: เพิ่มคอลัมน์แล้วให้ Thunderbit สรุปแต่ละส่วนหรือจัดหมวดข้อมูลได้แบบทันที
การแยกข้อมูลจาก PDF เพื่อตอบโจทย์ธุรกิจเฉพาะทาง
- ฝ่ายขาย: ดึงเฉพาะข้อมูลติดต่อจากชุด PDF ใบเสนอราคา
- อีคอมเมิร์ซ: ดึงสเปกสินค้า ราคา และรูปภาพจากแคตตาล็อกของซัพพลายเออร์
- งานวิจัย: ดึงตาราง เอกสารอ้างอิง และแม้แต่สร้างบทสรุปจากบทความวิชาการ
และเมื่อได้ข้อมูลแล้ว ก็จัดโครงสร้างให้พร้อมสำหรับการวิเคราะห์ใน Excel, Google Sheets หรือ Notion—Thunderbit จัดการงานหนักให้หมด คุณแค่เอาผลลัพธ์ไปใช้ต่อ
การส่งออกและใช้งานข้อมูล PDF ของคุณ: จากการดึงข้อมูลสู่การลงมือทำ
การเอาข้อมูลออกมาเป็นแค่จุดเริ่มต้น นี่คือวิธีทำให้มันเกิดประโยชน์จริง:
- ตัวเลือกการส่งออก: CSV, Excel, Google Sheets, Airtable, Notion—เลือกแบบที่ถนัด
- เคล็ดลับการจัดรูปแบบ: ใช้การตั้งค่าชนิดคอลัมน์ของ Thunderbit (ตัวเลข วันที่ ข้อความ) เพื่อให้ข้อมูลสะอาดและพร้อมวิเคราะห์
- ผสานเข้ากับเวิร์กโฟลว์: เชื่อมข้อมูลที่ส่งออกไปยัง CRM ระบบสต็อก หรือแดชบอร์ดวิเคราะห์
- การทำงานร่วมกัน: แชร์ Google Sheets หรือ Airtable base ให้ทีมได้ ทุกคนทำงานบนข้อมูลชุดเดียวที่อัปเดตล่าสุด
ส่วนที่ดีที่สุด? คือไม่ต้องส่งสเปรดชีตไปมาทางอีเมลอีกต่อไป และไม่ต้องนั่งลุ้นว่าคุณพลาดแถวไหนไปหรือเปล่า
ปัญหาที่พบบ่อยในการดึงข้อมูลจาก PDF และวิธีหลีกเลี่ยง
ถึงจะมีเครื่องมือดีแค่ไหน ก็ยังมีจุดที่ต้องระวังได้เหมือนกัน นี่คือสิ่งที่ผมเรียนรู้มา (บางทีก็ต้องเรียนแบบเจ็บ ๆ):
- ข้อผิดพลาดจาก OCR: ไฟล์สแกนไม่ชัดหรือฟอนต์แปลก ๆ อาจทำให้ OCR ที่ดีที่สุดก็พลาดได้ พยายามใช้ PDF ที่ชัดที่สุดเท่าที่ทำได้ และตรวจฟิลด์สำคัญซ้ำ
- เลย์เอาต์ซับซ้อน: ตารางหลายคอลัมน์หรือตารางซ้อนกันอาจต้องมีการชี้นำด้วยมือเล็กน้อย—ใช้การเลือกด้วยมือหรือพรอมป์ของ Thunderbit
- ชนิดข้อมูล: ตัวเลขที่มีเครื่องหมายจุลภาคหรือวันที่อยู่ในรูปแบบแปลก ๆ? ตั้งค่าชนิดคอลัมน์ก่อนส่งออก หรือค่อยไปเก็บงานใน Excel/Sheets
- ข้อจำกัดเรื่องขนาดไฟล์/จำนวนหน้า: PDF ใหญ่มาก? แบ่งเป็นก้อนเล็กลง หรือใช้โหมดคลาวด์ของ Thunderbit สำหรับงานแบบเป็นชุด
- AI “มโน” ขึ้นมาเอง: เจอบ้างไม่บ่อย แต่บางครั้ง AI อาจเดาชื่อคอลัมน์หรือใส่ข้อมูลที่หายไปมาให้ ควรตรวจจุดสำคัญเสมอ โดยเฉพาะตัวเลขที่มีผลมาก
- การตรวจทานด้วยคน: ถ้าเป็นข้อมูลที่สำคัญมาก ให้ตรวจสอบอีกชั้น—เครื่องมืออัตโนมัติก็แม่น แต่มีสายตาคนช่วยดูสักรอบไม่เสียหาย
และถ้าติดขัดจริง ๆ ทีมซัพพอร์ตและคอมมูนิตี้ของ Thunderbit ก็พร้อมช่วย
สรุปและประเด็นสำคัญ: ทำให้การดึงข้อมูลจาก PDF ใช้งานได้จริงกับธุรกิจของคุณ
มาปิดท้ายกัน การดึงข้อมูลจาก PDF เคยเป็นฝันร้าย—ช้า ผิดพลาดง่าย และน่าเบื่อสุด ๆ แต่ด้วยเครื่องมือสมัยใหม่อย่าง ตอนนี้มันทั้งเร็ว แม่นยำ และ (ขอพูดเลย) สนุกขึ้นเกือบจะน่าแปลกใจ
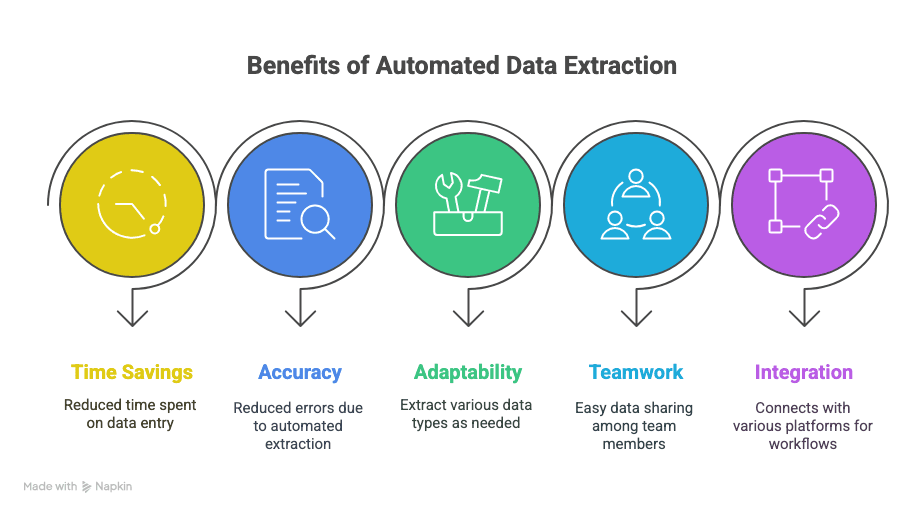
สิ่งที่คุณจะได้คือ:
- คืนเวลาให้ตัวเอง: ประหยัดเวลาคีย์ข้อมูลด้วยมือได้เป็นชั่วโมง ๆ หรือเป็นสัปดาห์ ๆ
- ผิดพลาดน้อยลง: การดึงข้อมูลอัตโนมัติช่วยลดพิมพ์ผิดและการตกหล่นของแถวข้อมูล
- ยืดหยุ่น: ดึงได้ตรงตามที่ต้องการ—ข้อความ ตาราง รูปภาพ ลิงก์ จะเอาอะไรบอกมา
- ทำงานร่วมกันได้ง่าย: แชร์ข้อมูลให้ทีมได้ทันที ไม่ว่าใครจะอยู่ที่ไหน
- เวิร์กโฟลว์ฉลาดขึ้น: เชื่อมกับ Sheets, Notion, Airtable และอื่น ๆ ได้อีกมาก
พร้อมลองแล้วหรือยัง? ดาวน์โหลด ลองกับ PDF ฉบับถัดไปของคุณ แล้วดูว่าชีวิตจะง่ายขึ้นแค่ไหน ตัวคุณในอนาคต (รวมถึงอาการปวดข้อมือ) จะขอบคุณคุณแน่นอน
ถ้าอยากได้เคล็ดลับและคู่มือเพิ่มเติม ลองเข้าไปดู หรืออ่านลึกขึ้นที่
มาเปลี่ยนปัญหาปวดหัวจาก PDF ให้กลายเป็นผลงานด้านประสิทธิภาพกัน—ทีละคลิก
Shuai Guan, ผู้ร่วมก่อตั้งและซีอีโอ, Thunderbit