
มีอะไรบางอย่างที่ชวนพอใจแบบแปลก ๆ เวลามองสคริปต์วิ่งผ่านเว็บไซต์ กวาดข้อมูลไปเรื่อย ๆ ในขณะที่เราจิบกาแฟอยู่ ถ้าคุณเป็นเหมือนผม คุณคงเคยสงสัยว่า “จะทำให้การทำเว็บสแครปปิงเร็วขึ้น ฉลาดขึ้น และปวดหัวน้อยลงได้ยังไง?”
นั่นแหละคือเหตุผลที่พาผมเข้าสู่โลกของ OpenClaw web scraping ในภูมิทัศน์ดิจิทัลที่ กว่า 90% ขององค์กรพึ่งพาการดึงข้อมูลจากเว็บ สำหรับทุกอย่างตั้งแต่ลีดขายไปจนถึงข้อมูลเชิงลึกด้านตลาด การเชี่ยวชาญเครื่องมือที่ใช่ไม่ใช่แค่เรื่องเท่ ๆ ทางเทคนิค แต่มันคือความจำเป็นทางธุรกิจ
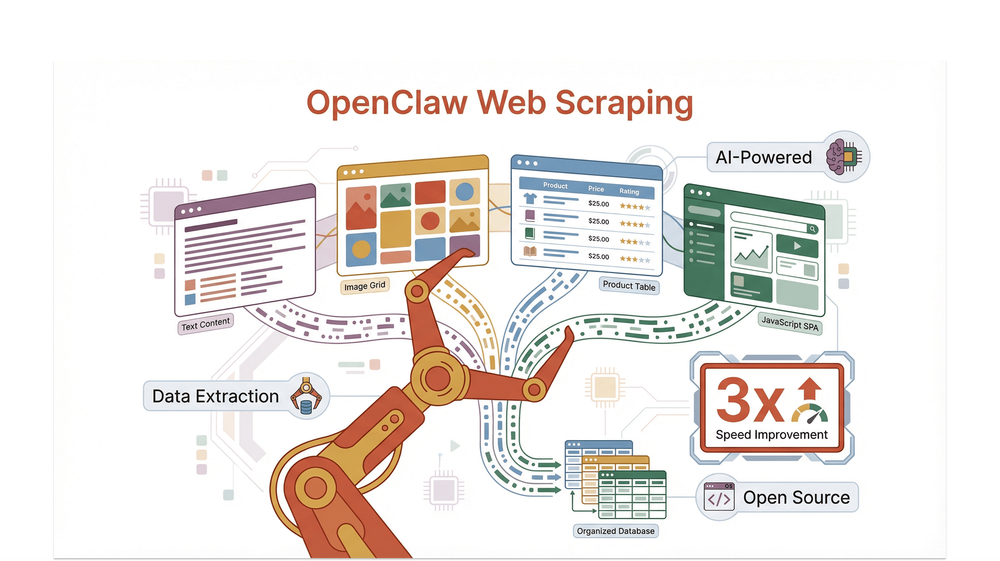
OpenClaw กลายเป็นหนึ่งในตัวโปรดของชุมชนสแครปปิงอย่างรวดเร็ว โดยเฉพาะสำหรับคนที่ต้องรับมือกับเว็บไซต์แบบไดนามิก เว็บไซต์ที่เน้นรูปภาพ หรือเว็บที่ซับซ้อน ซึ่งทำให้สแครปเปอร์แบบเดิมแทบหายใจไม่ทัน
ในคู่มือนี้ ผมจะพาคุณไล่ตั้งแต่การติดตั้ง OpenClaw ไปจนถึงการสร้างเวิร์กโฟลว์อัตโนมัติขั้นสูง และเพราะผมให้ความสำคัญกับการประหยัดเวลา ผมจะโชว์ด้วยว่าคุณจะเร่งพลังการดึงข้อมูลของคุณด้วยฟีเจอร์ AI ของ Thunderbit ได้อย่างไร เพื่อให้เวิร์กโฟลว์ไม่เพียงทรงพลัง แต่ยังใช้งานสนุกจริง ๆ
ลองใช้ Thunderbit เพื่อการทำเว็บสแครปปิงที่ฉลาดกว่า
OpenClaw Web Scraping คืออะไร?
เริ่มจากพื้นฐานก่อน OpenClaw web scraping หมายถึงการใช้แพลตฟอร์ม OpenClaw—เกตเวย์เอเจนต์แบบโอเพนซอร์สที่ติดตั้งและโฮสต์เองได้—เพื่อทำให้การดึงข้อมูลจากเว็บไซต์เป็นอัตโนมัติ OpenClaw ไม่ได้เป็นแค่สแครปเปอร์อีกตัวหนึ่ง แต่มันคือระบบแบบโมดูลาร์ที่เชื่อมช่องทางแชตที่คุณชอบ (เช่น Discord หรือ Telegram) เข้ากับชุดเครื่องมือสำหรับเอเจนต์ ซึ่งรวมถึงเครื่องมือดึงข้อมูลเว็บ เครื่องมือค้นหา และแม้แต่เบราว์เซอร์ที่จัดการให้สำหรับเว็บที่พึ่งพา JavaScript หนัก ๆ จนเครื่องมืออื่นต้องเหนื่อย
อะไรที่ทำให้ OpenClaw เด่นสำหรับการดึงข้อมูลจากเว็บ? มันถูกออกแบบมาให้ทั้งยืดหยุ่นและแข็งแรง คุณสามารถใช้เครื่องมือในตัวอย่าง web_fetch สำหรับการดึงข้อมูลผ่าน HTTP แบบง่าย ๆ เปิดเบราว์เซอร์ Chromium ที่เอเจนต์ควบคุมได้สำหรับคอนเทนต์แบบไดนามิก หรือจะเสียบสกิลที่ชุมชนสร้างไว้แล้ว เช่น openclaw-plugin-web-scraper สำหรับเวิร์กโฟลว์ที่ซับซ้อนขึ้นก็ได้ มันเป็นโอเพนซอร์ส (MIT licensed) มีการดูแลอย่างต่อเนื่อง และมีระบบนิเวศของปลั๊กอินกับสกิลที่คึกคัก จึงเป็นตัวเลือกอันดับต้น ๆ สำหรับคนที่จริงจังกับการสแครปในระดับสเกล
OpenClaw รองรับข้อมูลและรูปแบบเว็บไซต์หลากหลาย เช่น:
- ข้อความและ HTML แบบมีโครงสร้าง
- รูปภาพและลิงก์สื่อ
- คอนเทนต์แบบไดนามิกที่เรนเดอร์ด้วย JavaScript
- โครงสร้าง DOM ที่ซับซ้อนและหลายชั้น
และเพราะมันขับเคลื่อนด้วยเอเจนต์ คุณจึงสามารถจัดการงานสแครป ทำรายงานอัตโนมัติ และแม้แต่โต้ตอบกับข้อมูลแบบเรียลไทม์ได้—ทั้งหมดจากแอปแชตหรือเทอร์มินัลที่คุณใช้เป็นประจำ
ทำไม OpenClaw ถึงเป็นเครื่องมือทรงพลังสำหรับการดึงข้อมูลจากเว็บ
แล้วทำไมมืออาชีพด้านข้อมูลและสายออโตเมชันจำนวนมากถึงหันมาใช้ OpenClaw? มาดูจุดแข็งทางเทคนิคที่ทำให้มันเป็นตัวท็อปของวงการเว็บสแครปปิงกัน
ความเร็วและความเข้ากันได้
สถาปัตยกรรมของ OpenClaw ถูกสร้างมาเพื่อความเร็ว เครื่องมือหลักอย่าง web_fetch ใช้การร้องขอ HTTP GET ร่วมกับการดึงคอนเทนต์อย่างชาญฉลาด แคช และการจัดการรีไดเร็กต์ ในเบนช์มาร์กทั้งภายในและของชุมชน OpenClaw มักทำเวลาได้ดีกว่าเครื่องมือรุ่นเก่าอย่าง BeautifulSoup หรือ Selenium อย่างสม่ำเสมอ เมื่อต้องดึงข้อมูลจำนวนมากจากเว็บไซต์แบบสแตติกและกึ่งไดนามิก (docs.openclaw.ai)
แต่จุดที่ OpenClaw โดดเด่นจริง ๆ คือความเข้ากันได้ ด้วยโหมดเบราว์เซอร์ที่จัดการให้ มันรับมือกับเว็บที่อาศัย JavaScript ในการเรนเดอร์ได้—ซึ่งเป็นจุดที่สแครปเปอร์แบบเดิมหลายตัวพลาด ไม่ว่าคุณจะกำลังเจาะแคตตาล็อกอีคอมเมิร์ซที่เต็มไปด้วยรูปภาพ หรือแอปหน้าเดียวที่เลื่อนแบบไม่รู้จบ โปรไฟล์ Chromium ที่เอเจนต์ควบคุมของ OpenClaw ก็จัดการให้ได้
ทนต่อการเปลี่ยนแปลงของเว็บไซต์
หนึ่งในปัญหาหนักที่สุดของการทำเว็บสแครปปิงคือการรับมือกับการอัปเดตไซต์ที่ทำให้สคริปต์พัง ระบบปลั๊กอินและสกิลของ OpenClaw ถูกออกแบบมาให้ทนทาน ตัวอย่างเช่น ตัวห่อหุ้มรอบไลบรารี Scrapling ให้การดึงข้อมูลแบบปรับตัวได้ หมายความว่าสแครปเปอร์ของคุณสามารถ “ย้ายตำแหน่ง” องค์ประกอบได้แม้โครงสร้างหน้าเว็บจะเปลี่ยน—เป็นข้อได้เปรียบมหาศาลสำหรับโปรเจกต์ระยะยาว
ประสิทธิภาพในโลกจริง
จากการทดสอบแบบเทียบกันตรง ๆ เวิร์กโฟลว์ที่อิง OpenClaw แสดงผลว่า:

- ดึงข้อมูลได้เร็วขึ้นสูงสุด 3 เท่า บนเว็บไซต์ที่ซับซ้อนและหลายหน้า เมื่อเทียบกับสแครปเปอร์ Python แบบดั้งเดิม (scrapling.readthedocs.io)
- สำเร็จสูงกว่าบนหน้าไดนามิกที่ใช้ JavaScript หนัก ๆ ด้วยเบราว์เซอร์ที่จัดการให้
- จัดการหน้าที่มีคอนเทนต์ผสมกันได้ดีกว่า (ข้อความ รูปภาพ ชิ้นส่วน HTML)
คำบอกเล่าจากผู้ใช้มักชี้ให้เห็นว่า OpenClaw “ใช้งานได้เลย” ในจุดที่เครื่องมืออื่นล้มเหลว โดยเฉพาะเวลาสแครปข้อมูลจากเว็บที่มีเลย์เอาต์ชวนงงหรือมีมาตรการป้องกันบอท
เริ่มต้นใช้งาน: ตั้งค่า OpenClaw สำหรับ Web Scraping
พร้อมลุยแล้วใช่ไหม? นี่คือวิธีทำให้ OpenClaw พร้อมใช้งานบนเครื่องของคุณ
ขั้นตอนที่ 1: ติดตั้ง OpenClaw
OpenClaw รองรับ Windows, macOS และ Linux เอกสารทางการแนะนำให้เริ่มจากขั้นตอนแนะนำการใช้งานเบื้องต้น:
openclaw onboard
คำสั่งนี้จะพาคุณผ่านขั้นตอนเริ่มต้นทั้งหมด รวมถึงการตรวจสอบสภาพแวดล้อมและการตั้งค่าพื้นฐาน
ขั้นตอนที่ 2: ติดตั้ง Dependencies ที่จำเป็น
ขึ้นอยู่กับเวิร์กโฟลว์ของคุณ คุณอาจต้องใช้:
- Node.js (สำหรับเกตเวย์หลัก)
- Python 3.10+ (สำหรับปลั๊กอิน/สกิลที่ใช้ Python เช่น ตัวห่อหุ้ม Scrapling)
- Chromium/Chrome (สำหรับโหมดเบราว์เซอร์ที่จัดการให้)
บน Linux คุณอาจต้องติดตั้งแพ็กเกจเพิ่มเติมเพื่อรองรับเบราว์เซอร์ เอกสารมีส่วนแก้ปัญหาเฉพาะ สำหรับปัญหาที่พบบ่อย
ขั้นตอนที่ 3: ตั้งค่าเครื่องมือเว็บ
ตั้งค่าผู้ให้บริการเว็บค้นหาของคุณ:
openclaw configure --section web
ตรงนี้คุณเลือกได้จากผู้ให้บริการอย่าง Brave, DuckDuckGo หรือ Firecrawl
ขั้นตอนที่ 4: ติดตั้งปลั๊กอินหรือสกิล (ไม่บังคับ)
ถ้าอยากปลดล็อกการสแครปขั้นสูง ให้ติดตั้งปลั๊กอินหรือสกิลจากชุมชน ตัวอย่างเช่น ถ้าจะเพิ่ม openclaw-plugin-web-scraper:
git clone https://github.com/hvkeyn/openclaw-plugin-web-scraper.git
cd openclaw-plugin-web-scraper
openclaw plugins install .
openclaw gateway restart

เคล็ดลับสำหรับมือใหม่
- รัน
openclaw security auditหลังติดตั้งปลั๊กอินใหม่เพื่อเช็กช่องโหว่ (docs.openclaw.ai) - ถ้าใช้ Node ผ่าน nvm อย่าลืมตรวจใบรับรอง CA ให้ดี—ถ้าไม่ตรงกันอาจทำให้คำขอ HTTPS ล้มเหลว (docs.openclaw.ai)
- ควรแยกปลั๊กอินและส่วนประกอบเบราว์เซอร์ไว้ใน VM หรือคอนเทนเนอร์เสมอเพื่อความปลอดภัยเพิ่มขึ้น
คู่มือสำหรับมือใหม่: โปรเจกต์สแครปปิง OpenClaw แรกของคุณ
มาสร้างโปรเจกต์สแครปปิงง่าย ๆ กัน—ไม่ต้องจบปริญญาเอกด้านวิทยาการคอมพิวเตอร์ก็ทำได้
ขั้นตอนที่ 1: เลือกเว็บไซต์เป้าหมาย
เลือกเว็บที่มีข้อมูลเป็นโครงสร้าง เช่น รายการสินค้า หรือไดเรกทอรี ตัวอย่างนี้เราจะสแครปชื่อสินค้าจากหน้าเดโมอีคอมเมิร์ซ
ขั้นตอนที่ 2: ทำความเข้าใจโครงสร้าง DOM
ใช้เครื่องมือ “Inspect Element” ของเบราว์เซอร์เพื่อหาแท็ก HTML ที่เก็บข้อมูลที่ต้องการ (เช่น <h2 class="product-title">)
ขั้นตอนที่ 3: ตั้งค่าเงื่อนไขการดึงข้อมูล
ด้วยสกิลของ OpenClaw ที่อิง Scrapling คุณสามารถใช้ CSS selector เพื่อระบุองค์ประกอบได้ ตัวอย่างสคริปต์นี้ใช้สกิล openclaw-ultra-scraping:
PYTHON=/opt/scrapling-venv/bin/python3
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text"
คำสั่งนี้จะดึงหน้าเว็บและแยกชื่อสินค้าทั้งหมดออกมา
ขั้นตอนที่ 4: จัดการข้อมูลอย่างปลอดภัย
ส่งออกผลลัพธ์เป็น CSV หรือ JSON เพื่อให้นำไปวิเคราะห์ต่อได้ง่าย:
$PYTHON scripts/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o products.csv
แนวคิดสำคัญที่ควรรู้
- สคีมาของเครื่องมือ: กำหนดว่าเครื่องมือหรือสกิลแต่ละตัวทำอะไรได้บ้าง (ดึงข้อมูล แยกข้อมูล สแกนเว็บไซต์)
- การลงทะเบียนสกิล: เพิ่มความสามารถสแครปปิงใหม่เข้า OpenClaw ผ่าน ClawHub หรือการติดตั้งแบบ manual
- การจัดการข้อมูลอย่างปลอดภัย: ตรวจสอบและทำความสะอาดผลลัพธ์เสมอก่อนนำไปใช้ในงานจริง
ทำเวิร์กโฟลว์การสแครปที่ซับซ้อนให้เป็นอัตโนมัติด้วย OpenClaw

พอคุณเชี่ยวชาญพื้นฐานแล้ว ก็ถึงเวลาทำให้มันอัตโนมัติ ต่อไปนี้คือวิธีสร้างเวิร์กโฟลว์ที่รันตัวเองได้ (ระหว่างที่คุณไปโฟกัสเรื่องสำคัญกว่า เช่น มื้อกลางวัน)
ขั้นตอนที่ 1: สร้างและลงทะเบียนสกิลแบบกำหนดเอง
เขียนหรือติดตั้งสกิลที่ตรงกับความต้องการดึงข้อมูลของคุณโดยเฉพาะ ตัวอย่างเช่น คุณอาจอยากดึงข้อมูลสินค้าและรูปภาพ แล้วส่งรายงานประจำวัน
ขั้นตอนที่ 2: ตั้งเวลางานอัตโนมัติ
บน Linux หรือ macOS ให้ใช้ cron เพื่อกำหนดเวลารันสคริปต์สแครปของคุณ:
0 6 * * * /usr/bin/python3 /path/to/scrape.py fetch "https://example.com/products" --css "h2.product-title::text" -f csv -o /data/products_$(date +\%F).csv
บน Windows ให้ใช้ Task Scheduler ด้วยอาร์กิวเมนต์ลักษณะคล้ายกัน
ขั้นตอนที่ 3: เชื่อมกับเครื่องมืออื่น
ถ้าต้องมีการนำทางแบบไดนามิก เช่น คลิกปุ่มหรือเข้าสู่ระบบ ให้ผสาน OpenClaw กับ Selenium หรือ Playwright สกิลของ OpenClaw หลายตัวสามารถเรียกใช้เครื่องมือเหล่านี้หรือรับสคริปต์ออโตเมชันของเบราว์เซอร์ได้
เปรียบเทียบเวิร์กโฟลว์แบบทำเองกับแบบอัตโนมัติ
| ขั้นตอน | เวิร์กโฟลว์แบบทำเอง | เวิร์กโฟลว์ OpenClaw แบบอัตโนมัติ |
|---|---|---|
| การดึงข้อมูล | รันสคริปต์ด้วยมือ | ตั้งเวลาผ่าน cron/Task Scheduler |
| การนำทางแบบไดนามิก | คลิกเอง | ทำอัตโนมัติด้วย Selenium/สกิล |
| การส่งออกข้อมูล | คัดลอก/วาง หรือดาวน์โหลด | ส่งออกเป็น CSV/JSON อัตโนมัติ |
| การรายงาน | สรุปเอง | สร้างและส่งอีเมลรายงานอัตโนมัติ |
| การจัดการข้อผิดพลาด | แก้ไปทีละจุด | มีระบบลองใหม่/บันทึกล็อกในตัว |
ผลลัพธ์คืออะไร? ข้อมูลมากขึ้น งานจุกจิกน้อยลง และเวิร์กโฟลว์ที่เติบโตไปพร้อมกับเป้าหมายของคุณ
เพิ่มประสิทธิภาพ: ผสานฟีเจอร์ AI Scraping ของ Thunderbit กับ OpenClaw
ตรงนี้แหละที่เรื่องเริ่มน่าสนใจจริง ๆ ในฐานะผู้ร่วมก่อตั้ง Thunderbit ผมเชื่ออย่างมากในการผสานข้อดีของทั้งสองโลกเข้าด้วยกัน: เอนจินสแครปปิงที่ยืดหยุ่นของ OpenClaw และการตรวจจับฟิลด์พร้อมการส่งออกด้วย AI ของ Thunderbit
Thunderbit ช่วยยกระดับ OpenClaw อย่างไร
- AI Suggest Fields: Thunderbit สามารถวิเคราะห์หน้าเว็บโดยอัตโนมัติและแนะนำคอลัมน์ที่ควรดึงข้อมูลให้—ไม่ต้องเดา CSS selector อีกต่อไป
- ส่งออกข้อมูลทันที: ส่งออกข้อมูลที่สแครปได้ตรงไปยัง Excel, Google Sheets, Airtable หรือ Notion ได้ในคลิกเดียว (Thunderbit Docs)
- เวิร์กโฟลว์แบบไฮบริด: ใช้ OpenClaw สำหรับการนำทางและตรรกะการสแครปที่ซับซ้อน จากนั้นส่งผลลัพธ์เข้า Thunderbit เพื่อทำแมปฟิลด์ เพิ่มความสมบูรณ์ของข้อมูล และส่งออก

ตัวอย่างเวิร์กโฟลว์แบบไฮบริด
- ใช้เบราว์เซอร์ที่จัดการให้ของ OpenClaw หรือสกิล Scrapling เพื่อดึงข้อมูลดิบจากเว็บแบบไดนามิก
- นำผลลัพธ์เข้า Thunderbit
- คลิก “AI Suggest Fields” เพื่อแมปข้อมูลอัตโนมัติ
- ส่งออกไปยังรูปแบบหรือแพลตฟอร์มที่คุณต้องการ
ชุดนี้เปลี่ยนเกมสำหรับทีมที่ต้องการทั้งพลังและความง่ายในการใช้งาน—นึกถึงทีมเซลส์ออปส์ นักวิเคราะห์อีคอมเมิร์ซ และใครก็ตามที่เบื่อการรับมือสเปรดชีตยุ่งเหยิง
ลองใช้ Thunderbit AI Suggest Fields
แก้ปัญหาแบบเรียลไทม์: ข้อผิดพลาด OpenClaw ที่พบบ่อยและวิธีแก้
แม้แต่เครื่องมือที่ดีที่สุดก็ยังสะดุดได้เป็นครั้งคราว นี่คือคู่มือสั้น ๆ สำหรับวิเคราะห์และแก้ปัญหาการสแครปด้วย OpenClaw ที่พบบ่อย:
ข้อผิดพลาดที่พบบ่อย
- ปัญหาการยืนยันตัวตน: บางเว็บบล็อกบอทหรือบังคับให้ล็อกอิน ใช้เบราว์เซอร์ที่จัดการให้ของ OpenClaw หรือผสานกับ Selenium สำหรับโฟลว์ล็อกอิน (docs.openclaw.ai)
- คำขอถูกบล็อก: หมุน user agent ใช้พร็อกซี หรือชะลออัตราการร้องขอเพื่อหลีกเลี่ยงการถูกแบน
- การแยกวิเคราะห์ล้มเหลว: ตรวจ CSS/XPath selector อีกครั้ง บางเว็บไซต์อาจเปลี่ยนโครงสร้างไปแล้ว
- ข้อผิดพลาดของปลั๊กอิน/สกิล: รัน
openclaw plugins doctorเพื่อตรวจวิเคราะห์ปัญหาของส่วนขยายที่ติดตั้งไว้ (docs.openclaw.ai)
คำสั่งสำหรับตรวจวินิจฉัย
openclaw status– ตรวจสถานะของเกตเวย์และเครื่องมือopenclaw security audit– สแกนหาช่องโหว่openclaw browser --browser-profile openclaw status– ตรวจสุขภาพของระบบออโตเมชันเบราว์เซอร์
แหล่งข้อมูลจากชุมชน
แนวปฏิบัติที่ดีที่สุดสำหรับการสแครปด้วย OpenClaw ให้เสถียรและขยายสเกลได้

อยากให้การสแครปของคุณราบรื่นและยั่งยืนใช่ไหม? นี่คือเช็กลิสต์ของผม:
- เคารพ robots.txt: สแครปเฉพาะสิ่งที่คุณได้รับอนุญาต
- จำกัดอัตราคำขอ: อย่ายิงคำขอถี่เกินไปจนเว็บรับไม่ไหว
- ตรวจสอบผลลัพธ์: เช็กความครบถ้วนและความถูกต้องของข้อมูลเสมอ
- ติดตามการใช้งาน: บันทึกการรันสแครปและคอยดูข้อผิดพลาดหรือการถูกแบน
- ใช้พร็อกซีเมื่อทำงานระดับสเกล: หมุน IP เพื่อหลีกเลี่ยงการจำกัดอัตรา
- ดีพลอยบนคลาวด์: สำหรับงานใหญ่ ให้รัน OpenClaw ใน VM หรือสภาพแวดล้อมแบบคอนเทนเนอร์
- จัดการข้อผิดพลาดอย่างนุ่มนวล: สร้างระบบลองใหม่และตรรกะสำรองไว้ในสคริปต์
| สิ่งที่ควรทำ | สิ่งที่ไม่ควรทำ |
|---|---|
| ใช้ปลั๊กอิน/สกิลทางการ | ติดตั้งโค้ดที่ไม่น่าเชื่อถือแบบไม่ตรวจสอบ |
| รันการตรวจสอบความปลอดภัยเป็นประจำ | เพิกเฉยต่อคำเตือนเรื่องช่องโหว่ |
| ทดสอบบนสภาพแวดล้อม staging ก่อนขึ้นโปรดักชัน | สแครปข้อมูลอ่อนไหวหรือข้อมูลส่วนตัว |
| จัดทำเอกสารเวิร์กโฟลว์ของคุณ | พึ่งพา selector ที่ฝังแบบตายตัว |
เคล็ดลับขั้นสูง: ปรับแต่งและขยาย OpenClaw ให้ตอบโจทย์เฉพาะทาง
ถ้าคุณพร้อมจะเล่นระดับโปรเต็มตัว OpenClaw เปิดให้สร้างสกิลและปลั๊กอินแบบกำหนดเองสำหรับงานเฉพาะทางได้
การพัฒนาสกิลแบบกำหนดเอง
- ทำตาม เอกสาร OpenClaw skill SDK เพื่อสร้างเครื่องมือดึงข้อมูลใหม่ ๆ
- ใช้ Python หรือ TypeScript ตามที่คุณถนัด
- ลงทะเบียนสกิลของคุณกับ ClawHub เพื่อแชร์และนำกลับมาใช้ซ้ำได้ง่าย
ฟีเจอร์ขั้นสูง
- เชื่อมสกิลเป็นทอด ๆ: รวมหลายขั้นตอนการดึงข้อมูลเข้าด้วยกัน (เช่น สแครปหน้ารายการ แล้วค่อยเข้าไปหน้ารายละเอียดแต่ละรายการ)
- เบราว์เซอร์แบบ headless: ใช้ Chromium ที่จัดการให้ของ OpenClaw หรือผสานกับ Playwright สำหรับเว็บที่พึ่งพา JavaScript หนัก ๆ
- การเชื่อมเอเจนต์ AI: เชื่อม OpenClaw กับบริการ AI ภายนอกเพื่อการแยกวิเคราะห์หรือเพิ่มข้อมูลที่ฉลาดขึ้น
การจัดการข้อผิดพลาดและคอนเท็กซ์
- ใส่ระบบจัดการข้อผิดพลาดที่แข็งแรงลงในสกิลของคุณ (try/except ใน Python, error callback ใน TypeScript)
- ใช้อ็อบเจ็กต์ context เพื่อส่งสถานะระหว่างขั้นตอนการสแครป
ถ้าอยากหาตัวอย่างเพิ่มเติม ลองดู สกิลที่ชุมชนช่วยกันสร้าง และ เอกสารอ้างอิง API ของ Scrapling
สรุปและประเด็นสำคัญที่ควรจำ
เราได้ครอบคลุมตั้งแต่การติดตั้ง OpenClaw และการรันสแครปครั้งแรก ไปจนถึงการสร้างเวิร์กโฟลว์แบบอัตโนมัติและแบบไฮบริดร่วมกับ Thunderbit นี่คือสิ่งที่ผมหวังว่าคุณจะจำได้:
- OpenClaw คือขุมพลังโอเพนซอร์สที่ยืดหยุ่น สำหรับการดึงข้อมูลจากเว็บ โดยเฉพาะบนเว็บที่ซับซ้อนหรือไดนามิก
- ระบบปลั๊กอิน/สกิลของมันช่วยให้คุณรับมือได้ทุกอย่าง ตั้งแต่งานดึงข้อมูลง่าย ๆ ไปจนถึงงานสแครปหลายขั้นตอนที่ซับซ้อน
- การผสาน OpenClaw กับฟีเจอร์ AI ของ Thunderbit ทำให้การแมปฟิลด์ การส่งออกข้อมูล และการทำเวิร์กโฟลว์อัตโนมัติเป็นเรื่องง่าย
- รักษาความปลอดภัยและปฏิบัติตามข้อกำหนด: ตรวจสภาพแวดล้อม เคารพกติกาของเว็บไซต์ และตรวจสอบความถูกต้องของข้อมูล
- อย่ากลัวที่จะทดลอง: ชุมชน OpenClaw คึกคักและเป็นมิตร—ลองเข้ามา ลองสกิลใหม่ ๆ แล้วแชร์ความสำเร็จของคุณ
ถ้าคุณอยากยกระดับประสิทธิภาพการสแครปไปอีกขั้น Thunderbit พร้อมช่วยคุณ และถ้าอยากเรียนรู้ต่อ ลองดู Thunderbit Blog สำหรับบทวิเคราะห์เชิงลึกและคู่มือใช้งานจริงเพิ่มเติม
ขอให้สแครปสนุก และขอให้ selector ของคุณเจอเป้าหมายเสมอ
คำถามที่พบบ่อย
1. อะไรทำให้ OpenClaw แตกต่างจากเว็บสแครปเปอร์แบบดั้งเดิมอย่าง BeautifulSoup หรือ Scrapy?
OpenClaw ถูกสร้างมาในรูปแบบเกตเวย์เอเจนต์พร้อมเครื่องมือแบบโมดูลาร์ รองรับเบราว์เซอร์ที่จัดการให้ และระบบปลั๊กอิน/สกิล ซึ่งทำให้ยืดหยุ่นกว่าสำหรับเว็บแบบไดนามิก เว็บที่พึ่งพา JavaScript หนัก ๆ หรือเว็บที่เต็มไปด้วยรูปภาพ และยังทำให้อัตโนมัติเวิร์กโฟลว์ตั้งแต่ต้นจนจบได้ง่ายกว่ากรอบงานแบบดั้งเดิมที่ต้องเขียนโค้ดเยอะ (docs.openclaw.ai)
2. ถ้าไม่ใช่นักพัฒนา ฉันใช้ OpenClaw ได้ไหม?
ได้! โฟลว์เริ่มต้นใช้งานและระบบปลั๊กอินของ OpenClaw เหมาะกับมือใหม่ สำหรับงานที่ซับซ้อนขึ้น คุณสามารถใช้สกิลที่ชุมชนสร้างไว้ หรือผสาน OpenClaw กับเครื่องมือแบบ no-code อย่าง Thunderbit เพื่อช่วยแมปฟิลด์และส่งออกข้อมูลได้ง่าย ๆ
3. จะแก้ปัญหาข้อผิดพลาด OpenClaw ที่พบบ่อยได้อย่างไร?
เริ่มจาก openclaw status และ openclaw security audit ถ้าเป็นปัญหาปลั๊กอิน ให้ใช้ openclaw plugins doctor ตรวจสอบ ดูเอกสารทางการ และปัญหาใน GitHub เพื่อหาวิธีแก้ปัญหาที่พบบ่อย
4. ใช้ OpenClaw สำหรับ web scraping ปลอดภัยและถูกกฎหมายไหม?
เช่นเดียวกับสแครปเปอร์ทุกตัว ควรเคารพเงื่อนไขการให้บริการของเว็บไซต์และ robots.txt เสมอ OpenClaw เป็นโอเพนซอร์สและรันในเครื่องได้ แต่คุณควรตรวจปลั๊กอินด้านความปลอดภัย และหลีกเลี่ยงการสแครปข้อมูลอ่อนไหวหรือข้อมูลส่วนตัวโดยไม่ได้รับอนุญาต (github.com)
5. จะผสาน OpenClaw กับ Thunderbit เพื่อให้ได้ผลลัพธ์ที่ดีกว่าได้อย่างไร?
ใช้ OpenClaw สำหรับตรรกะการสแครปที่ซับซ้อน จากนั้นนำข้อมูลดิบเข้า Thunderbit Thunderbit AI Suggest Fields จะช่วยแมปข้อมูลให้อัตโนมัติ และคุณสามารถส่งออกตรงไปยัง Excel, Google Sheets, Notion หรือ Airtable ได้เลย—ทำให้เวิร์กโฟลว์เร็วขึ้นและเชื่อถือได้มากขึ้น (Thunderbit Docs)
อยากดูไหมว่า Thunderbit ช่วยยกระดับการสแครปของคุณได้แค่ไหน? ดาวน์โหลดส่วนขยาย Chrome แล้วเริ่มสร้างเวิร์กโฟลว์แบบไฮบริดที่ฉลาดขึ้นได้เลยวันนี้ และอย่าลืมแวะชม ช่อง YouTube ของ Thunderbit สำหรับบทเรียนและเคล็ดลับแบบลงมือทำจริง
ลองใช้ Thunderbit เพื่อการทำเว็บสแครปปิงที่ฉลาดกว่า Get Started Free
อ่านเพิ่มเติม




