
สัปดาห์ที่แล้วฉันใช้เวลาทั้งบ่ายไปกับการพยายามให้ AI agent กรอกฟอร์มซัพพลายเออร์บนพอร์ทัลที่ต้องล็อกอินเข้าไปใช้งานได้ ผ่านไปชั่วโมงที่สาม ฉันก็ยังจ้อง error "Connection Refused" อยู่ดี VPS ก็หน่วยความจำเต็ม และเริ่มคิดจริงจังว่าคงกรอกเองยังง่ายกว่า
ประสบการณ์แบบนี้แหละคือชุดเริ่มต้นของ OpenClaw browser automation อย่างแท้จริง เครื่องมือนี้สามารถพาไปยังหน้าเว็บ ดึงข้อมูล กรอกฟอร์ม และเชื่อมต่อเวิร์กโฟลว์ซับซ้อนด้วยคำสั่งภาษาอังกฤษล้วน ๆ ได้ — เป็นของที่น่าประทับใจมาก แต่ช่องว่างระหว่าง "ฟังดูดีสุด ๆ" กับ "มันรันได้จริงบนเครื่องฉัน" นี่แหละคือจุดที่คนส่วนใหญ่ติดขัด
ฉันใช้เวลาพอสมควรทั้งในฐานะคนที่สร้างเครื่องมือ automation ที่ Thunderbit และในฐานะคนที่ลองของในโลกโอเพนซอร์สมาเยอะ คู่มือนี้จึงเป็นแบบที่ฉันอยากมีตั้งแต่แรก: ไล่ตั้งค่าจริงแบบทีละขั้น, เลือกโหมดเบราว์เซอร์ให้ถูกตั้งแต่ต้น, เส้นทางสำหรับ Windows แบบไม่ต้องพึ่ง WSL, คู่มือเอาตัวรอดจากบอทบล็อก, ตัวอย่างผลลัพธ์จริง, error ที่พบบ่อยพร้อมวิธีแก้ที่ใช้ได้จริง และมุมมองตรงไปตรงมาว่าเมื่อไหร่ OpenClaw เหมาะ — และเมื่อไหร่ที่มันเกินจำเป็น
ลอง Thunderbit เพื่อเว็บสแครปปิ้งแบบไม่ต้องออกแรง
ดึงข้อมูลจากทุกเว็บไซต์ด้วย AI Get Started Free
OpenClaw Browser Automation คืออะไร?
OpenClaw คือแพลตฟอร์ม AI agent แบบโอเพนซอร์สใช้ฟรีภายใต้ MIT license ที่สามารถควบคุมเบราว์เซอร์แทนคุณได้ แทนที่จะเขียนสคริปต์ Selenium หรือโค้ด Puppeteer คุณแค่บอกเป็นภาษาธรรมดาว่าอยากให้ทำอะไร — เช่น "เข้าไปหน้านี้แล้วดึงชื่อสินค้าและราคาทั้งหมด" — จากนั้น AI จะหาวิธีทำให้เอง ระบบจะใช้ snapshot แบบมีหมายเลขกำกับ โดย agent จะระบุองค์ประกอบบนหน้าเว็บ ใส่เลขอ้างอิง และโต้ตอบทีละขั้น
สถาปัตยกรรมของมันมี 3 ส่วน ซึ่งนี่คือเหตุผลที่การตั้งค่ามันไม่ใช่แค่ติดตั้ง extension แล้วจบ:
- Gateway (VPS/server): ส่วน "สมอง" ที่ประมวลผลคำสั่งของคุณและเชื่อมต่อกับ LLM ทำงานบนพอร์ต 18789 โดยค่าเริ่มต้น
- Node Host (เครื่อง local): ตัวกลางที่ช่วยให้ Gateway ส่งคำสั่งเบราว์เซอร์มายัง Chrome บนเครื่องคุณ เชื่อมต่อผ่าน secure tunnel อย่าง Tailscale
- Chrome Extension (Browser Relay): ทำให้ agent ควบคุมแท็บเบราว์เซอร์ใน Chrome จริงของคุณได้โดยตรง
พอร์ตอื่น ๆ ที่เกี่ยวข้อง ได้แก่ Control Service (18791), CDP Relay (18792) และ managed browser CDP (18800–18899 รองรับโปรไฟล์พร้อมกันได้สูงสุด 100 โปรไฟล์)
ใช่ มันมีหลายชิ้นส่วนพอสมควร แต่พอเข้าใจหน้าที่ของแต่ละส่วนแล้ว การตั้งค่าจะเริ่มมีเหตุผล ลองนึกภาพเป็นรถบังคับวิทยุ: Gateway คือรีโมต, Node Host คือสัญญาณวิทยุ, และ Chrome Extension ก็คือตัวรถนั่นเอง

ทำไม OpenClaw Browser Automation ถึงสำคัญกับทีมธุรกิจ
คนทำงานด้านความรู้ใช้เวลาสูงสุดถึง 60% กับงานธุรการประจำ แทนที่จะไปโฟกัสกับงานที่สร้างมูลค่า รวมถึงใช้เวลา 1.8 ชั่วโมงต่อวันไปกับการค้นหาและรวบรวมข้อมูล Smartsheet พบว่า พนักงานมากกว่า 40% ใช้เวลาทำงานอย่างน้อยหนึ่งในสี่ของสัปดาห์ไปกับงานซ้ำ ๆ ที่ต้องทำมือ ส่วนการคีย์ข้อมูลเองล้วน ๆ ทำให้บริษัทในสหรัฐฯ เสียค่าใช้จ่ายโดยประมาณ $8,500 ต่อพนักงานต่อปี
นี่แหละคือปัญหาที่ OpenClaw browser automation ถูกสร้างมาเพื่อแก้ ในการใช้งานจริง มันเชื่อมโยงกับเวิร์กโฟลว์ธุรกิจได้แบบชัดเจน:
| Use Case | OpenClaw ทำอะไร | ผลลัพธ์ทางธุรกิจ |
|---|---|---|
| Lead generation | ดึงข้อมูลติดต่อจากไดเรกทอรีและหน้าเว็บไซต์บริษัท | เติม pipeline ฝ่ายขายได้เร็วขึ้น |
| ตรวจราคาคู่แข่ง | เข้าไปดูหน้าสินค้าทุกวันและดึงราคามาเปรียบเทียบ | ได้ข้อมูลแข่งขันแบบเรียลไทม์ |
| กรอกฟอร์ม / คีย์ข้อมูล | กรอกแบบฟอร์มเว็บที่ทำซ้ำ ๆ เช่น CRM, พอร์ทัล, ใบสมัคร | ประหยัดเวลาหลายชั่วโมงต่อสัปดาห์ |
| เฝ้าติดตามคอนเทนต์ | เช็กบล็อกคู่แข่ง, job board, press release | รู้สัญญาณการแข่งขันได้ก่อน |
| QA / ทดสอบระบบ | วิ่งผ่าน flow บนเว็บเพื่อตรวจว่าทำงานได้จริง | ลดประสบการณ์ใช้งานที่พังกลางทาง |
ตลาด AI agent โตถึง $7.38 พันล้านดอลลาร์ในปี 2025 เพิ่มขึ้นเกือบเท่าตัวจาก 3.7 พันล้านดอลลาร์ในปี 2023 และ 88% ขององค์กร ใช้ AI automation ในอย่างน้อยหนึ่งฟังก์ชันแล้ว นี่ไม่ใช่หมวดเฉพาะกลุ่มอีกต่อไป
Sandbox Chromium vs. Browser Relay vs. Chrome Remote Debugging: เลือกโหมดไหนให้ถูก
จากประสบการณ์ของฉัน การเลือกโหมดเบราว์เซอร์ผิดคือสาเหตุใหญ่ที่สุดของความหงุดหงิดสำหรับผู้ใช้ OpenClaw มือใหม่ ฉันเห็นมาหลายคนเสียเวลาหลายชั่วโมงไปกับการไล่บั๊กการเชื่อมต่อ ทั้งที่จริงหลีกเลี่ยงได้ถ้าเลือกโหมดให้ถูกตั้งแต่แรก OpenClaw มี 3 วิธีเชื่อมต่อ และแต่ละแบบก็มีข้อแลกเปลี่ยนจริง ๆ:
- Sandbox Chromium (Managed Profile): OpenClaw จะเปิดเบราว์เซอร์ headless ของตัวเองบนเซิร์ฟเวอร์ ไม่ต้องมี session ล็อกอิน ตั้งค่าเร็ว แต่ถูกระบบ anti-bot ตรวจจับได้ง่ายกว่า
- Browser Relay (Existing-Session): ใช้ node host บนเครื่อง local ของคุณส่งคำสั่งจาก VPS ไปยัง Chrome จริงของคุณ รองรับ session ล็อกอินและคุกกี้ และใช้ browser fingerprint จริงของคุณ
- Chrome Remote Debugging (Remote CDP): เชื่อมต่อไปยังเบราว์เซอร์ระยะไกลผ่าน WebSocket URL ใช้งาน session ได้เต็มรูปแบบ แต่ตั้งค่ายากที่สุด ใช้ได้กับผู้ให้บริการคลาวด์อย่าง Browserless หรือ Browserbase

ตารางเปรียบเทียบ: ทั้ง 3 โหมดเบราว์เซอร์
| Factor | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| รองรับการล็อกอิน | ❌ ไม่ได้ (โปรไฟล์ใหม่ทุกครั้ง) | ✅ ได้ (session จริง) | ✅ ได้ (pre-authenticated) |
| ความเสี่ยงถูกบอทบล็อก | ⚠️ ปานกลาง-สูง | ✅ ต่ำ (fingerprint จริง) | ✅ ต่ำ (ผู้ให้บริการดูแลให้) |
| ความเร็ว | ✅ เร็ว | ⚠️ ช้ากว่า (ผ่าน network relay) | ⚠️ แล้วแต่บริการ |
| ความยากในการตั้งค่า | ต่ำ | ปานกลาง | สูง |
| รองรับฟีเจอร์ครบ | ✅ ได้ (ทุกฟีเจอร์) | ⚠️ จำกัด (ไม่มี batch, ไม่มี download intercept) | แล้วแต่ผู้ให้บริการ |
| เหมาะกับ | หน้าเว็บสาธารณะ, งานดึงข้อมูลเร็ว ๆ | เว็บที่ต้องล็อกอิน, งานกรอกฟอร์ม | โครงสร้างคลาวด์, มอนิเตอร์ตลอดเวลา |
Flowchart การตัดสินใจ: ควรเลือกโหมดไหน?
ไล่ตอบคำถามตามลำดับนี้:
- "ต้องล็อกอินไหม?" — ไม่ต้อง → Sandbox Chromium. ต้อง → คำถามถัดไป
- "เว็บไซต์มีระบบป้องกันบอทหนักไหม?" — ใช่ → Browser Relay (fingerprint ของเบราว์เซอร์จริงช่วยลดการถูกจับได้) ไม่ใช่ → ใช้ Browser Relay หรือ Remote CDP ก็ได้
- "ต้องการ session ที่ต่อเนื่องและเปิดค้างตลอดไหม เช่น มอนิเตอร์แดชบอร์ด 24/7?" — ใช่ → Remote CDP กับผู้ให้บริการคลาวด์. ไม่ใช่ → Browser Relay
ตัวอย่างการจับคู่สถานการณ์จริง:
- ดึงรายการสินค้า Amazon แบบสาธารณะ → Sandbox Chromium
- กรอกฟอร์ม CRM ที่ต้องล็อกอิน → Browser Relay
- เฝ้าดูแดชบอร์ด analytics ภายในตลอด 24 ชั่วโมง → Remote CDP กับ Browserless/Browserbase
เลือกให้ถูกตั้งแต่ต้น คุณจะประหยัดเวลาการดีบักไปได้หลายชั่วโมง จริง ๆ
ก่อนเริ่ม
- ระดับความยาก: ปานกลาง (ควรพอใช้ CLI ได้)
- เวลาที่ต้องใช้: 45–75 นาทีสำหรับการตั้งค่าครบ; 10–15 นาทีต่อแต่ละขั้น
- สิ่งที่ต้องมี: VPS (RAM ขั้นต่ำ 2GB, แนะนำ 4GB), Node.js v22.12.0+, บัญชี Tailscale (ฟรี), เบราว์เซอร์ Chrome และความอดทน
ขั้นตอนที่ 1: ทำให้ OpenClaw รันบน VPS (หรือรันในเครื่องก็ได้)
VPS คือที่ที่ "สมอง" ของ OpenClaw อาศัยอยู่ มี 2 ทางให้เลือก:
ตัวเลือก A: VPS แบบกดครั้งเดียวพร้อมใช้
ผู้ให้บริการหลายรายมี image ของ OpenClaw ที่ตั้งค่ามาให้แล้ว:
| Provider | Starting Price | Notes |
|---|---|---|
| Hostinger | เริ่มต้น $6.99/เดือน | image ตั้งค่าพร้อมใช้ |
| Tencent Cloud Lighthouse | เริ่มต้นประมาณ $0.08/ปี (โปรโมชัน) | แนะนำ 2 คอร์/4GB |
| Hetzner | เริ่มต้น $4.09/เดือน (CX22) | คุ้มสุด; ต้องติดตั้งเอง |
| DigitalOcean | เริ่มต้น $4/เดือน | ต้องติดตั้งเอง |
| Vultr | เริ่มต้น $3.50/เดือน | ต้องติดตั้งเอง |
ตัวเลือก B: ติดตั้งด้วย CLI เอง
# ติดตั้งผ่าน npm (ต้องใช้ Node.js v22.12.0+)
npm install -g openclaw
# เริ่มตัวช่วย onboarding
openclaw onboard
# สร้าง gateway token (เก็บไว้ให้ดี — node host จะต้องใช้)
openclaw doctor --generate-gateway-token
# ตรวจสอบการตั้งค่า
openclaw doctor --fix
สเปกขั้นต่ำ: RAM 2GB (1GB มักจะล้ม), แนะนำ 4GB แต่ละ browser headless ใช้หน่วยความจำราว 400–800 MB ตอน idle ถ้าใช้ Docker ให้ตั้ง shm_size: '2gb' — จุดนี้สำคัญต่อความเสถียรมาก
พอจบขั้นนี้ คุณควรมี OpenClaw รันอยู่แล้ว และมี Gateway token เก็บไว้เรียบร้อย (ฉันเก็บไว้ใน password manager อย่าทำหายเชียว)
ขั้นตอนที่ 2: ตั้งค่า Tailscale เพื่อเชื่อม VPS กับเครื่อง local
Tailscale จะสร้าง tunnel ส่วนตัวแบบเข้ารหัสระหว่าง VPS กับอุปกรณ์ local ของคุณ ทำให้คำสั่งเบราว์เซอร์ไม่ต้องวิ่งผ่านอินเทอร์เน็ตสาธารณะ พอคิดว่าช่วงต้นปี 2026 OpenClaw ถูก Kaspersky รายงานว่ามี 512 ช่องโหว่ที่ถูกแจ้งเตือน การข้ามขั้นนี้ถือว่าไม่ค่อยฉลาดนัก
# บน VPS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# จด Tailscale IP ของ VPS (100.x.x.x)
# ตั้งค่าให้ Gateway ฟังบนเครือข่าย Tailscale
openclaw config set gateway.listen "100.x.x.x:18789"
ติดตั้ง Tailscale บนเครื่อง local จาก tailscale.com/download อุปกรณ์ทั้งสองเครื่องต้องใช้บัญชี Tailscale เดียวกัน
ทางเลือกอื่นถ้าไม่อยากใช้ Tailscale:
| Factor | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| ใช้เวลาตั้งค่า | 5 นาที | 10–15 นาที | 20–30 นาที |
| ค่าใช้จ่าย | ฟรี (ใช้งานส่วนตัว) | ฟรี | ฟรี |
| ข้าม NAT | อัตโนมัติ | อัตโนมัติ | ต้องตั้งเอง |
ตอนนี้คุณควร ping Tailscale IP ของ VPS จากเครื่อง local ได้แล้ว ถ้ายังไม่ได้ ให้เช็กว่าใช้งานบัญชี Tailscale เดียวกันทั้งสองฝั่งหรือไม่
ขั้นตอนที่ 3: ติดตั้ง Node Host บนอุปกรณ์ local
Node host ทำหน้าที่ส่งต่อคำสั่งจาก VPS Gateway ไปยัง Chrome บนเครื่องคุณ — เป็นตัวแปลระหว่างเซิร์ฟเวอร์กับเบราว์เซอร์
# ติดตั้งแพ็กเกจ node host
npm install -g @openclaw/node-host
# ตั้งค่า gateway token จากขั้นตอนที่ 1
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# เริ่ม node host โดยชี้ไปที่ Tailscale IP ของ VPS
openclaw node install --host 100.x.x.x --port 18789
# อนุมัติการเชื่อมต่อจากฝั่ง VPS
openclaw node approve <node-id>
คุณควรเห็นข้อความยืนยันว่า node เชื่อมต่อและได้รับการอนุมัติแล้ว ถ้าขั้นตอน approve ค้าง ให้รีสตาร์ต Gateway process บน VPS
ขั้นตอนที่ 4: ติดตั้ง OpenClaw Chrome Extension
Extension นี้จะเปิดทางให้ agent ควบคุมแท็บเบราว์เซอร์ได้โดยตรง คุณยังหาได้จาก Chrome Web Store โดยค้นหา "OpenClaw Browser Relay"
# ติดตั้งไฟล์ extension
openclaw browser extension install
# หรือทำเองแบบ manual:
# 1. เปิด chrome://extensions
# 2. เปิด "Developer mode" (สวิตช์มุมขวาบน)
# 3. กด "Load unpacked" → เลือกโฟลเดอร์ extension
# 4. ปักหมุดไว้บนแถบเครื่องมือ
# 5. ยืนยันว่า badge แสดง "ON"
ถ้า badge ขึ้น "ON" ก็ใช้ได้แล้ว ถ้ายังคงเป็น "OFF" ให้ข้ามไปดูส่วน troubleshooting ด้านล่าง
ขั้นตอนที่ 5: ลองงาน OpenClaw Browser Automation แรกของคุณ
เปิดแท็บเป้าหมาย แล้วลองพิมพ์อะไรที่ง่าย ๆ จากหน้าต่างแชตของ OpenClaw เช่น:
เข้าไปที่ https://books.toscrape.com แล้วดึงชื่อและราคาของหนังสือทุกเล่มบนหน้านี้
ลำดับการทำงานที่คาดหวัง: ส่งคำสั่ง → agent ถ่าย snapshot (ระบุองค์ประกอบบนหน้าด้วยเลขอ้างอิง) → agent ดึงข้อมูล → ส่งผลลัพธ์ที่มีโครงสร้างกลับมาเป็น JSON หรือ CSV
ทิปจากประสบการณ์: เริ่มจาก prompt ที่ง่ายสุดก่อน การอธิบายเยอะเกินไปบางครั้งทำให้ AI สับสนได้ — ใส่รายละเอียดเพิ่มก็ต่อเมื่อ agent ตีความคำสั่งแรกผิด
สำหรับหนังสือ 20 เล่มบนหน้าแรก ควรใช้เวลาราว 30–60 วินาที ถ้าได้ข้อมูลเป็นโครงสร้างกลับมา แปลว่าการตั้งค่า OpenClaw browser automation ของคุณใช้งานได้แล้ว
OpenClaw Browser Automation บน Windows: เส้นทางตั้งค่าแบบเนทีฟ
คู่มือ OpenClaw ส่วนใหญ่มักสมมติว่าคุณใช้ macOS หรือ Linux ซึ่งถ้าคุณเป็นคนใช้ Windows ก็คงสังเกตแล้ว มีคนในฟอรัมคนหนึ่งพูดไว้ตรงมากว่า "หลายทางเลือกดูเหมือนจะใช้ได้ในเชิงแนวคิด แต่ไม่มีอันไหนออกแบบมาสำหรับ Windows แบบเนทีฟจริง ๆ"
นี่คือวิธีที่ใช้ได้จริง
ตัวเลือก A: Chrome Remote Debugging บน Windows (แนะนำสำหรับ native)
เป็นวิธีบน Windows ที่เสถียรที่สุด เปิด PowerShell แล้วเรียก Chrome ด้วย remote debugging:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
ถ้า Chrome ไม่ได้อยู่ที่ path นี้ ให้ลอง:
# ตรวจสอบตำแหน่งอื่น
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# หรือเช็กใน AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
จากนั้นตั้งค่า OpenClaw ให้เชื่อมผ่าน Remote CDP โดยกำหนด cdpUrl เป็น ws://localhost:9222 ในไฟล์คอนฟิก openclaw.json
ตัวเลือก B: ใช้ Docker Desktop เป็นทางเลือกสำรองบน Windows
ถ้าเส้นทางแบบ native ยังมีปัญหา Docker Desktop บน Windows สามารถรัน Chromium แบบ headless ได้:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# ชี้ OpenClaw ไปที่: cdpUrl: "ws://localhost:9222"
มันเพิ่มชั้นความซับซ้อนอีกนิด แต่สำหรับบางคนกลับเสถียรกว่า ใช้ได้แต่ไม่ค่อยสวย
คลัง error เฉพาะ Windows
| Error | สาเหตุ | วิธีแก้ (PowerShell) |
|---|---|---|
| Port 9222 ถูกใช้งานอยู่แล้ว | มี DevTools session อื่นเปิดอยู่ | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| ไม่พบ Chrome binary | path ผิด | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Tailscale connection refused | Windows Firewall บล็อก | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| npm permission errors | ไม่ได้รันสิทธิ์ admin | เปิด PowerShell แบบ Administrator หรือใช้ nvm-windows |
ทุกคำสั่งด้านบนเป็น PowerShell ไม่ใช่ bash คัดลอกไปใช้ได้เลย
คู่มือเอาตัวรอดจากบอทบล็อกสำหรับ OpenClaw Browser Automation
การตรวจจับบอทคือปัญหาอันดับหนึ่งของผู้ใช้ OpenClaw browser automation OpenClaw Chromium ค่าเริ่มต้นไม่มี กลไก stealth ในตัว เว็บไซต์จึงจับได้จาก WebDriver flag, ขนาดหน้าจอ, fingerprint ของฟอนต์ และชื่อเสียงของ IP ฉันเคยเห็น agent โดนบล็อกภายในไม่กี่วินาทีบนบางเว็บ
แต่ก็มีแนวทางแบบเป็นชั้น ๆ เริ่มจากแก้ที่ง่ายที่สุด แล้วค่อยขยับขึ้นเมื่อจำเป็นจริง ๆ
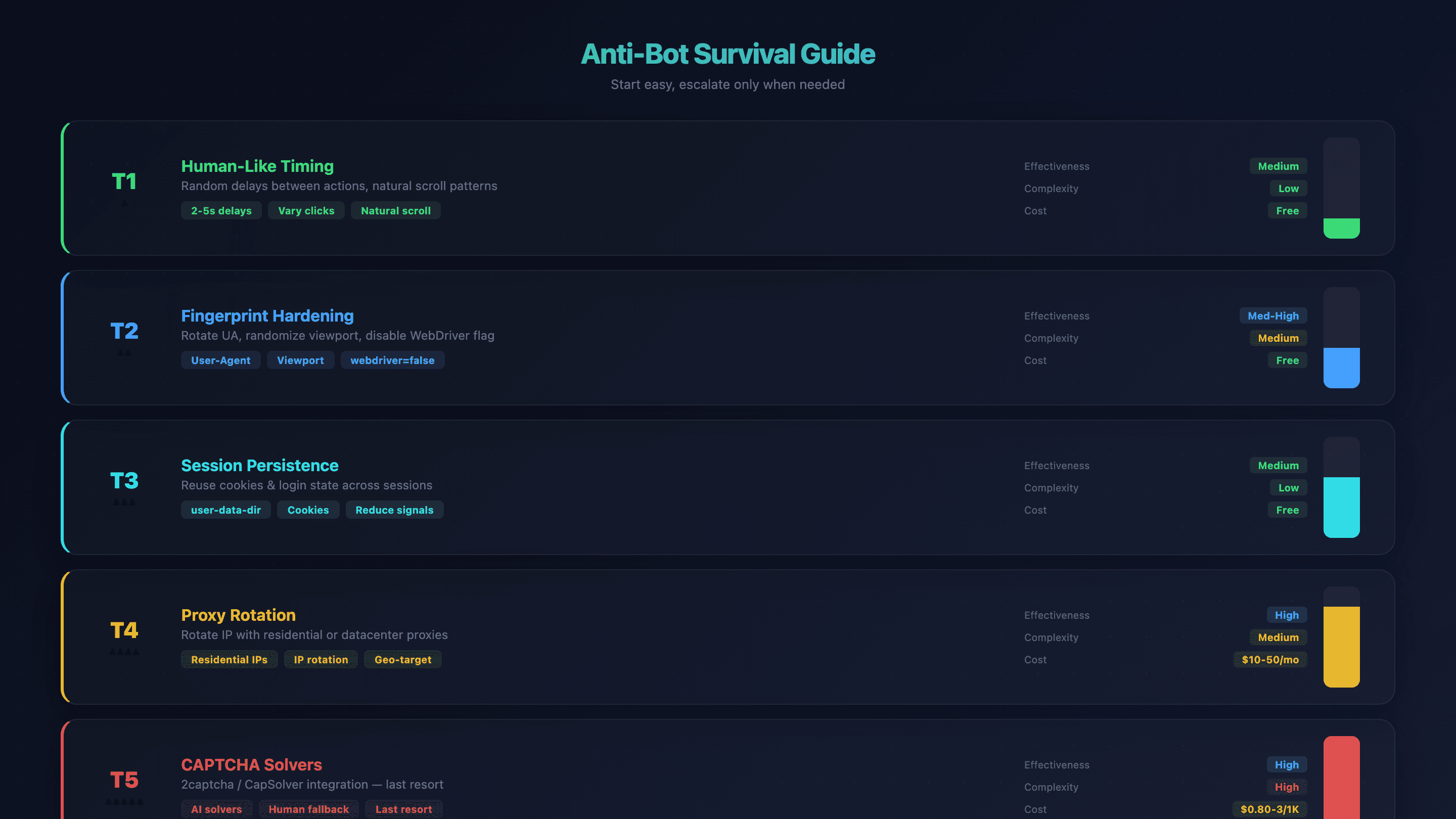
ชั้นที่ 1: จังหวะและพฤติกรรมที่ดูเป็นมนุษย์
ใส่ดีเลย์แบบสุ่มระหว่างแต่ละ action ใน prompt ของคุณ แทนที่จะสั่งให้คลิกเร็วเท่าเครื่อง ให้บอก agent ว่า "รอ 2–5 วินาทีระหว่างการคลิกแต่ละครั้ง" AI จะปรับจังหวะเองได้ระดับหนึ่งอยู่แล้ว แต่การสั่งตรง ๆ ช่วยได้มาก
ประสิทธิภาพ: ปานกลาง | ความซับซ้อน: ต่ำ | ต้นทุน: ฟรี
ชั้นที่ 2: เสริมความทนทานของ fingerprint
สลับ user-agent, สุ่มขนาด viewport และให้ OpenClaw ปิด navigator.webdriver อัตโนมัติ (ผ่าน --disable-blink-features=AutomationControlled)
# ตั้งค่า headers แบบกำหนดเอง
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# สุ่ม viewport
openclaw browser set viewport 1366 768
# ตั้ง timezone และ locale
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
ถ้าต้องการหลบการตรวจจับขั้นลึกขึ้น ชุมชนมักแนะนำ Camoufox (เบราว์เซอร์ Firefox-based anti-detect ที่มีการ spoof fingerprint ระดับ engine ด้วย C++)
ประสิทธิภาพ: ปานกลาง-สูง | ความซับซ้อน: ปานกลาง | ต้นทุน: ฟรี
ชั้นที่ 3: เก็บ session ให้ต่อเนื่อง
ใช้ user-data-dir เพื่อเก็บคุกกี้และสถานะล็อกอินข้าม session วิธีนี้ช่วยลดสัญญาณ "เบราว์เซอร์ใหม่เอี่ยม" ที่มักไปกระตุ้นระบบ anti-bot
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
ประสิทธิภาพ: ปานกลาง | ความซับซ้อน: ต่ำ | ต้นทุน: ฟรี
ชั้นที่ 4: สลับ proxy
ถ้าจังหวะและ fingerprint ยังไม่พอ ก็ต้องเปลี่ยน IP address ไปเรื่อย ๆ Residential proxy ตรวจจับยากกว่า ส่วน datacenter proxy เร็วและถูกกว่า
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
หมายเหตุ: การตั้งค่า proxy ระดับเบราว์เซอร์ยังเป็นฟีเจอร์ที่ถูกขอเพิ่มอยู่ (GitHub Issue #8079) ตอนนี้ต้องตั้งที่ระดับ OS หรือ environment เท่านั้น
| Provider | Residential | Datacenter | Best For |
|---|---|---|---|
| Bright Data | $4–8.40/GB | $0.43–0.60/GB | องค์กร, คุณภาพสูงสุด |
| Oxylabs | $6–8/GB | $0.48–5/GB | ดึงข้อมูลขนาดใหญ่ |
| Decodo (Smartproxy) | $4–5.50/GB | $0.70–5/GB | งบระดับกลาง |
| IPRoyal | $5–7/GB | -- | คุ้มงบ |
| DataImpulse | $1/GB | -- | ราคาต่ำสุด |
ประสิทธิภาพ: สูง | ความซับซ้อน: ปานกลาง | ต้นทุน: $10–50/เดือน
ชั้นที่ 5: ตัวแก้ CAPTCHA
ตัวเลือกสุดท้าย ลองเชื่อมต่อบริการอย่าง 2captcha หรือ CapSolver
| Service | reCAPTCHA v2 | Cloudflare Turnstile | Latency |
|---|---|---|---|
| 2Captcha | $2.99/1K | $2.99/1K | 15–45 วินาที (ใช้คนแก้) |
| CapSolver | $0.80–1.50/1K | $0.80/1K | 0.5–10 วินาที (AI) |
FlareSolverr (เครื่องมือโอเพนซอร์สสำหรับ bypass Cloudflare) มีเอกสารระบุว่าไม่น่าเชื่อถือในช่วงปี 2025–2026 เพราะการป้องกันของ Cloudflare แข็งแรงขึ้นเรื่อย ๆ
ประสิทธิภาพ: สูง | ความซับซ้อน: สูง | ต้นทุน: $0.80–3/1K ครั้งที่แก้สำเร็จ
ตารางสรุป Anti-Bot
| Technique | Effectiveness | Complexity | Cost |
|---|---|---|---|
| จังหวะเหมือนมนุษย์ | ปานกลาง | ต่ำ | ฟรี |
| เสริม fingerprint | ปานกลาง-สูง | ปานกลาง | ฟรี |
| เก็บ session ต่อเนื่อง | ปานกลาง | ต่ำ | ฟรี |
| สลับ proxy | สูง | ปานกลาง | $10–50/เดือน |
| ตัวแก้ CAPTCHA | สูง | สูง | $0.80–3/1K ครั้งที่แก้สำเร็จ |
สำหรับคนที่ชนกำแพง anti-bot บ่อย ๆ และแค่อยากได้ข้อมูลจริง ๆ: cloud scraping ของ Thunderbit จัดการ anti-bot ให้พร้อมใช้สำหรับเว็บไซต์สาธารณะอยู่แล้ว — ไม่ต้องตั้ง proxy, ไม่ต้องปรับ fingerprint มันเป็นอีกแนวทางหนึ่งโดยสิ้นเชิง (AI อ่านหน้าเว็บแต่ละครั้งผ่าน cloud infrastructure ที่จัดการให้) ซึ่งช่วยเลี่ยงสงคราม anti-bot ทั้งระบบสำหรับงานดึงข้อมูลทั่วไป
ผลลัพธ์จริง: OpenClaw Browser Automation สร้างอะไรได้บ้าง
ก่อนจะทุ่มเวลา 45–75 นาทีไปกับการตั้งค่า คุณคงอยากรู้ว่าปลายทางหน้าตาเป็นยังไง ซึ่งก็สมเหตุสมผล — นี่คือตัวอย่างเวิร์กโฟลว์ 3 แบบพร้อมผลลัพธ์จริง
ตัวอย่างที่ 1: Web Scraping — ดึงข้อมูลสินค้า
Prompt: "เข้าไปที่ https://books.toscrape.com แล้วดึงชื่อและราคาของหนังสือทุกเล่มบนหน้านี้"
Output (5 แถวแรก):
| Title | Price |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
เวลาที่ใช้: ~45 วินาทีสำหรับ 20 แถว (หน้าเดียว) ถ้าจะไล่หลายหน้า ต้องสั่งต่อว่า "กดปุ่ม Next แล้วทำซ้ำอีก 5 หน้า" รวมแล้วได้ประมาณ ~100 แถวในราว 3 นาที
ตัวอย่างที่ 2: Form Automation — กรอกฟอร์มเว็บหลายช่อง
สถานการณ์: กรอกแบบฟอร์มสอบถามซัพพลายเออร์ที่มีชื่อบริษัท, ข้อมูลติดต่อ และความสนใจในสินค้า
agent จะถ่าย snapshot ของฟอร์ม ระบุแต่ละฟิลด์ด้วยเลขอ้างอิง แล้วกรอกทีละช่อง ก่อนกรอก: ช่องว่างทั้งหมด หลังกรอก: ใส่ครบทุกช่องและมีข้อความยืนยันแสดงขึ้นมา เมนูแบบดรอปดาวน์หรือ checkbox ก็จัดการผ่านระบบ snapshot ได้ — agent "มองเห็น" ตัวเลือกแล้วเลือกให้ถูกต้อง
เวลาที่ใช้: ~30 วินาทีสำหรับฟอร์ม 6 ช่อง
ตัวอย่างที่ 3: Pagination — ดึงข้อมูลหลายหน้า
ผลลัพธ์เริ่มต้น: 20 แถวจากหน้า 1 หลังสั่งว่า "กด Next แล้วทำซ้ำทุกหน้า": ได้ 1,000 แถวจาก 50 หน้าใน books.toscrape.com agent จะตรวจจับปุ่ม "Next" ผ่าน snapshot แล้วคลิกวนลูปไปเรื่อย ๆ
เวลาที่ใช้: ~12 นาทีสำหรับ dataset เต็ม 1,000 แถว
เทียบแบบตัวต่อตัว: งาน scrape เดียวกันใน Thunderbit
ถ้าใช้ตัวอย่าง books.toscrape.com เดียวกัน นี่คือ workflow ใน Thunderbit:
- ติดตั้ง Thunderbit Chrome Extension (~30 วินาที)
- เปิดหน้าเว็บ
- คลิก "AI Suggest Fields" → AI ตรวจจับ Title, Price, Availability, Rating
- คลิก "Scrape" → ดึงข้อมูลได้ 20 แถว
- ใช้ pagination controls → ดึงครบทุกหน้า
- ส่งออกไป Google Sheets (ฟรี)
ใช้เวลารวม: ~3 นาที ตั้งแต่เริ่มต้นจนได้ข้อมูลในชีต โดยไม่ต้องมี VPS, ไม่ต้องใช้ CLI, ไม่ต้องตั้งค่าอะไรซับซ้อน
ประเด็นไม่ใช่ว่าเครื่องมือไหน "ดีกว่า" แต่เป็นการเลือกให้เหมาะกับสิ่งที่คุณต้องทำจริง ๆ
ลอง Thunderbit Chrome Extension
เมื่อไหร่ที่ OpenClaw Browser Automation เกินจำเป็น (และควรใช้อะไรแทน)
OpenClaw เหมาะมากกับ automation ที่ซับซ้อน หลายขั้นตอน แบบ agentic — งานที่ต้องล็อกอิน, งานที่เชื่อม browser actions กับ shell commands, หรือรันบน VPS ตลอด 24/7 แต่ถ้าสิ่งที่คุณต้องการคือ "ดึงข้อมูลสินค้าจากหน้ารายการ" หรือ "ดึงอีเมลจากไดเรกทอรี" การยกชุด VPS + Tailscale + node host มาใช้ทั้งหมดก็มักจะหนักเกินความจำเป็น
ฉันเคยเห็นคนใช้เวลาตั้งค่านานกว่า 60 นาทีเพื่อทำงานที่เครื่องมือที่ง่ายกว่าสามารถทำเสร็จใน 2 นาที ไม่คุ้มเลย

เครื่องมือที่ใช่สำหรับงาน: ตารางเปรียบเทียบ
| Factor | OpenClaw Browser Automation | Thunderbit |
|---|---|---|
| เวลาในการตั้งค่า | 45–75 นาที (VPS + Tailscale + node host) | ~2 นาที (ติดตั้ง Chrome extension) |
| ต้องเขียนโค้ดไหม | CLI + prompt ภาษาธรรมชาติ | ไม่ต้องเลย — คลิก "AI Suggest Fields" → "Scrape" |
| การรับมือ anti-bot | ต้องตั้งเอง (proxy, fingerprint config) | มี cloud scraping ในตัว |
| การเข้าเว็บที่ต้องล็อกอิน | ✅ Browser Relay / remote debug | ✅ โหมด browser scraping |
| ดึงข้อมูลจาก subpage | ต้องเขียนสคริปต์เฉพาะแต่ละ workflow | กดครั้งเดียวก็ดึง subpage ได้ |
| งานตั้งเวลา / รัน 24×7 | ใช้ VPS แบบเปิดค้าง | มี scheduled scraper ในตัว |
| ค่าใช้จ่ายรายเดือน | $8–14 (งานเล็ก) ถึง $110–280 (ใช้งานหนัก) | $0 (ฟรีแพ็กเกจ) ถึง $15/เดือน |
| ภาระดูแล | สูง (อัปเดต, VPS, ดีบัก) | แทบไม่มี — AI ปรับตามการเปลี่ยนเลย์เอาต์ได้ |
| เหมาะกับ | เวิร์กโฟลว์ agentic ซับซ้อน, pipeline เฉพาะทาง | ดึงข้อมูล, กรอกฟอร์ม, lead gen, ตรวจราคาคู่แข่ง |
การเลือกตาม use case
- ถ้าคุณต้องการเวิร์กโฟลว์ agentic หลายขั้น ที่เชื่อม browser actions กับ shell commands, แอปแชต, และฐานข้อมูล → OpenClaw คือคำตอบที่เหมาะกว่า
- ถ้าคุณต้องการดึงข้อมูลจากเว็บไซต์, กรอกฟอร์ม, หรือเฝ้าราคาสินค้า โดยไม่ต้องแตะ terminal → Thunderbit จะพาไปถึงเร็วกว่า คุณดู Thunderbit YouTube Channel เพื่อดูเดโมสั้น ๆ ได้
- ถ้าคุณต้องการสคริปต์เบา ๆ สำหรับ endpoint API เดียว → Python script แบบ requests ธรรมดาอาจเพียงพอแล้ว
นี่คือกรอบคิดที่ฉันใช้จริงทุกครั้งที่มีคนในทีมถามว่า "งานนี้ควรใช้เครื่องมือไหน?"
Error ของ OpenClaw Browser Automation ที่พบบ่อย และวิธีแก้
บันทึกส่วนนี้ไว้ได้เลย จัดตามอาการเพื่อให้กด Ctrl+F หาแนวทางแก้ได้เร็ว
"Connection Refused" หรือ Node Host เชื่อมต่อไม่ได้
สาเหตุที่เป็นไปได้ (เช็กตามลำดับ):
- Tailscale ไม่ได้รันบนทั้งสองเครื่อง → รัน
tailscale statusบนทั้งคู่ - Gateway ยังไม่ได้ตั้งให้ฟังบนเครือข่าย Tailscale (ยังอยู่ที่ localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - ใส่ IP ผิด → ตรวจอีกครั้งด้วย
tailscale ip -4 - Firewall บล็อกพอร์ต 18789 →
sudo ufw allow 18789/tcp(Linux) หรือเพิ่ม Windows Firewall rule
Badge ของ Extension ค้างที่ "OFF" หรือไม่เจอแท็บ
- Extension ยังไม่ได้โหลดใน Developer mode → ไปที่
chrome://extensions→ เปิด Developer mode → โหลดใหม่ - Node host ไม่ได้รัน → รีสตาร์ตด้วย
openclaw node start - Chrome instance ชนกัน → ปิด Chrome ทุกหน้าต่าง แล้วเปิดใหม่และรีโหลด extension
Agent คืนค่าข้อมูลว่างหรือข้อมูลผิด
- หน้าเว็บยังโหลดไม่เสร็จ: สั่ง agent ว่า "รอ 3 วินาทีหลังเข้าเว็บก่อนค่อยดึงข้อมูล" SPA หลายเว็บต้องใช้เวลารอให้ render เสร็จ
- โดนบอทบล็อก: เช็กว่าคุณกำลังเห็นหน้า CAPTCHA แทนเนื้อหาจริงหรือไม่ ถ้าใช่ ให้เปลี่ยนจาก Sandbox Chromium ไป Browser Relay
- snapshot เก่า: ขอให้ agent "take a new snapshot" — เลขอ้างอิงจะหมดอายุหลังมีการนำทางไปหน้าใหม่
"Port 9222 Already in Use"
มักเกิดเมื่อ Chrome DevTools หรือ automation tool ตัวอื่นใช้พอร์ตนี้อยู่แล้ว
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
VPS หน่วยความจำเต็ม
browser headless แต่ละ instance ใช้ RAM ราว 400–800 MB ถ้ารันหลายตัวพร้อมกัน VPS ขนาดเล็กอาจล้มได้
วิธีแก้:
- ปิดการโหลดรูป/CSS/font:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - จำกัดจำนวน instance พร้อมกันให้เหมาะกับ RAM
- ตั้ง
shm_size: '2gb'ในคอนฟิก Docker - เปิด session hibernation:
OPENCLAW_HIBERNATE_AFTER=300 - อัปเกรดเป็น VPS RAM 4GB+ ถ้าต้องการเผื่อใช้งานมากขึ้น
ทิปให้ OpenClaw Browser Automation รันได้ลื่น
แนวปฏิบัติที่ฉันเก็บได้จากการดูแลระบบพวกนี้มานาน:
- ปิดการโหลดรูป, stylesheet และ font สำหรับงานดึงข้อมูลอย่างเดียว วิธีนี้ช่วยลดการใช้ทรัพยากรได้เยอะและทำให้เร็วขึ้น
- ใช้ browser instance เดิมซ้ำ แทนการเปิดใหม่ทุกงาน Instance ใหม่กิน RAM มากและกระตุ้นสัญญาณ anti-bot มากกว่า
- เริ่มจาก prompt ง่าย ๆ แล้วค่อยเพิ่มรายละเอียดเมื่อ agent ตีความผิด การอธิบายเยอะเกินไปอาจทำให้ AI งงมากกว่าช่วย
- เฝ้าดูการใช้ทรัพยากรของ VPS (CPU, RAM) และขยายสเปกก่อนจะชนเพดาน การต้องไล่แก้ VPS ล่มตอนตี 2 ไม่สนุกเลย
- อัปเดต OpenClaw และ Chrome extension อยู่เสมอ — แต่ควรทดสอบใน staging ก่อน OpenClaw มี release ประมาณ 13 ครั้งต่อเดือน และไม่ได้ลื่นทุกครั้ง
- สำหรับงานที่ต้องทำซ้ำต่อเนื่อง (เช็กราคาทุกวัน, ดึง lead ทุกสัปดาห์) scheduled scraper ของ Thunderbit's scheduled scraper ให้คุณตั้งรอบเวลาเป็นภาษาธรรมดาแล้วปล่อยทิ้งไว้ได้เลย ไม่ต้องดูแล VPS
ข้อพิจารณาด้านจริยธรรมและกฎหมาย
สั้น ๆ แต่สำคัญ เคารพ robots.txt (ซึ่งถูกกำหนดเป็นมาตรฐาน IETF ใน RFC 9309), จำกัดอัตราการร้องขอ, ตรวจสอบเงื่อนไขการใช้งานของเว็บไซต์เป้าหมาย และจัดการข้อมูลส่วนบุคคลให้สอดคล้องกับ GDPR และกฎหมายความเป็นส่วนตัว คำตัดสิน hiQ v. LinkedIn (2022) ระบุว่าการดึงข้อมูลที่เข้าถึงได้สาธารณะไม่ถือว่าละเมิด CFAA แต่ก็ไม่ได้แปลว่าทำอะไรก็ได้ การใช้ automation อย่างรับผิดชอบจะช่วยปกป้องทั้งคุณและธุรกิจของคุณ ถ้าอยากอ่านต่อ ลองดูคู่มือของเราเกี่ยวกับ ผลทางกฎหมายของ web scraping
สรุปท้ายบท
OpenClaw browser automation เป็นตัวเลือกที่ทรงพลังสำหรับเวิร์กโฟลว์เว็บหลายขั้นตอนที่ซับซ้อนและควบคุมด้วยภาษาธรรมชาติ สิ่งที่สำคัญที่สุดมีอยู่ไม่กี่ข้อ:
- เลือกโหมดเบราว์เซอร์ให้ถูกตั้งแต่แรก (Sandbox, Relay, Remote CDP) — การตัดสินใจข้อนี้ช่วยประหยัดเวลาการดีบักได้มหาศาล
- ผู้ใช้ Windows มีเส้นทางที่ใช้ได้จริง แต่ต้องใช้คำสั่งเฉพาะ Windows และระวัง firewall กับปัญหา path
- การรับมือ anti-bot คือโจทย์จริง — เริ่มจากวิธีที่ง่ายที่สุด (จังหวะ, fingerprint) แล้วค่อยไล่ระดับขึ้นเมื่อจำเป็น
- ดูผลลัพธ์ก่อนตัดสินใจลงทุน ถ้าสิ่งที่คุณต้องการคือข้อมูลโครงสร้างจากหน้ารายการ เครื่องมือ no-code อย่าง Thunderbit จะพาคุณไปถึงในไม่กี่นาทีโดยแทบไม่ต้องดูแลอะไรต่อ
- เผื่องบสำหรับการดูแลรักษาไว้ด้วย OpenClaw มี release ราว 13 ครั้งต่อเดือน ค่า VPS ก็สะสม และการดีบักเป็นส่วนหนึ่งของแพ็กเกจนี้
ถ้าคุณอยากลองเส้นทางที่ง่ายกว่าก่อน Thunderbit มีฟรีแพ็กเกจ — ติดตั้ง extension, ลองดึงข้อมูลจากหน้าเว็บหนึ่งหน้า แล้วดูว่ามันตอบโจทย์คุณไหม ก่อนจะลงทุนกับการตั้งค่า VPS แบบเต็มรูปแบบ ถ้าคุณจะไปทาง OpenClaw จริง ๆ ก็แนะนำให้บันทึกคู่มือนี้ไว้ เพราะคุณอาจต้องกลับมาเปิดดู error catalog สักวัน และขอให้ browser instance ของคุณมี RAM เหลือพอเสมอ
คำถามที่พบบ่อย
OpenClaw Sandbox Chromium กับ Browser Relay ต่างกันอย่างไร?
Sandbox Chromium จะรันเบราว์เซอร์ headless บนเซิร์ฟเวอร์ — เร็วและตั้งค่าง่าย แต่จะสร้างโปรไฟล์ใหม่ทุกครั้ง (ไม่มี session ล็อกอิน) และถูกระบบ anti-bot ตรวจจับได้ง่ายกว่า ส่วน Browser Relay จะส่งคำสั่งไปยัง Chrome จริงบนเครื่อง local ของคุณ จึงรองรับการล็อกอิน ใช้ browser fingerprint จริง และเว็บไซต์จับว่าเป็น automation ได้ยากกว่า ข้อแลกเปลี่ยนคือ Browser Relay ช้ากว่าเพราะต้องวิ่งผ่าน network relay และมีข้อจำกัดบางอย่าง (ไม่มี batch actions, ไม่มี download intercept)
รัน OpenClaw browser automation บน Windows โดยไม่ใช้ WSL ได้ไหม?
ได้ แต่มีข้อควรระวัง เส้นทาง native บน Windows ที่น่าเชื่อถือที่สุดคือ Chrome Remote Debugging ผ่าน PowerShell (chrome.exe --remote-debugging-port=9222) หากไม่เสถียร Docker Desktop ก็เป็นทางสำรอง การรองรับ Node Host แบบ native เต็มรูปแบบบน Windows อาจยังมีจุดสะดุดอยู่บ้าง — ควรดูเอกสารล่าสุดและเตรียมรับมือปัญหาเฉพาะ Windows เช่น firewall บล็อก หรือ path ของ binary ที่ต่างกัน ทุกคำสั่งในส่วน Windows ของคู่มือนี้เป็น PowerShell ไม่ใช่ bash
จัดการ CAPTCHA ใน OpenClaw browser automation อย่างไร?
เริ่มจากลดโอกาสถูกจับให้ได้ก่อน: ใส่จังหวะการทำงานแบบมนุษย์, ทำให้ fingerprint ของเบราว์เซอร์แนบเนียนขึ้น, และใช้ session persistence เพื่อลดสัญญาณว่าเป็นเบราว์เซอร์ใหม่ หาก CAPTCHA ยังโผล่อยู่ ให้เชื่อมบริการแก้ CAPTCHA เช่น 2captcha ($2.99/1K solves) หรือ CapSolver ($0.80–1.50/1K แบบใช้ AI) สำหรับเว็บไซต์สาธารณะที่คุณแค่อยากได้ข้อมูล Thunderbit cloud scraping จะจัดการ anti-bot ให้โดยอัตโนมัติโดยไม่ต้องตั้ง proxy หรือ CAPTCHA config ใด ๆ
OpenClaw browser automation ฟรีจริงไหม?
OpenClaw ตัวซอฟต์แวร์เป็นโอเพนซอร์ส (MIT license) และใช้ฟรี แต่การใช้งานจริงต้องมีโครงสร้างรองรับ เช่น VPS ที่อาจอยู่ราว $4–15/เดือน รวมถึงบริการเสริมอย่าง proxy rotation ($10–50/เดือน) หรือ CAPTCHA solver (จ่ายตามครั้งที่แก้) โดยรวมแล้วค่าใช้จ่ายรายเดือนอาจอยู่ที่ $8–14 สำหรับงานอดิเรก ไปจนถึง $110–280 สำหรับงาน automation หนัก ๆ เทียบกันแล้ว Thunderbit free tier รองรับงานดึงข้อมูลพื้นฐานโดยไม่มีค่าโครงสร้างพื้นฐาน
ถ้า agent ของ OpenClaw คืนค่าผลลัพธ์ว่างตลอด ควรทำอย่างไร?
มี 3 อย่างที่ควรเช็กตามลำดับ: อย่างแรก หน้าเว็บอาจยังโหลดไม่เสร็จ ให้สั่ง agent ว่า "wait 3 seconds after navigating before extracting" อย่างที่สอง คุณอาจชนกำแพง anti-bot — ถ้า agent "เห็น" หน้า CAPTCHA แทนเนื้อหาจริง ให้เปลี่ยนจาก Sandbox Chromium ไป Browser Relay อย่างที่สาม snapshot reference อาจเก่า ให้สั่ง agent "take a new snapshot" หลังการนำทางทุกครั้ง ถ้ายังไม่ได้อีก ให้เช็กการใช้ RAM ของ VPS ด้วย เพราะ browser instance ที่ล้มมักคืนค่าว่างแบบเงียบ ๆ
ลอง Thunderbit เพื่อดึงข้อมูลเว็บได้เร็วขึ้น Get Started Free




