ความเร็วของข่าวดิจิทัลยุคนี้บอกเลยว่า “หมุนตามแทบไม่ทัน” จริง ๆ ทุกนาทีมีพาดหัวข่าวนับพันถูกปล่อย อัปเดต หรือแก้ไขแบบเงียบ ๆ—ตั้งแต่สื่อกระแสหลัก บล็อกเฉพาะทาง ไปจนถึงฟีดโซเชียล ถ้าจะให้เห็นภาพชัด ๆ รับข่าวมากกว่า 4 ล้านบทความต่อวัน ส่วน ติดตามข่าวใน มากกว่า 100 ภาษา และอัปเดตฟีดทั่วโลกทุก ๆ 15 นาที สำหรับคนทำสื่อ นักวิจัย หรือสาย Business Intelligence การพยายามตามข่าวด้วยมือก็เหมือนตักน้ำออกจากเรือที่กำลังจมด้วยแก้วกาแฟใบเดียว
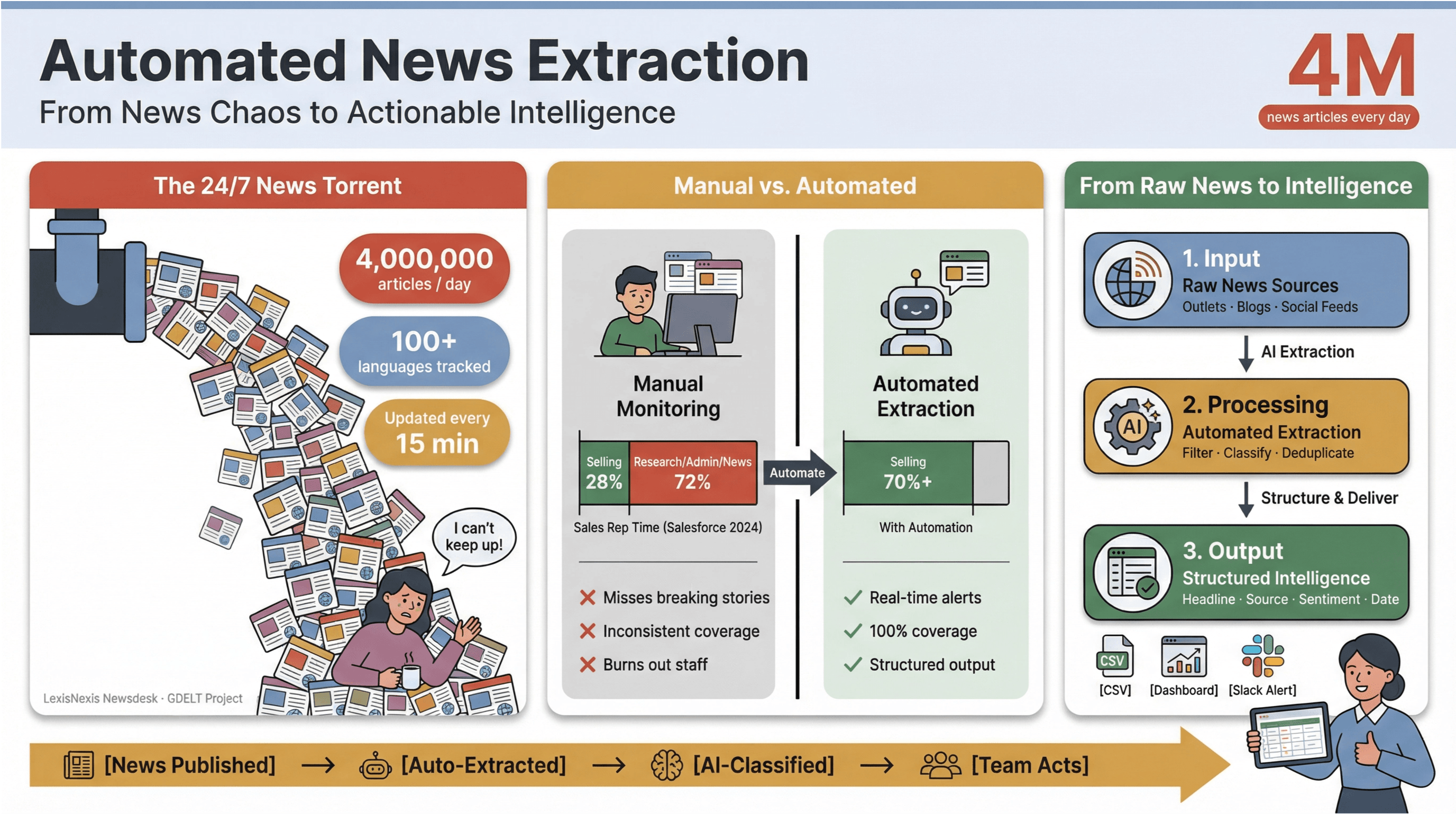
ฉันเห็นกับตาว่าการมอนิเตอร์ข่าวแบบแมนนวลมันกินทั้งเวลาและทรัพยากรขนาดไหน ทีมขายจำนวนมากใช้เวลาน้อยกว่าหนึ่งในสามของสัปดาห์ไปกับการ “ขายจริง ๆ”——เวลาที่เหลือหายไปกับการรีเสิร์ช งานแอดมิน และการสลับแท็บข่าวแบบไม่รู้จบ นี่แหละที่ทำให้การดึงข้อมูลข่าวแบบอัตโนมัติกลายเป็นอาวุธลับของทีมยุคใหม่: มันคือวิธีที่เปลี่ยนความโกลาหลของข่าว 24/7 ให้กลายเป็นอินไซต์ที่เป็นระบบและเอาไปใช้ต่อได้จริง—โดยไม่ทำให้ทีมหมดไฟ และไม่พลาดข่าวสำคัญ
มาดูกันว่า “การดึงข้อมูลข่าวแบบอัตโนมัติ” คืออะไร ทำไมถึงจำเป็นสำหรับคนที่ต้องพึ่งข่าวแบบเรียลไทม์ และจะวางเวิร์กโฟลว์ให้แข็งแรง แถมทำตามข้อกำหนดได้ยังไงด้วยเครื่องมือที่ใช่ (รวมถึงวิธีที่ ทำให้ทุกอย่างง่ายแบบน่าตกใจ—ขนาดคนไม่สายเทคอย่างคุณแม่ของฉันก็ทำได้)
การดึงข้อมูลข่าวแบบอัตโนมัติ: ทำไมถึงจำเป็นสำหรับห้องข่าวยุคใหม่
การดึงข้อมูลข่าวแบบอัตโนมัติคือการใช้ซอฟต์แวร์เพื่อ เก็บเนื้อหาข่าวโดยอัตโนมัติ แล้วแปลงให้อยู่ในรูปข้อมูลที่มีโครงสร้างและค้นหาได้—นึกภาพเป็นตารางแถว/คอลัมน์ แทนหน้าเว็บหรือ PDF ที่ดูรก ๆ ในการใช้งานจริง คุณสามารถเฝ้าดูแหล่งข่าวได้เป็นร้อย (หรือเป็นพัน) ดึงฟิลด์สำคัญอย่างพาดหัว เวลา ผู้เขียน และเนื้อหาบทความ แล้วส่งต่อไปยังแดชบอร์ด ระบบแจ้งเตือน หรือขั้นวิเคราะห์ถัดไป—โดยไม่ต้องแตะ Ctrl+C/Ctrl+V เลย
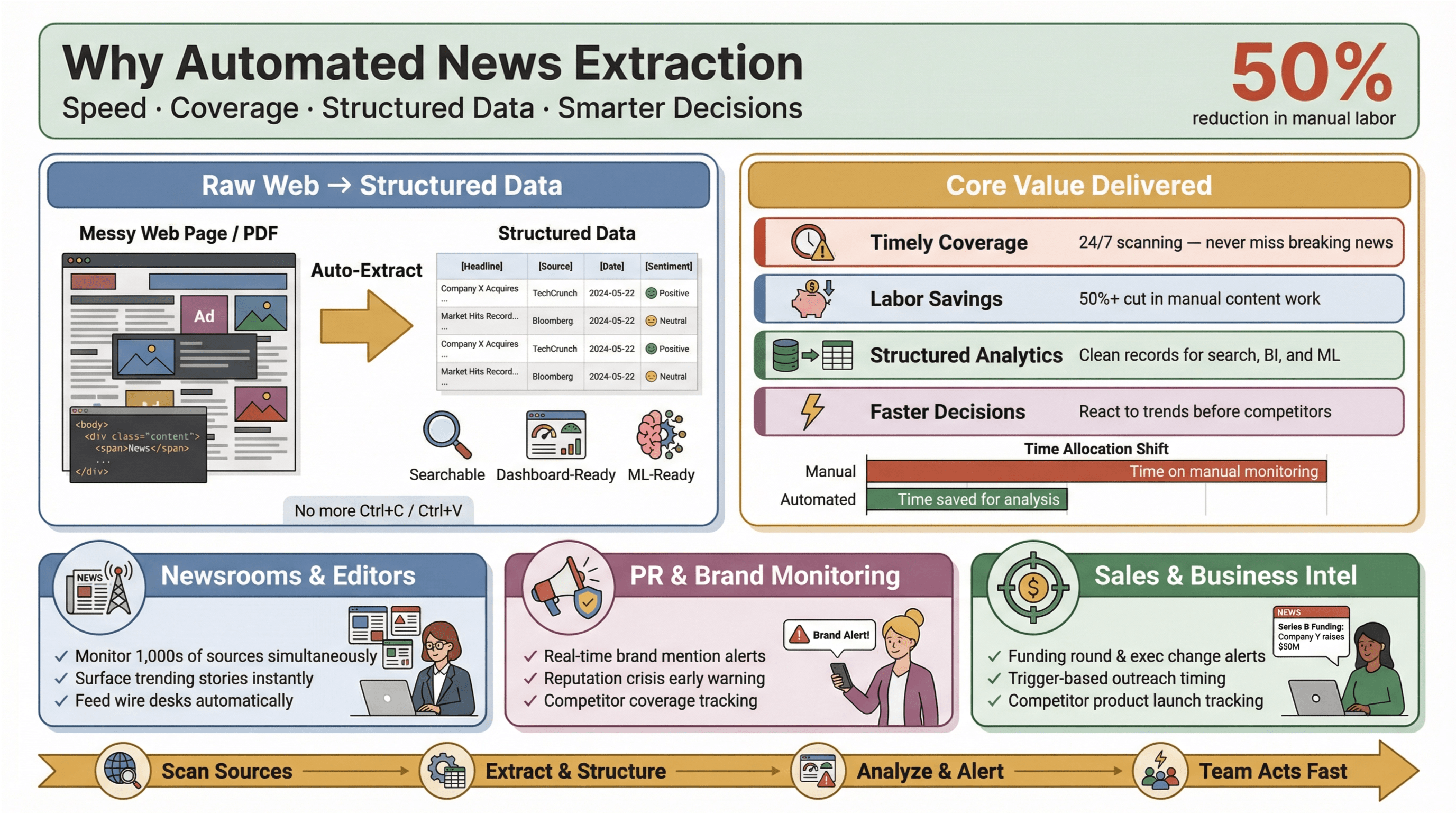 ทำไมเรื่องนี้ถึงสำคัญ? เพราะในโลกข่าววันนี้ ความเร็วคือทุกอย่าง ไม่ว่าคุณจะเป็นบรรณาธิการ PR ที่ต้องจับตาการกล่าวถึงแบรนด์ หรือแอนะลิสต์ที่ตามความเคลื่อนไหวคู่แข่ง การรู้ก่อนอาจหมายถึงคว้าโอกาสได้ทัน vs. ต้องมานั่งไล่ตามทีหลัง เครื่องมือดึงข้อมูลอัตโนมัติช่วยให้ทีมเล็กทำงานได้ “เกินตัว”—เก็บข้อมูลข่าวแบบเรียลไทม์จากทั่วเว็บ ลดงานมือ และดันข่าวที่สำคัญขึ้นมาให้เห็นก่อน
ทำไมเรื่องนี้ถึงสำคัญ? เพราะในโลกข่าววันนี้ ความเร็วคือทุกอย่าง ไม่ว่าคุณจะเป็นบรรณาธิการ PR ที่ต้องจับตาการกล่าวถึงแบรนด์ หรือแอนะลิสต์ที่ตามความเคลื่อนไหวคู่แข่ง การรู้ก่อนอาจหมายถึงคว้าโอกาสได้ทัน vs. ต้องมานั่งไล่ตามทีหลัง เครื่องมือดึงข้อมูลอัตโนมัติช่วยให้ทีมเล็กทำงานได้ “เกินตัว”—เก็บข้อมูลข่าวแบบเรียลไทม์จากทั่วเว็บ ลดงานมือ และดันข่าวที่สำคัญขึ้นมาให้เห็นก่อน
ผลลัพธ์ที่จับต้องได้: งานวิจัยหลายชิ้นชี้ว่าออโตเมชันช่วยลดแรงงานแมนนวลในการอัปเดตคอนเทนต์ได้ อย่างน้อย 50% ทำให้มีเวลามากขึ้นสำหรับการวิเคราะห์และการตัดสินใจจริง ๆ
คุณค่าหลักของการดึงข้อมูลข่าวแบบอัตโนมัติในอุตสาหกรรมข่าว
มาพูดแบบใช้งานจริงกันเลยว่า การดึงข้อมูลข่าวแบบอัตโนมัติช่วยห้องข่าวและทีมธุรกิจได้อะไรบ้าง?
- ครอบคลุมและทันเวลา: ไม่ต้องพลาดข่าวด่วนเพราะลืมเช็กฟีด เครื่องมืออัตโนมัติสแกนแหล่งข่าวตลอด 24/7
- ประหยัดแรงและต้นทุน: ทีมเล็ก/กลางติดตามแหล่งข่าวได้เทียบเท่าทีมใหญ่ โดยไม่ต้องจ้างอินเทิร์นเป็นกอง
- ข้อมูลเป็นโครงสร้างพร้อมวิเคราะห์: แทนที่จะไล่อ่านบทความที่ไม่เป็นระเบียบ คุณได้เรคคอร์ดที่สะอาด พร้อมค้นหา ทำแดชบอร์ด และทำแมชชีนเลิร์นนิง
- ตัดสินใจไวและฉลาดขึ้น: ข่าวเรียลไทม์ช่วยให้ตอบสนองต่อการเปลี่ยนแปลงตลาด วิกฤต PR หรือเทรนด์ใหม่ได้ก่อนคู่แข่ง
ในสาย PR/สื่อสารองค์กร แพลตฟอร์มอย่าง และ วางตำแหน่งการมอนิเตอร์สื่อแบบเรียลไทม์ว่าเป็นสิ่งจำเป็นต่อการปกป้องชื่อเสียงและการรับมือข่าวลบอย่างรวดเร็ว ส่วนในงานขาย การแจ้งเตือนข่าวแบบเรียลไทม์กลายเป็น “การ์ดบริบท” สำหรับการหาลูกค้า—เช่น ข่าวระดมทุน เปลี่ยนผู้บริหาร หรือเปิดตัวสินค้า ที่เป็นสัญญาณให้ทักไปได้ถูกจังหวะ
เลือกเครื่องมือสแครปข่าวให้เหมาะกับแต่ละสถานการณ์
เครื่องมือสแครปข่าวไม่ได้เหมือนกันทั้งหมด ตัวเลือกที่เหมาะจะขึ้นอยู่กับเป้าหมาย ความถนัดด้านเทคนิค และประเภทข่าวที่คุณสนใจ นี่คือกรอบคิดช่วยเลือกให้ตรงงาน:
ประเมินความง่ายในการใช้งานและการเข้าถึง
สำหรับผู้ใช้สายธุรกิจและนักข่าวส่วนใหญ่ ใช้งานง่ายคือเงื่อนไขที่ต่อรองไม่ได้ คุณต้องการเครื่องมือที่เปิดแล้วใช้งานได้เลย ไม่ต้องเขียนโค้ดหรือเซ็ตอัปให้ปวดหัว แพลตฟอร์มแบบ no-code/low-code อย่าง , และ ช่วยให้สร้างสแครปเปอร์แบบภาพได้—ชี้ คลิก แล้วดึงข้อมูล
โดยเฉพาะ Thunderbit เด่นด้วย ขั้นตอนแค่สองสเต็ป: บอกว่าต้องการข้อมูลอะไร ให้ AI แนะนำฟิลด์ แล้วกด “Scrape” ผู้ใช้ที่ไม่ใช่สายเทคก็ทำท่อข้อมูลข่าวได้ในไม่กี่นาที ไม่ใช่หลายชั่วโมง
ข้อพิจารณาด้านความปลอดภัยและความเป็นส่วนตัวของข้อมูล
ข้อมูลยิ่งเยอะ ความรับผิดชอบก็ยิ่งต้องแน่น เครื่องมือสแครปข่าวอาจไปแตะคอนเทนต์ที่อ่อนไหวได้ ดังนั้น ความปลอดภัยและการทำตามข้อกำหนด ต้องมาก่อน มองหาประเด็นเหล่านี้:
- การเข้ารหัสข้อมูล (ระหว่างส่งและขณะจัดเก็บ)
- นโยบายความเป็นส่วนตัวที่ชัดเจน (เช่น Thunderbit ระบุว่าไม่ขายข้อมูลผู้ใช้ และเข้าถึงเฉพาะคอนเทนต์ที่คุณเลือกให้สแครป)
- สิทธิ์การเข้าถึงแบบละเอียด (โดยเฉพาะส่วนขยายเบราว์เซอร์—ควรเช็กว่าเข้าถึงข้อมูลอะไรได้บ้าง)
- สอดคล้องกฎหมายท้องถิ่น (GDPR, CCPA และสำหรับผู้ใช้ EU รวมถึง )
เพื่อความสบายใจ เลือกผู้ให้บริการที่น่าเชื่อถือ ตรวจสิทธิ์ของส่วนขยาย และจำกัดการเข้าถึงเท่าที่จำเป็น
จับคู่เครื่องมือให้เหมาะกับประเภทข่าวและความต้องการของอุตสาหกรรม
บางเครื่องมือจะเหมาะกับโดเมนข่าวเฉพาะทางเป็นพิเศษ:
- การเงิน: API อย่าง และ มีฟีเจอร์จัดกลุ่ม วิเคราะห์อารมณ์ และตรวจจับเหตุการณ์สำหรับข่าวการเงิน
- เทค & สตาร์ทอัป: สแครปแบบปรับแต่งด้วย Thunderbit หรือ Octoparse ช่วยเล็งบล็อกเฉพาะทาง ข่าวประชาสัมพันธ์ หรือรายการอีเวนต์
- การเมือง & นโยบาย: ฐานข้อมูลแบบมีไลเซนส์อย่าง และ ให้เข้าถึงแหล่งพรีเมียมและคลังย้อนหลัง
ถ้าต้องมอนิเตอร์ทั้งสื่อกระแสหลัก แหล่งเฉพาะทาง และต่างประเทศ—รวมถึงเว็บที่ไม่มี API—สแครปเปอร์แบบยืดหยุ่นที่ขับเคลื่อนด้วย AI อย่าง Thunderbit มักตอบโจทย์ที่สุด
จุดเด่นเฉพาะของ Thunderbit สำหรับการดึงข้อมูลข่าวแบบเรียลไทม์
ต่อไปมาดูกันว่าอะไรทำให้ เป็นตัวเลือกที่เด่นสำหรับการดึงข้อมูลข่าวแบบอัตโนมัติ—โดยเฉพาะถ้าคุณต้องการ ข้อมูลข่าวแบบเรียลไทม์ โดยไม่ต้องปวดหัวเรื่องเทคนิค
Thunderbit คือ AI Web Scraper ส่วนขยาย Chrome ที่ทำมาเพื่อผู้ใช้สายธุรกิจ นักข่าว และนักวิเคราะห์ที่อยากได้คอนเทนต์ข่าวที่อัปเดตและเป็นโครงสร้างจากเว็บไหนก็ได้ นี่คือเหตุผลที่ฉันใช้เป็นตัวหลัก:
- AI Suggest Fields: Thunderbit อ่านหน้าเว็บข่าวแล้วแนะนำคอลัมน์ที่ควรดึงให้อัตโนมัติ—พาดหัว เวลา ผู้เขียน สรุป และอื่น ๆ ไม่ต้องมานั่งปรับ selector หรือทำเทมเพลต
- Subpage Scraping: อยากได้เนื้อหาทั้งบทความ ไม่ใช่แค่พาดหัว? Thunderbit เข้าไปที่ลิงก์ข่าวแต่ละอัน ดึงเนื้อหา เอนทิตี และแท็ก แล้วรวมเป็นตารางเดียวแบบเป็นระบบ
- ส่งออกจำนวนมาก & อัปเดตทันที: ส่งออกข้อมูลข่าวไป Excel, Google Sheets, Airtable หรือ Notion ได้ในคลิกเดียว จบปัญหาคัดลอกวางหรือจัดการ CSV
- Scheduled Scraping: ตั้งงานให้รันซ้ำ (รายชั่วโมง รายวัน หรือกำหนดเอง) เพื่อให้ท่อข้อมูลข่าวสดเสมอ เหมาะกับข่าวด่วน มอนิเตอร์ตลาด หรือรีเสิร์ชต่อเนื่อง
- ปรับตัวเก่ง: AI ของ Thunderbit ปรับตามการเปลี่ยนเลย์เอาต์และเว็บข่าวหางยาวได้ดี ลดเวลาซ่อมสแครปเปอร์ที่พัง แล้วเอาเวลาไปวิเคราะห์แทน
ด้วยผู้ใช้มากกว่า และเรตติ้ง 4.8 ดาว จึงเป็นเครื่องมือที่ทีมทั่วโลกไว้ใจ ตั้งแต่ PR monitoring ไปจนถึง competitive intelligence
การตรวจจับฟิลด์ด้วย AI และการสแครปหน้าเนื้อหาย่อย
หนึ่งในฟีเจอร์ที่เด่นมากของ Thunderbit คือ การตรวจจับฟิลด์ด้วย AI แค่กด “AI Suggest Fields” เครื่องมือจะสแกนหน้าเว็บข่าวและระบุฟิลด์สำคัญอย่างชื่อเรื่อง วันที่ ผู้เขียน และสรุป คุณยังปรับแต่งหรือเพิ่มฟิลด์เองได้ (เช่น “ติดแท็กบทความนี้ว่า ‘earnings’ ถ้ามีคำว่าผลประกอบการรายไตรมาส”) แล้วให้ AI จัดการต่อ
สำหรับงานข่าว Subpage scraping คือจุดเปลี่ยน: สแครปหน้าโฮมหรือหน้าหมวดเพื่อเก็บพาดหัว จากนั้นให้ Thunderbit เข้าไปที่ URL ของแต่ละบทความเพื่อดึงเนื้อหาเต็ม เอนทิตี และแม้แต่รูปภาพ ผลลัพธ์คือ เรคคอร์ดข่าวที่ครบและเสริมข้อมูลแล้ว พร้อมใช้กับการค้นหา แดชบอร์ด หรือการวิเคราะห์ด้วย AI ขั้นต่อไป
ส่งออกจำนวนมากและอัปเดตทันที
Thunderbit ทำให้การส่งออกข้อมูลข่าวไม่ยุ่งยาก คลิกเดียวก็ส่งฟีดข่าวแบบมีโครงสร้างไป Google Sheets, Airtable, Notion หรือดาวน์โหลดเป็น CSV/Excel ได้ สำหรับทีมที่ทำงานบนสเปรดชีตหรือ BI เป็นหลัก นี่คือการประหยัดเวลาครั้งใหญ่
และเพราะ Thunderbit รองรับ Scheduled Scraping คุณตั้งให้รันทุกชั่วโมง ทุกวัน หรือกำหนดเองได้ ทำให้ข้อมูลข่าวอัปเดตตลอด ไม่ต้องรอ Google Alerts ที่บางทีอินเด็กซ์ช้าหลายวัน
รับมือความท้าทายเชิงปฏิบัติการของโซลูชันข่าวแบบเรียลไทม์
ถึงจะมีเครื่องมือดีแค่ไหน การดึงข่าวแบบเรียลไทม์ก็มีโจทย์เฉพาะตัวอยู่ดี นี่คือวิธีรับมือเรื่องที่เจอบ่อย:
จัดการความหน่วงและความสดของข้อมูล
- ตั้งตารางสแครปตามความเร็วของข่าว: ข่าวด่วนให้รันทุก 15–30 นาที (ให้สอดคล้องกับ ) ส่วนหมวดที่ช้ากว่าอาจพอแค่รายวันหรือรายชั่วโมง
- ติดตามเวลาหน่วงระหว่างเผยแพร่กับเวลาที่ดึงได้: วัดส่วนต่างระหว่างเวลาที่บทความถูกเผยแพร่กับเวลาที่ระบบดึงมา หากหน่วงมากขึ้นให้ตรวจการบล็อกหรือความช้า
- สแครปซ้ำเพื่อจับ “การแก้ไขเงียบ”: ข่าวมักถูกแก้หลังเผยแพร่ ตั้งสแครปรอบสองหลัง 24 ชั่วโมงเพื่อจับการแก้ไขหรือปรับคำแบบไม่ประกาศ ()
จัดการข้อจำกัด API และความหลากหลายของแหล่งข่าว
- เคารพโควตา API: หากใช้ news API ให้ระวัง rate limit กระจายคำขอตามเวลา และแคชผลลัพธ์เมื่อทำได้ ()
- ตัดข้อมูลซ้ำและทำ canonical: ข่าวเดียวกันอาจมีหลาย URL หรือถูกอัปเดต เก็บ canonical URL และใช้แฮช (เช่น ชื่อเรื่อง + วันที่) เพื่อกันข้อมูลซ้ำ ()
- รับมือคอนเทนต์ไดนามิก: เว็บที่มี infinite scroll หรือ lazy loading ควรใช้เครื่องมือที่เรนเดอร์ไดนามิกได้ และเฝ้าดูการเปลี่ยนเลย์เอาต์ ()
วิเคราะห์ข้อมูลข่าวอย่างชาญฉลาด: บทบาทของ AI และ Machine Learning
การดึงข่าวเป็นแค่ก้าวแรก คุณค่าจริงอยู่ที่ การวิเคราะห์และลงมือทำจากข้อมูลนั้น—และนี่คือจุดที่ AI/แมชชีนเลิร์นนิงโชว์ของ
- ดึงเอนทิตี: ใช้ NLP เพื่อดึงชื่อคน องค์กร และสถานที่ที่ถูกกล่าวถึงในบทความ ()
- จัดหมวดหมู่หัวข้อ: ติดแท็กบทความตามหัวข้อ อารมณ์ หรือความเร่งด่วนอัตโนมัติ เพื่อทำแดชบอร์ด/แจ้งเตือนที่ฉลาดขึ้น ()
- จัดกลุ่มเหตุการณ์: รวมข่าวซ้ำหรือข่าวที่เกี่ยวข้องจากหลายสำนัก เพื่อเห็นภาพรวม ไม่ใช่แค่พาดหัวคล้าย ๆ กันถาโถม
- ทำ personalization และการยิงเป้าหมาย: ใช้ข่าวเรียลไทม์เพื่อแบ่งกลุ่มผู้ชม ปรับการยิงโฆษณา หรือแนะนำคอนเทนต์ เพิ่ม engagement และ ROI
ตัวอย่างเช่น ทีม PR ใช้การวิเคราะห์ข่าวเรียลไทม์เพื่อจับสัญญาณวิกฤตก่อนลุกลาม ส่วนทีมขายใช้ข่าวเป็น “trigger event” อย่างการระดมทุนหรือการจ้างผู้บริหาร เพื่อเสริมข้อมูลรายชื่อเป้าหมาย
เช็กลิสต์แนวทางปฏิบัติที่ดีที่สุดสำหรับการดึงข้อมูลข่าวแบบอัตโนมัติ
นี่คือเช็กลิสต์แบบดูเร็วเพื่อให้ท่อข้อมูลข่าวของคุณทำงานลื่น ๆ:
| แนวทางปฏิบัติที่ดีที่สุด | ทำไมถึงสำคัญ | วิธีนำไปใช้ |
|---|---|---|
| ตั้งสแครปให้ถี่พอ | ลดความหน่วง จับข่าวด่วนได้ทัน | ปรับความถี่ตามความเร็วของข่าว (เช่น ทุก 15 นาทีสำหรับหมวดที่เร็ว) |
| ใช้การดึงข้อมูลด้วย AI | ปรับตัวตามเลย์เอาต์ ลดเวลาตั้งค่า | เครื่องมืออย่าง Thunderbit, Diffbot, Zyte API |
| ตัดข้อมูลซ้ำและทำ canonical | ลดการแจ้งเตือนซ้ำ ทำข้อมูลสะอาด | เก็บ canonical URL และใช้แฮชเพื่อตัดซ้ำ |
| เฝ้าดูคุณภาพการดึงข้อมูล | จับฟิลด์หาย/ดริฟต์/ล้มเหลว | ติดตาม % เรคคอร์ดที่ครบ เวลาหน่วง และอัตรา error |
| เคารพขอบเขตกฎหมาย/คอมพลายแอนซ์ | ลดความเสี่ยงทางกฎหมาย รักษาความน่าเชื่อถือ | ใช้ API/ฟีดทางการ ตรวจเงื่อนไข ลดข้อมูลส่วนบุคคล |
| ส่งออกเป็นรูปแบบมีโครงสร้าง | ทำให้วิเคราะห์ต่อได้ง่าย | CSV, Excel, Sheets, Notion, Airtable |
| ตั้งสแครปซ้ำเพื่อจับการแก้ไข | จับการเปลี่ยนหลังเผยแพร่ | กลับไปดึงซ้ำหลัง 24 ชม./1 สัปดาห์ (โมเดล GDELT) |
| ทำให้ท่อข้อมูลปลอดภัย | ปกป้องข้อมูลอ่อนไหว | เข้ารหัส ควบคุมสิทธิ์ เลือกเครื่องมือที่น่าเชื่อถือ |
สร้างเวิร์กโฟลว์การดึงข้อมูลข่าวแบบอัตโนมัติให้แข็งแรง
พร้อมทำ “กล่องดำ” สำหรับข้อมูลข่าวของคุณแล้วหรือยัง? นี่คือเวิร์กโฟลว์แบบทีละสเต็ป:
- ระบุแหล่งข่าว: ลิสต์เว็บข่าว บล็อก หรือ API ที่ต้องการติดตาม
- ตั้งค่าการดึงข้อมูล: ใช้ Thunderbit หรือเครื่องมือที่เลือกเพื่อกำหนดฟิลด์ (AI Suggest Fields ช่วยให้เร็วมาก)
- ตั้งตารางสแครป: ปรับความถี่ตามความเร็วของข่าว—รายชั่วโมงสำหรับข่าวด่วน รายวันสำหรับหมวดช้ากว่า
- เสริมข้อมูลจากหน้าบทความ: สำหรับแต่ละพาดหัว ให้ดึงบทความเต็มเพื่อเก็บเนื้อหา เอนทิตี และแท็ก
- ตัดซ้ำและทำให้เป็นมาตรฐาน: เก็บ canonical URL ทำแฮชเรคคอร์ด และทำฟิลด์ให้เป็นรูปแบบเดียวกัน
- ส่งออกและเชื่อมต่อ: ส่งข้อมูลแบบมีโครงสร้างไป Excel, Google Sheets, Airtable หรือ Notion เพื่อวิเคราะห์
- มอนิเตอร์และปรับตัว: ติดตามคุณภาพการดึงข้อมูล เฝ้าดูการเปลี่ยนเลย์เอาต์ และปรับเมื่อจำเป็น
- ทำตามข้อกำหนด: ตรวจเงื่อนไข เคารพ robots.txt และลดการเก็บข้อมูลส่วนบุคคล
ถ้าคิดเป็นภาพ:
Sources → Extraction (AI fields) → Subpage enrichment → Deduplication → Export → Analysis/Alerts → Monitoring
สรุปและประเด็นสำคัญ
การดึงข้อมูลข่าวแบบอัตโนมัติไม่ใช่แค่ “มีก็ดี” อีกต่อไป—แต่เป็นของจำเป็นสำหรับคนที่ต้องนำหน้าในโลกที่ข่าวเกิด (และเปลี่ยน) ทุกนาที เมื่อทำตามแนวทางที่ดีและเลือกเครื่องมือให้เหมาะ คุณจะเปลี่ยนสายน้ำข่าวดิจิทัลที่ไหลแรงให้กลายเป็นข้อมูลเชิงลึกที่เป็นระบบและนำไปใช้ได้จริง
สรุปประเด็นสำคัญ:
- ปริมาณและความเร็วของข่าวออนไลน์บังคับให้ต้องใช้ออโตเมชัน—ทำมือไม่ทันแน่นอน
- เครื่องมือดึงข่าวอัตโนมัติช่วยประหยัดเวลา ลดต้นทุน และทำให้ทีมเล็กครอบคลุมได้ใกล้เคียงองค์กรใหญ่
- การเลือกเครื่องมือที่ใช่คือการบาลานซ์ระหว่างความง่าย ความปลอดภัย และความยืดหยุ่น—Thunderbit เด่นด้วยความง่ายแบบ AI และตัวเลือกส่งออกแบบเรียลไทม์
- ออกแบบเวิร์กโฟลว์โดยยึดความสด การตัดซ้ำ คอมพลายแอนซ์ และการมอนิเตอร์คุณภาพ เพื่อให้ข้อมูลเชื่อถือได้และนำไปใช้ได้
- AI และแมชชีนเลิร์นนิงเพิ่มมูลค่าได้อีกมาก—ทั้งการยิงเป้าหมาย การทำ personalization และการตัดสินใจที่ดีขึ้น
ถ้าคุณยังคัดลอกพาดหัวทีละอัน หรือรอ Google Alerts ที่ตามไม่ทัน ถึงเวลายกระดับแล้ว แล้วจะเห็นว่าการดึงข่าวอัตโนมัติมันง่ายแค่ไหน สำหรับทิปส์ เวิร์กโฟลว์ และบทความเชิงลึกเพิ่มเติม ไปที่
คำถามที่พบบ่อย (FAQs)
1. การดึงข้อมูลข่าวแบบอัตโนมัติคืออะไร และทำงานอย่างไร?
การดึงข้อมูลข่าวแบบอัตโนมัติคือการใช้ซอฟต์แวร์เก็บบทความข่าวและแปลงเป็นข้อมูลแบบมีโครงสร้าง (เช่น ตารางหรือ JSON) เพื่อใช้วิเคราะห์ ค้นหา หรือทำระบบแจ้งเตือน เครื่องมืออย่าง Thunderbit ใช้ AI เพื่อระบุฟิลด์สำคัญ (พาดหัว เวลา ผู้เขียน เนื้อหา) และดึงจากหน้าเว็บหรือ API ให้อัตโนมัติ
2. ทำไมข้อมูลข่าวแบบเรียลไทม์ถึงสำคัญกับธุรกิจ?
ข่าวแบบเรียลไทม์ช่วยให้ธุรกิจตอบสนองต่อเหตุการณ์ตลาด วิกฤต PR หรือความเคลื่อนไหวคู่แข่งได้รวดเร็ว ไม่ว่าคุณอยู่สายขาย PR หรือวิจัย ข่าวที่อัปเดตทำให้ตัดสินใจได้ไวและแม่นขึ้น และนำหน้าคู่แข่ง
3. Thunderbit ทำให้การสแครปข่าวง่ายขึ้นสำหรับคนไม่สายเทคอย่างไร?
Thunderbit มีขั้นตอนง่าย ๆ แค่สองสเต็ป: บอกว่าต้องการข้อมูลอะไร แล้วให้ AI แนะนำฟิลด์ ด้วยฟีเจอร์อย่าง subpage scraping และการส่งออกทันทีไป Excel หรือ Google Sheets คนไม่สายเทคก็สร้างท่อข้อมูลข่าวที่แข็งแรงได้ภายในไม่กี่นาที
4. ข้อกฎหมายและคอมพลายแอนซ์ที่ควรคำนึงถึงในการสแครปข่าวมีอะไรบ้าง?
ควรอ่านเงื่อนไขการใช้งานของเว็บไซต์เป้าหมาย เลือกใช้ API/ฟีดทางการเมื่อมี และเคารพคำสั่ง robots.txt หลีกเลี่ยงการสแครปคอนเทนต์ที่ต้องล็อกอินหรืออยู่หลังเพย์วอลล์โดยไม่มีสิทธิ์ และลดการเก็บข้อมูลส่วนบุคคลเพื่อให้สอดคล้องกฎหมายความเป็นส่วนตัว
5. ทำอย่างไรให้เวิร์กโฟลว์ดึงข่าวเชื่อถือได้ในระยะยาว?
ตั้งสแครปเป็นประจำ มอนิเตอร์คุณภาพการดึงข้อมูล และใช้เครื่องมือที่ปรับตัวตามการเปลี่ยนเลย์เอาต์ได้ (เช่นการดึงด้วย AI ของ Thunderbit) ตัดข้อมูลซ้ำ ติดตามเวลาหน่วงระหว่างเผยแพร่กับการดึง และตั้งแจ้งเตือนเมื่อเกิดความล้มเหลวหรือฟิลด์หาย เพื่อให้ระบบแข็งแรงและอัปเดตเสมอ
อ่านเพิ่มเติม