

ไม่กี่เดือนก่อน ผู้ใช้คนหนึ่งของเราถามคำถามที่ทำให้ผมชะงักกลางจิบกาแฟ: "ถ้าผมดึงราคาสินค้าสาธารณะจาก Coupang จะโดนฟ้องในศาลเกาหลีไหม?" พูดตรง ๆ คือ ผมก็ไม่ได้มีคำตอบสั้น ๆ ที่มั่นใจนัก — และคู่มือกฎหมายออนไลน์ที่ผมหาเจอส่วนใหญ่ก็ไม่ต่างกัน
คำถามนี้ติดอยู่ในใจผม เพราะมันเป็นคำถามเดียวกับที่ผู้ประกอบการอีคอมเมิร์ซ ทีมขาย และผู้ก่อตั้ง SaaS หลายพันคนแอบค้นหาใน Google ทุกสัปดาห์ ตลาดบริการดึงข้อมูลเว็บทั่วโลกมีมูลค่าราว 1.03 พันล้านดอลลาร์สหรัฐในปี 2024 และเติบโตเร็วมาก ธุรกิจที่เก็บข้อมูลจากเว็บมีมากขึ้นกว่าเดิม — และยิ่งมีมากขึ้นเท่าไร ก็ยิ่งมีคนตั้งคำถามว่าเส้นแบ่งทางกฎหมายในเกาหลีอยู่ตรงไหน เกาหลีไม่ได้ห้ามการดึงข้อมูลเว็บแบบเหมารวม
แต่มี 4 กฎหมายหลักที่อาจเกี่ยวข้อง ขึ้นอยู่กับว่าคุณดึงข้อมูลอะไร ดึงอย่างไร และดึงไปทำอะไร คดีสำคัญที่ทุกคนอ้างถึงคือคำพิพากษาศาลฎีกาเกาหลีในคดี Yanolja (2021Do1533 ตัดสินเมื่อ 12 พฤษภาคม 2022) ซึ่งยกฟ้องเครื่องมือดึงข้อมูลของคู่แข่งในคดีอาญา — แต่ในคดีแพ่งอีกเส้นทางหนึ่ง กลับสั่งให้บริษัทเดียวกันชดใช้ค่าเสียหายราว 1,000 ล้านวอน นี่แหละคือประเด็นสำคัญที่สุดที่คนที่ไม่ใช่นักกฎหมายต้องเข้าใจเกี่ยวกับกฎหมายการดึงข้อมูลเว็บของเกาหลี และเป็นแกนหลักของคู่มือนี้ ไม่ต้องจบกฎหมายก็อ่านและใช้งานได้ — แค่มีกรอบประเมินความเสี่ยงแบบลงมือใช้จริง
ระดับความยาก: มือใหม่ (ไม่จำเป็นต้องมีพื้นฐานกฎหมายหรือเทคนิค)
เวลาที่ต้องใช้: อ่านประมาณ 15 นาที; ใช้อ้างอิงต่อเนื่องได้
สิ่งที่ควรรู้ก่อน: เข้าใจพื้นฐานว่าการดึงข้อมูลเว็บทำอะไรได้บ้าง (ถ้าต้องการทบทวน ดูบทความของเราเรื่อง การดึงข้อมูลเว็บคืออะไร)
การดึงข้อมูลเว็บในเกาหลีถูกกฎหมายหรือไม่? คำตอบสั้น ๆ
การดึงข้อมูลเว็บไม่ได้ผิดกฎหมายในเกาหลีโดยตัวมันเอง มันเป็นเทคโนโลยีที่เป็นกลาง — เหมือนเว็บเบราว์เซอร์หรือสูตรในสเปรดชีต ศาลเกาหลีให้ความสำคัญไม่ใช่ที่เครื่องมือ แต่ที่พฤติการณ์รอบการใช้งาน
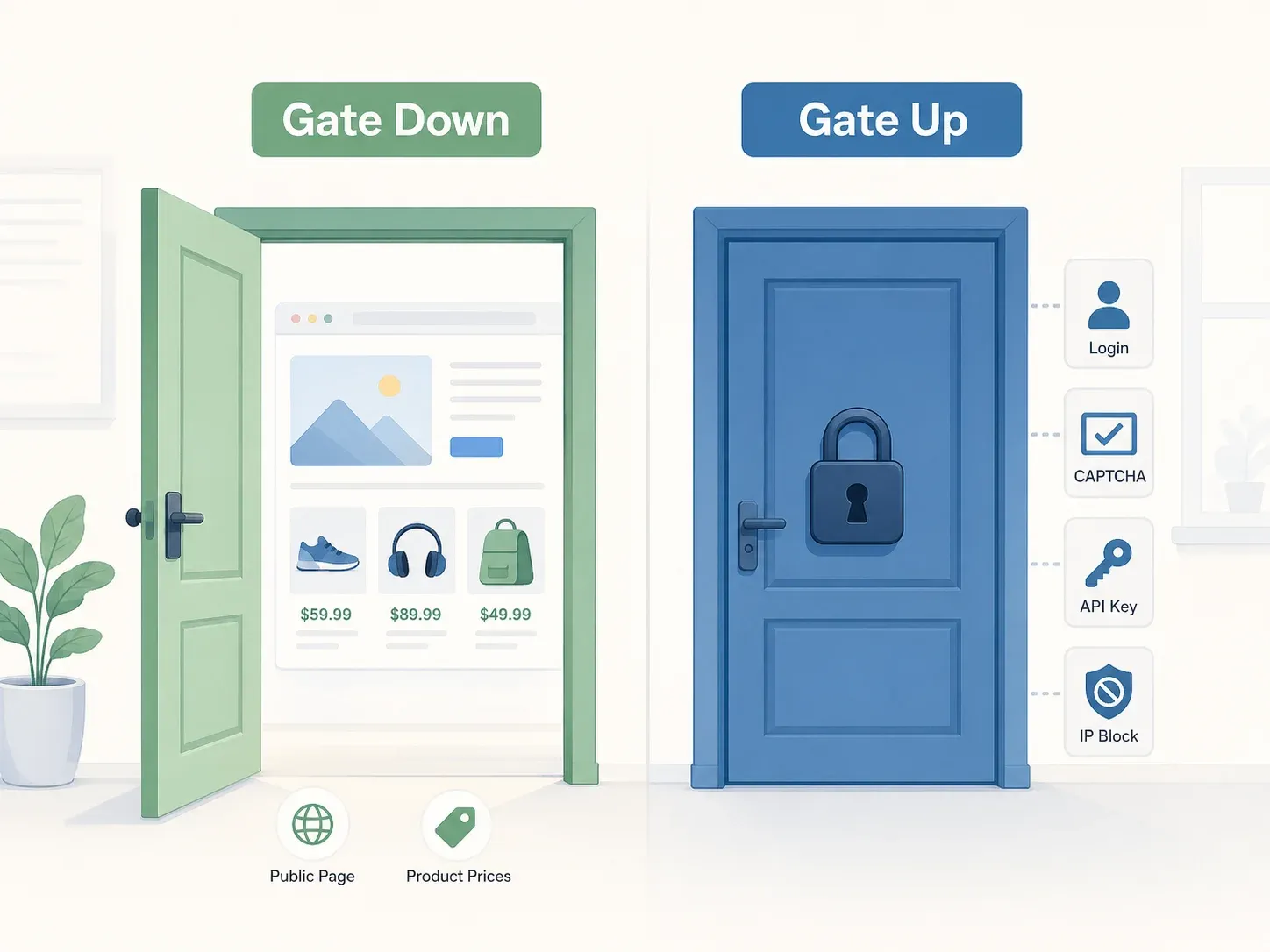
กรอบความคิดที่ดีที่สุดมาจากคำพิพากษาศาลฎีกาในคดี Yanolja: หลักการแบบ "ประตูเปิด vs. ประตูปิด" ถ้าเว็บไซต์ไม่มีข้อจำกัดการเข้าถึงที่เป็นรูปธรรม — ไม่มีหน้าล็อกอิน ไม่มี CAPTCHA ไม่ต้องใช้คีย์ API ไม่บล็อก IP — ประตูก็ถือว่า "เปิด" และการเข้าถึงข้อมูลที่เปิดสาธารณะโดยทั่วไปไม่ใช่ความผิดอาญาตามกฎหมายเครือข่ายข้อมูลและการสื่อสารของเกาหลี (ICNA) ศาลพิจารณาโดยเฉพาะว่ามี "มาตรการคุ้มครอง เงื่อนไขการใช้งาน และพฤติการณ์อื่นที่เปิดเผยอย่างเป็นรูปธรรม" มาจำกัดการเข้าถึงหรือไม่ และพบว่าเซิร์ฟเวอร์ API ของ Yanolja เข้าถึงได้โดยเสรีผ่านแอปสาธารณะ
แต่คำว่า "ไม่เป็นความผิดอาญา" ไม่ได้แปลว่า "ไม่มีความเสี่ยงเลย"
ความรับผิดทางแพ่งเป็นอีกเรื่องหนึ่งโดยสิ้นเชิง คุณอาจหลีกเลี่ยงการถูกดำเนินคดีอาญาได้ แต่ยังต้องรับผิดชอบค่าเสียหายระดับพันล้านวอนอยู่ดี คดี Yanolja ทำให้เรื่องนี้ชัดเจนเจ็บแสบมาก
กฎหมายเกาหลี 4 ฉบับที่อาจนำมาใช้กับการดึงข้อมูลเว็บได้แก่:
- ICNA (Information and Communications Network Act) — กฎแบบ "ห้ามบุกรุก"
- Copyright Act — สิทธิของผู้ผลิตฐานข้อมูล
- PIPA (Personal Information Protection Act) — กฎการเก็บข้อมูลส่วนบุคคล
- UCPA (Unfair Competition Prevention Act) — กฎครอบจักรวาลแบบ "ห้ามเกาะกินฟรี"
ส่วนที่เหลือของคู่มือนี้จะจับกฎหมายเหล่านี้ไปผูกกับสถานการณ์จริง เพื่อให้คุณประเมินได้ว่าโปรเจกต์ดึงข้อมูลของคุณเข้าข่ายไหนกันแน่
กรอบประเมินความเสี่ยงแบบเขียว-เหลือง-แดงสำหรับการดึงข้อมูลเว็บในเกาหลี
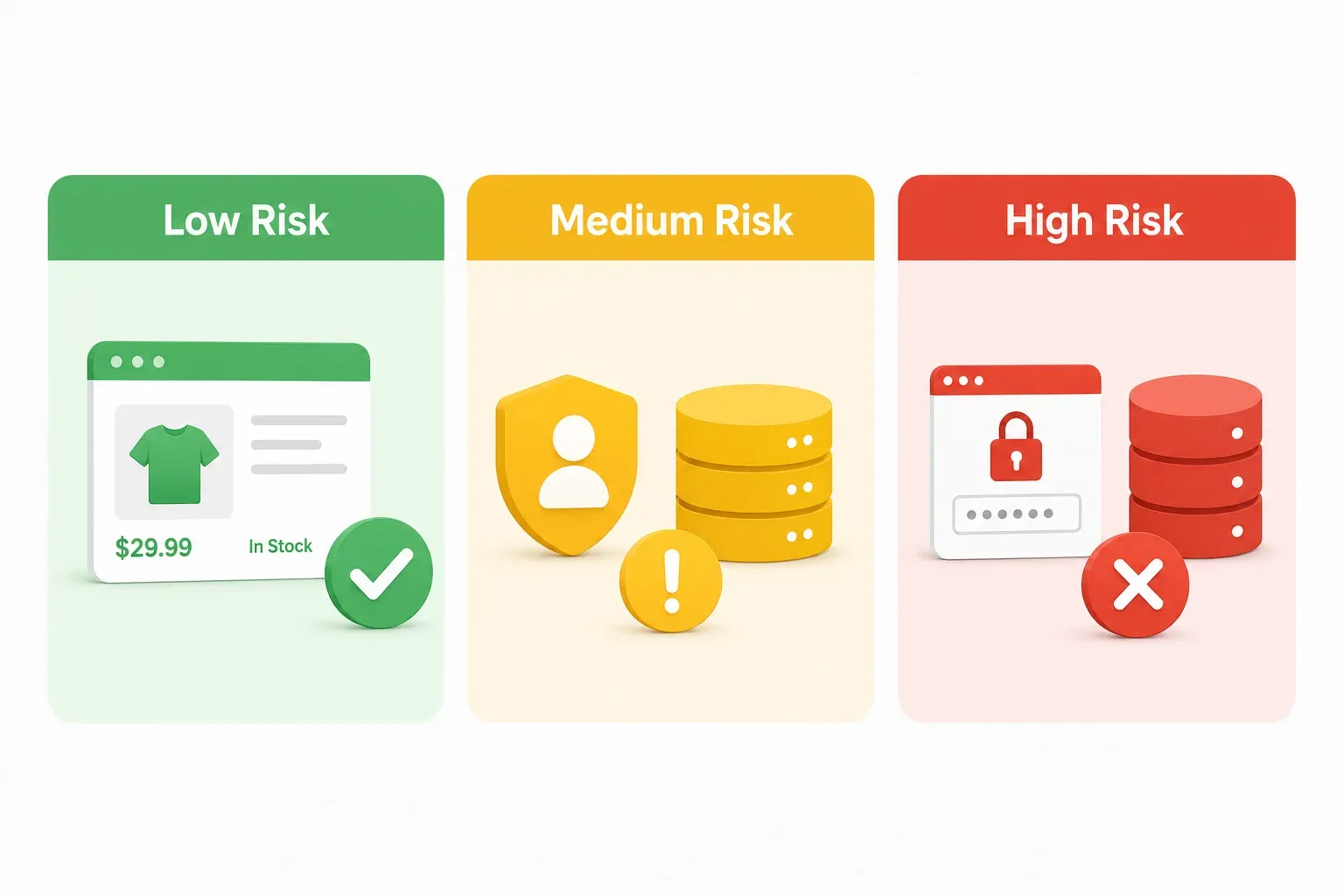
บทความกฎหมายทุกชิ้นที่ผมหาเจอเรื่องการดึงข้อมูลเว็บในเกาหลีอ่านเหมือนเขียนให้ทนายทั้งนั้น ถ้าคุณเป็นผู้จัดการฝ่ายปฏิบัติการอีคอมเมิร์ซหรือผู้ก่อตั้ง SaaS คุณไม่ได้ต้องการการวิเคราะห์บทบัญญัติ 40 หน้า — คุณต้องการวิธีประเมินความเสี่ยงแบบเร็ว ๆ ก่อนเริ่มโปรเจกต์ ลองนึกเป็นไฟจราจร สีเขียวคือไปต่อได้ (แต่ต้องระวังตามปกติ) สีเหลืองคือชะลอและเช็กกระจก สีแดงคือหยุดและโทรหาทนาย
โซนสีเขียว: สถานการณ์ดึงข้อมูลความเสี่ยงต่ำ
| สถานการณ์ | ระดับความเสี่ยง | กฎหมายหลัก | เหตุผล |
|---|---|---|---|
| ดึงรายการสินค้าสาธารณะ (ไม่มีล็อกอิน ไม่มี CAPTCHA) | 🟢 ต่ำ | ICNA, Copyright Act | คำพิพากษา Yanolja: ไม่มีข้อจำกัดการเข้าถึง = ไม่ละเมิด ICNA; ข้อมูลข้อเท็จจริง (ราคา, สินค้าพร้อมขาย) ไม่ใช่งานสร้างสรรค์ |
| ดึงราคาสาธารณะมาใช้เพื่อวิเคราะห์ภายในเท่านั้น | 🟢 ต่ำ | UCPA, Copyright Act | ข้อมูลเชิงข้อเท็จจริง ขอบเขตจำกัด ไม่กระจายต่อเพื่อแข่งขันโดยตรง |
| รวบรวมข้อเท็จจริงที่ไม่ใช่ข้อมูลส่วนบุคคลและไม่ติดลิขสิทธิ์จากหน้าเว็บสาธารณะ | 🟢 ต่ำ | ICNA, Copyright Act | ไม่ได้ฝ่าข้อจำกัดการเข้าถึง; ข้อเท็จจริงรายชิ้นไม่ได้รับการคุ้มครอง |
คำพิพากษาอาญาในคดี Yanolja เป็นตัวตั้งของโซนนี้ ศาลฎีกาเห็นว่าไม่มีการบุกรุกตาม ICNA เพราะเซิร์ฟเวอร์ API เข้าถึงได้โดยเสรี — ผู้ใช้ทั่วไปเข้าถึงผ่านแอปได้ทั้งแบบมีหรือไม่มีสมาชิก และไม่มีมาตรการป้องกันเฉพาะที่บล็อกการเข้าถึง API
สำหรับผู้ใช้ Thunderbit นี่คือจุดที่เหมาะที่สุด ถ้าคุณกำลังดึงข้อมูลจากหน้าเว็บอีคอมเมิร์ซหรืออสังหาริมทรัพย์ที่เปิดสาธารณะด้วยโหมดดึงข้อมูลบนคลาวด์ — เก็บชื่อสินค้า ราคา สินค้าพร้อมขาย หรือเมตาดาต้ารายการ โดยตัดฟิลด์ข้อมูลส่วนบุคคลออก — โดยทั่วไปจะอยู่ในโซนสีเขียว (แต่คำว่า "โดยทั่วไป" ไม่ได้แปลว่า "เสมอไป" และผมจะอธิบายรายละเอียดด้านล่าง)
ลองใช้ Thunderbit สำหรับการดึงข้อมูลสาธารณะ
โซนสีเหลือง: สถานการณ์ดึงข้อมูลความเสี่ยงปานกลาง
| สถานการณ์ | ระดับความเสี่ยง | กฎหมายหลัก | เหตุผล |
|---|---|---|---|
| ดึงข้อมูลส่วนบุคคล (ชื่อ อีเมล เบอร์โทร) แม้จากหน้าเว็บสาธารณะ | 🟡 ปานกลาง | PIPA, ICNA | PIPA ใช้บังคับไม่ว่าข้อมูลจะมองเห็นสาธารณะหรือไม่; การแก้ไขปี 2023 ทำให้กฎเรื่องความยินยอมเข้มขึ้น |
| ดึงข้อมูลจำนวนมากจนเข้าข่ายเป็น "ส่วนสำคัญ" ของฐานข้อมูลคู่แข่ง | 🟡 ปานกลาง | Copyright Act, UCPA | เกณฑ์พิจารณาทั้งเชิงปริมาณและเชิงคุณภาพตามกฎหมายเกาหลี |
| เพิกเฉยต่อสัญญาณ robots.txt | 🟡 ปานกลาง | หลักฐานของเจตนาไม่สุจริต | ไม่เป็นความผิดอาญาโดยตรง แต่ใช้เป็นหลักฐานสู้คุณในศาลได้ |
| ดึงข้อมูลสาธารณะ แต่เอาไปใช้แข่งขันกับต้นทางโดยตรง | 🟡 ปานกลาง | UCPA | เกาะกินผลประโยชน์จากการลงทุนของแพลตฟอร์มอื่น |
ข้อมูลส่วนบุคคลคือทริกเกอร์สำคัญที่สุดของโซนสีเหลือง
แม้เบอร์โทรหรืออีเมลจะมองเห็นบนหน้าเว็บสาธารณะ PIPA ก็ยังคงใช้บังคับอยู่ การปฏิรูป PIPA ปี 2023 ขยายสิทธิของเจ้าของข้อมูลและทำให้เงื่อนไขความยินยอมเข้มขึ้น และในปี 2024 คณะกรรมาธิการคุ้มครองข้อมูลส่วนบุคคลของเกาหลี (PIPC) ได้ออก แนวทางที่เจาะจงเรื่องข้อมูลส่วนบุคคลที่เปิดสาธารณะ ในบริบทของ AI และการเก็บข้อมูล ทำให้ชัดว่าการเปิดให้เข้าถึงได้สาธารณะอย่างเดียวไม่ได้แปลว่าอนุญาตโดยอัตโนมัติ
ปริมาณก็สำคัญเหมือนกัน คำพิพากษาศาลฎีกาในคดี Yanolja บอกว่าต้องดูทั้งปัจจัยเชิงปริมาณและเชิงคุณภาพเพื่อประเมินว่าคุณคัดลอก "ส่วนสำคัญ" ของฐานข้อมูลหรือไม่ ให้เปรียบเทียบสัดส่วนที่คัดลอกกับฐานข้อมูลทั้งหมด และดูว่ามันสะท้อนการลงทุนที่สำคัญของผู้ผลิตฐานข้อมูลหรือไม่
โซนสีแดง: สถานการณ์ดึงข้อมูลความเสี่ยงสูง
| สถานการณ์ | ระดับความเสี่ยง | กฎหมายหลัก | เหตุผล |
|---|---|---|---|
| ดึงข้อมูลหลังหน้าล็อกอิน หรือฝ่ามาตรการควบคุมการเข้าถึง | 🔴 สูง | ICNA มาตรา 48 | "ประตูปิด" = เข้าถึงโดยไม่ได้รับอนุญาต; ความเสี่ยงถูกดำเนินคดีสูง |
| เลี่ยง CAPTCHA, IP ban หรือระบบตรวจจับบอท | 🔴 สูง | ICNA มาตรา 48(4) | การแก้ไขปี 2024 มุ่งไปที่เครื่องมือ/อุปกรณ์สำหรับข้ามระบบโดยเฉพาะ |
| คัดลอกและขายต่อฐานข้อมูลทั้งหมดของคู่แข่ง | 🔴 สูง | Copyright Act (สิทธิฐานข้อมูล), UCPA | คัดลอกส่วนสำคัญ + เกาะกินเชิงพาณิชย์ |
| เก็บข้อมูลส่วนบุคคลโดยไม่มีฐานกฎหมายเพื่อการตลาด/การติดต่อ | 🔴 สูง | PIPA | โทษจำคุกสูงสุด 5 ปี / ปรับ 50 ล้านวอน; โทษทางปกครองสูงสุด 3% ของรายได้ |
การเพิ่มเติมใน ICNA ปี 2024 — มาตรา 48(4) — ระบุห้ามติดตั้ง โอน หรือแจกจ่ายโปรแกรมหรืออุปกรณ์ทางเทคนิคที่ข้าม "กระบวนการคุ้มครองหรือยืนยันตัวตนตามปกติ" โดยไม่มีเหตุอันชอบธรรม
นอกจากนี้ คำพิพากษาศาลฎีกาในเดือนพฤศจิกายน 2024 (2021Do5555) ยังย้ำว่า การบุกรุกเครือข่ายโดยไม่ได้รับอนุญาตอาจเกิดขึ้นได้แม้ไม่มีการทำลายมาตรการป้องกันทางกายภาพ การใช้อัตลักษณ์ของผู้อื่นหรือคำสั่งที่ไม่ถูกต้องเพื่อหลบเลี่ยงข้อจำกัดการเข้าถึงก็เพียงพอแล้ว
กฎหมายเกาหลี 4 ฉบับที่เกี่ยวข้องกับการดึงข้อมูลเว็บ
| กฎหมาย | คุ้มครองอะไร | เมื่อใดที่เริ่มใช้กับผู้ดึงข้อมูล |
|---|---|---|
| ICNA มาตรา 48 | เสถียรภาพของเครือข่าย, สิทธิในการเข้าถึง | ฝ่าล็อกอิน, CAPTCHA, การยืนยันตัวตน, การบล็อก IP, ขีดจำกัดคีย์ API |
| Copyright Act (มาตรา 93) | งานสร้างสรรค์ + สิทธิของผู้ผลิตฐานข้อมูล | คัดลอกเนื้อหาเชิงสร้างสรรค์ รูปภาพ หรือทั้งหมด/ส่วนสำคัญของฐานข้อมูล |
| PIPA | ข้อมูลส่วนบุคคล, สิทธิของเจ้าของข้อมูล | เก็บชื่อ เบอร์โทร อีเมล รหัสประจำตัว — แม้จากหน้าเว็บสาธารณะ |
| UCPA (มาตรา 2(1)(k) และ (m)) | การแข่งขันที่เป็นธรรม, ข้อมูลที่มีมูลค่าทางการค้า | เกาะกินจากการลงทุนข้อมูลของอีกฝ่ายเพื่อธุรกิจแข่งขันของตนเอง |
ICNA มาตรา 48: กฎแบบ "ห้ามบุกรุก"
ICNA มาตรา 48(1) ระบุว่า ห้ามบุคคลใดบุกรุกเครือข่ายข้อมูลและการสื่อสาร "โดยไม่มีอำนาจเข้าถึงโดยชอบธรรม หรือเกินกว่าขอบเขตอำนาจที่ได้รับอนุญาต" ถ้าแปลเป็นภาษาการดึงข้อมูลเว็บคือ: หากเว็บไซต์มีข้อจำกัดการเข้าถึงที่คุณฝ่าฝืน คุณก็มีความเสี่ยงละเมิด หากไม่มีข้อจำกัด — หน้าเว็บสาธารณะ ไม่มีล็อกอิน — โดยมากคุณก็อยู่ในฝั่งปลอดภัย
โทษสำหรับการฝ่าฝืนตาม ICNA มาตรา 71 คือจำคุกสูงสุด 5 ปี หรือปรับไม่เกิน 50 ล้านวอน
อีกประเด็นที่ควรรู้คือ ศาลฎีกาเกาหลีแยกชัดเจนระหว่างข้อจำกัดใน Terms of Service กับข้อจำกัดการเข้าถึง ข้อกำหนดในแอปของ Yanolja จำกัดการนำไปใช้เชิงพาณิชย์และห้ามโปรแกรมอัตโนมัติที่สร้างภาระให้เซิร์ฟเวอร์ แต่ศาลเห็นว่าข้อความเหล่านั้นไม่ได้จำกัด การเข้าถึง เซิร์ฟเวอร์ API โดยตรง
Copyright Act: สิทธิของผู้ผลิตฐานข้อมูล
กฎหมายลิขสิทธิ์ของเกาหลีคุ้มครองผู้ผลิตฐานข้อมูลแยกต่างหากจากลิขสิทธิ์ในเนื้อหารายชิ้น ภายใต้มาตรา 93 การทำซ้ำ "ทั้งหมดหรือส่วนสำคัญ" ของฐานข้อมูลเป็นสิ่งผิดกฎหมาย — แม้ว่าข้อมูลแต่ละรายการจะเป็นข้อเท็จจริงสาธารณะก็ตาม
เกณฑ์พิจารณามีทั้งเชิงปริมาณ (คัดลอกไปมากแค่ไหนเมื่อเทียบกับทั้งหมด) และเชิงคุณภาพ (ส่วนที่คัดลอกสะท้อนการลงทุนสำคัญของผู้ผลิตในการสร้าง ตรวจสอบ หรือดูแลฐานข้อมูลหรือไม่) การคัดลอกทีละน้อยแต่ทำซ้ำอย่างต่อเนื่องหรือเป็นระบบก็อาจเข้าข่ายได้ ถ้าผลลัพธ์สุดท้ายเทียบเท่ากับการคัดลอกส่วนสำคัญ
โทษสำหรับการละเมิดสิทธิผู้ผลิตฐานข้อมูลคือจำคุกสูงสุด 3 ปี หรือปรับ 30 ล้านวอนตามมาตรา 136(2)(3) และค่าเสียหายตามกฎหมายในมาตรา 125-2 อนุญาตให้เรียกได้สูงสุด 10 ล้านวอนต่อหนึ่งงาน หรือ 50 ล้านวอนต่อหนึ่งงานสำหรับการละเมิดโดยเจตนาเพื่อแสวงหากำไร
PIPA: กฎหมายคุ้มครองข้อมูลส่วนบุคคล
PIPA กำกับการเก็บข้อมูลส่วนบุคคล — ชื่อ ข้อมูลติดต่อ รหัสประจำตัว — แม้ข้อมูลนั้นจะมองเห็นสาธารณะ การปฏิรูปปี 2023 มีนัยสำคัญมาก: ขยายสิทธิของเจ้าของข้อมูล เข้มงวดเงื่อนไขความยินยอม เพิ่มกฎเรื่องการตัดสินใจอัตโนมัติ และกำหนดโทษทางปกครองสูงสุดถึง 3% ของยอดขายรวม สำหรับการละเมิดบางประเภท
แนวทาง AI สำหรับข้อมูลสาธารณะปี 2024 ของ PIPC กล่าวถึงข้อมูลที่ได้มาจาก "web crawling and scraping" โดยตรงในบริบทของข้อมูลส่วนบุคคลที่เปิดสาธารณะ แนวทางนี้ชี้ว่าผลประโยชน์โดยชอบอาจใช้เป็นฐานได้ในบางบริบท แต่หน่วยงานต้องมีการชั่งน้ำหนัก มีมาตรการป้องกัน คุ้มครองสิทธิ และมีธรรมาภิบาล
และแนวโน้มก็เข้มงวดขึ้นเรื่อย ๆ ในเดือนมีนาคม 2026 สื่อเกาหลีรายงานการแก้ PIPA ที่เพิ่มโทษสูงสุดสำหรับกรณีละเมิดข้อมูลร้ายแรงและซ้ำซ้อนเป็นสูงสุด 10% ของรายได้ มีผลในช่วงปลายปี 2026
UCPA: ตัวกวาดล้างเรื่องการแข่งขันที่ไม่เป็นธรรม
UCPA คือกฎหมายที่เอาผิด GC Company ในคดีแพ่ง Yanolja บทบัญญัติที่เกี่ยวข้องในฉบับปัจจุบันมี 2 ส่วนคือ:
- มาตรา 2(1)(k): ครอบคลุมการใช้ข้อมูลทางเทคนิคหรือข้อมูลทางธุรกิจที่สะสมและจัดการด้วยระบบอิเล็กทรอนิกส์อย่างไม่เป็นธรรม โดยข้อมูลนั้นไม่ใช่ความลับ
- มาตรา 2(1)(m): บทกวาดล้างแบบกว้างสำหรับการนำผลลัพธ์ของผู้อื่นที่เกิดจากการลงทุนหรือความพยายามอย่างมีนัยสำคัญ มาใช้ในธุรกิจของตนเองโดยไม่ได้รับอนุญาต และขัดต่อแนวปฏิบัติทางการค้าที่เป็นธรรม
บทบัญญัติ UCPA เหล่านี้เป็นคดีแพ่งเท่านั้น — ไม่มีโทษอาญา — แต่ยังอาจนำไปสู่คำสั่งห้ามตาม มาตรา 4 ค่าเสียหายตามมาตรา 5 และแม้กระทั่งค่าเสียหายสามเท่าสำหรับกรณีเจตนาเฉพาะตามมาตรา 14-2 คดีแพ่ง Yanolja สั่งค่าเสียหายราว 1,000 ล้านวอนภายใต้กรอบนี้
คดี Yanolja: ทำไมคุณชนะคดีอาญาได้ แต่แพ้คดีแพ่งได้
นี่คือคดีที่ผู้ใช้ธุรกิจทุกคนในเกาหลีต้องเข้าใจ ผมจะเล่าเป็นเรื่องเดียว เพราะในความจริงมันก็เกิดขึ้นแบบนั้น — และเพราะผลลัพธ์ที่แยกกันคนละทางนี่แหละคือสาระสำคัญทั้งหมด
เกิดอะไรขึ้น: GC Company ดึงข้อมูลการท่องเที่ยวของ Yanolja
GC Company ดำเนินแพลตฟอร์มท่องเที่ยวออนไลน์ที่เป็นคู่แข่ง พวกเขาสร้าง crawler ของตนเองที่เข้าถึงเซิร์ฟเวอร์ API ของแอป Baro Reservation ของ Yanolja โดยเรียนรู้ URL ของ API และคำสั่ง request แล้วส่งไปยังเซิร์ฟเวอร์ เครื่องมือดึงข้อมูลเก็บข้อมูลที่พัก — ชื่อพาร์ตเนอร์ ที่อยู่ ราคา ความพร้อมให้จอง และรูปภาพ — GC Company นำข้อมูลนี้ไปใช้ภายในเพื่อการตลาดและวางตำแหน่งทางการแข่งขัน
Yanolja จึงยื่นทั้งคดีอาญาและคดีแพ่ง
คำพิพากษาคดีอาญา: ยกฟ้องทุกข้อหา (ศาลฎีกา 2021Do1533)
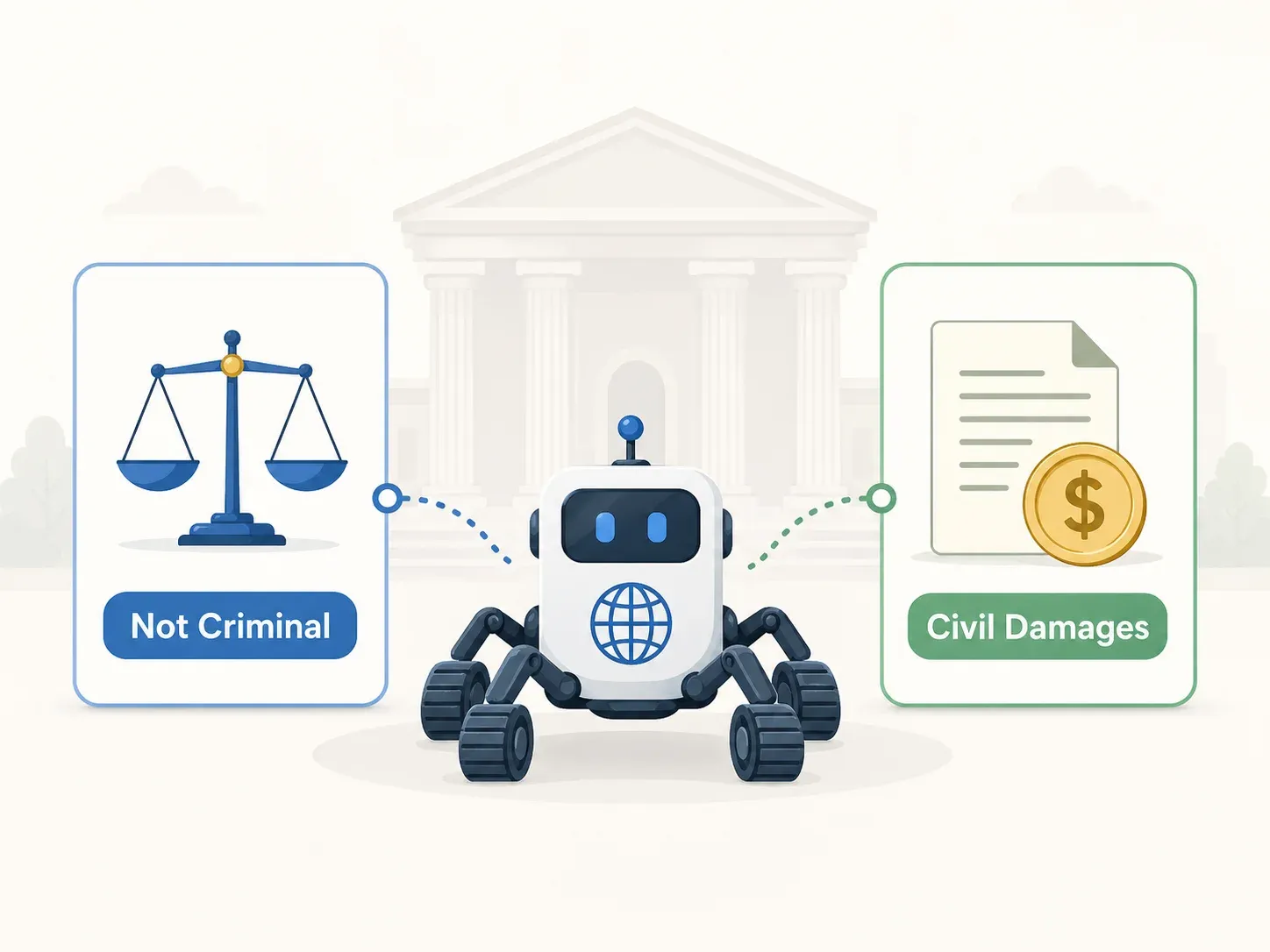
ศาลฎีกายืนตามคำยกฟ้องของศาลอุทธรณ์ เมื่อวันที่ 12 พฤษภาคม 2022 ในทั้ง 3 ข้อหา:
- ICNA มาตรา 48 (การบุกรุก): ไม่มีข้อจำกัดการเข้าถึง เซิร์ฟเวอร์ API เปิดให้เข้าถึงได้ผ่านเบราว์เซอร์และแอปมือถือ ไม่มีการบล็อกทางเทคนิค ข้อกำหนด ToS จำกัด การใช้งาน ไม่ใช่ การเข้าถึง
- Copyright Act (สิทธิผู้ผลิตฐานข้อมูล): จำเลยไม่ได้ทำซ้ำ "ทั้งหมดหรือส่วนสำคัญ" ของฐานข้อมูล ข้อมูลที่คัดลอกเป็นข้อเท็จจริงที่เปิดเผยอยู่แล้ว และพยานหลักฐานไม่พิสูจน์ว่าส่วนที่คัดลอกสะท้อนการลงทุนที่สำคัญของ Yanolja
- ประมวลกฎหมายอาญามาตรา 314 (รบกวนการประกอบธุรกิจ): ไม่ได้พิสูจน์ว่ามีการรบกวนการทำงานของเซิร์ฟเวอร์ API ของ Yanolja จริง ไม่มีการแก้ไขข้อมูล และไม่มีเจตนาในการรบกวนธุรกิจ
กฎที่อ้างอิงได้คือ: ต้องประเมินข้อจำกัดการเข้าถึงผ่าน "มาตรการคุ้มครอง เงื่อนไขการใช้งาน และพฤติการณ์อื่นที่เปิดเผยอย่างเป็นรูปธรรม" ถ้าประตูเปิดอยู่ การเดินผ่านเข้าไปไม่ใช่การบุกรุก
คำพิพากษาคดีแพ่ง: ค่าเสียหาย 1,000 ล้านวอนภายใต้ UCPA
ตรงนี้แหละที่เรื่องหักมุม ศาลแขวงกลางโซล — และต่อมาศาลอุทธรณ์โซล (คดี 2021Na2034740 ตัดสินเมื่อ 25 สิงหาคม 2022) — วินิจฉัยว่า GC Company ละเมิดบทกวาดล้างของ UCPA ศาลสั่งค่าเสียหายชดเชยประมาณ 1,000 ล้านวอน (~800,000 ดอลลาร์สหรัฐ) และสั่งให้หยุดการคัดลอกข้อมูลต่อไป
เหตุผลคือ ฐานข้อมูลที่พักของ Yanolja มีมูลค่าทางการค้าและสะท้อนการลงทุนอย่างมีนัยสำคัญ — ทั้งการรวบรวม ตรวจสอบ และอัปเดตข้อมูลที่พัก GC Company เกาะกินการลงทุนนั้น คำพิพากษาแพ่งสิ้นสุดที่ระดับศาลอุทธรณ์โซล
ข้อสรุปเชิงปฏิบัติ: ยกฟ้องคดีอาญา ไม่ได้แปลว่าปลอดภัยทางแพ่ง
นี่คือบทเรียนที่ขัดกับความรู้สึกที่สุดจากกฎหมายการดึงข้อมูลเว็บของเกาหลี การเข้าถึงที่ชอบด้วยกฎหมายในทางอาญาไม่ได้ทำให้การใช้ข้อมูลเชิงพาณิชย์ที่ไม่เป็นธรรมปลอดความรับผิด คำถามว่า "จะโดนดำเนินคดีอาญาไหม" กับ "จะถูกฟ้องไหม" เป็นคนละคำถาม และคำตอบอาจตรงข้ามกันได้
สำหรับผู้ใช้ทางธุรกิจ: แม้ว่าวิธีดึงข้อมูลของคุณจะอยู่ในโซนสีเขียวในทางอาญาอย่างชัดเจน แต่ การนำข้อมูลไปใช้ — โดยเฉพาะถ้าไปแข่งขันกับต้นทางโดยตรง — คือสิ่งที่กำหนดความเสี่ยงทางแพ่งของคุณ
เกาหลี vs. สหรัฐฯ vs. สหภาพยุโรป: กฎหมายการดึงข้อมูลเว็บต่างกันอย่างไร
ผมหาคู่มืออื่นที่เอาเรื่องนี้มารวมไว้ในตารางเดียวไม่ได้เลย ซึ่งก็น่าประหลาดใจมากเมื่อคิดว่ามีหลายธุรกิจที่ดึงข้อมูลข้ามพรมแดน
| มิติ | เกาหลีใต้ | สหรัฐอเมริกา | สหภาพยุโรป / EEA |
|---|---|---|---|
| กฎหมายหลัก | ICNA มาตรา 48, Copyright Act | CFAA (18 U.S.C. §1030), กฎหมายของแต่ละรัฐ | GDPR, Database Directive (96/9/EC) |
| คดีสำคัญ | Yanolja v GC Company (ศาลฎีกา 2021Do1533, 2022) | hiQ v LinkedIn (9th Cir. 2022), Van Buren v. US (2021) | Ryanair v PR Aviation (CJEU C-30/14, 2015) |
| การดึงข้อมูลสาธารณะ | ถูกกฎหมายถ้าไม่มีอุปสรรคการเข้าถึงเชิงรูปธรรม ("ประตูเปิด") | ถูกกฎหมายตามเหตุผลในคดี hiQ (ข้อมูลสาธารณะ); Van Buren ทำให้ CFAA แคบลง | ขึ้นอยู่กับสิทธิฐานข้อมูล สัญญา ลิขสิทธิ์ GDPR และกฎหมายของรัฐสมาชิก |
| กฎข้อมูลส่วนบุคคล | PIPA (แก้ไข 2023) — ต้องมีความยินยอมหรือฐานกฎหมาย | เป็นรายภาคส่วน: CCPA (แคลิฟอร์เนีย), กฎหมายความเป็นส่วนตัวของแต่ละรัฐ | GDPR — ความยินยอม / legitimate interest เข้มงวด; ค่าปรับสูงสุด 20 ล้านยูโร หรือ 4% ของรายได้ทั่วโลก |
| ละเมิด ToS = อาชญากรรมหรือไม่? | ไม่ใช่ (ศาลวินิจฉัยว่า ToS ≠ การละเมิด ICNA) | ไม่ใช่ (Van Buren 2021: ToS ≠ CFAA) | โดยทั่วไปไม่ใช่ แต่อาจผิดสัญญาได้ (Ryanair) |
| การคุ้มครองฐานข้อมูล | สิทธิผู้ผลิตฐานข้อมูลตาม Copyright Act | ไม่มีสิทธิฐานข้อมูลระดับรัฐบาลกลางโดยทั่วไป | สิทธิฐานข้อมูลแบบ sui generis |
| โทษอาญาสูงสุด | สูงสุด 5 ปี / ปรับ 50 ล้านวอน (ICNA) | สูงสุด 10 ปี / 250,000 ดอลลาร์ (CFAA) | แตกต่างตามประเทศสมาชิก |
ความแตกต่างสำคัญที่มีผลกับธุรกิจของคุณ
- เกาหลีไม่มีข้อยกเว้น text-and-data-mining (TDM) แบบกว้าง เหมือน DSM Directive ของสหภาพยุโรป ถ้าคุณฝึกโมเดล AI ด้วยข้อมูลเกาหลีที่ดึงมา คุณไม่ได้รับข้อยกเว้นตามกฎหมายแบบอัตโนมัติ
- บทกวาดล้างของ UCPA ในเกาหลีมีขอบเขตกว้างกว่าและคาดเดายากกว่า กฎหมายการแข่งขันที่ไม่เป็นธรรมของสหรัฐฯ คดี Yanolja ในทางแพ่งจะนำไปเทียบคดีแบบเดียวกันในสหรัฐฯ ได้ยากกว่า
- ทั้งสามเขตอำนาจเห็นตรงกัน: การละเมิด Terms of Service เพียงอย่างเดียวไม่ใช่ความผิดอาญา
- การคุ้มครองฐานข้อมูลของเกาหลีเป็นแบบตามกฎหมายบัญญัติ (เหมือนสหภาพยุโรป) ขณะที่สหรัฐฯ ไม่มีสิทธิฐานข้อมูลระดับรัฐบาลกลางทั่วไป ทำให้เจ้าของแพลตฟอร์มในเกาหลีมีเครื่องมือทางแพ่งมากกว่า
- ถ้าคุณดึงข้อมูลข้ามพรมแดน กฎหมายที่เข้มที่สุดที่เกี่ยวข้องจะเป็นตัวกำกับ โปรเจกต์ที่แตะข้อมูลเกาหลี สหรัฐฯ และสหภาพยุโรปต้องสอดคล้องกับทั้ง 3 ระบอบ
สถานการณ์เฉพาะอุตสาหกรรม: การดึงข้อมูลเว็บในเกาหลีถูกกฎหมายหรือไม่สำหรับธุรกิจของคุณ?
ระดับความเสี่ยงต่างกันมากตามอุตสาหกรรม และคู่มือที่ผมเจอไม่มีอันไหนแมปกฎหมายการดึงข้อมูลเว็บของเกาหลีกับแต่ละแนวธุรกิจแบบชัด ๆ เลย ผมจึงรวบรวมเอง
อีคอมเมิร์ซ: การติดตามราคาและข้อมูลสินค้า

การดึงราคาสินค้าสาธารณะจาก Coupang, Gmarket หรือ 11Street เป็นตัวอย่างโซนสีเขียวที่สะอาดที่สุด — ยึดเฉพาะฟิลด์ข้อเท็จจริง (ราคา สินค้าพร้อมขาย ชื่อสินค้า) หลีกเลี่ยงพื้นที่ที่ต้องล็อกอิน อย่าฝ่ากลไกเทคนิค และใช้ข้อมูลเพื่อ benchmark ภายใน
ความเสี่ยงจะเพิ่มขึ้นเมื่อคุณดึงคำอธิบายสินค้า (เนื้อหาเชิงสร้างสรรค์ → ลิขสิทธิ์) ข้อมูลติดต่อผู้ขาย (PIPA) รูปภาพ (ลิขสิทธิ์) หรือทั้งแค็ตตาล็อก (สิทธิผู้ผลิตฐานข้อมูล + UCPA)
ผมไม่พบคดีดึงข้อมูลเว็บของอีคอมเมิร์ซเกาหลีที่โดดเด่นเทียบได้กับ Yanolja แบบตรงตัว คดีที่พัฒนาไว้มากกว่าคือด้านท่องเที่ยวและการสรรหาบุคลากร — แต่ไม่มีคดีไม่ได้แปลว่าไม่มีความเสี่ยง
โหมด scheduled scraper และ cloud scraping ของ Thunderbit ถูกสร้างมาสำหรับแพตเทิร์นนี้โดยตรง: ตรวจสอบราคาและสต็อกบนหน้าเว็บสาธารณะเป็นระยะ พร้อมให้ AI Suggest Fields ช่วยเลือกคอลัมน์ที่ต้องการและตัดฟิลด์ข้อมูลส่วนบุคคลออก
อสังหาริมทรัพย์: รายการประกาศทรัพย์สิน
อสังหาริมทรัพย์เป็นพื้นที่สีเหลืองโดยธรรมชาติ รายการบนแพลตฟอร์มอย่าง Zigbang หรือ Naver Real Estate ผสมทั้งข้อมูลข้อเท็จจริง (ราคา พื้นที่ ย่าน) กับชื่อเอเจนต์ เบอร์สำนักงาน เบอร์มือถือ รูปภาพ และฐานข้อมูลแพลตฟอร์มที่คัดสรรไว้แล้ว
การดึงรายละเอียดทรัพย์สินที่เปิดสาธารณะอาจมีความเสี่ยงต่ำกว่า แต่ถ้าเก็บคอลัมน์ข้อมูลติดต่อเอเจนต์ก็จะเข้า PIPA ทันที — และการดึงรายการทั้งหมดในภูมิภาคเดียวเริ่มดูคล้ายการคัดลอกฐานข้อมูลจำนวนมาก
วิธีลดความเสี่ยง: ตัดคอลัมน์ส่วนบุคคล ลดขอบเขตพื้นที่ จดบันทึกวัตถุประสงค์ธุรกิจที่ชอบธรรม เคารพ rate limit และหลีกเลี่ยงการทำซ้ำบริการประกาศขาย/เช่าของคู่แข่ง Thunderbit AI สามารถตั้งค่าให้ดึงเฉพาะฟิลด์ที่คุณต้องการ — ราคา ตารางเมตร ทำเล — โดยข้ามข้อมูลติดต่อส่วนบุคคล
การสรรหาบุคลากร: ประกาศงาน
งานสรรหาบุคลากรคือภาคส่วนที่มีความเสี่ยงสูงแบบไม่ต้องอ้อมค้อม เกาหลีมีบรรทัดฐานโดยตรง: JobKorea v. Saramin Saramin ดึงฐานข้อมูลประกาศงานของ JobKorea และถูกวินิจฉัยว่าละเมิดสิทธิฐานข้อมูลและการแข่งขันไม่เป็นธรรม ข้อมูลการสรรหามักผสมการลงทุนของแพลตฟอร์ม (รายการที่คัดสรรและตรวจสอบแล้ว) การคัดลอกฐานข้อมูลจำนวนมาก และข้อมูลส่วนบุคคลหรือข้อมูลติดต่อผู้สรรหา
คำแนะนำของผมคือ: โดยทั่วไปอย่าดึงข้อมูลจากแพลตฟอร์มหางานคู่แข่งเพื่อสร้างหรือเติมฐานข้อมูลงานของตนเอง หากกรณีใช้งานมีขอบเขตแคบ ให้ทนายตรวจสอบก่อนเก็บข้อมูล ลดปริมาณให้มากที่สุด ลบข้อมูลติดต่อส่วนบุคคล และอย่านำผลลัพธ์ไปกระจายต่อ
ตารางโทษฉบับเต็ม: ความเสี่ยงเมื่อการดึงข้อมูลเว็บในเกาหลีผิดพลาด
| กฎหมายเกาหลี | ประเภทการละเมิด | โทษอาญาสูงสุด | เยียวยาทางแพ่ง/ปกครองสูงสุด | การเปลี่ยนแปลงสำคัญปี 2023–2026 |
|---|---|---|---|---|
| ICNA มาตรา 48 | เข้าถึง/รบกวนโดยไม่ได้รับอนุญาต | 5 ปี / ปรับ 50 ล้านวอน | ค่าเสียหาย + คำสั่งห้าม | 2024: เพิ่มมาตรา 48(4) มุ่งเป้าไปที่เครื่องมือข้ามระบบ |
| Copyright Act (สิทธิฐานข้อมูล, มาตรา 93) | คัดลอกฐานข้อมูลส่วนสำคัญ | 3 ปี / ปรับ 30 ล้านวอน | ค่าเสียหายตามกฎหมายสูงสุด 50 ล้านวอน/งาน (กรณีเจตนาเพื่อแสวงหากำไร) | — |
| PIPA | เก็บข้อมูลส่วนบุคคลโดยมิชอบ | 5 ปี / ปรับ 50 ล้านวอน | โทษทางปกครองสูงสุด 3% ของยอดขายรวม; ฟ้องแบบกลุ่มได้ | ปฏิรูป 2023; แนวทาง AI สำหรับข้อมูลสาธารณะ 2024; แนวโน้มปี 2026 ไปสู่ 10% สำหรับกรณีรั่วไหลซ้ำ |
| UCPA มาตรา 2(1)(k)/(m) | ได้มาหรือใช้ข้อมูลอย่างไม่เป็นธรรม | เฉพาะทางแพ่ง (ไม่มีโทษอาญาสำหรับบทกวาดล้าง) | ค่าเสียหาย + คำสั่งห้าม; ค่าเสียหายสามเท่าสำหรับกรณีเจตนาเฉพาะ | 2022 Data Framework Act เสริมความเข้มของบทบัญญัติ |
| Criminal Code มาตรา 314 | รบกวนธุรกิจด้วยวิธีทางเทคโนโลยี | 5 ปี / ปรับ 15 ล้านวอน | — | Yanolja: ไม่พิสูจน์ว่ามีการรบกวนจริง |
จุดสำคัญคือ เส้นคดีอาญาและคดีแพ่งเดินแยกจากกัน คุณอาจโดนทั้งสองเส้นพร้อมกัน — และชนะคดีหนึ่งแต่แพ้อีกคดีหนึ่ง
เช็กลิสต์การปฏิบัติตามกฎหมาย 10 ข้อสำหรับการดึงข้อมูลเว็บในเกาหลี
นี่คือคำถามใช่/ไม่ใช่ 10 ข้อที่ควรถามตัวเองก่อนเริ่มโปรเจกต์ดึงข้อมูลใด ๆ พิมพ์เก็บไว้ บุ๊กมาร์กไว้ หรือแปะหน้าจอไว้ก็ได้
- เว็บไซต์เป้าหมายไม่ต้องล็อกอินเพื่อเข้าถึงข้อมูลที่คุณต้องการใช่หรือไม่? ถ้าต้องใช้ล็อกอิน โทเคน หรือบัญชี ความเสี่ยงจะขยับไปทาง ICNA มาตรา 48 อย่างชัดเจน
- ไม่มีข้อจำกัดการเข้าถึงทางเทคนิคใช่หรือไม่? CAPTCHA, การบล็อก IP, คีย์ API, rate limit และกำแพงบอทคือสัญญาณโซนแดง
- คุณตรวจสอบ robots.txt แล้วหรือยัง? ในบรรทัดฐานเกาหลีมันไม่ใช่ข้อผูกพันทางกฎหมายโดยตัวมันเอง แต่ใช้เป็นหลักฐานเรื่องความคาดหวังของเว็บไซต์และความสุจริตของคุณได้
- คุณกำลังเก็บข้อมูลส่วนบุคคลอยู่หรือไม่? ถ้ามีชื่อ เบอร์โทร อีเมล รหัสประจำตัว หรือข้อมูลติดต่อรายบุคคล ต้องวิเคราะห์ตาม PIPA
- คุณกำลังคัดลอก "ส่วนสำคัญ" ของฐานข้อมูลเว็บไซต์หรือไม่? ให้ถามทั้งเชิงปริมาณและเชิงคุณภาพ — มากแค่ไหน และส่วนที่คัดลอกสะท้อนการลงทุนของต้นทางหรือไม่
- คุณกำหนดวัตถุประสงค์ไว้หรือยัง? การวิเคราะห์ภายในมีความเสี่ยงต่ำกว่าการกระจายต่อหรือสร้างฐานข้อมูลคู่แข่ง (แต่คดี Yanolja แสดงให้เห็นว่าการใช้ภายในเพื่อการแข่งขันก็ไม่ใช่เกราะป้องกันทั้งหมด)
- คุณมีเอกสารระบุวัตถุประสงค์ธุรกิจที่ชอบธรรมเป็นลายลักษณ์อักษรหรือไม่? เอกสารช่วยเรื่องการชั่งน้ำหนัก legitimate interest ตาม PIPA และเป็นหลักฐานความสุจริต
- คุณตัดหรือทำข้อมูลส่วนบุคคลให้ไม่ระบุตัวตนก่อนเก็บ/ใช้หรือยัง? การตัดข้อมูลติดต่อมักช่วยให้การดึงข้อมูลอสังหาฯ งานสรรหา และไดเรกทอรีหลุดจากรูปแบบที่อันตรายที่สุดของ PIPA
- คุณใช้ช่วงเวลาการร้องขอที่เหมาะสมหรือไม่? หลีกเลี่ยงการถล่มเซิร์ฟเวอร์ — ความเสี่ยงตาม Criminal Act มาตรา 314 และ ICNA มาตรา 48(3) จะสูงขึ้นเมื่อการดึงข้อมูลกระทบการทำงานของบริการ
- คุณได้ปรึกษาทนายเกาหลีสำหรับโปรเจกต์ปริมาณมาก เชิงพาณิชย์ หรือข้ามพรมแดนแล้วหรือยัง? กฎหมายเกาหลีรวมกับ GDPR/กฎหมายความเป็นส่วนตัวหรือกฎหมายเข้าถึงคอมพิวเตอร์ของสหรัฐฯ อาจใช้พร้อมกันได้
⚠️ ข้อจำกัดความรับผิด: เช็กลิสต์นี้มีไว้เพื่อให้เห็นภาพ ไม่ใช่คำปรึกษากฎหมาย ควรปรึกษาทนายในเกาหลีสำหรับกรณีเฉพาะเสมอ
Thunderbit ช่วยให้คุณดึงข้อมูลเว็บไซต์เกาหลีอย่างรับผิดชอบได้อย่างไร
ขอเปิดเผยก่อน: ผมทำงานในทีมการตลาดของ Thunderbit แต่ผมเชื่อจริง ๆ ว่าความเข้ากันได้ระหว่างตัวผลิตภัณฑ์กับกฎหมายในกรณีนี้มีประโยชน์จริง ไม่ใช่แค่ขายของ
Thunderbit ถูกออกแบบมาสำหรับกรณีใช้งานในโซนสีเขียวที่บทความนี้อธิบาย: ดึงข้อมูลที่เปิดสาธารณะโดยไม่ต้องล็อกอิน นี่คือวิธีที่ฟีเจอร์เฉพาะต่าง ๆ ผูกเข้ากับกรอบการปฏิบัติตามกฎหมาย:
- โหมด cloud scraping สำหรับเว็บไซต์สาธารณะ — ไม่ต้องล็อกอิน ไม่ต้องมีเซสชันในเครื่อง อยู่ในขอบเขตที่เปิดให้เข้าถึงได้สาธารณะ ซึ่งสอดคล้องกับหลัก "ประตูเปิด" ของ Yanolja
- AI Suggest Fields ให้คุณกำหนดคอลัมน์ข้อมูลที่จะดึงได้แบบตรงเป๊ะ ต้องการราคาและสินค้าพร้อมขายแต่ไม่เอาเบอร์โทรผู้ขาย? ก็แค่ตัดคอลัมน์ส่วนบุคคลออก วิธีนี้ง่ายที่สุดในการหลีกเลี่ยงตัวกระตุ้นของ PIPA
- scheduled scraper สำหรับตรวจสอบราคา สต็อก หรือรายการแบบต่อเนื่องในช่วงเวลาที่เหมาะสม — ไม่ต้องยิงเซิร์ฟเวอร์ถี่ ๆ
- ส่งออกข้อมูลฟรี ไปยัง Excel, Google Sheets, Airtable และ Notion สำหรับเวิร์กโฟลว์วิเคราะห์ภายใน
- การดึงข้อมูลซับเพจ เพื่อเสริมข้อมูลรายการสาธารณะ (เช่น กดเข้าไปดูหน้าสินค้าแต่ละรายการเพื่อดึงสเปก) โดยไม่เข้าพื้นที่ล็อกอินหรือพื้นที่จำกัด
- การปรับตามเลย์เอาต์ด้วย AI — ตัวดึงข้อมูลอ่านโครงสร้างเว็บไซต์ใหม่ทุกครั้ง ปรับตามการเปลี่ยนเลย์เอาต์ได้โดยไม่ต้องพึ่งตัวเลือกที่ hardcode ไว้
Thunderbit รองรับการใช้งานหลายภาษาในหลายสิบภาษา ซึ่งสำคัญมากสำหรับทีมที่ทำงานกับเว็บไซต์ภาษาเกาหลี คุณสามารถทดลองใช้ฟรีผ่าน Thunderbit Chrome Extension
ไม่มีเครื่องมือไหนลบความเสี่ยงทางกฎหมายได้หมด แต่การตั้งค่าอย่างรับผิดชอบ — หน้าเว็บสาธารณะ ข้อมูลข้อเท็จจริง ตัดฟิลด์ข้อมูลส่วนบุคคลออก ใช้ช่วงเวลาที่เหมาะสม — จะทำให้คุณอยู่ในกรอบการปฏิบัติตามกฎหมายที่บทความนี้อธิบาย
ข้อสรุปสำคัญเกี่ยวกับความถูกกฎหมายของการดึงข้อมูลเว็บในเกาหลี
มี 5 เรื่องที่ควรจำไว้:
- เทคโนโลยีการดึงข้อมูลเว็บเองถูกกฎหมายในเกาหลี ศาลฎีกายืนยันไว้ในคดี Yanolja
- ความเสี่ยงขึ้นอยู่กับวิธีเข้าถึง (ประตูเปิด vs. ประตูปิด) ประเภทข้อมูล (ส่วนบุคคล vs. ข้อเท็จจริง) และการใช้งาน (ภายใน vs. การกระจายเพื่อแข่งขัน)
- ยกฟ้องคดีอาญา ≠ ปลอดภัยทางแพ่ง คดี Yanolja พิสูจน์แล้วว่าคุณหลุดคดีอาญาได้ แต่ยังโดนค่าเสียหายระดับพันล้านวอนได้
- ถ้าดึงข้อมูลสาธารณะ ที่ไม่ใช่ข้อมูลส่วนบุคคล และเป็นข้อเท็จจริงเพื่อใช้ภายใน โดยไม่มีอุปสรรคการเข้าถึง โดยทั่วไปจะอยู่ในโซนปลอดภัย แต่คำว่า "โดยทั่วไป" มีน้ำหนัก — ขอบเขต ปริมาณ และวัตถุประสงค์ล้วนสำคัญ
- โปรเจกต์ขนาดใหญ่หรือเชิงพาณิชย์ควรปรึกษาทนายเกาหลีในพื้นที่เสมอ บทความนี้มีไว้เพื่อให้เห็นภาพ ไม่ใช่คำปรึกษากฎหมาย
ถ้าคุณกำลังมองหาวิธีเริ่มดึงข้อมูลเว็บไซต์เกาหลีอย่างรับผิดชอบ แพ็กเกจฟรีของ Thunderbit ช่วยให้คุณทดลองเวิร์กโฟลว์ในสเกลเล็กได้ สำหรับข้อมูลเพิ่มเติมว่าการดึงข้อมูลด้วย AI ทำงานจริงอย่างไร ดูคู่มือของเราเรื่อง AI web scraping และ web scraping without coding และถ้าอยากดูเครื่องมือทำงานจริง ช่อง YouTube ของเรา มีวิดีโอสอนสำหรับกรณีใช้งานทั่วไป
คำถามที่พบบ่อย
1. การดึงข้อมูลที่เปิดให้สาธารณะในเกาหลีถูกกฎหมายไหม?
โดยทั่วไปใช่ในทางอาญา — ตามคำพิพากษาศาลฎีกา Yanolja การเข้าถึงข้อมูลจากเว็บไซต์ที่ไม่มีข้อจำกัดการเข้าถึงเชิงรูปธรรมไม่ถือว่าละเมิด ICNA อย่างไรก็ดี ความรับผิดทางแพ่งตาม UCPA หรือ Copyright Act อาจยังเกิดขึ้นได้ ขึ้นอยู่กับปริมาณ การลงทุนของต้นทาง และการนำข้อมูลไปใช้เชิงพาณิชย์
2. ฉันถูกฟ้องคดีดึงข้อมูลเว็บในเกาหลีได้ไหม แม้มันไม่เป็นคดีอาญา?
ได้ เส้นคดีอาญาและคดีแพ่งแยกจากกัน GC Company ถูกยกฟ้องทุกข้อหาในคดีอาญา แต่ถูกสั่งให้จ่ายค่าเสียหายทางแพ่งประมาณ 1,000 ล้านวอนภายใต้บทกวาดล้างของ UCPA การยกฟ้องคดีอาญาไม่ได้ป้องกันการฟ้องแพ่ง
3. การละเมิด Terms of Service ของเว็บไซต์ทำให้การดึงข้อมูลในเกาหลีผิดกฎหมายไหม?
ศาลเกาหลีวินิจฉัยอย่างสม่ำเสมอว่าการละเมิด ToS เพียงอย่างเดียวไม่ถือเป็นความผิดอาญาตาม ICNA — ศาลแยกระหว่างการจำกัด การใช้งาน (ToS) กับการจำกัด การเข้าถึง (อุปสรรคทางเทคนิค) อย่างไรก็ดี การละเมิด ToS อาจยังสนับสนุนการเรียกค่าสัญญาเสียหาย หรือใช้เป็นหลักฐานเรื่องเจตนาไม่สุจริตในการวิเคราะห์การแข่งขันที่ไม่เป็นธรรมได้
4. กฎหมายการดึงข้อมูลเว็บของเกาหลีเทียบกับสหรัฐฯ อย่างไร?
ทั้งสองเขตอำนาจคุ้มครองการดึงข้อมูลสาธารณะ (Yanolja ในเกาหลี, hiQ v LinkedIn ในสหรัฐฯ) และทั้งคู่ก็ถือว่าฝ่าฝืน ToS อย่างเดียวไม่ใช่ความผิดอาญา (Van Buren ในสหรัฐฯ) ความแตกต่างสำคัญคือ เกาหลีมีการคุ้มครองฐานข้อมูลตามกฎหมายที่เข้มกว่า และมีบทกวาดล้างเรื่องการแข่งขันที่ไม่เป็นธรรมที่กว้างกว่าสหรัฐฯ ซึ่งไม่มีสิทธิฐานข้อมูลระดับรัฐบาลกลางโดยทั่วไป เจ้าของแพลตฟอร์มในเกาหลีจึงมีเครื่องมือทางแพ่งมากกว่าในการไล่เอาผิดผู้ดึงข้อมูล
5. จะเกิดอะไรขึ้นถ้าฉันดึงข้อมูลส่วนบุคคลจากเว็บไซต์เกาหลี?
PIPA ใช้บังคับไม่ว่าข้อมูลนั้นจะมองเห็นสาธารณะหรือไม่ การเก็บข้อมูลส่วนบุคคล — ชื่อ เบอร์โทร อีเมล — โดยไม่มีความยินยอมหรือฐานกฎหมายอื่นถือเป็นการละเมิด การแก้ไข PIPA ปี 2023 ทำให้การคุ้มครองเข้มขึ้น และแนวทางปี 2024 ของ PIPC เรื่องข้อมูลส่วนบุคคลที่เปิดสาธารณะกล่าวถึง web crawling และ scraping โดยตรง โทษอาจสูงถึงจำคุก 5 ปี ปรับ 50 ล้านวอน และโทษทางปกครองสูงสุด 3% ของยอดขายรวม
ลองใช้ Thunderbit สำหรับการดึงข้อมูลเว็บอย่างรับผิดชอบ Get Started Free
ดูข้อมูลเพิ่มเติม




