
Amazon Web Scraper คืออะไร
Amazon Web Scraper คือเครื่องมือหรือซอฟต์แวร์ที่ออกแบบมาเพื่อดึงข้อมูลจาก Amazon.com แบบอัตโนมัติ ข้อมูลที่ดึงมาได้อาจเป็นรายละเอียดสินค้า ราคา รีวิว สถานะสต็อก และอื่น ๆ จุดประสงค์หลักของการใช้ Amazon Web Scraper คือการรวบรวมข้อมูลจำนวนมากเพื่อใช้ในการวิจัยตลาด เปรียบเทียบราคา หรือวิเคราะห์คู่แข่ง คุณยังสามารถเก็บรีวิวผู้ใช้ไปใช้ทำ keyword research เพื่อดูจุดเด่นและจุดด้อยของสินค้าได้อีกด้วย
ฟีเจอร์เด่นของ Amazon Web Scraper
- ดึงข้อมูลอัตโนมัติ: ลืมงานคัดลอกวางข้อมูลแบบเดิม ๆ ไปได้เลย เครื่องมือ web scraper สามารถเก็บข้อมูลที่ต้องการจากหน้าเว็บให้โดยอัตโนมัติ
- ปรับแต่งการสแกนได้: คุณสามารถกำหนดข้อมูลที่ต้องการดึงให้ตรงกับความต้องการ ช่วยให้วิเคราะห์ได้แบบเจาะจง
- ส่งออกข้อมูลได้ง่าย: นำข้อมูลที่ดึงมาออกเป็นไฟล์ยอดนิยมอย่าง Excel, CSV หรือ JSON เพื่อไปวิเคราะห์ต่อด้วยเครื่องมือข้อมูลอื่น ๆ ได้สะดวก
- อัปเดตสม่ำเสมอ: ตั้งรอบเวลาการสแกนเพื่ออัปเดตฐานข้อมูลสินค้า Amazon ให้เป็นปัจจุบันอยู่เสมอ
- ดึงรีวิวสินค้า: หลายครั้งคุณจำเป็นต้องดึงส่วนข้อดีข้อเสียจากหน้ารีวิวเพื่อใช้วิเคราะห์คู่แข่ง

ทำไมต้องใช้ Amazon Web Scraper
Amazon เป็นผู้เล่นรายใหญ่ในอีคอมเมิร์ซระดับโลก ขึ้นชื่อเรื่องสินค้าที่มีให้เลือกหลากหลาย ราคาที่แข่งขันได้ และประสบการณ์ช้อปปิ้งที่ราบรื่น แพลตฟอร์มนี้ช่วยให้ธุรกิจเข้าถึงลูกค้าทั่วโลกและขยายตลาดได้กว้างขึ้น ผู้บริโภคจำนวนมากเชื่อมั่น Amazon ในฐานะแหล่งซื้อของออนไลน์หลัก เพราะมีสภาพแวดล้อมการขายที่เชื่อถือได้สำหรับผู้ขาย นอกจากนี้เครือข่ายโลจิสติกส์ของ Amazon ยังช่วยให้ธุรกิจส่งมอบสินค้าได้รวดเร็วและมีประสิทธิภาพ เพิ่มความพึงพอใจให้ลูกค้า อีกทั้ง Amazon ยังมีเครื่องมือการตลาดหลายรูปแบบเพื่อช่วยเพิ่มการมองเห็นสินค้าและยอดขาย เช่น โฆษณาสินค้าสปอนเซอร์และการโปรโมตแบรนด์
สำหรับธุรกิจอีคอมเมิร์ซ การวิเคราะห์ข้อมูลยอดขายบน Amazon เป็นเรื่องสำคัญมาก การใช้ Amazon Web Scraper ช่วยให้ธุรกิจรวบรวมข้อมูลเพื่อ เข้าใจแนวโน้มตลาด และ พฤติกรรมผู้บริโภค พร้อม ปรับกลยุทธ์สินค้า และ การจัดการสต็อก ได้อย่างมีประสิทธิภาพ สิ่งนี้ช่วยให้ธุรกิจเติบโตบนแพลตฟอร์ม Amazon ได้ดีขึ้น เพิ่มยอดขายและการรับรู้แบรนด์เพื่อการเติบโตระยะยาว ต่อไปนี้คือวิธีใช้ Amazon Web Scraper เพื่อการวิเคราะห์:
วิจัยตลาด
-
การเลือก SKU
การเลือก SKU (Stock-Keeping Unit) ที่เหมาะสมคือหัวใจของความสำเร็จในอีคอมเมิร์ซ เพราะส่งผลต่อการคัดสรรสินค้า ประสิทธิภาพของซัพพลายเชน และการบริหารสต็อก เมื่อใช้ Amazon Web Scraper คุณสามารถดึงข้อมูลเชิงลึกจากสินค้านับล้านรายการเพื่อนำมาวิเคราะห์แนวโน้มยอดขายและความต้องการของลูกค้าได้ ตัวอย่างเช่น หากสแกนหน้า Product Detail ของ Amazon คุณจะเข้าถึงข้อมูลสำคัญอย่างราคา จำนวนรีวิว และคะแนนผู้ขาย เพื่อใช้วิเคราะห์ตลาดเชิงลึก ข้อมูลเหล่านี้ช่วยประเมินได้ว่า SKU นั้นมีศักยภาพในตลาดหรือไม่ และสินค้าประเภทใดทำผลงานได้ดีที่สุด เมื่อเปรียบเทียบสินค้าภายในหมวดเดียวกัน ธุรกิจสามารถปรับการเลือกสินค้า เพิ่มสต็อกให้ SKU ที่ขายดี และลดสต็อกสินค้าที่เคลื่อนไหวช้า เพื่อเพิ่มอัตราการหมุนเวียนของสินค้าในคลัง
-
จับสัญญาณเทรนด์ลูกค้า
ด้วยการสแกนรีวิว คะแนน และฟีดแบ็กจากลูกค้าในปริมาณมาก web scraper สามารถช่วยให้คุณมองเห็นการเปลี่ยนแปลงของความต้องการผู้บริโภคได้อย่างรวดเร็ว ตัวอย่างเช่น การวิเคราะห์ข้อมูลรีวิวจะช่วยชี้ให้เห็นว่าลูกค้าให้ความสำคัญกับคุณสมบัติใดของสินค้ามากที่สุด เช่น "ราคาคุ้มค่า" หรือ "ความทนทาน" ข้อมูลนี้มีประโยชน์มากต่อการพัฒนาสินค้า กลยุทธ์ราคา และกลยุทธ์การตลาด นอกจากนี้ การสแกนข้อมูลความถี่ในการซื้อและแนวโน้มยอดขายตามช่วงเวลา ยังช่วยคาดการณ์ความผันผวนตามฤดูกาล และวางแผนสต็อกกับกิจกรรมการตลาดล่วงหน้าได้

วิเคราะห์คู่แข่ง
-
ติดตามราคา
ในตลาดที่การแข่งขันสูง การติดตามราคาเป็นสิ่งจำเป็นสำหรับธุรกิจอีคอมเมิร์ซ Amazon Web Scraper ช่วยดึงข้อมูลสินค้าแบบเรียลไทม์เพื่อติดตามการเปลี่ยนแปลงราคาของคู่แข่ง ทำให้คุณรักษาระดับราคาที่แข่งขันได้ ฟีเจอร์นี้มีประโยชน์อย่างยิ่งสำหรับการทำ dynamic pricing โดยเก็บข้อมูลราคาของสินค้าที่คล้ายกัน ธุรกิจสามารถสร้างโมเดลราคาที่ยืดหยุ่นและปรับราคาอัตโนมัติตามความต้องการตลาด ระดับสต็อก และราคาคู่แข่ง เพื่อเพิ่มกำไรสูงสุด
-
สแกนรีวิว
รีวิวจากลูกค้า ไม่เพียงส่งผลต่อยอดขาย แต่ยังสะท้อนการเปลี่ยนแปลงของความต้องการในตลาดอีกด้วย Amazon Web Scraper ช่วยให้ธุรกิจรวบรวมฟีดแบ็กจากลูกค้าได้จำนวนมาก โดย AI web scraper ยังช่วยสรุปและวิเคราะห์อารมณ์ความรู้สึก เพื่อให้เข้าใจมุมมองของผู้ใช้ที่มีต่อสินค้าของคุณและคู่แข่งได้ชัดเจนขึ้น ช่วยให้คุณปรับดีไซน์สินค้า หรือกลยุทธ์การตลาดได้อย่างทันท่วงที
เปรียบเทียบต้นทุน
เมื่อใช้ Amazon Web Scraper ธุรกิจสามารถเก็บข้อมูลราคาสินค้าที่ใกล้เคียงกัน ค่าขนส่ง และโปรโมชันต่าง ๆ เพื่อนำมาเปรียบเทียบต้นทุนได้อย่างครอบคลุม การวิเคราะห์ข้อมูลนี้ช่วยให้ธุรกิจปรับโครงสร้างต้นทุน ลดค่าใช้จ่ายที่ไม่จำเป็น และเพิ่มอัตรากำไร หากกำลังมองหาซัพพลายเออร์บน Amazon ข้อมูลนี้ยังช่วยให้เห็นภาพค่าจัดส่งและราคาขายของผู้ขายแต่ละราย ทำให้ลดต้นทุนและตั้งราคาได้แข่งขันในตลาดมากขึ้น สุดท้ายก็ช่วยเพิ่มอัตรากำไรขั้นต้นได้ดีขึ้น
ลองใช้ AI ช่วยสแกนเว็บ
ลองเลย! คุณสามารถคลิก สำรวจ และรันเวิร์กโฟลว์ไปพร้อมกับดูการทำงานได้
ทำไมต้องใช้ AI ในการสแกนข้อมูลสินค้า Amazon
เมื่อ AI พัฒนาอย่างรวดเร็ว เครื่องมือ Amazon Web Scraper ที่ขับเคลื่อนด้วย AI กำลังก้าวเข้ามาเป็นตัวเลือกใหม่ของการดึงข้อมูล ช่วยยกระดับกระบวนการสแกนเว็บแบบเดิมไปอีกขั้น AI ไม่เพียงทำให้การเก็บข้อมูลมีประสิทธิภาพและแม่นยำมากขึ้น แต่ยังลดอุปสรรคด้านเทคนิคลงอย่างมาก เปิดโอกาสใหม่ ๆ ที่สร้างสรรค์ให้กับธุรกิจอีคอมเมิร์ซ
ใช้งานง่ายสำหรับคนไม่สายเทคนิค
สำหรับผู้ใช้ที่ไม่มีพื้นฐานด้านเทคนิค เครื่องมือ Amazon Web Scraper ที่มี AI ช่วยให้ใช้งานได้สะดวกมาก ต่างจาก scraper แบบดั้งเดิมที่ต้องเขียนโค้ดและเรียก API เอง ผู้ใช้เพียงระบุความต้องการในการดึงข้อมูลและเลือกชื่อคอลัมน์ที่ต้องการ AI จะสร้างแผนการสแกนและข้อเสนอแนะที่เหมาะสมให้อัตโนมัติ ลดความยุ่งยากเรื่องการเขียนโปรแกรมและการตั้งค่าที่ซับซ้อน ฟีเจอร์ที่ใช้งานง่ายนี้ช่วยให้ทีมอีคอมเมิร์ซดึงข้อมูลได้อย่างมีประสิทธิภาพโดยไม่ต้องพึ่งผู้เชี่ยวชาญด้านเทคนิค เพิ่มประสิทธิภาพการทำงานของทีม และทำให้พนักงานที่ไม่ใช่สายเทคนิคใช้เครื่องมือเก็บข้อมูลขั้นสูงได้ง่ายขึ้น
รวดเร็วและมีประสิทธิภาพ
ดึงข้อมูลจากเว็บไซต์ใดก็ได้ด้วย AI Get Started Free
AI Web Scraper ช่วยทำให้กระบวนการดึงข้อมูลเป็นอัตโนมัติ เพิ่มความเร็วและประสิทธิภาพของการสแกนเว็บอย่างเห็นได้ชัด เครื่องมือนี้รับมือกับโครงสร้างเว็บที่ซับซ้อนและคอนเทนต์แบบไดนามิกได้อย่างรวดเร็ว ดึงข้อมูลเป้าหมายได้แม่นยำ ลดการทำงานด้วยมือ และเพิ่มความถูกต้องโดยรวม นอกจากนี้ AI Web Scraper ยังช่วยลดต้นทุนการดำเนินงานและปรับเวิร์กโฟลว์ให้คล่องตัวขึ้น ทำให้ธุรกิจได้ข้อมูลคุณภาพสูงในต้นทุนที่ต่ำกว่า และนำไปใช้สนับสนุนการตัดสินใจได้แม่นยำยิ่งขึ้น
การวิเคราะห์และคำแนะนำอัจฉริยะ
เมื่อเทียบกับ web scraper แบบดั้งเดิม AI web scraper มีข้อได้เปรียบเรื่องการทำงานอัตโนมัติแบบอัจฉริยะ เครื่องมือ AI สามารถจัดหมวดหมู่ข้อมูล สรุปข้อมูล และให้ insight ได้โดยอัตโนมัติ ตัวอย่างเช่น ธุรกิจสามารถใช้ AI เพื่อจัดกลุ่มสินค้าตามหมวดหมู่ที่กำหนดไว้ล่วงหน้า หรือวิเคราะห์ข้อมูลรีวิวจำนวนมากเพื่อดึงคีย์เวิร์ดและแนวโน้มของอารมณ์ความรู้สึก ช่วยให้เข้าใจฟีดแบ็กลูกค้าได้ดีขึ้นและปรับปรุงสินค้าได้ตรงจุด AI ยังสามารถสร้างรายงานแบบกำหนดเองจากข้อมูลที่สแกนมา พร้อมสรุปการวิเคราะห์ตลาดให้อัตโนมัติ ช่วยให้ธุรกิจมองเห็นจุดเด่นของสินค้ายอดนิยมและโอกาสทางการตลาดได้เร็วขึ้น
รูปแบบผลลัพธ์และตัวเลือกการส่งออกที่ชาญฉลาด
การใช้ Amazon web scraper ที่ขับเคลื่อนด้วย AI ช่วยให้การแสดงผลข้อมูลฉลาดขึ้น วิธีเขียนโค้ดแบบเดิมมักส่งออกได้แค่ไฟล์ CSV แต่เครื่องมือ AI รองรับทั้ง CSV และยังส่งออกข้อมูลที่สแกนไปยังแพลตฟอร์มทำงานร่วมกันอย่าง Google Sheets และ Notion ได้โดยอัตโนมัติ ทำให้การวิเคราะห์และการแชร์ข้อมูลง่ายขึ้นมาก ตัวอย่างเช่น คุณสามารถนำข้อมูลเข้า Google Sheets เพื่อวิเคราะห์แบบเรียลไทม์ หรือเชื่อมต่อกับเครื่องมือทำงานร่วมกันของทีม เพื่อให้ข้อมูลไหลลื่นระหว่างแผนกอย่างไร้รอยต่อ วิธีส่งออกข้อมูลอัจฉริยะนี้ช่วยให้ทีมตัดสินใจได้เร็วขึ้น เพิ่มความยืดหยุ่นและการตอบสนองของธุรกิจโดยรวม
สแกนด้วย Thunderbit: AI Web Scraper
Thunderbit คือเครื่องมือ web scraper แบบ AI ที่เพิ่งเปิดตัว มีความทรงพลังและครบวงจร ออกแบบมาเพื่อตอบโจทย์ความต้องการด้านข้อมูลของคุณ ด้วย Thunderbit ผู้ใช้สามารถเก็บข้อมูลจาก Amazon ได้อย่างง่ายดาย ไม่ว่าจะเป็นรายละเอียดสินค้า ความเคลื่อนไหวของราคา หรือรีวิวลูกค้า แล้วเปลี่ยนเป็น insight ทางธุรกิจได้อย่างรวดเร็ว มาดูกันว่า Thunderbit ช่วยเพิ่มความสามารถในการแข่งขันให้ธุรกิจอีคอมเมิร์ซได้อย่างไร
เริ่มจากเข้าไปที่ เว็บไซต์ Thunderbit แล้วเพิ่มส่วนขยาย web scraper extension ของ Thunderbit ลงในเบราว์เซอร์ Chrome ของคุณ จากนั้นล็อกอินด้วยบัญชี Google หรืออีเมลอื่น ๆ
 จากนั้นคุณสามารถใช้ web scraper ที่ติดตั้งมาใน Thunderbit หรือ AI web scraper เพื่อ สแกนข้อมูลสินค้าและรีวิว Amazon ได้ วิธีใช้งานมีดังนี้:
จากนั้นคุณสามารถใช้ web scraper ที่ติดตั้งมาใน Thunderbit หรือ AI web scraper เพื่อ สแกนข้อมูลสินค้าและรีวิว Amazon ได้ วิธีใช้งานมีดังนี้:
ตัวเลือกที่ 1: ใช้ Web Scraper สำเร็จรูปของ Thunderbit
Thunderbit ได้ออกแบบและปรับแต่งเครื่องมือ web scraper สำเร็จรูปหลายแบบตามความต้องการของผู้ใช้ รวมถึงโมดูลที่สร้างมาเฉพาะสำหรับ Amazon เครื่องมือเหล่านี้มีเทมเพลตที่เตรียมไว้ล่วงหน้าสำหรับโครงสร้างข้อมูลที่ซับซ้อนของ Amazon และเก็บข้อมูลจำนวนมากไว้แล้ว ช่วยลดภาระการออกแบบตรรกะการสแกนเอง และทำให้กระบวนการเก็บข้อมูลเร็วขึ้นและมีประสิทธิภาพมากขึ้น
เมื่อคุณเปิดหน้าใดก็ได้บน Amazon ให้เปิด web scraper ในส่วนขยาย Thunderbit คุณจะเห็น scraper สำเร็จรูป 2 แบบพร้อมชื่อคอลัมน์ให้เลือกมากมาย เพียงติ๊กเลือกคอลัมน์ที่ต้องการดึงข้อมูล แล้วปล่อยให้ Thunderbit จัดการส่วนที่เหลือ
-
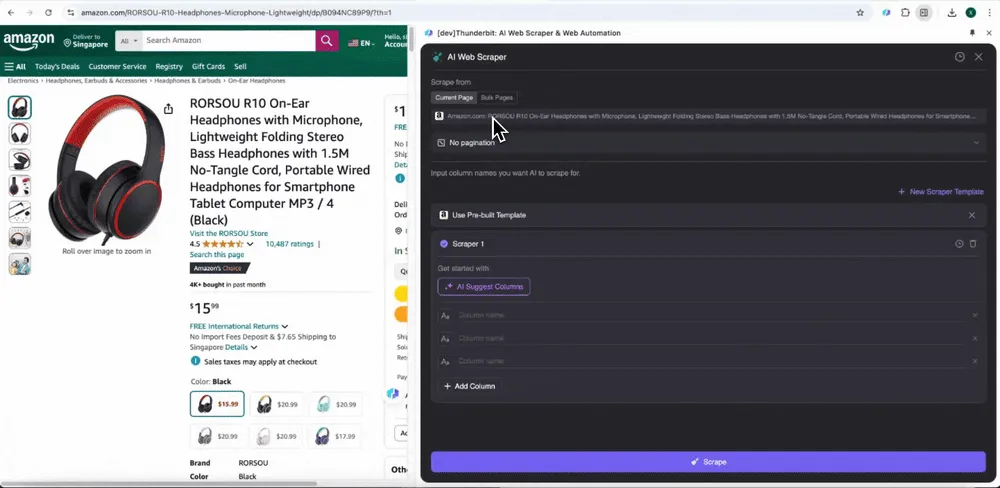
Amazon Collect SKU Reviews
เครื่องมือนี้มีชื่อคอลัมน์สำเร็จรูป เช่น ชื่อสินค้า URL สินค้า คะแนนสินค้าโดยรวม รายละเอียดคะแนนย่อย จำนวนรีวิวสินค้า ชื่อรีวิว ชื่อผู้เขียน เนื้อหารีวิว ประเทศของรีวิว และคีย์เวิร์ด คุณสามารถเลือกคอลัมน์ที่ต้องการดึงข้อมูล กด scrape แล้วรับข้อมูลรีวิว SKU ที่ต้องใช้สำหรับการวิเคราะห์รีวิวสินค้าได้อย่างรวดเร็ว
-
Amazon Collect SKU Details
เครื่องมือนี้มีชื่อคอลัมน์สำเร็จรูป เช่น ชื่อสินค้า URL สินค้า แบรนด์ ผู้ผลิต ราคาเริ่มต้น ราคาสุดท้าย คำอธิบาย คะแนน หมวดหมู่ ตัวเลือกการจัดส่ง และ URL ผู้ขาย เพียงเลือกคอลัมน์ที่ต้องการดึงข้อมูล กด scrape แล้วรับข้อมูลรายละเอียด SKU ได้ทันที ไม่ว่าจะใช้เปรียบเทียบผู้ขาย ผู้ผลิต และตัวเลือกการจัดส่ง ทำวิจัยตลาด ประเมินความสามารถในการแข่งขันด้านราคา หรือทำความเข้าใจแนวโน้มยอดขายล่าสุด ข้อมูลรายละเอียด SKU เหล่านี้ก็ช่วยต่อยอดการวิเคราะห์ได้มาก
ตัวเลือกที่ 2: ใช้ AI Web Scraper ของ Thunderbit
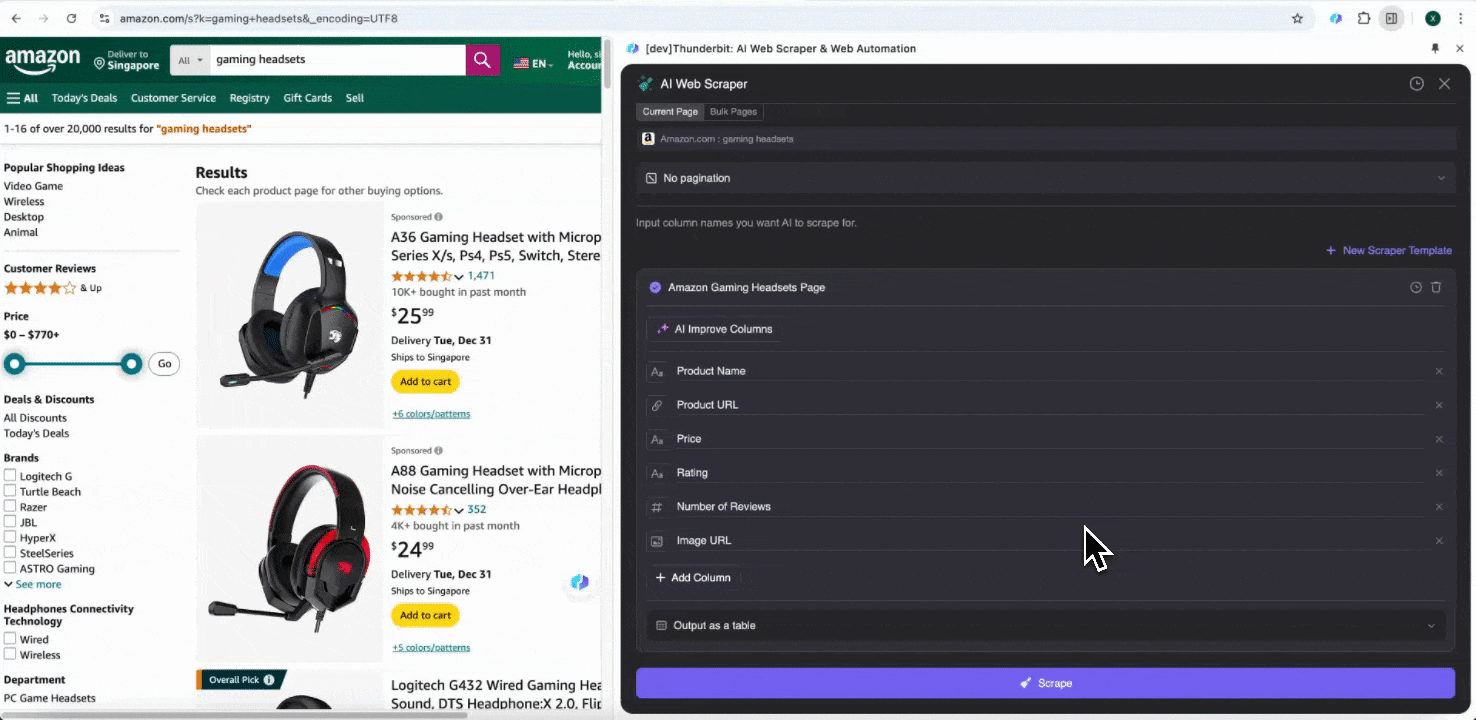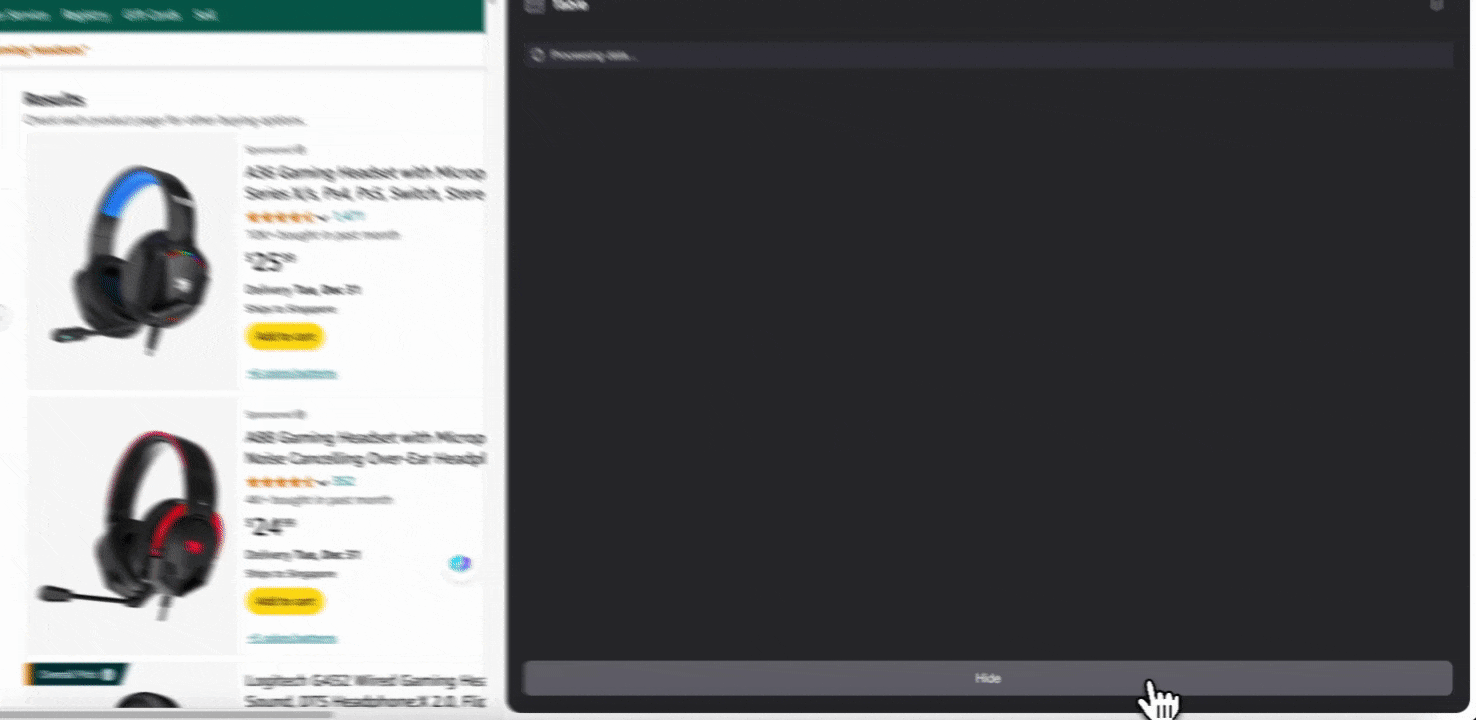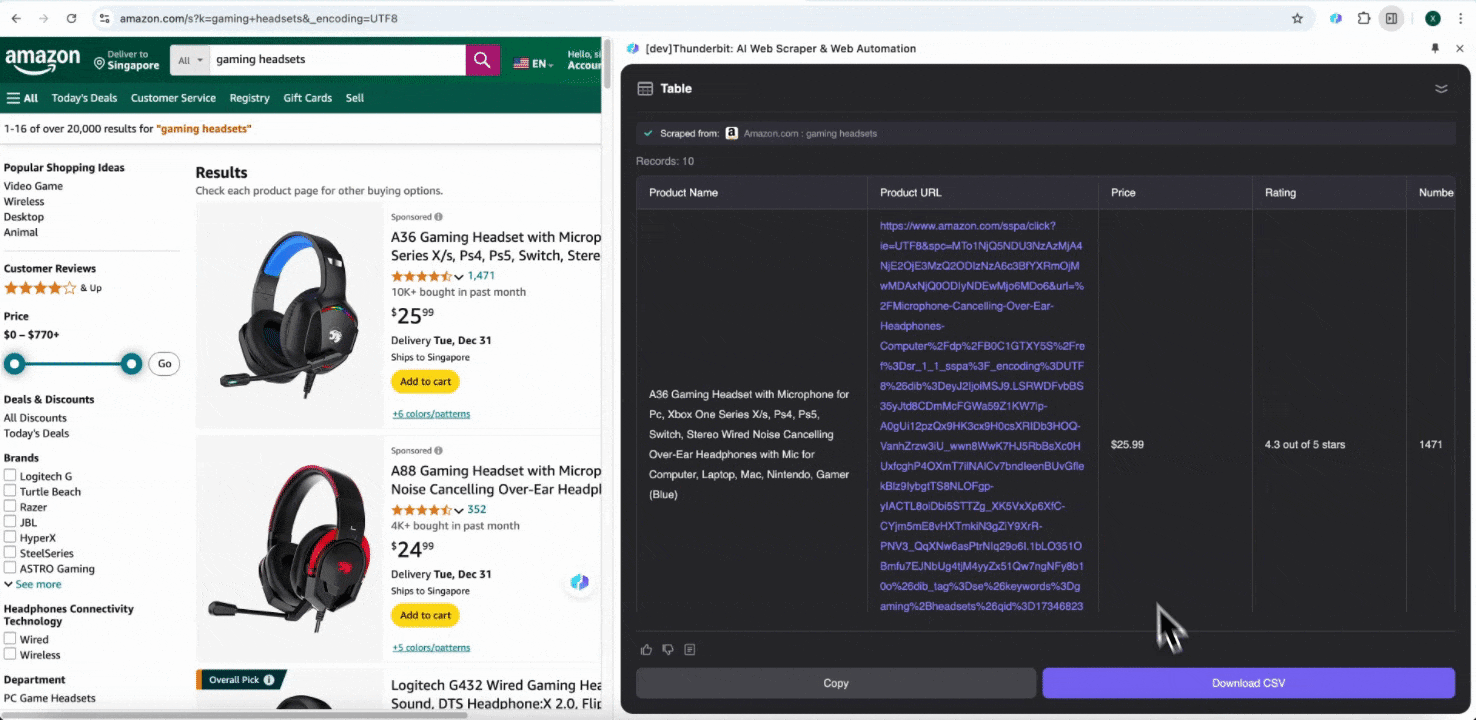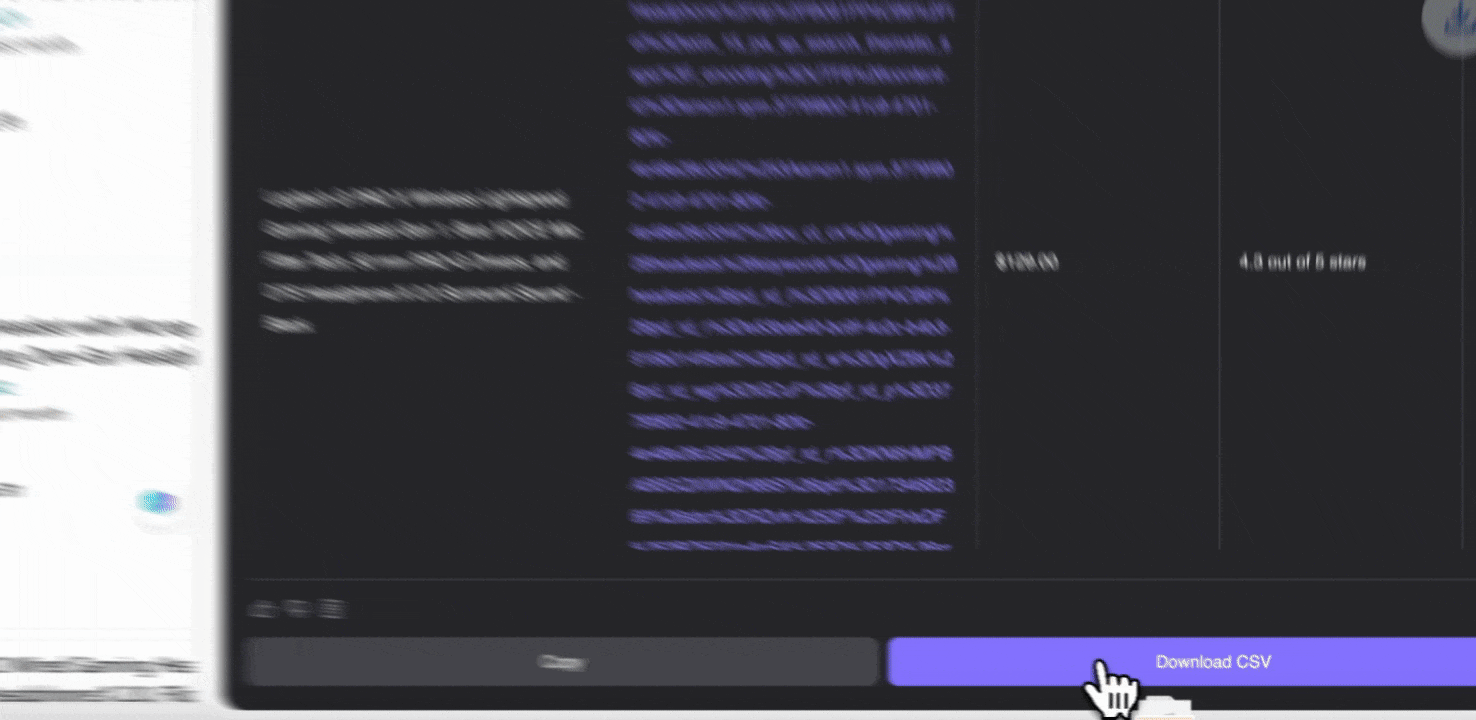
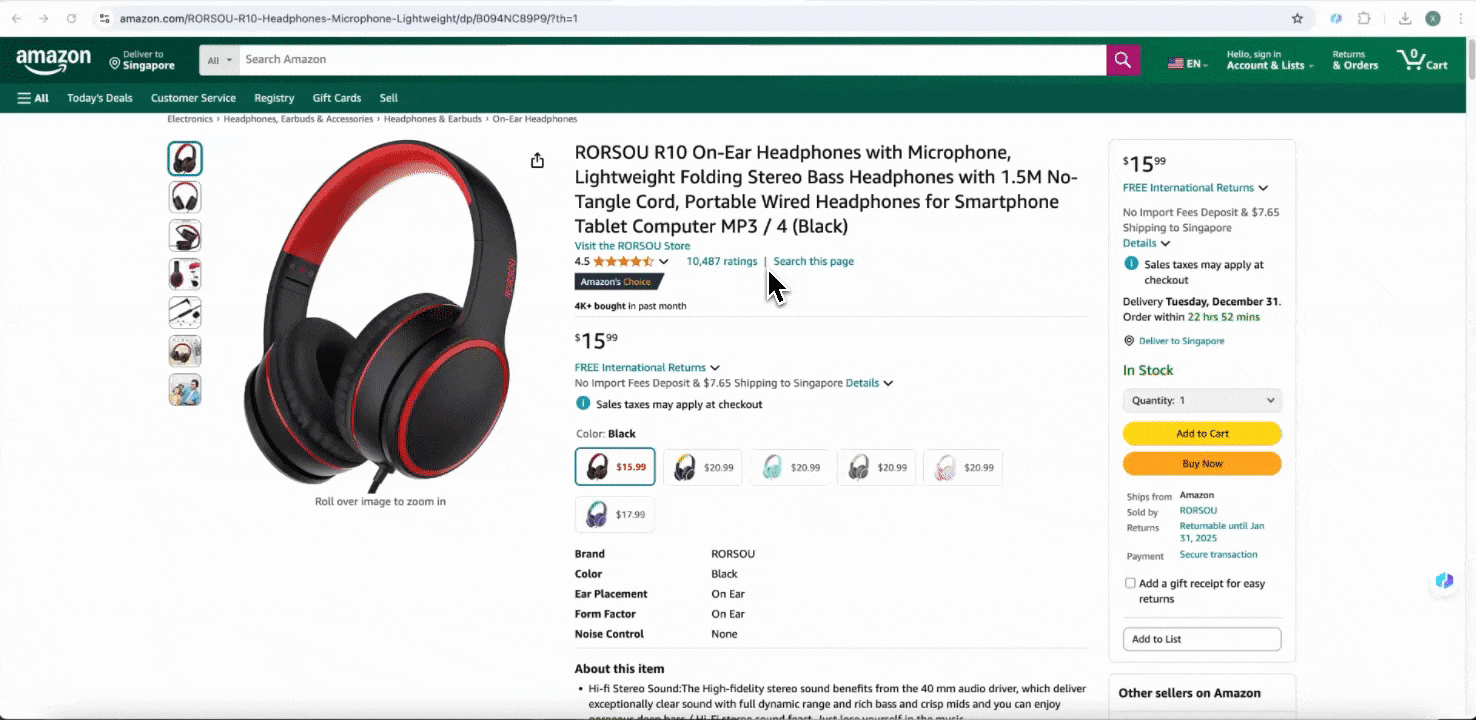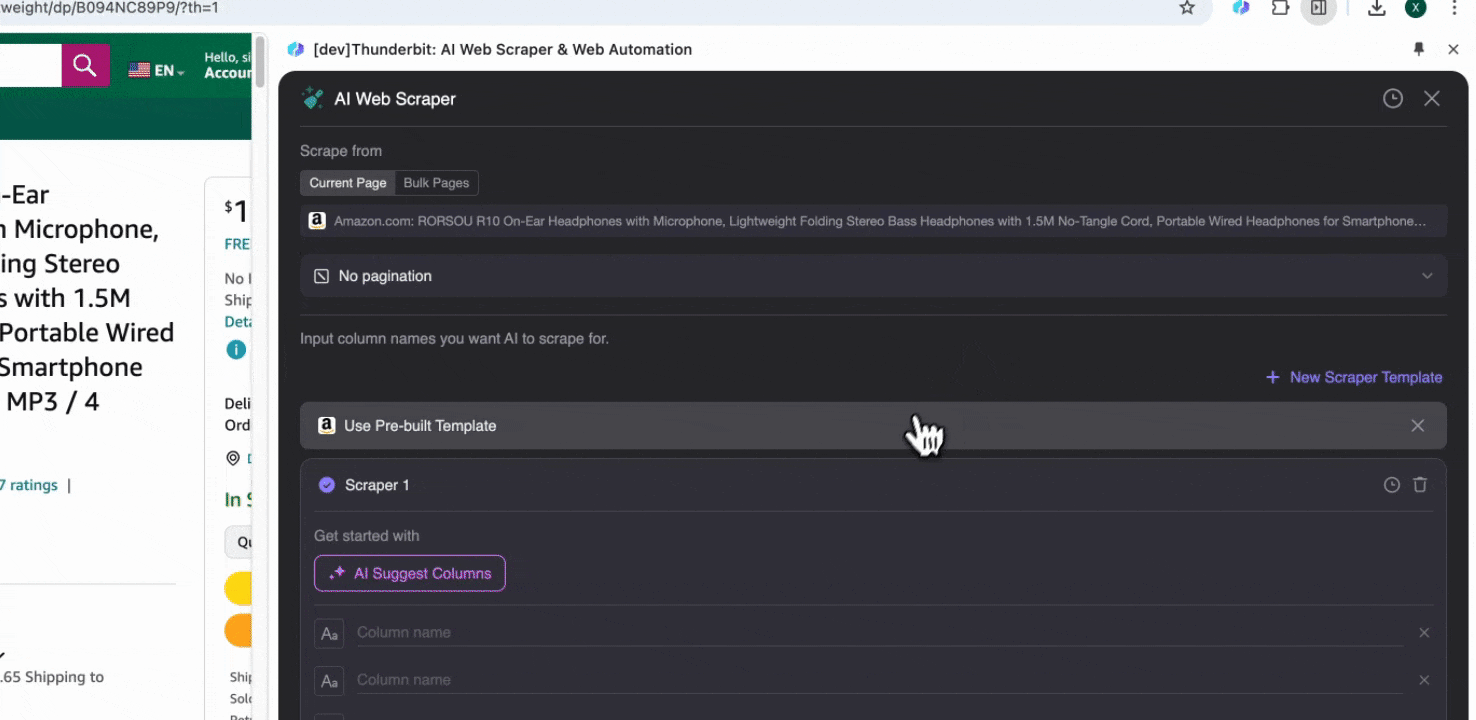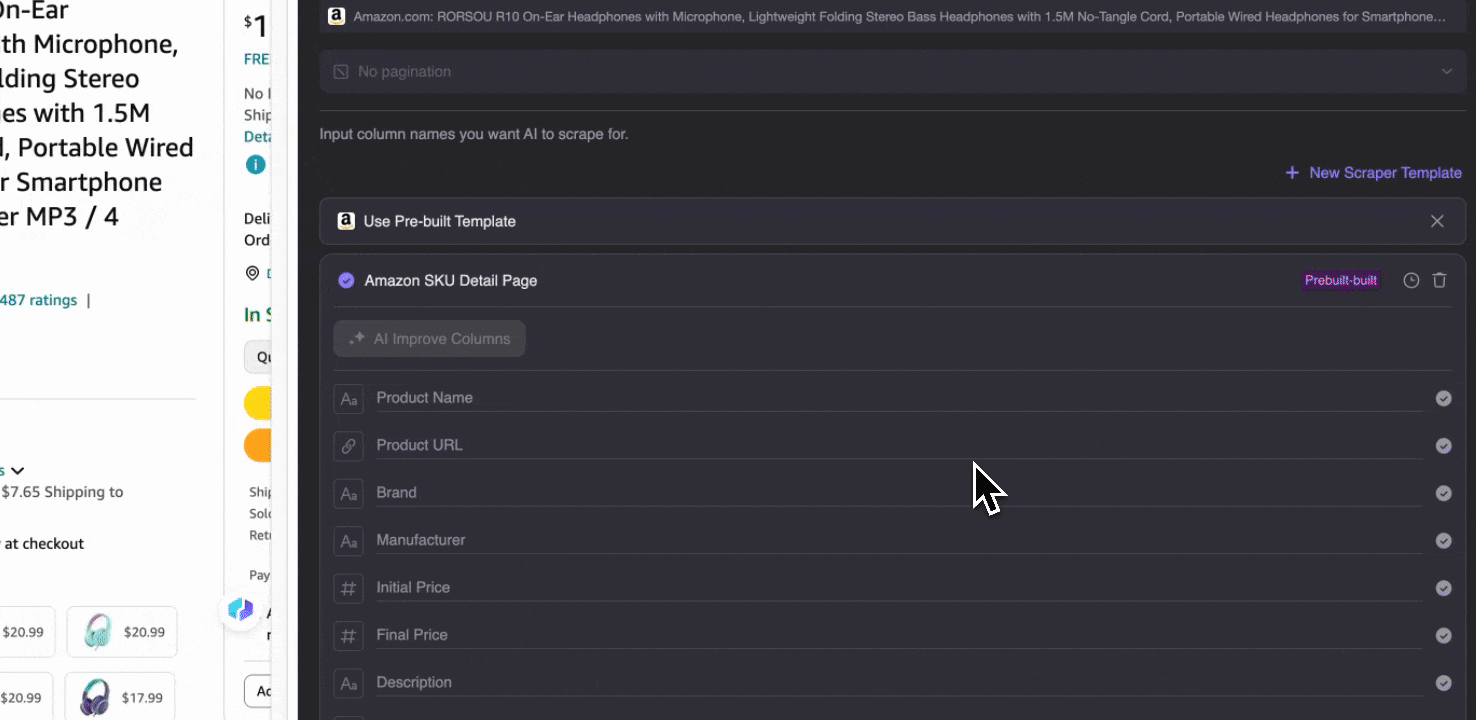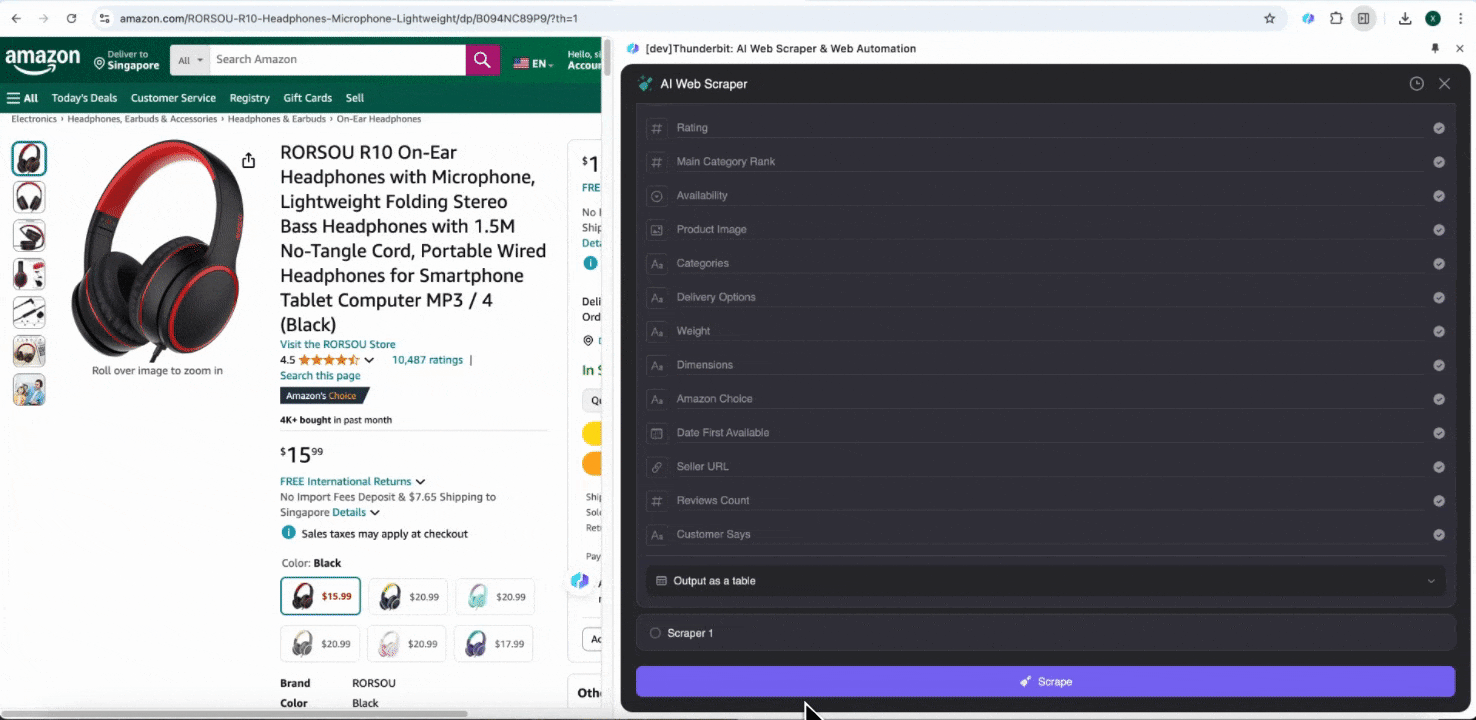
ขั้นตอนที่ 1: เปิด Amazon.com แล้วคลิก “AI Web Scraper” ที่แถบด้านข้าง
เปิด เว็บไซต์ Amazon ใน Chrome แล้วค้นหาหรือเปิดหน้าที่ต้องการดึงข้อมูล จากนั้นคลิกไอคอน Thunderbit มุมขวาบนของ Chrome เพื่อเปิดส่วนขยาย Thunderbit แล้วกด “AI Web Scraper”
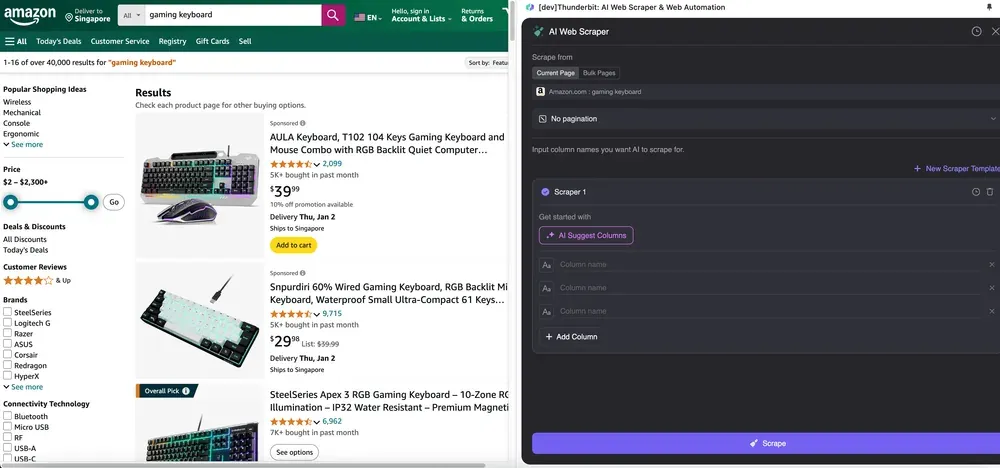
ขั้นตอนที่ 2: ปรับแต่งฟิลด์ข้อมูลที่ต้องการดึง
หากคุณยังไม่แน่ใจว่าจะเลือกแท็กข้อมูลใด ให้คลิก AI Suggest Columns เพื่อให้ AI ของ Thunderbit สร้างชื่อคอลัมน์ที่เหมาะสมให้อัตโนมัติ คุณยังสามารถอธิบายชื่อข้อมูลที่ต้องการด้วยภาษาธรรมชาติแล้วกรอกลงในช่องชื่อคอลัมน์ได้ เลือกไอคอนเพื่อเปลี่ยนชนิดข้อมูลที่ต้องการ ไม่ว่าจะเป็นรูปภาพ URL ข้อความ ตัวเลข หรือประเภทข้อมูลอื่น ๆ แล้วดึงข้อมูลตามที่ต้องการ
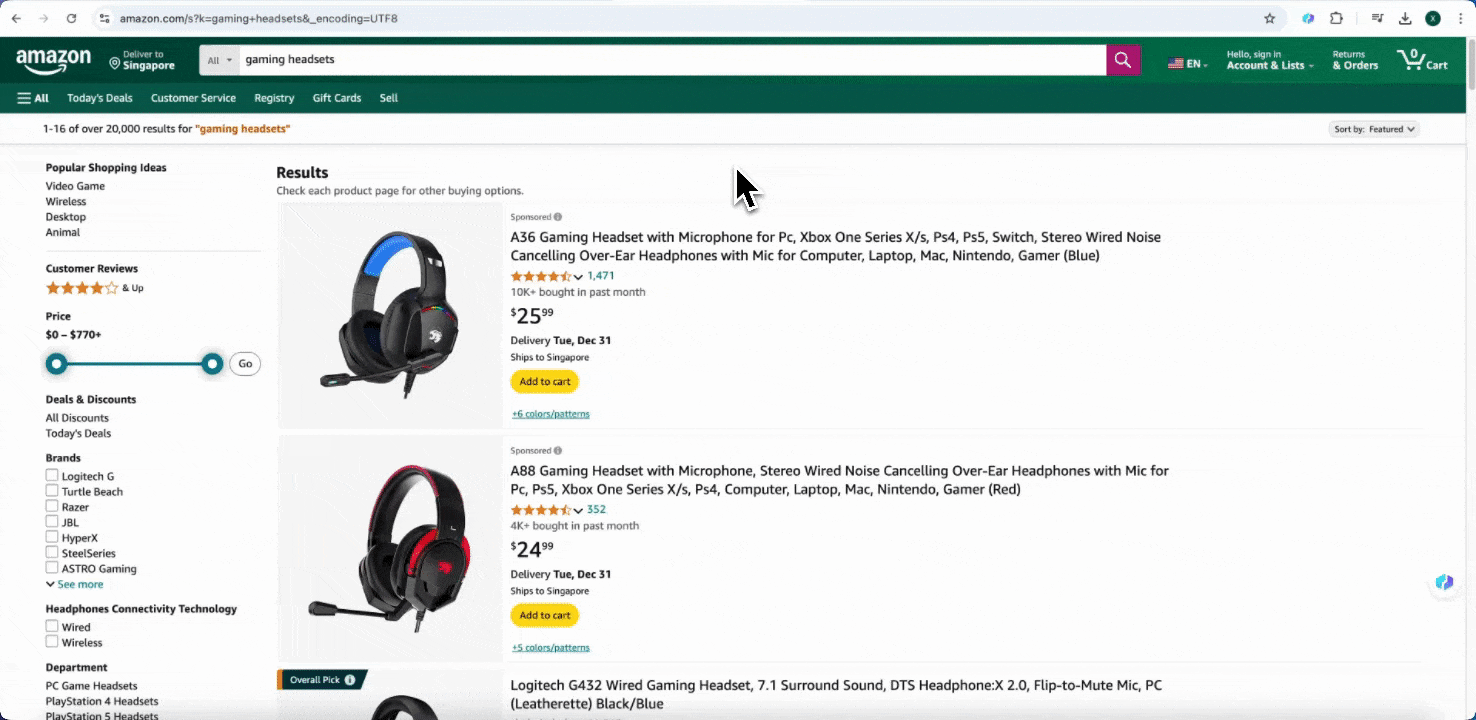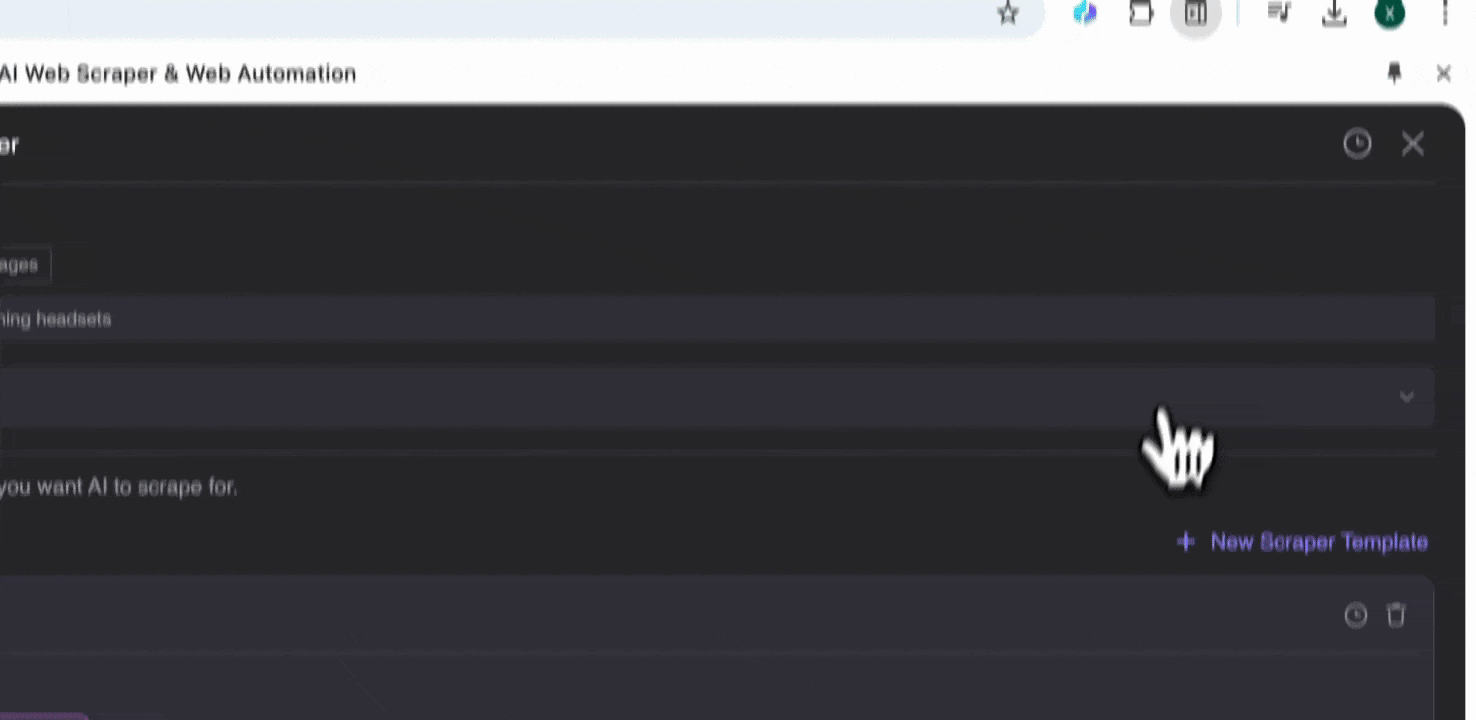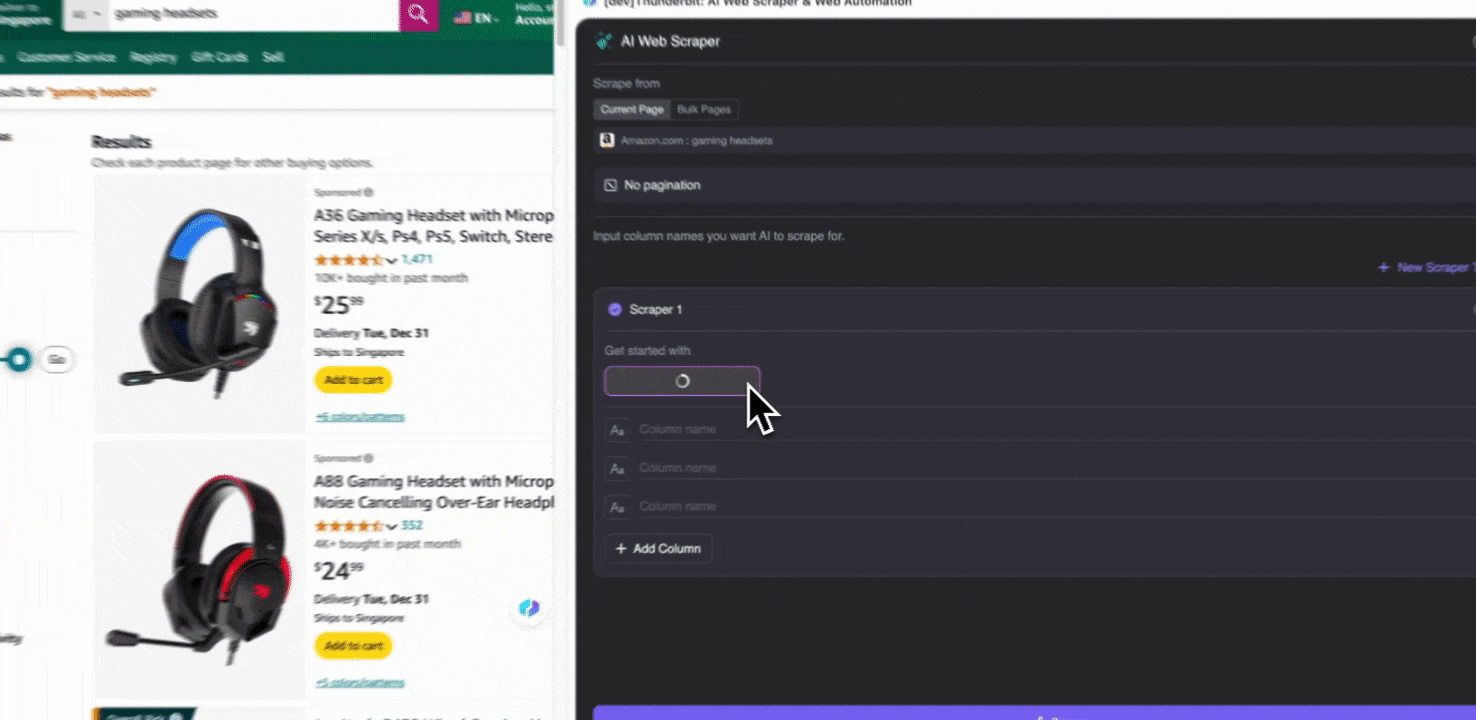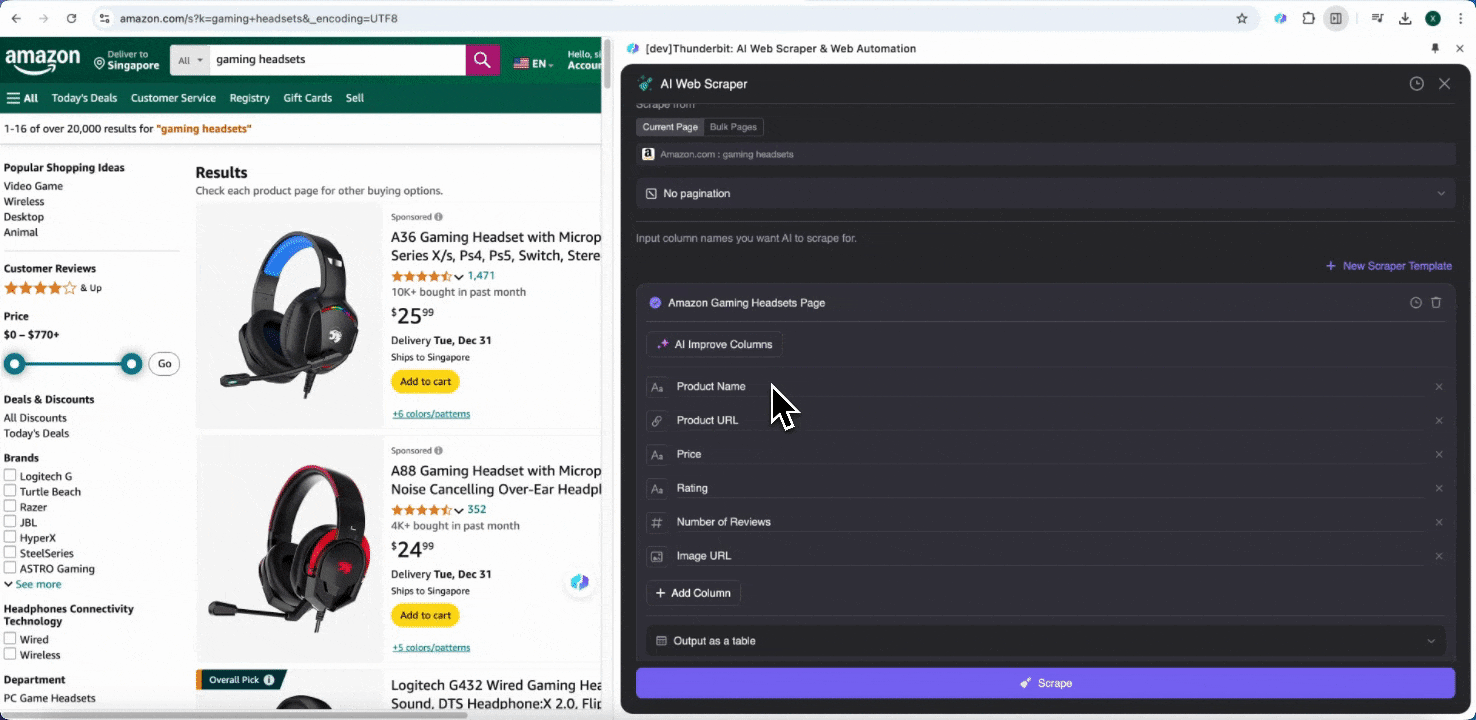
หลังจากกรอกชื่อคอลัมน์เริ่มต้นแล้ว คุณสามารถเลือก AI Improve Columns เพื่อให้ AI ช่วยปรับปรุงรายการของคุณให้ดียิ่งขึ้นได้ และยังสามารถเพิ่มคำแนะนำรายละเอียดของคอลัมน์เพื่อปรับแต่งตามต้องการได้ เช่น คุณอาจขอให้คอลัมน์ประเภทสินค้าจัดหมวดสินค้าเป็น ผู้ชาย ผู้หญิง เด็ก และหมวดหมู่อื่น ๆ Thunderbit จะจัดข้อมูลแต่ละรายการในคอลัมน์นั้นให้เข้าไปอยู่ใน 4 หมวดที่คุณกำหนดไว้ นอกจากนี้คุณยังสามารถขอให้ Thunderbit แปลงราคาทั้งหมดในคอลัมน์ราคาให้เป็นสกุลเงินที่ต้องการตามอัตราแลกเปลี่ยนปัจจุบัน เพื่อให้ได้ค่าที่พร้อมใช้วิเคราะห์โดยไม่ต้องกังวลเรื่องสกุลเงินที่ไม่สอดคล้องกัน
สุดท้าย คุณสามารถกำหนดปริมาณข้อมูลที่ต้องการได้ สำหรับหน้า Amazon product pages คุณสามารถเลือกคลิก pagination และกำหนดจำนวนหน้าที่ต้องการสแกน Thunderbit จะเปลี่ยนหน้าให้อัตโนมัติและดึงข้อมูลจากทุกหน้า
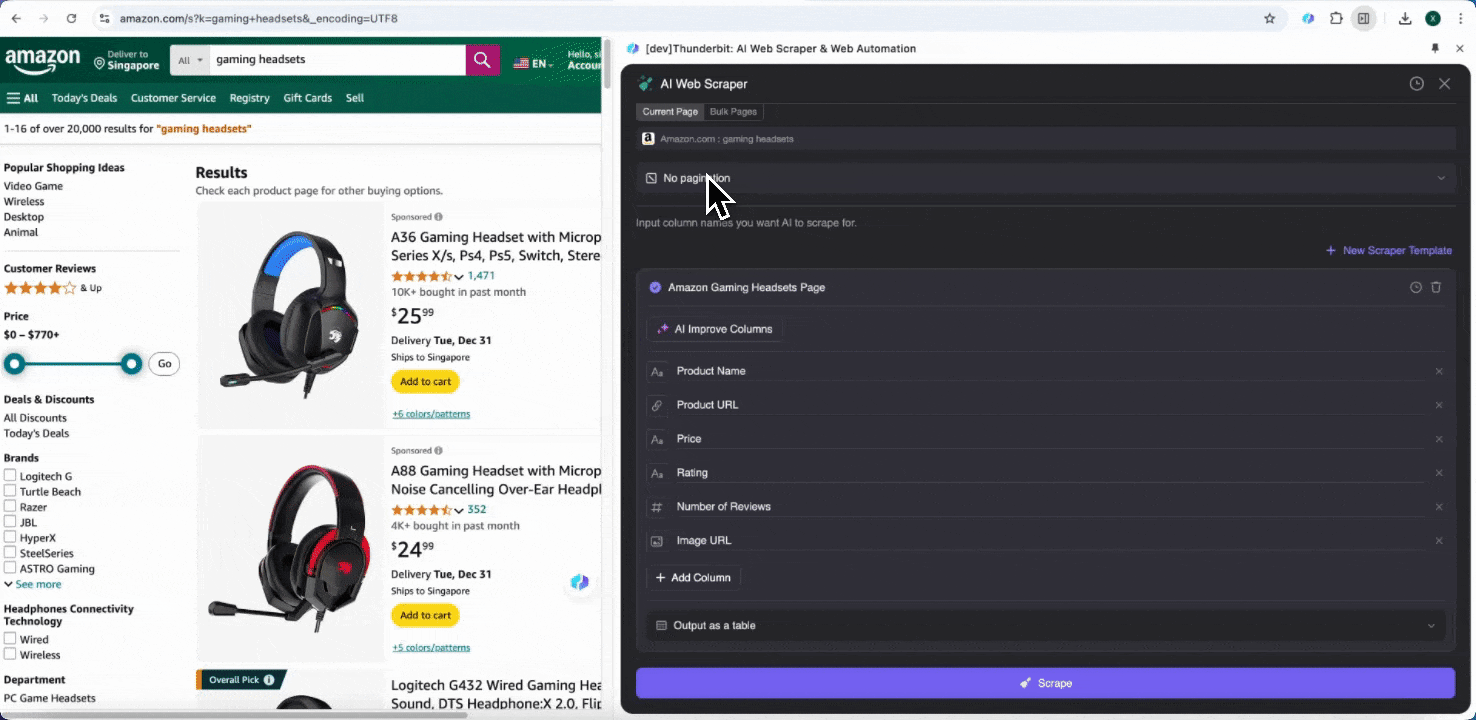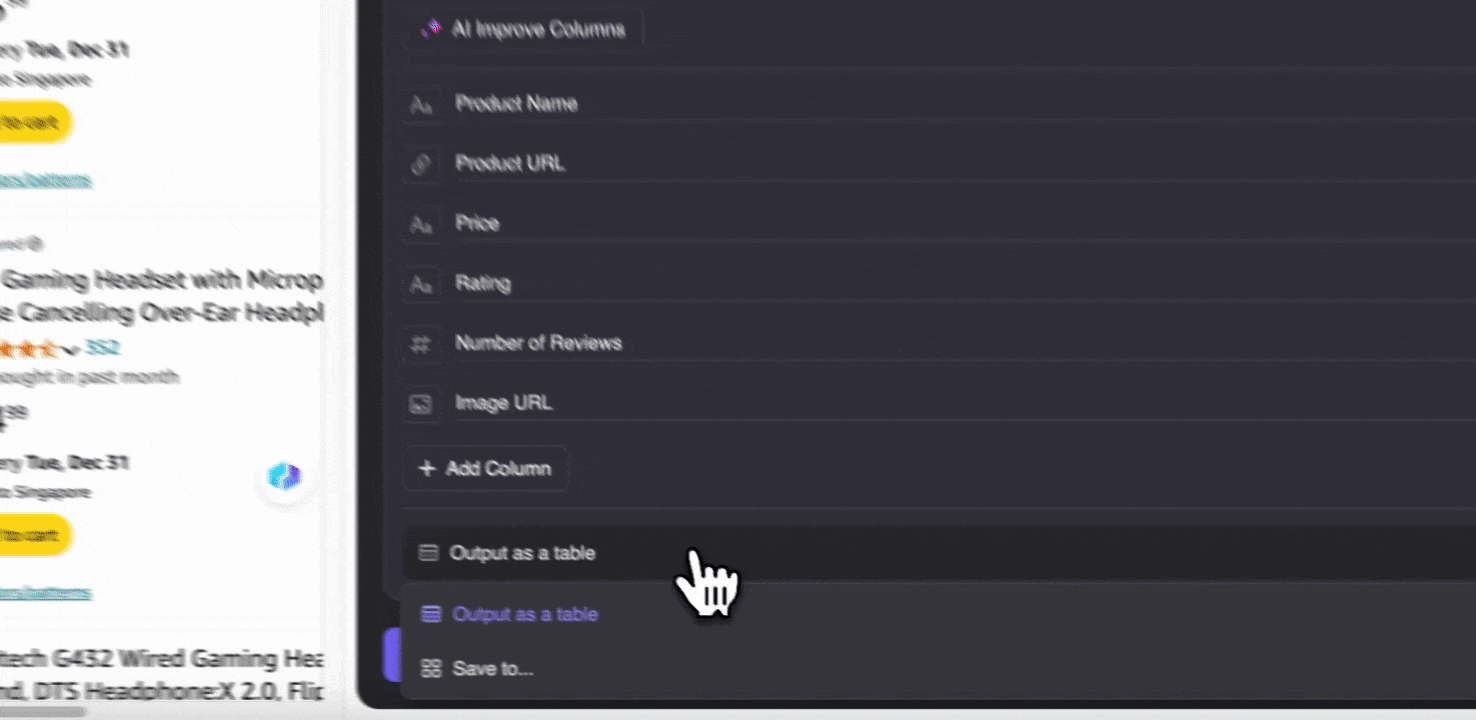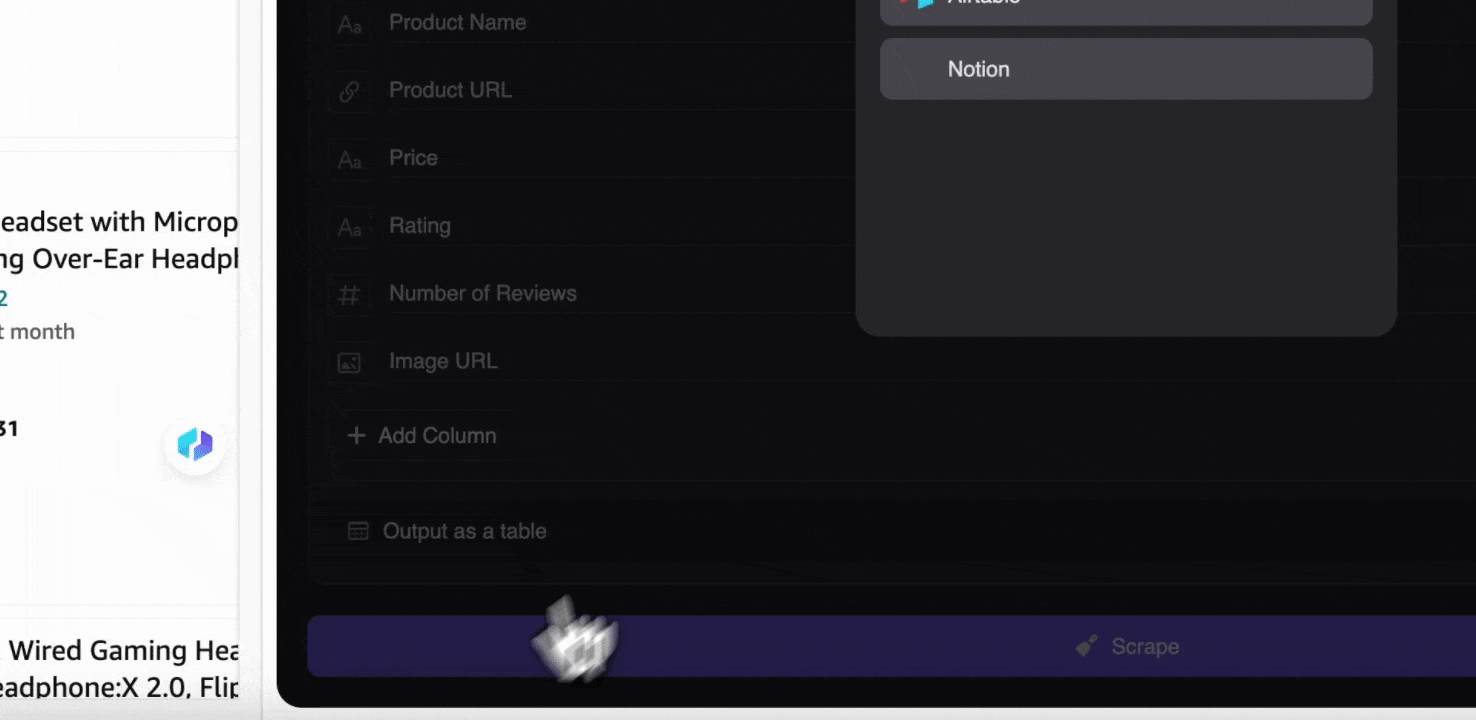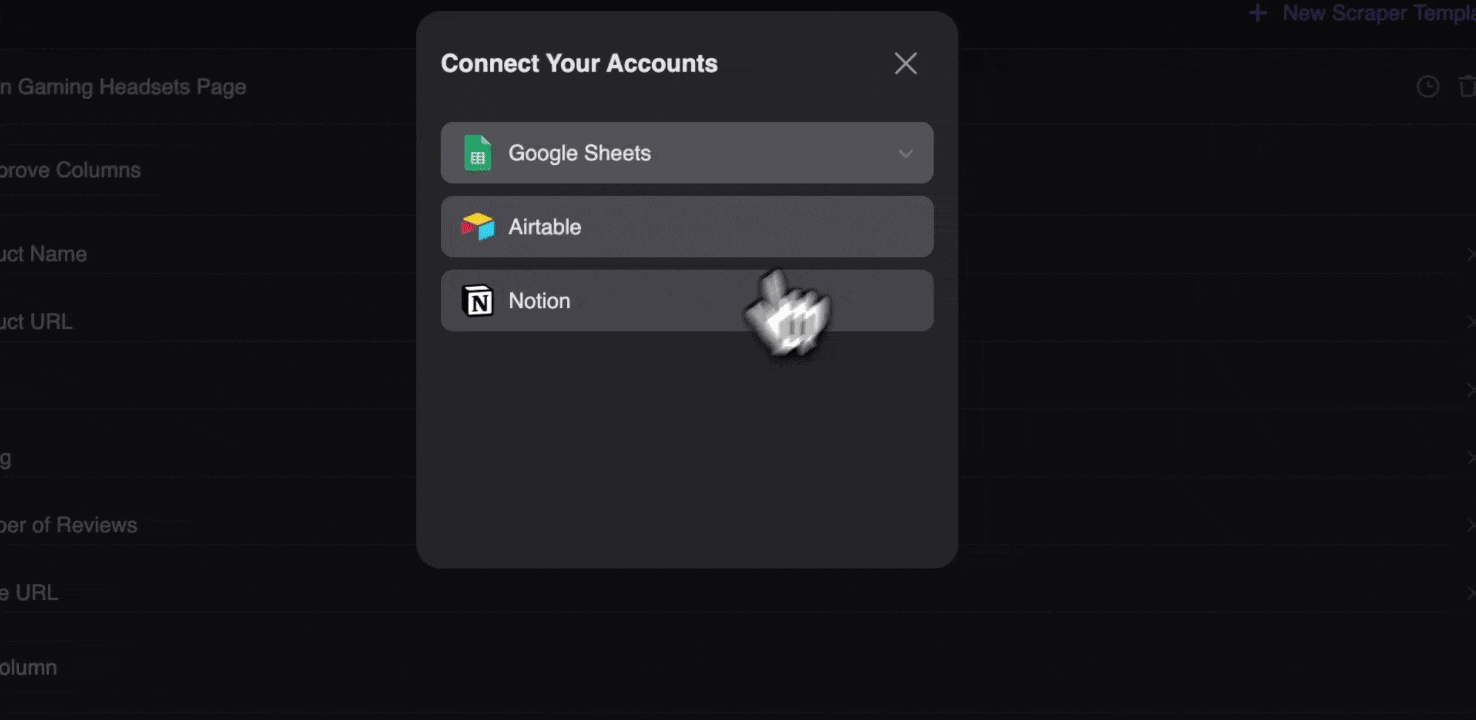
ขั้นตอนที่ 3: ดาวน์โหลดข้อมูลที่สแกนมา หรือส่งออกเป็นตาราง
ด้วยส่วนขยาย web scraper ของ Thunderbit คุณสามารถ ส่งออกข้อมูลที่สแกนได้หลายรูปแบบ เลือกแสดงผลเป็นตาราง แล้วดาวน์โหลดไฟล์ CSV ลงเครื่อง หรือเลือก บันทึกไปยัง Google Sheets, Notion หรือ Airtable ก็ได้ เพียงล็อกอินบัญชีของคุณแล้วส่งออกตรงไปยังแพลตฟอร์มจัดการไฟล์และทำงานร่วมกันบนออนไลน์เหล่านี้
สแกนข้อมูล SKU Amazon ด้วย AI ใน 2 คลิก
สแกนด้วย Traditional Web Scraper
นอกจากเครื่องมือ AI รุ่นใหม่แล้ว คุณยังสามารถใช้ traditional web scraper ร่วมกับโค้ดเบา ๆ และ API เพื่อดึงข้อมูลสินค้า Amazon ได้เช่นกัน
ScraperAPI: ดึงข้อมูลสินค้า Amazon ออกมาเป็น JSON ผ่าน API
ScraperAPI มี API สำหรับเก็บข้อมูล Amazon ที่ช่วยดึงรายละเอียดสินค้า รีวิว ผลการค้นหา และข้อมูลราคาออกมาจาก Amazon แล้วส่งกลับมาในรูปแบบ JSON ที่เป็นโครงสร้างชัดเจน วิธีใช้งาน API เพื่อสแกนข้อมูลมีดังนี้
ขั้นตอนที่ 1: ตั้งค่า Python Environment
ก่อนอื่นตรวจสอบให้แน่ใจว่าคุณติดตั้ง Python 3.8 หรือใหม่กว่าแล้ว จากนั้นติดตั้งไลบรารีสำหรับการวิเคราะห์อย่าง Pandas และไลบรารีสำหรับ web scraping อย่าง requests และ BeautifulSoup เครื่องมือเหล่านี้ช่วยให้คุณดึงข้อมูลจากหน้าเว็บได้ง่ายขึ้น
ขั้นตอนที่ 2: สร้างบัญชี ScraperAPI
เข้าไปที่ เว็บไซต์ ScraperAPI เพื่อสร้างบัญชีฟรีและรับ API key คุณสามารถใช้คีย์นี้เพื่อเรียกใช้งาน ScraperAPI ในโค้ดของคุณได้
ขั้นตอนที่ 3: เตรียมโค้ด
สร้างโฟลเดอร์เฉพาะไว้ในเครื่องแล้วเขียนสคริปต์ Python สำหรับดึงข้อมูล นี่คือเวิร์กโฟลว์พื้นฐาน:
- ดึง URL ค้นหาของ Amazon: ค้นหาสินค้าที่ต้องการบน Amazon แล้วคัดลอก URL ของหน้าผลการค้นหา
- สร้างคำขอ: ScraperAPI จะวนผ่านผลการค้นหา 5 หน้าแรกให้อัตโนมัติ โดยแต่ละหน้าจะสร้าง URL จาก base URL ด้วยการเพิ่ม &page= และหมายเลขหน้าที่สอดคล้องกัน
- ส่งคำขอและแยกวิเคราะห์ข้อมูล: ใช้เมธอด get() เพื่อส่งคำขอไปยัง ScraperAPI หากคำขอสำเร็จ (ได้ status code 200) ให้แยกข้อมูลในหน้าเพื่อดึง ASIN (Amazon Standard Identification Number) ที่ต้องการ
- ดึงข้อมูลสินค้ารายละเอียด: เมื่อเรียก structured data endpoint คุณจะได้ข้อมูลสินค้าราย ASIN สำหรับนำไปวิเคราะห์ต่อ
ขั้นตอนที่ 4: ดูคู่มือเพิ่มเติม
หากต้องการวิธีใช้งานแบบละเอียดเพิ่มเติม สามารถดูได้จาก บทความคู่มือในบล็อกทางการของ ScraperAPI
ScrapFly: ป้องกันการถูกบล็อกและสแกนในสเกลใหญ่
เมื่อต้องสแกนข้อมูล Amazon มักเจอความท้าทายจากเทคนิคป้องกันการสแกน เช่น การบล็อก IP, CAPTCHA และการโหลดคอนเทนต์แบบไดนามิก ScrapFly มี API ที่ช่วยหลีกเลี่ยงกลไกเหล่านี้ ทำให้การดึงข้อมูลเป็นไปอย่างราบรื่น
ฟีเจอร์หลักของ ScrapFly ได้แก่:
- Rotating Residential Proxies: สลับ IP อัตโนมัติเพื่อป้องกันการถูกบล็อก
- JavaScript Rendering: จัดการเนื้อหาแบบไดนามิกและสแกนหน้าเว็บที่เรนเดอร์ด้วย JavaScript ได้
- Full Browser Automation: ควบคุมเบราว์เซอร์เพื่อเลื่อนหน้า กรอกข้อมูล และคลิกวัตถุต่าง ๆ
- Format Conversion: สแกนออกมาเป็น HTML, JSON, Text หรือ Markdown ได้
เพียงเขียนโค้ดไม่กี่บรรทัด คุณก็ใช้ ScrapFly เพื่อสแกนข้อมูล Amazon ได้ ตัวอย่างง่าย ๆ มีดังนี้:
import scrapfly_sdk
# สร้าง client
client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
# ส่งคำขอ
response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
# ดึงข้อมูลที่ส่งกลับมา
print(response.json())
เมื่อใช้ ScrapFly scraper ของคุณจะรับมือกับกลไกป้องกันการสแกนของ Amazon ได้ดีขึ้น ทำให้อัตราความสำเร็จในการดึงข้อมูลสูงขึ้น ไม่ว่าจะเป็นการดึงข้อมูลสินค้าทั่วไปหรือการวิเคราะห์รีวิวที่ซับซ้อน ScrapFly ก็เป็นเครื่องมือที่ใช้งานได้จริงมาก หากต้องการอ่านคู่มือแบบละเอียดเพิ่มเติม ดูได้ที่ คู่มือทางการของ ScrapFly
สแกนด้วย Python: วิธีเขียนโค้ดแบบดั้งเดิม
สำหรับคนที่ถนัดเทคนิคและเขียนโค้ดได้ คุณสามารถลองใช้ Python ในการสแกนข้อมูลสินค้า Amazon ได้เช่นกัน ด้านล่างนี้เป็นตัวอย่างแบบง่ายสำหรับอ้างอิง
ขั้นตอนที่ 1: เตรียมสิ่งที่ต้องใช้
ก่อนอื่นสร้างโฟลเดอร์สำหรับโปรเจกต์ของคุณโดยเฉพาะ
mkdir amazonscraper
จากนั้นติดตั้งไลบรารีที่จำเป็นในโฟลเดอร์นี้
pip install beautifulsoup4
pip install requests
ต่อไปสร้างไฟล์ Python ชื่ออะไรก็ได้ตามต้องการ ไฟล์นี้จะเป็นไฟล์หลักที่เราใช้เก็บโค้ดของเรา ผมขอตั้งชื่อว่า amazon.py
ขั้นตอนที่ 2: ส่งคำขอ GET ไปยังหน้าที่ต้องการ
มาส่งคำขอ GET ไปยังหน้าที่เราต้องการด้วยไลบรารี requests กัน
import requests
from bs4 import BeautifulSoup
target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
headers = {
"accept-language": "en-US,en;q=0.9",
"accept-encoding": "gzip, deflate, br",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
}
response = requests.get(target_url, headers=headers)
ขั้นตอนที่ 3: สแกนข้อมูลสินค้า Amazon
ตอนนี้เราต้องกำหนดว่าจะดึงอะไรจาก หน้าที่ต้องการ
# ตรวจสอบว่าคำขอสำเร็จหรือไม่
if response.status_code == 200:
# แยกวิเคราะห์เนื้อหาของหน้า
soup = BeautifulSoup(response.content, 'html.parser')
# ค้นหารายการสินค้าทั้งหมด
products = soup.find_all('div', {'data-component-type': 's-search-result'})
# วนทีละสินค้าแล้วดึงรายละเอียด
for product in products:
# ดึงชื่อสินค้า
title = product.h2.text.strip()
# ดึงราคาสินค้า
price = product.find('span', 'a-price')
if price:
price = price.find('span', 'a-offscreen').text.strip()
else:
price = "ไม่มีข้อมูลราคา"
# ดึงคะแนนสินค้า
rating = product.find('span', 'a-icon-alt')
if rating:
rating = rating.text.strip()
else:
rating = "ไม่มีข้อมูลคะแนน"
# แสดงรายละเอียดสินค้า
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Rating: {rating}")
print("-" * 40)
else:
print(f"ไม่สามารถดึงหน้าเว็บได้ สถานะโค้ด: {response.status_code}")
คำถามที่พบบ่อย
1. การสแกนข้อมูลจาก amazon.com ถูกกฎหมายหรือไม่?
ใช่ การสแกนข้อมูลสาธารณะของ Amazon ทำได้อย่างถูกกฎหมาย! เช่นเดียวกับเว็บไซต์อื่น ๆ Amazon เปิดข้อมูลรายการสินค้าและข้อมูลสาธารณะอื่น ๆ ให้ทุกคนเข้าชมได้ คุณจึงสามารถสแกนและรวบรวมข้อมูลที่เปิดให้เข้าถึงได้โดยไม่ละเมิดเงื่อนไขการใช้งานของ Amazon
2. ทดลองใช้ Thunderbit ฟรีได้ไหม?
ได้ Thunderbit มีฟีเจอร์สำหรับดึงข้อมูลหน้าเว็บและข้อมูลต่าง ๆ ให้ใช้ฟรี แม้ว่าฟังก์ชันขั้นสูงบางอย่างอาจมีค่าใช้จ่าย แต่ความสามารถพื้นฐานในการดึงข้อมูลมักใช้งานได้ฟรี โดยทั่วไป
3. ฉันสามารถดึงข้อมูลอะไรจาก Amazon ได้บ้าง?
คุณสามารถดึงข้อมูลหลากหลายประเภทจาก Amazon ได้ เช่น ชื่อสินค้า ราคา คำอธิบาย รีวิว คะแนน และข้อมูลผู้ขาย ข้อมูลเหล่านี้มีคุณค่าอย่างมากสำหรับการวิจัยตลาด การติดตามราคา และการวิเคราะห์คู่แข่ง
4. ควรสแกนข้อมูล Amazon บ่อยแค่ไหน?
ความถี่ขึ้นอยู่กับประเภทของข้อมูลที่คุณต้องการ ถ้าคุณกำลังติดตามราคา หรือกิจกรรมของคู่แข่ง อาจสแกนรายวันหรือรายสัปดาห์ แต่ถ้าเป็นข้อมูลที่ไม่เปลี่ยนบ่อย เช่น รายละเอียดสินค้า อาจสแกนเดือนละครั้งก็เพียงพอ
อ่านเพิ่มเติม
- วิธีดึงข้อมูลเว็บไซต์ลง Excel ด้วย AI
- 6 ตัวเลือก Twitter (x.com) Scraper ที่ดีที่สุดในปี 2025
- วิธีดึงข้อมูลจาก PDF ด้วย AI
ลองใช้ AI Web Scraper Get Started Free




