
ก่อนเที่ยงวันอังคาร ผมเปิดดูแดชบอร์ด OpenRouter แล้วเห็นยอดใช้จ่ายพุ่งไป $47 แล้ว ผมเพิ่งทำงานเขียนโค้ดไปแค่ราวสิบกว่างาน — ไม่มีอะไรหนักหนา แค่รีแฟกเตอร์นิดหน่อยกับแก้บั๊กไม่กี่จุด นั่นแหละที่ทำให้ผมรู้ว่า OpenClaw ตั้งค่าเริ่มต้นไว้แบบเงียบ ๆ ให้ส่งทุกอย่าง ไม่ว่าจะเป็นการโต้ตอบปกติหรือแม้แต่สัญญาณ heartbeat พื้นหลัง ไปผ่าน Claude Opus ที่คิดราคามากกว่า $15 ต่อหนึ่งล้านโทเค็น
ถ้าคุณเคยเจอเรื่องช็อกแบบนี้เหมือนกัน — และจากที่เห็นในฟอรัม หลายคนก็เจอเหมือนกัน (“ผมใช้ไปแล้ว 40 ดอลลาร์ ทั้งที่แทบไม่ได้ใช้มันเลย” มีผู้ใช้คนหนึ่งเขียนไว้) — คู่มือนี้จะพาคุณไล่ตรวจและปรับแต่งแบบครบวงจรที่ผมใช้ลดค่าใช้จ่ายรายเดือนได้ราว 90% ไม่ใช่แค่ “เปลี่ยนไปใช้โมเดลที่ถูกกว่า” แต่เป็นการแกะดูเป็นระบบว่าโทเค็นไหลไปทางไหนบ้าง จะติดตามมันยังไง โมเดลราคาประหยัดตัวไหนที่ยังใช้งานจริงกับงาน agentic ได้ และมีคอนฟิกแบบคัดลอกไปใช้ได้เลย 3 แบบ ทุกขั้นตอนใช้เวลาทั้งหมดแค่บ่ายเดียว
การใช้งานโทเค็นของ OpenClaw คืออะไร และทำไมค่าเริ่มต้นถึงสูงขนาดนั้น?
โทเค็นคือหน่วยที่ใช้คิดเงินสำหรับทุกการโต้ตอบกับ AI ใน OpenClaw ลองมองว่ามันเป็นชิ้นข้อความเล็ก ๆ — โดยประมาณ 4 ตัวอักษรภาษาอังกฤษต่อ 1 โทเค็น ทุกข้อความที่คุณส่ง ทุกคำตอบที่ได้รับ ทุกกระบวนการพื้นหลังที่ทำงาน ล้วนถูกคิดเงินเป็นโทเค็นทั้งหมด
ปัญหาคือค่าเริ่มต้นของ OpenClaw ถูกออกแบบมาเพื่อ “ความสามารถสูงสุด” ไม่ใช่ “ต้นทุนต่ำสุด” นอกกล่อง โมเดลหลักถูกตั้งเป็น anthropic/claude-opus-4-5 ซึ่งเป็นตัวเลือกที่แพงที่สุด Heartbeat ping ก็วิ่งผ่าน Opus ด้วย Sub-agent ที่ถูกเรียกขึ้นมาเพื่อทำงานย่อย ๆ ก็ใช้ Opus เช่นกัน การเอา Opus ไปทำ heartbeat ping ก็เหมือนจ้างศัลยแพทย์สมองมาปิดพลาสเตอร์ แก้ได้ก็จริง แต่แพงเกินเหตุแบบน่าตกใจ
ผู้ใช้ส่วนใหญ่ไม่รู้ด้วยซ้ำว่ากำลังจ่ายแพงเพื่อให้งานเบื้องหลังที่ไม่สำคัญ ค่าเริ่มต้นแบบนี้แทบจะสมมติว่าคุณอยากได้โมเดลดีที่สุดสำหรับทุกอย่าง ตลอดเวลา — แล้วก็เก็บเงินตามนั้นจริง ๆ
ทำไมการลดการใช้งานโทเค็นของ OpenClaw ถึงคุ้มกว่าแค่ประหยัดเงิน
ประโยชน์ที่เห็นชัดที่สุดคือประหยัดค่าใช้จ่าย แต่ยังมีผลดีอื่น ๆ ที่สะสมไปเรื่อย ๆ ด้วย
โมเดลที่ถูกกว่ามัก เร็วกว่า Gemini 2.5 Flash-Lite ทำความเร็วได้ราว เทียบกับ Opus ที่ประมาณ 51 — เร็วขึ้น 4 เท่าในทุกการโต้ตอบ GPT-OSS-120B บน Cerebras ทำได้ถึง ซึ่งเร็วกว่า Opus ราว 35 เท่า ในลูปแบบ agentic ที่มีการเรียกเครื่องมือ 50+ รอบ ความเร็วที่ต่างกันนี้หมายถึงเสร็จภายในไม่กี่นาที แทนที่จะต้องรอเวลาแรกของคำตอบจาก Opus ที่ทรมานถึง 13.6 วินาทีในทุกครั้งที่รับส่ง
คุณยังมีพื้นที่หายใจมากขึ้นก่อนชน rate limit เซสชันโดน throttle น้อยลง และมีช่องให้ขยายการใช้งานได้ โดยไม่ต้องขยายความกังวลเรื่องบิลตามไปด้วย
ประมาณการประหยัดตามรูปแบบการใช้งาน:
| โปรไฟล์ผู้ใช้ | ค่าใช้จ่ายรายเดือนโดยประมาณ (ค่าเริ่มต้น) | หลังปรับแต่งเต็มรูปแบบ | ประหยัดต่อเดือน |
|---|---|---|---|
| ใช้น้อย (~10 queries/วัน) | ~$100 | ~$12 | ~88% |
| ใช้ปานกลาง (~50 queries/วัน) | ~$500 | ~$90 | ~82% |
| ใช้หนัก (~200+ queries/วัน) | ~$1,750 | ~$220 | ~87% |
นี่ไม่ใช่ตัวเลขสมมติ มีนักพัฒนารายหนึ่งบันทึกไว้ว่าจาก — ลดได้จริง 90% — โดยใช้ทั้งการเลือกเส้นทางโมเดลและแก้ตัวดูดเงินที่ซ่อนอยู่ ซึ่งผมจะอธิบายต่อในคู่มือนี้
โครงสร้างการใช้โทเค็นของ OpenClaw: โทเค็นแต่ละก้อนไหลไปไหนบ้าง
นี่คือส่วนที่คู่มือเพิ่มประสิทธิภาพส่วนใหญ่มักข้ามไป แต่เป็นส่วนที่สำคัญที่สุด เพราะคุณจะปรับไม่ได้ ถ้ายังมองไม่เห็นภาพรวม
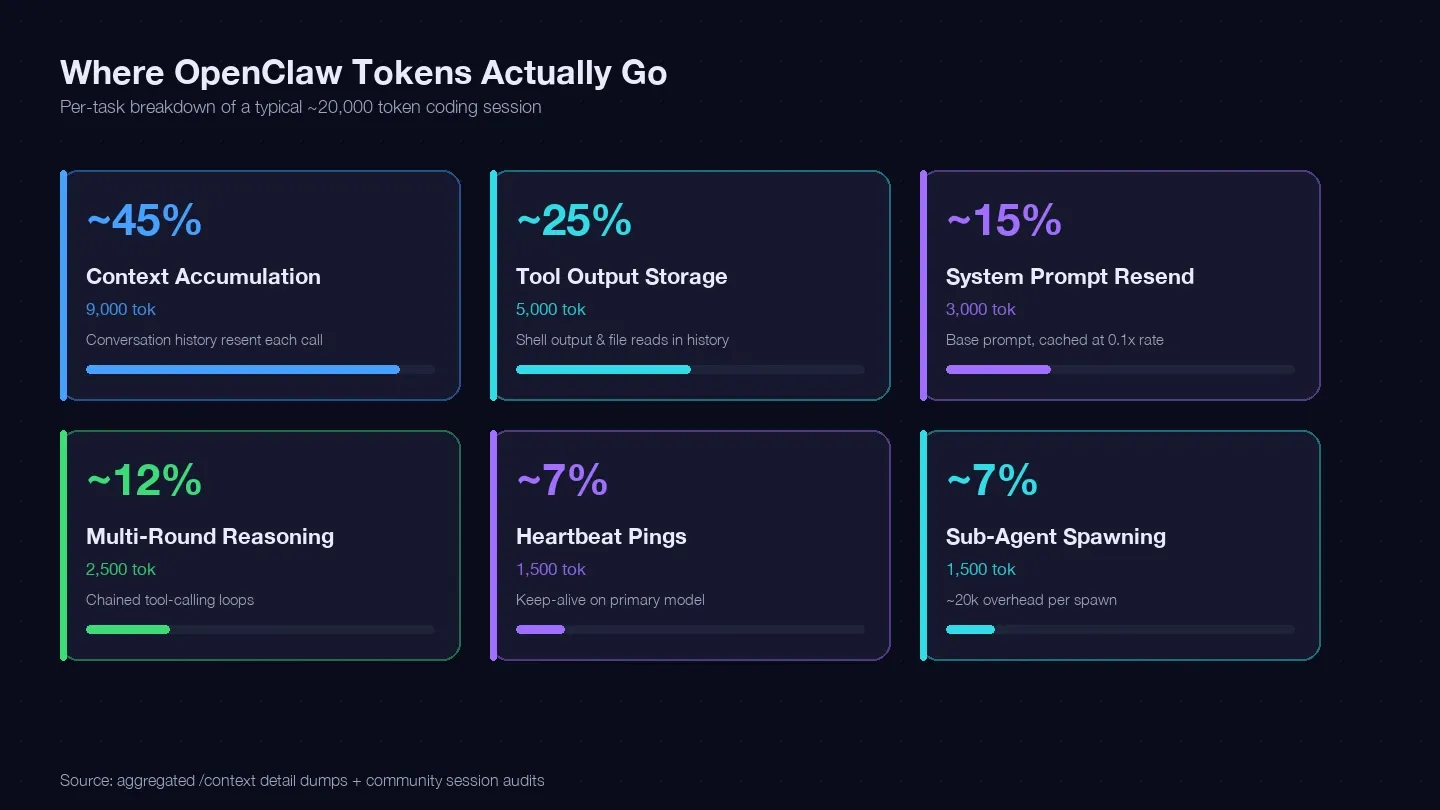
ผมตรวจสอบหลายเซสชันและเทียบกับ รวมถึงข้อมูล dump จากชุมชน /context เพื่อสร้างบัญชีแยกประเภทโทเค็นสำหรับงานเขียนโค้ดทั่วไปหนึ่งงาน นี่คือจุดที่โทเค็นราว 20,000 ตัวไหลไปจริง ๆ:
| หมวดโทเค็น | สัดส่วนโดยทั่วไปของทั้งหมด | ตัวอย่าง (งานเขียนโค้ด 1 งาน) | ควบคุมได้ไหม? |
|---|---|---|---|
| การสะสม context (ส่งประวัติแชตซ้ำทุกครั้ง) | ~40–50% | ~9,000 tokens | ได้ — /clear, /compact, ทำเซสชันให้สั้นลง |
| การเก็บ output จากเครื่องมือ (shell output, file reads ที่ค้างในประวัติ) | ~20–30% | ~5,000 tokens | ได้ — อ่านให้น้อยลง จำกัดขอบเขตเครื่องมือให้แคบลง |
| การส่ง system prompt ซ้ำ (~15K base) | ~10–15% | ~3,000 tokens | ได้บางส่วน — cache reads ในอัตรา 0.1x |
| การคิดเหตุผลหลายรอบ (ลูปเรียกเครื่องมือแบบต่อเนื่อง) | ~10–15% | ~2,500 tokens | เลือกโมเดล + ปรับ prompt ให้ดีขึ้น |
| Heartbeat / keep-alive pings | ~5–10% | ~1,500 tokens | ได้ — เปลี่ยนคอนฟิก |
| การเรียก sub-agent | ~5–10% | ~1,500 tokens | ได้ — กำหนดเส้นทางโมเดล |
ก้อนใหญ่ที่สุด — การสะสม context — คือประวัติการสนทนาที่ถูกส่งซ้ำไปทุกครั้งที่เรียก API มี อันหนึ่งที่แสดง 185,400 tokens อยู่ใน bucket Messages เพียงอย่างเดียว โดยที่โมเดลยังไม่ได้ตอบอะไรเลย ส่วน system prompt และ tools ยังเพิ่ม overhead คงที่อีกประมาณ 35,800 tokens ทับลงไป
สรุปคือ ถ้าคุณไม่ล้างเซสชันระหว่างงานที่ไม่เกี่ยวกัน คุณกำลังจ่ายเงินเพื่อส่งประวัติการสนทนาทั้งก้อนซ้ำทุกครั้งที่คุยต่อ
วิธีติดตามการใช้งานโทเค็นของ OpenClaw (ถ้ามองไม่เห็น ก็ลดไม่ได้)
ก่อนจะเปลี่ยนอะไรทั้งนั้น ต้องทำให้เห็นก่อนว่าโทเค็นกำลังไหลไปไหน การกระโดดไปสรุปว่า “ใช้โมเดลถูกกว่า” โดยไม่มอนิเตอร์ ก็เหมือนพยายามลดน้ำหนักโดยไม่เคยขึ้นชั่ง
เช็กบน OpenRouter Dashboard
ถ้าคุณส่งผ่าน OpenRouter หน้า คือแดชบอร์ดที่ตั้งค่าง่ายที่สุด คุณกรองตามโมเดล ผู้ให้บริการ API key และช่วงเวลาได้ มุม Usage Accounting จะแยก prompt, completion, reasoning และ cached tokens ในแต่ละคำขอ มีปุ่ม Export ทั้ง CSV หรือ PDF สำหรับวิเคราะห์ระยะยาว
สิ่งที่ควรดูคือ โมเดลไหนกินโทเค็นมากที่สุด และมี request จาก heartbeat หรือ sub-agent โผล่มาเป็นรายการที่ใหญ่ผิดปกติหรือไม่
ตรวจสอบ Local API Logs
OpenClaw เก็บข้อมูลเซสชันไว้ใน ~/.openclaw/agents.main/sessions/sessions.json ซึ่งมี totalTokens ต่อเซสชัน คุณยังสั่ง openclaw logs --follow --json เพื่อดูล็อกแบบเรียลไทม์รายคำขอได้ด้วย
ข้อควรรู้คือ ดังนั้นแดชบอร์ดอาจแสดงค่าก่อน compact ที่ไม่อัปเดตแล้ว ให้เชื่อ /status และ /context detail มากกว่าค่าที่บันทึกไว้
ใช้เครื่องมือติดตามจากภายนอก (สำหรับคนใช้ระดับปานกลางถึงหนัก)
LiteLLM proxy ให้ endpoint ที่เข้ากันกับ OpenAI หน้า provider มากกว่า 100 เจ้า และ จุดเด่นที่สุดคือ ตั้งงบแบบ hard limit ต่อคีย์ได้ ซึ่งยังอยู่รอดแม้ใช้ /clear — sub-agent ที่วิ่งหลุดวงจรจะไม่สามารถเผื่องบเกินที่คุณกำหนดไว้ได้
Helicone ใช้ง่ายกว่าอีก — แค่ ก็ได้หน้า Sessions ที่รวม request ที่เกี่ยวข้องไว้ด้วยกัน พรอมป์ต์ “ช่วยแก้บั๊กนี้” ที่แตกแขนงไปเป็น 8+ sub-agent calls จะถูกแสดงเป็นหนึ่งแถวเซสชันพร้อมต้นทุนรวมจริง ๆ
เช็กเร็ว ๆ ภายใน OpenClaw
สำหรับมอนิเตอร์ประจำวัน มี 4 คำสั่งในเซสชันที่พอใช้ได้:
/status— แสดงการใช้ context, token ล่าสุดของ input/output, ต้นทุนโดยประมาณ/usage full— footer การใช้งานรายคำตอบ/context detail— แยกโทเค็นตามไฟล์ ตามสกิล และตามเครื่องมือ/compact [guidance]— บังคับ compact พร้อมสตริงโฟกัสเสริมได้
ให้รัน /context detail ก่อนและหลังปรับคอนฟิก นั่นคือวิธีวัดว่าการปรับแต่งของคุณได้ผลจริงไหม
ศึกชิงโมเดลราคาประหยัดของ OpenClaw: LLM รุ่นประหยัดตัวไหนทำงานแบบ agentic ได้จริง
คู่มือส่วนใหญ่พลาดตรงนี้ พวกเขาแค่เปิดตารางราคา ชี้ไปที่แถวถูกสุด แล้วจบเลย แต่ benchmark ไม่ได้ทำนายประสิทธิภาพจริงในการทำงานแบบ agentic ได้ดีนัก ซึ่งชุมชนก็พูดตรงกันและพูดซ้ำหลายครั้งอย่างชัดเจน มีผู้ใช้คนหนึ่งกล่าวไว้ว่า: “benchmarks ไม่ได้ช่วยให้เข้าใจว่าอะไรเหมาะกับ agentic AI จริง ๆ เลย”
ข้อสังเกตสำคัญคือ โมเดลที่ถูกที่สุด ไม่ได้แปลว่าเป็นผลลัพธ์ที่ถูกที่สุดเสมอไป โมเดลที่พลาดแล้วต้องลองใหม่สี่ครั้ง มักแพงกว่าโมเดลระดับกลางที่ ในระบบ agent สำหรับโปรดักชัน ควรเผื่ออัตรารีทราย — และถ้ามีการเรียก LLM 5 ขั้นตอนต่อเนื่องแล้วด่านที่ 4 ล้ม การรีไทรแบบง่าย ๆ อาจทำให้ต้องรันทั้ง 5 ขั้นตอนใหม่หมด
นี่คือเมทริกซ์ความสามารถของผม โดยให้คะแนน “Real Agentic Score” จากประสบการณ์ผู้ใช้จริง ไม่ใช่จาก benchmark สังเคราะห์:
| โมเดล | ราคา Input / 1M | ราคา Output / 1M | ความน่าเชื่อถือในการเรียกเครื่องมือ | การคิดเหตุผลหลายขั้น | คะแนน Real Agentic (1–5) | เหมาะกับ |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | ผสม ๆ — บางครั้งติดลูป | พื้นฐาน | ⭐2.5 | heartbeat, ค้นหาง่าย ๆ |
| GPT-OSS-120B | $0.04 | $0.19 | พอใช้ได้ | พอใช้ได้ | ⭐3.0 | ทดลองแบบประหยัด, งานที่ต้องการความเร็ว |
| DeepSeek V3.2 | $0.26 | $0.38 | ไม่สม่ำเสมอ (มี 6 issues เปิดอยู่) | ดี | ⭐3.0 | งาน reasoning หนัก, เรียกเครื่องมือน้อย |
| Kimi K2.5 | $0.38 | $1.72 | ดี (ผ่าน :exacto) | พอใช้ได้ | ⭐3.5 | งานโค้ดระดับง่ายถึงกลาง |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | ดี | ดี | ⭐4.0 | โมเดลหลักสำหรับเขียนโค้ดทั่วไป |
| Claude Haiku 4.5 | $1.00 | $5.00 | ยอดเยี่ยม | ดี | ⭐4.5 | ตัวสำรองระดับกลางที่เชื่อถือได้ |
| Claude Sonnet 4.6 | $3.00 | $15.00 | ยอดเยี่ยม | ยอดเยี่ยม | ⭐5.0 | งานซับซ้อนหลายขั้น |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | ยอดเยี่ยม | ยอดเยี่ยม | ⭐5.0 | เก็บไว้ใช้เฉพาะงานที่ยากที่สุด |
คำเตือนเกี่ยวกับ DeepSeek และ Gemini Flash สำหรับงานเรียกเครื่องมือ
DeepSeek V3.2 ดูดีมากบนกระดาษ — 72–74% บน และถูกกว่า Sonnet 11–36 เท่า แต่ในทางปฏิบัติ จาก Cline, Roo Code, Continue และ NVIDIA NIM ระบุปัญหาพฤติกรรมการเรียกเครื่องมือที่เสียหายไว้ชัดเจน ข้อสรุปของ Composio แบบเทียบกันตรง ๆ คือ “.” ส่วนประโยคสั้น ๆ ของ Zvi Mowshowitz คือ: “”
Gemini 2.5 Flash ก็มีช่องว่างคล้ายกัน กระทู้ใน Google AI Developers Forum ชื่อ “Very frustrating experience with Gemini 2.5 function calling performance” เปิดด้วยประโยคว่า: “.”
OpenRouter ชี้ประเด็นสำคัญว่า “.” ถ้าคุณส่งโมเดลราคาถูกผ่าน OpenRouter ให้มองหาแท็ก :exacto — การสลับผู้ให้บริการแบบเงียบ ๆ อาจเปลี่ยนโมเดลราคาถูกที่ไว้ใจได้ ให้กลายเป็นลูปรีไทรราคาแพงได้ข้ามคืน
ควรใช้โมเดลไหนตอนไหน
- Gemini Flash-Lite: ใช้กับ heartbeat, keep-alive ping, Q&A ง่าย ๆ ไม่ควรใช้กับงานเรียกเครื่องมือหลายขั้น
- MiniMax M2.5/M2.7: โมเดลหลักสำหรับงานเขียนโค้ดทั่วไป ในราคาที่ถูกกว่า Sonnet มาก
- Claude Haiku 4.5: ตัวสำรองที่เชื่อถือได้เมื่อโมเดลราคาถูกอื่น ๆ เรียกเครื่องมือไม่รอด ความเสถียรในการเรียกเครื่องมือดีเยี่ยม ในราคาประมาณถูกกว่า Sonnet 3 เท่า
- Claude Sonnet 4.6: งาน agentic หลายขั้นที่ซับซ้อน นี่คือจุดที่คุณจะได้ความคุ้มค่ากับเงินที่จ่าย
- Claude Opus: เก็บไว้สำหรับงานที่ยากที่สุดจริง ๆ อย่าให้มันเป็นค่าเริ่มต้นของอะไรทั้งนั้น
(ราคาของโมเดลเปลี่ยนบ่อย ควรตรวจสอบอัตราปัจจุบันบน หรือหน้า provider โดยตรงก่อนตั้งค่าจริง)
ตัวดูดโทเค็นที่ซ่อนอยู่ซึ่งคู่มือส่วนใหญ่มักข้ามไป
ผู้ใช้ในฟอรัมรายงานว่าการปิดฟีเจอร์บางอย่างช่วยลดค่าใช้จ่ายได้มาก แต่จากที่ผมหาคู่มือมา ยังไม่เจออันไหนที่รวมเช็กลิสต์ของตัวดูดเงินที่ซ่อนอยู่ทั้งหมดพร้อมผลกระทบต่อโทเค็นแบบครบชุดไว้ ผมสรุปให้แบบแกะทั้งระบบด้านล่างนี้:
| ตัวดูดที่ซ่อนอยู่ | ต้นทุนโทเค็นต่อ 1 ครั้ง | วิธีแก้ | คีย์คอนฟิก |
|---|---|---|---|
| heartbeat ค่าเริ่มต้นบน Opus | ~100,000 tokens/run หากไม่แยกเซสชัน | override เป็น Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| การ spawn sub-agent | ~20,000 tokens ต่อการเรียก ก่อนเริ่มงานจริง | route sub-agent ไป Haiku | subagents.model |
| โหลด context ทั้ง codebase | ~3,000–15,000 tokens ต่อการ auto-explore | ใช้ .clawignore สำหรับ node_modules, dist, lockfiles | .clawrules + .clawignore |
| memory auto-summarize | ~500–2,000 tokens/เซสชัน | ปิดหรือให้น้อยลง | memory: false หรือ memory.max_context_tokens |
| การสะสมประวัติการสนทนา | ~500+ tokens/รอบ (สะสมต่อเนื่อง) | เริ่มเซสชันใหม่เมื่องานไม่เกี่ยวกัน | วินัยในการใช้ /clear |
| overhead เครื่องมือ MCP server | ~7,000 tokens สำหรับ 4 servers; 50,000+ สำหรับ 5+ | คง MCP ให้น้อยที่สุด | ลบ MCP ที่ไม่ใช้ |
| การเริ่มต้น skill/plugin | 200–1,000 tokens ต่อ skill ที่โหลด | ปิด skill ที่ไม่ได้ใช้ | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7x ของค่าเซสชันปกติ | ใช้เฉพาะเมื่อจำเป็นต้องทำงานขนานจริง ๆ | เลือกแบบ sequential จะดีกว่า |
ตัวดูดจาก heartbeat ควรพูดถึงแยกต่างหาก โดยปกติ heartbeat จะยิงบนโมเดลหลัก (Opus) ทุก 30 นาที การตั้ง isolatedSession: true ทำให้จากราว ~100,000 tokens ต่อรอบ — ลดได้ 95–98% ในก้อนเดียว
3 วิธีชนะไวที่สุดที่ช่วยลดโทเค็นได้มากสุดในไม่ถึงสองนาที
ทั้ง 3 ข้อนี้ปลอดความเสี่ยงและใช้เวลาไม่ถึงสองนาที:
-
ใช้
/clearระหว่างงานที่ไม่เกี่ยวกัน (5 วินาที) นี่คือตัวประหยัดโทเค็นที่แรงที่สุดเพียงตัวเดียว ฉันทามติในฟอรัมประเมินว่าช่วยลดได้ แค่ล้างประวัติเซสชันก่อนเริ่มงานใหม่ จำ bucket Messages ที่ 185k tokens จาก /context dump ได้ไหม?/clearจะลบมันทิ้ง -
ใช้
/model haiku-4.5กับงานจุกจิก (10 วินาที) การสลับโมเดลแบบมีแผนช่วยลดต้นทุนได้ สำหรับงานประจำ Haiku รับงานเขียนโค้ดตรงไปตรงมา ค้นหาไฟล์ และเขียน commit message ได้ดีสบาย ๆ -
ลด
.clawrulesให้ต่ำกว่า 200 บรรทัด + เพิ่ม.clawignore(90 วินาที) ไฟล์ rules ของคุณถูกโหลดทุกครั้งที่มีข้อความใหม่ 200 บรรทัดก็ราว ~1,500–2,000 tokens ต่อรอบแล้ว ถ้า 1,000 บรรทัดจะกลายเป็น 8,000–10,000 tokens ที่คอยเก็บภาษีทุกคำขอแบบถาวร เมื่อรวมกับ.clawignoreที่ตัดnode_modules/,dist/, lockfiles และโค้ดที่ generate แล้ว นักพัฒนาคนหนึ่งอ้างว่าได้ จากวินัยข้อนี้เพียงอย่างเดียว
ทีละขั้น: 3 คอนฟิกพร้อมใช้ที่ช่วยลดการใช้งานโทเค็นของ OpenClaw ได้จริง

ต่อไปนี้คือคอนฟิก openclaw.json แบบครบชุดที่ใส่คำอธิบายไว้แล้ว 3 แบบ — ไล่ระดับตั้งแต่ “เริ่มต้นให้ได้ก่อน” ไปจนถึง “ชุดปรับเต็มระบบ” แต่ละชุดมีคอมเมนต์ในบรรทัดและประมาณการค่าใช้จ่ายรายเดือน
ก่อนเริ่ม:
- ระดับความยาก: มือใหม่ (Config A) → ระดับกลาง (Config B) → ขั้นสูง (Config C)
- เวลาที่ต้องใช้: ~5 นาทีสำหรับ Config A, ~15 นาทีสำหรับ Config C
- สิ่งที่ต้องมี: ติดตั้ง OpenClaw แล้ว, ตัวแก้ไขข้อความ, เข้าถึง
~/.openclaw/openclaw.json
Config A: มือใหม่ — แค่เริ่มประหยัดเงิน
ห้าบรรทัด ไม่มีความซับซ้อน สลับโมเดลเริ่มต้นจาก Opus ไป Sonnet ปิด memory overhead และแยก heartbeat ไปใช้ Haiku
1// ~/.openclaw/openclaw.json
2{
3 "agents": {
4 "defaults": {
5 "model": { "primary": "anthropic/claude-sonnet-4-6" }, // เดิมคือ Opus — ประหยัดได้ 3-5x ทันที
6 "heartbeat": {
7 "every": "55m", // ให้ตรงกับ cache TTL 1 ชั่วโมงเพื่อให้ cache hit สูงสุด
8 "model": "anthropic/claude-haiku-4-5", // ใช้ Haiku สำหรับ ping ไม่ใช่ Opus
9 "isolatedSession": true // ~100k → 2-5k tokens ต่อรอบ
10 }
11 }
12 },
13 "memory": { "enabled": false } // ประหยัด ~500-2k tokens/เซสชัน
14}สิ่งที่ควรเห็นหลังใช้งาน: รัน /status ก่อนและหลัง ต้นทุนต่อคำขอควรลดลงอย่างเห็นได้ชัด และรายการ heartbeat ใน OpenRouter Activity page ควรแสดงเป็น Haiku แทน Opus
| ระดับการใช้งาน | ค่าเริ่มต้น (Opus) | Config A (Sonnet + Haiku heartbeats) | ประหยัด |
|---|---|---|---|
| ใช้น้อย (~10 q/day) | ~$100 | ~$35 | 65% |
| ใช้ปานกลาง (~50 q/day) | ~$500 | ~$250 | 50% |
| ใช้หนัก (~200 q/day) | ~$1,750 | ~$900 | 49% |
Config B: ระดับกลาง — Routing อัจฉริยะแบบ 3 ชั้น
ใช้ Sonnet เป็นหลักสำหรับงานจริง ใช้ Haiku สำหรับ sub-agent และ compaction ใช้ Gemini Flash-Lite เป็น fallback ราคาประหยัดเมื่อ Claude ถูก throttle และมี fallback chain รับมือ provider ล่มโดยอัตโนมัติ
1{
2 "agents": {
3 "defaults": {
4 "model": {
5 "primary": "anthropic/claude-sonnet-4-6",
6 "fallbacks": [
7 "anthropic/claude-haiku-4-5", // ถ้า Sonnet โดน throttle
8 "google/gemini-2.5-flash-lite" // ตัวสุดท้ายราคาถูกมาก
9 ]
10 },
11 "models": {
12 "anthropic/claude-sonnet-4-6": {
13 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
14 }
15 },
16 "heartbeat": {
17 "every": "55m", // 55 นาที < cache TTL 1 ชม. = ได้ cache hit
18 "model": "google/gemini-2.5-flash-lite", // จ่ายแค่เศษเงินต่อ ping
19 "isolatedSession": true,
20 "lightContext": true // context ใน heartbeat น้อยที่สุด
21 },
22 "subagents": {
23 "maxConcurrent": 4, // ลดจากค่าเริ่มต้น 8
24 "model": "anthropic/claude-haiku-4-5" // sub-agent ไม่จำเป็นต้องใช้ Sonnet
25 },
26 "compaction": {
27 "mode": "safeguard",
28 "model": "anthropic/claude-haiku-4-5", // สรุป compaction ผ่าน Haiku
29 "memoryFlush": { "enabled": true }
30 }
31 }
32 }
33}ผลลัพธ์ที่คาดหวัง: รายการ sub-agent ในล็อกจะขึ้นราคาของ Haiku แทน Heartbeat แทบไม่มีต้นทุน และ fallback chain จะทำให้ถ้า Claude มีปัญหา เซสชันของคุณยังเดินต่อได้โดยลดระดับลงไป Gemini อย่างนุ่มนวล
| ระดับการใช้งาน | ค่าเริ่มต้น | Config B | ประหยัด |
|---|---|---|---|
| ใช้น้อย | ~$100 | ~$20 | 80% |
| ใช้ปานกลาง | ~$500 | ~$150 | 70% |
| ใช้หนัก | ~$1,750 | ~$500 | 71% |
Config C: Power User — ชุดปรับเต็มสแตก
กำหนดโมเดลแยกต่อ sub-agent, ปัก compaction context ไว้ที่ Haiku, route งาน vision ไป Gemini Flash, ลด .clawrules + .clawignore ให้แน่น, ปิด skill ที่ไม่ใช้ นี่คือคอนฟิกที่พาคุณเข้าสู่ช่วงประหยัด 85–90%
1{
2 "agents": {
3 "defaults": {
4 "workspace": "~/clawd",
5 "model": {
6 "primary": "anthropic/claude-sonnet-4-6",
7 "fallbacks": [
8 "openrouter/anthropic/claude-sonnet-4-6", // provider อื่นเป็นแบ็กอัป
9 "minimax/minimax-m2-7", // fallback ราคาถูกสำหรับใช้งานประจำ
10 "anthropic/claude-haiku-4-5" // ตัวสุดท้าย
11 ]
12 },
13 "models": {
14 "anthropic/claude-sonnet-4-6": {
15 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
16 },
17 "minimax/minimax-m2-7": {
18 "params": { "maxTokens": 8192 }
19 }
20 },
21 "heartbeat": {
22 "every": "55m",
23 "model": "google/gemini-2.5-flash-lite",
24 "isolatedSession": true,
25 "lightContext": true,
26 "activeHours": "09:00-19:00" // ไม่ยิง heartbeat ตอนกลางคืน
27 },
28 "subagents": {
29 "maxConcurrent": 4,
30 "model": "anthropic/claude-haiku-4-5"
31 },
32 "contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
33 "compaction": {
34 "mode": "safeguard",
35 "model": "anthropic/claude-haiku-4-5",
36 "identifierPolicy": "strict",
37 "memoryFlush": { "enabled": true }
38 },
39 "bootstrapMaxChars": 12000, // ลดจากค่าเริ่มต้น 20000
40 "imageModel": "google/gemini-3-flash" // งานภาพผ่านโมเดลราคาถูก
41 }
42 },
43 "memory": { "enabled": true, "max_context_tokens": 800 }, // memory แบบขั้นต่ำ
44 "skills": {
45 "entries": {
46 "web-search": { "enabled": false },
47 "image-generation": { "enabled": false },
48 "audio-transcribe": { "enabled": false }
49 }
50 }
51}ตัวอย่าง override แยกต่อ sub-agent — วางลงใน ~/.openclaw/agents/lint-runner/SOUL.md:
1---
2name: lint-runner
3description: รัน lint/format checks และแก้ไขเรื่องเล็กน้อยแบบ trivial
4tools: [Bash, Read, Edit]
5model: anthropic/claude-haiku-4-5
6---.clawignore ขั้นต่ำที่ควรมี — แค่นี้ก็ช่วยลด bootstrap ทั่วไปจาก 150k ตัวอักษรลงมาราว 30–50k ได้แล้ว:
1node_modules/
2dist/
3build/
4.next/
5coverage/
6.venv/
7vendor/
8*.lock
9package-lock.json
10yarn.lock
11pnpm-lock.yaml
12*.min.js
13*.min.css
14**/__snapshots__/
15**/*.snap| ระดับการใช้งาน | ค่าเริ่มต้น | Config C | ประหยัด |
|---|---|---|---|
| ใช้น้อย | ~$100 | ~$12 | 88% |
| ใช้ปานกลาง | ~$500 | ~$90 | 82% |
| ใช้หนัก | ~$1,750 | ~$220 | 87% |
ตัวเลขเหล่านี้สอดคล้องกับรายงานจริงจากผู้ใช้สองแหล่งอิสระ: ประสบการณ์ที่ Praney Behl บันทึกไว้จาก (ลด 90%) และกรณีศึกษาของ LaoZhang ที่แสดงผลจากการปรับบางส่วนเป็น
การใช้คำสั่ง /model เพื่อคุมการใช้งานโทเค็นของ OpenClaw แบบทันทีทันใด
คำสั่ง /model จะสลับโมเดลที่ใช้งานสำหรับรอบถัดไป โดย ยังคง context การสนทนาไว้ครบ — ไม่รีเซ็ต ไม่หายประวัติ นี่คือพฤติกรรมประจำวันเล็ก ๆ ที่สะสมเป็นการประหยัดได้มากในระยะยาว
เวิร์กโฟลว์ที่ใช้งานได้จริง:
- กำลังทำ refactor หลายไฟล์ที่ซับซ้อน? ใช้ Sonnet ต่อไป
- แค่ถามว่า “regex นี้ทำอะไร?” ใช้
/model haikuถามเสร็จแล้วสลับกลับ/model sonnet - แค่เขียน commit message หรือปรับเอกสาร? ใช้
/model flash-liteแล้วจบ
คุณสามารถตั้ง alias ใน openclaw.json ภายใต้ commands.aliases เพื่อแมปชื่อสั้น ๆ (haiku, sonnet, opus, flash) ไปยังสตริง provider เต็มรูปแบบ ช่วยประหยัดการพิมพ์ทุกครั้งที่สลับโมเดล
คณิตศาสตร์ง่าย ๆ: 50 queries/วันบน Sonnet อยู่ราว $3/วัน ถ้าแบ่ง 50 queries เดิมเป็นสัดส่วน 70/20/10 ระหว่าง Haiku/Sonnet/Opus จะเหลือประมาณ $1.10/วัน ตลอดเดือนจะกลายเป็น $90 → $33 — ถูกลง 63% โดยไม่ต้องเปลี่ยนเครื่องมือ แค่เปลี่ยนนิสัยการใช้งาน
โบนัส: ติดตามราคาของโมเดล OpenClaw ข้ามหลายผู้ให้บริการด้วย Thunderbit
ด้วยจำนวนโมเดลและผู้ให้บริการที่มีมากมาย — OpenRouter, API ของ Anthropic โดยตรง, Google AI Studio, DeepSeek, MiniMax — ราคาจึงเปลี่ยนบ่อยมาก Anthropic เคยลดราคา output ของ Opus ลงราว 67% แบบข้ามคืน Google ก็ปรับลดข้อจำกัด free-tier ของ Gemini ลง ในเดือนธันวาคม 2025 การดูแลสเปรดชีตราคาแบบคงที่ด้วยมืออย่างเดียว แทบเป็นสงครามที่ไม่มีทางชนะ
แก้ปัญหานี้ได้โดยไม่ต้องเขียนสคริปต์ scraping เลย มันคือ AI web scraper แบบ ที่สร้างมาเพื่อการดึงข้อมูลแบบมีโครงสร้างโดยเฉพาะ
เวิร์กโฟลว์ที่ผมใช้คือ:
- เปิดหน้ารวมโมเดลของ OpenRouter ใน Chrome แล้วคลิก “AI Suggest Fields” ของ Thunderbit ระบบจะอ่านหน้าและเสนอคอลัมน์ให้ เช่น ชื่อโมเดล, ราคา input, ราคา output, context window, provider
- กด Scrape แล้วส่งออกตรงไปยัง Google Sheets
- ตั้ง scheduled scrape ด้วยภาษาธรรมดา เช่น “ทุกวันจันทร์เวลา 9 โมงเช้า ให้ดึงรายการโมเดลของ OpenRouter ใหม่อีกครั้ง” แล้วระบบจะทำงานบนคลาวด์ให้อัตโนมัติ
หลังจากนั้น ตัวติดตามราคาส่วนตัวของคุณจะอัปเดตตัวเอง ถ้าโมเดลไหนถูกลงทันที 30% หรือผู้ให้บริการไหนได้แท็ก Exacto โผล่ขึ้นมา มันจะไปปรากฏในสเปรดชีตเช้าวันจันทร์ของคุณโดยที่คุณไม่ต้องทำอะไรเลย เราเขียนเพิ่มเติมเกี่ยวกับ ไว้ในบล็อกของเราแล้ว
ถ้าคุณต้องเทียบราคาจากหน้าผู้ให้บริการโดยตรง (Anthropic, Google, DeepSeek)? การ scrape แบบ subpage ของ Thunderbit จะตามลิงก์แต่ละโมเดลเข้าไปยังหน้ารายละเอียด แล้วดึงเรตราคาแยกผู้ให้บริการให้ เหมาะมากเวลาคุณอยากรู้ว่า routing Kimi K2.5 ผ่าน OpenRouter คุ้มกว่าการไปตรงผ่าน หรือไม่ ดูรายละเอียดแผนฟรีและแพ็กเกจได้ที่
ประเด็นสำคัญสำหรับการลดการใช้งานโทเค็นของ OpenClaw
กรอบคิดคือ: เข้าใจ → ติดตาม → จัดเส้นทาง → ปรับแต่ง
สิ่งที่ให้ผลมากที่สุด เรียงตามลำดับ:
- อย่าใช้ Opus เป็นค่าเริ่มต้น เปลี่ยนโมเดลหลักเป็น Sonnet หรือ MiniMax M2.7 แค่นี้ก็ลดต้นทุนได้ 3–5 เท่าแล้ว
- แยก heartbeat ออกไป ตั้ง
isolatedSession: trueและ route heartbeat ไป Gemini Flash-Lite จากจุดที่กิน ~100k tokens จะเหลือ ~2–5k - ส่ง sub-agent ไป Haiku ทุกครั้งที่ spawn จะโหลด context ราว 20k tokens ก่อนเริ่มงาน อย่าให้สิ่งนี้เกิดบน Opus
- ใช้
/clearอย่างเคร่งครัด ฟรี ใช้เวลา 5 วินาที และตามฉันทามติของชุมชน มันช่วยประหยัดได้มากกว่าวิธีใดวิธีหนึ่ง - เพิ่ม
.clawignoreการตัดnode_modules, lockfiles และไฟล์ build ออกจาก context ช่วยลด bootstrap อย่างมาก - มอนิเตอร์ด้วย
/context detailก่อนและหลังปรับ ถ้าวัดไม่ได้ ก็พัฒนาไม่ได้
โมเดลที่ถูกที่สุดขึ้นอยู่กับงาน Gemini Flash-Lite สำหรับ heartbeat, MiniMax M2.7 สำหรับเขียนโค้ดประจำวัน, Haiku สำหรับการเรียกเครื่องมือที่เชื่อถือได้, Sonnet สำหรับงานหลายขั้นที่ซับซ้อน และ Opus ไว้สำหรับปัญหาที่ยากจริง ๆ เท่านั้น — อย่างอื่นไม่ควรใช้
ผู้อ่านส่วนใหญ่สามารถเห็นการประหยัดได้ 50–70% ภายในบ่ายเดียวด้วย Config A หรือ B ถ้าจะไปถึง 85–90% แบบเต็ม ต้องใช้ทุกอย่างประกอบกัน — model routing, แก้ hidden drain, .clawignore, วินัยในการจัดเซสชัน — แต่ทำได้จริง และผลลัพธ์อยู่ทน
คำถามที่พบบ่อย
1. OpenClaw มีค่าใช้จ่ายต่อเดือนเท่าไหร่?
ขึ้นอยู่กับคอนฟิก ปริมาณการใช้งาน และการเลือกโมเดลเป็นหลัก ผู้ใช้เบา ๆ (~10 queries/วัน) มักใช้ประมาณ $5–30/เดือนเมื่อปรับแต่งแล้ว หรือ $100+ ถ้าใช้ค่าเริ่มต้น ผู้ใช้ระดับปานกลาง (~50 queries/วัน) จะอยู่ราว $90–400/เดือน ผู้ใช้หนักอาจแตะ หากใช้ค่าเริ่มต้น — มีกรณีสุดโต่งที่บันทึกไว้ถึง $5,623 ในเดือนเดียว Telemetry ภายในของ Anthropic เองยังบอกว่าค่ากลางอยู่ที่ประมาณ
2. โมเดล OpenClaw ที่ถูกที่สุดแต่ยังใช้งานเขียนโค้ดได้ดีคืออะไร?
คือโมเดล daily driver ที่ดีที่สุดโดยรวม — ความน่าเชื่อถือในการเรียกเครื่องมือดี, SWE-Pro 56.22, ในราคาประมาณ $0.28/$1.10 ต่อหนึ่งล้านโทเค็น สำหรับ heartbeat และการค้นหาแบบง่าย Gemini 2.5 Flash-Lite ที่ $0.10/$0.40 ก็หาตัวสู้ยาก ส่วน Claude Haiku 4.5 ที่ $1/$5 คือ fallback ระดับกลางที่ไว้ใจได้เมื่อคุณต้องการเรียกเครื่องมือได้ดีเยี่ยมโดยไม่ต้องจ่ายราคา Sonnet
3. ใช้โมเดล free-tier กับ OpenClaw ได้ไหม?
ในเชิงเทคนิค ได้ GPT-OSS-120B ฟรีบนแท็ก :free ของ OpenRouter และ NVIDIA Build, Gemini Flash-Lite มี free tier (15 RPM, 1,000 requests/วัน), ส่วน DeepSeek ให้ แต่ free tier มักจำกัด rate หนัก ความเร็วช้ากว่า และความพร้อมใช้งานไม่นิ่ง โมเดลราคาถูกแบบเสียเงิน — แค่เศษเงินต่อหนึ่งล้านโทเค็น — มักเชื่อถือได้กว่าสำหรับการใช้งานประจำ
4. สลับโมเดลกลางคันด้วย /model แล้ว context จะหายไหม?
ไม่หาย /model จะเก็บ context ของเซสชันไว้ครบ แล้วส่ง turn ถัดไปไปยังโมเดลใหม่พร้อมประวัติเดิมทั้งหมด พฤติกรรมนี้ยืนยันไว้ในเอกสาร concepts ของ OpenClaw และทำงานเหมือนกันกับ Claude Code คุณสามารถสลับไปมาระหว่าง Haiku สำหรับคำถามเร็ว ๆ กับ Sonnet สำหรับงานซับซ้อนได้โดยไม่เสียอะไร
5. วิธีที่เร็วที่สุดในการลดบิล OpenClaw วันนี้คืออะไร?
พิมพ์ /clear ระหว่างงานที่ไม่เกี่ยวกัน ฟรี ใช้เวลา 5 วินาที และลบประวัติการสนทนาที่ถูกส่งซ้ำในทุก API call มี session จริงหนึ่งอันที่แสดง ของ message history ที่สะสมไว้ — ทั้งหมดนั้นถูกส่งซ้ำและคิดเงินซ้ำในทุก turn การล้างก่อนเริ่มงานใหม่คือพฤติกรรมที่ให้ผลคุ้มค่าสูงสุดที่คุณสร้างได้