การปรับแต่งคิวรีของ apollo lists ไม่ได้เป็นแค่เรื่องเทคนิคจ๋า ๆ แต่มันคือ “สกิลเอาตัวรอด” ของคนที่ต้องพึ่งพาข่าวแบบเรียลไทม์ การดึงข่าวอัตโนมัติ หรือเวิร์กโฟลว์งานขาย/ปฏิบัติการที่ต้องวิ่งเร็วตลอดเวลา ผมเห็นมากับตาว่าแค่คิวรี list ที่ช้า ก็ทำให้แดชบอร์ดที่ดูโปร ๆ กลายเป็นคอขวดได้ทันที—ทีมขายนั่งมองวงกลมโหลดไม่จบ ส่วนทีม ops ก็ต้องแก้ขัดด้วยสเปรดชีตไปก่อน ในโลกที่ ทุกมิลลิวินาทีมีความหมายจริง ๆ

แล้วจะทำยังไงให้ Apollo Client list queries เร็วแบบสายฟ้าแลบ เสถียร และสเกลได้—โดยเฉพาะเวลาคุณต้องสแครปข่าว ติดตามลีด หรือขับเคลื่อนแดชบอร์ดที่สำคัญต่อธุรกิจ? ในคู่มือนี้ผมจะสรุปแนวทางที่ได้เรียนรู้มา (บางอย่างก็เรียนรู้จากความเจ็บปวดล้วน ๆ) ตั้งแต่การออกแบบคิวรี การทำแคช การแบ่งหน้า ไปจนถึงการต่อเครื่องมือ no-code อย่าง เพื่อจัดระบบงานหนัก ๆ เรื่องการดึงข่าวอัตโนมัติให้เป็นเรื่องเป็นราว ไม่ว่าคุณจะเป็นนักพัฒนา PM หรือคนที่โดนเรียกทุกครั้งที่แดชบอร์ดช้า นี่คือคู่มือภาคปฏิบัติสำหรับยกระดับประสิทธิภาพ Apollo GraphQL list ของคุณ (รวมถึงเคส apollo missions ที่ต้องยิงข้อมูลถี่ ๆ และงานที่อยากเอา apollp ai มาช่วยให้เวิร์กโฟลว์ลื่นขึ้นด้วย)
ทำไมต้องปรับแต่ง Apollo List Queries? (apollo client list performance, optimize apollo list queries)
พูดกันแบบไม่อ้อมค้อม ไม่มีใครอยากรอให้หัวข้อข่าวหรือรายชื่อลีดโหลด ในสภาพแวดล้อมธุรกิจ—โดยเฉพาะทีมที่พึ่งพา หรือข้อมูลเรียลไทม์—คิวรี Apollo list ที่ช้าไม่ได้แค่ทำให้หงุดหงิด แต่มันทำให้เสียเงิน ตัดสินใจช้า และสุดท้ายก็ผลักคนกลับไปทำงานมืออีก บอกว่าพนักงานออฟฟิศใช้เวลาประมาณ หนึ่งในสามของวันไปกับงานมูลค่าต่ำ ซึ่งมักเกิดจากเครื่องมือที่ช้าหรือข้อมูลกระจัดกระจาย
สิ่งที่มักเกิดขึ้นเมื่อ list queries ไม่ได้ถูกปรับแต่ง:
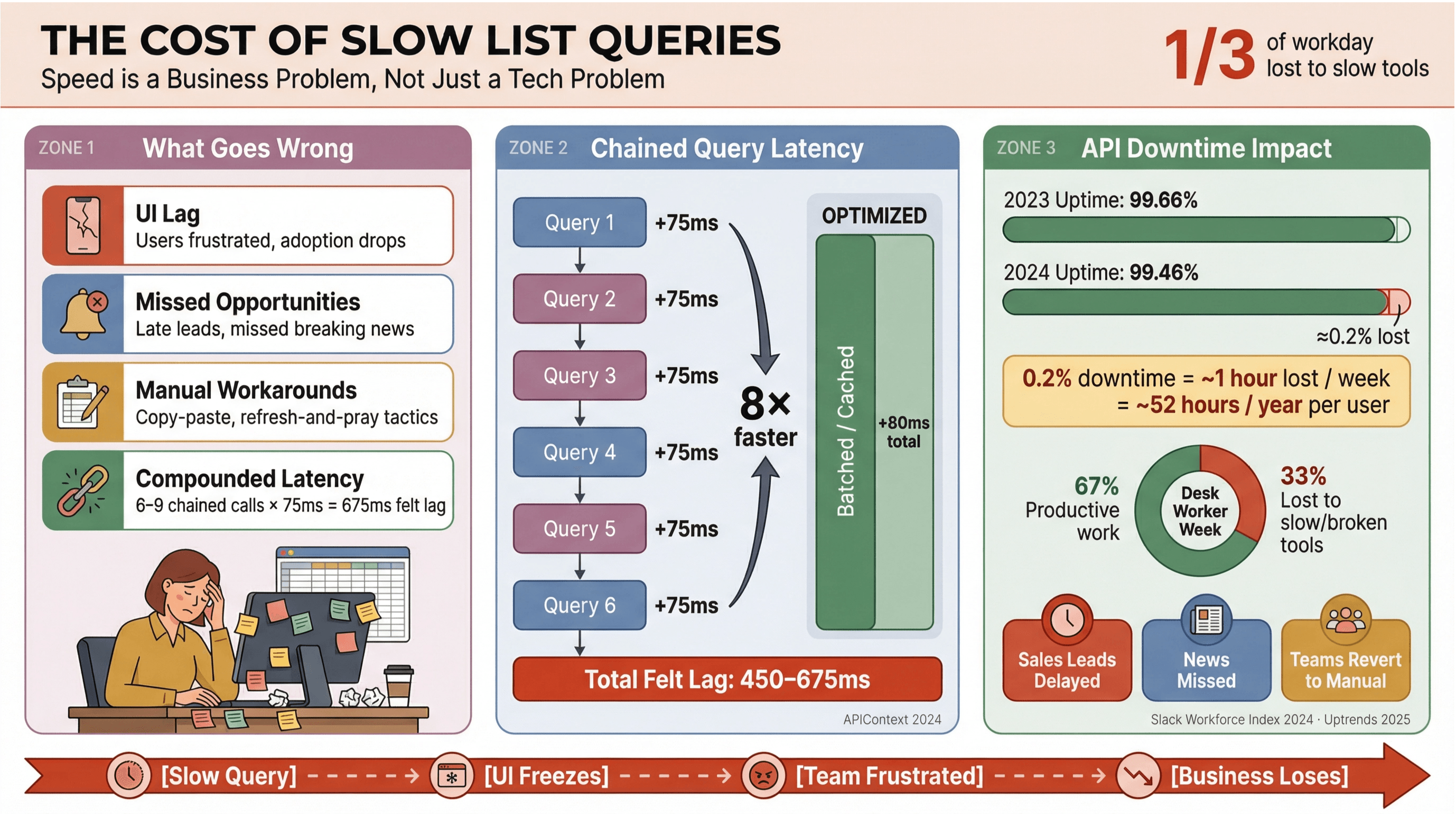
- UI หน่วง: ผู้ใช้เจอดีเลย์จนหงุดหงิด แล้วก็ใช้งานน้อยลง
- พลาดโอกาส: งานขายหรือมอนิเตอร์ข่าว แค่ช้าหลายวินาทีก็อาจพลาดลีดร้อนหรือข่าวด่วน
- หันไปใช้วิธีแก้ขัด: ทีมกลับไป copy-paste, สเปรดชีต หรือ “กดรีเฟรชแล้วภาวนา”
- ความหน่วงสะสม: ทุก API call ที่ช้าจะทบกัน—ถ้าเวิร์กโฟลว์ของคุณต้องยิงคิวรีต่อเนื่อง 6–9 ครั้ง ดีเลย์แค่ 75ms ต่อครั้ง ก็อาจกลายเป็นความหน่วงที่ผู้ใช้ “รู้สึกได้” 450–675ms ()
และมันไม่ใช่แค่เรื่องความเร็วอย่างเดียวด้วย โดยค่า uptime เฉลี่ยลดจาก 99.66% เหลือ 99.46% ภายในปีเดียว—แปลเป็นเวลาสูญเสียประสิทธิภาพเกือบชั่วโมงต่อสัปดาห์สำหรับแอปที่ใช้ list หนัก ๆ ถ้าธุรกิจคุณต้องพึ่งข่าวเรียลไทม์ นี่คือความเสี่ยงที่มองข้ามไม่ได้เลย
เลือกโครงสร้างข้อมูลและฟิลด์ให้เหมาะ (apollo graphql list best practices)
ความผิดพลาดที่เจอบ่อย (และผมก็เคยพลาดเอง) คือปฏิบัติกับ list query เหมือนเป็น detail query ทั้งหมด ทั้งที่ใน GraphQL คุณเลือกดึง “เท่าที่จำเป็น” ได้—ใช้ให้คุ้ม เพราะการดึงเกิน (overfetching) คือศัตรูตัวฉกาจของประสิทธิภาพ โดยเฉพาะเครื่องมือสแครปข่าวและแดชบอร์ดเรียลไทม์
ปรับฟิลด์ให้เหมาะกับการดึงข่าวอัตโนมัติ
สมมติคุณทำฟีดข่าว คุณจำเป็นต้องดึงเนื้อหาทั้งบทความ แท็กทั้งหมด คอมเมนต์ และประวัติผู้เขียนใน list query ไหม? ส่วนใหญ่ไม่จำเป็น นี่คือความต่าง:
List Query ที่มีประสิทธิภาพ:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}List Query ที่หนักเกินไป (อย่าทำแบบนี้):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}คิวรีแรก “เบาและตรงจุด” เหมาะกับการจัดอันดับ กรอง และเรนเดอร์รายการ ส่วนคิวรีที่สองคือ detail query ที่ปลอมตัวมา—ดึง payload ใหญ่จนทำให้ทุกอย่างช้าลง (, )
ทริก: ใช้แนวคิดสองชั้น—list ดึงเฉพาะฟิลด์เบา ๆ แล้วค่อยโหลดข้อมูลหนัก (เช่น full text หรือการทำ NLP enrichment) ตอนผู้ใช้เปิดรายการหรือโฮเวอร์
ใช้ Apollo Client Cache ให้คิวรีเร็วขึ้น (apollo client list performance)
แคชของ Apollo Client คืออาวุธลับสำหรับ list queries ที่อยากให้ลื่น ๆ ถ้าตั้งค่าดี คุณจะได้:
- คิวรีเดิมตอบกลับทันที (ไม่ต้องวิ่งไปเครือข่าย)
- ลดภาระเซิร์ฟเวอร์และค่าใช้จ่าย API
- ย้อนกลับ/ไปหน้าเดิม และเปลี่ยนฟิลเตอร์ได้เนียนขึ้น
แต่แคชไม่ใช่เวทมนตร์—ต้องตั้งค่าให้ถูก และต้องมีวินัยพอสมควร
ตั้งค่า Cache Policies ให้เหมาะ
Apollo รองรับ หลายแบบ:
| Policy | ทำอะไร | เหมาะกับลิสต์ข่าวแบบไหน |
|---|---|---|
| cache-first | อ่านจากแคชก่อน ถ้าไม่มีค่อยดึงจากเครือข่าย | กลับมาดูลิสต์เดิม, สลับฟิลเตอร์, ย้อนกลับ/ไปข้างหน้า |
| network-only | ดึงจากเครือข่ายทุกครั้ง | รีเฟรชเอง, “หัวข้อข่าวล่าสุด” |
| cache-and-network | แสดงจากแคชก่อน แล้วอัปเดตด้วยผลจากเครือข่าย | เปิดหน้าไว + อัปเดตเบื้องหลัง (เหมาะกับฟีดข่าว) |
| no-cache | ดึงทุกครั้งและไม่เก็บลงแคช | คิวรีเฉพาะกิจที่อ่อนไหว (ไม่ค่อยใช้กับลิสต์) |
สำหรับข้อมูลข่าวเรียลไทม์ ผมมักเทใจให้ cache-and-network เพราะผู้ใช้เห็นผลทันที แล้วค่อยอัปเดตเบื้องหลัง แต่ต้องระวังอาการ UI กระพริบถ้าข้อมูลมีการเรียงใหม่ตอนรีเฟรช ()
ทิปการตั้งค่าแคช:
- ใช้ ID ที่คงที่ (
idหรือ_id) เพื่อ normalization () - ปรับขนาดแคชและ garbage collection ให้เหมาะกับลิสต์ใหญ่ ()
- เลี่ยงการเก็บก้อนข้อมูลใหญ่แบบไม่ normalize ไว้ใต้
ROOT_QUERYเพราะอาจทำให้แอปหน่วง ()
ทำ Pagination และจำกัดจำนวนรายการ (apollo graphql list best practices)
ถ้าคุณโหลดข่าวหรือรายชื่อลีดทีละหลายร้อย/หลายพันรายการ คุณกำลังชวนให้เกิดปัญหาแบบเต็ม ๆ Pagination ไม่ใช่แค่เรื่อง UX แต่มันคือ “ข้อจำเป็นด้านประสิทธิภาพ”
Apollo รองรับทั้ง และ โดยเปรียบเทียบได้ดังนี้:
| ประเภท Pagination | ข้อดี | ข้อเสีย | เหมาะกับ |
|---|---|---|---|
| Offset-based | เข้าใจง่าย ทำตามได้เร็ว | ข้อมูลเลื่อนแล้วอาจข้าม/ซ้ำรายการ | ลิสต์เล็กหรือข้อมูลไม่เปลี่ยน |
| Cursor-based | เสถียรกว่า รับมือข้อมูลเปลี่ยนได้ดี | ซับซ้อนขึ้นเล็กน้อย | ฟีดข่าว, ลิสต์ใหญ่ |
สำหรับลิสต์ข่าวเรียลไทม์หรือรายชื่อลีดส่วนใหญ่ cursor-based pagination คือคำตอบ เพราะช่วยให้ข้อมูลสอดคล้องแม้มีรายการใหม่เข้ามาหรือรายการเก่าถูกลบ ()
ทิป Pagination ใน Apollo:
- ตั้งค่า
keyArgsเพื่อคุม cache keys ของฟิลด์ที่แบ่งหน้า () - เขียน
mergefunction เพื่อรวมหน้าต่าง ๆ ในแคช - ใช้
fetchMoreเพื่อโหลดหน้าถัดไปโดยไม่ทับผลเดิม
แพตเทิร์น Pagination ที่ใช้ได้จริงกับเครื่องมือสแครปข่าว
UI ข่าวที่ดีมักจะ:
- แสดงหัวข้อข่าวล่าสุด 20–50 รายการ (ดึงเฉพาะฟิลด์เบา ๆ)
- โหลดเพิ่มเมื่อเลื่อนหรือกด “หน้าถัดไป”
- ดึงรายละเอียดเมื่อจำเป็นเท่านั้น
ผลลัพธ์คือ UI เร็ว API ไม่โดนถล่ม และผู้ใช้ทำงานต่อได้แบบไม่สะดุด
เชื่อม Thunderbit เพื่อดึงข่าวอัตโนมัติ
ทีนี้มาถึงคำถามใหญ่: แล้วข้อมูลข่าวแบบมีโครงสร้าง (structured) มาจากไหน? ตรงนี้แหละที่ เข้ามาช่วย
Thunderbit คือส่วนขยาย Chrome แบบ no-code ที่เป็น AI Web Scraper สามารถดึงหัวข้อข่าว URL แหล่งข่าว ผู้เขียน วันที่เผยแพร่ สรุป และรูปภาพจากแทบทุกเว็บไซต์ได้โดยไม่ต้องเขียนโค้ด ผมเห็นหลายทีมใช้ Thunderbit ทำให้กระบวนการดึงข่าวทั้งระบบเป็นอัตโนมัติ เปลี่ยนหน้าเว็บที่กระจัดกระจายให้กลายเป็นข้อมูลสะอาด ๆ พร้อมป้อนเข้าฐานข้อมูลหรือ GraphQL API ได้ทันที
ใช้ Thunderbit คู่กับ Apollo เพื่อข้อมูลข่าวเรียลไทม์
เวิร์กโฟลว์ที่ผมชอบสำหรับทีมขายและ ops ที่ต้องการข่าวอัปเดตตลอด:
- ชั้นดึงข้อมูล: ใช้ ของ Thunderbit เพื่อดึงข่าวแบบมีโครงสร้างตามตารางเวลา
- ชั้นจัดเก็บ: เก็บข้อมูลที่สแครปไว้ในฐานข้อมูลที่ออกแบบให้ดึงเร็ว
- ชั้น GraphQL: เปิดให้เรียก
newsFeedสำหรับลิสต์ และnewsArticle(id)สำหรับรายละเอียดผ่าน API - ชั้น Client: ใช้ Apollo Client ดึงลิสต์ (ฟิลด์เบา ๆ + แบ่งหน้า) และค่อยดึงรายละเอียดเมื่อจำเป็น
พายป์ไลน์ “สแครป → เก็บ → คิวรี” แบบนี้ทำให้ Apollo queries ของคุณทำงานกับข้อมูลใหม่และเป็นโครงสร้างเสมอ—ไม่ต้อง copy-paste และไม่ต้องพึ่งสคริปต์ที่พังง่าย
โบนัส: Thunderbit ยังช่วยเติมฟิลด์เพิ่ม (เช่น sentiment หรือหมวดหมู่) ด้วยคำแนะนำฟิลด์จาก AI ทำให้ฟีดข่าวฉลาดขึ้นอีกขั้น (ถ้าทีมคุณกำลังทดลอง apollp ai ในงาน enrichment ก็ยิ่งเข้าทาง)
คู่มือทีละขั้น: ปรับแต่ง Apollo List Queries
พร้อมลงมือแล้วใช่ไหม? นี่คือเช็กลิสต์ที่ผมใช้ประจำสำหรับการปรับแต่ง Apollo list query:
-
ทำคิวรีให้เบาที่สุด
- ขอเฉพาะฟิลด์ที่จำเป็นต่อการแสดงลิสต์ (title, URL, timestamp ฯลฯ)
- ย้ายฟิลด์หนัก (full text, images, enrichment) ไปไว้ใน detail queries
-
ทำ Pagination
- ใช้ cursor-based pagination สำหรับลิสต์ใหญ่หรือข้อมูลที่เปลี่ยนตลอด
- ตั้งค่า
keyArgsและmergeให้แคชถูกต้อง
-
ใช้ Apollo Cache ให้คุ้ม
- Normalize entity ด้วย ID ที่คงที่
- เลือก fetch policy ให้เหมาะ (
cache-and-networkเหมาะกับข่าว) - ปรับขนาดแคชและ garbage collection ให้เหมาะกับปริมาณข้อมูล
-
เชื่อมการดึงข้อมูลอัตโนมัติ
- ใช้ Thunderbit ทำข่าวสแครปอัตโนมัติให้ข้อมูลสดเสมอ
- ส่งออกข้อมูลแบบมีโครงสร้างเข้าฐานข้อมูลหรือสเปรดชีตได้ทันที
-
มอนิเตอร์และแก้ปัญหา
- ใช้ ตรวจคิวรี แคช และประสิทธิภาพ
- เฝ้าดูการเขียนแคชก้อนใหญ่ watched queries ที่มากเกิน และอาการ UI กระตุก
- ติดตาม p95/p99 latency และอัตรา error (, )
การมอนิเตอร์และแก้ปัญหาประสิทธิภาพคิวรี
Devtools ของ Apollo ช่วยชีวิตได้มาก คุณสามารถ:
- ดูคิวรีที่กำลังทำงานและสถานะแคช
- เจอคิวรีซ้ำหรือ watcher ที่มากเกิน
- ระบุปัญหาก้อนข้อมูลใหญ่ในแคชหรือ normalization ที่ผิด
ถ้าเจอ UI หน่วงหรืออัปเดตช้า ให้เช็ก:
- list query ใหญ่เกินไป (ลดฟิลด์)
- normalization ไม่ดี (แก้ ID)
- ปัญหา merge ของ pagination (ตรวจ
keyArgsและmerge)
และอย่าลืมวัด tail latency ไม่ใช่ดูแค่ค่าเฉลี่ย เพราะความเจ็บปวดของผู้ใช้มักซ่อนอยู่ตรงนั้น
เปรียบเทียบการสแครปข่าวแบบเดิม vs แบบขับเคลื่อนด้วย AI
ยอมรับกันตรง ๆ เมื่อก่อนการสแครปข่าวคือการเขียนสคริปต์เอง จัดการ headless browser แล้วก็ได้แต่ภาวนาให้เลย์เอาต์เว็บไม่เปลี่ยนข้ามคืน แต่ตอนนี้ด้วยเครื่องมือ AI อย่าง Thunderbit คุณทำให้ทั้งกระบวนการเป็นอัตโนมัติได้—ไม่ต้องเขียนโค้ด ไม่ต้องปวดหัว
| แนวทาง | จุดแข็ง | ข้อจำกัดสำหรับผู้ใช้ธุรกิจ |
|---|---|---|
| สแครปด้วยสคริปต์ | ปรับแต่งได้สุด คุ้มเมื่อสเกลใหญ่ | ดูแลยาก ต้องใช้เวลาทีมวิศวกร |
| แพลตฟอร์มสแครปแบบ Managed | เริ่มได้ไว โยนงาน anti-bot ให้แพลตฟอร์ม | ยังต้องตั้งค่า และค่าใช้จ่ายเพิ่มตามการใช้งาน |
| การดึงข้อมูลด้วย AI (Thunderbit) | รับมือเลย์เอาต์ยุ่ง ๆ ได้ ไม่ต้องเขียนโค้ด | ต้อง QA ผลลัพธ์ และเชื่อมเข้ากับสคีมาของคุณ |
| No-code visual scrapers | คนไม่ใช่วิศวกรก็ใช้ได้ | พังได้เมื่อ UI เปลี่ยน สเกลจำกัด |
| โครงสร้าง proxy/unlocker | ช่วยผ่านบล็อก รองรับ throughput สูง | ยังต้องมีตรรกะการดึงข้อมูล และมีความเสี่ยงด้าน compliance |
หมายเหตุด้านกฎหมาย: การสแครปข้อมูลสาธารณะโดยทั่วไปทำได้ แต่ควรเคารพเงื่อนไขการใช้งานและ rate limits เสมอ ()
สรุปหัวใจสำคัญ: Apollo GraphQL List Best Practices
สรุปประเด็นหลัก:
- โฟกัสความเร็วและความชัดเจน: ทำ list query ให้เบา แบ่งหน้า และใช้แคชอย่างจริงจัง
- โครงสร้างสำคัญ: ดึงเท่าที่จำเป็น—ฟิลด์หนักย้ายไป detail query
- แคชคือเพื่อนแท้: ใช้ normalization และ fetch policies ของ Apollo เพื่อเสิร์ฟข้อมูลทันที
- ทำการดึงข้อมูลให้เป็นอัตโนมัติ: เครื่องมืออย่าง ทำให้การสแครปข่าวและการ enrich ลิสต์เป็นเรื่องที่ทุกคนทำได้
- มอนิเตอร์และปรับต่อเนื่อง: ใช้ Devtools และแดชบอร์ด observability เพื่อจับคอขวดตั้งแต่เนิ่น ๆ
สำหรับทีมขาย ทีม ops และทีมข่าว แนวทางเหล่านี้แปลว่า “รอน้อยลง ลงมือได้มากขึ้น” และลดข้อความใน Slack แนว “ทำไมมันช้าจัง?” ลงได้เยอะ
บทสรุป: ขั้นต่อไปในการปรับแต่ง Apollo List Queries ของคุณ
ถ้าคุณยังใช้ list queries ที่หนัก ไม่แบ่งหน้า หรือไม่เป็นมิตรกับแคช ตอนนี้คือเวลาตรวจและอัปเกรด เริ่มจากเรื่องเล็ก ๆ: ตัดฟิลด์ที่ไม่จำเป็น ใส่ pagination และปรับแคชให้เหมาะ จากนั้นค่อยยกระดับด้วยการเชื่อมเครื่องมือดึงข้อมูลอัตโนมัติอย่าง เพื่อให้ข้อมูลสดและพร้อมใช้งานตลอด
อยากลงลึกกว่านี้? ไปดู , หรือเข้าร่วม เพื่อทิปจากการใช้งานจริงและการแก้ปัญหา และถ้าคุณพร้อมทำการดึงข่าวอัตโนมัติ ลองใช้ ของ Thunderbit ได้เลย—เหมาะมากสำหรับคนที่ต้องการข้อมูลเรียลไทม์แบบไม่ต้องปวดหัว
ขอให้คิวรีของคุณลื่นไหล—และขอให้ลิสต์โหลดเสร็จก่อนกาแฟจะเย็น
FAQs
1. ทำไม Apollo list queries ถึงช้าลงในแดชบอร์ดข่าวเรียลไทม์หรือแดชบอร์ดงานขาย?
คิวรีลิสต์มักช้าลงเมื่อดึงข้อมูลมากเกินไป ไม่ทำ pagination หรือไม่ได้ตั้งค่าแคชอย่างถูกต้อง ในงานที่ต้องเรียกบ่อยอย่างการมอนิเตอร์ข่าว ดีเลย์เล็ก ๆ จะสะสมจนเกิด UI หน่วงและทำให้ประสิทธิภาพตก
2. โครงสร้าง Apollo list queries ที่เหมาะกับการดึงข่าวอัตโนมัติควรเป็นแบบไหน?
ขอเฉพาะฟิลด์ที่จำเป็นต่อการแสดงลิสต์ (เช่น title, URL, timestamp) แล้วย้ายฟิลด์หนัก (เช่นเนื้อหาทั้งบทความหรือรูปภาพ) ไปไว้ใน detail queries พร้อมทำ pagination เพื่อให้ payload เล็กและเร็ว
3. แคชของ Apollo Client ช่วยให้ลิสต์เร็วขึ้นอย่างไร?
แคชจะเก็บข้อมูลที่เคยดึงไว้ ทำให้คิวรีเดิมตอบกลับได้ทันที การทำ normalization ให้ถูกและเลือก fetch policy ที่เหมาะ (เช่น cache-and-network) ช่วยเร่งความเร็วหน้าลิสต์และลดภาระเซิร์ฟเวอร์ได้มาก
4. Thunderbit ช่วยเรื่องสแครปข่าวและการเชื่อมกับ Apollo ได้อย่างไร?
Thunderbit เป็น AI Web Scraper แบบ no-code ที่ดึงข้อมูลข่าวแบบมีโครงสร้างจากเว็บไซต์ใดก็ได้ คุณสามารถทำให้การดึงข่าวเป็นอัตโนมัติ แล้วส่งข้อมูลเข้าฐานข้อมูลหรือ GraphQL API เพื่อใช้งานร่วมกับ Apollo Client ได้
5. มีเครื่องมืออะไรช่วยมอนิเตอร์และแก้ปัญหาประสิทธิภาพ Apollo list query ได้บ้าง?
ช่วยตรวจคิวรี สถานะแคช และประสิทธิภาพแบบเรียลไทม์ ควบคู่กับแดชบอร์ด observability (เช่น New Relic หรือ Uptrends) เพื่อดู latency และ error rates แล้วปรับการออกแบบคิวรีให้เหมาะที่สุด
อยากได้ทิปเพิ่มเรื่อง web scraping, automation และเวิร์กโฟลว์ข้อมูลเรียลไทม์? ไปที่ เพื่ออ่านบทความเชิงลึก คู่มือ และอัปเดตล่าสุดด้านประสิทธิภาพที่ขับเคลื่อนด้วย AI
เรียนรู้เพิ่มเติม