เมื่อก่อนการ จ้างนักพัฒนา web scraping ยังถือว่าเป็นงานเฉพาะทางสุด ๆ—มักจะไปอยู่ในมือของนักวิทยาศาสตร์ข้อมูล หรือไม่ก็สายมาร์เก็ตติ้งที่ค่อนข้างเทค ๆ หน่อยและอยากทำอะไร “นอกกรอบ” แต่พอเข้าปี 2025 ภาพมันเปลี่ยนไปแบบคนละเรื่อง แทบทุกทีมขาย ทีมปฏิบัติการ หรือทีมการตลาดที่ผมคุยด้วย ต่างก็เริ่มมองหา ผู้เชี่ยวชาญ web scraping ฟรีแลนซ์ หรือ ผู้เชี่ยวชาญการดึงข้อมูลจากเว็บ กันเป็นเรื่องปกติ ทำไมถึงเป็นแบบนั้น? เพราะเว็บคือฐานข้อมูลที่ใหญ่ที่สุดในโลก—และก็รกที่สุดด้วย—แถมแรงกดดันในการเปลี่ยนความวุ่นวายนั้นให้กลายเป็นอินไซต์ที่เอาไปใช้ได้จริงก็ยิ่งเพิ่มขึ้นเรื่อย ๆ ผมเห็นมากับตาว่าการจ้าง “คนที่ใช่” (หรือ “คนที่ไม่ใช่”) สามารถทำให้โปรเจกต์ไปได้สวยแบบลื่น ๆ หรือพังยับแบบกู้ไม่กลับได้เลย
ตลาด Web Scraping และการดึงข้อมูลกำลังโตแบบแรงมาก คาดว่าการใช้จ่ายทั่วโลกจะเพิ่มขึ้นเป็น 4 เท่าในทศวรรษหน้า () แต่ในเวลาเดียวกัน เว็บไซต์ก็เปลี่ยนหน้าตา/โครงสร้างตลอด ระบบกันบอทก็ฉลาดขึ้นทุกวัน และฝั่งธุรกิจก็ต้องการข้อมูลที่ “สะอาดกว่า” และ “เร็วกว่า” เดิมอีก ทำให้การเลือกคนให้ถูก (หรือเลือกเครื่องมือให้เหมาะ) สำคัญกว่าที่เคย ดังนั้นไม่ว่าคุณจะเป็นผู้ก่อตั้ง หัวหน้าทีม หรือเป็น “คนข้อมูล” ที่โดนจับฉลากให้รับงานนี้ เรามาไล่กันทีละขั้นว่าควร จ้างนักพัฒนา web scraping ยังไง—และเมื่อไหร่ที่จริง ๆ แล้วคุณอาจไม่จำเป็นต้องจ้างเลย
นักพัฒนา Web Scraping ทำอะไรบ้าง?
นักพัฒนา Web Scraping คือ “สะพาน” ที่เชื่อมโลกอินเทอร์เน็ตอันดิบเถื่อนเข้ากับสเปรดชีตหรือระบบข้อมูลที่ทีมของคุณเอาไปใช้งานได้จริง หน้าที่หลักคือแปลงหน้าเว็บที่เปลี่ยนไปเปลี่ยนมาและข้อมูลที่กระจัดกระจาย ให้กลายเป็นชุดข้อมูลที่มีโครงสร้างและเชื่อถือได้—เช่น CSV, JSON หรือส่งเข้าฐานข้อมูลโดยตรง แต่บอกเลยว่าไม่ใช่แค่เขียนสคริปต์ไว ๆ แล้วจบ งานจริงคือทำให้สคริปต์นั้น “ยังรันได้” แม้เว็บจะเปลี่ยน จัดการการแบ่งหน้า (pagination) การไล่เก็บข้อมูลจากหน้ารายละเอียด (subpages) การกันบอท และความจุกจิกของเว็บยุคใหม่ทั้งหมด ()
ความรับผิดชอบที่พบบ่อย ได้แก่:
- ตรวจโครงสร้างหน้าเว็บเพื่อเลือกวิธีดึงข้อมูลที่เหมาะที่สุด (HTML scraping, เรียก API, ใช้ headless browser)
- จัดการคอนเทนต์แบบไดนามิก การเรนเดอร์ JavaScript และขั้นตอนล็อกอิน
- จัดการ pagination และการเก็บข้อมูลเพิ่มจาก subpage (เช่น ดึงรายการสินค้า แล้วเข้าไปแต่ละหน้าสินค้าเพื่อเก็บรายละเอียด)
- ส่งออกข้อมูลให้สะอาดและพร้อมวิเคราะห์ (CSV, JSON, ฐานข้อมูล หรือเชื่อมต่อระบบโดยตรง)
- ตั้งระบบมอนิเตอร์ รีทราย และแจ้งเตือนเมื่อเกิดปัญหา (เพราะมันพังแน่นอน)
- ทำเอกสารสเปกข้อมูล นิยามฟิลด์ และตารางเวลารีเฟรช
ผู้เชี่ยวชาญ web scraping ฟรีแลนซ์ มักถูกจ้างเพื่อโปรเจกต์ครั้งเดียว เป้าหมายเฉพาะทาง หรือทำต้นแบบแบบเร่งด่วน ส่วน ผู้เชี่ยวชาญการดึงข้อมูลจากเว็บแบบ in-house มักเหมาะกว่าเมื่อการดึงข้อมูลเป็นงานหลักที่ต้องทำต่อเนื่องของธุรกิจ—เช่น ติดตามราคาแบบรายวัน สร้างลีด หรือป้อนข้อมูลให้แดชบอร์ดภายใน ()
สำหรับทีมที่ไม่ถนัดเทคนิค บทบาทเหล่านี้โคตรมีค่า เพราะช่วยเปลี่ยนงานก็อปปี้-วางที่กินเวลาหลายชั่วโมงให้กลายเป็นเวิร์กโฟลว์อัตโนมัติ ทำให้นักวิเคราะห์และทีมขายได้ไปโฟกัสงานที่สร้างผลลัพธ์จริง
ทักษะและประสบการณ์ที่ควรมองหาเมื่อคุณจ้างนักพัฒนา Web Scraping
นักพัฒนา “สายสแครป” ไม่ได้เก่งเท่ากันหมด ผมเจอหลายคนที่เขียนสคริปต์ได้ภายในบ่ายเดียว แต่ทำให้มันรันได้เกินหนึ่งสัปดาห์ไม่ได้ นี่แหละคือเส้นแบ่งระหว่างมืออาชีพกับมือสมัครเล่น:
- ทักษะการเขียนโปรแกรมที่แน่นจริง: Python มักเป็นตัวหลัก แต่ JavaScript, Node.js หรือ Go ก็เจอบ่อย มองหาคนที่คุ้นกับไลบรารีอย่าง BeautifulSoup, Scrapy, Selenium หรือ Puppeteer
- ประสบการณ์กับเครื่องมือ Web Scraping: ถ้ารู้ทั้งสายโค้ดและ no-code (เช่น ) จะยิ่งได้เปรียบ คนที่เก่งจริงจะรู้ว่าเมื่อไหร่ควรใช้เครื่องมือ และเมื่อไหร่ควรเขียนเอง
- รับมือเว็บไดนามิกและเว็บที่มีการป้องกัน: เว็บสมัยนี้เต็มไปด้วย JavaScript และระบบกันบอท นักพัฒนาควรถนัด headless browser, proxy, CAPTCHA และการจัดการ session
- มุมมองแบบ data engineering: ไม่ใช่แค่ดึงออกมา—การทำความสะอาด ลบข้อมูลซ้ำ ตรวจความถูกต้อง และจัดโครงสร้างสำคัญพอ ๆ กัน
- ทักษะด้านการทำงานร่วมกัน: สื่อสารชัด ใส่ใจรายละเอียด และแก้ปัญหาเก่ง คุณต้องการคนที่ถามคำถามให้เคลียร์ ไม่ใช่คนที่ตอบว่า “ได้ เดี๋ยวสแครปให้” แล้วหายไป
เช็กลิสต์ทักษะด้านเทคนิค
เช็กลิสต์สั้น ๆ สำหรับคัดกรองผู้สมัคร:
| ทักษะที่ต้องมี | ทักษะที่มีแล้วดี |
|---|---|
| Python (หรือ JS/Node) | ประสบการณ์กับแพลตฟอร์มสแครปบนคลาวด์ |
| การอ่าน/แยก HTML/CSS/DOM | คุ้นเคยกับการทำคอนเทนเนอร์ (Docker) |
| จัดการ pagination และ subpage | ตั้งระบบมอนิเตอร์ ล็อก และแจ้งเตือน |
| กลยุทธ์รับมือกันบอท (proxy, throttling) | เชื่อมต่อ data pipeline (ETL, APIs) |
| ตรวจสอบความถูกต้องของข้อมูล & QA | ความเข้าใจด้านคอมพลายแอนซ์และความเป็นส่วนตัว |
| ใช้เครื่องมืออย่าง Thunderbit, Octoparse ได้ | ประสบการณ์ดึงข้อมูลด้วย AI ช่วย |
อีกข้อที่เป็นแต้มต่อแบบเห็นผล: ผู้สมัครที่ใช้เครื่องมืออย่าง ได้ มักส่งงานได้ไวกว่าและดูแลง่ายกว่า โดยเฉพาะงานธุรกิจทั่วไปที่ต้องทำซ้ำ ๆ
ทำเอง vs จ้างผู้เชี่ยวชาญ Web Scraping: เปรียบเทียบต้นทุนและประสิทธิภาพ
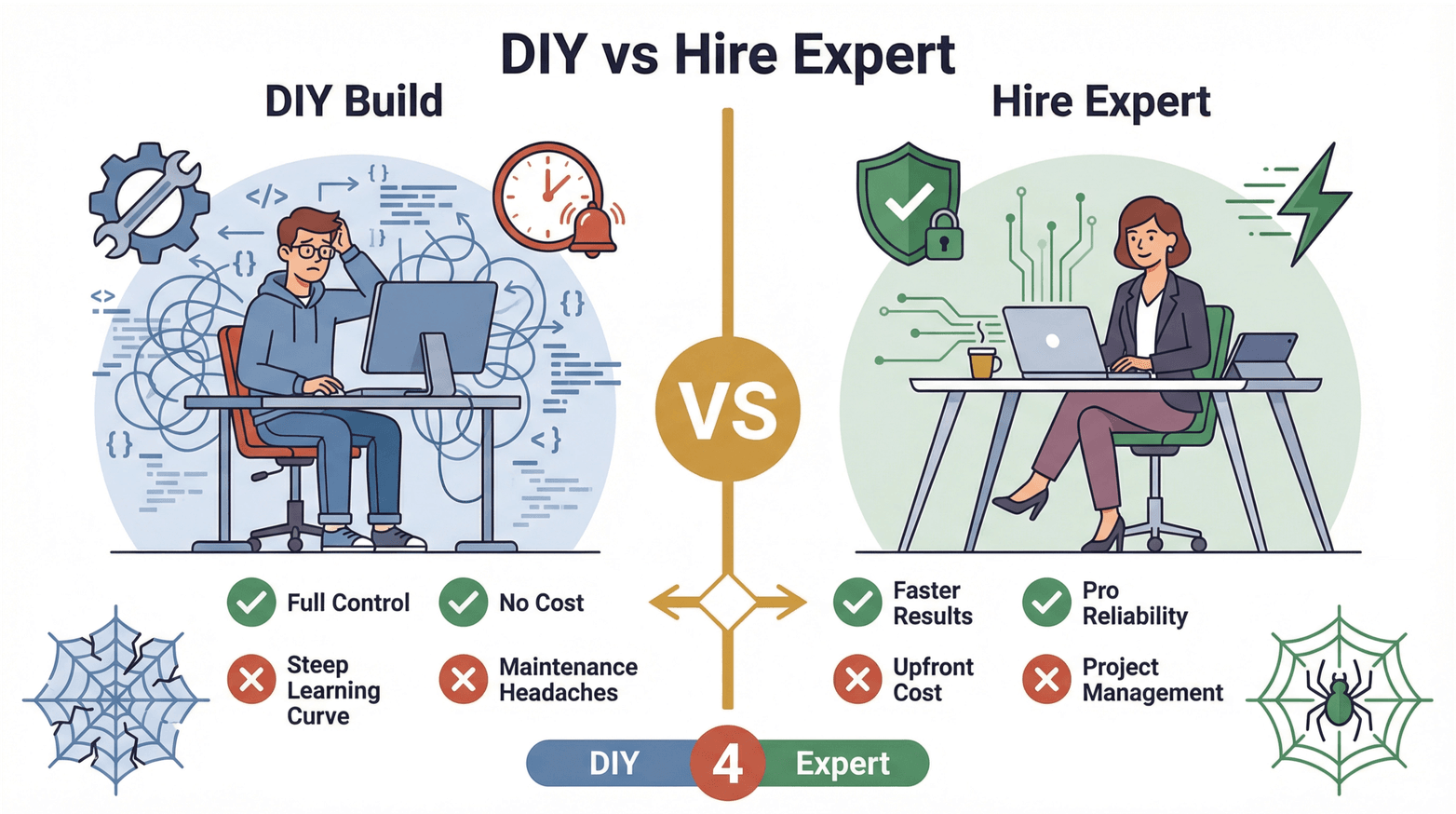
คำถามยอดฮิตคือ คุณควรลงมือทำสแครปเอง หรือจ้าง ผู้เชี่ยวชาญ web scraping ฟรีแลนซ์? มาดูแบบชัด ๆ กัน
DIY (ทำเอง):
- ข้อดี: คุมได้ทั้งหมด ไม่ต้องจ่ายคนนอก เหมาะกับการเรียนรู้
- ข้อเสีย: ต้องใช้เวลาศึกษาเยอะ กินเวลา ดูแลยาก และมักประเมินความซับซ้อนต่ำไป
จ้างผู้เชี่ยวชาญ web scraping ฟรีแลนซ์:
- ข้อดี: ได้ผลลัพธ์เร็ว ความเสถียรระดับมืออาชีพ ลดความเสี่ยงพังเมื่อเว็บเปลี่ยน และได้ความเชี่ยวชาญเฉพาะทาง
- ข้อเสีย: มีค่าใช้จ่ายเริ่มต้น ต้องบริหารโปรเจกต์ และอาจมีช่องว่างด้านการสื่อสาร
ตารางเปรียบเทียบค่าใช้จ่าย:
| แนวทาง | ค่าใช้จ่ายโดยทั่วไป | ระยะเวลาส่งมอบ | การดูแลหลังส่งมอบ |
|---|---|---|---|
| DIY | เวลาของคุณ (ต้นทุนโอกาส) | หลายวันถึงหลายสัปดาห์ (ถ้าต้องเรียนรู้) | คุณรับภาระซ่อม/แก้ทั้งหมด |
| ฟรีแลนซ์ (รายชั่วโมง) | $20–$40/ชม. (upwork.com) | 1–2 สัปดาห์สำหรับงานส่วนใหญ่ | ต่อรองซัพพอร์ตระยะยาวได้ |
| ฟรีแลนซ์ (เหมาจ่าย) | $500–$5,000+ (upwork.com) | 1–4 สัปดาห์ ตามขอบเขตงาน | ค่าดูแลอาจคิดเพิ่ม |
| จ้างประจำ (in-house) | $100k+/ปี (glassdoor.com) | ต่อเนื่อง | เป็นเจ้าของทั้งหมด (พร้อมต้นทุนทั้งหมด) |
เมื่อไหร่ที่ DIY คุ้ม? ถ้าคุณมีพื้นฐานเทคนิค งานไม่ซับซ้อน และโอเคกับการลองผิดลองถูก แต่ถ้าเป็นงานสำคัญต่อธุรกิจ ปริมาณมาก หรือเว็บเปลี่ยนบ่อย การจ้างผู้เชี่ยวชาญมักคุ้มเร็วมาก
เมื่อไหร่ควรเลือกผู้เชี่ยวชาญการดึงข้อมูลจากเว็บ
ควรพิจารณาจ้าง ผู้เชี่ยวชาญการดึงข้อมูลจากเว็บ เมื่อ:
- ต้องสแครปเว็บที่ซับซ้อน ไดนามิก หรือมีการป้องกัน
- ข้อมูลสำคัญต่อธุรกิจ หรือจำเป็นต้องรีเฟรชสม่ำเสมอ
- ต้องเชื่อมต่อกับระบบอื่น (CRM, ฐานข้อมูล, APIs)
- มีประเด็นด้านคอมพลายแอนซ์ ความเป็นส่วนตัว หรือกฎหมาย
- อยากเลี่ยงความปวดหัวเรื่องดูแลและแก้ปัญหาระยะยาว
แต่ถ้าเป็นการดึงข้อมูลเร็ว ๆ ครั้งเดียว หรือทำลิสต์แบบง่าย ๆ เครื่องมืออย่าง อาจเอาอยู่
จะหาและจ้างนักพัฒนา Web Scraping และผู้เชี่ยวชาญฟรีแลนซ์ได้ที่ไหน
แหล่งหาคนมีเยอะมาก แต่ละแพลตฟอร์มก็มีจุดเด่นและจุดที่ต้องระวังต่างกัน
- : คนเยอะสุด ตั้งแต่มือใหม่ถึงมือโปร เลือกได้ทั้งรายชั่วโมงหรือเหมาจ่าย และใช้ milestone เพื่อลดความเสี่ยง
- : เหมาะกับงานที่ต้องคุมงบและมีผลลัพธ์ชัด ใช้ milestone payment เพื่อให้เห็นความคืบหน้า
- : สายพรีเมียม คัดกรองมาแล้ว เหมาะถ้าคุณอยากเอาท์ซอร์สขั้นตอนคัดคนและยอมจ่ายแพงขึ้น
- Fiverr: เหมาะกับงานเล็ก ๆ ที่นิยามชัด (“กิ๊ก”) แต่ถ้างานซับซ้อนหรือยาว ๆ ต้องระวัง
ทิปในการคัดกรองผู้สมัคร:
- มองหาโปรไฟล์ที่มีประสบการณ์ Web Scraping โดยตรง (ไม่ใช่แค่ “Python developer”)
- ดูประสบการณ์ในอุตสาหกรรมที่เกี่ยวข้อง (เช่น อีคอมเมิร์ซ อสังหา ลีด B2B)
- ขอพอร์ต ตัวอย่างงาน หรือโค้ดสั้น ๆ
- อ่านรีวิวและเรตติ้งอย่างละเอียด
ทิปการคัดกรองและสัมภาษณ์
อย่าเชื่อแค่คำพูด นี่คือวิธีที่ผมชอบใช้คัดคน:
คำถามสำคัญที่ควรถาม:
- เล่าโปรเจกต์ Web Scraping ล่าสุดที่คุณส่งมอบให้ฟังได้ไหม? เจอความท้าทายอะไรบ้าง?
- ถ้าเว็บใช้ JavaScript หนัก ๆ หรือมีระบบกันบอท คุณรับมืออย่างไร?
- คุณมีขั้นตอนอย่างไรในการทำให้ข้อมูลมีคุณภาพและเชื่อถือได้?
- คุณทำเอกสารงานอย่างไรเพื่อส่งต่อหรือดูแลต่อในอนาคต?
- ก่อนเริ่มโปรเจกต์ใหม่ คุณมีเช็กลิสต์ด้านคอมพลายแอนซ์อะไรบ้าง?
แบบทดสอบเชิงปฏิบัติ:
- ให้เว็บตัวอย่างที่มีหน้า list + หน้า detail แล้วขอไฟล์ CSV ที่มีข้อมูล enriched
- ขอ “สัญญาข้อมูล” แบบสั้น ๆ (นิยามฟิลด์ ความจำเป็น ตารางรีเฟรช) ก่อนเริ่มเขียนโค้ด
- ขอเดโมสั้น ๆ ในการดึงตารางที่เรนเดอร์ด้วย JavaScript
Thunderbit ช่วยลดการพึ่งพานักพัฒนา Web Scraping ได้อย่างไร
มีความจริงข้อหนึ่ง: ผู้ใช้ฝั่งธุรกิจส่วนใหญ่ไม่จำเป็นต้องมีสแครปเปอร์เขียนโค้ดเฉพาะทุกโปรเจกต์ เครื่องมืออย่าง ทำให้ทีมที่ไม่ใช่สายเทคทำงานได้ง่ายขึ้นแบบเห็นได้ชัด
Thunderbit คือ ที่ช่วยดึงข้อมูลแบบมีโครงสร้างจากแทบทุกเว็บไซต์ได้ในไม่กี่คลิก แค่บอกว่าต้องการข้อมูลอะไร กด “AI Suggest Fields” แล้ว AI ของ Thunderbit จะจัดการให้ ที่สำคัญยังรองรับการดึงข้อมูลจาก subpage, pagination และส่งออกไป Excel, Google Sheets, Airtable หรือ Notion ได้ทันที
แล้วมันเกี่ยวอะไรกับการจ้างคน? เพราะ Thunderbit ช่วยลดจำนวนงานที่ “จำเป็นต้องใช้” นักพัฒนา สำหรับทีมขาย อีคอมเมิร์ซ และทีมรีเสิร์ช หลายครั้งการใช้ Thunderbit เพื่อดึงข้อมูลประจำ ๆ ทำลิสต์ลีด หรือมอนิเตอร์ราคา จะไวกว่าและคุ้มกว่ามาก เก็บงานวิศวกรรมหนัก ๆ ไว้ให้เคสที่ซับซ้อนจริง ๆ
Thunderbit vs วิธี Web Scraping แบบดั้งเดิม
ลองเทียบเวิร์กโฟลว์ของ Thunderbit กับการจ้าง ผู้เชี่ยวชาญ web scraping ฟรีแลนซ์:
| ปัจจัย | Thunderbit | ผู้เชี่ยวชาญฟรีแลนซ์ |
|---|---|---|
| เวลาเริ่มต้น | ไม่กี่นาที (ไม่ต้องเขียนโค้ด) | หลายวันถึงหลายสัปดาห์ |
| ค่าใช้จ่าย | มีฟรี และแพ็กเกจ $15–$249/เดือน (Thunderbit Pricing) | $500–$5,000+ ต่อโปรเจกต์ |
| การดูแล | AI ปรับตามการเปลี่ยนแปลงของเว็บ | ต้องอัปเดตด้วยมือ |
| การส่งออก | Excel, Sheets, Airtable, Notion, CSV, JSON | แตกต่างกันไป (มักเป็น CSV/JSON) |
| Subpage/Pagination | มีในตัว 2 คลิก | ต้องเขียนโค้ดเฉพาะ |
| เหมาะกับ | งานเร็ว ทำบ่อย งานเบา | งานซับซ้อน ปริมาณมาก อินทิเกรตเฉพาะทาง |
เมื่อไหร่ยังควรจ้างนักพัฒนา? ถ้าเป็น data pipeline ที่สำคัญต่อธุรกิจ เป้าหมาย “ยาก” (เช่น ต้องล็อกอินหรือกันบอทหนัก) หรือจำเป็นต้องทำอินทิเกรชันและมอนิเตอร์แบบเฉพาะทาง
บริหารโปรเจกต์ Web Scraping แบบเอาท์ซอร์สให้สำเร็จ
จ้างคนได้แล้วเป็นแค่จุดเริ่ม การบริหารให้ดีต่างหากที่ทำให้งานเดิน (และไม่ต้องเจอสถานการณ์ “ข้อมูลอยู่ไหน?”)
แนวทางที่แนะนำ:
- กำหนด “สัญญาข้อมูล” ให้ชัดตั้งแต่ต้น: ระบุฟิลด์ที่ต้องมี ชนิดข้อมูล ความถี่การรีเฟรช และเกณฑ์รับงาน ()
- ใช้ milestone และ escrow: แบ่งงานเป็นช่วง ๆ (ชุดข้อมูลตัวอย่าง, รันเต็ม, ตั้งรันตามเวลา, มอนิเตอร์) แล้วจ่ายเมื่อส่งมอบแต่ละช่วง ()
- ตั้งด่าน QA: ตรวจให้แน่ใจว่าข้อมูลลบซ้ำแล้ว ผ่านการตรวจสอบ และพร้อมใช้กับเคสธุรกิจ
- วางแผนการดูแล: สแครปเปอร์พังได้เสมอ ถ้าข้อมูลสำคัญ ควรตกลงเรตดูแลหรือแผนบำรุงรักษา
- ทำเอกสารให้ครบ: ขอ README, runbook และรายการจุดพังที่พบบ่อย เอกสารดีช่วยลดค่าใช้จ่ายแฝงในอนาคต
ทิปการสื่อสารและทำงานร่วมกัน
- เช็กอินสม่ำเสมอ: อัปเดตรายสัปดาห์หรือเดโมช่วยให้ทุกคนไปทางเดียวกัน
- ใช้เครื่องมือจัดการงานร่วมกัน: เช่น Trello, Asana หรือ Google Docs เพื่อเก็บความคืบหน้าและฟีดแบ็ก
- กำหนดทางแก้ปัญหา/เอสคาเลชัน: ตกลงล่วงหน้าว่าถ้าติดบล็อกจะทำอย่างไร
- สนับสนุนให้ถาม: ฟรีแลนซ์ที่ดีจะถามให้เคลียร์ตั้งแต่ต้นและถามต่อเนื่อง
ประเด็นกฎหมาย จริยธรรม และคอมพลายแอนซ์เมื่อจ้างนักพัฒนา Web Scraping
Web scraping ไม่ได้ “เสรี” เหมือนเมื่อก่อนแล้ว มีทั้งข้อกฎหมายและจริยธรรม โดยเฉพาะเรื่องข้อมูลส่วนบุคคล เงื่อนไขการใช้งาน และการหลบเลี่ยงระบบกันบอท
ประเด็นสำคัญ:
- ข้อมูลสาธารณะไม่ได้แปลว่าเก็บได้ตามใจ: แม้ข้อมูลจะเปิดให้เห็น แต่ก็ยังมีความเสี่ยงทางกฎหมาย โดยเฉพาะถ้าคุณข้ามกำแพงเทคนิคหรือฝ่าฝืนเงื่อนไขการใช้งาน ()
- กฎหมายความเป็นส่วนตัวสำคัญมาก: GDPR, CCPA และกฎอื่น ๆ บังคับให้คุณต้องมีเหตุผลในการเก็บข้อมูล ลดผลกระทบ และเคารพการ opt-out ()
- เช็กลิสต์คอมพลายแอนซ์: จำกัดการสแครปเฉพาะเว็บ/ชนิดข้อมูลที่อนุมัติ หลีกเลี่ยงข้อมูลอ่อนไหว/ส่วนบุคคลหากไม่ได้รับอนุญาต ทำเอกสารกระบวนการ และจัดการ credential อย่างปลอดภัย ()
- ความโปร่งใส: แจ้งข้อกำหนดคอมพลายแอนซ์ให้ชัด และใส่ไว้ในขอบเขตงาน (SOW)
เครื่องมืออย่าง Thunderbit ช่วยได้ในแง่การโฟกัสข้อมูลสาธารณะที่เกี่ยวกับธุรกิจ และทำให้บันทึกว่าเก็บอะไร/ทำไมได้ง่ายขึ้น
คู่มือทีละขั้น: วิธีจ้างนักพัฒนา Web Scraping
พร้อมเริ่มแล้วใช่ไหม? นี่คือกระบวนการที่ทำตามได้จริง:
- กำหนดความต้องการ: ต้องการข้อมูลอะไร จากเว็บไหน บ่อยแค่ไหน และต้องการรูปแบบไหน?
- ทำ “สัญญาข้อมูล”: ระบุฟิลด์ ชนิดข้อมูล ความถี่รีเฟรช และเกณฑ์รับงาน
- เลือกแพลตฟอร์มจ้างงาน: Upwork, Freelancer, Toptal หรือ Fiverr เลือกตามงบ เวลา และระดับการคัดกรองที่ต้องการ
- โพสต์โปรเจกต์: ระบุ deliverables ไทม์ไลน์ และข้อกำหนดคอมพลายแอนซ์ให้ชัด
- คัดกรองผู้สมัคร: ใช้เช็กลิสต์และคำถามด้านบน ขอผลงานตัวอย่างหรือทำเทสต์แบบจ่ายเงินเล็กน้อย
- ตกลง milestone: แบ่งงานเป็นช่วง ๆ พร้อมผลลัพธ์ที่ชัดเจน
- บริหารโปรเจกต์: เช็กอินสม่ำเสมอ ตั้งด่าน QA และใช้เครื่องมือร่วมกันติดตามงาน
- วางแผนการดูแล: ตกลงวิธีจัดการอัปเดต แก้บั๊ก และการเปลี่ยนแปลง
- ทำเอกสารให้ครบ: ขอ README, runbook และขั้นตอนส่งมอบที่ชัดเจน
และอย่าลืม: งานประจำจำนวนมากอาจไม่ต้องจ้างเลย—ลอง ก่อนเพื่อดูว่าครอบคลุมความต้องการของคุณหรือไม่
สรุปและประเด็นสำคัญ
การ จ้างนักพัฒนา web scraping ไม่ได้เป็นเรื่องของบริษัทเทคยักษ์ใหญ่อีกต่อไป แต่กลายเป็นสิ่งจำเป็นสำหรับทีมที่อยากเปลี่ยนข้อมูลบนเว็บให้เป็นมูลค่าทางธุรกิจ และเมื่ออุตสาหกรรม Web Scraping และการดึงข้อมูลเติบโตมากกว่า ความเสี่ยง (และความซับซ้อน) ก็สูงขึ้นตามไปด้วย
สิ่งที่ควรโฟกัสที่สุด:
- มองหาคนที่โค้ดแน่น มีประสบการณ์สแครปจริง และคิดแบบ data engineering
- ใช้แพลตฟอร์มอย่าง Upwork, Freelancer และ Toptal เพื่อหาและคัดคน แต่ต้องบริหารด้วยสัญญาชัด milestone และด่าน QA
- งานประจำที่ต้องการความเร็ว เครื่องมืออย่าง ช่วยประหยัดเวลา เงิน และลดปวดหัวได้มาก—ไม่ต้องเขียนโค้ด
- ให้ความสำคัญกับคอมพลายแอนซ์ ความเป็นส่วนตัว และเอกสารเสมอ
- ผลลัพธ์ที่ดีที่สุดมาจากความคาดหวังที่ชัด การสื่อสารสม่ำเสมอ และการปรับตัวตามเว็บที่เปลี่ยน (ซึ่งเกิดขึ้นแน่นอน)
ก่อนจ้าง ลองถามตัวเองว่า: นี่เป็นงานครั้งเดียว งานที่ต้องทำซ้ำ หรือเป็น pipeline ที่สำคัญต่อธุรกิจ? บางทีทางเลือกที่ฉลาดที่สุดคือทำให้ทีมทำเองได้ด้วยเครื่องมือที่ใช้ง่าย และเก็บงานหนักไว้สำหรับตอนที่จำเป็นจริง ๆ
อยากรู้ไหมว่าคุณทำได้แค่ไหนโดยไม่ต้องจ้างนักพัฒนา? ลอง แล้วทดลองด้วยตัวเอง และถ้าอยากได้ทิปเพิ่มเกี่ยวกับ web scraping, data automation หรือการสร้าง data stack สมัยใหม่ แวะอ่าน ได้เลย
คำถามที่พบบ่อย (FAQs)
1. ผู้เชี่ยวชาญ web scraping ฟรีแลนซ์ต่างจากผู้เชี่ยวชาญการดึงข้อมูลจากเว็บแบบ in-house อย่างไร?
ฟรีแลนซ์มักเหมาะกับงานเฉพาะกิจ ระยะสั้น หรือเป้าหมายเฉพาะทาง ส่วน in-house จะดูแล data pipeline และการเชื่อมต่อระบบที่ต้องทำต่อเนื่องและสำคัญต่อธุรกิจ
2. จ้างนักพัฒนา web scraping ราคาเท่าไหร่?
ฟรีแลนซ์มักคิด $20–$40 ต่อชั่วโมง หรือ $500–$5,000+ ต่อโปรเจกต์ ขึ้นกับความซับซ้อน ส่วนตำแหน่งประจำอาจอยู่ที่ $100k+ ต่อปี ขณะที่เครื่องมืออย่าง Thunderbit มีแพ็กเกจเริ่มต้นที่ $15/เดือน
3. ควรมองหาทักษะอะไรเมื่อจ้างนักพัฒนา web scraping?
ควรมองหาทักษะการเขียนโปรแกรมที่แข็งแรง (Python, JS) ประสบการณ์กับเว็บไดนามิกและกลยุทธ์กันบอท ความรู้ด้าน data engineering และความคุ้นเคยทั้งเครื่องมือแบบเขียนโค้ดและ no-code อย่าง Thunderbit
4. เมื่อไหร่ควรใช้เครื่องมืออย่าง Thunderbit แทนการจ้างนักพัฒนา?
Thunderbit เหมาะกับงานดึงข้อมูลที่ต้องทำเร็ว ทำบ่อย หรือทำครั้งเดียว เช่น สร้างลีด มอนิเตอร์ราคา โดยเฉพาะเมื่ออยากได้ไฟล์ส่งออกแบบมีโครงสร้างและตั้งค่าน้อย ควรจ้างนักพัฒนาสำหรับงานซับซ้อน สำคัญต่อธุรกิจ หรือปรับแต่งสูง
5. มีประเด็นกฎหมายหรือคอมพลายแอนซ์อะไรที่ควรคำนึงเมื่อจ้างงาน Web Scraping?
ควรเคารพเงื่อนไขการใช้งานของเว็บไซต์ ปฏิบัติตามกฎหมายความเป็นส่วนตัว (เช่น GDPR/CCPA) และหลีกเลี่ยงการเก็บข้อมูลอ่อนไหวหรือข้อมูลส่วนบุคคลหากไม่ได้รับอนุญาต ควรทำเอกสารกระบวนการและให้ผู้พัฒนาทำตามแนวปฏิบัติที่ดีด้านคอมพลายแอนซ์
พร้อมทำให้โปรเจกต์ข้อมูลครั้งต่อไปสำเร็จแล้วหรือยัง? เริ่มจากแผนที่ถูก คนที่ใช่ และเครื่องมือที่เหมาะ แล้วคุณจะเห็นว่าคุณทำได้มากขึ้นแค่ไหน
เรียนรู้เพิ่มเติม