กำลังมี “การปฏิวัติแบบเงียบๆ” เกิดขึ้นในออฟฟิศทั่วโลก และมันไม่เกี่ยวกับโต๊ะปิงปองหรือคอมบูชากดได้ไม่อั้นเลย แต่มันคือการเติบโตของ “easy web extract” — ความสามารถที่ทำให้ใครๆ (ไม่ใช่แค่นักเขียนโค้ด) ดึงข้อมูลจากเว็บแบบง่าย ได้ภายในไม่กี่นาที ไม่ใช่หลายวัน ถ้าคุณเคยนั่งจ้องหน้าเว็บแล้วคิดว่า “อยากก๊อบชื่อ ราคา หรืออีเมลทั้งหมดลงสเปรดชีตทีเดียวได้ไหม” บอกเลยว่าไม่ได้คิดอยู่คนเดียวแน่นอน จริงๆ แล้วผมคุยกับทั้งเซลส์ มาร์เก็ตติ้ง และทีมโอเปอเรชัน หลายคนพูดเหมือนกันเป๊ะว่า “ทำไมเรื่องนี้ยังยากอยู่เลย?”
ความจริงคือ ความต้องการ “วิธี web scraping แบบเรียบง่าย” กำลังพุ่งแรงมาก ตามรายงานของ ระบุว่า 65% ขององค์กรใช้ generative AI อย่างน้อย 1 ฟังก์ชันในงานธุรกิจแล้ว และการดึงข้อมูลจากเว็บกำลังกลายเป็นหนึ่งในยูสเคสที่คนต้องการมากที่สุด ตลาด web scraping ถูกคาดการณ์ว่าจะแตะ และผู้ใช้สายธุรกิจ—โดยเฉพาะคนที่ไม่ได้มีพื้นฐานเทคนิค—กำลังเป็นแรงขับเคลื่อนหลักที่มองหาเครื่องมือซึ่งทำให้การดึงข้อมูล “ง่ายเหมือนคัดลอก-วาง” แต่ “easy web extract” จริงๆ หมายถึงอะไร และคุณจะใช้มันเพื่อลดความยุ่งยากในงานได้อย่างไร? มาดูกันแบบเป็นขั้นเป็นตอน
Easy Web Extract สำหรับผู้ใช้ที่ไม่ใช่สายเทคนิค: ไม่ต้องเขียนโค้ด ไม่ต้องปวดหัว
เริ่มจากพื้นฐานก่อน: “easy web extract” คืออะไร? แก่นของมันคือการเปลี่ยนเว็บที่ทั้งรกและเปลี่ยนตลอดเวลา ให้กลายเป็นตารางข้อมูลที่เป็นระเบียบ—โดยไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียว สำหรับผู้ใช้ธุรกิจที่ไม่ใช่สายเทคนิค นี่คือการเปลี่ยนเกมแบบชัดๆ ไม่ต้องไปง้อ IT ไม่ต้องมานั่งงัดกับสคริปต์ Python และไม่ต้องยอมแพ้ทุกครั้งที่เว็บเปลี่ยนเลย์เอาต์ข้ามคืน
ทำไมเรื่องนี้ถึงสำคัญมากในตอนนี้? เพราะเว็บ “ไดนามิก” กว่าเดิมเยอะมาก เว็บไซต์จำนวนมากใช้ infinite scroll, ป๊อปอัป และ JavaScript ซับซ้อนที่ทำให้สแครปเปอร์แบบเดิมพังได้ง่าย ในขณะเดียวกัน ทีมธุรกิจก็ถูกกดดันให้ส่งอินไซต์ให้เร็วกว่าเดิมแบบสุดๆ ในอุตสาหกรรม 98% ขององค์กรบอกว่าข้อมูลสาธารณะบนเว็บสำคัญหรือสำคัญมากต่อการดำเนินงาน และมากกว่าครึ่งใช้งานทุกวัน
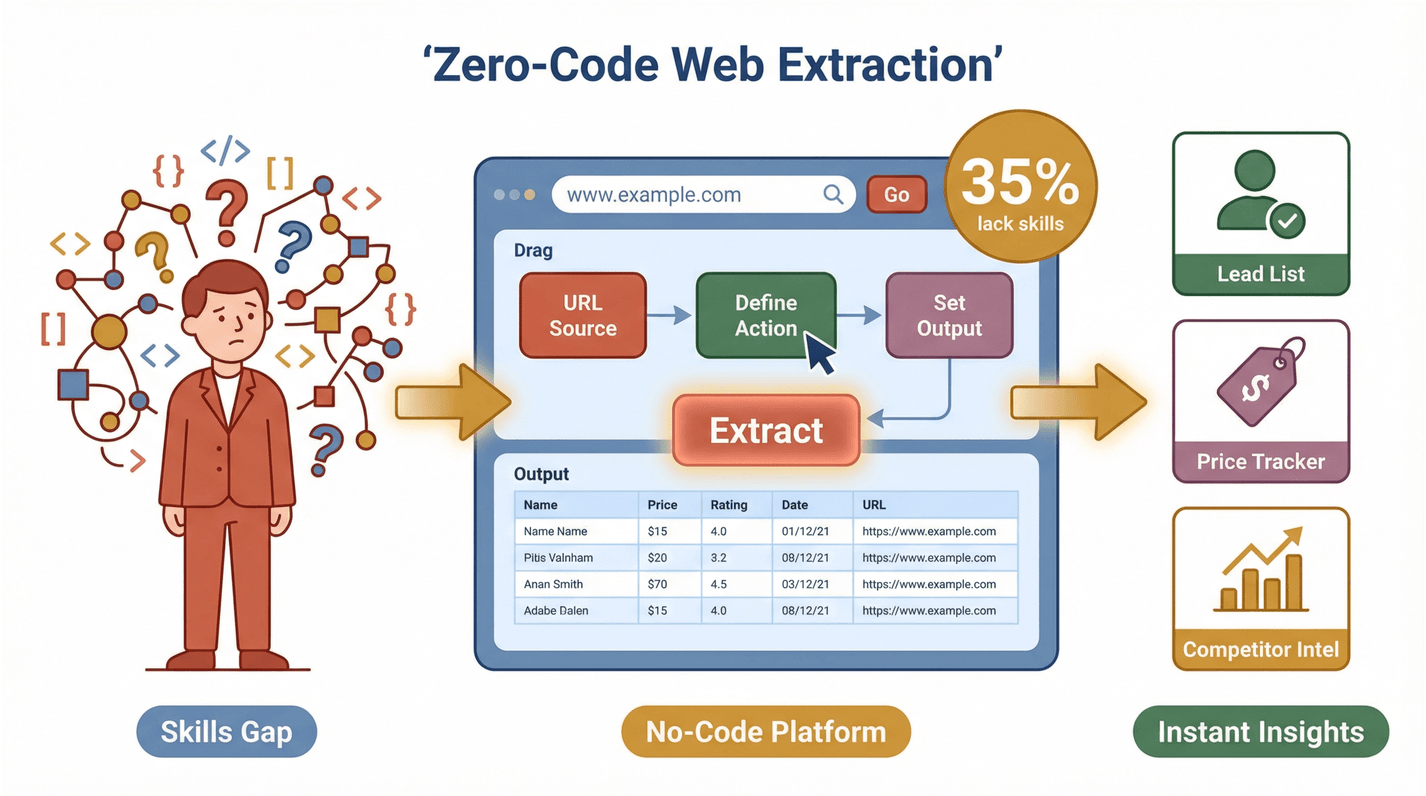
แต่ประเด็นคือ ทีมเหล่านี้ส่วนใหญ่ไม่ใช่ทีมเทคนิค ผลสำรวจล่าสุดพบว่า 35% ขององค์กรขาดทักษะที่เหมาะสมในการดึงข้อมูลจากเว็บ และ 33% ไม่มีเครื่องมือที่เหมาะสม นี่จึงเป็นโอกาสมหาศาลของโซลูชันแบบไม่ต้องเขียนโค้ด เมื่อใครๆ ก็สามารถดึงและใช้ข้อมูลจากเว็บได้ คุณจะปลดล็อกประสิทธิภาพการทำงานอีกระดับ—ไม่ว่าจะเป็นการทำลิสต์ลีด ติดตามคู่แข่ง หรือมอนิเตอร์ราคา
กระแส No-Code/Low-Code: ทำไมถึงสำคัญ
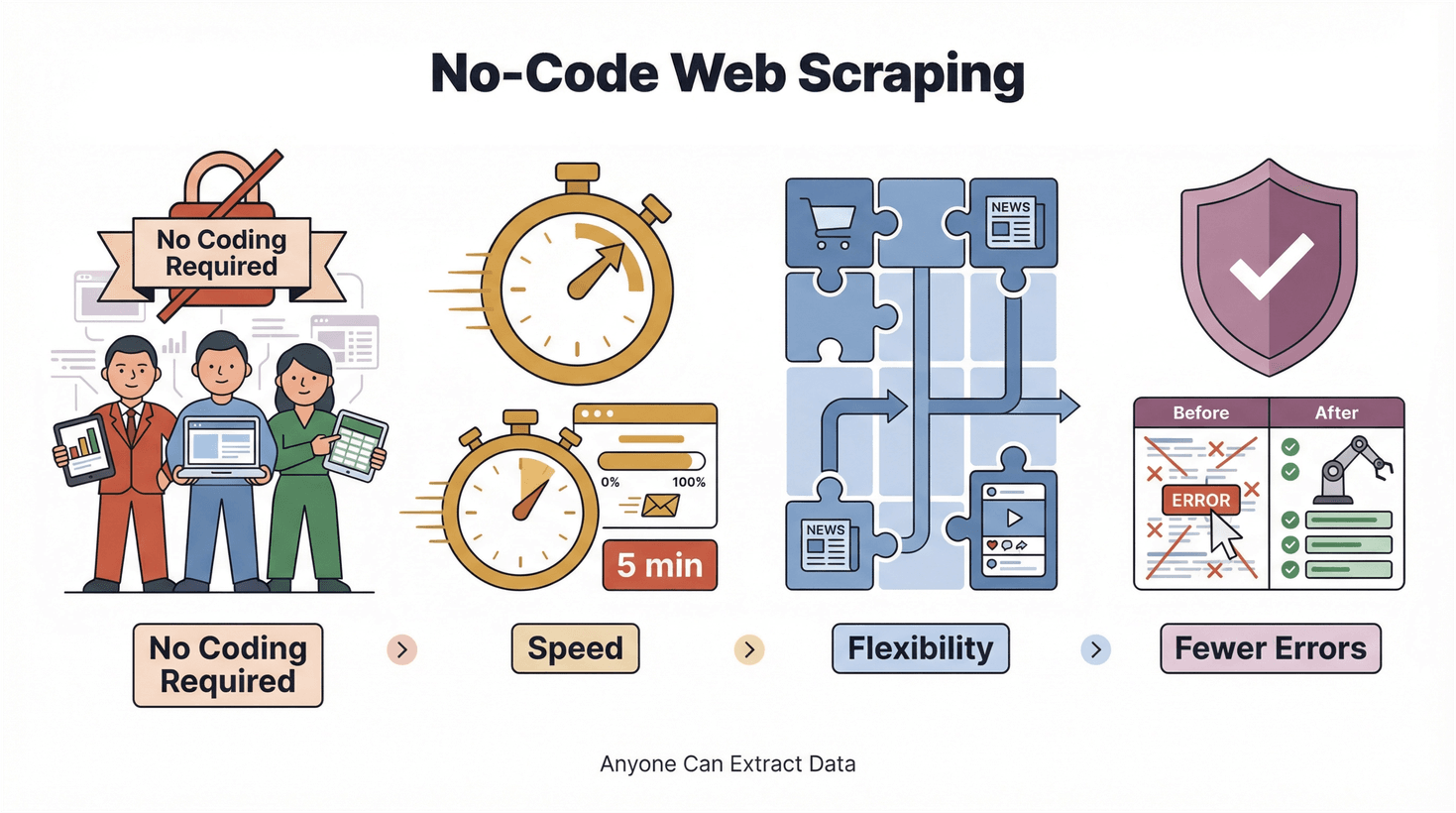
การเติบโตของเครื่องมือ no-code และ low-code คือการทำให้เทคโนโลยีเข้าถึงได้สำหรับทุกคน ไม่ใช่แค่คำฮิตในซิลิคอนวัลเลย์ แต่เป็นการเปลี่ยนวิธีทำงานจริงๆ สำหรับโลกของ web scraping มันหมายถึง:
- ไม่ต้องเขียนโค้ด: ใครก็สกัดข้อมูลได้ ไม่จำกัดแค่วิศวกร
- เร็ว: ได้ผลลัพธ์ในไม่กี่นาที ไม่ใช่หลายวัน
- ยืดหยุ่น: ปรับตามเว็บใหม่และความต้องการข้อมูลได้ทันที
- ลดความผิดพลาด: ทำอัตโนมัติช่วยลดข้อผิดพลาดจากการคัดลอก-วาง
ที่สำคัญคือ คุณไม่จำเป็นต้องเป็นสายเทคขั้นเทพถึงจะเริ่มได้
ทำไมเครื่องมือ Web Scraping แบบดั้งเดิมถึงน่าหงุดหงิด
พูดกันตรงๆ: เครื่องมือ web scraping แบบเดิมหลายตัวเหมือนถูกออกแบบมาเพื่อ “นักพัฒนา” ไม่ใช่ผู้ใช้ธุรกิจ ผมเห็นกับตา—ทีมตื่นเต้นกับโปรเจกต์ใหม่ แต่พอเครื่องมือถามหา CSS selector, XPath หรือ regular expression ก็เริ่มตาลอย แล้วจบด้วยอีเมล “ไว้ไตรมาสหน้า”
สิ่งที่มักพังมีประมาณนี้:
- ต้องเขียนโค้ด: เครื่องมือรุ่นเก่ามักให้เขียนสคริปต์หรือคอนฟิกเทมเพลตที่ซับซ้อน
- ตั้งค่ายุ่งยาก: ต้องแมปฟิลด์เอง จัดการขั้นตอนล็อกอิน และตั้ง proxy กันโดนบล็อก
- ตรรกะเปราะบาง: เว็บเปลี่ยนเลย์เอาต์นิดเดียว สแครปเปอร์ก็พัง แล้วคุณต้องดีบักแทนที่จะทำงานจริง
- ภาระดูแลรักษา: เว็บอัปเดตที ก็ต้องเริ่มใหม่แทบทั้งหมด
ไม่น่าแปลกที่ตาม ความท้าทายทางเทคนิคอันดับต้นๆ ของ web scraping คือ การบล็อก/แบน IP (56%), คอนเทนต์แบบไดนามิก (55%), และ CAPTCHA (52%) แม้แต่ทีมที่เก่งก็ยังตามให้ทันยาก
ในขณะที่ผู้ใช้ธุรกิจต้องการแค่วิธีที่ง่ายและเชื่อถือได้ในการเอาข้อมูลลงสเปรดชีตหรือ CRM นี่แหละคือจุดที่ easy web extract และวิธี web scraping แบบเรียบง่ายเข้ามาช่วย
Thunderbit ทำให้ Easy Web Extract เป็นจริงได้อย่างไร
ตรงนี้แหละที่ผมตื่นเต้น—เพราะนี่คือปัญหาที่เราตั้งใจแก้ตั้งแต่แรกที่ เป้าหมายของเราคือทำให้ web scraping ง่ายจนใครๆ ก็ทำได้ ไม่ว่าคุณจะมีพื้นฐานเทคนิคหรือไม่
Thunderbit คือ ที่เปลี่ยนการดึงข้อมูลจากเว็บให้เหลือแค่ “สองคลิก” วิธีทำงานเป็นแบบนี้:
- บอกสิ่งที่ต้องการ: ใช้ภาษาธรรมดาอธิบายว่าต้องการข้อมูลอะไร เช่น “ดึงชื่อสินค้าและราคาทั้งหมดจากหน้านี้”
- กด “AI Suggest Fields”: AI ของ Thunderbit จะอ่านหน้าเว็บและแนะนำคอลัมน์ที่เหมาะที่สุด เช่น “Name,” “Price,” “Email,” หรือ “Image”
- กด “Scrape”: Thunderbit จัดการที่เหลือให้ทั้งหมด ทั้งการไล่หน้า (pagination) การเข้า subpage และแม้แต่คอนเทนต์หลังล็อกอิน (ถ้าจำเป็น)
จบเลย ไม่ต้องเขียนโค้ด ไม่ต้องทำเทมเพลต ไม่ต้องปวดหัวกับการตั้งค่า อินเทอร์เฟซถูกออกแบบมาเพื่อผู้ใช้ธุรกิจ—เซลส์ มาร์เก็ตติ้ง อีคอมเมิร์ซ อสังหา—ที่ต้องการผลลัพธ์แบบทันที
เวิร์กโฟลว์ที่ขับเคลื่อนด้วย AI ของ Thunderbit: ฉลาดขึ้น ไม่เหนื่อยขึ้น
ความพิเศษจริงๆ อยู่ที่ AI Thunderbit ไม่ได้ “เดา” ว่าคุณต้องการอะไร แต่มันอ่านหน้าเว็บ เข้าใจบริบท และจัดโครงสร้างข้อมูลให้อัตโนมัติ ถ้าคุณอยากปรับละเอียด ก็สามารถใส่คำสั่งเฉพาะให้แต่ละฟิลด์ได้ (เช่น “จัดหมวดหมู่คอลัมน์นี้” หรือ “แปลเป็นอังกฤษ”) แต่ผู้ใช้ส่วนใหญ่แค่คลิกแล้วไปต่อ
แนวทางแบบ AI-first นี้ช่วยให้:
- ผิดพลาดน้อยลง: AI ปรับตัวกับเลย์เอาต์ที่ต่างกันได้ จึงได้ผลลัพธ์สม่ำเสมอแม้เว็บเปลี่ยน
- ตั้งค่าเร็วขึ้น: ไม่ต้องสร้างเทมเพลตหรือเขียนสคริปต์
- ข้อมูลพร้อมใช้งาน: Thunderbit สามารถติดป้าย จัดหมวดหมู่ และเสริมข้อมูลระหว่างสแครปได้
ถ้าอยากลงลึก แนะนำดู หรือ และยังมีไกด์อีกมากบน เช่น และ
ฟีเจอร์เด่นของ Thunderbit สำหรับวิธี web scraping แบบเรียบง่าย
สิ่งที่ทำให้ Thunderbit ต่าง ไม่ใช่แค่ AI แต่คือเวิร์กโฟลว์ทั้งชุดที่ออกแบบมาเพื่อการใช้งานจริงของทีมธุรกิจ ฟีเจอร์ที่ผู้ใช้ชอบมีเช่น:
- จัดการ pagination อัตโนมัติ: รองรับเว็บหลายหน้าและ infinite scroll แบบไม่ต้องตั้งค่า
- สแครป subpage: ต้องการรายละเอียดเพิ่ม? Thunderbit เข้าไปเก็บข้อมูลจากแต่ละหน้ารายละเอียด (เช่น รายละเอียดสินค้า หรือโปรไฟล์ LinkedIn) แล้วเติมลงชุดข้อมูลให้อัตโนมัติ
- ส่งออกได้ทุกที่: ส่งตรงไป Excel, Google Sheets, Airtable, Notion หรือดาวน์โหลดเป็น CSV/JSON ไม่ต้องมาราธอนคัดลอก-วาง
- ใช้ได้กับหน้าที่ต้องล็อกอิน: สแครปเว็บที่ต้องเข้าสู่ระบบได้ เพราะ Thunderbit ทำงานในเบราว์เซอร์ เห็นเหมือนที่คุณเห็น
- ติดป้าย/จัดหมวดหมู่ด้วย AI: ใส่คำสั่งให้ช่วยจำแนก ติดแท็ก หรือแปลข้อมูลระหว่างดึงได้
- Scheduled scraping: ตั้งงานให้รันซ้ำเพื่ออัปเดตข้อมูลเสมอ เหมาะกับการติดตามราคา หรือเช็กลีด
และใช่—ทั้งหมดนี้อยู่ในเครื่องมือที่มีผู้ใช้มากกว่า ไว้วางใจ
Pagination อัตโนมัติและการดึงข้อมูลจาก Subpage
หนึ่งในเรื่องที่ปวดหัวที่สุดของ web scraping คือการจัดการลิสต์หลายหน้า หรือหน้ารายละเอียดที่ซ่อนอยู่หลายชั้น แต่กับ Thunderbit คุณไม่ต้องกังวล AI จะตรวจจับ pagination (ทั้งปุ่ม “Next” หรือ infinite scroll) และตามลิงก์ไป subpage ให้อัตโนมัติ นั่นหมายความว่าคุณดึงข้อมูลได้เป็นร้อยเป็นพันเรคคอร์ดในครั้งเดียว—ไม่ต้องคลิกเอง
ตัวอย่างเช่น ถ้าคุณสแครปรายการสินค้าบน Amazon, Thunderbit สามารถดึงสินค้าทุกหน้ามารวมกัน แล้วเข้าไปแต่ละหน้าสินค้าเพื่อดึงรีวิว เรตติ้ง หรือข้อมูลผู้ขายต่อได้ เหมือนมีผู้ช่วยที่ทำงานไม่เหนื่อยและไม่เบื่อ
ส่งออกหลายรูปแบบและเชื่อมต่อ CRM
ข้อมูลจะมีค่าก็ต่อเมื่อเอาไปใช้ได้จริง Thunderbit ให้คุณส่งออกผลลัพธ์ในรูปแบบที่ทีมต้องการ—Excel, Google Sheets, Airtable, Notion หรือ CSV/JSON และยังสามารถส่งเข้าระบบ CRM หรือเครื่องมือเวิร์กโฟลว์ได้โดยตรง เพื่อให้ทีมเซลส์และโอเปอเรชันมีข้อมูลล่าสุดเสมอ
การเชื่อมต่อแบบตรงนี้ช่วยประหยัดเวลามาก ไม่ต้องมานั่งล้างไฟล์ส่งออกที่เละ หรือจัดคอลัมน์ใหม่—AI ของ Thunderbit จัดการให้
ตัวอย่างการใช้งานจริงของ Easy Web Extract
แล้ว easy web extract ช่วยได้มากที่สุดในงานแบบไหน? นี่คือสถานการณ์จริงที่ผมเห็นจากผู้ใช้ Thunderbit:
ดึงลีดสำหรับทีมขาย
ทีมขายอยู่ได้ด้วยลิสต์ลีด Thunderbit ช่วยให้คุณสแครปข้อมูลติดต่อจาก LinkedIn, Google Maps หรือไดเรกทอรีธุรกิจได้ในไม่กี่นาที แค่เปิดหน้าเว็บ กด “AI Suggest Fields” แล้วให้ Thunderbit ดึงชื่อ อีเมล เบอร์โทร และรายละเอียดบริษัทลงสเปรดชีตที่พร้อมใช้งาน
ผู้จัดการทีมขายคนหนึ่งบอกผมว่า เมื่อก่อนต้องเสียเวลาหลายชั่วโมงต่อสัปดาห์กับการคัดลอก-วางลีด ตอนนี้ใช้ Thunderbit ทำลิสต์แบบเจาะกลุ่มได้เร็วขึ้นมาก และทีมได้โฟกัสกับการติดต่อ ไม่ใช่กรอกข้อมูล
อีคอมเมิร์ซและการมอนิเตอร์ตลาด
ทีมอีคอมเมิร์ซใช้ Thunderbit เพื่อติดตาม SKU ราคา และรีวิวของคู่แข่งบน Amazon, Shopify และแพลตฟอร์มอื่นๆ อยากมอนิเตอร์การเปลี่ยนราคา หรือดูการเปิดตัวสินค้าใหม่? ตั้ง scheduled scrape แล้วให้ข้อมูลใหม่ส่งเข้า Google Sheet ทุกเช้าได้เลย
ฟีเจอร์ subpage scraping มีประโยชน์มากในงานนี้—คุณดึงรายละเอียดสินค้า รูปภาพ และแม้แต่รีวิวลูกค้าได้แบบแทบไม่ต้องทำอะไร
เก็บข้อมูลอสังหาริมทรัพย์
สายอสังหาฯ ใช้ Thunderbit เพื่อรวบรวมประกาศขาย ราคา และข้อมูลเอเจนต์จากเว็บอย่าง Zillow หรือ Realtor.com AI จัดการทั้ง pagination และ subpage ทำให้คุณได้ภาพรวมตลาดที่ครบและอัปเดต เหมาะกับการวิเคราะห์หรือทำรายงานให้ลูกค้า
นักวิเคราะห์อสังหาฯ คนหนึ่งแชร์ว่า งานที่เคยกินเวลาทั้งบ่าย ตอนนี้เหลือแค่ไม่กี่คลิก นี่แหละพลังของวิธี web scraping แบบเรียบง่าย
เปรียบเทียบวิธี web scraping แบบเดิม vs แบบเรียบง่าย
สรุปให้เห็นภาพด้วยตารางเทียบแบบชัดๆ:
| ฟีเจอร์ | สแครปเปอร์แบบดั้งเดิม | Easy Web Extract (Thunderbit) |
|---|---|---|
| ต้องเขียนโค้ด | ใช่ (สคริปต์, selector) | ไม่ต้อง (AI + ภาษาธรรมชาติ) |
| เวลาในการตั้งค่า | สูง (เทมเพลต, คอนฟิก) | ต่ำ (2 คลิก) |
| การดูแลรักษา | บ่อย (พังเมื่อเว็บเปลี่ยน) | น้อยมาก (AI ปรับตัวได้) |
| จัดการ pagination | ต้องตั้งค่าเอง | อัตโนมัติ |
| ดึงข้อมูล subpage | ตรรกะซับซ้อน | 1 คลิก |
| รูปแบบการส่งออก | มักจำกัด | Excel, Sheets, Airtable, Notion, CSV, JSON |
| ใช้กับหน้าล็อกอิน | บางครั้ง (ต้องคอนฟิก) | ได้ (ทำงานในเบราว์เซอร์) |
| ติดป้าย/จัดหมวดหมู่ข้อมูล | ต้องทำหลังบ้านเอง | มี AI ในตัว |
| ตั้งเวลาสแครป/มอนิเตอร์ | บางครั้ง (ขั้นสูง) | ได้ (ตั้งค่าง่าย) |
ความต่างชัดเจนมาก ด้วย Thunderbit ใครๆ ก็สามารถดึง จัดระเบียบ และนำข้อมูลจากเว็บไปใช้ได้—ไม่ต้องมีทักษะเทคนิค
เทรนด์อนาคตของ Easy Web Extract และวิธี web scraping แบบเรียบง่าย
มองไปข้างหน้า อนาคตของ easy web extract สดใสมาก AI ฉลาดขึ้นเรื่อยๆ และความต้องการเครื่องมือแบบไม่ต้องเขียนโค้ดก็โตเร็ว ตาม 78% ขององค์กรใช้ AI อย่างน้อย 1 ฟังก์ชันแล้ว และระบบแบบ agentic—เครื่องมือ AI ที่ทำเวิร์กโฟลว์บนเว็บหลายขั้นตอนได้เอง—กำลังมาแรง
สำหรับผู้ใช้ธุรกิจ นี่แปลว่า “ทำได้มากขึ้น แต่ยุ่งยากน้อยลง” เมื่อ AI พัฒนาต่อ เราจะเห็น:
- ตรวจจับฟิลด์ได้ฉลาดขึ้น: เข้าใจข้อมูลที่ซับซ้อนและความสัมพันธ์ได้ดีขึ้น
- อินทิเกรชันดีขึ้น: เชื่อมต่อกับเครื่องมือธุรกิจและแพลตฟอร์มได้มากขึ้น
- เสถียรขึ้น: พังน้อยลง ผลลัพธ์สม่ำเสมอขึ้น แม้เว็บไดนามิกหรือมีการป้องกัน
- เข้าถึงง่ายขึ้น: การดึงข้อมูลจากเว็บจะกลายเป็นทักษะพื้นฐานของทุกคน ไม่ใช่เฉพาะสายเทค
และใช่ Thunderbit อยู่แถวหน้าของกระแสนี้
สรุป & ประเด็นสำคัญที่ควรจำ
เว็บคือฐานข้อมูลที่ใหญ่ที่สุดในโลก—แต่ก่อนหน้านี้มีแค่นักเขียนโค้ดที่เข้าถึงได้ง่าย ตอนนี้ทุกอย่างกำลังเปลี่ยนไปอย่างรวดเร็ว ด้วย easy web extract และวิธี web scraping แบบเรียบง่าย ใครๆ ก็เปลี่ยนเว็บไซต์ให้เป็นข้อมูลที่นำไปใช้ต่อได้ภายในไม่กี่นาที
สิ่งที่ผมได้เรียนรู้ (และอยากให้คุณได้กลับไปด้วย) คือ:
- การดึงข้อมูลจากเว็บแบบไม่ต้องเขียนโค้ดจะอยู่กับเราไปอีกนาน: เครื่องมืออย่าง Thunderbit ทำให้ทุกคนเก็บและใช้ข้อมูลจากเว็บได้ โดยไม่ต้องมีทักษะเทคนิค
- AI คือหัวใจสำคัญ: เมื่อ AI ช่วยเลือกฟิลด์ จัดการ pagination ดึง subpage และติดป้ายข้อมูล สแครปเปอร์แบบ AI จะประหยัดเวลาและลดความผิดพลาด
- ผลลัพธ์ทางธุรกิจจับต้องได้: ทีมขาย อีคอมเมิร์ซ และอสังหาฯ เห็นประสิทธิภาพดีขึ้น ข้อมูลสดขึ้น และตัดสินใจได้ดีขึ้นแล้ว
- อนาคตจะยิ่งง่ายกว่าเดิม: เมื่อ AI และ no-code พัฒนา การดึงข้อมูลจากเว็บจะกลายเป็นเรื่องปกติพอๆ กับการส่งอีเมล
ถ้าคุณเบื่อการคัดลอก-วางด้วยมือ หงุดหงิดกับสแครปเปอร์ที่พัง หรือแค่อยากรู้ว่าทำอะไรได้บ้าง ลอง ดู คุณสามารถ แล้วเริ่มดึงข้อมูลได้ฟรี—ไม่ต้องตั้งค่า ไม่ต้องเขียนโค้ด ไม่ต้องยุ่งยาก
และถ้าอยากศึกษาเพิ่ม เข้าไปที่ เพื่อดูไกด์ ทิปส์ และตัวอย่างใช้งานจริงเพิ่มเติม
คำถามที่พบบ่อย (FAQs)
1. “easy web extract” คืออะไร และเหมาะกับใคร?
easy web extract คือวิธี web scraping แบบไม่ต้องเขียนโค้ดที่ขับเคลื่อนด้วย AI ช่วยให้ใครๆ—โดยเฉพาะผู้ใช้ธุรกิจที่ไม่ใช่สายเทคนิค—ดึงข้อมูลแบบมีโครงสร้างจากเว็บไซต์ได้อย่างรวดเร็วและง่าย เหมาะกับทีมขาย มาร์เก็ตติ้ง อีคอมเมิร์ซ และโอเปอเรชันที่ต้องการข้อมูลพร้อมใช้งานโดยไม่ต้องปวดหัวเรื่องเทคนิค
2. Thunderbit ต่างจากเครื่องมือ web scraping แบบเดิมอย่างไร?
Thunderbit ใช้ AI ทำงานอัตโนมัติทั้งการเลือกฟิลด์ การไล่หน้า และการดึงข้อมูลจาก subpage ต่างจากสแครปเปอร์แบบเดิมที่ต้องเขียนโค้ดหรือทำเทมเพลตซับซ้อน Thunderbit ให้คุณบอกความต้องการด้วยภาษาธรรมดา แล้วดึงข้อมูลได้ด้วยแค่สองคลิก
3. Thunderbit รับมือเว็บไดนามิกหรือเว็บหลายหน้าได้ไหม?
ได้ Thunderbit ตรวจจับและจัดการ pagination (รวมถึง infinite scroll) อัตโนมัติ และสามารถตามลิงก์ไป subpage เพื่อดึงข้อมูลเชิงลึกได้—โดยแทบไม่ต้องตั้งค่า
4. Thunderbit ส่งออกข้อมูลได้แบบไหนบ้าง?
Thunderbit ส่งออกข้อมูลไป Excel, Google Sheets, Airtable, Notion, CSV หรือ JSON ได้โดยตรง และยังเชื่อมต่อกับ CRM และเครื่องมือเวิร์กโฟลว์อื่นๆ เพื่อให้กระบวนการทำงานลื่นไหล
5. การใช้เครื่องมือ easy web extract อย่าง Thunderbit ปลอดภัยและถูกต้องตามจริยธรรมหรือไม่?
Thunderbit สนับสนุนการทำ web scraping อย่างรับผิดชอบและมีจริยธรรม ควรเคารพเงื่อนไขการใช้งานของเว็บไซต์ หลีกเลี่ยงการสแครปข้อมูลส่วนบุคคลโดยไม่ได้รับความยินยอม และใช้การจำกัดอัตราการดึงข้อมูลเพื่อไม่ให้รบกวนบริการ สำหรับแนวทางปฏิบัติที่ดีเพิ่มเติม ดูได้ที่
พร้อมปลดล็อกพลังของข้อมูลบนเว็บแล้วหรือยัง? ลอง Thunderbit วันนี้ แล้วคุณจะเห็นว่า easy web extract ช่วยเปลี่ยนเวิร์กโฟลว์ของคุณให้ทำงานง่ายขึ้นได้แค่ไหน
เรียนรู้เพิ่มเติม