
ลิงก์พัง หน้าโดดเดี่ยว (orphan pages) หรือหน้า “test” ที่หลุดมาตั้งแต่ปี 2019 แล้ว Google ดันเก็บเข้าดัชนีไว้เฉย ๆ… ถ้าคุณเป็นคนดูแลเว็บอยู่ น่าจะเข้าใจฟีลปวดหัวแบบนี้ดี
Crawler ที่ดีจะช่วยสแกนจับปัญหาเหล่านี้ได้แทบหมด แถมยังไล่สำรวจและทำแผนผังทั้งเว็บให้ด้วย เพื่อให้คุณแก้ได้ตรงจุด แต่หลายคนยังชอบงงระหว่าง “web crawler” กับ “web scraper” ซึ่งจริง ๆ แล้วคนละเรื่องกันเลย
ผมลองมาแล้ว 10 ตัวที่ใช้งานได้ฟรีกับเว็บไซต์จริง บางตัวเหมาะกับงานตรวจ SEO บางตัวเหมาะกับงานดึงข้อมูล นี่คือสิ่งที่เวิร์ก—และสิ่งที่ไม่เวิร์ก
Website Crawler คืออะไร? ทำความเข้าใจพื้นฐาน
ขอเคลียร์ให้ชัดก่อน: website crawler ไม่ใช่สิ่งเดียวกับ web scraper สองคำนี้โดนใช้ปนกันบ่อยมาก แต่แก่นต่างกันชัดเจน ลองนึกภาพว่า crawler คือ “คนทำแผนที่” ของเว็บไซต์—มันจะเดินสำรวจทุกซอกทุกมุม ไล่ตามทุกลิงก์ แล้วประกอบเป็นแผนผังของทุกหน้า หน้าที่หลักคือ การค้นพบ (discovery): หา URL, ทำความเข้าใจโครงสร้างเว็บ และช่วยให้เนื้อหาถูกจัดทำดัชนี นี่แหละคือสิ่งที่บอทของ Google ทำ และเป็นสิ่งที่เครื่องมือ SEO ใช้เพื่อตรวจสุขภาพเว็บไซต์ ().
ส่วน web scraper คือ “คนขุดข้อมูล” มันไม่ได้สนใจแผนที่ทั้งเว็บ แต่สนใจ “ของมีค่า” ที่ต้องการ เช่น ราคาสินค้า ชื่อบริษัท รีวิว อีเมล ฯลฯ Scraper จะดึงฟิลด์ข้อมูลเฉพาะจากหน้าที่ crawler ไปเจอมา ().
ยกตัวอย่างให้เห็นภาพ:
- Crawler: คนที่เดินครบทุกแถวในซูเปอร์มาร์เก็ตเพื่อทำรายการสินค้าทั้งหมด
- Scraper: คนที่เดินตรงไปชั้นกาแฟ แล้วจดราคากาแฟออร์แกนิกทุกยี่ห้อ
ทำไมต้องแยกให้ออก? เพราะถ้าคุณต้องการ “หาให้ครบทุกหน้าในเว็บ” (เช่น ทำ SEO audit) คุณต้องใช้ crawler แต่ถ้าคุณอยากดึง “ราคาสินค้าทั้งหมด” จากเว็บคู่แข่ง คุณต้องใช้ scraper—หรือดีที่สุดคือเครื่องมือที่ทำได้ทั้งสองอย่าง
ทำไมต้องใช้ Online Web Crawler? ประโยชน์สำคัญต่อธุรกิจ
แล้วทำไมต้องเสียเวลาคลานเว็บ? เพราะเว็บไม่ได้เล็กลงเลย ตรงกันข้าม—ตอนนี้ข้อมูลมันบวมขึ้นเรื่อย ๆ ถึงขั้นมีรายงานว่า เพื่อปรับปรุงเว็บไซต์ และบางเครื่องมือ SEO คลานได้ถึง
สิ่งที่ crawler ช่วยคุณได้ เช่น:
- SEO Audits: หา broken links, title หาย, เนื้อหาซ้ำ, orphan pages และอื่น ๆ ().
- ตรวจลิงก์ & QA: จับ 404 และ redirect loop ก่อนผู้ใช้จะเจอเอง ().
- สร้าง Sitemap: สร้าง XML sitemap อัตโนมัติสำหรับเสิร์ชเอนจินและการวางแผน ().
- ทำ Content Inventory: รวบรวมรายการทุกหน้า ลำดับชั้น และเมทาดาต้า
- Compliance & Accessibility: ตรวจทุกหน้าตาม WCAG, SEO และข้อกำหนดทางกฎหมาย ().
- ประสิทธิภาพ & ความปลอดภัย: ชี้หน้าช้า รูปใหญ่เกิน หรือประเด็นด้านความปลอดภัย ().
- ป้อนข้อมูลให้ AI/การวิเคราะห์: ส่งข้อมูลที่คลานได้เข้าเครื่องมือ analytics หรือ AI ().
ตารางสรุป use case กับบทบาทงานแบบเร็ว ๆ:
| Use Case | เหมาะกับใคร | ผลลัพธ์/ประโยชน์ |
|---|---|---|
| SEO & Site Auditing | ทีมการตลาด, SEO, เจ้าของธุรกิจขนาดเล็ก | เจอปัญหาเชิงเทคนิค ปรับโครงสร้าง เพิ่มอันดับค้นหา |
| Content Inventory & QA | ผู้จัดการคอนเทนต์, เว็บมาสเตอร์ | ตรวจ/ย้ายคอนเทนต์ จับลิงก์หรือรูปเสีย |
| Lead Generation (Scraping) | ทีมขาย, Biz Dev | ทำ prospecting อัตโนมัติ เติมลีดใหม่เข้า CRM |
| Competitive Intelligence | E-commerce, Product Managers | ติดตามราคาคู่แข่ง สินค้าใหม่ สต็อกเปลี่ยน |
| Sitemap & Structure Cloning | นักพัฒนา, DevOps, ที่ปรึกษา | โคลนโครงสร้างเว็บเพื่อรีดีไซน์หรือสำรอง |
| Content Aggregation | นักวิจัย, สื่อ, นักวิเคราะห์ | รวบรวมข้อมูลหลายเว็บเพื่อวิเคราะห์/ดูเทรนด์ |
| Market Research | นักวิเคราะห์, ทีมเทรน AI | เก็บชุดข้อมูลขนาดใหญ่เพื่อวิเคราะห์หรือเทรนโมเดล AI |
()
เราเลือกเครื่องมือ Website Crawler ฟรีที่ดีที่สุดอย่างไร
ผมใช้เวลาหลายคืน (พร้อมกาแฟมากกว่าที่อยากยอมรับ) ไล่ลองเครื่องมือ อ่านเอกสาร และรันทดสอบจริง เกณฑ์ที่ผมดูมีดังนี้:
- ความสามารถเชิงเทคนิค: รับมือเว็บสมัยใหม่ได้ไหม (JavaScript, ต้องล็อกอิน, คอนเทนต์ไดนามิก)
- ใช้งานง่ายแค่ไหน: คนไม่สายเทคใช้ได้หรือจำเป็นต้องพึ่ง command line
- ข้อจำกัดของแผนฟรี: ฟรีจริงหรือแค่ให้ลองชิม
- เข้าถึงแบบออนไลน์: เป็นคลาวด์ เดสก์ท็อป หรือไลบรารีโค้ด
- ฟีเจอร์เด่น: มีอะไรพิเศษไหม เช่น AI extraction, sitemap แบบภาพ, หรือ crawling แบบ event-driven
ผมลองทีละตัว ดูฟีดแบ็กผู้ใช้ และเทียบฟีเจอร์แบบข้างต่อข้าง ถ้าเครื่องมือไหนทำให้ผมอยากโยนโน้ตบุ๊กทิ้ง—ก็ไม่ติดลิสต์
ตารางเทียบเร็ว: 10 Website Crawler ฟรีที่น่าใช้
| เครื่องมือ & ประเภท | ฟีเจอร์หลัก | เหมาะกับงาน | ต้องมีทักษะเทคนิคแค่ไหน | รายละเอียดแผนฟรี |
|---|---|---|---|---|
| BrightData (Cloud/API) | คลานระดับองค์กร, proxy, เรนเดอร์ JS, แก้ CAPTCHA | เก็บข้อมูลปริมาณมาก | มีทักษะเทคนิคจะง่ายกว่า | ทดลองฟรี: 3 scrapers, 100 records ต่อ scraper (รวมราว 300 records) |
| Crawlbase (Cloud/API) | คลานผ่าน API, กันบอท, proxy, เรนเดอร์ JS | นักพัฒนาที่ต้องการโครงสร้างพื้นฐานฝั่ง backend | ต้องอินทิเกรต API | ฟรี: ~5,000 API calls 7 วัน จากนั้น 1,000/เดือน |
| ScraperAPI (Cloud/API) | หมุน proxy, เรนเดอร์ JS, async crawl, endpoint สำเร็จรูป | นักพัฒนา, มอนิเตอร์ราคา, ข้อมูล SEO | ตั้งค่าน้อย | ฟรี: 5,000 API calls 7 วัน จากนั้น 1,000/เดือน |
| Diffbot Crawlbot (Cloud) | คลาน+ดึงข้อมูลด้วย AI, knowledge graph, เรนเดอร์ JS | ข้อมูลแบบมีโครงสร้างระดับสเกล, AI/ML | ต้องอินทิเกรต API | ฟรี: 10,000 credits/เดือน (ประมาณ 10k หน้า) |
| Screaming Frog (Desktop) | SEO audit, วิเคราะห์ลิงก์/เมตา, sitemap, custom extraction | SEO audits, ผู้ดูแลเว็บ | แอปเดสก์ท็อป, GUI | ฟรี: 500 URLs ต่อการคลาน, เฉพาะฟีเจอร์หลัก |
| SiteOne Crawler (Desktop) | SEO, performance, accessibility, security, export offline, Markdown | นักพัฒนา, QA, ย้ายเว็บ, ทำเอกสาร | Desktop/CLI, GUI | ฟรีและโอเพ่นซอร์ส, รายงาน GUI 1,000 URLs (ปรับได้) |
| Crawljax (Java, OpenSrc) | คลานแบบ event-driven สำหรับเว็บ JS หนัก, export แบบ static | นักพัฒนา, QA สำหรับเว็บแอปไดนามิก | Java, CLI/ตั้งค่า | ฟรีและโอเพ่นซอร์ส, ไม่จำกัด |
| Apache Nutch (Java, OpenSrc) | คลานแบบกระจาย, ปลั๊กอิน, ต่อ Hadoop, ทำเสิร์ชเอง | ทำเสิร์ชเอนจินเอง, คลานสเกลใหญ่ | Java, command-line | ฟรีและโอเพ่นซอร์ส, มีแค่ต้นทุนโครงสร้างพื้นฐาน |
| YaCy (Java, OpenSrc) | คลาน+ค้นหาแบบ P2P, เน้นความเป็นส่วนตัว, ทำดัชนีเว็บ/อินทราเน็ต | เสิร์ชส่วนตัว, แนวกระจายศูนย์ | Java, UI ผ่านเบราว์เซอร์ | ฟรีและโอเพ่นซอร์ส, ไม่จำกัด |
| PowerMapper (Desktop/SaaS) | sitemap แบบภาพ, accessibility, QA, ความเข้ากันได้ของเบราว์เซอร์ | เอเจนซี, QA, ทำแผนผังแบบภาพ | GUI ใช้ง่าย | ทดลองฟรี: 30 วัน, 100 หน้า (เดสก์ท็อป) หรือ 10 หน้า (ออนไลน์) ต่อการสแกน |
BrightData: Crawler บนคลาวด์ระดับองค์กร

BrightData คือสาย “ของหนัก” ในโลก web crawling เป็นแพลตฟอร์มคลาวด์ที่มีเครือข่าย proxy ขนาดใหญ่ เรนเดอร์ JavaScript ได้ แก้ CAPTCHA ได้ และมี IDE สำหรับทำงานคลานแบบปรับแต่งเอง ถ้าคุณต้องเก็บข้อมูลระดับใหญ่ เช่น ติดตามราคาจากเว็บ e-commerce หลายร้อยเว็บ โครงสร้างพื้นฐานของ BrightData ถือว่าแน่นและอึดมาก ().
จุดแข็ง:
- รับมือเว็บที่กันบอทโหด ๆ ได้
- สเกลได้ระดับองค์กร
- มีเทมเพลตสำเร็จรูปสำหรับเว็บยอดนิยม
ข้อจำกัด:
- ไม่มีแผนฟรีถาวร (มีแค่ทดลอง: 3 scrapers, 100 records ต่อ scraper)
- อาจเกินจำเป็นสำหรับงาน audit ง่าย ๆ
- คนไม่สายเทคอาจต้องใช้เวลาทำความเข้าใจ
ถ้าคุณต้องคลานเว็บระดับสเกลใหญ่ BrightData ก็เหมือนเช่ารถ F1—แต่หลังทดลองขับ อย่าหวังว่าจะฟรีต่อไป ().
Crawlbase: Web Crawler ฟรีแบบ API สำหรับนักพัฒนา

Crawlbase (ชื่อเดิม ProxyCrawl) โฟกัสที่การคลานแบบโปรแกรมล้วน ๆ คุณเรียก API พร้อม URL แล้วระบบจะส่ง HTML กลับมา โดยจัดการ proxy, geotargeting และ CAPTCHA ให้เบื้องหลัง ().
จุดแข็ง:
- อัตราสำเร็จสูง (99%+)
- รองรับเว็บที่ใช้ JavaScript หนัก
- เหมาะกับการฝังเข้าแอปหรือเวิร์กโฟลว์ของคุณ
ข้อจำกัด:
- ต้องอินทิเกรต API/SDK
- แผนฟรี: ~5,000 API calls 7 วัน จากนั้น 1,000/เดือน
ถ้าคุณเป็นนักพัฒนาที่อยากคลาน (และอาจสแครป) แบบสเกลได้ โดยไม่ต้องดูแล proxy เอง Crawlbase เป็นตัวเลือกที่น่าไว้ใจ ().
ScraperAPI: ทำให้การคลานเว็บไดนามิกง่ายขึ้น

ScraperAPI คือแนว “ขอแค่ดึงหน้าให้ฉันก็พอ” คุณส่ง URL เข้าไป ระบบจัดการ proxy, headless browser และการกันบอท แล้วคืน HTML (หรือบางเว็บคืนข้อมูลแบบมีโครงสร้างให้) เหมาะมากกับหน้าไดนามิก และมีโควตาฟรีที่ค่อนข้างใจดี ().
จุดแข็ง:
- ง่ายมากสำหรับนักพัฒนา (เรียก API ครั้งเดียว)
- จัดการ CAPTCHA, IP ban, JavaScript ได้
- ฟรี: 5,000 API calls 7 วัน จากนั้น 1,000/เดือน
ข้อจำกัด:
- ไม่มีรายงานแบบภาพ
- ถ้าต้องการไล่ตามลิงก์ คุณต้องเขียนลอจิกการคลานเอง
ถ้าคุณอยากต่อ web crawling เข้ากับโค้ดภายในไม่กี่นาที ScraperAPI คือคำตอบที่ตรงและไว
Diffbot Crawlbot: ค้นหาโครงสร้างเว็บแบบอัตโนมัติ

Diffbot Crawlbot เริ่ม “ฉลาด” ขึ้นไปอีกขั้น เพราะไม่ได้แค่คลาน แต่ใช้ AI จัดประเภทหน้าและดึงข้อมูลแบบมีโครงสร้าง (บทความ สินค้า อีเวนต์ ฯลฯ) ออกมาเป็น JSON เหมือนมีเด็กฝึกงานหุ่นยนต์ที่อ่านแล้วเข้าใจจริง ๆ ().
จุดแข็ง:
- ดึงข้อมูลด้วย AI ไม่ใช่แค่คลาน
- รองรับ JavaScript และคอนเทนต์ไดนามิก
- ฟรี: 10,000 credits/เดือน (ประมาณ 10k หน้า)
ข้อจำกัด:
- เน้นนักพัฒนา (ต้องอินทิเกรต API)
- ไม่ใช่เครื่องมือ SEO แบบภาพ เน้นงานข้อมูลมากกว่า
ถ้าคุณต้องการข้อมูลแบบมีโครงสร้างในสเกลใหญ่ โดยเฉพาะเพื่อ AI/analytics Diffbot คือสายพลัง
Screaming Frog: SEO Crawler บนเดสก์ท็อปที่ใช้ฟรีได้

Screaming Frog คือคลาสสิกสำหรับทำ SEO audit บนเดสก์ท็อป เวอร์ชันฟรีคลานได้สูงสุด 500 URL ต่อครั้ง และให้ข้อมูลครบ: ลิงก์เสีย เมตาแท็ก เนื้อหาซ้ำ sitemap และอีกมาก ().
จุดแข็ง:
- เร็ว ละเอียด และเป็นที่ยอมรับในวงการ SEO
- ไม่ต้องเขียนโค้ด ใส่ URL แล้วรันได้เลย
- ฟรีถึง 500 URL ต่อการคลาน
ข้อจำกัด:
- ใช้ได้บนเดสก์ท็อปเท่านั้น (ไม่มีคลาวด์)
- ฟีเจอร์ขั้นสูง (เรนเดอร์ JS, ตั้งเวลารัน) ต้องซื้อไลเซนส์
ถ้าคุณจริงจังกับ SEO Screaming Frog ควรมีติดเครื่อง—แต่อย่าหวังให้มันคลานเว็บ 10,000 หน้าแบบฟรี ๆ
SiteOne Crawler: ส่งออกเว็บเป็นไฟล์สแตติกและทำเอกสาร

SiteOne Crawler เป็นเหมือนมีดพกสำหรับงานเทคนิค เป็นโอเพ่นซอร์ส ใช้ได้หลายแพลตฟอร์ม คลาน ตรวจ และยัง export เว็บไซต์เป็น Markdown เพื่อทำเอกสารหรือใช้งานออฟไลน์ได้ ().
จุดแข็ง:
- ครอบคลุม SEO, performance, accessibility, security
- ส่งออกเพื่อเก็บถาวรหรือย้ายเว็บได้
- ฟรีและโอเพ่นซอร์ส ไม่มีลิมิตการใช้งาน
ข้อจำกัด:
- เชิงเทคนิคกว่าบางเครื่องมือที่เป็น GUI ล้วน
- รายงานใน GUI จำกัด 1,000 URL โดยดีฟอลต์ (ปรับได้)
ถ้าคุณเป็นนักพัฒนา QA หรือที่ปรึกษาที่อยากได้อินไซต์ลึก ๆ (และชอบโอเพ่นซอร์ส) SiteOne คือของดีที่คนมักมองข้าม
Crawljax: Java Web Crawler โอเพ่นซอร์สสำหรับหน้าไดนามิก
Crawljax เป็นสายเฉพาะทาง: ออกแบบมาเพื่อคลานเว็บแอปยุคใหม่ที่ใช้ JavaScript หนัก ๆ โดยจำลองการโต้ตอบของผู้ใช้ (คลิก กรอกฟอร์ม ฯลฯ) เป็นการคลานแบบ event-driven และยังสามารถสร้างเวอร์ชันสแตติกจากเว็บไดนามิกได้ด้วย ().
จุดแข็ง:
- เหนือชั้นสำหรับ SPA และเว็บที่ใช้ AJAX หนัก
- โอเพ่นซอร์สและต่อยอดได้
- ไม่จำกัดการใช้งาน
ข้อจำกัด:
- ต้องใช้ Java และต้องเขียน/ตั้งค่าพอสมควร
- ไม่เหมาะกับผู้ใช้ทั่วไปที่ไม่สายเทค
ถ้าคุณต้องคลานเว็บ React หรือ Angular ให้เหมือนผู้ใช้จริง Crawljax คือเพื่อนที่ไว้ใจได้
Apache Nutch: Crawler แบบกระจายที่สเกลได้มาก

Apache Nutch คือรุ่นใหญ่ของ crawler โอเพ่นซอร์ส ออกแบบมาสำหรับงานคลานแบบกระจายขนาดมหาศาล เช่น ทำเสิร์ชเอนจินเองหรือทำดัชนีเป็นล้านหน้า ().
จุดแข็ง:
- สเกลได้ถึงระดับพันล้านหน้าด้วย Hadoop
- ปรับแต่งได้สูงและต่อยอดได้
- ฟรีและโอเพ่นซอร์ส
ข้อจำกัด:
- เรียนรู้ยาก (Java, command-line, config)
- ไม่เหมาะกับเว็บเล็กหรือผู้ใช้ทั่วไป
ถ้าคุณอยากคลานเว็บระดับใหญ่และไม่กลัว command line Nutch คือเครื่องมือที่ใช่
YaCy: Web Crawler และเสิร์ชเอนจินแบบ Peer-to-Peer
YaCy เป็นตัวเลือกที่ไม่เหมือนใคร เพราะเป็น crawler และเสิร์ชเอนจินแบบกระจายศูนย์ แต่ละอินสแตนซ์จะคลานและทำดัชนีเอง และคุณสามารถเข้าร่วมเครือข่าย P2P เพื่อแชร์ดัชนีกับคนอื่นได้ ().
จุดแข็ง:
- เน้นความเป็นส่วนตัว ไม่มีเซิร์ฟเวอร์กลาง
- เหมาะกับการทำเสิร์ชส่วนตัวหรือเสิร์ชในอินทราเน็ต
- ฟรีและโอเพ่นซอร์ส
ข้อจำกัด:
- คุณภาพผลลัพธ์ขึ้นกับความครอบคลุมของเครือข่าย
- ต้องตั้งค่าบ้าง (Java, UI ผ่านเบราว์เซอร์)
ถ้าคุณสนใจแนว decentralization หรืออยากมีเสิร์ชเอนจินของตัวเอง YaCy น่าสนใจมาก
PowerMapper: สร้าง Visual Sitemap สำหรับ UX และ QA

PowerMapper เด่นเรื่อง “เห็นภาพ” มันคลานเว็บแล้วสร้าง sitemap แบบอินเทอร์แอคทีฟ พร้อมตรวจ accessibility ความเข้ากันได้ของเบราว์เซอร์ และพื้นฐาน SEO ().
จุดแข็ง:
- sitemap แบบภาพเหมาะกับเอเจนซีและนักออกแบบ
- ตรวจ accessibility และ compliance ได้
- GUI ใช้ง่าย ไม่ต้องมีทักษะเทคนิค
ข้อจำกัด:
- มีแค่ช่วงทดลอง (30 วัน, 100 หน้าเดสก์ท็อป/10 หน้าออนไลน์ต่อการสแกน)
- เวอร์ชันเต็มต้องจ่าย
ถ้าคุณต้องนำเสนอแผนผังเว็บให้ลูกค้า หรืออยากตรวจ compliance แบบเห็นภาพ PowerMapper เป็นเครื่องมือที่สะดวก
เลือก Web Crawler ฟรีให้เหมาะกับงานของคุณ
ตัวเลือกเยอะแล้วจะเลือกยังไง? นี่คือไกด์แบบเร็วของผม:
- ทำ SEO audits: Screaming Frog (เว็บเล็ก), PowerMapper (เน้นภาพ), SiteOne (ตรวจลึก)
- เว็บแอปไดนามิก: Crawljax
- งานสเกลใหญ่/ทำเสิร์ชเอง: Apache Nutch, YaCy
- นักพัฒนาที่ต้องการ API: Crawlbase, ScraperAPI, Diffbot
- ทำเอกสาร/เก็บถาวร: SiteOne Crawler
- ระดับองค์กรแบบมีช่วงทดลอง: BrightData, Diffbot
ปัจจัยที่ควรคิดก่อนเลือก:
- สเกล: เว็บคุณใหญ่แค่ไหน หรือจะคลานหนักแค่ไหน
- ความง่าย: ถนัดโค้ดไหม หรืออยากคลิก ๆ แล้วจบ
- การส่งออกข้อมูล: ต้องการ CSV, JSON หรือเชื่อมกับเครื่องมืออื่น
- ซัพพอร์ต: มีคอมมูนิตี้/เอกสารช่วยไหมเวลาติดปัญหา
เมื่อ Web Crawling เจอกับ Web Scraping: ทำไม Thunderbit ถึงฉลาดกว่า
ความจริงคือ คนส่วนใหญ่ไม่ได้คลานเว็บเพื่อทำแผนที่สวย ๆ เป้าหมายมักเป็น “ข้อมูลแบบมีโครงสร้าง” ไม่ว่าจะเป็นรายการสินค้า ข้อมูลติดต่อ หรือ inventory ของคอนเทนต์ และนี่คือจุดที่ เข้ามา
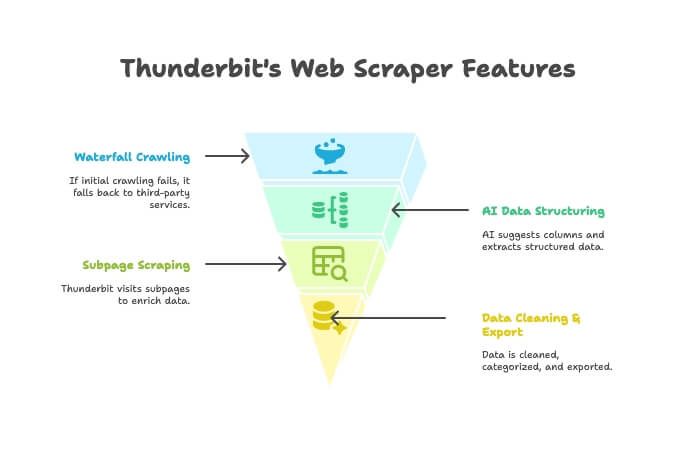
Thunderbit ไม่ได้เป็นแค่ crawler หรือ scraper แต่มันคือส่วนขยาย Chrome ที่ขับเคลื่อนด้วย AI และรวมทั้งสองอย่างไว้ด้วยกัน วิธีทำงานโดยสรุป:
- AI Crawler: Thunderbit สำรวจเว็บไซต์เหมือน crawler
- Waterfall Crawling: ถ้าเอนจินของ Thunderbit ดึงหน้าไม่ได้ (เช่น เจอกำแพงกันบอท) ระบบจะสลับไปใช้บริการคลานของบุคคลที่สามให้อัตโนมัติ—ไม่ต้องตั้งค่าเอง
- AI จัดโครงสร้างข้อมูล: เมื่อได้ HTML แล้ว AI จะช่วยแนะนำคอลัมน์ที่เหมาะสม และดึงข้อมูลแบบมีโครงสร้าง (ชื่อ ราคา อีเมล ฯลฯ) โดยไม่ต้องเขียน selector
- Subpage Scraping: ถ้าต้องการรายละเอียดจากหน้าสินค้าทุกหน้า Thunderbit เข้าไปเก็บจาก subpage ให้และเติมตารางให้ครบได้
- ทำความสะอาดข้อมูล & ส่งออก: สรุป จัดหมวด แปล และส่งออกไป Excel, Google Sheets, Airtable หรือ Notion ได้ในคลิกเดียว
- ใช้งานแบบ No-code: ใช้เป็นก็แค่เบราว์เซอร์—ไม่ต้องโค้ด ไม่ต้อง proxy ไม่ต้องปวดหัว
ควรใช้ Thunderbit แทน crawler แบบเดิมเมื่อไหร่?
- เมื่อเป้าหมายสุดท้ายคือสเปรดชีตที่สะอาดและใช้งานได้จริง ไม่ใช่แค่ลิสต์ URL
- เมื่ออยากทำให้ทั้งกระบวนการ (คลาน → ดึงข้อมูล → ทำความสะอาด → ส่งออก) จบในที่เดียว
- เมื่อคุณให้ค่ากับเวลาและความสบายใจ
คุณสามารถ แล้วลองเองว่าทำไมผู้ใช้สายธุรกิจจำนวนมากถึงเริ่มเปลี่ยนมาใช้
สรุป: ใช้ประโยชน์จาก Website Crawler ฟรีให้คุ้มที่สุด
เครื่องมือคลานเว็บพัฒนาไปไกลมาก ไม่ว่าคุณจะเป็นนักการตลาด นักพัฒนา หรือแค่อยากดูแลเว็บให้สุขภาพดี ก็มีเครื่องมือฟรี (หรืออย่างน้อย “ฟรีให้ลอง”) ให้เลือก ตั้งแต่แพลตฟอร์มระดับองค์กรอย่าง BrightData และ Diffbot ไปจนถึงโอเพ่นซอร์สคุณภาพอย่าง SiteOne และ Crawljax รวมถึงสายทำแผนผังแบบภาพอย่าง PowerMapper—ตัวเลือกหลากหลายกว่าที่เคย
แต่ถ้าคุณอยากได้วิธีที่ฉลาดและเชื่อมต่อกันมากกว่า เพื่อไปจาก “ฉันต้องการข้อมูลนี้” ไปสู่ “นี่คือสเปรดชีตของฉัน” แบบลื่น ๆ ลอง Thunderbit ดู มันถูกออกแบบมาเพื่อผู้ใช้ธุรกิจที่ต้องการผลลัพธ์ ไม่ใช่แค่รายงาน
พร้อมเริ่มคลานแล้วหรือยัง? ดาวน์โหลดเครื่องมือสักตัว รันสแกน แล้วดูว่าคุณพลาดอะไรไปบ้าง และถ้าคุณอยากเปลี่ยนจากการคลานไปเป็นข้อมูลที่นำไปใช้ได้จริงในสองคลิก
อยากอ่านบทความเชิงลึกและไกด์ใช้งานจริงเพิ่มเติม เข้าไปที่
FAQ
Website crawler ต่างจาก web scraper อย่างไร?
Crawler มีหน้าที่ค้นหาและทำแผนที่ทุกหน้าบนเว็บไซต์ (เหมือนทำสารบัญ) ส่วน scraper จะดึงข้อมูลเฉพาะฟิลด์ (เช่น ราคา อีเมล หรือรีวิว) จากหน้าที่พบ Crawler คือคนหา ส่วน scraper คือคนขุด ().
Web crawler ฟรีตัวไหนเหมาะกับคนไม่สายเทคที่สุด?
ถ้าเป็นเว็บเล็กและทำ SEO audit, Screaming Frog ใช้ง่ายมาก ถ้าต้องการแผนผังแบบภาพ PowerMapper ก็เหมาะ (ในช่วงทดลอง) แต่ถ้าเป้าหมายคือข้อมูลแบบมีโครงสร้างและอยากได้ประสบการณ์แบบ no-code ผ่านเบราว์เซอร์ Thunderbit จะง่ายที่สุด
มีเว็บไซต์ที่บล็อก web crawler ไหม?
มี—บางเว็บใช้ robots.txt หรือมาตรการกันบอท (เช่น CAPTCHA หรือบล็อก IP) เพื่อกันการคลาน เครื่องมืออย่าง ScraperAPI, Crawlbase และ Thunderbit (ด้วย waterfall crawling) มักช่วยผ่านด่านเหล่านี้ได้ในหลายกรณี แต่ควรคลานอย่างรับผิดชอบและเคารพกติกาของเว็บไซต์เสมอ ().
Website crawler ฟรีมีลิมิตจำนวนหน้าหรือฟีเจอร์ไหม?
ส่วนใหญ่มี เช่น Screaming Frog เวอร์ชันฟรีจำกัด 500 URL ต่อการคลาน ส่วน PowerMapper ช่วงทดลองจำกัด 100 หน้า เครื่องมือแบบ API มักจำกัดเครดิตรายเดือน ขณะที่โอเพ่นซอร์สอย่าง SiteOne หรือ Crawljax มักไม่มีลิมิตตายตัว แต่จะติดข้อจำกัดที่เครื่อง/ฮาร์ดแวร์ของคุณเอง
การใช้ web crawler ถูกกฎหมายและสอดคล้องความเป็นส่วนตัวไหม?
โดยทั่วไป การคลานหน้าเว็บสาธารณะถือว่าถูกกฎหมาย แต่ควรตรวจเงื่อนไขการใช้งานของเว็บไซต์และ robots.txt เสมอ ห้ามคลานข้อมูลส่วนตัวหรือข้อมูลหลังล็อกอินโดยไม่ได้รับอนุญาต และถ้าคุณดึงข้อมูลส่วนบุคคล ต้องระวังกฎหมายความเป็นส่วนตัวที่เกี่ยวข้อง ().