
โปรเจกต์สแครปแรกๆ ของผมเริ่มจากสคริปต์ Python เขียนเองแบบบ้านๆ ใช้พร็อกซีร่วมกัน แล้วก็ได้แต่ “기도” ให้มันรอด สรุปคือพังทุกๆ สามวันแบบไม่ไว้หน้า
พอมาในปี 2026 ต้องบอกว่า API สำหรับการสแครปมันรับงานหนักแทนเราไปเยอะมาก—ทั้งพร็อกซี การเรนเดอร์หน้าเว็บ CAPTCHAs การรีทราย—เลยไม่ต้องมานั่งปวดหัวเอง มันกลายเป็นอินฟราที่แทบทุกงานต้องใช้ ตั้งแต่ติดตามราคา ไปจนถึงทำดาต้าไพป์ไลน์สำหรับเทรน AI
แต่ก็มีอีกด้านเหมือนกัน: เครื่องมือที่ขับเคลื่อนด้วย AI อย่าง Thunderbit กำลังทำให้หลายเคสที่เมื่อก่อนต้องพึ่ง API “ไม่จำเป็น” อีกต่อไป โดยเฉพาะสำหรับคนที่ไม่ใช่นักพัฒนา เดี๋ยวเล่าต่อด้านล่าง
ต่อไปนี้คือ 10 API สำหรับการสแครปที่ผมเคยใช้หรือประเมินมาแล้ว—แต่ละตัวเด่นอะไร ติดตรงไหน และเมื่อไหร่ที่คุณอาจไม่ต้องใช้ API เลยด้วยซ้ำ
ทำไมควรพิจารณา Thunderbit AI แทน Web Scraping API แบบดั้งเดิม?
ก่อนจะไปดูรายชื่อ API ขอพูดถึง “ช้างในห้อง” กันก่อน: ระบบอัตโนมัติที่ขับเคลื่อนด้วย AI ผมช่วยทีมต่างๆ ทำงานออโตเมชันกับงานน่าเบื่อมาหลายปี และบอกได้เลยว่ามีเหตุผลที่ธุรกิจจำนวนมากเริ่มข้าม API ที่ต้องเขียนโค้ดเยอะ แล้วไปใช้เอเจนต์ AI อย่าง Thunderbit แทน
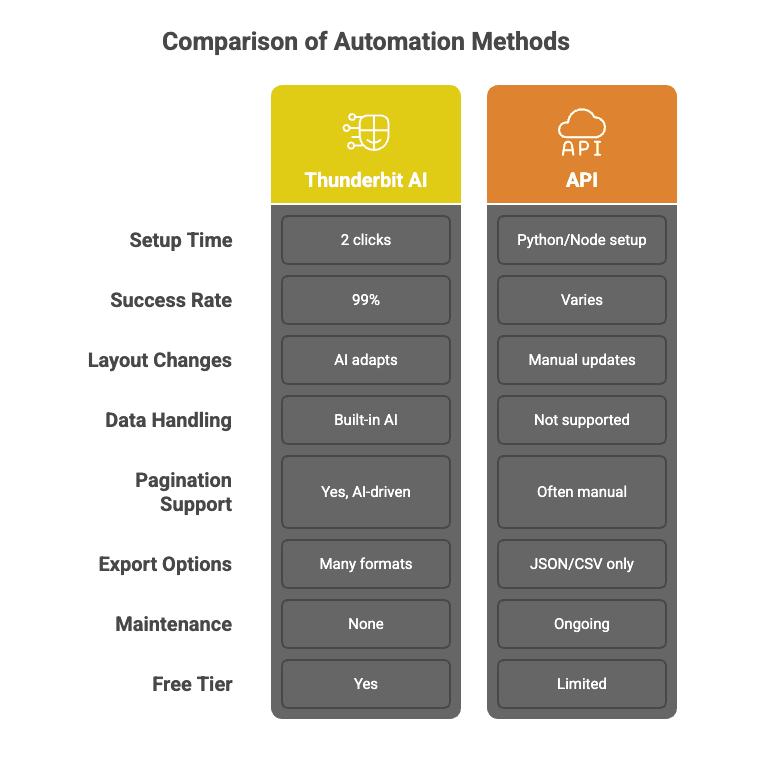
สิ่งที่ทำให้ Thunderbit ต่างจาก Web Scraping API แบบเดิมๆ:
-
เรียก API แบบ Waterfall เพื่อความสำเร็จ 99%
AI ของ Thunderbit ไม่ได้ยิง API ครั้งเดียวแล้วลุ้นเอา แต่มันใช้แนวทางแบบ waterfall—เลือกวิธีสแครปที่เหมาะที่สุดให้แต่ละงานโดยอัตโนมัติ รีทรายเมื่อจำเป็น และตั้งเป้าอัตราสำเร็จ 99% คุณได้ข้อมูล ไม่ได้ได้ปัญหา
-
ไม่ต้องเขียนโค้ด ตั้งค่าแค่สองคลิก
ลืมการเขียนสคริปต์ Python หรือไล่อ่านเอกสาร API ไปได้เลย ใช้ Thunderbit แค่กด “AI Suggest Fields” แล้วกด “Scrape” จบ แม้แต่แม่ผมก็ใช้ได้ (ทั้งที่ยังคิดว่า “คลาวด์” คืออากาศครึ้มๆ ฝนจะตก)
-
สแครปแบบแบตช์: เร็วและแม่น
โมเดล AI ของ Thunderbit ประมวลผลเว็บไซต์จำนวนมากพร้อมกันได้ และปรับตัวตามเลย์เอาต์แต่ละเว็บแบบเรียลไทม์ เหมือนมี 인턴 เป็นกองทัพ—แต่ไม่ต้องพักกินกาแฟ
-
แทบไม่ต้องดูแลรักษา
เว็บไซต์เปลี่ยนตลอดเวลา API แบบเดิม? พังบ่อย Thunderbit? AI อ่านหน้าเว็บใหม่ทุกครั้ง คุณเลยไม่ต้องคอยแก้โค้ดเมื่อเว็บขยับเลย์เอาต์หรือเพิ่มปุ่มใหม่
-
ดึงข้อมูลแบบปรับตามต้องการ + จัดการหลังบ้านได้เลย
อยากให้ข้อมูลถูกทำความสะอาด ติดป้ายกำกับ แปลภาษา หรือสรุป? Thunderbit ทำไปพร้อมกับการดึงข้อมูลได้เลย นึกภาพเหมือนโยนเว็บ 10,000 หน้าเข้า ChatGPT แล้วได้ชุดข้อมูลที่จัดโครงสร้างมาเรียบร้อย
-
สแครปหน้าลูก (Subpage) และการแบ่งหน้า (Pagination)
AI ของ Thunderbit ตามลิงก์ จัดการ pagination และเติมข้อมูลจากหน้าลูกกลับเข้าตารางได้ โดยไม่ต้องเขียนโค้ดเฉพาะทาง
-
ส่งออกข้อมูลฟรี + เชื่อมต่อเครื่องมือยอดนิยม
ส่งออกไป Excel, Google Sheets, Airtable, Notion หรือดาวน์โหลดเป็น CSV/JSON ได้เลย—ไม่ล็อกไว้หลังเพย์วอลล์ ไม่เล่นแง่
เทียบให้เห็นภาพแบบเร็วๆ:
อยากเห็นของจริง? ลองดู Thunderbit Chrome Extension
Data Scraping API คืออะไร?
กลับมาที่พื้นฐานกันสักนิด data scraping api คือเครื่องมือที่ช่วยให้คุณดึงข้อมูลจากเว็บไซต์แบบโปรแกรมเมติกได้ โดยไม่ต้องสร้างสแครปเปอร์เองตั้งแต่ศูนย์ ลองนึกว่าเป็นหุ่นยนต์ที่คุณส่งไปเอาราคาล่าสุด รีวิว หรือรายการประกาศ แล้วมันส่งข้อมูลกลับมาเป็นโครงสร้างสวยๆ (ส่วนใหญ่เป็น JSON หรือ CSV)
แล้วมันทำงานยังไง? โดยทั่วไป scraping API จะจัดการส่วนที่ยุ่งยากให้—เช่นหมุนพร็อกซี แก้ CAPTCHA เรนเดอร์ JavaScript—เพื่อให้คุณโฟกัสกับสิ่งที่ต้องการจริงๆ: ข้อมูล คุณส่งคำขอ (มักเป็น URL พร้อมพารามิเตอร์บางอย่าง) แล้ว API ก็ส่งคอนเทนต์กลับมาให้พร้อมใช้ในเวิร์กโฟลว์ธุรกิจ
ข้อดีหลักๆ:
- ความเร็ว: API สามารถสแครปได้เป็นพันๆ หน้าในหนึ่งนาที
- สเกลได้: อยากมอนิเตอร์สินค้า 10,000 รายการ? ทำได้
- เชื่อมต่อระบบง่าย: ต่อเข้ากับ CRM, BI tool หรือ data warehouse ได้แบบไม่ยุ่งยาก
แต่เดี๋ยวจะเห็นว่า API ไม่ได้เหมือนกันหมด—และหลายตัวก็ไม่ได้ “ตั้งแล้วลืม” ได้จริงอย่างที่โฆษณา
ผมประเมิน API เหล่านี้อย่างไร
ผมอยู่หน้างานมาพอสมควร—ทั้งทดสอบ ทำพัง และบางครั้งก็เผลอทำให้เซิร์ฟเวอร์ตัวเองเหมือนโดน DDoS (อย่าไปบอกทีม IT เก่าผมนะ) สำหรับลิสต์นี้ ผมโฟกัสที่:
- ความเสถียร: ใช้งานได้จริงไหม โดยเฉพาะเว็บที่กันบอทหนักๆ?
- ความเร็ว: ทำงานเร็วแค่ไหนเมื่อรันในสเกลใหญ่?
- ราคา: สตาร์ทอัพจ่ายไหวไหม และขยายไปองค์กรใหญ่ได้หรือเปล่า?
- การรองรับสเกล: รับได้เป็นล้านรีเควสต์ไหม หรือเริ่มล้มตอน 100?
- เป็นมิตรกับนักพัฒนา: เอกสารชัดไหม มี SDK และตัวอย่างโค้ดหรือไม่?
- ซัพพอร์ต: เวลามีปัญหา (ซึ่งมีแน่) ขอความช่วยเหลือได้ไหม?
- เสียงจากผู้ใช้จริง: รีวิวจากการใช้งานจริง ไม่ใช่คำโฆษณา
ผมยังอาศัยการลองใช้จริง การอ่านรีวิวเชิงลึก และฟีดแบ็กจากคอมมูนิตี้ Thunderbit (พวกเราค่อนข้างเรื่องมาก)
10 API ที่น่าพิจารณาในปี 2026
พร้อมแล้วไปกันต่อ นี่คือรายชื่ออัปเดตของผมสำหรับ Web Scraping API และแพลตฟอร์มที่เหมาะทั้งกับผู้ใช้ธุรกิจและนักพัฒนาในปี 2026
1. Oxylabs
 ภาพรวม:
ภาพรวม:
Oxylabs คือสายแข็งระดับองค์กรสำหรับการดึงข้อมูลเว็บ มีพูลพร็อกซีขนาดใหญ่และ API เฉพาะทางตั้งแต่ SERP ไปจนถึงอีคอมเมิร์ซ จึงเป็นตัวเลือกยอดนิยมของบริษัทใหญ่และทีมที่ต้องการความเสถียรในสเกลสูง
ฟีเจอร์เด่น:
- เครือข่ายพร็อกซีขนาดใหญ่ (residential, datacenter, mobile, ISP) ครอบคลุม 195+ ประเทศ
- Scraper API พร้อมระบบกันบอท แก้ CAPTCHA และเรนเดอร์ผ่าน headless browser
- Geotargeting, session persistence และความแม่นยำสูง (อัตราสำเร็จ 95%+)
- OxyCopilot: ผู้ช่วย AI ที่สร้างโค้ดพาร์สและคำสั่ง API ให้อัตโนมัติ
ราคา:
เริ่มราวๆ ~$49/เดือนสำหรับ API เดี่ยว และ $149/เดือนสำหรับแพ็กแบบ all-in-one มีทดลองฟรี 7 วัน สูงสุด 5,000 รีเควสต์
เสียงจากผู้ใช้:
ได้คะแนน 4.8/5 บน G2 คนชมเรื่องความเสถียรและซัพพอร์ต ข้อเสียหลักคือราคาสูง แต่ก็ได้ของตามราคา
ดูรายละเอียด Oxylabs เพิ่มเติม
2. ScrapingBee
 ภาพรวม:
ภาพรวม:
ScrapingBee เป็นเพื่อนแท้นักพัฒนา—เรียบง่าย ราคาเข้าถึงได้ และโฟกัสชัด คุณส่ง URL เข้าไป มันจัดการ headless Chrome, พร็อกซี และ CAPTCHA ให้ แล้วส่งกลับเป็นหน้าเว็บที่เรนเดอร์แล้วหรือเฉพาะข้อมูลที่ต้องการ
ฟีเจอร์เด่น:
- เรนเดอร์ผ่าน headless browser (รองรับ JavaScript)
- หมุน IP อัตโนมัติและแก้ CAPTCHA
- พูลพร็อกซีแบบ stealth สำหรับเว็บที่โหด
- ตั้งค่าน้อย—เรียก API ก็ใช้งานได้
ราคา:
มีฟรีแพ็กประมาณ ~1,000 ครั้ง/เดือน แพ็กเสียเงินเริ่มราวๆ ~$29/เดือนสำหรับ 5,000 รีเควสต์
เสียงจากผู้ใช้:
ได้คะแนนสม่ำเสมอ 4.8/5 บน G2 นักพัฒนาชอบความง่าย แต่คนไม่เขียนโค้ดอาจรู้สึกว่ามัน “โล่ง” ไปหน่อย
3. Apify
 ภาพรวม:
ภาพรวม:
Apify คือมีดพกสวิสของโลกสแครป คุณสร้างสแครปเปอร์เอง (“Actors”) ด้วย JavaScript หรือ Python ก็ได้ หรือจะใช้คลัง actor สำเร็จรูปจำนวนมากสำหรับเว็บยอดนิยมก็ได้ ยืดหยุ่นตามที่คุณต้องการ
ฟีเจอร์เด่น:
- สแครปเปอร์แบบสร้างเองและแบบสำเร็จรูป (Actors) ครอบคลุมแทบทุกเว็บ
- โครงสร้างพื้นฐานบนคลาวด์ การตั้งเวลา และการจัดการพร็อกซีรวมมาให้
- ส่งออกข้อมูลเป็น JSON, CSV, Excel, Google Sheets และอื่นๆ
- คอมมูนิตี้แอคทีฟและซัพพอร์ตผ่าน Discord
ราคา:
มีแพ็กฟรีตลอดพร้อมเครดิต $5/เดือน แพ็กเสียเงินเริ่มที่ $39/เดือน
เสียงจากผู้ใช้:
คะแนน 4.7+ บน G2/Capterra นักพัฒนาชอบความยืดหยุ่น แต่ผู้เริ่มต้นต้องใช้เวลาทำความเข้าใจ
ดูว่า Apify เทียบกับ Thunderbit เป็นอย่างไร
4. Decodo (เดิมชื่อ Smartproxy)
 ภาพรวม:
ภาพรวม:
Decodo (รีแบรนด์จาก Smartproxy) เด่นเรื่องคุ้มค่าและใช้ง่าย รวมโครงสร้างพร็อกซีที่แข็งแรงเข้ากับ scraping API สำหรับเว็บทั่วไป, SERP, อีคอมเมิร์ซ และโซเชียล—จบในซับสคริปชันเดียว
ฟีเจอร์เด่น:
- scraping API แบบรวมศูนย์สำหรับทุก endpoint (ไม่ต้องซื้อแอดออนแยก)
- สแครปเปอร์เฉพาะทางสำหรับ Google, Amazon, TikTok และอื่นๆ
- แดชบอร์ดใช้ง่าย มี playground และตัวช่วยสร้างโค้ด
- ไลฟ์แชตซัพพอร์ต 24/7
ราคา:
เริ่มราวๆ ~$50/เดือนสำหรับ 25,000 รีเควสต์ ทดลองฟรี 7 วัน พร้อม 1,000 รีเควสต์
เสียงจากผู้ใช้:
คนชมว่าคุ้มราคาและซัพพอร์ตตอบไว คะแนน 4.7/5 บน G2
5. Octoparse
 ภาพรวม:
ภาพรวม:
Octoparse คือแชมป์สาย no-code ถ้าคุณไม่ชอบโค้ดแต่ชอบข้อมูล แอปเดสก์ท็อปแบบคลิกเลือก (พร้อมฟีเจอร์คลาวด์) ช่วยให้สร้างสแครปเปอร์แบบภาพและรันได้ทั้งเครื่องตัวเองหรือบนคลาวด์
ฟีเจอร์เด่น:
- ตัวสร้างเวิร์กโฟลว์แบบภาพ—คลิกเลือกฟิลด์ข้อมูลได้เลย
- ดึงข้อมูลบนคลาวด์ ตั้งเวลา และหมุน IP อัตโนมัติ
- มีเทมเพลตสำหรับเว็บยอดนิยม และมาร์เก็ตเพลสสำหรับสแครปเปอร์แบบสั่งทำ
- Octoparse AI: ผสาน RPA และ ChatGPT เพื่อทำความสะอาดข้อมูลและทำเวิร์กโฟลว์อัตโนมัติ
ราคา:
มีแพ็กฟรีสำหรับงานโลคอลสูงสุด 10 งาน แพ็กเสียเงินเริ่มที่ $119/เดือน (ฟีเจอร์คลาวด์ งานไม่จำกัด) ทดลองพรีเมียม 14 วัน
เสียงจากผู้ใช้:
คะแนน 4.4/5 บน G2 คนไม่เขียนโค้ดชอบมาก แต่ผู้ใช้ขั้นสูงอาจเจอข้อจำกัด
6. Bright Data
 ภาพรวม:
ภาพรวม:
Bright Data คือสายใหญ่ตัวจริง—ถ้าคุณต้องการสเกล ความเร็ว และฟีเจอร์ครบแบบจัดเต็ม นี่คือแพลตฟอร์มที่ทำมาเพื่อองค์กร ด้วยเครือข่ายพร็อกซีที่ใหญ่ที่สุดในโลกและ IDE สำหรับสแครปที่ทรงพลัง
ฟีเจอร์เด่น:
- 150M+ IPs (residential, mobile, ISP, datacenter)
- Web Scraper IDE, data collectors สำเร็จรูป และชุดข้อมูลพร้อมซื้อ
- ระบบกันบอทขั้นสูง แก้ CAPTCHA และรองรับ headless browser
- โฟกัสด้านคอมพลายแอนซ์และกฎหมาย (Ethical Web Data initiative)
ราคา:
แบบจ่ายตามใช้: ราวๆ ~$1.05 ต่อ 1,000 รีเควสต์ พร็อกซีเริ่ม $3–$15/GB มีทดลองฟรีสำหรับหลายผลิตภัณฑ์
เสียงจากผู้ใช้:
คนชมเรื่องประสิทธิภาพและฟีเจอร์ แต่ราคาและความซับซ้อนอาจเป็นอุปสรรคสำหรับทีมเล็ก
7. WebAutomation
 ภาพรวม:
ภาพรวม:
WebAutomation เป็นแพลตฟอร์มบนคลาวด์ที่ออกแบบมาสำหรับคนไม่ใช่นักพัฒนา มีมาร์เก็ตเพลสของตัวดึงข้อมูลสำเร็จรูปและตัวสร้างแบบ no-code เหมาะกับผู้ใช้ธุรกิจที่อยากได้ข้อมูล ไม่อยากได้โค้ด
ฟีเจอร์เด่น:
- ตัวดึงข้อมูลสำเร็จรูปสำหรับเว็บยอดนิยม (Amazon, Zillow ฯลฯ)
- ตัวสร้าง extractor แบบ no-code ด้วย UI คลิกเลือก
- ตั้งเวลา ส่งมอบข้อมูล และดูแลรักษาบนคลาวด์ให้ครบ
- คิดราคาตามจำนวนแถว (จ่ายตามที่ดึงจริง)
ราคา:
แพ็กโปรเจกต์ $74/เดือน (~400k แถว/ปี) แบบ pay-as-you-go $1 ต่อ 1,000 แถว ทดลองฟรี 14 วัน พร้อมเครดิต 10 ล้าน
เสียงจากผู้ใช้:
ผู้ใช้ชอบความง่ายและราคาที่โปร่งใส ซัพพอร์ตช่วยได้จริง และทีมดูแลเรื่องเมนเทนให้
8. ScrapeHero
 ภาพรวม:
ภาพรวม:
ScrapeHero เริ่มจากบริษัทรับทำสแครปแบบสั่งทำ และตอนนี้มีแพลตฟอร์มคลาวด์แบบ self-service คุณใช้สแครปเปอร์สำเร็จรูปสำหรับเว็บยอดนิยม หรือขอโปรเจกต์แบบดูแลให้ทั้งหมดก็ได้
ฟีเจอร์เด่น:
- ScrapeHero Cloud: สแครปเปอร์สำเร็จรูปสำหรับ Amazon, Google Maps, LinkedIn และอื่นๆ
- ใช้งานแบบ no-code ตั้งเวลา และส่งข้อมูลผ่านคลาวด์
- โซลูชันสั่งทำสำหรับความต้องการเฉพาะ
- มี API สำหรับเชื่อมต่อแบบโปรแกรมเมติก
ราคา:
แพ็กคลาวด์เริ่มต่ำสุด $5/เดือน โปรเจกต์สั่งทำเริ่มที่ $550 ต่อเว็บไซต์ (จ่ายครั้งเดียว)
เสียงจากผู้ใช้:
คนชมเรื่องความเสถียร คุณภาพข้อมูล และซัพพอร์ต เหมาะสำหรับขยายจากทำเองไปสู่แบบมีทีมดูแล
9. Sequentum
 ภาพรวม:
ภาพรวม:
Sequentum คือมีดพกสวิสสำหรับองค์กร—เน้นคอมพลายแอนซ์ ตรวจสอบย้อนหลังได้ และสเกลใหญ่สุดๆ ถ้าคุณต้องการ SOC-2, audit trail และการทำงานร่วมกันเป็นทีม นี่คือคำตอบ
ฟีเจอร์เด่น:
- ตัวออกแบบเอเจนต์แบบ low-code (คลิกเลือก + สคริปต์)
- ใช้ได้ทั้งแบบ SaaS บนคลาวด์หรือวางระบบ on-premise
- มีระบบจัดการพร็อกซี แก้ CAPTCHA และ headless browser ในตัว
- Audit trail, สิทธิ์ตามบทบาท และรองรับ SOC-2
ราคา:
แบบ pay-as-you-go ($6/ชั่วโมง runtime, $0.25/GB export) แพ็ก Starter $199/เดือน สมัครแล้วได้เครดิตฟรี $5
เสียงจากผู้ใช้:
องค์กรชอบฟีเจอร์ด้านคอมพลายแอนซ์และการรองรับสเกล มีช่วงเรียนรู้ แต่ซัพพอร์ตและเทรนนิ่งดีมาก
10. Grepsr
 ภาพรวม:
ภาพรวม:
Grepsr เป็นบริการดึงข้อมูลแบบ managed—คุณแค่บอกว่าต้องการอะไร ทีมเขาจะสร้าง รัน และดูแลสแครปเปอร์ให้ทั้งหมด เหมาะกับธุรกิจที่อยากได้ข้อมูลโดยไม่อยากยุ่งเรื่องเทคนิค
ฟีเจอร์เด่น:
- บริการแบบ managed (“Grepsr Concierge”)—ตั้งค่าและดูแลให้ครบ
- แดชบอร์ดคลาวด์สำหรับตั้งเวลา มอนิเตอร์ และดาวน์โหลดข้อมูล
- รองรับหลายฟอร์แมตและอินทิเกรชัน (Dropbox, S3, Google Drive)
- คิดเงินต่อเรคคอร์ดข้อมูล (ไม่ใช่ต่อรีเควสต์)
ราคา:
Starter pack $350 (ดึงครั้งเดียว) ส่วนซับสคริปชันรายเดือนคิดราคาตามใบเสนอราคา
เสียงจากผู้ใช้:
ลูกค้าชอบความ “ไม่ต้องทำเอง” และซัพพอร์ตตอบไว เหมาะกับทีมที่ไม่เทคนิคและให้ค่ากับเวลา มากกว่าการปรับจูนเอง
ตารางเทียบแบบเร็ว: Web Scraping API ชั้นนำ
นี่คือชีตสรุปของทั้ง 10 แพลตฟอร์ม:




