การค้นหา "tiktok scraper" บน GitHub แสดงผลลัพธ์ ประมาณ ไม่มีการ push มานานกว่าหนึ่งปีแล้ว และอย่างน้อย
ถ้าคุณเคย clone รีโป TikTok scraper ที่ดัง ๆ มา แล้วต้องเสียเวลาหนึ่งชั่วโมงกับการไล่แก้ dependency สุดท้ายได้ผลลัพธ์เป็นศูนย์ — คุณไม่ได้เจอเรื่องนี้คนเดียว TikTok scraper ที่ได้ดาวมากที่สุดบน GitHub อย่าง drawrowfly/tiktok-scraper ยังมียอดดาวมากกว่า 5,000 ดาว แต่ใน issue tracker เต็มไปด้วยเธรดอย่าง และ — ทั้งคู่รายงานว่าไม่มีผลลัพธ์เลย ผมติดตามสถานะของรีโปสำหรับการดึงข้อมูล TikTok ที่ Thunderbit มาหลายเดือนแล้ว และรูปแบบมันชัดมาก: เครื่องมือพวกนี้พังเร็ว และส่วนใหญ่ไม่เคยถูกแก้ให้กลับมาใช้ได้อีก บทความนี้คือคู่มือเอาตัวรอดแบบใช้งานจริงที่ผมอยากให้มีตอนเริ่มประเมินรีโปพวกนี้ครั้งแรก เราจะดูว่าอะไรยังใช้ได้ อะไรตายแล้ว ควรใช้อะไรแทน และจะเลิกเสียเวลาหลายชั่วโมงกับโค้ดที่หยุดทำงานตั้งแต่ก่อนคุณจะเจอมันได้อย่างไร
ทำไม TikTok Scraper ส่วนใหญ่บน GitHub ถึงพัง (และพังซ้ำเรื่อย ๆ)
TikTok ไม่ใช่เป้าหมายสำหรับการดึงข้อมูลแบบทั่วไป เว็บของมันเปลี่ยนตลอด ต่างจากหน้าสินค้าอีคอมเมิร์ซแบบนิ่ง ๆ หรือรายการไดเรกทอรี TikTok จะสลับ endpoint อัปเดตระบบป้องกันบอท เปลี่ยนวิธีเรนเดอร์หน้า และเพิ่มข้อกำหนดเรื่อง session/token ใหม่ ๆ — บางครั้งภายในไม่กี่สัปดาห์หลังการเปลี่ยนแปลงครั้งล่าสุด
ผู้ดูแลโอเพนซอร์สเป็นอาสาสมัคร พอ TikTok ปล่อยอัปเดตที่ทำให้เส้นทาง request ของ scraper พัง รีโปอาจค้างอยู่อย่างเสียหายเป็นวัน เป็นสัปดาห์ หรือถาวร นี่ไม่ใช่การโทษผู้ดูแล แต่เป็นความไม่สอดคล้องเชิงโครงสร้างระหว่างแพลตฟอร์มที่เปลี่ยนเร็วและมีงบหนา กับนักพัฒนาที่ไม่ได้รับค่าจ้างและยังมีงานประจำ
แม้แต่ TikTok scraper ที่ดีที่สุดก็ยังต้องวนอยู่กับการแก้แล้วพัง ถ้าจะใช้สักตัว คุณต้องมีวิธีประเมิน แก้ปัญหา และมีแผนสำรอง
ระบบป้องกันบอทของ TikTok: คุณกำลังเจอกับอะไร
- การจำกัดอัตรา request เอกสารนักพัฒนาอย่างเป็นทางการของ TikTok ไว้อย่างชัดเจนแม้สำหรับการเชื่อมต่อที่ได้รับอนุมัติ Scraper ที่ไม่เป็นทางการจะชนข้อจำกัดเหล่านี้เร็วกว่าเยอะ
- การบังคับใช้ cookie และ session รีโปยุคใหม่อย่าง ต้องใช้
ms_token; รีโปเก่าอย่าง แสดงtt_webid_v2ในตัวอย่าง; ระบุmsToken,ttwid,X-BogusและA_BogusTikTok ตรวจว่าคำขอของคุณดูเหมือนมาจากเซสชันการใช้งานจริงหรือไม่ - การทำ browser fingerprinting อธิบายว่าทำไมเว็บไซต์ถึงเปรียบเทียบ header, cookie, ลายเซ็น TLS และคุณสมบัติของเบราว์เซอร์ที่ JavaScript มองเห็นกับทราฟฟิกของผู้ใช้จริง ครอบคลุมสัญญาณจาก Canvas, WebGL, WebRTC, ฟอนต์ และ runtime การทำ fingerprinting ก็เหมือน TikTok ตรวจบัตรประชาชนของเบราว์เซอร์คุณ — ถ้าเบราว์เซอร์ คุกกี้ จังหวะเวลา และลายเซ็นเครือข่ายไม่ตรงกัน คำขอก็จะดูปลอมตั้งแต่ก่อนส่งเนื้อหากลับมา
- การตรวจจับพฤติกรรม เกี่ยวกับการดึงข้อมูล TikTok มักพูดว่าการเปิดเซสชัน Playwright ใหม่สด ๆ จะกระตุ้น CAPTCHA โพสต์จากชุมชนในช่วง พูดถึงการตรวจจับที่ดูทั้งจังหวะการกระทำและคุณภาพของการโต้ตอบ ไม่ใช่แค่การใช้ IP ซ้ำ
- พารามิเตอร์ request ที่เข้ารหัส/ลงลายเซ็น Evil0ctal อธิบาย
X-BogusและA_Bogus; gists จากชุมชนรุ่นเก่ามักวนอยู่กับการ sign URL และสร้าง token TikTok ยิ่งคาดหวังมากขึ้นว่าคำขอจะมาพร้อม “ตรา” แบบเดียวกับทราฟฟิกจากเบราว์เซอร์หรือแอปของตัวเอง - CAPTCHA และ flow การยืนยันตัวตน การมีอยู่ของ และ ยืนยันว่า CAPTCHA ยังเป็นส่วนหนึ่งของพื้นผิว anti-bot อยู่
ทำไมผู้ดูแลโอเพนซอร์สถึงตามไม่ทัน
วงจรมักเหมือนเดิมเสมอ นักพัฒนาสร้าง TikTok scraper ขึ้นมา มันดังบน GitHub TikTok แก้ทาง ผู้ดูแลก็แก้ต่อหรือไม่ก็ไปทำอย่างอื่น
มี 2 รีโปที่สะท้อนรูปแบบนี้ได้ชัดมาก:
- drawrowfly/tiktok-scraper ยังมี 5,052 ดาวและ 889 forks แต่ มันคือ TikTok scraper แบบตรงคำค้นที่ได้ดาวมากที่สุดบน GitHub และตอนนี้อ่านดูเหมือนหลักฐานทางประวัติศาสตร์: คนเห็นเยอะ เคยน่าเชื่อถือ แต่ไม่มีการดูแลอยู่ในปัจจุบัน
- davidteather/TikTok-Api แสดง ฟีด แสดงว่ามีการดูแลจริงในเดือนเมษายน 2025 กรกฎาคม 2025 ตุลาคม 2025 และเมษายน 2026 — รวมถึงการแก้เรื่องการ crawl วิดีโอของผู้ใช้และการควบคุม proxy/session แบบใหม่ แต่ถึงโปรเจกต์นี้จะดีกว่า ก็ยังเตือนอย่างตรงไปตรงมาว่า TikTok บล็อก request ได้ และผู้ใช้อาจต้องใช้ proxy, Playwright และตรรกะ session แบบกำหนดเอง
รูปแบบมันง่ายมาก:
- รีโป TikTok scraper ที่เก่าเกินไปน่าจะตายแล้ว
- รีโป TikTok scraper ที่ยัง active ก็ยังเปราะบางอยู่ดี
- ความต่างจริง ๆ มีแค่ว่ายังมีคนอยู่คอยแก้ปัญหาในเดือนนี้หรือไม่
เช็กลิสต์สภาพรีโปใน 60 วินาที: ประเมิน TikTok Scraper บน GitHub อย่างไร
ก่อนจะ clone อะไรให้รันเช็กลิสต์นี้ก่อน ใช้เวลาไม่ถึงนาที แต่ช่วยประหยัดความหงุดหงิดได้หลายชั่วโมง
| สัญญาณ | 🟢 สุขภาพดี | 🟡 มีความเสี่ยง | 🔴 ตายแล้ว |
|---|---|---|---|
| push ที่มีความหมายล่าสุด | ไม่เกิน 3 เดือน | 3–12 เดือน | 12 เดือนขึ้นไป |
| จำนวน issue ที่เปิดอยู่ | น้อย และ issue ใหม่มีคนตอบ | กองมากขึ้นพร้อมกิจกรรมจากผู้ดูแลบ้าง | มีรายงาน "พัง/โดนบล็อก/ใช้ไม่ได้" จำนวนมากแต่ไม่มีคนตอบ |
| คำร้องเรียนจากผู้ใช้ล่าสุด | ส่วนใหญ่เป็นคำถามการตั้งค่า | ผสมทั้งการตั้งค่าและปัญหาพัง | พูดซ้ำ ๆ ว่า "ไม่มีผลลัพธ์", "403", "ยังใช้ได้ไหม" |
| โมเดล auth/session ปัจจุบัน | มีเอกสารเส้นทาง session/cookie ชัดเจน | ใช้ token เยอะ แต่มีเอกสาร | ยังพึ่ง endpoint เว็บเก่า ๆ โดยไม่มีแนวทาง auth ปัจจุบัน |
| พื้นผิวการติดตั้ง | ตั้งค่าได้ชัดเจนและทดสอบแล้ว | มีขั้นตอนที่ต้องทำเองบ้าง | dependency เก่า ไม่มีโน้ตตั้งค่าแบบใหม่ |
| CI/tests | มีเทสต์และยังใหม่ | มีเทสต์แต่ไม่ชัดว่าครอบคลุมแค่ไหน | ไม่มีเทสต์ หรือ action เก่า |
| ความสอดคล้องกับขอบเขตข้อมูล | ตรงกับ use case จริงของคุณ | รองรับแค่บางส่วนของ use case | แก้ปัญหาคนละเรื่องไปเลย |
วิธีเช็กแต่ละสัญญาณให้เสร็จภายใน 60 วินาที
- วันที่ push ล่าสุด: ดูที่หัว repo บน GitHub ถ้ามันบอกว่า "last pushed 2 years ago" ก็จบได้เลย
- Issue ที่เปิดอยู่: คลิกแท็บ Issues แล้วกวาดดูหัวข้อล่าสุด ค้นหาคำว่า
not working,403,blocked,captchaหรือzero output - คำร้องเรียนจากผู้ใช้: ถ้า 5 issue ที่เปิดอยู่บนสุดเป็นเวอร์ชันต่าง ๆ ของ "อันนี้ใช้ไม่ได้แล้ว" นั่นคือคำตอบ
- โมเดล auth/session: เปิด README มองหาคำแนะนำปัจจุบัน เช่น
ms_token, การตั้งค่า Playwright หรือหมายเหตุเรื่อง proxy ถ้า README ยังอ้าง endpoint ปี 2023 ก็ข้ามไปได้ - พื้นผิวการติดตั้ง: ดูว่ามีไฟล์ requirements, รองรับ Docker หรือมีคำสั่งตั้งค่าชัดเจนไหม ถ้า README บอกแค่ "npm install" และ Node เวอร์ชันล่าสุดที่ทดสอบคือ 14 ให้เตรียมเจอปัญหา
- CI/tests: ดูแท็บ Actions ถ้าเทสต์ล้มเหลวหรือไม่มีเลย การเดาเอาว่าจะพังตรงไหนก็ไม่ต่างกัน
- ขอบเขตข้อมูล: รีโปนั้นอธิบายชนิดข้อมูลที่คุณต้องการจริงไหม เช่น profile, video metadata, comments, hashtags หลายรีโปทำได้แค่ดาวน์โหลดวิดีโอ ไม่ได้ดึงข้อมูลแบบมีโครงสร้าง
สัญญาณเตือนที่แปลว่า “เดินออกมาเถอะ”
- รีโปถูกเก็บถาวรแล้ว
- README เขียนว่า "no longer maintained"
- commit ล่าสุดอ้างอิง TikTok API เวอร์ชันเมื่อ 2 ปีก่อนขึ้นไป
- issue ถูกถล่มด้วยรายงานว่า "ใช้ไม่ได้" และผู้ดูแลไม่ตอบมาหลายเดือน
- รีโปได้ดาวสูงแต่ไม่มี forks หรือ pull request ใหม่ ๆ
ทิปเล็ก ๆ: ค้นหาในแท็บ Issues ด้วย is:issue is:open "not working" หรือ is:issue is:open "403" ถ้าผลลัพธ์เยอะและใหม่อยู่เสมอ รีโปนั้นน่าจะพัง
รีโป TikTok Scraper บน GitHub ที่นิยม: ตรวจสถานะอย่างตรงไปตรงมา (2026)
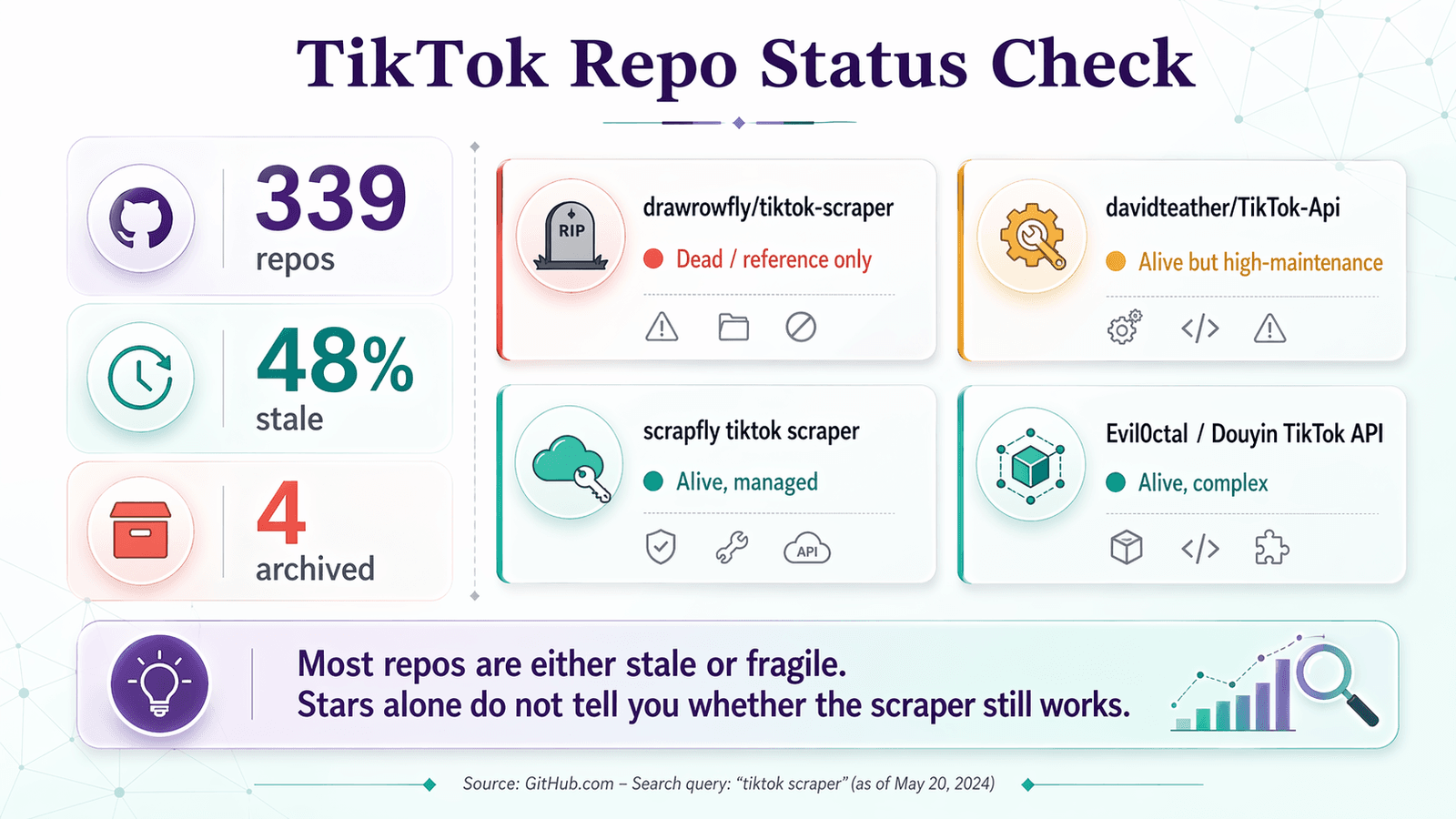
นี่คือเช็กลิสต์สภาพรีโปที่นำไปใช้กับรีโปที่คุณจะเจอจริง ๆ ตอนค้นหา "tiktok scraper" บน GitHub:
| Repo | Push ล่าสุด | ดาว | Issue ที่เปิดอยู่ | ข้อสรุป | หมายเหตุ |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5,052 | 58 | 🔴 ตายแล้ว / อ้างอิงเท่านั้น | ยังดังอยู่ แต่เก่าเกินไปสำหรับงาน production ปี 2026 |
| davidteather/TikTok-Api | 2026-04-01 | 6,301 | 134 | 🟡 ยังอยู่แต่ต้องดูแลหนัก | ตัวเลือกโอเพนซอร์สที่แข็งแรงที่สุด; ต้องใช้ Playwright, tokens และมักต้องใช้ proxies |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938 (parent) | ~0 (monorepo) | 🟡 ยังอยู่ แต่ไม่ใช่ OSS ล้วน | ทันสมัยและมีประโยชน์ แต่ต้องใช้ ScrapFly API key |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17,397 | 135 | 🟡 ยังอยู่ ขอบเขตกว้าง ซับซ้อน | โปรเจกต์หลายแพลตฟอร์มที่มีฟีเจอร์เยอะ; ใกล้เคียงแพลตฟอร์มสำหรับผู้ใช้ระดับโปร |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 มีความเสี่ยง | รีโปขนาดเล็กที่มีคำร้องเรียนเปิดอยู่เกี่ยวกับข้อมูลผู้ใช้และ flow ของ hashtag |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 ใหม่เกินกว่าจะเชื่อถือ | รีโปโชว์เคส ไม่ใช่โปรเจกต์ที่ผ่านการพิสูจน์จากชุมชน |
drawrowfly/tiktok-scraper
หลายปีมานี้ TypeScript scraper/downloader ตัวนี้คือคำตอบมาตรฐานของคำว่า "tiktok scraper github" — รองรับ feed ของ user, trend, hashtag และ music ในปี 2026 มันเหมาะจะถูกมองเป็นเอกสารประวัติศาสตร์มากกว่า และคิว issue ยังมีรายงานที่ยังไม่จบอย่าง กับ จากช่วง 2023–2025 ถ้าคุณอ่านบทความนี้เพราะ clone รีโปนี้แล้วไม่ได้อะไรเลย คุณไม่ได้โดดเดี่ยว
davidteather/TikTok-Api
ตัวห่อข้อมูล TikTok แบบโอเพนซอร์สที่น่าเชื่อถือที่สุดที่ยังมีชีวิตอยู่ในปี 2026 มัน active มี และระบุชัดเจนเรื่องการตั้งค่า Playwright การใช้งาน async การจัดการ token การรองรับ proxy และฟีเจอร์กู้คืน session แต่ไม่ใช่เครื่องมือแบบ "clone แล้วใช้ได้เลย" README ของมันบอกเองว่า EmptyResponseException มักหมายถึง TikTok กำลังบล็อก request และ แสดงปัญหาซ้ำ ๆ เกี่ยวกับ ms_token, การดึงคอมเมนต์ที่พัง, KeyError: 'ItemModule' และความล้มเหลวเฉพาะ endpoint สรุป: ยังอยู่ ใช้ได้จริง แต่เหมาะกับนักพัฒนา และต้องดูแลเยอะ
รีโปอื่น ๆ ที่น่าสนใจ
- : ทันสมัยและเกี่ยวข้องในเชิงเทคนิค แต่ README ต้องใช้
SCRAPFLY_KEYนี่คือตัวอย่างโค้ดสำหรับแพลตฟอร์มสครัปแบบมีการจัดการ ไม่ใช่เครื่องมือฟรีแบบแยกเดี่ยว - : ครอบคลุม TikTok และ Douyin มีเอกสารเรื่อง logic การ sign (
X-Bogus,A_Bogus,msToken) และรองรับคอมเมนต์ ผู้ติดตาม เพลย์ลิสต์ และอื่น ๆ อีกมากมาย ต้องใช้ทักษะทางเทคนิคสูงและเกี่ยวข้องกับ API แบบเสียเงินมากขึ้นเรื่อย ๆ issue tracker แสดงบั๊กที่ยังเกิดในปี 2026 เกี่ยวกับลิงก์วิดีโอและ endpoint ข้อมูลผู้ใช้ ยังอยู่และฟีเจอร์เยอะ แต่ซับซ้อน - : ขนาดเล็กกว่า และมีคำร้องเรียนที่เปิดอยู่ มีความเสี่ยงสำหรับงาน production
- : ดาว 4 ดวง ไม่มี issue ใหม่ ใหม่เกินไปที่จะเชื่อถือ บทความ Medium ที่โปรโมตมันก็สรุปแบบไม่วิจารณ์เลย
TikTok Official API vs. GitHub Scrapers vs. เครื่องมือ No-Code: กรอบการตัดสินใจ

บทความคู่แข่งส่วนใหญ่มักจะมองข้ามเส้นทางการเข้าถึงแบบทางการของ TikTok หรือกระโดดจาก "ใช้ GitHub" ไปเป็น "ซื้อบริการเราเลย" ด้านล่างคือการเปรียบเทียบแบบเป็นกลางของทั้ง 3 ทางเลือก:
| ปัจจัย | TikTok Research API | GitHub Scrapers | เครื่องมือ No-Code (เช่น Thunderbit) |
|---|---|---|---|
| อุปสรรคในการเข้าถึง | ต้องสมัครเชิงวิชาการ/ธุรกิจ; ใช้เวลาประมาณ 4 สัปดาห์ กว่าจะอนุมัติ | แค่ git clone + ตั้งค่า | ติดตั้ง browser extension |
| ขอบเขตข้อมูล | เฉพาะ endpoint ที่อนุมัติ (accounts, videos, comments, shops) | กว้าง (profiles, videos, comments, hashtags, shops) | ข้อมูลที่มองเห็นบนหน้าเว็บ (profiles, videos, engagement, hashtags) |
| ภาระการดูแล | ต่ำ (เป็นทางการ เสถียร) | สูง (รีโปพังเมื่อ TikTok อัปเดต) | ไม่มี (AI ปรับตามการเปลี่ยนเลย์เอาต์) |
| ความเสี่ยงโดนแบน | ไม่มี (ได้รับอนุญาต) | สูง | ต่ำ (ทำงานผ่านเบราว์เซอร์ เลียนแบบผู้ใช้จริง) |
| ค่าใช้จ่าย | ฟรี (ถ้าอนุมัติ) | ฟรี (แต่กินเวลา) | มี แผนใช้ฟรี; แผนแบบเครดิตเริ่มต้นที่ $15/เดือน |
| ต้องเขียนโค้ดไหม | ใช่ (Python/R) | ใช่ (Python/Node.js) | ไม่ต้อง |
| เหมาะที่สุดสำหรับ | นักวิจัย นักวิชาการ หน่วยงานที่ผ่านการอนุมัติ | นักพัฒนาที่รับการดูแลระบบได้ | นักการตลาด ทีมขาย ทีมปฏิบัติการ คนไม่ใช่นักพัฒนา |
เมื่อ TikTok Research API คือคำตอบที่เหมาะ
ของ TikTok คือเส้นทางทางการที่สะอาดที่สุดถ้าคุณมีคุณสมบัติ ผู้วิจัยที่มีสิทธิ์ใน สามารถสมัครเพื่อศึกษาคอนเทนต์สาธารณะและข้อมูลบัญชีได้ หมวดข้อมูลที่มีให้ ได้แก่ accounts, followers/following, liked videos, pinned videos, reposted videos, content, comments และ shops เปิดให้ดู field อย่าง video_description, view_count, like_count, comment_count, share_count และ field ระดับคอมเมนต์อย่าง text, reply_count, create_time
ข้อเสียคือ สิทธิ์เข้าถึงจำกัดเฉพาะสถาบันวิชาการและผู้วิจัยอิสระ/ไม่แสวงหากำไรที่มีสิทธิ์ในบางภูมิภาค รวมถึง ถ้าคุณเป็นทีม growth หรือเอเจนซีที่ต้องการข้อมูลเชิงปฏิบัติการเร็ว ๆ นี่ไม่ใช่ทางของคุณ
TikTok ยังมี สำหรับข้อมูลโฆษณาและคอนเทนต์ของผู้ลงโฆษณา ซึ่งมีประโยชน์สำหรับงานวิจัยด้านความโปร่งใส แต่ไม่ใช่การดึงข้อมูลทั่วไป
เมื่อ GitHub Scraper ยังมีเหตุผลให้ใช้
GitHub scraper ยังเหมาะกับนักพัฒนาที่ต้องการเข้าถึงข้อมูลสาธารณะนอกเหนือจากกำแพงอนุมัติของ API ทางการ และยอมรับได้ว่าจะต้องดูแลสแตกต่อเอง ซึ่งรวมถึง use case อย่างการดึงกริดโปรไฟล์ที่มองเห็นได้ แฮชแท็ก คอมเมนต์ เพลย์ลิสต์ หรือ metadata วิดีโอใน pipeline ที่เขียนเองซึ่งการ fork รีโปแล้วแพตช์ต่อเป็นเรื่องปกติ
ข้อควรยอมรับแบบตรงไปตรงมา: นี่ไม่ใช่การตั้งครั้งเดียวจบ แม้แต่รีโปที่ไว้ใจได้ที่สุดในปี 2026 อย่าง ก็ยังบอกผู้ใช้อยู่ดีว่าอาจต้องใช้ Playwright, cookies/tokens, proxies และ factory สำหรับ page/session แบบกำหนดเอง
เมื่อเครื่องมือ No-Code อย่าง Thunderbit คือคำตอบที่เหมาะ
ไม่ใช่นักพัฒนาใช่ไหม? หรือเป็นนักพัฒนาที่เบื่อวงจรแก้แล้วพัง? เครื่องมือ AI บนเบราว์เซอร์คือทางที่เร็วที่สุดสำหรับข้อมูล TikTok แบบมีโครงสร้าง
เราออกแบบ มาเป็น AI web scraper ที่ทำงานผ่าน Chrome extension บน TikTok มันอ่านได้ทุกหน้าที่มองเห็นได้ (profile, video, hashtag, search results) เสนอคอลัมน์ผ่านฟีเจอร์ "AI Suggest Fields" และให้คุณคลิก "Scrape" เพื่อดึงข้อมูลออกมาเป็นโครงสร้าง หน้า ระบุ field อย่างวันที่โพสต์ ระยะเวลาวิดีโอ ยอดไลก์ ยอดแชร์ ยอดบันทึก คอมเมนต์ ยอดวิว และแฮชแท็ก หน้า แสดงวิธีเก็บภาพปกโพสต์ URL คำบรรยาย แฮนเดิลของครีเอเตอร์ และสัญญาณการมีส่วนร่วมจากหน้าฟีดโปรไฟล์ หน้า ครอบคลุม video URL ชื่อผู้ใช้ครีเอเตอร์ คำอธิบาย เวลาโพสต์ ยอดวิว ไลก์ คอมเมนต์ แชร์ เสียง/ออดิโอ และ URL รูปปก
การ scrape แบบ subpage ช่วยให้คุณกดเข้าไปแต่ละหน้าวิดีโอจากรายการโปรไฟล์แล้วเพิ่มข้อมูลลงตารางด้วยตัวชี้วัดการมีส่วนร่วม คำบรรยาย และแฮชแท็ก ซึ่งมีประโยชน์มากสำหรับนักการตลาดที่สร้างฐานข้อมูลอินฟลูเอนเซอร์หรือทำ audit คอนเทนต์คู่แข่ง
ไม่ต้องดูแล ไม่ต้องติดตั้งให้วุ่นวาย ไม่ต้องตั้งค่า anti-ban AI ปรับตามการเปลี่ยนเลย์เอาต์ของ TikTok ให้อัตโนมัติ ส่งออกไป Google Sheets, Excel, Airtable, Notion, CSV หรือ JSON ได้ฟรี
ถ้าคุณเผาผลาญเวลาไปหลายชั่วโมงกับรีโป GitHub ที่พังอยู่ นี่คือทางเลือกที่ถูกต้องจริง ๆ ไม่ใช่การขายของยัดเยียด
การกู้สถานะติดตั้ง: แก้ 5 ปัญหาติดตั้ง TikTok Scraper บน GitHub ที่เจอบ่อยที่สุด
ปัญหาติดตั้งเป็นจุดที่ถูกพูดถึงมากเป็นอันดับสามในฟอรัมเกี่ยวกับการดึงข้อมูล TikTok และไกด์ใหญ่ ๆ ก็ไม่ได้ช่วยให้คุณแก้ได้จริง นี่คือสิ่งที่มักพัง
ความขัดแย้งของเวอร์ชัน Node.js
ปัญหา: รีโป TikTok scraper เก่า ๆ หลายตัว (โดยเฉพาะ drawrowfly/tiktok-scraper) ถูกสร้างมาสำหรับ Node.js 14–16 ถ้าคุณใช้ Node 20+ npm install อาจล้มเหลวแบบเงียบ ๆ หรือสร้าง binary ที่เข้ากันไม่ได้
วิธีแก้: ใช้ nvm (Node Version Manager) เพื่อติดตั้งและสลับไปใช้เวอร์ชันที่ถูกต้อง:
1nvm install 16
2nvm use 16
3npm installถ้ารีโปไม่ระบุเวอร์ชัน Node ให้เช็กฟิลด์ engines ใน package.json หรือดู config ของ CI
ปัญหา Python dependency และการตั้งค่า Playwright
ปัญหา: ต้องใช้ และ Playwright พร้อม browser binary เฉพาะ ผู้ใช้จะเจอ error อย่าง "browser not found" หรือ dependency conflict
วิธีแก้: ใช้ virtual environment เสมอ แล้วติดตั้ง browser ของ Playwright โดยตรง:
1python -m venv .venv
2source .venv/bin/activate # บน Windows: .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installถ้า playwright install ล้มเหลว ให้เช็ก package manager ของระบบว่าขาด system dependency บางตัวหรือไม่ (เช่น libnss3 บน Ubuntu)
ปัญหา permission บน Linux/Ubuntu
ปัญหา: การรัน sudo pip install จะทำให้สภาพแวดล้อม Python ของระบบเสีย และก่อปัญหา dependency ต่อเนื่องตามมา
วิธีแก้: ห้ามใช้ sudo pip install เด็ดขาด ให้สร้าง virtual environment ก่อนเสมอ:
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtวิธีนี้จะช่วยแยก dependency ของ scraper ออกจาก Python ของระบบ
ปัญหา path และ encoding บน Windows
ปัญหา: Windows CMD มีปัญหาเรื่อง encoding และข้อจำกัดความยาว path ซึ่งทำให้การติดตั้ง scraper พัง โดยเฉพาะตอน Playwright ดาวน์โหลด browser binary ลงในโฟลเดอร์ที่ซ้อนลึกมาก
วิธีแก้: ใช้ WSL (Windows Subsystem for Linux) หรือ Git Bash แทน CMD WSL จะให้สภาพแวดล้อม Linux เต็มรูปแบบอยู่ภายใน Windows:
1wsl --install
2# จากนั้นเปิด terminal ของ WSL แล้วทำตามขั้นตอนตั้งค่า Linuxทางลัดด้วย Docker: ข้ามปัญหา dependency ไปเลย
ปัญหา: ทุกข้อด้านบน
วิธีแก้: ถ้าคุณถนัด Docker ให้คอนเทนเนอร์สภาพแวดล้อมของ scraper ไปเลย Dockerfile พื้นฐานสำหรับ TikTok scraper ที่เขียนด้วย Python จะดูประมาณนี้:
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]วิธีนี้รับประกันสภาพแวดล้อมที่ทำซ้ำได้ไม่ว่า host OS ของคุณจะเป็นอะไร ถ้า scraper ใช้ได้ใน Docker แล้วพังข้างนอก Docker แปลว่าปัญหาอยู่ที่สภาพแวดล้อม ไม่ใช่โค้ด
แผนผังการแก้ปัญหา:
- รีโปสามารถรัน example ของมันเองได้ไหม? → ถ้าไม่ได้ ให้เช็กเวอร์ชัน runtime
- เวอร์ชัน runtime ถูกไหม? → เช็กการติดตั้ง browser/Playwright
- ติดตั้ง browser แล้วหรือยัง? → เช็ก token/cookie
- token/cookie ใช้ได้ไหม? → เช็กว่า TikTok บล็อกเซสชันอยู่หรือเปล่า
- ทุกข้อข้างต้นยังไม่ผ่าน? → ให้ถือว่าเป็นปัญหาจากรีโป ไม่ใช่ความผิดผู้ใช้ เปลี่ยนเครื่องมือ
แนวปฏิบัติ Anti-Ban สำหรับการดึงข้อมูล TikTok (โดยไม่ต้องจ่ายค่า proxy)
ผู้ใช้ในฟอรัมบ่นเรื่องการโดนแบนและการถูกตรวจจับซ้ำ ๆ: "they get your accounts banned, which is an added expense" และ "without using Apify or expensive paid APIs." นี่คือวิธีหลีกเลี่ยงแบบฟรีและใช้งานได้จริง โดยไม่ต้องสมัคร proxy แบบเสียเงิน

| แนวทาง | ความยาก | ค่าใช้จ่าย | ประสิทธิภาพ |
|---|---|---|---|
| หน่วง request แบบสุ่ม (jitter 2–8 วิ) | ง่าย | ฟรี | ปานกลาง |
| หมุนเวียน session/cookie | ปานกลาง | ฟรี | ปานกลาง |
| scrape เฉพาะหน้าสาธารณะที่ล็อกเอาต์อยู่ | ง่าย | ฟรี | ปานกลาง |
เคารพ robots.txt + rate-limit header | ง่าย | ฟรี | ระดับพื้นฐาน |
| สุ่ม browser fingerprint แบบ headless (Playwright) | ปานกลาง | ฟรี | สูง |
| ใช้ endpoint ของ mobile API ของ TikTok (ตรวจจับยากกว่า) | ยาก | ฟรี | สูง |
| หมุนเวียน residential proxy | ปานกลาง | $20–100/เดือน | สูง |
เทคนิคฟรีที่ช่วยได้จริง
หน่วง request แบบสุ่ม อย่าส่ง request แบบรัวติดกัน ให้ใส่ jitter สุ่ม 2–8 วินาทีระหว่างแต่ละ request นี่คือสิ่งที่ทำได้ง่ายที่สุด:
1import time, random
2time.sleep(random.uniform(2, 8))ใช้ session และ cookie ซ้ำ อย่าสร้าง session ใหม่ทุกครั้งที่ส่ง request ให้ใช้ cookie และ session state เดิมในชุด request หนึ่งก่อน แล้วค่อยหมุนใหม่ นี่คือเหตุผลที่รีโปยุคใหม่ขอ ms_token แทนที่จะสัญญาว่าจะ scrape แบบไม่ต้องมีสถานะ
scrape เฉพาะหน้าสาธารณะที่ล็อกเอาต์อยู่ ว่าไม่รองรับเส้นทางที่ต้องยืนยันตัวตนของผู้ใช้ และใช้งานได้เฉพาะข้อมูลที่มองเห็นตอนล็อกเอาต์เท่านั้น การ scrape ตอนล็อกเอาต์มีโอกาสถูกตรวจจับต่ำกว่า session ที่ล็อกอิน
เคารพ robots.txt บล็อกเอเจนต์จำนวนมากทั้งหมด และอนุญาตให้ crawl เฉพาะพาธสาธารณะบางส่วนเท่านั้น นี่ไม่ใช่ใบอนุญาตให้ scrape แบบรุกหนัก แต่การเคารพมันจะช่วยลดโอกาสโดน blacklist ทันที
เทคนิคระดับกลางเพื่อเพิ่มโอกาสสำเร็จ
สุ่ม browser fingerprint สำหรับ headless browser ถ้าคุณใช้ Playwright ให้สุ่มขนาด viewport user-agent timezone และ locale สำหรับแต่ละ session วิธีนี้ทำให้ scraper ของคุณดูเหมือนผู้ใช้จริงคนละคนทุกครั้ง แทนที่จะเป็นบอทตัวเดิมที่แค่เปลี่ยน IP ใหม่
ใช้ endpoint ของ mobile API ของ TikTok สมาชิกชุมชนบางคนรายงานว่าการยิงไปยัง endpoint แบบมือถือมีอัตราถูกตรวจจับต่ำกว่าการใช้หน้าเว็บ frontend วิธีนี้ยากกว่าและมีเอกสารน้อยกว่า แต่เป็นเทคนิคจริงสำหรับผู้ใช้ระดับสูง
เมื่อคุณต้องใช้ proxy จริง ๆ และตัวเลือกที่พอเอื้อมถึง
เมื่อสเกลใหญ่ เทคนิคฟรีมักไม่พอ การหมุนเวียน residential proxy คือแนวทางมาตรฐานสำหรับการดึงข้อมูล TikTok ปริมาณมาก ผมจะไม่แนะนำบริการ proxy แบบเสียเงินเจาะจงที่นี่ แต่คำแนะนำทั่วไปคือ: เลี่ยง datacenter proxy (TikTok ตรวจจับแรง) และมองหา pool แบบ residential หรือ mobile ที่หมุน IP ราย request ได้
หรือถ้าใช้เครื่องมือแบบเบราว์เซอร์อย่าง ก็ไม่ต้องคิดเรื่อง proxy เลย เพราะมันทำงานในเซสชันเบราว์เซอร์ของคุณเองและเลียนแบบผู้ใช้จริง ซึ่งไม่ได้แปลว่าจะปลอดภัยจากการถูกตรวจจับที่สเกลใหญ่ แต่สำหรับ use case ด้านการตลาดหรือการวิจัยทั่วไป (หลักสิบถึงหลักร้อยหน้า ไม่ใช่หลักล้าน) มันง่ายกว่ามาก
คุณได้ข้อมูลอะไรจริง ๆ? ตัวอย่างผลลัพธ์จาก TikTok Scraper
ผู้ใช้มักอยากรู้ก่อนว่าจะได้ข้อมูลอะไรจริง ๆ ก่อนตัดสินใจใช้เครื่องมือ — และไกด์ส่วนใหญ่ก็มักข้ามส่วนนี้ไปเลย นี่คือตัวอย่างโครงสร้าง field ที่อ้างอิงจากเอกสารต้นทาง
ข้อมูลโปรไฟล์
| ชื่อผู้ใช้ | ชื่อที่แสดง | ผู้ติดตาม | กำลังติดตาม | ไลก์ทั้งหมด | ประวัติ | ยืนยันแล้ว | URL โปรไฟล์ |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1,240,000 | 312 | 48,700,000 | "ทำอาหาร + คอมเมดี้ 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890,000 | 150 | 22,100,000 | "บล็อกเกอร์ท่องเที่ยว 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2,100,000 | 88 | 91,300,000 | "ออกกำลังกายและสุขภาพ" | ✅ | tiktok.com/@fitnessmaya |
ได้จาก: GitHub scrapers (TikTok-Api, Evil0ctal), Research API, Thunderbit (จากหน้าโปรไฟล์ที่มองเห็นได้)
Metadata วิดีโอ
| URL วิดีโอ | คำบรรยาย | ยอดวิว | ไลก์ | คอมเมนต์ | แชร์ | เพลง | แฮชแท็ก | วันที่โพสต์ | ระยะเวลา |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "ทริกทำพาสต้าให้อร่อยที่สุด 🍝" | 4,200,000 | 312,000 | 8,400 | 21,000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV: แมวของคุณกำลังตัดสินคุณ" | 9,100,000 | 1,100,000 | 23,000 | 55,000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "รูทีนตอนเช้าที่ไม่มีใครขอ" | 1,800,000 | 98,000 | 3,200 | 7,500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
ได้จาก: GitHub scrapers (TikTok-Api, Evil0ctal), (field มี video_description, view_count, like_count, comment_count, share_count, music_id, hashtag_names, video_duration), Thunderbit ()
ข้อมูลคอมเมนต์
| ผู้คอมเมนต์ | ข้อความคอมเมนต์ | ไลก์ | เวลา | การตอบกลับ |
|---|---|---|---|---|
| @user_abc | "ฉันลองแล้ว ใช้งานได้จริง 😂" | 1,200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "คราวหน้าลองใส่กระเทียมดู เชื่อผม" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "นี่แหละคอนเทนต์ที่ฉันรอ" | 340 | 2026-03-16T11:30:00Z | 2 |
ได้จาก: GitHub scrapers (TikTok-Api, Evil0ctal), (field มี text, like_count, reply_count, create_time), Thunderbit (จากส่วนคอมเมนต์ที่มองเห็นได้)
ข้อมูลแฮชแท็กและการค้นหา
| แฮชแท็ก | URL วิดีโอยอดนิยม | ยอดวิวรวม | กำลังมาแรง |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4,200,000 | ใช่ |
| #cooking | tiktok.com/@chef/video/321 | 11,000,000 | ใช่ |
| #hack | tiktok.com/@tips/video/654 | 2,900,000 | ไม่ |
ได้จาก: GitHub scrapers (แล้วแต่รีโป), Thunderbit ()
หมายเหตุ: ไม่มีรีโปไหนรับประกันว่าทุก field จะได้ครบทุกครั้ง โครงสร้าง response ของ TikTok เปลี่ยนได้ และแม้แต่ผู้ดูแลรีโปก็เตือนเรื่องนี้ไว้ ให้มองว่านี่คือตัวอย่างที่ใกล้เคียง ไม่ใช่สิ่งที่การันตี
วิธีดึงข้อมูล TikTok ใน 2 คลิกด้วย Thunderbit (ทีละขั้น)
เบื่อวงจรแก้แล้วพังแล้วใช่ไหม? นี่คือทาง no-code — ทางหนีสำหรับทุกคนที่เคยลองรีโป GitHub แล้วไม่สำเร็จ
- ติดตั้ง
- เปิดหน้าของ TikTok ที่ต้องการดึงข้อมูล — อาจเป็นโปรไฟล์ หน้าผลการค้นหา หน้าแฮชแท็ก หรือวิดีโอแต่ละชิ้น
- คลิก "AI Suggest Fields" AI ของ Thunderbit จะอ่านหน้าและเสนอคอลัมน์ เช่น ชื่อผู้ใช้ ผู้ติดตาม คำบรรยายวิดีโอ ไลก์ แฮชแท็ก ฯลฯ
- ปรับ field ถ้าจำเป็น แล้วคลิก "Scrape" ข้อมูลจะถูกเติมลงในตารางแบบมีโครงสร้าง
- ใช้ Subpage Scraping เพื่อเพิ่มความสมบูรณ์ของข้อมูล คลิกเข้าไปยังแต่ละวิดีโอจากรายการโปรไฟล์ แล้วดึง field เพิ่มเติม เช่น คำบรรยายเต็ม รายละเอียดเพลง จำนวนคอมเมนต์ จำนวนแชร์
- ส่งออกไป Google Sheets, Excel, Airtable หรือ Notion — ฟรีทั้งหมด
ไม่ต้องดูแล ไม่ต้องติดตั้งให้วุ่นวาย ไม่ต้องตั้งค่า anti-ban AI ปรับตามการเปลี่ยนเลย์เอาต์ของ TikTok ให้อัตโนมัติ
เพิ่มความสมบูรณ์ให้ข้อมูล TikTok ด้วย Subpage Scraping
หลังดึงรายการวิดีโอจากหน้าโปรไฟล์หรือหน้าแฮชแท็กแล้ว คลิก "Scrape Subpages" ให้ AI เปิดแต่ละหน้าวิดีโอแล้วดึง field เพิ่มเติม วิธีนี้เหมาะมากสำหรับนักการตลาดที่สร้างฐานข้อมูลอินฟลูเอนเซอร์หรือทำ audit คอนเทนต์คู่แข่ง — คุณจะได้ตารางข้อมูลการมีส่วนร่วมระดับวิดีโอแบบครบถ้วน โดยไม่ต้องกดเข้าออกหลายสิบหน้าเอง
การส่งออกและนำข้อมูล TikTok ไปใช้
Thunderbit ส่งออกไป Google Sheets, Excel, Airtable, Notion, CSV หรือ JSON ได้ฟรีทั้งหมด use case ที่พบบ่อย:
- นำข้อมูลไปใส่สเปรดชีตเพื่อวิเคราะห์ engagement
- ส่งเข้า Airtable เพื่อทำตัวติดตามอินฟลูเอนเซอร์แบบ CRM
- ดันเข้า Notion เพื่อให้ทีมทำงานร่วมกันบนงานวิจัยคอนเทนต์
ถ้าอยากเข้าใจลึกขึ้นว่า Thunderbit จัดการการดึงข้อมูลเว็บอย่างไร ลองดู หรือดูวิดีโอสอนบน
อยู่ให้ถูกกฎหมาย: ข้อกำหนดการใช้งานของ TikTok และการปฏิบัติตามข้อบังคับเรื่องการ scrape
จุดยืนทางกฎหมายของ TikTok ชัดเจน บล็อกความเป็นส่วนตัวของแพลตฟอร์มเกี่ยวกับการ scrape ว่า Terms of Service ห้ามสคริปต์อัตโนมัติที่เก็บข้อมูลหรือโต้ตอบกับบริการในทางที่ไม่ได้รับอนุญาต และระบุชัดว่าห้ามหลีกเลี่ยงข้อจำกัดในการเข้าถึง ของ TikTok ก็ห้ามความพยายามหลอกลวงเพื่อเข้าถึงข้อมูลผ่านสคริปต์อัตโนมัติหรือ web crawling เช่นกัน
แนวทางปฏิบัติจริง:
- ยึดเฉพาะข้อมูลที่เปิดเผยสาธารณะ อย่า scrape เนื้อหาส่วนตัวหรือเนื้อหาที่ต้องล็อกอิน
- เคารพ rate limit อย่ายิงเซิร์ฟเวอร์ TikTok ถี่เกินไป
- ปฏิบัติตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล GDPR และ CCPA ยังมีผล ถ้าคุณเก็บ จัดเก็บ หรือวิเคราะห์ข้อมูลส่วนบุคคล
- ใช้ Research API เมื่อมีสิทธิ์ นี่คือทางที่ปลอดภัยที่สุดในมุม compliance
- นี่ไม่ใช่คำแนะนำทางกฎหมาย ปรึกษาผู้เชี่ยวชาญสำหรับกรณีของคุณโดยเฉพาะ
อ่านภาพรวมกฎหมายเพิ่มเติมได้ที่คู่มือ
ต้องทำอย่างไรเมื่อ GitHub Repo ของ TikTok Scraper ตาย
สรุปแบบสั้น:
- รันเช็กลิสต์ Repo Vitals 60 วินาทีเสมอ ก่อน clone TikTok scraper ใด ๆ จาก GitHub รีโปส่วนใหญ่ตายไปแล้ว
- เข้าใจตัวเลือกของคุณ API ทางการ, GitHub scrapers และเครื่องมือ no-code ต่างก็เหมาะกับผู้ใช้และ use case คนละแบบ
- ถ้าจะไปทาง GitHub ให้เผื่อเวลาสำหรับการแก้ปัญหาติดตั้งและตั้งค่า anti-ban ไว้ด้วย เตรียมรับงานดูแลต่อเนื่อง
- รู้ก่อนว่าจะได้ข้อมูลอะไรจริง ๆ ก่อนตัดสินใจใช้เครื่องมือ ดู field ที่ออกมา ไม่ใช่ดูแค่จำนวนดาว
- ถ้าคุณไม่ใช่นักพัฒนา (หรือเบื่อรีโปพัง ๆ) ลองใช้เครื่องมือ no-code อย่าง — สองคลิก ข้อมูลมีโครงสร้าง ส่งออกฟรี
ข้อมูล TikTok ที่คุณต้องการเข้าถึงได้อยู่แล้ว คำถามคือคุณอยากใช้เวลาไปกับการดูแล scraper หรือเอาเวลาไปใช้ข้อมูลจริง เลือกแนวทางที่เหมาะกับทักษะและ use case ของคุณ แล้วอย่าให้รีโป GitHub ที่ตายแล้วมาขโมยช่วงบ่ายของคุณไปอีก
คำถามที่พบบ่อย
มี TikTok scraper บน GitHub ที่ยังใช้ได้ในปี 2026 ไหม?
มี แต่มีน้อยมาก เป็นตัวเลือกโอเพนซอร์สที่น่าเชื่อถือที่สุดและยังมีการดูแลอยู่ ณ เดือนเมษายน 2026 ก็ยังอยู่แต่ซับซ้อนกว่า รีโปที่ได้ดาวสูงสุดอย่าง drawrowfly/tiktok-scraper ไม่ได้อัปเดตตั้งแต่พฤษภาคม 2023 และแทบถือว่าตายแล้ว รัน Repo Vitals Checklist เสมอก่อนใช้เวลาไปกับรีโปใด ๆ
การ scrape TikTok ถูกกฎหมายไหม?
Terms of Service ของ TikTok ห้ามการ scrape อัตโนมัติอย่างชัดเจน ข้อมูลที่มองเห็นสาธารณะอยู่ในพื้นที่สีเทาทางกฎหมายซึ่งต่างกันไปตามเขตอำนาจศาล ทางที่ปลอดภัยที่สุดคือใช้ แบบทางการสำหรับผู้วิจัยที่มีสิทธิ์ ถ้าคุณ scrape ข้อมูลสาธารณะ ให้ยึดเฉพาะคอนเทนต์ที่เข้าถึงได้แบบสาธารณะ เคารพ rate limit และปฏิบัติตาม GDPR/CCPA นี่ไม่ใช่คำแนะนำทางกฎหมาย — ควรปรึกษาผู้เชี่ยวชาญตามสถานการณ์ของคุณ
ฉัน scrape TikTok ได้ไหมโดยไม่ต้องเขียนโค้ด?
ได้ เครื่องมือ AI บนเบราว์เซอร์อย่าง ช่วยให้คุณดึงข้อมูล TikTok แบบมีโครงสร้าง (โปรไฟล์ metadata วิดีโอ แฮชแท็ก ตัวชี้วัด engagement) ได้โดยไม่ต้องเขียนโค้ดเลย TikTok Research API ก็ต้องเขียนโค้ดเพียงเล็กน้อยสำหรับผู้สมัครที่ได้รับอนุมัติ สำหรับคนไม่ใช่นักพัฒนา เครื่องมือ no-code คือทางที่เร็วและเชื่อถือได้ที่สุด
TikTok scraper ดึงข้อมูลอะไรได้บ้าง?
ชนิดข้อมูลที่พบบ่อย ได้แก่ ข้อมูลโปรไฟล์ (ชื่อผู้ใช้ ผู้ติดตาม ประวัติ สถานะยืนยันตัวตน), metadata วิดีโอ (คำบรรยาย ยอดวิว ไลก์ คอมเมนต์ แชร์ เพลง แฮชแท็ก ระยะเวลา วันที่โพสต์), คอมเมนต์ (ข้อความ ไลก์ เวลา การตอบกลับ), และข้อมูลแฮชแท็ก/การค้นหา (วิดีโอยอดนิยม ยอดวิวรวม สถานะกำลังมาแรง) ฟิลด์จริงขึ้นอยู่กับเครื่องมือและวิธีที่ใช้ — ดูตัวอย่างผลลัพธ์ด้านบนเพื่อรายละเอียด
ทำไม TikTok scraper ของฉันถึงโดนบล็อกอยู่เรื่อย ๆ?
TikTok ใช้ระบบป้องกันบอทหลายชั้น: การจำกัดอัตรา request, การบังคับใช้ cookie/session, browser fingerprinting, การตรวจจับพฤติกรรม, พารามิเตอร์ request ที่เข้ารหัส และ CAPTCHA สาเหตุที่พบบ่อยของการถูกบล็อก ได้แก่ ส่ง request เร็วเกินไป ใช้ session ใหม่สะอาดทุกครั้ง รัน headless browser ด้วย fingerprint ค่าเริ่มต้น หรือใช้ datacenter proxy ดูส่วนแนวปฏิบัติ anti-ban ด้านบนสำหรับวิธีแก้ฟรีและแบบเสียเงิน