
สัปดาห์ก่อน ผู้ใช้คนหนึ่งส่งข้อความมาหาเราว่า: "ผมต้องการราคา คำอธิบาย และข้อมูลตัวแปรสินค้าจากร้าน Shopify ของคู่แข่ง 14 ร้าน — ก่อนวันศุกร์" นั่นหมายถึงประมาณ 4,000 หน้าโปรดักต์ ถ้าจะให้ก็อปปี้วางทีละหน้าก็คงไม่ไหวแน่
ถ้าคุณเคยพยายามดึงข้อมูลสินค้าออกจากร้าน Shopify ไม่ว่าจะเป็นราคา รูปภาพ คำอธิบาย ตัวแปร รีวิว คุณจะรู้ดีว่ามันชวนปวดหัวแค่ไหน ปัจจุบันมี ในปี 2026 และไม่มีร้านไหนมีปุ่ม "ส่งออกสำหรับคนนอก" ให้คุณเลย ขณะเดียวกัน บอกว่าพวกเขาติดตามราคาคู่แข่งอย่างจริงจัง และผู้ให้บริการด้านอีคอมเมิร์ซรายงานว่าการอัปโหลดสินค้าเพียงชิ้นเดียวที่มีทั้งตัวแปรและรูปภาพอาจใช้เวลา คูณเข้าไปกับสินค้าหลายร้อยรายการ แล้วคุณจะเสียเวลาทั้งสัปดาห์ไปเลย
นั่นจึงเป็นเหตุผลที่ส่วนขยาย Chrome สำหรับ Shopify scraper กลายเป็นเครื่องมือมาตรฐานในชุดอุปกรณ์อีคอมเมิร์ซ — ใช้ได้ทั้งวิจัยคู่แข่ง หาโอกาส dropshipping ย้ายแค็ตตาล็อก และอีกมากมาย แต่บทความ "scraper ที่ดีที่สุด" ส่วนใหญ่ก็มักแค่ลิสต์ฟีเจอร์ โดยไม่แสดงให้เห็นว่าพอเอาไปใช้กับร้าน Shopify จริงแล้วเกิดอะไรขึ้น บทความนี้ต่างออกไป ผมทดสอบส่วนขยาย 8 ตัวกับหน้าร้านจริง เจอกำแพงกันบอทจริง และดูให้ชัดว่าเครื่องมือไหนดึงข้อมูลสินค้าเชิงลึกที่คุณต้องการได้จริง — และตัวไหนหยุดอยู่แค่ผิวเผิน
ทำไมทีมอีคอมเมิร์ซถึงต้องใช้ส่วนขยาย Chrome สำหรับ Shopify Scraper
ร้าน Shopify คือขุมทรัพย์ของข้อมูลสินค้าเชิงพาณิชย์ แต่ถ้าคุณเป็นคนนอก คุณจะไม่ได้ไฟล์ CSV มาโหลดตรง ๆ คุณได้แค่หน้าร้าน ดังนั้นถ้าจะเปลี่ยนหน้าร้านนั้นให้เป็นอินไซต์ที่ใช้งานได้จริง คุณต้องมี scraper — และกรณีใช้งานมันไกลกว่าการบอกว่า "อยากได้รายชื่อสินค้า" เยอะมาก
คำถามจริง ๆ คือ: คุณต้องการข้อมูลอะไร และจะเอาไปใช้ในเวิร์กโฟลว์แบบไหน? นี่คือการจับคู่กรณีใช้งานอีคอมเมิร์ซที่พบบ่อยกับฟิลด์ข้อมูลที่ต้องใช้:
การวิจัยราคาคู่แข่ง
คุณต้องการ: ชื่อสินค้า ราคา ราคาเปรียบเทียบก่อนลด และราคาตามตัวแปรสินค้า ข้อมูลพวกนี้คือหัวใจของกลยุทธ์ตั้งราคาแบบไดนามิก — ไม่ใช่แค่รู้ว่าคู่แข่งคิดราคาเท่าไร แต่รู้ด้วยว่าพวกเขาลดราคา จัดชุด หรือแยกราคาอย่างไรตามไซซ์หรือสี
การค้นหาสินค้าสำหรับ Dropshipping
คุณต้องการ: ชื่อสินค้า รูปภาพทั้งหมด (ไม่ใช่แค่ภาพย่อ) คำอธิบายเต็ม และวันที่เผยแพร่ การเรียงตามวันที่เผยแพร่ล่าสุดช่วยให้คุณเจอสินค้าที่กำลังมาแรงหรือเพิ่งเปิดตัว ก่อนที่ตลาดจะอิ่มตัว
การนำเข้าคา็ตตาล็อกเข้าสู่ร้านของคุณเอง
คุณต้องการ: ชื่อสินค้า HTML เนื้อหา รูปภาพทั้งหมด ตัวแปรสินค้า SKU และราคา — ในอุดมคติควรอยู่ใน ไม่ใช่ทุกเครื่องมือจะสร้างไฟล์แบบนี้ได้สะอาดพอดี
การประมาณความเร็วในการขาย
คุณต้องการ: ชื่อสินค้าและจำนวนสต็อกที่ติดตามตามเวลา โดยการบันทึกระดับสต็อกเป็นช่วงเวลา คุณสามารถประมาณได้ว่าคู่แข่งขายสินค้าออกเร็วแค่ไหน — แม้จะเป็นตัวชี้วัดคร่าว ๆ แต่ก็มีประโยชน์มากเมื่อไม่มีข้อมูลยอดขายตรง ๆ
การหาลีด (หาเจ้าของร้าน)
คุณต้องการ: ชื่อร้าน อีเมลติดต่อ หมายเลขโทรศัพท์ และบางครั้งรวมถึงแอปหรือสแต็กเทคโนโลยีที่ร้านใช้อยู่ ทีมขายใช้ข้อมูลนี้เพื่อสร้างลิสต์ outreach ที่แบ่งตามกลุ่มธุรกิจหรือเทคโนโลยี
นี่คือสรุปแบบเร็ว:
| กรณีใช้งาน | ฟิลด์ข้อมูลสำคัญที่ต้องมี | เวิร์กโฟลว์ที่แนะนำ |
|---|---|---|
| วิจัยราคาคู่แข่ง | ชื่อสินค้า ราคา ราคาเปรียบเทียบก่อนลด ราคาตามตัวแปร | ดึงข้อมูลหน้ารายการ + เพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า |
| ค้นหาสินค้าสำหรับ dropshipping | ชื่อสินค้า ราคา รูปภาพทั้งหมด คำอธิบาย วันที่เผยแพร่ | ดึงข้อมูลจากหน้าสินค้า + เรียงตามวันที่เผยแพร่ล่าสุด |
| นำเข้าคา็ตตาล็อกเข้าสู่ร้านของคุณ | ชื่อสินค้า HTML เนื้อหา รูปภาพ ตัวแปร SKU ราคา | ดึงข้อมูลครบทุกหน้าสินค้า → ส่งออกเป็น CSV สำหรับ Shopify |
| ประเมินยอดขาย | ชื่อสินค้า จำนวนสต็อก (ตามเวลา) | ตั้งเวลาดึงข้อมูล → ติดตามใน Google Sheets |
| การหาลีด (เจ้าของร้าน) | ชื่อร้าน อีเมล โทรศัพท์ แอปที่ใช้ | ดึงข้อมูลหน้าติดต่อร้าน + เครื่องมือดึงอีเมล/โทรศัพท์ |
ผมประเมินส่วนขยาย Chrome สำหรับ Shopify Scraper ทั้ง 8 ตัวนี้อย่างไร
ผมติดตั้งส่วนขยายทั้ง 8 ตัว แล้วทดสอบกับร้าน Shopify จริงชุดเดียวกัน — รวมทั้งร้านสาธารณะ ร้านที่มี Cloudflare ป้องกัน และร้านที่ปิด products.json ไว้ ผมไม่ได้ดูแค่รายการฟีเจอร์ ผมอยากเห็นว่าพอกด "scrape" บนหน้า collection ของ Shopify จริง ๆ แล้วเกิดอะไรขึ้น
นี่คือ 8 เกณฑ์ที่ผมใช้ และเหตุผลว่าทำไมแต่ละข้อถึงสำคัญกับ Shopify โดยเฉพาะ:
| เกณฑ์ | ทำไมถึงสำคัญกับการดึงข้อมูล Shopify |
|---|---|
| ความง่ายในการตั้งค่า | คนที่ไม่ถนัดเทคนิคจะเริ่มดึงข้อมูลได้ภายใน 5 นาทีไหม? |
| ฟิลด์ข้อมูลที่ดึงได้ | ดึงได้แค่ชื่อ ราคา รูปภาพ คำอธิบาย ตัวแปรสินค้า และรีวิว หรือได้แค่ข้อมูลผิวเผิน? |
| การเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า | ดึงข้อมูลจากหน้ารวมสินค้าแล้วไปเปิดหน้าสินค้าแต่ละชิ้นอัตโนมัติเพื่อเก็บรายละเอียดครบได้ไหม? |
| การจัดการ Pagination | ดึงข้อมูลเกินหน้าสินค้าหน้าแรกได้ไหม (คลิก pagination หรือเลื่อนแบบ infinite scroll)? |
| ความทนต่อบอท | รับมือ Cloudflare Turnstile หรือระบบป้องกันบอทของ Shopify ได้โดยไม่พังไหม? |
| รูปแบบการส่งออก | CSV, Excel, Google Sheets, Airtable, Notion, ไฟล์ CSV ที่พร้อมนำเข้า Shopify ได้ไหม? |
| การดึงข้อมูลตามกำหนดเวลา | มอนิเตอร์ราคา หรือการเปลี่ยนแปลงสต็อกอัตโนมัติได้ไหม? |
| ความชัดเจนด้านราคา | ข้อจำกัดแพ็กฟรี ระบบเครดิต ค่าบริการแบบเหมาจ่าย — และคุณได้อะไรจริง ๆ |
เมื่อมีกรอบประเมินแบบนี้แล้ว มาดูกันว่าแต่ละเครื่องมือทำผลงานได้อย่างไร
1. Thunderbit — AI Shopify Scraper ที่สร้างมาเพื่อคนไม่เขียนโค้ด
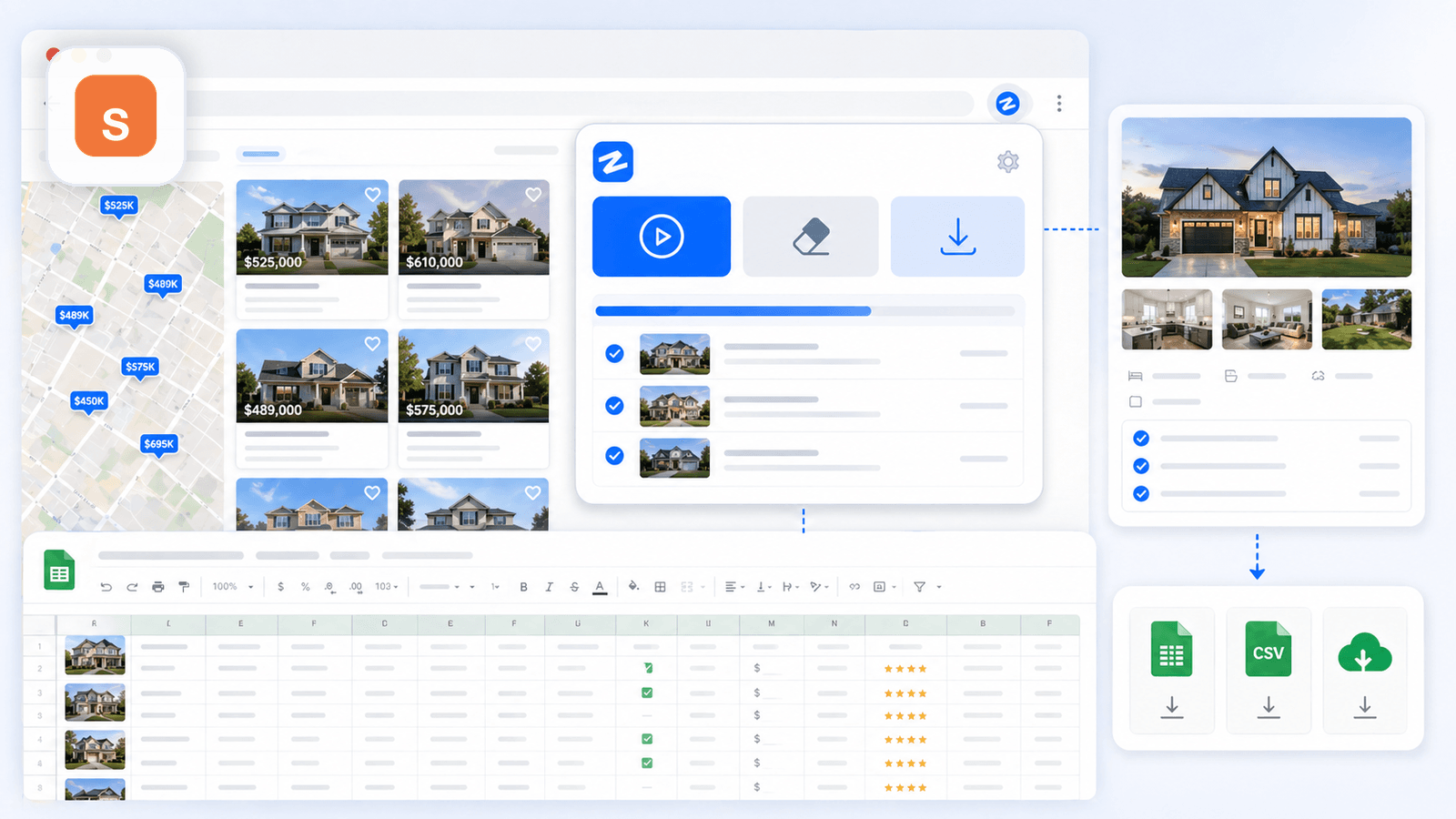
คือเครื่องมือที่เราสร้างขึ้นที่ Thunderbit สำหรับผู้ใช้สายธุรกิจที่ต้องการข้อมูลสินค้าเชิงลึก โดยไม่ต้องเขียนโค้ด ตั้งค่า CSS selector หรือเสียเวลาเตรียมระบบ 20 นาที เวิร์กโฟลว์บนร้าน Shopify ง่ายจริง ๆ แค่ 2 คลิก: เปิดหน้า collection กด "AI Suggest Fields" แล้ว AI จะอ่านหน้าและเสนอคอลัมน์ให้ เช่น ชื่อสินค้า ราคา รูปภาพ ฯลฯ จากนั้นกด "Scrape" เท่านี้ก็จบสำหรับหน้ารวมสินค้า
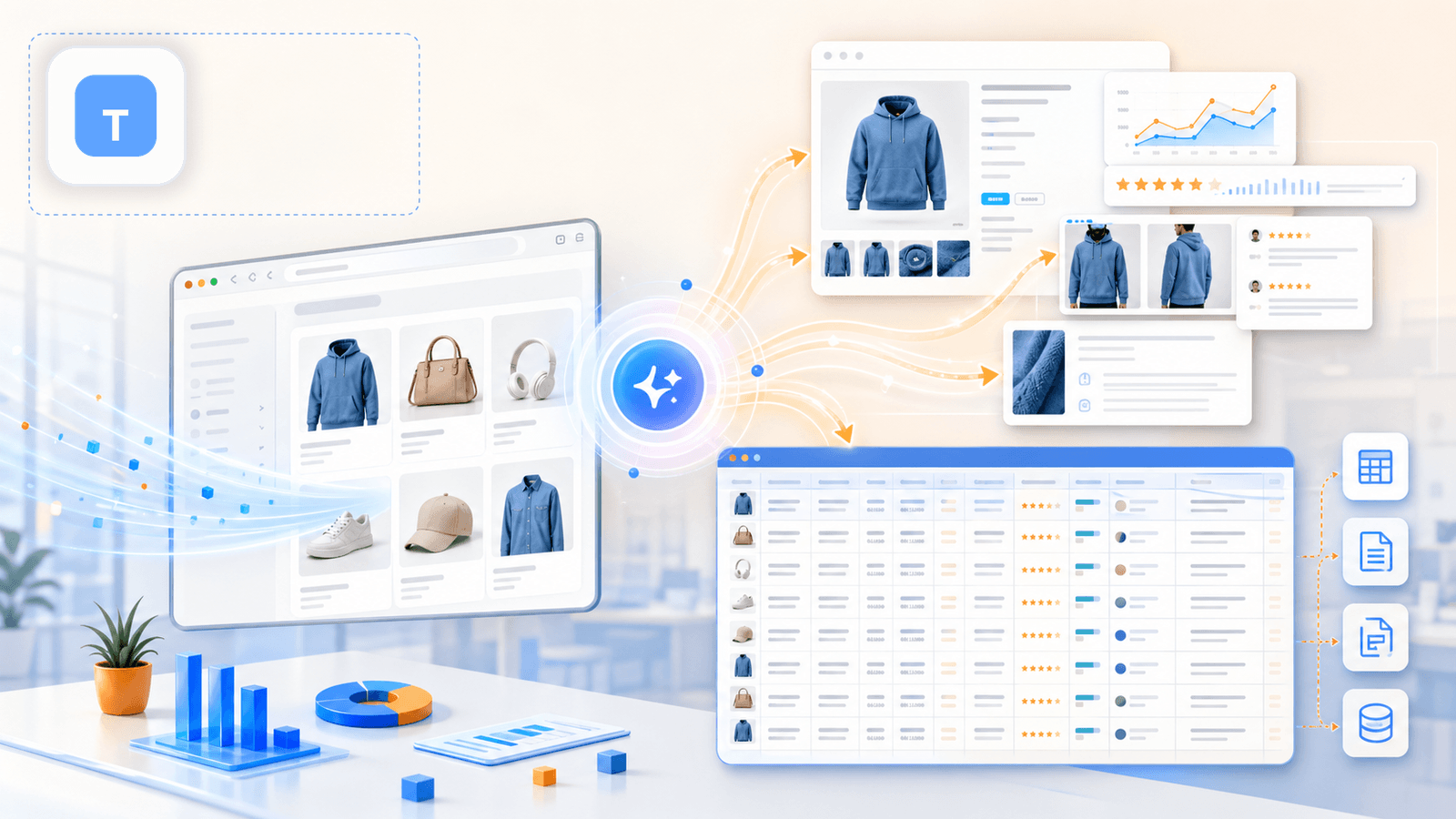
แต่จุดต่างจริง ๆ — และเป็นสิ่งที่บทความคู่แข่งส่วนใหญ่มองข้าม — คือขั้นตอนถัดไป
การเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า: ฟีเจอร์ที่เปลี่ยนทุกอย่าง
หลังจากดึงข้อมูลจากหน้ารวมสินค้าแล้ว คุณกด "Scrape Subpages" ได้เลย AI ของ Thunderbit จะไปเปิด URL ของสินค้าทุกชิ้น แล้วต่อข้อมูลจากหน้ารายละเอียดเข้ากับตารางเดิมของคุณ: คำอธิบายเต็ม รูปภาพแกลเลอรีทั้งหมด ตัวเลือกตัวแปร SKU จำนวนรีวิว และอีกมากมาย นี่คือขั้นตอนที่เปลี่ยนสเปรดชีตแบบตื้น ๆ ให้กลายเป็นชุดข้อมูลวิจัยคู่แข่งที่ใช้งานได้จริง
ผมจะอธิบายเพิ่มเติมว่าทำไมเรื่องนี้ถึงสำคัญ (พร้อมตัวอย่างก่อน/หลัง) ในหัวข้อเฉพาะด้านล่าง
จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- AI Suggest Fields อ่านหน้า Shopify แล้วสร้างโครงสร้างคอลัมน์ที่เหมาะสมให้อัตโนมัติ — ไม่ต้องใช้ CSS selector ไม่ต้องตั้งค่าเอง
- การดึงข้อมูลจากหน้าสินค้าแต่ละหน้า เติมช่องว่างของข้อมูลที่หน้ารวมสินค้าไม่มี เช่น คำอธิบายเต็ม ตัวเลือกตัวแปร แกลเลอรีรูปภาพ และรีวิว
- โหมดดึงข้อมูลบนคลาวด์ สำหรับการดึงข้อมูลจำนวนมากจากร้านสาธารณะอย่างรวดเร็ว; โหมดดึงข้อมูลบนเบราว์เซอร์ สำหรับร้านที่มี Cloudflare ป้องกันหรือจำเป็นต้องล็อกอิน
- การจัดการ pagination ทั้งแบบคลิกและแบบเลื่อนต่อเนื่อง
- การดึงข้อมูลตามกำหนดเวลา สำหรับมอนิเตอร์ราคา/สต็อกต่อเนื่อง — อธิบายตารางเวลาเป็นภาษาธรรมดาได้เลย (เช่น "ทุกวันจันทร์ 9 โมงเช้า")
- เครื่องมือดึงอีเมลและโทรศัพท์ฟรี สำหรับกรณีใช้งานหา lead
- ส่งออกไปยัง Excel, Google Sheets, Airtable, Notion, CSV, JSON — รวมถึงรูปแบบที่เป็นมิตรกับการนำเข้า Shopify
- Field AI Prompt ให้คุณใส่คำสั่งพิเศษต่อคอลัมน์ได้ เช่น "จัดกลุ่มเป็น 3 ประเภทสินค้า" หรือ "แปลคำอธิบายเป็นภาษาอังกฤษ"
ข้อจำกัด
- ราคาแบบใช้เครดิตทำให้การดึงข้อมูลขนาดใหญ่มาก ๆ (สินค้าหลายหมื่นรายการ) ต้องใช้แพ็กเกจเสียเงิน
- การประมวลผลด้วย AI ใช้เวลาเพิ่มขึ้นไม่กี่วินาทีต่อแถว เมื่อเทียบกับ scraper แบบเทมเพลตบนหน้าที่เรียบง่ายมาก
ราคา
- แพ็กฟรี: 6 หน้า (หรือสูงสุด 10 หน้าพร้อมทดลองใช้ฟรี) ส่งออกฟรีทั้งหมด
- Starter: 500 เครดิต/เดือน
- Professional: เริ่มที่ 38 ดอลลาร์/เดือน (3,000 เครดิต) ไปจนถึง 249 ดอลลาร์/เดือน (20,000 เครดิต)
- กติกาเครดิต: 1 แถวผลลัพธ์ = 1 เครดิตสำหรับ web scraping; 1 แถวผลลัพธ์ = 2 เครดิตสำหรับ subpage scraping; การส่งออกฟรีเสมอ
เหมาะสำหรับ: ทีมอีคอมเมิร์ซที่ไม่ถนัดเทคนิคและต้องการข้อมูลสินค้า Shopify ที่ลึกที่สุด โดยตั้งค่าน้อยที่สุด — และอยากมอนิเตอร์คู่แข่งไปเรื่อย ๆ
2. Instant Data Scraper — ตัวเลือกอัตโนมัติแบบไม่ต้องตั้งค่า
Instant Data Scraper เป็นส่วนขยาย Chrome ฟรีที่ใช้อัลกอริทึมเชิงฮิวริสติกในการตรวจจับข้อมูลแบบตารางบนหน้าเว็บให้อัตโนมัติ ไม่มีการตั้งค่าใด ๆ เลย — เปิดหน้า collection ของ Shopify แล้วคลิกไอคอนส่วนขยาย มันจะพยายามตรวจจับและแสดงข้อมูลสินค้าเป็นตาราง
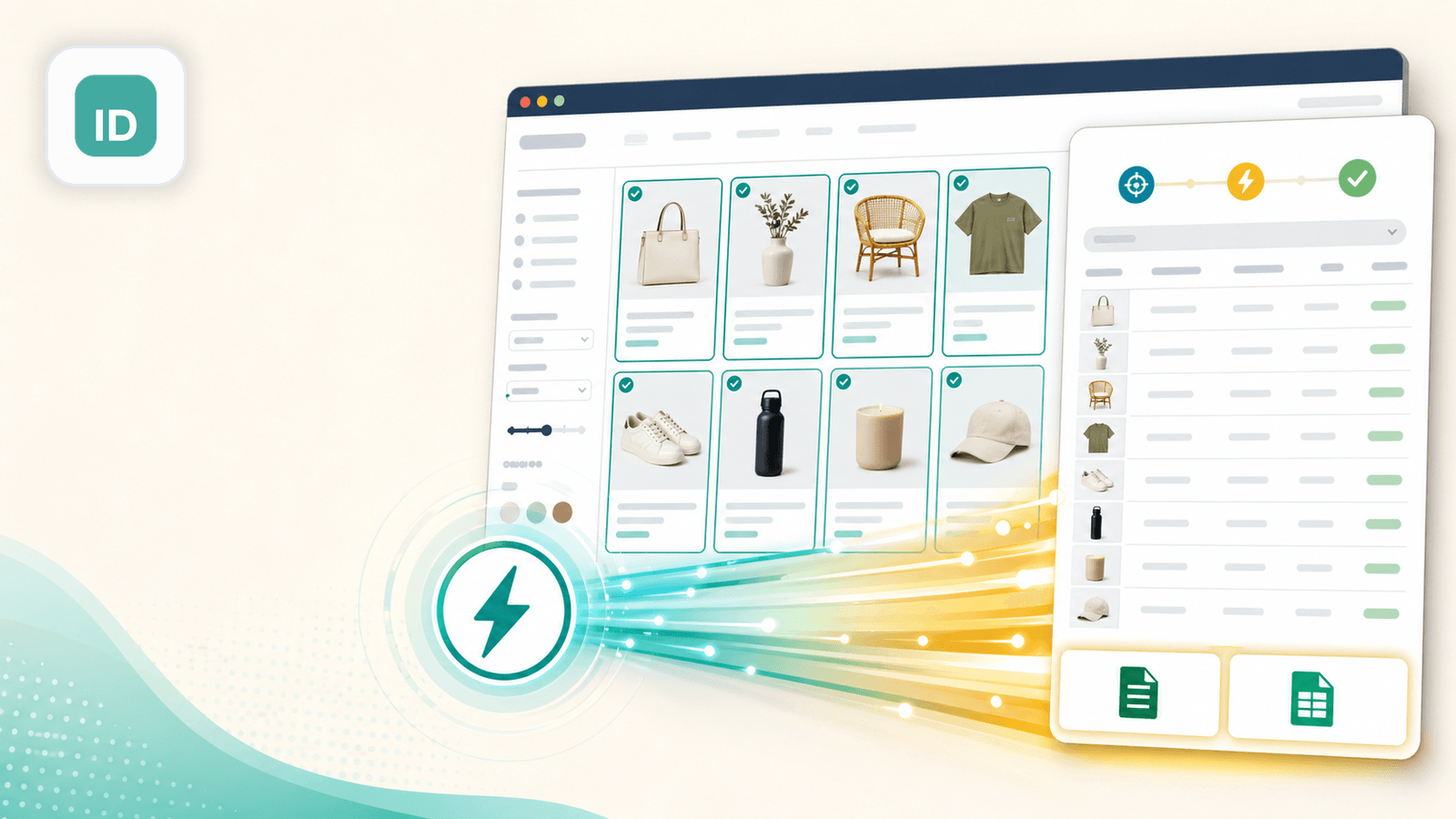
จากการทดสอบของผม มันทำงานได้ดีบนหน้า collection ของธีม Dawn มาตรฐานของ Shopify โดยดึงชื่อสินค้า ราคา และ URL รูปภาพย่อได้ภายในไม่กี่วินาที แต่ในร้านที่ใช้เลย์เอาต์ไม่มาตรฐาน บางครั้งมันจะดึงลิงก์นำทางหรือเนื้อหา footer มาแทนสินค้า คุณต้องดูผลลัพธ์ด้วยตาเองอีกที
จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- ฟรีทั้งหมด ไม่มีข้อจำกัดการใช้งาน
- การตรวจจับอัตโนมัติทำให้ใช้เวลาเตรียมแทบเป็นศูนย์ — เหมาะกับการส่งออกเร็ว ๆ แบบครั้งเดียว
- รองรับ pagination (กด "หน้าถัดไป" อัตโนมัติได้)
- ส่งออกเป็น CSV และ XLSX
ข้อจำกัด
- การตรวจจับอัตโนมัติเดาได้บ้างไม่ได้บ้างในร้าน Shopify ที่เลย์เอาต์ไม่มาตรฐาน
- ไม่มีการเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า: คุณจะได้แค่สิ่งที่อยู่บนหน้ารวมสินค้า (ชื่อ ราคา รูปย่อ) แต่ไม่ใช่คำอธิบายเต็ม ตัวแปร หรือรีวิว
- ไม่มี AI สำหรับทำความสะอาด ติดป้าย หรือแปลงข้อมูล
- ไม่มีการตั้งเวลา ไม่มีการดึงข้อมูลบนคลาวด์
- ไม่มีการส่งออกตรงไปยัง Google Sheets, Airtable หรือ Notion
ราคา
- ฟรีทั้งหมด
เหมาะสำหรับ: ใครก็ตามที่ต้องการส่งออกข้อมูลที่มองเห็นบนหน้ารวมสินค้าแบบเร็ว ฟรี และไม่ต้องตั้งค่า จากร้าน Shopify มาตรฐาน
3. Web Scraper — เครื่องมือสร้าง sitemap แบบภาพ
Web Scraper (webscraper.io) คือส่วนขยาย Chrome แบบคลิกเลือกบนหน้าจอคลาสสิกสำหรับการสร้าง "sitemap" — สูตรการดึงข้อมูลที่ให้คุณเลือกองค์ประกอบบนหน้าและกำหนดขั้นตอนการ scrape สำหรับ Shopify คุณจะสร้าง sitemap โดยคลิกที่ชื่อสินค้า ราคา รูปภาพ และกำหนดกฎสำหรับ pagination กับการตามลิงก์
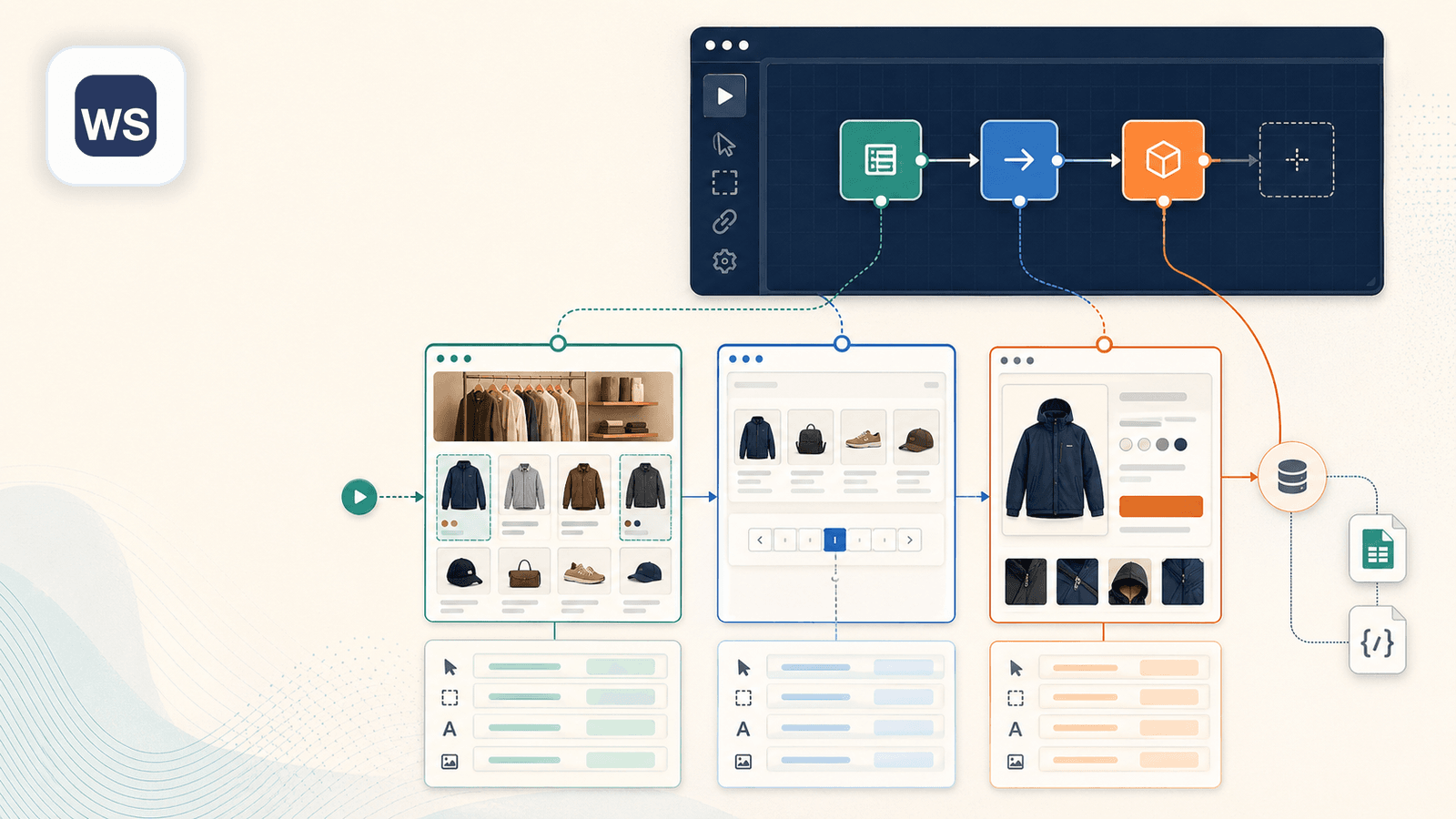
จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- ตัวสร้าง selector แบบภาพให้การควบคุมมากกว่าเครื่องมือ auto-detect
- ตามลิงก์ไปยังหน้าสินค้าแต่ละหน้าได้ — แต่ต้องตั้งค่า parent-child selector ใน sitemap เอง
- จัดการ pagination ได้เมื่อเซ็ตอัปถูกต้อง
- ดึงข้อมูลผ่านเบราว์เซอร์ฟรี มีแผน cloud แบบเสียเงิน (เริ่มที่ 50 ดอลลาร์/เดือน)
- ส่งออกเป็น CSV; แผน cloud รองรับ Google Sheets และรูปแบบอื่น ๆ
ข้อจำกัด
- การตั้งค่ากินเวลามากกว่า: การสร้าง sitemap ด้วย parent-child selector สำหรับร้าน Shopify ใหม่หนึ่งร้านใช้เวลาราว 15 นาที
- การดึงข้อมูลจากหน้าสินค้าแต่ละหน้าต้อง — ไม่ใช่การเพิ่มข้อมูลแบบคลิกครั้งเดียว
- sitemap จะพังเมื่อร้าน Shopify เปลี่ยนเลย์เอาต์หรือคลาส CSS
- เส้นโค้งการเรียนรู้ชันกว่าเครื่องมือที่ใช้ AI
ราคา
- ส่วนขยายเบราว์เซอร์: ฟรี
- แผน Cloud: Project 50 ดอลลาร์/เดือน, Professional 100 ดอลลาร์/เดือน, Scale เริ่มที่ 200 ดอลลาร์/เดือน
เหมาะสำหรับ: ผู้ใช้สายเทคนิคที่ต้องการคุมเวิร์กโฟลว์การดึงข้อมูลอย่างละเอียด และไม่ติดที่จะสร้างสูตรเอง
4. Data Miner — Scraper แบบใช้สูตร
Data Miner (dataminer.io) สร้างขึ้นรอบแนวคิด "recipe" — เทมเพลตการดึงข้อมูลที่มีอยู่แล้วหรือคุณสร้างเองแล้วนำมาใช้กับหน้าเว็บ มีคลังสูตรสาธารณะ คุณอาจเจอเทมเพลต Shopify ที่ผู้ใช้อื่นแชร์ไว้ หรือจะสร้างของตัวเองโดยเลือกองค์ประกอบบนหน้า
จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- คลัง recipe อาจมีเทมเพลต Shopify สำเร็จรูปที่ผู้ใช้อื่นแชร์ไว้
- ตัวสร้าง recipe แบบภาพสำหรับตั้งค่าการดึงข้อมูลเอง
- จัดการ pagination ได้ด้วยการตั้งค่าใน recipe
- ส่งออกเป็น CSV, Excel, Google Sheets และ TSV
- มีเวิร์กโฟลว์ crawl สำหรับเปิดหน้ารายละเอียดหลังจากหน้ารายการ
ข้อจำกัด
- แพ็กฟรีจำกัด 500 หน้า/เดือน
- สูตรใช้ CSS selector ซึ่งจะพังเมื่อเลย์เอาต์ร้านเปลี่ยน
- ไม่มี AI สำหรับแนะนำฟิลด์หรือแปลงข้อมูล
- ไม่มีเวิร์กโฟลว์เพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้าแบบคลิกครั้งเดียวในตัว — ต้องมี recipe แยกสำหรับหน้ารายละเอียด
- มี scheduled crawls แต่ไม่ได้เรียบง่ายที่สุด
ราคา
- ฟรี: 500 หน้า/เดือน
- Solo: 19.99 ดอลลาร์/เดือน
- Small Business: 49 ดอลลาร์/เดือน
- Business: 99 ดอลลาร์/เดือน
- Business Plus: 200 ดอลลาร์/เดือน
เหมาะสำหรับ: ผู้ใช้ที่ชอบทำงานกับเทมเพลต และอยากมีคลัง recipe ช่วยเร่งการตั้งค่าสำหรับเว็บไซต์ที่พบบ่อย
5. Simplescraper — เครื่องมือดึงข้อมูลเบา ๆ
Simplescraper (simplescraper.io) เป็นส่วนขยาย Chrome แบบเรียบง่ายและ scraper บนคลาวด์ที่เน้นความง่ายเป็นหลัก คุณคลิกที่องค์ประกอบข้อมูลบนหน้า Shopify แล้ว Simplescraper จะสร้าง CSS selector และดึงข้อมูลที่ตรงกันออกมา
จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- อินเทอร์เฟซสะอาด เรียบง่าย — เรียนรู้ได้เร็ว
- มี cloud scraping สำหรับงานตามกำหนดเวลาและงานปริมาณมาก
- มี API สำหรับนักพัฒนาที่อยากเชื่อมข้อมูลที่ดึงได้เข้ากับเวิร์กโฟลว์
- ส่งออกเป็น CSV, JSON, Google Sheets, Airtable และผ่าน webhooks
- มีแนวคิด deep scraping สำหรับตามลิงก์ไปยังหน้ารายละเอียด
- รองรับเวิร์กโฟลว์ที่ต้องล็อกอินสำหรับร้านที่ไวต่อเซสชัน
ข้อจำกัด
- เป็นแนวใช้ selector แบบ manual — ไม่มี AI ตรวจจับฟิลด์อัตโนมัติ
- การดึงข้อมูลจากหน้าสินค้าต้องตั้งค่าเพิ่ม
- ชุมชนน้อยกว่า และมีเทมเพลตสำเร็จรูปน้อยกว่า Web Scraper หรือ Data Miner
- แพ็กฟรี: 100 เครดิต (1 หน้าที่เรนเดอร์ด้วย JS = 2 เครดิต)
- ราคาแพ็กจ่ายเงินบนเว็บทางการไม่โปร่งใสเท่าคู่แข่งส่วนใหญ่
ราคา
- ฟรี: 100 เครดิต
- แพ็กจ่ายเงิน: แหล่งข้อมูลภายนอกรายงานว่า Plus ประมาณ 39 ดอลลาร์/เดือน, Pro ประมาณ 70 ดอลลาร์/เดือน, Premium ประมาณ 150 ดอลลาร์/เดือน (ตามข้อมูลราคาของ G2)
เหมาะสำหรับ: ผู้ใช้ที่อยากได้ cloud scraper แบบเบา ทันสมัย เชื่อมต่อได้ดี และไม่ต้องการการตรวจจับฟิลด์ด้วย AI
6. Octoparse — ส่วนขยาย Chrome ที่ขับเคลื่อนด้วยเดสก์ท็อป
Octoparse (octoparse.com) หลัก ๆ เป็นแอปเดสก์ท็อปที่มีส่วนขยาย Chrome คู่กัน มันมีทั้งตัวสร้างเวิร์กโฟลว์แบบภาพและเทมเพลตสำเร็จรูปสำหรับเว็บไซต์ยอดนิยม รวมถึงคู่มือการดึงข้อมูลเฉพาะ Shopify ด้วย

จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- มีเทมเพลต Shopify สำเร็จรูปสำหรับงานดึงข้อมูลที่พบบ่อย
- แอปเดสก์ท็อปทรงพลังพร้อมฟีเจอร์ขั้นสูง เช่น IP rotation, scheduled scraping, cloud extraction
- จัดการ pagination, infinite scroll และคอนเทนต์ที่โหลดด้วย AJAX ได้ดี
- เป็นตัวที่มีเอกสารรองรับการจัดการบอทดีที่สุดในรายการนี้ รวมถึงจัดการ CAPTCHA อัตโนมัติ
- ส่งออกเป็น CSV, Excel, JSON, HTML, XML, ฐานข้อมูล และ Google Sheets
ข้อจำกัด
- ถ้าใช้แค่ส่วนขยาย Chrome อย่างเดียว ความสามารถหลัก ๆ จะจำกัด — ฟีเจอร์แรง ๆ ส่วนใหญ่ต้องใช้แอปเดสก์ท็อป
- แอปเดสก์ท็อปมีเส้นโค้งการเรียนรู้ชันกว่า เพราะมีตัวสร้างเวิร์กโฟลว์แบบภาพ
- แพ็กฟรีมีข้อจำกัด; การใช้งานจริงจังต้องใช้แพ็กเสียเงิน
- ตั้งค่าหนักกว่าเครื่องมือที่เป็นส่วนขยาย Chrome ล้วน ๆ — ไม่เหมาะกับการ scrape เร็ว ๆ ภายใน 5 นาที
- แอปเดสก์ท็อปใช้ได้เฉพาะ Windows/Mac (ไม่ใช่เบราว์เซอร์ล้วน)
ราคา
- แผนฟรี มีให้ใช้
- Basic: 39 ดอลลาร์/เดือน
- Standard: ประมาณ 83 ดอลลาร์/เดือน (รายเดือน), ประมาณ 75 ดอลลาร์/เดือน (รายปี)
- Professional: ประมาณ 299 ดอลลาร์/เดือน (รายเดือน), ประมาณ 208 ดอลลาร์/เดือน (รายปี)
- Enterprise: กำหนดเอง
เหมาะสำหรับ: ทีมที่ต้องการการดึงข้อมูลระดับองค์กร พร้อม IP rotation, การจัดการบอท และงานคลาวด์แบบทำซ้ำได้ — และไม่ติดที่จะใช้แอปเดสก์ท็อป
7. Bardeen — เครื่องมือดึงข้อมูลที่เน้นอัตโนมัติเป็นหลัก
Bardeen (bardeen.ai) คือแพลตฟอร์มอัตโนมัติเบราว์เซอร์ที่รวมการดึงข้อมูลเว็บเข้ากับการทำงานอัตโนมัติ ผู้ใช้สร้าง "playbooks" ที่สามารถดึงข้อมูลแล้วส่งต่อไปยังแอปอื่น ๆ ได้ — ถ้าจะให้นึกง่าย ๆ ก็เหมือน "ถ้าฉันดึงข้อนี้มาแล้ว ให้ส่งเข้าระบบ CRM ของฉันต่อเลย"

จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- ทำอัตโนมัติได้มากกว่าการดึงข้อมูลอย่างเดียว: ดึงข้อมูล Shopify → เพิ่มความสมบูรณ์ → ส่งเข้า CRM หรือสเปรดชีตใน playbook เดียว
- เชื่อมกับแอปกว่า 100 ตัว (Google Sheets, Airtable, Notion, HubSpot, Slack ฯลฯ)
- มีฟีเจอร์ AI สำหรับการดึงและจัดประเภทข้อมูล
- ทำงานในเบราว์เซอร์ — ไม่ต้องใช้แอปเดสก์ท็อป
- ระบบอัตโนมัติตามเวลา/วันที่สำหรับตั้งตาราง
ข้อจำกัด
- เป็นเครื่องมืออัตโนมัติเป็นหลัก ไม่ใช่ scraper เฉพาะทาง — ฟีเจอร์ดึงข้อมูลจึงไม่ลึกเท่าเครื่องมือเฉพาะ
- การสร้าง playbook อาจสับสนสำหรับผู้ใช้ที่แค่อยากดึงรายชื่อสินค้า
- แพ็กฟรีจำกัด 100 เครดิต
- การเพิ่มข้อมูลจากหน้าสินค้าและการจัดการ pagination ไม่ได้ใช้งานง่ายเท่าเครื่องมือดึงข้อมูลเฉพาะทาง
- เกินความจำเป็น ถ้าคุณแค่ต้องการดึงข้อมูลโดยไม่ต้องทำอัตโนมัติปลายทาง
ราคา
- ฟรี: 100 เครดิต
- Basic: 10 ดอลลาร์/เดือน, 100 เครดิต/เดือน
- Premium: 50 ดอลลาร์/เดือน, 1,000 เครดิต/เดือน (ประมาณ 40 ดอลลาร์/เดือนเมื่อจ่ายรายปี)
- Enterprise: กำหนดเอง
- ระบบเครดิต: 1 เครดิตต่อหนึ่งแถว scraper, 3 เครดิตต่อหนึ่งแถว enrichment
เหมาะสำหรับ: ทีมที่อยากดึงข้อมูล Shopify แล้วส่งต่อเข้าแอปปลายทางทันที (CRM, สเปรดชีต, Slack) ในเวิร์กโฟลว์อัตโนมัติเดียว
8. Listly — ตัวแปลงรายการเป็นสเปรดชีต
Listly (listly.io) ถูกออกแบบมาโดยเฉพาะเพื่อแปลงลิสต์และตารางบนหน้าเว็บให้เป็นข้อมูลที่พร้อมใช้ในสเปรดชีต คลิกส่วนขยายบนหน้า collection ของ Shopify แล้ว Listly จะพยายามตรวจจับรายการสินค้าและส่งออกเป็นสเปรดชีต

จุดแข็งหลักสำหรับการดึงข้อมูล Shopify
- อินเทอร์เฟซเรียบง่ายมาก — ออกแบบมาสำหรับการดึงรายการแบบคลิกเดียว
- เก่งในการตรวจจับโครงสร้างรายการที่ซ้ำ ๆ กัน (เช่นกริดสินค้า)
- ส่งออกตรงไปยัง Excel และ Google Sheets
- มีฟีเจอร์ group scraping สำหรับประมวลผลหลาย URL พร้อมกัน
- มีการตั้งเวลาสำหรับแผน Business
ข้อจำกัด
- จำกัดแค่สิ่งที่ตรวจจับอัตโนมัติบนหน้า — ไม่มีการตั้งค่าฟิลด์แบบกำหนดเอง
- ไม่มีการเพิ่มข้อมูลจากหน้าสินค้า — ส่งออกได้แค่ข้อมูลระดับหน้ารวมสินค้า
- รับมือธีม Shopify ที่ไม่มาตรฐานหรือร้านที่เรนเดอร์ด้วย JavaScript หนัก ๆ ได้ไม่ดี
- แพ็กฟรีจำกัดมาก (10 URL/เดือน)
- ตัวเลือกการส่งออกน้อยกว่าคู่แข่ง (หลัก ๆ คือ Excel และ Sheets)
ราคา
- ฟรี: 10 URL/เดือน ดึงข้อมูลพื้นฐาน 1 หน้า ดาวน์โหลด Excel ส่งออก Google Sheet
- Light: 30 ดอลลาร์/เดือน (187.20 ดอลลาร์/ปี เมื่อจ่ายรายปี)
- Business: 90 ดอลลาร์/เดือน (993.60 ดอลลาร์/ปี เมื่อจ่ายรายปี) — เพิ่มการดึงข้อมูลขั้นสูง, group extraction, การตั้งเวลา, auto-scroll/click, API เบต้า
เหมาะสำหรับ: ผู้ใช้ที่ต้องการเส้นทางที่ง่ายที่สุดจากหน้า collection ของ Shopify ไปสู่สเปรดชีต — และไม่ได้ต้องการข้อมูลสินค้าเชิงลึก
เปรียบเทียบส่วนขยาย Chrome สำหรับ Shopify Scraper ทั้ง 8 ตัว
นี่คือเทียบกันแบบเต็ม ๆ ผมพยายามใส่ความเฉพาะเจาะจงในแต่ละช่องมากกว่าการติ๊กช่องเฉย ๆ — เพราะคำว่า "รองรับ pagination" หมายความต่างกันมากขึ้นอยู่กับเครื่องมือ
| เครื่องมือ | ความง่ายในการตั้งค่า | ฟิลด์ข้อมูล | การเพิ่มข้อมูลจากหน้าสินค้า | Pagination | การรับมือบอท | รูปแบบการส่งออก | การตั้งเวลา | แพ็กฟรี / ราคา |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | ง่ายมาก (AI นำทาง, 2 คลิก) | แข็งแกร่งที่สุดสำหรับผู้ใช้ไม่ถนัดเทคนิค (AI แนะนำฟิลด์ที่เกี่ยวข้องทั้งหมด) | มี — เพิ่มข้อมูลได้ในคลิกเดียว | มี (คลิก + infinite scroll) | คลาวด์สำหรับเว็บสาธารณะ, เบราว์เซอร์สำหรับเว็บที่ป้องกัน | Sheets, Airtable, Notion, CSV, JSON, Excel | มี (ตั้งเวลาภาษาอังกฤษธรรมดา) | ฟรี 6 หน้า; จ่ายเริ่ม 15 ดอลลาร์/เดือน |
| Instant Data Scraper | ง่ายมากสุด (ไม่ต้องตั้งค่า) | ดีสำหรับข้อมูลระดับหน้ารวมเท่านั้น | ไม่มี | มี (ตรวจจับหน้าถัดไปอัตโนมัติ) | ใช้เบราว์เซอร์เท่านั้น ไม่มีแนวทางรับมือบอท | CSV, XLSX | ไม่มี | ฟรี |
| Web Scraper | ปานกลาง-ยาก (สร้าง sitemap เอง) | ยืดหยุ่นถ้าสร้าง sitemap ดี | มี แต่ต้องตั้งค่าด้วยตัวเลือกเชื่อมโยง | มี (เมื่อกำหนดใน sitemap) | เบราว์เซอร์บนเครื่อง; หมุนพร็อกซีได้ในแผน cloud | CSV บนเครื่อง; บน cloud รองรับมากกว่า | มีในแผน cloud | ส่วนขยายฟรี; cloud เริ่ม 50 ดอลลาร์/เดือน |
| Data Miner | ปานกลาง (ใช้ recipe) | ดีถ้ามี recipe อยู่แล้วหรือสร้างได้ | มี แต่ต้องตั้ง crawl หลายขั้น | มี (ตั้งค่าใน recipe) | ส่วนใหญ่ทำงานฝั่งเบราว์เซอร์ | CSV, Excel, Sheets, TSV | มีงาน crawl อัตโนมัติ | ฟรี 500 หน้า/เดือน; จ่ายเริ่ม 19.99 ดอลลาร์/เดือน |
| Simplescraper | ง่าย-ปานกลาง (ใช้ selector) | เหมาะกับงานดึงข้อมูลเบา ๆ | มี deep scraping แต่ไม่ใช่คลิกเดียว | มี (รองรับ infinite scroll) | มีหมุนพร็อกซีและรองรับการล็อกอิน | CSV, JSON, Sheets, Airtable, webhooks | มี | ฟรี 100 เครดิต; มีแพ็กจ่ายเงิน |
| Octoparse | ยากกว่า (แอปเดสก์ท็อป) | แข็งแกร่งมากเมื่อเซ็ตอัปแล้ว | มี ผ่านเวิร์กโฟลว์หรือเทมเพลต | มี (AJAX, infinite scroll) | แข็งแกร่งที่สุดเรื่องกันบอท (IP rotation, CAPTCHA) | CSV, Excel, JSON, HTML, XML, DBs, Sheets | มีใน Standard ขึ้นไป | ฟรี; Basic 39 ดอลลาร์/เดือน; cloud เริ่มราว 83 ดอลลาร์/เดือน |
| Bardeen | ปานกลาง (ตัวสร้าง playbook) | ดีเมื่อผูกกับระบบอัตโนมัติ | ทำได้ในตรรกะเวิร์กโฟลว์ แต่ไม่ใช่แนว Shopify-first | ทำได้ | ทำงานในเบราว์เซอร์ การรับมือบอทไม่ใช่แกนหลัก | CSV, Sheets, Airtable, Notion | มีผ่านระบบอัตโนมัติ | ฟรี 100 เครดิต; Basic 10 ดอลลาร์/เดือน; Premium 50 ดอลลาร์/เดือน |
| Listly | ง่ายมาก (ตรวจจับรายการคลิกเดียว) | เหมาะที่สุดสำหรับแถวรายการที่มองเห็นบนหน้า | ไม่มี | จำกัดตามโครงสร้างรายการที่ตรวจจับได้ | ขั้นต่ำ | Excel, Sheets, CSV/JSON API บน Business | มีใน Business | ฟรี 10 URL/เดือน; Light 30 ดอลลาร์/เดือน; Business 90 ดอลลาร์/เดือน |
สรุปแบบเร็วตามลำดับความสำคัญ
ถ้าคุณต้องการ ข้อมูลสินค้า Shopify ที่ลึกที่สุดพร้อมการตั้งค่าน้อยที่สุด Thunderbit ที่มี AI + การเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า คือชุดที่แข็งแรงที่สุด ถ้าคุณต้องการ ส่งออกฟรีแบบเร็วและง่ายที่สุด Instant Data Scraper ใช้ได้กับหน้าธรรมดา ถ้าคุณต้องการ คุมได้เต็มมือและไม่ติดที่จะสร้างสูตรเอง Web Scraper หรือ Octoparse ให้พลังตรงนั้น และถ้าเป้าหมายจริงของคุณคือ ดึงข้อมูล → ทำอัตโนมัติ → ส่งเข้า CRM Bardeen คือแพลตฟอร์มเวิร์กโฟลว์ที่ควรดู
การดึงข้อมูลจากหน้ารวมสินค้าเป็นแค่ครึ่งเดียว: เวิร์กโฟลว์การเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า
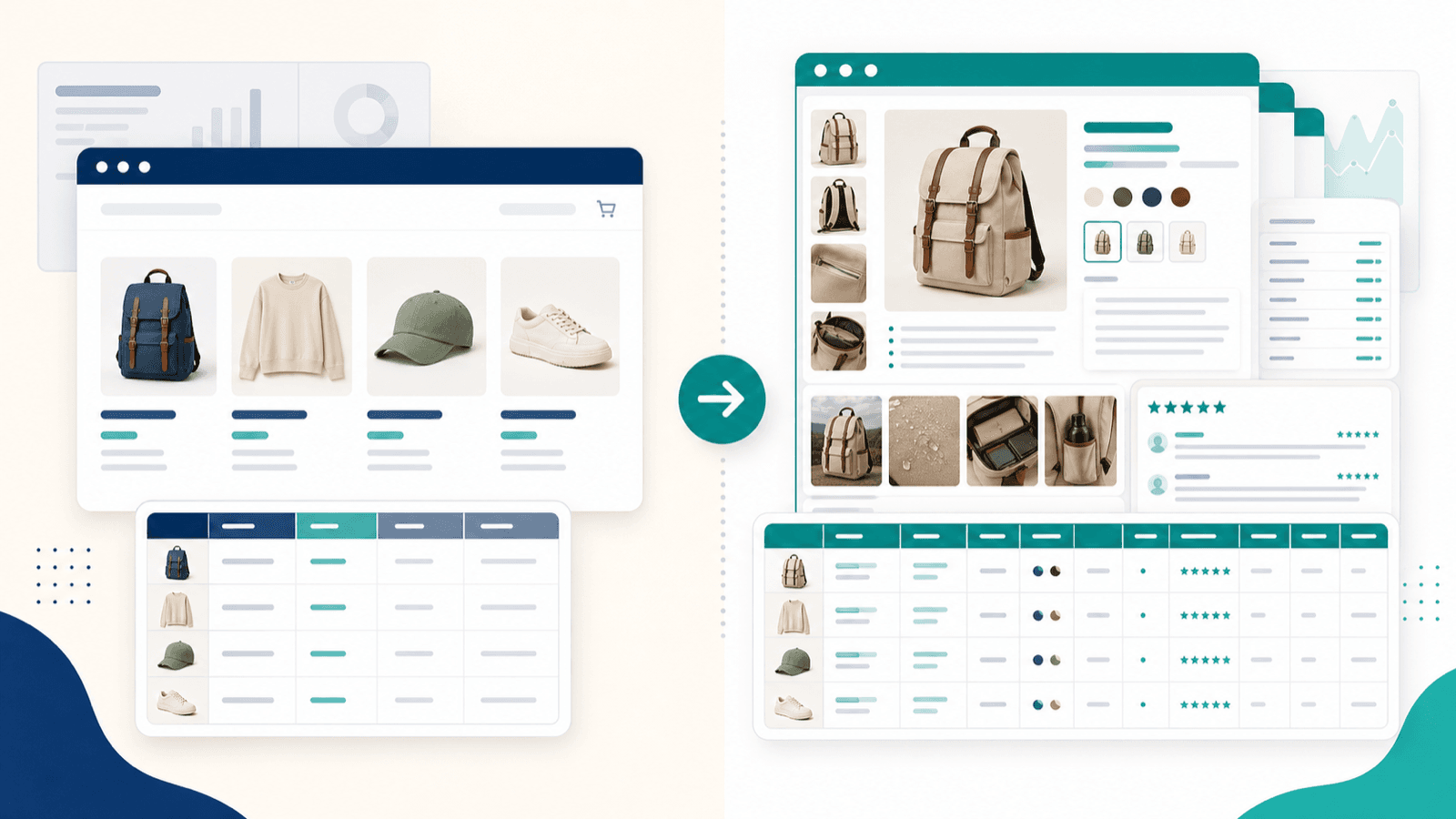
นี่คือหัวข้อที่ผมอยากให้บทความเกี่ยวกับ Shopify scraper ทุกชิ้นใส่ไว้ — เพราะนี่คือช่องว่างที่ใหญ่ที่สุดในคอนเทนต์ของคู่แข่ง และเป็นปัญหาอันดับ 1 ที่ผมได้ยินจากผู้ใช้อีคอมเมิร์ซ
เมื่อคุณดึงข้อมูลจากหน้า collection ของ Shopify (หน้ารวมสินค้า) คุณจะได้ข้อมูลระดับผิวเผิน: ชื่อ ราคา รูปย่อ บางทีก็คำอธิบายที่ถูกตัดทอน แต่ฟิลด์ที่คุณต้องใช้จริงสำหรับการวิเคราะห์คู่แข่ง นำเข้าคา็ตตาล็อก หรือวิจัย dropshipping จะอยู่บนหน้ารายละเอียดสินค้าทีละชิ้น
สิ่งที่ได้จากหน้ารวมสินค้า เทียบกับหลังเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า
| ฟิลด์ข้อมูล | จากหน้ารวมสินค้าอย่างเดียว | หลังเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า |
|---|---|---|
| ชื่อสินค้า | ✅ | ✅ |
| ราคา | ✅ | ✅ |
| รูปภาพย่อ | ✅ | ✅ + รูปแกลเลอรีทั้งหมด |
| คำอธิบายสั้น | ⚠️ ถูกตัดทอน | ✅ คำอธิบาย HTML ฉบับเต็ม |
| ตัวแปรสินค้า (ไซซ์, สี) | ❌ | ✅ |
| SKU / สต็อก | ❌ | ✅ |
| รีวิว / คะแนน | ❌ | ✅ |
ความต่างมันมหาศาล
การส่งออกแบบได้แค่หน้ารวมสินค้า จะได้สเปรดชีตตื้น ๆ แต่การส่งออกที่เพิ่มข้อมูลจากหน้าสินค้าแล้ว จะได้ชุดข้อมูลวิจัยคู่แข่งที่ใช้งานได้จริง
การดึงข้อมูลจากหน้าสินค้าแต่ละหน้าทำงานอย่างไรใน Thunderbit (ทีละขั้นตอน)
- ไปที่หน้า collection/หน้ารวมสินค้าของร้าน Shopify
- คลิก "AI Suggest Fields" — Thunderbit จะอ่านหน้าและเสนอคอลัมน์ให้ (ชื่อ ราคา รูปภาพ ลิงก์ ฯลฯ)
- คลิก "Scrape" เพื่อดึงข้อมูลจากหน้ารวมสินค้า
- คลิก "Scrape Subpages" — AI จะเปิด URL ของสินค้าทุกชิ้น แล้วต่อข้อมูลจากหน้ารายละเอียด (คำอธิบายเต็ม รูปภาพทั้งหมด ตัวแปร รีวิว) เข้ากับตารางเดิม
- ส่งออก ตารางที่เพิ่มข้อมูลแล้วไปยัง Excel, Google Sheets, Airtable, Notion หรือ CSV
กระบวนการทั้งหมดใช้เวลาไม่กี่นาทีสำหรับ collection ทั่วไป และสุดท้ายคุณจะได้ชุดข้อมูลที่ถ้าทำมือเองคงใช้เวลาหลายชั่วโมง
เครื่องมืออื่นรองรับการเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้าหรือไม่
- Web Scraper: มี แต่ต้องตั้งค่า sitemap เองด้วย link selector และ child sitemap — เฉลี่ยต้องใช้เวลาตั้งค่าร้านละ 15-20 นาที
- Octoparse: มี ผ่านตัวสร้างเวิร์กโฟลว์หรือเทมเพลต — ทรงพลังแต่ตั้งค่าหนัก
- Data Miner: มี ผ่านเวิร์กโฟลว์ crawl หลายขั้น — ไม่ใช่การคลิกครั้งเดียว
- Simplescraper: มีแนวคิด deep scraping แต่ไม่ใช่แบบพร้อมใช้ทันที
- Instant Data Scraper, Listly, Bardeen: ไม่มีเอกสารรองรับการเพิ่มข้อมูลจากหน้าสินค้าแบบคลิกครั้งเดียวสำหรับ Shopify
ความต่างระหว่าง "ทำได้ทางเทคนิคถ้าตั้งค่าเอง 20 นาที" กับ "เพิ่มข้อมูลได้ในคลิกเดียว" คือความต่างระหว่างเครื่องมือสำหรับสายวิศวกรรม scraper กับเครื่องมือสำหรับคนทำอีคอมเมิร์ซ
เมื่อ products.json ของ Shopify ใช้ไม่ได้ — และทำไมส่วนขยาย Chrome ถึงเป็นแผนสำรองของคุณ
ถ้าคุณเคยอ่านคู่มือการดึงข้อมูล Shopify อื่น ๆ คุณน่าจะเคยเห็นทริก /products.json คือแค่เติม /products.json ต่อท้าย URL ของร้าน Shopify แล้วคุณจะได้ข้อมูลสินค้าแบบโครงสร้างในรูป JSON มันเป็น endpoint จริง และใช้สะดวกมากเมื่อมันทำงานได้
products.json ทำงานอย่างไร
ร้าน Shopify เปิด ที่ /products.json ซึ่งคืนค่าข้อมูลสินค้าแบบมีโครงสร้าง คุณสามารถแบ่งหน้าได้ด้วย ?page=2&limit=250 (สูงสุด 250 สินค้าต่อหน้า)
ฟิลด์ที่มักได้กลับมาจะรวมถึง: title, body_html, vendor, product_type, tags, published_at, variants (พร้อม price, compare_at_price, sku, available) และ images
products.json ขาดอะไรไปบ้าง
- ไม่มีข้อมูลรีวิวหรือจำนวนคะแนน
- การจัดรูปแบบคำอธิบายมีจำกัดเมื่อเทียบกับหน้าเว็บที่เรนเดอร์แล้ว
- custom metafields มักไม่ถูกรวมมา
- รูปภาพระดับตัวแปรสินค้าอาจไม่สม่ำเสมอ
- ไม่มีคอนเทนต์การจัดวางสินค้า badges หรือ social proof ที่เรนเดอร์แล้ว
เมื่อ products.json พัง
ผมทดสอบ HTTP โดยตรงกับหน้าร้าน Shopify จริง 8 แห่งเมื่อวันที่ 27 เมษายน 2026 ผลลัพธ์น่าสนใจมาก:
| ร้าน | ผลลัพธ์ |
|---|---|
| kith.com | ✅ ใช้ได้ — JSON สะอาด |
| colourpop.com | ✅ ใช้ได้ |
| allbirds.com | ✅ ใช้ได้ |
| brooklinen.com | ✅ ใช้ได้ |
| negativeunderwear.com | ✅ ใช้ได้ |
| gymshark.com | ❌ ถูกบล็อก — ได้ HTML 403 แทน JSON |
| mvmt.com | ⚠️ ปิดบางส่วน — ได้หน้า HTML 200 ไม่ใช่ JSON |
| fashionnova.com | ❌ ปิดไว้ — 404 |
จาก 8 ร้าน มี 5 ร้านที่ส่ง JSON สะอาดกลับมา ส่วนอีก 3 ร้านไม่ส่ง
ผู้ใช้ในฟอรัมก็รายงานคล้ายกัน: "ด้วยเหตุผลบางอย่าง ร้าน Shopify บางร้านเลือกที่จะไม่เปิดให้ใช้ products.json" ร้านที่ต้องใส่รหัสผ่าน ร้านที่ตั้งค่า API เอง และโดเมนที่มี Cloudflare ป้องกัน ล้วนทำให้แพทเทิร์นนี้ใช้ไม่ได้
ทางเลือกสำรองด้วยส่วนขยาย Chrome
เมื่อ products.json ใช้ไม่ได้ scraper แบบส่วนขยาย Chrome จะดึงข้อมูลจากหน้าที่เรนเดอร์แล้วโดยตรง (DOM) นี่คือคุณค่าหลักของ scraper แบบเบราว์เซอร์: มันเห็นและดึงสิ่งที่คุณเห็นในเบราว์เซอร์ ไม่ว่ามี API ให้ใช้หรือไม่ก็ตาม ทำให้ส่วนขยาย Chrome เป็นแผน B ที่เชื่อถือได้ — และมักเป็นแผน A ด้วยซ้ำเมื่อคุณต้องการข้อมูลจากหน้าเรนเดอร์แล้ว เช่น รีวิว คอนเทนต์จัดวางสินค้า หรือแกลเลอรีรูปภาพเต็มชุด
การป้องกันบอท: อะไรเกิดขึ้นจริงเมื่อคุณดึงข้อมูลจากร้าน Shopify
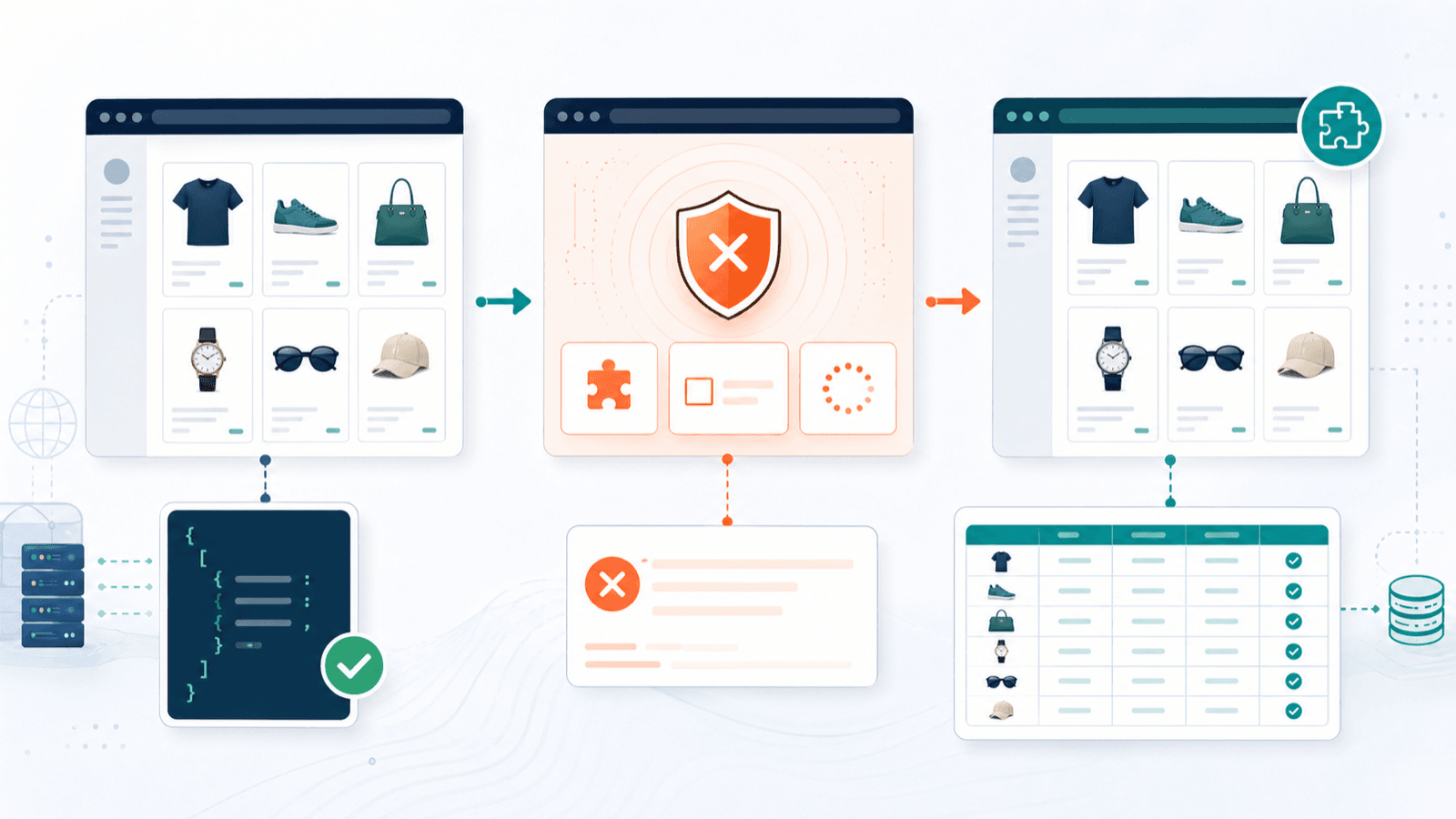
บทความ Shopify scraper ส่วนใหญ่มักทำเหมือนว่าทุกร้านเปิดโล่งหมด จริง ๆ ไม่ใช่เลย ว่า 99.2% ของร้าน Shopify ใช้โครงสร้างพื้นฐาน Cloudflare นั่นไม่ได้แปลว่าทุกร้านจะบล็อก scraper อย่างเข้มงวด แต่แปลว่าโครงสร้างสำหรับการบล็อกมีอยู่แทบทุกที่
ในทางปฏิบัติ ภาพรวมจะเป็นแบบนี้:
ดึงข้อมูลได้ง่าย
- ร้านสาธารณะที่ไม่ได้ป้องกันด้วย Cloudflare แบบเข้มงวด
- ร้านที่เปิด products.json ไว้
- ร้านที่ใช้ธีม Shopify มาตรฐาน (โครงสร้าง DOM สม่ำเสมอ)
ดึงข้อมูลยากขึ้น
- ร้านที่มี Cloudflare ป้องกัน (CAPTCHA, Turnstile)
- ร้านที่ต้องล็อกอินหรือใส่รหัสผ่าน
- ร้าน Shopify Plus ที่มีชั้นความปลอดภัยแบบกำหนดเอง
- ร้านที่จำกัดอัตราการเข้าถึงอย่างเข้ม
แต่ละเครื่องมือรับมือสถานการณ์กันบอทอย่างไร
| สถานการณ์ | แนวทางที่ดีที่สุด | เครื่องมือที่รับมือได้ |
|---|---|---|
| ร้านสาธารณะ ไม่มีการกันบอท | ดึงบนคลาวด์ (เร็ว) | Thunderbit (โหมดคลาวด์), Instant Data Scraper, และส่วนใหญ่ |
| ร้านที่ป้องกันด้วย Cloudflare | ดึงผ่านเบราว์เซอร์ (ใช้เซสชันของคุณ) | Thunderbit (โหมดเบราว์เซอร์), Web Scraper, Octoparse |
| ร้านที่ต้องล็อกอิน / ร้านส่วนตัว | ดึงผ่านเบราว์เซอร์ด้วยเซสชันที่ล็อกอินแล้ว | Thunderbit (โหมดเบราว์เซอร์), Web Scraper, Simplescraper |
| ปิด products.json ไว้ | ดึงจาก DOM ของหน้าเรนเดอร์แล้ว | ส่วนขยาย Chrome ทั้งหมด (นี่คือจุดแข็งของมัน) |
โหมดดึงข้อมูลแบบคลาวด์/เบราว์เซอร์คู่ของ Thunderbit มีความหมายมากในจุดนี้ โหมดคลาวด์เร็วสำหรับการดึงร้านสาธารณะจำนวนมาก โหมดเบราว์เซอร์ใช้เซสชัน Chrome จริงของคุณเมื่อการป้องกันบอทต้องพึ่งสิ่งนั้น ความยืดหยุ่นนี้ช่วยผมไว้ตอนทดสอบ gymshark.com ซึ่งคำขอแบบคลาวด์ถูกบล็อก แต่โหมดเบราว์เซอร์ใช้งานได้ปกติ
การดึงข้อมูล Shopify ตามกำหนดเวลา: ติดตามราคาและสต็อกไปตามเวลา
การดึงข้อมูลครั้งเดียวก็มีประโยชน์ แต่ทีมงานอีคอมเมิร์ซมักต้องการข้อมูลคู่แข่งแบบต่อเนื่อง — ไม่ใช่แค่ภาพถ่ายครั้งเดียว การเปลี่ยนราคา ความผันผวนของสต็อก การเปิดตัวสินค้าใหม่: สิ่งเหล่านี้เกิดขึ้นตลอดเวลา ผู้ใช้รายหนึ่งในฟอรัมพูดตรงมากว่า: "จะมีประโยชน์กว่าถ้าเห็นระดับสต็อกปัจจุบันและสแนปช็อตของระดับที่ลดลงไป"
แต่แทบไม่มีบทความคู่แข่งพูดถึงการดึงข้อมูลตามกำหนดเวลาหรือแบบทำซ้ำเลย นี่คือจุดบอดที่ชัดเจน
การมอนิเตอร์ Shopify ตามกำหนดเวลาทำงานอย่างไร
- ตั้งค่าการดึงข้อมูลซ้ำของ collection หรือหน้าสินค้าคู่แข่ง
- ส่งออกข้อมูลไปยัง Google Sheets (หรือ Airtable) ทุกครั้งที่รัน เพื่อสร้างไทม์ซีรีส์ของข้อมูลราคาและสต็อก
- ใช้ข้อมูลเพื่อติดตาม: การลด/ขึ้นราคา สินค้าหมดสต็อก การเพิ่มสินค้าใหม่ และแพทเทิร์นตามฤดูกาล
การตั้งค่าการดึงข้อมูลตามกำหนดเวลาด้วย Thunderbit
Thunderbit ทำเรื่องนี้ให้ง่ายแบบไม่น่าเชื่อ
คุณบอกตารางเวลาด้วยภาษาธรรมดา (เช่น "ทุกวันจันทร์ 9 โมงเช้า") ใส่ URL ของร้าน Shopify แล้วกด "Schedule" จากนั้น Thunderbit จะรันการดึงข้อมูลอัตโนมัติและส่งออกไปยังปลายทางที่คุณเลือก ไม่ต้อง cron job ไม่ต้องเขียนโค้ด ไม่ต้องใช้ scheduler ของคนอื่น
การรองรับการตั้งเวลาของทั้ง 8 เครื่องมือ
| เครื่องมือ | ตั้งเวลาได้ไหม? |
|---|---|
| Thunderbit | ได้ — ตั้งเวลาด้วยภาษาธรรมดา |
| Instant Data Scraper | ไม่ได้ |
| Web Scraper | ได้ — ในแผน cloud |
| Data Miner | มีงาน crawl อัตโนมัติ แต่ไม่ใช่วิธีตั้งเวลาที่ง่ายที่สุด |
| Simplescraper | ได้ |
| Octoparse | ได้ — ใน Standard ขึ้นไป |
| Bardeen | ได้ — ผ่านระบบอัตโนมัติตามเวลา/วันที่ |
| Listly | ได้ — ในแผน Business |
ถ้าการมอนิเตอร์คู่แข่งอย่างต่อเนื่องเป็นส่วนหนึ่งของเวิร์กโฟลว์คุณ นี่คือจุดต่างสำคัญ ส่วนขยาย Chrome ฟรีส่วนใหญ่ไม่มีฟีเจอร์นี้เลย
ส่วนขยาย Chrome สำหรับ Shopify Scraper แบบไหนเหมาะกับกรณีใช้งานของคุณ?

แทนที่จะสรุปแบบ "เลือกอันที่คุณชอบ" แบบกว้าง ๆ นี่คือ decision matrix ที่ผูกกับกรณีใช้งานเฉพาะ:
| กรณีใช้งาน | คำแนะนำที่ดีที่สุด | เหตุผล |
|---|---|---|
| วิจัยราคาคู่แข่ง | Thunderbit | หน้ารวม + เพิ่มข้อมูลจากหน้าสินค้า + ตั้งเวลา = เวิร์กโฟลว์ราคาที่ครบ |
| ส่งออกครั้งเดียวแบบเร็ว | Instant Data Scraper | เส้นทางฟรีที่เร็วที่สุดเมื่อคุณต้องการแค่ข้อมูลรายการที่มองเห็น |
| นำแค็ตตาล็อกเข้าสู่ร้าน Shopify ของคุณ | Thunderbit | ข้อมูลครบจากหน้าสินค้า + ส่งออก CSV/Excel ที่เหมาะกับ Shopify |
| มอนิเตอร์ราคา/สต็อกต่อเนื่อง | Thunderbit หรือ Octoparse | ตั้งเวลาแบบ no-code ที่ง่ายที่สุด vs. การตั้งเวลาระดับองค์กรที่แข็งแรงที่สุด |
| หา lead จากข้อมูลเจ้าของร้าน | Thunderbit | มีเครื่องมือดึงอีเมล/โทรศัพท์ในตัว + ส่งออกเป็นโครงสร้าง |
| ระบบอัตโนมัติหลายขั้นที่ซับซ้อน | Bardeen | ดึงข้อมูล เพิ่มความสมบูรณ์ และส่งเข้าแอปปลายทางในเวิร์กโฟลว์เดียว |
| ผู้ใช้สายเทคนิคที่อยากคุมได้เต็มที่ | Web Scraper หรือ Octoparse | ควบคุม selector, flow, และตรรกะการดึงข้อมูลได้ดีที่สุด |
สรุปท้ายบทความ
การดึงข้อมูล Shopify ในปี 2026 ไม่ได้อยู่ที่ว่าคุณดึงข้อมูลสินค้าได้ไหม — แต่อยู่ที่ว่าคุณต้องการข้อมูลลึกแค่ไหน เร็วแค่ไหน และเวิร์กโฟลว์ของคุณทำซ้ำได้ดีแค่ไหน บทความส่วนใหญ่มักหยุดแค่หน้ารวมสินค้า แต่คุณค่าจริงอยู่ที่การเพิ่มข้อมูลจากหน้าสินค้าแต่ละหน้า การมอนิเตอร์ตามกำหนดเวลา และการรับมือกับทริกกันบอทที่ร้าน Shopify จริงโยนมาให้คุณ
ถ้าคุณอยากดูว่ามันทำงานจริงหน้าตาเป็นอย่างไร — ตั้งแต่หน้า collection ไปจนถึงชุดข้อมูลที่เพิ่มความสมบูรณ์ครบในไม่กี่คลิก — ลองใช้ ดู และถ้า Thunderbit ยังไม่ใช่ตัวที่เหมาะที่สุด Instant Data Scraper ก็เป็นจุดเริ่มต้นฟรีที่ดีสำหรับงานง่าย ๆ ขณะที่ Web Scraper และ Octoparse เป็นตัวเลือกแข็งแรงสำหรับผู้ใช้สายเทคนิคที่อยากคุมได้มากขึ้น
ขอให้การ scrape ของคุณราบรื่น — และขอให้ข้อมูลสินค้าของคุณครบถ้วน มีโครงสร้าง และมีตัวแปรสินค้าครบเสมอ
คำถามที่พบบ่อย
1. การดึงข้อมูลจากร้าน Shopify ถือว่าถูกกฎหมายไหม?
ข้อมูลสินค้าที่เปิดเผยต่อสาธารณะบนร้าน Shopify โดยทั่วไปใครที่เข้าชมเว็บไซต์ก็เข้าถึงได้อยู่แล้ว อย่างไรก็ตาม ความถูกต้องตามกฎหมายขึ้นอยู่กับเขตอำนาจศาล ข้อกำหนดการใช้งานของร้าน และสิ่งที่คุณทำกับข้อมูลนั้น การดึงราคาสาธารณะเพื่อวิเคราะห์คู่แข่งเป็นเรื่องที่ทำกันทั่วไป แต่การคัดลอกคอนเทนต์ทั้งก้อนเพื่อเผยแพร่อีกครั้งมีความเสี่ยงมากกว่า นี่ไม่ใช่คำแนะนำทางกฎหมาย — ควรปรึกษาผู้เชี่ยวชาญสำหรับกรณีของคุณโดยเฉพาะ
2. ฉันสามารถดึงข้อมูลจากร้าน Shopify ที่ต้องล็อกอินหรือใส่รหัสผ่านได้ไหม?
ได้ แต่คุณต้องใช้ scraper แบบเบราว์เซอร์ที่ทำงานผ่านเซสชัน Chrome ที่คุณล็อกอินไว้ Cloud scraper โดยทั่วไปจะเข้าเพจที่มีกั้นล็อกอินไม่ได้ Thunderbit โหมดเบราว์เซอร์, Web Scraper (แบบ local) และเวิร์กโฟลว์ล็อกอินของ Simplescraper ล้วนรองรับกรณีนี้
3. ฉันสามารถดึงสินค้าจากร้าน Shopify ได้ครั้งละกี่รายการ?
ขึ้นอยู่กับเครื่องมือและแพ็กเกจ Shopify products.json endpoint แบ่งหน้าที่ Thunderbit โหมดคลาวด์ประมวลผลได้สูงสุด 50 หน้าพร้อมกัน แพ็กฟรีของเครื่องมือส่วนใหญ่จะจำกัดที่จำนวนหน้า แถว หรือเครดิต — ดังนั้นควรเช็กขีดจำกัดของแพ็กก่อนเริ่มงานใหญ่
4. ความต่างระหว่าง cloud scraping กับ browser scraping สำหรับ Shopify คืออะไร?
Cloud scraping รันบนเซิร์ฟเวอร์ระยะไกล — เร็วกว่าและเหมาะกับร้านสาธารณะที่ไม่มีการป้องกันบอท Browser scraping ใช้เซสชัน Chrome บนเครื่องของคุณเอง ซึ่งหมายความว่ารับมือร้านที่ป้องกันด้วย Cloudflare ร้านที่ต้องล็อกอิน หรือร้านที่ไวต่อภูมิภาคได้ Thunderbit มีทั้งสองโหมด และการเลือกมักขึ้นอยู่กับว่าร้านบล็อกคำขอจากระยะไกลหรือไม่
5. ฉันสามารถส่งออกข้อมูล Shopify ที่ดึงมาไปยัง Google Sheets หรือ Airtable ได้โดยตรงไหม?
ได้ แต่ไม่ใช่ทุกเครื่องมือจะรองรับ Thunderbit ส่งออกไปยัง Google Sheets, Airtable, Notion, Excel, CSV และ JSON ได้ — ฟรีทั้งหมด Data Miner และ Listly รองรับ Google Sheets Simplescraper รองรับ Sheets และ Airtable Octoparse รองรับ Google Sheets ในแพ็กพรีเมียม Bardeen เชื่อมกับ Sheets, Airtable และ Notion ส่วน Instant Data Scraper ส่งออกได้แค่ CSV และ XLSX ไม่มีการเชื่อมต่อ Sheets โดยตรง
เรียนรู้เพิ่มเติม