
ควรใช้ภาษาโปรแกรมอะไรทำ web scraping ดี? บอกเลยว่าคำตอบมันคือ “แล้วแต่โปรเจกต์” จริง ๆ — และฉันเห็นนักพัฒนาหลายคนหัวร้อนจนเทงานทิ้ง เพราะดันเลือกภาษาพลาดตั้งแต่ก้าวแรก
ตลาดซอฟต์แวร์ web scraping ตอนนี้แตะมูลค่า การเลือกภาษาให้ถูกมันช่วยให้ทำงานไวขึ้น ดูแลง่ายขึ้น แต่ถ้าเลือกผิด…เตรียมเจอ scraper ล่มบ่อย ๆ แล้ววันหยุดก็หายไปกับการไล่แก้บั๊กแบบงง ๆ
ฉันทำเครื่องมือออโตเมชันมาหลายปี บทความนี้เลยรวบรวม 7 ภาษาที่ฉันเคยใช้ทำ scraping — มีตัวอย่างโค้ด มีข้อดีข้อเสียแบบพูดตรง ๆ ไม่อวย และยังบอกด้วยว่าเมื่อไหร่ควร “ไม่ต้องเขียนโค้ด” แล้วใช้ แทน
เราเลือก “ภาษาที่เหมาะกับ Web Scraping” จากอะไร
สำหรับ web scraping ไม่ใช่ว่าทุกภาษาจะเหมาะพอ ๆ กัน ฉันเห็นทั้งโปรเจกต์ที่พุ่งแบบสวย ๆ และโปรเจกต์ที่พังยับแบบกู้ไม่กลับ ซึ่งส่วนใหญ่ก็มักจะขึ้นกับปัจจัยหลัก ๆ พวกนี้:
- ใช้งานง่ายแค่ไหน: เริ่มได้เร็วไหม ไวยากรณ์อ่านรู้เรื่องหรือเปล่า หรือแค่จะพิมพ์ “Hello, World” ยังรู้สึกเหมือนต้องมีปริญญาเอก
- ไลบรารีรองรับ: มีของดี ๆ สำหรับยิง HTTP, แยก HTML, และจัดการเว็บไดนามิกไหม หรือสุดท้ายต้องทำเองแทบทั้งหมด
- ประสิทธิภาพ: รับไหวไหมถ้าต้องเก็บข้อมูลเป็นล้านหน้า หรือเริ่มหอบตั้งแต่ไม่กี่ร้อยหน้า
- รับมือคอนเทนต์ไดนามิก: เว็บสมัยนี้ JavaScript หนักมาก ภาษานั้นตามเกมทันไหม
- คอมมูนิตี้และซัพพอร์ต: เวลาติดปัญหา (ซึ่งยังไงก็ต้องติด) มีคนตอบ มีตัวอย่าง มีทางออกให้ตามไหม
จากเกณฑ์พวกนี้—บวกกับการเทสต์ดึก ๆ อีกนับไม่ถ้วน—นี่คือ 7 ภาษาที่เราจะคุยกัน:
- Python: ตัวเลือกยอดฮิตทั้งมือใหม่และมือโปร
- JavaScript & Node.js: ตัวท็อปสำหรับเว็บไดนามิก
- Ruby: โค้ดอ่านลื่น เขียนสคริปต์ไว
- PHP: เรียบง่ายสายเซิร์ฟเวอร์
- C++: เมื่ออยากได้ความเร็วแบบดิบ ๆ
- Java: พร้อมใช้ระดับองค์กรและสเกลได้ดี
- Go (Golang): เร็ว และทำงานพร้อมกันได้โหดมาก
และถ้าคุณกำลังคิดว่า “Shuai ฉันไม่อยากเขียนโค้ดเลยอะ” รอช่วง Thunderbit ตอนท้ายได้เลย
Python Web Scraping: พลังสายง่ายสำหรับมือใหม่
เริ่มจากขวัญใจมหาชน: Python ถ้าคุณถามคนสายข้อมูลทั้งห้องว่า “ภาษาที่ดีที่สุดสำหรับ web scraping คืออะไร?” คุณแทบจะได้ยินคำว่า Python ตอบกลับมาพร้อมกัน เหมือนเสียงเชียร์ในคอนเสิร์ต Taylor Swift
ทำไมต้อง Python?
- ไวยากรณ์เป็นมิตร: อ่านโค้ด Python แล้วแทบเหมือนอ่านภาษาอังกฤษ
- ไลบรารีครบเครื่อง: ตั้งแต่ สำหรับแยก HTML, สำหรับ crawl งานใหญ่, สำหรับ HTTP และ สำหรับคุมเบราว์เซอร์—Python มีให้ครบ
- คอมมูนิตี้ใหญ่มาก: คำถามบน Stack Overflow เรื่อง web scraping ด้วย python มีมากกว่า
ตัวอย่างโค้ด Python: ดึงชื่อหน้า (Page Title)
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: {title}")จุดแข็ง:
- ทำงานไว ทั้งพัฒนาและทำต้นแบบ
- มีบทเรียนและ Q&A ให้ตามเยอะมาก
- เหมาะกับงานข้อมูลสุด ๆ — scrape เสร็จต่อด้วย pandas วิเคราะห์ ทำกราฟด้วย matplotlib ได้เลย
ข้อจำกัด:
- ช้ากว่าภาษาแบบคอมไพล์เมื่อสเกลใหญ่มาก
- เว็บที่ไดนามิกสุด ๆ อาจวุ่นวายหน่อย (แต่ Selenium และ Playwright ช่วยได้)
- ไม่เหมาะถ้าต้องเก็บข้อมูลเป็นล้านหน้าแบบสปีดจัด
สรุป:
ถ้าคุณเพิ่งเริ่ม หรืออยากทำงานให้เสร็จไว Python คือภาษาที่เหมาะกับ web scraping ที่สุดแบบไม่ต้องคิดเยอะ
JavaScript & Node.js: เก็บข้อมูลเว็บไดนามิกได้สบาย
ถ้า Python คือมีดพกสารพัดประโยชน์ JavaScript (และ Node.js) ก็เหมือนสว่านไฟฟ้า—โดยเฉพาะเวลาต้องเจอเว็บยุคใหม่ที่พึ่ง JavaScript หนัก ๆ
ทำไมต้อง JavaScript/Node.js?
- เกิดมาเพื่อคอนเทนต์ไดนามิก: อยู่ในโลกเบราว์เซอร์ เลย “เห็น” หน้าเว็บเหมือนผู้ใช้เห็น แม้จะสร้างด้วย React, Angular หรือ Vue
- Async เป็นค่าเริ่มต้น: Node.js จัดการคำขอพร้อมกันได้เยอะมาก
- คุ้นมือสำหรับเว็บเดฟ: ถ้าคุณทำเว็บมาก่อน ส่วนใหญ่ก็จับ JavaScript ได้อยู่แล้ว
ไลบรารีเด่น:
- : คุม Headless Chrome
- : ออโตเมชันหลายเบราว์เซอร์
- : แยก HTML ใน Node แบบฟีล jQuery
ตัวอย่างโค้ด Node.js: ดึงชื่อหน้าด้วย Puppeteer
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: ${title}`);
8 await browser.close();
9})();จุดแข็ง:
- จัดการคอนเทนต์ที่เรนเดอร์ด้วย JavaScript ได้ตรง ๆ
- เหมาะกับ infinite scroll, pop-up และเว็บที่ต้องมีการโต้ตอบ
- ทำงานแบบ concurrent ได้ดีสำหรับงานใหญ่
ข้อจำกัด:
- แนวคิด async อาจทำให้มือใหม่มึนได้
- Headless browser กินแรมหนัก ถ้ารันพร้อมกันหลายตัว
- เครื่องมือวิเคราะห์ข้อมูลไม่แน่นเท่า Python
เมื่อไหร่ JavaScript/Node.js เหมาะสุดสำหรับ web scraping?
เมื่อเว็บเป้าหมายเป็นเว็บไดนามิก หรือคุณต้องออโตเมตการกระทำในเบราว์เซอร์
Ruby: โค้ดอ่านง่าย เหมาะกับสคริปต์เร็ว ๆ
Ruby ไม่ได้มีดีแค่ Rails หรือความสวยของโค้ดนะ มันก็เป็นตัวเลือกที่เวิร์กสำหรับ web scraping เหมือนกัน โดยเฉพาะถ้าคุณชอบโค้ดที่อ่านลื่น ๆ เหมือนบทกวี
ทำไมต้อง Ruby?
- อ่านง่ายและสื่อความหมายดี: เขียน scraper แล้วอ่านเหมือนลิสต์ของในซูเปอร์
- เหมาะกับการทำต้นแบบ: เขียนไว แก้ไว
- ไลบรารีหลัก: สำหรับ parsing, สำหรับออโตเมตการนำทาง
ตัวอย่างโค้ด Ruby: ดึงชื่อหน้า
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #{title}"จุดแข็ง:
- โค้ดสั้น กระชับ และอ่านง่ายมาก
- เหมาะกับโปรเจกต์เล็ก สคริปต์ครั้งเดียว หรือคนที่ใช้ Ruby อยู่แล้ว
ข้อจำกัด:
- งานใหญ่ ๆ อาจช้ากว่า Python หรือ Node.js
- ไลบรารีและคอมมูนิตี้สาย scraping ไม่ใหญ่เท่า
- ไม่เหมาะกับเว็บที่ใช้ JavaScript หนัก (แต่ใช้ Watir หรือ Selenium ได้)
เหมาะกับใคร:
ถ้าคุณเป็นสาย Ruby หรืออยากทำสคริปต์เร็ว ๆ Ruby สนุกจริง แต่ถ้าต้องเก็บข้อมูลมหาศาลจากเว็บไดนามิก แนะนำมองตัวอื่นจะชัวร์กว่า
PHP: เรียบง่ายฝั่งเซิร์ฟเวอร์สำหรับดึงข้อมูลเว็บ
PHP อาจดูเหมือนของเก่าจากยุคเว็บแรก ๆ แต่ยังถูกใช้งานจริงเยอะมาก โดยเฉพาะถ้าคุณอยากดึงข้อมูลบนเซิร์ฟเวอร์ของตัวเองแบบตรงไปตรงมา
ทำไมต้อง PHP?
- รันได้แทบทุกที่: เว็บเซิร์ฟเวอร์ส่วนใหญ่มี PHP ติดอยู่แล้ว
- เชื่อมกับเว็บแอปง่าย: ดึงข้อมูลแล้วเอาไปแสดงบนเว็บในระบบเดียวกันได้เลย
- ไลบรารีหลัก: สำหรับ HTTP, สำหรับ requests, สำหรับ headless browser
ตัวอย่างโค้ด PHP: ดึงชื่อหน้า
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>จุดแข็ง:
- ดีพลอยบนเซิร์ฟเวอร์ง่าย
- เหมาะกับงาน scraping ที่เป็นส่วนหนึ่งของ workflow บนเว็บ
- เร็วพอสำหรับงานฝั่งเซิร์ฟเวอร์พื้นฐาน
ข้อจำกัด:
- ไลบรารีสำหรับงานขั้นสูงมีจำกัด
- ไม่ได้ออกแบบมาสำหรับ concurrency สูงหรือสเกลใหญ่
- เว็บที่ใช้ JavaScript หนักจัดการยาก (แต่ Panther ช่วยได้)
เหมาะกับใคร:
ถ้าระบบคุณใช้ PHP อยู่แล้ว หรืออยากดึงข้อมูลแล้วเอาไปแสดงบนเว็บทันที PHP เป็นตัวเลือกที่ใช้งานได้จริง
C++: Web Scraping ประสิทธิภาพสูงสำหรับงานสเกลใหญ่
C++ คือรถกล้ามของโลกภาษาโปรแกรม ถ้าคุณต้องการความเร็วและการควบคุมแบบสุดทาง และไม่กลัวงานจุกจิก C++ ก็พาคุณไปได้ไกลจริง
ทำไมต้อง C++?
- เร็วมาก: มักชนะหลายภาษาในงานที่กิน CPU
- ควบคุมละเอียด: จัดการหน่วยความจำ เธรด และจูนประสิทธิภาพได้เต็มที่
- ไลบรารีหลัก: สำหรับ HTTP, สำหรับ parsing
ตัวอย่างโค้ด C++: ดึงชื่อหน้า
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}จุดแข็ง:
- ความเร็วระดับสุดสำหรับงาน scraping ปริมาณมหาศาล
- เหมาะกับการฝัง scraping เข้าไปในระบบที่ต้องการประสิทธิภาพสูง
ข้อจำกัด:
- เส้นชันในการเรียนรู้สูง (เตรียมกาแฟไว้)
- ต้องจัดการหน่วยความจำเอง
- ไลบรารีระดับสูงมีน้อย และไม่เหมาะกับคอนเทนต์ไดนามิก
เหมาะกับใคร:
เมื่อคุณต้องเก็บข้อมูลเป็นล้านหน้า หรือประสิทธิภาพคือเรื่องสำคัญที่สุด ไม่งั้นคุณอาจหมดเวลาไปกับการดีบักมากกว่าการเก็บข้อมูลจริง
Java: โซลูชัน Web Scraping ระดับองค์กร
Java คือม้าทำงานของโลกองค์กร ถ้าคุณต้องสร้างระบบที่ต้องรันยาว ๆ รับข้อมูลเยอะ ๆ และต้องทนมือทนเท้าแบบสุด ๆ Java คือเพื่อนที่ไว้ใจได้
ทำไมต้อง Java?
- แข็งแรงและขยายได้: เหมาะกับโปรเจกต์ scraping ขนาดใหญ่และรันต่อเนื่อง
- Strong typing + จัดการข้อผิดพลาดดี: ลดเซอร์ไพรส์ตอนขึ้นโปรดักชัน
- ไลบรารีหลัก: สำหรับ parsing, สำหรับออโตเมตเบราว์เซอร์, สำหรับ HTTP
ตัวอย่างโค้ด Java: ดึงชื่อหน้า
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}จุดแข็ง:
- ประสิทธิภาพและ concurrency ดี
- เหมาะกับโค้ดเบสใหญ่ที่ต้องดูแลระยะยาว
- รองรับเว็บไดนามิกได้ดีผ่าน Selenium หรือ HtmlUnit
ข้อจำกัด:
- โค้ดค่อนข้างยาว และต้องเซ็ตอัปมากกว่าภาษาแบบสคริปต์
- งานเล็ก ๆ ทำครั้งเดียวอาจเกินจำเป็น
เหมาะกับใคร:
งาน scraping ระดับองค์กร หรือโปรเจกต์ระยะยาวที่ต้องการความเสถียรและสเกล
Go (Golang): เร็วและทำงานพร้อมกันได้ดีสำหรับ Web Scraping
Go เป็นน้องใหม่ที่ดังไวมาก โดยเฉพาะงาน scraping ที่ต้องการทั้งความเร็วและการทำงานแบบขนาน (concurrent)
ทำไมต้อง Go?
- ความเร็วแบบคอมไพล์: ใกล้เคียง C++
- Concurrency ในตัว: goroutine ทำให้การเก็บข้อมูลแบบขนานทำได้ง่ายมาก
- ไลบรารีหลัก: สำหรับ scraping, สำหรับ parsing
ตัวอย่างโค้ด Go: ดึงชื่อหน้า
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}จุดแข็ง:
- เร็วและประหยัดทรัพยากร เหมาะกับงานสเกลใหญ่
- ดีพลอยง่าย (ไฟล์ไบนารีเดียวจบ)
- เหมาะกับการ crawl แบบ concurrent
ข้อจำกัด:
- คอมมูนิตี้เล็กกว่า Python หรือ Node.js
- ไลบรารีระดับสูงยังไม่เยอะเท่า
- เว็บที่ใช้ JavaScript หนักต้องตั้งค่าเพิ่ม (Chromedp หรือ Selenium)
เหมาะกับใคร:
เมื่อคุณต้องเก็บข้อมูลจำนวนมาก หรือ Python ไม่เร็วพอ
เปรียบเทียบภาษาโปรแกรมที่เหมาะกับ Web Scraping
สรุปให้เห็นภาพชัด ๆ นี่คือการเทียบแบบตัวต่อตัว เพื่อช่วยคุณเลือกภาษาโปรแกรมที่ดีที่สุดสำหรับ web scraping ในปี 2026:
| ภาษา/เครื่องมือ | ใช้งานง่าย | ประสิทธิภาพ | ไลบรารีรองรับ | จัดการคอนเทนต์ไดนามิก | เหมาะกับงานแบบไหน |
|---|---|---|---|---|---|
| Python | สูงมาก | ปานกลาง | ยอดเยี่ยม | ดี (Selenium/Playwright) | งานทั่วไป มือใหม่ งานวิเคราะห์ข้อมูล |
| JavaScript/Node.js | ปานกลาง | สูง | แข็งแรง | ยอดเยี่ยม (ทำได้โดยตรง) | เว็บไดนามิก งาน async นักพัฒนาเว็บ |
| Ruby | สูง | ปานกลาง | พอใช้ | จำกัด (Watir) | สคริปต์เร็ว ๆ ทำต้นแบบ |
| PHP | ปานกลาง | ปานกลาง | พอใช้ | จำกัด (Panther) | งานฝั่งเซิร์ฟเวอร์ เชื่อมเว็บแอป |
| C++ | ต่ำ | สูงมาก | จำกัด | จำกัดมาก | งานที่ต้องการความเร็วสุด ๆ สเกลมหาศาล |
| Java | ปานกลาง | สูง | ดี | ดี (Selenium/HtmlUnit) | องค์กร บริการที่รันยาว ๆ |
| Go (Golang) | ปานกลาง | สูงมาก | กำลังเติบโต | ปานกลาง (Chromedp) | งานเร็ว งาน concurrent สเกลใหญ่ |
เมื่อไหร่ควรข้ามการเขียนโค้ด: Thunderbit ทางเลือกแบบ No-code
พูดกันแบบไม่อ้อมค้อม: บางทีคุณก็แค่อยากได้ข้อมูล—ไม่อยากเขียนโค้ด ไม่อยากดีบัก และไม่อยากปวดหัวกับ “ทำไม selector นี้พังอีกแล้ว” นั่นแหละคือเหตุผลที่ ถูกสร้างขึ้นมา
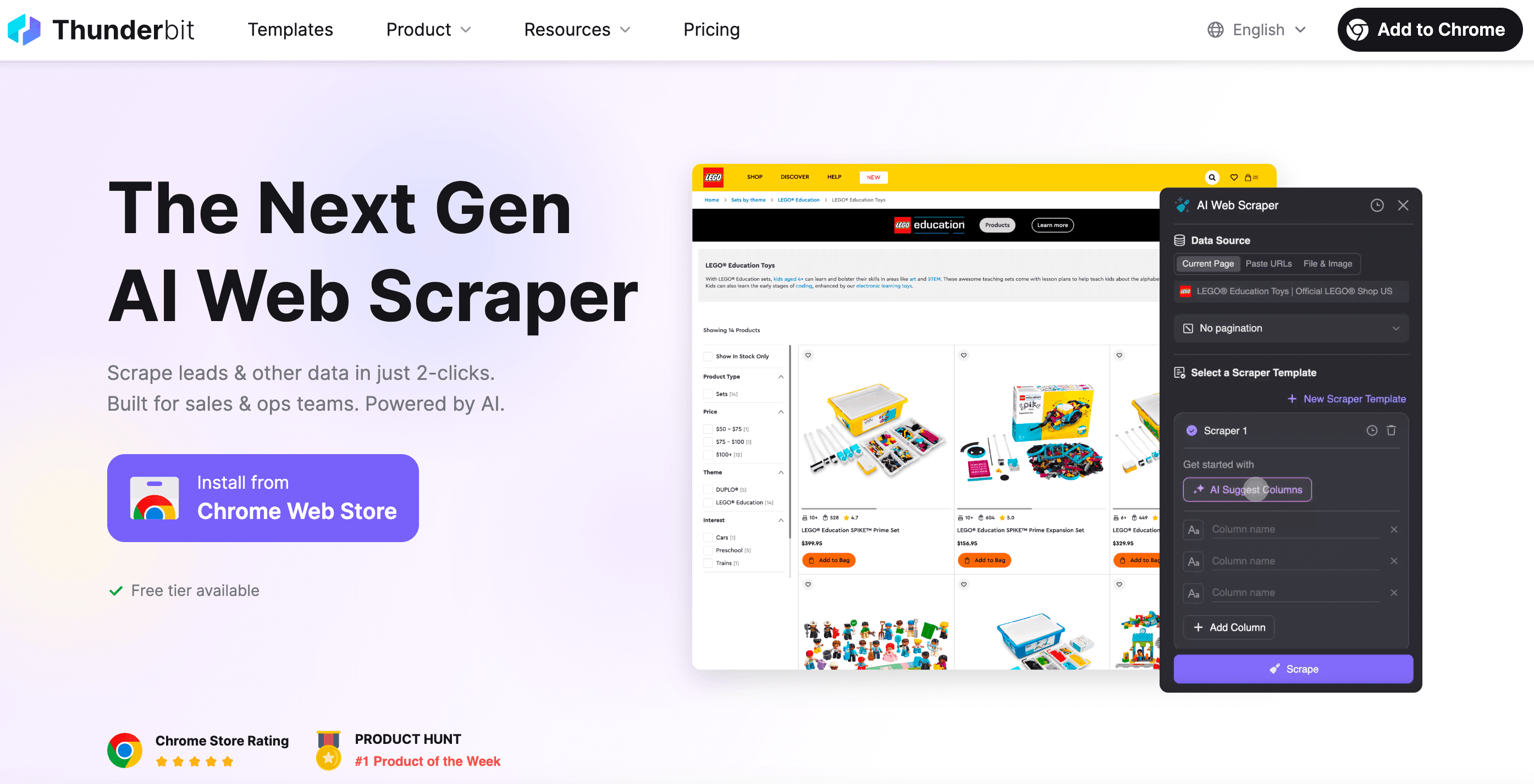
ในฐานะผู้ร่วมก่อตั้ง Thunderbit ฉันอยากทำเครื่องมือที่ทำให้การทำ web scraping ง่ายพอ ๆ กับการสั่งอาหารเดลิเวอรี นี่คือสิ่งที่ทำให้ Thunderbit เด่นและต่าง:
- ตั้งค่าแค่ 2 คลิก: กด “AI Suggest Fields” แล้วกด “Scrape” ไม่ต้องยุ่งกับ HTTP requests, proxy หรือเทคนิคหลบ anti-bot
- เทมเพลตฉลาด: เทมเพลตเดียวปรับใช้ได้กับหลายเลย์เอาต์ ไม่ต้องเขียนใหม่ทุกครั้งที่เว็บเปลี่ยน
- Scrape ได้ทั้งในเบราว์เซอร์และบนคลาวด์: เลือก scrape ในเบราว์เซอร์ (เหมาะกับเว็บที่ต้องล็อกอิน) หรือบนคลาวด์ (เร็วมากสำหรับข้อมูลสาธารณะ)
- รับมือเว็บไดนามิก: AI ของ Thunderbit คุมเบราว์เซอร์จริง จัดการ infinite scroll, pop-up, ล็อกอิน และอื่น ๆ ได้
- ส่งออกได้ทุกที่: ดาวน์โหลดเป็น Excel, Google Sheets, Airtable, Notion หรือคัดลอกลงคลิปบอร์ด
- แทบไม่ต้องดูแล: เว็บเปลี่ยนก็แค่ให้ AI แนะนำฟิลด์ใหม่ ไม่ต้องนั่งดีบักดึก ๆ
- ตั้งเวลาและออโตเมชัน: ตั้งให้รันตามตารางได้ ไม่ต้องตั้ง cron ไม่ต้องตั้งเซิร์ฟเวอร์
- ตัวดึงข้อมูลเฉพาะทาง: อยากได้อีเมล เบอร์โทร หรือรูปภาพ? มีตัวดึงแบบคลิกเดียวให้ด้วย
ที่สำคัญคือ คุณไม่ต้องรู้โค้ดแม้แต่บรรทัดเดียว Thunderbit ทำมาเพื่อผู้ใช้ธุรกิจ นักการตลาด ทีมขาย สายอสังหา—หรือใครก็ตามที่ต้องการข้อมูลแบบเร็วและเป็นโครงสร้าง
อยากดู Thunderbit ทำงานจริงไหม? ไปที่ หรือดูเดโมใน ของเราได้เลย
บทสรุป: เลือกภาษาที่เหมาะกับ Web Scraping ในปี 2026
Web scraping ในปี 2026 เข้าง่ายขึ้น—และทรงพลังขึ้น—กว่าเดิมเยอะ นี่คือสิ่งที่ฉันเรียนรู้จากการทำงานออโตเมชันมาหลายปี:
- Python ยังเป็นตัวเลือกอันดับหนึ่ง ถ้าคุณอยากเริ่มไว และอยากมีทรัพยากรให้ค้นหาเพียบ
- JavaScript/Node.js เหนือชั้นสำหรับเว็บไดนามิกที่ใช้ JavaScript หนัก
- Ruby และ PHP เหมาะกับสคริปต์เร็ว ๆ และการเชื่อมกับเว็บ โดยเฉพาะถ้าคุณใช้อยู่แล้ว
- C++ และ Go เหมาะเมื่อคุณต้องการความเร็วและสเกล
- Java เหมาะกับงานระดับองค์กรและโปรเจกต์ระยะยาว
- และถ้าคุณอยากข้ามการเขียนโค้ดไปเลย? คืออาวุธลับของคุณ
ก่อนเริ่ม ลองถามตัวเองสั้น ๆ ว่า:
- โปรเจกต์ใหญ่แค่ไหน?
- ต้องรับมือคอนเทนต์ไดนามิกไหม?
- ความถนัดด้านเทคนิคของเราอยู่ระดับไหน?
- อยาก “สร้างระบบ” หรือแค่อยาก “ได้ข้อมูล”?
ลองโค้ดตัวอย่างด้านบน หรือให้ Thunderbit ช่วยในโปรเจกต์ถัดไปก็ได้ และถ้าอยากลงลึกกว่านี้ แวะอ่าน ได้เลย มีไกด์ ทิปส์ และเรื่องจริงจากงาน scraping อีกเพียบ
ขอให้สนุกกับการ scraping—และขอให้ข้อมูลของคุณสะอาด เป็นโครงสร้าง และอยู่ห่างแค่คลิกเดียวเสมอ
P.S. ถ้าคุณหลงเข้าไปในโพรงกระต่ายของ web scraping ตอนตี 2 เมื่อไหร่ จำไว้ว่ายังมี Thunderbit อยู่เสมอ หรือกาแฟ หรือทั้งสองอย่าง
คำถามที่พบบ่อย (FAQs)
1. ภาษาโปรแกรมที่ดีที่สุดสำหรับ web scraping ในปี 2026 คืออะไร?
Python ยังเป็นตัวเลือกอันดับหนึ่ง เพราะอ่านง่าย ไลบรารีทรงพลัง (เช่น BeautifulSoup, Scrapy และ Selenium) และมีคอมมูนิตี้ใหญ่ เหมาะทั้งมือใหม่และมือโปร โดยเฉพาะเมื่อทำ scraping ควบคู่กับการวิเคราะห์ข้อมูล
2. ภาษาไหนเหมาะสุดสำหรับเว็บที่ใช้ JavaScript หนัก ๆ?
JavaScript (Node.js) เหมาะที่สุดสำหรับเว็บไดนามิก เครื่องมืออย่าง Puppeteer และ Playwright ให้คุณควบคุมเบราว์เซอร์ได้เต็มรูปแบบ จึงโต้ตอบกับคอนเทนต์ที่โหลดผ่าน React, Vue หรือ Angular ได้
3. มีตัวเลือกแบบไม่ต้องเขียนโค้ดสำหรับ web scraping ไหม?
มี— คือ AI Web Scraper แบบ no-code ที่จัดการได้ตั้งแต่คอนเทนต์ไดนามิกไปจนถึงการตั้งเวลาใช้งาน แค่คลิก “AI Suggest Fields” แล้วเริ่ม scrape ได้ทันที เหมาะมากสำหรับทีมขาย การตลาด หรือทีมปฏิบัติการที่ต้องการข้อมูลแบบเป็นโครงสร้างอย่างรวดเร็ว
อ่านเพิ่มเติม: