ข้อมูลบนเว็บนี่แหละคือ “วัตถุดิบ” ตัวจริงของทีมขาย การตลาด และฝ่ายปฏิบัติการในยุคนี้ ถ้ายังนั่งก็อปปี้-วางอยู่ บอกเลยว่าคุณช้ากว่าคนอื่นไปแล้ว
แต่ปัญหาของเครื่องมือสแครป “ฟรี” คือ ส่วนใหญ่ไม่ได้ฟรีจริง หลายเจ้าก็ให้แค่ช่วงทดลองแบบโดนล็อกหนักๆ หรือซ่อนฟีเจอร์สำคัญไว้หลังเพย์วอลล์แบบเนียนๆ
ผมเลยไปลองมาให้ครบ 12 เครื่องมือ เพื่อดูว่าอันไหนที่แพ็กเกจฟรียัง “ทำงานจริง” ได้ ผมเทสต์ตั้งแต่ดึงรายชื่อจาก Google Maps หน้าเว็บไดนามิกที่ต้องล็อกอิน ไปจนถึงไฟล์ PDF บางตัวทำได้ดีมาก บางตัวทำเอาผมเสียเวลาไปทั้งบ่าย
นี่คือสรุปแบบไม่อ้อมค้อม—เริ่มจากตัวที่ผมแนะนำได้จริงก่อนเลย
ทำไม Web Scraper ฟรีถึงสำคัญกว่าเดิม
พูดกันแบบตรงๆ: ปี 2026 การทำ web scraping ไม่ได้เป็นเรื่องของแฮกเกอร์หรือ data scientist เท่านั้นอีกต่อไป แต่มันกลายเป็นเครื่องมือมาตรฐานของธุรกิจยุคใหม่ไปแล้ว และตัวเลขก็ยืนยันชัดมาก ตลาดซอฟต์แวร์ web scraping แตะ และมีแนวโน้มโตมากกว่าสองเท่าภายในปี 2032 เพราะตั้งแต่ทีมขายไปจนถึงนายหน้าอสังหาฯ ต่างก็ใช้ข้อมูลจากเว็บเพื่อสร้างความได้เปรียบ
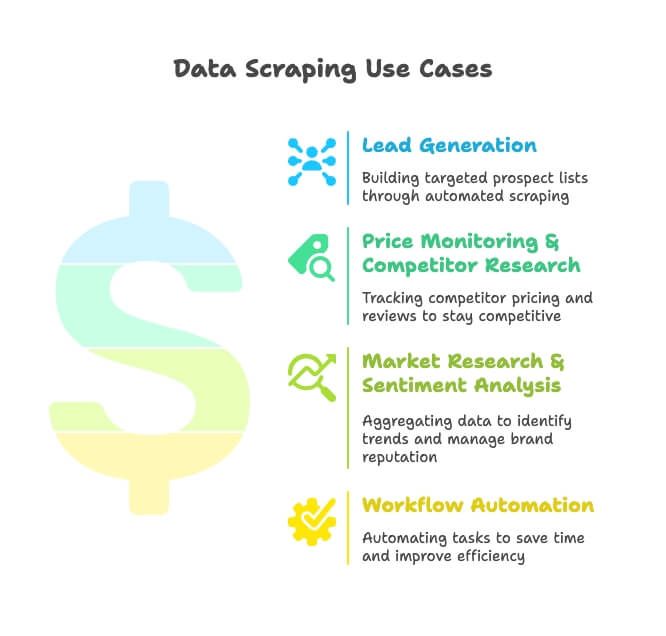
- สร้างลีด (Lead Generation): ทีมขายดึงข้อมูลจากไดเรกทอรี Google Maps และโซเชียลเพื่อทำลิสต์ลูกค้าเป้าหมายแบบเจาะจง ไม่ต้องไล่หาเองทีละราย
- ติดตามราคา & วิเคราะห์คู่แข่ง: ทีมอีคอมเมิร์ซ/รีเทลติดตาม SKU ราคา และรีวิวของคู่แข่งเพื่อปรับเกมให้ทัน (และใช่—82% ของบริษัทอีคอมเมิร์ซสแครปข้อมูลด้วยเหตุผลนี้)
- วิจัยตลาด & วิเคราะห์ความรู้สึก (Sentiment): นักการตลาดรวบรวมรีวิว ข่าว และกระแสบนโซเชียลเพื่อจับเทรนด์และดูแลภาพลักษณ์แบรนด์
- ทำงานอัตโนมัติ (Workflow Automation): ทีม ops ทำตั้งแต่เช็กสต็อกไปจนถึงรายงานตามรอบแบบอัตโนมัติ ประหยัดเวลาได้หลายชั่วโมงต่อสัปดาห์
อีกสถิติที่น่าสนใจ: บริษัทที่ใช้ web scraper ที่ขับเคลื่อนด้วย AI ประหยัดเวลาได้ เมื่อเทียบกับการทำมือ นี่ไม่ใช่แค่ “ประหยัดนิดหน่อย” แต่มันคือความต่างระหว่างเลิกงาน 6 โมงกับ 3 ทุ่ม
เราเลือกเครื่องมือ Data Scraper ฟรีที่ดีที่สุดอย่างไร
ผมเห็นลิสต์ “best web scraper” เยอะมากที่เหมือนแค่ก็อปคำโฆษณามาแปะ แต่บทความนี้ไม่ใช่แนวนั้น เกณฑ์ที่ผมใช้มีประมาณนี้:
- แพ็กเกจฟรีใช้งานได้จริงแค่ไหน: ทำงานจริงได้หรือเป็นแค่เดโมให้ลอง?
- ใช้ง่ายแค่ไหน: คนไม่เขียนโค้ดทำได้ในไม่กี่นาที หรือจำเป็นต้องเทพ Regex?
- รองรับเว็บแบบไหนบ้าง: เว็บนิ่ง เว็บไดนามิก หน้าแบ่งหน้า (pagination) เว็บต้องล็อกอิน PDF โซเชียล—เอาอยู่ในสถานการณ์จริงไหม
- ตัวเลือกการส่งออกข้อมูล: เอาข้อมูลไป Excel, Google Sheets, Notion หรือ Airtable ได้ง่ายหรือเปล่า
- ฟีเจอร์เสริม: การดึงข้อมูลด้วย AI, ตั้งเวลา, เทมเพลต, post-processing, อินทิเกรชัน
- เหมาะกับผู้ใช้แบบไหน: สายธุรกิจ นักวิเคราะห์ หรือสาย dev
ผมยังไล่อ่านเอกสารประกอบ ลอง onboarding และเทียบข้อจำกัดของแพ็กเกจฟรีของแต่ละตัวด้วย เพราะคำว่า “ฟรี” บนหน้าเว็บ มักไม่ฟรีอย่างที่เราคิดจริงๆ
สรุปภาพรวม: เทียบ 12 Data Scraper ฟรีแบบชัดๆ
ตารางนี้ช่วยให้คุณเลือกเครื่องมือที่เหมาะกับงานได้ไวขึ้น
| Tool | Platform | Free Plan Limitations | Best For | Export Formats | Unique Features |
|---|---|---|---|---|---|
| Thunderbit | ส่วนขยาย Chrome | 6 หน้า/เดือน | คนไม่เขียนโค้ด, สายธุรกิจ | Excel, CSV | พรอมป์ต์ AI, สแครป PDF/รูป, crawl ซับเพจ |
| Browse AI | คลาวด์ | 50 เครดิต/เดือน | ผู้ใช้ no-code | CSV, Sheets | บอทแบบคลิกเลือก, ตั้งเวลา |
| Octoparse | เดสก์ท็อป | 10 งาน, 50k แถว/เดือน | no-code, กึ่งเทคนิค | CSV, Excel, JSON | เวิร์กโฟลว์แบบภาพ, รองรับเว็บไดนามิก |
| ParseHub | เดสก์ท็อป | 5 โปรเจกต์, 200 หน้า/รัน | no-code, กึ่งเทคนิค | CSV, Excel, JSON | แบบภาพ, รองรับเว็บไดนามิก |
| Webscraper.io | ส่วนขยาย Chrome | ใช้โลคอลได้ไม่จำกัด | no-code, งานง่ายๆ | CSV, XLSX | ทำตาม sitemap, เทมเพลตจากชุมชน |
| Apify | คลาวด์ | เครดิต $5/เดือน | ทีม, กึ่งเทคนิค, dev | CSV, JSON, Sheets | ตลาด Actor, ตั้งเวลา, API |
| Scrapy | ไลบรารี Python | ไม่จำกัด (โอเพ่นซอร์ส) | นักพัฒนา | CSV, JSON, DB | คุมได้เต็ม, สเกลได้ |
| Puppeteer | ไลบรารี Node.js | ไม่จำกัด (โอเพ่นซอร์ส) | นักพัฒนา | ปรับเอง (เขียนโค้ด) | เบราว์เซอร์แบบ headless, รองรับ JS หนัก |
| Selenium | หลายภาษา | ไม่จำกัด (โอเพ่นซอร์ส) | นักพัฒนา | ปรับเอง (เขียนโค้ด) | ออโตเมชันเบราว์เซอร์, รองรับหลายเบราว์เซอร์ |
| Zyte | คลาวด์ | 1 spider, 1 ชม./งาน, เก็บ 7 วัน | dev, ทีม ops | CSV, JSON | Scrapy แบบโฮสต์, จัดการพร็อกซี |
| SerpAPI | API | 100 ค้นหา/เดือน | dev, นักวิเคราะห์ | JSON | API ข้อมูลเสิร์ช, กันบล็อก |
| Diffbot | API | 10,000 เครดิต/เดือน | dev, โปรเจกต์ AI | JSON | ดึงข้อมูลด้วย AI, knowledge graph |
Thunderbit: ตัวเลือกอันดับหนึ่งสำหรับการสแครปข้อมูลด้วย AI ที่ใช้ง่าย
มาดูกันว่าทำไม ถึงขึ้นมาอยู่บนสุดของลิสต์ผม ผมไม่ได้เชียร์เพราะอยู่ทีมเดียวกันนะ—แต่เพราะมันให้ฟีลเหมือนมี “เด็กฝึกงาน AI” ที่เข้าใจงานจริง (และไม่หายไปพักเบรกซื้อกาแฟ)
Thunderbit ไม่ใช่แนว “ต้องเรียนเครื่องมือก่อนแล้วค่อยสแครป” แต่มันเหมือนสั่งงานผู้ช่วยอัจฉริยะ: คุณแค่บอกว่าต้องการอะไร (เช่น “ดึงชื่อสินค้า ราคา และลิงก์ทั้งหมดจากหน้านี้”) แล้ว AI จะจัดการส่วนที่เหลือให้เอง ไม่ต้องไปปวดหัวกับ XPath, CSS selector หรือ Regex และถ้าต้องตามไปเก็บข้อมูลจากซับเพจ (อย่างหน้ารายละเอียดสินค้า หรือหน้าติดต่อบริษัท) Thunderbit ก็คลิกไล่ให้และเติมข้อมูลกลับลงตารางอัตโนมัติ—คุณแค่กดปุ่ม
สิ่งที่ทำให้ Thunderbit เด่นจริงๆ คือช่วง “หลังสแครปเสร็จ” เพราะถ้าคุณอยากสรุป แปล จัดหมวดหมู่ หรือทำความสะอาดข้อมูล AI post-processing ในตัวช่วยได้เลย คุณไม่ได้แค่ได้ข้อมูลดิบ แต่ได้ข้อมูลที่จัดรูปแบบพร้อมเอาไปใช้ต่อกับ CRM สเปรดชีต หรือโปรเจกต์ถัดไป
แพ็กเกจฟรี: ทดลองใช้ Thunderbit ฟรีสแครปได้สูงสุด 6 หน้า (หรือ 10 หน้าหากได้ trial boost) รวมถึง PDF รูปภาพ และแม้แต่เทมเพลตโซเชียลมีเดีย ส่งออกเป็น Excel หรือ CSV ได้ฟรี และลองฟีเจอร์อย่างการดึงอีเมล/เบอร์โทร/รูปภาพได้ งานใหญ่ขึ้นค่อยอัปเกรดเพื่อปลดล็อกจำนวนหน้ามากขึ้น ส่งออกตรงไป Google Sheets/Notion/Airtable, ตั้งเวลาสแครป และเทมเพลตสำเร็จรูปสำหรับเว็บยอดนิยมอย่าง Amazon, Google Maps และ Instagram
อยากดู Thunderbit ทำงานจริง ลองดู หรือเข้า ของเราเพื่อดูวิดีโอเริ่มต้นแบบเร็วๆ
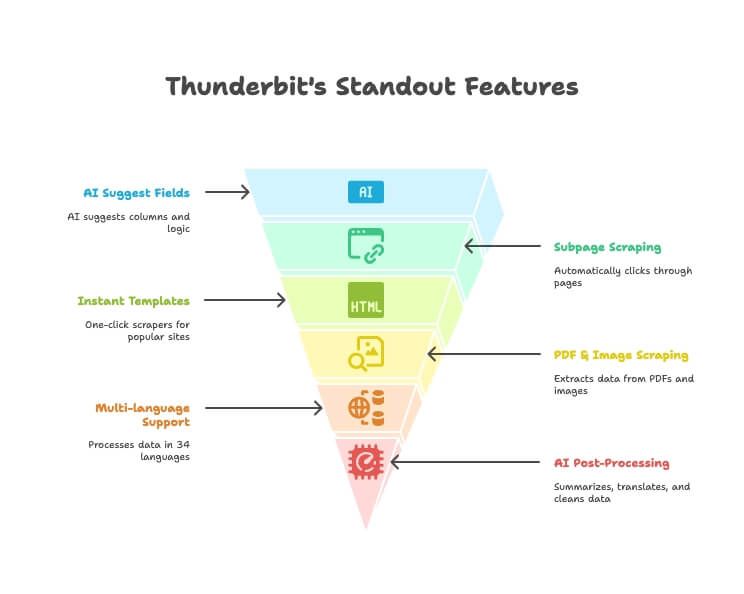
ฟีเจอร์เด่นของ Thunderbit
- AI Suggest Fields: แค่บอกว่าต้องการข้อมูลอะไร AI จะช่วยเสนอคอลัมน์และวิธีดึงข้อมูลให้เหมาะสม
- Subpage Scraping: คลิกไล่หน้ารายละเอียด/ลิงก์ต่างๆ แล้วเติมข้อมูลกลับมาที่ตารางหลักอัตโนมัติ ไม่ต้องตั้งค่าเอง
- Instant Templates: สแครปแบบคลิกเดียวสำหรับ Amazon, Google Maps, Instagram และอีกมาก
- PDF & Image Scraping: ดึงตารางและข้อมูลจาก PDF/รูปภาพด้วย AI โดยไม่ต้องใช้เครื่องมือเสริม
- Multi-language Support: สแครปและประมวลผลได้ 34 ภาษา
- Direct Export: ส่งออกตรงไป Excel, Google Sheets, Notion หรือ Airtable (เฉพาะแพ็กเกจเสียเงิน)
- AI Post-Processing: สรุป แปล จัดหมวดหมู่ และทำความสะอาดข้อมูลระหว่างสแครป
- Free Email/Phone/Image Extraction: ดึงข้อมูลติดต่อหรือรูปภาพจากเว็บใดก็ได้ในคลิกเดียว
Thunderbit เหมือนเป็นสะพานเชื่อมระหว่าง “แค่ดึงข้อมูล” กับ “ได้ข้อมูลที่เอาไปใช้ทำงานต่อได้จริง” ซึ่งเป็นสิ่งที่ผมแทบไม่ค่อยเห็นจากเครื่องมืออื่นในกลุ่มผู้ใช้สายธุรกิจ
ที่เหลือใน Top 12: รีวิวเครื่องมือ Data Scraper ฟรีแบบเจาะจง
ต่อไปคือเครื่องมือที่เหลือ โดยผมจัดกลุ่มตามประเภทผู้ใช้ที่เหมาะที่สุด
สำหรับผู้ใช้ No-Code & สายธุรกิจ
Thunderbit
พูดไปแล้วด้านบน นี่คือทางเข้าที่ง่ายที่สุดสำหรับคนไม่เขียนโค้ด ได้ทั้ง AI และเทมเพลตสำเร็จรูป
Webscraper.io
- แพลตฟอร์ม: ส่วนขยาย Chrome
- เหมาะกับ: เว็บนิ่ง/งานง่ายๆ; คนไม่เขียนโค้ดที่ยอมลองผิดลองถูกได้
- ฟีเจอร์หลัก: สแครปตาม sitemap, รองรับ pagination, ส่งออก CSV/XLSX
- แพ็กเกจฟรี: ใช้บนเครื่องได้ไม่จำกัด แต่ไม่มีรันบนคลาวด์หรือการตั้งเวลา ต้องทำแบบแมนนวล
- ข้อจำกัด: ไม่ได้ออกแบบมาสำหรับล็อกอิน, PDF หรือคอนเทนต์ไดนามิกซับซ้อน การช่วยเหลือหลักมาจากชุมชน
ParseHub
- แพลตฟอร์ม: แอปเดสก์ท็อป (Windows, Mac, Linux)
- เหมาะกับ: คนไม่เขียนโค้ดและผู้ใช้กึ่งเทคนิคที่พร้อมลงทุนเวลาเรียนรู้
- ฟีเจอร์หลัก: สร้างเวิร์กโฟลว์แบบภาพ รองรับเว็บไดนามิก, AJAX, ล็อกอิน, pagination
- แพ็กเกจฟรี: 5 โปรเจกต์แบบสาธารณะ, 200 หน้า/รัน, รันแบบแมนนวลเท่านั้น
- ข้อจำกัด: โปรเจกต์เป็นสาธารณะในแพ็กเกจฟรี (ระวังข้อมูลอ่อนไหว), ไม่มีตั้งเวลา, ความเร็วสกัดข้อมูลช้ากว่า
Octoparse
- แพลตฟอร์ม: แอปเดสก์ท็อป (Windows/Mac), คลาวด์ (เสียเงิน)
- เหมาะกับ: คนไม่เขียนโค้ดและนักวิเคราะห์ที่อยากได้ความยืดหยุ่นและพลัง
- ฟีเจอร์หลัก: คลิกเลือกแบบภาพ รองรับคอนเทนต์ไดนามิก มีเทมเพลตเว็บยอดนิยม
- แพ็กเกจฟรี: 10 งาน, สูงสุด 50,000 แถว/เดือน, ใช้ได้เฉพาะเดสก์ท็อป (ไม่มีคลาวด์/ตั้งเวลา)
- ข้อจำกัด: ไม่มี API, ไม่มีหมุน IP, ไม่มีตั้งเวลาในแพ็กเกจฟรี งานซับซ้อนอาจต้องใช้เวลาทำความเข้าใจ
Browse AI
- แพลตฟอร์ม: คลาวด์
- เหมาะกับ: ผู้ใช้ no-code ที่อยากทำสแครป/มอนิเตอร์งานง่ายๆ แบบอัตโนมัติ
- ฟีเจอร์หลัก: อัดบอทแบบคลิกเลือก, ตั้งเวลา, อินทิเกรชัน (Sheets, Zapier)
- แพ็กเกจฟรี: 50 เครดิต/เดือน, 1 เว็บไซต์, สูงสุด 5 robots
- ข้อจำกัด: ปริมาณจำกัด และเว็บซับซ้อนอาจต้องเรียนรู้เพิ่ม
สำหรับนักพัฒนา & ผู้ใช้สายเทคนิค
Scrapy
- แพลตฟอร์ม: ไลบรารี Python (โอเพ่นซอร์ส)
- เหมาะกับ: นักพัฒนาที่ต้องการคุมทุกอย่างและสเกลได้
- ฟีเจอร์หลัก: ปรับแต่งได้สูง รองรับ crawl ขนาดใหญ่ มี middleware และ pipeline
- แพ็กเกจฟรี: ไม่จำกัด (โอเพ่นซอร์ส)
- ข้อจำกัด: ไม่มี GUI ต้องเขียน Python ไม่เหมาะกับคนไม่เขียนโค้ด
Puppeteer
- แพลตฟอร์ม: ไลบรารี Node.js (โอเพ่นซอร์ส)
- เหมาะกับ: นักพัฒนาที่ต้องสแครปเว็บไดนามิก/หนัก JavaScript
- ฟีเจอร์หลัก: ออโตเมชันเบราว์เซอร์แบบ headless คุมการนำทางและการดึงข้อมูลได้เต็ม
- แพ็กเกจฟรี: ไม่จำกัด (โอเพ่นซอร์ส)
- ข้อจำกัด: ต้องเขียน JavaScript ไม่มี GUI
Selenium
- แพลตฟอร์ม: หลายภาษา (Python, Java ฯลฯ), โอเพ่นซอร์ส
- เหมาะกับ: นักพัฒนาที่ทำออโตเมชันเบราว์เซอร์เพื่อสแครปหรือเทสต์
- ฟีเจอร์หลัก: รองรับหลายเบราว์เซอร์ ออโตเมตคลิก เลื่อน ล็อกอิน
- แพ็กเกจฟรี: ไม่จำกัด (โอเพ่นซอร์ส)
- ข้อจำกัด: ช้ากว่าไลบรารี headless หลายตัว และต้องเขียนสคริปต์
Zyte (Scrapy Cloud)
- แพลตฟอร์ม: คลาวด์
- เหมาะกับ: นักพัฒนาและทีม ops ที่ต้องดีพลอย Scrapy spider แบบสเกล
- ฟีเจอร์หลัก: โฮสต์ Scrapy, จัดการพร็อกซี, ตั้งเวลางาน
- แพ็กเกจฟรี: 1 spider พร้อมกัน, 1 ชม./งาน, เก็บข้อมูล 7 วัน
- ข้อจำกัด: ตั้งเวลาขั้นสูงไม่ได้ในแพ็กเกจฟรี และต้องมีพื้นฐาน Scrapy
สำหรับทีม & องค์กร
Apify
- แพลตฟอร์ม: คลาวด์
- เหมาะกับ: ทีม ผู้ใช้กึ่งเทคนิค และนักพัฒนาที่อยากได้สแครปเปอร์สำเร็จรูปหรือทำเอง
- ฟีเจอร์หลัก: ตลาด Actor (บอทสำเร็จรูป), ตั้งเวลา, API, อินทิเกรชัน
- แพ็กเกจฟรี: เครดิต $5/เดือน (พอสำหรับงานเล็กๆ), เก็บข้อมูล 7 วัน
- ข้อจำกัด: มี learning curve และการใช้งานถูกจำกัดด้วยเครดิต
SerpAPI
- แพลตฟอร์ม: API
- เหมาะกับ: นักพัฒนาและนักวิเคราะห์ที่ต้องการข้อมูลจากเสิร์ชเอนจิน (Google, Bing, YouTube)
- ฟีเจอร์หลัก: Search APIs, กันบล็อก, ส่งออก JSON แบบมีโครงสร้าง
- แพ็กเกจฟรี: 100 ค้นหา/เดือน
- ข้อจำกัด: ไม่ได้ใช้กับเว็บทั่วไปแบบอิสระ ใช้ผ่าน API เท่านั้น
Diffbot
- แพลตฟอร์ม: API
- เหมาะกับ: นักพัฒนา ทีม AI/ML และองค์กรที่ต้องการข้อมูลเว็บแบบมีโครงสร้างในสเกลใหญ่
- ฟีเจอร์หลัก: ดึงข้อมูลด้วย AI, knowledge graph, API สำหรับบทความ/สินค้า
- แพ็กเกจฟรี: 10,000 เครดิต/เดือน
- ข้อจำกัด: ใช้ผ่าน API เท่านั้น ต้องมีทักษะเทคนิค และมีข้อจำกัดด้านอัตราการเรียกใช้งาน
ข้อจำกัดของแพ็กเกจฟรี: “ฟรี” ของแต่ละเครื่องมือหมายถึงอะไรจริงๆ
พูดตามตรง—คำว่า “ฟรี” บางทีก็แปลว่า “ไม่จำกัดสำหรับงานอดิเรก” หรือ “ให้พอใช้จนติดใจ” เท่านั้น ตารางนี้คือสิ่งที่คุณได้จริงแบบไม่มโน:
| Tool | Pages/Rows per Month | Export Formats | Scheduling | API Access | Notable Free Limits |
|---|---|---|---|---|---|
| Thunderbit | 6 หน้า | Excel, CSV | ไม่ได้ | ไม่ได้ | จำกัด AI suggest fields, ฟรียังส่งออกตรงไป Sheets/Notion ไม่ได้ |
| Browse AI | 50 เครดิต | CSV, Sheets | ได้ | ได้ | 1 เว็บไซต์, 5 robots, เก็บ 15 วัน |
| Octoparse | 50,000 แถว | CSV, Excel, JSON | ไม่ได้ | ไม่ได้ | ใช้ได้เฉพาะเดสก์ท็อป ไม่มีคลาวด์/ตั้งเวลา |
| ParseHub | 200 หน้า/รัน | CSV, Excel, JSON | ไม่ได้ | ไม่ได้ | 5 โปรเจกต์สาธารณะ, ความเร็วช้า |
| Webscraper.io | ไม่จำกัด (โลคอล) | CSV, XLSX | ไม่ได้ | ไม่ได้ | ต้องรันเอง ไม่มีคลาวด์ |
| Apify | เครดิต $5 (~งานเล็ก) | CSV, JSON, Sheets | ได้ | ได้ | เก็บ 7 วัน, จำกัดด้วยเครดิต |
| Scrapy | ไม่จำกัด | CSV, JSON, DB | ไม่ได้ | N/A | ต้องเขียนโค้ด |
| Puppeteer | ไม่จำกัด | ปรับเอง (เขียนโค้ด) | ไม่ได้ | N/A | ต้องเขียนโค้ด |
| Selenium | ไม่จำกัด | ปรับเอง (เขียนโค้ด) | ไม่ได้ | N/A | ต้องเขียนโค้ด |
| Zyte | 1 spider, 1 ชม./งาน | CSV, JSON | จำกัด | ได้ | เก็บ 7 วัน, รันพร้อมกันได้ 1 งาน |
| SerpAPI | 100 ค้นหา | JSON | ไม่ได้ | ได้ | เฉพาะ Search APIs |
| Diffbot | 10,000 เครดิต | JSON | ไม่ได้ | ได้ | API เท่านั้น, จำกัดอัตราการใช้งาน |
สรุปคือ ถ้าคุณอยาก “ลองทำงานจริง” แบบสายธุรกิจ Thunderbit, Browse AI และ Apify คือแพ็กเกจฟรีที่คุ้มและใช้งานได้จริงที่สุด แต่ถ้าต้องทำต่อเนื่องหรือสเกลใหญ่ ยังไงก็ชนเพดานเร็ว และสุดท้ายต้องอัปเกรดหรือย้ายไปสายโอเพ่นซอร์ส/เขียนโค้ดอยู่ดี
เครื่องมือ Data Scraper ไหนเหมาะกับคุณ? (ไกด์ตามประเภทผู้ใช้)
ตารางนี้ช่วยเลือกตามบทบาทและความถนัดด้านเทคได้ไวมาก:
| User Type | Best Tools (Free) | Why |
|---|---|---|
| ไม่เขียนโค้ด (Sales/Marketing) | Thunderbit, Browse AI, Webscraper.io | เรียนรู้ไว คลิกเลือกได้ มี AI ช่วย |
| กึ่งเทคนิค (Ops/Analyst) | Octoparse, ParseHub, Apify, Zyte | พลังมากขึ้น รับมือเว็บซับซ้อนได้ และอาจต่อสคริปต์ได้บ้าง |
| Developer/Engineer | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | คุมได้เต็ม ไม่จำกัด เน้น API |
| ทีม/องค์กร | Apify, Zyte | ทำงานร่วมกัน ตั้งเวลา อินทิเกรชัน |
สถานการณ์สแครปจริง: เทียบความยืดหยุ่นของเครื่องมือ
มาดูว่าแต่ละตัวเอาอยู่แค่ไหนใน 5 สถานการณ์ยอดฮิต:
| Scenario | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| รายการแบบแบ่งหน้า (Paginated) | ง่าย | ง่าย | ปานกลาง | ปานกลาง | ปานกลาง | ง่าย | ง่าย | ง่าย | ง่าย | ง่าย | N/A | ปานกลาง |
| รายชื่อบน Google Maps | ง่าย* | ยาก | ปานกลาง | ปานกลาง | ยาก | ง่าย | ยาก | ยาก | ยาก | ยาก | ง่าย | N/A |
| หน้าที่ต้องล็อกอิน | ง่าย | ปานกลาง | ปานกลาง | ปานกลาง | ทำมือ | ปานกลาง | ง่าย | ง่าย | ง่าย | ง่าย | N/A | N/A |
| ดึงข้อมูลจาก PDF | ง่าย | ไม่ได้ | ไม่ได้ | ไม่ได้ | ไม่ได้ | ปานกลาง | ยาก | ยาก | ยาก | ยาก | ไม่ได้ | จำกัด |
| คอนเทนต์โซเชียลมีเดีย | ง่าย* | บางส่วน | ยาก | ยาก | ยาก | ง่าย | ยาก | ยาก | ยาก | ยาก | YouTube | จำกัด |
- Thunderbit และ Apify มีเทมเพลต/actor สำเร็จรูปสำหรับ Google Maps และโซเชียล ทำให้เคสพวกนี้ง่ายขึ้นมากสำหรับคนที่ไม่ใช่สายเทคนิค
ส่วนขยาย vs เดสก์ท็อป vs คลาวด์: ประสบการณ์ใช้งานแบบไหนดีที่สุด
- ส่วนขยาย Chrome (Thunderbit, Webscraper.io):
- ข้อดี: เริ่มไว ทำในเบราว์เซอร์ ตั้งค่าน้อย
- ข้อเสีย: มักต้องทำเอง และเว็บเปลี่ยนโครงสร้างทีอาจพังได้ จำกัดด้านออโตเมชัน
- จุดแข็งของ Thunderbit: มี AI ช่วยรับมือโครงสร้างเปลี่ยน นำทางซับเพจ และยังสแครป PDF/รูปได้ เลยทนทานกว่าเอ็กซ์เทนชันแบบเดิมๆ
- แอปเดสก์ท็อป (Octoparse, ParseHub):
- ข้อดี: พลังสูง เวิร์กโฟลว์แบบภาพ รองรับเว็บไดนามิกและล็อกอิน
- ข้อเสีย: ต้องใช้เวลาเรียนรู้มากกว่า แพ็กเกจฟรีมักไม่มีคลาวด์ออโตเมชัน และขึ้นกับระบบปฏิบัติการ
- แพลตฟอร์มคลาวด์ (Browse AI, Apify, Zyte):
- ข้อดี: ตั้งเวลา ทำงานร่วมกัน สเกลได้ มีอินทิเกรชัน
- ข้อเสีย: แพ็กเกจฟรีมักจำกัดด้วยเครดิต ต้องตั้งค่าเพิ่ม และบางครั้งต้องเข้าใจ API
- ไลบรารีโอเพ่นซอร์ส (Scrapy, Puppeteer, Selenium):
- ข้อดี: ไม่จำกัด ปรับแต่งได้ เหมาะกับ dev
- ข้อเสีย: ต้องเขียนโค้ด ไม่เหมาะกับผู้ใช้สายธุรกิจ
เทรนด์ Web Scraping ปี 2026: อะไรทำให้เครื่องมือยุคใหม่ต่างออกไป
Web scraping ในปี 2026 โฟกัสหนักไปที่ AI ออโตเมชัน และการเชื่อมต่อเครื่องมือ นี่คือสิ่งที่เด่นขึ้นชัดๆ:
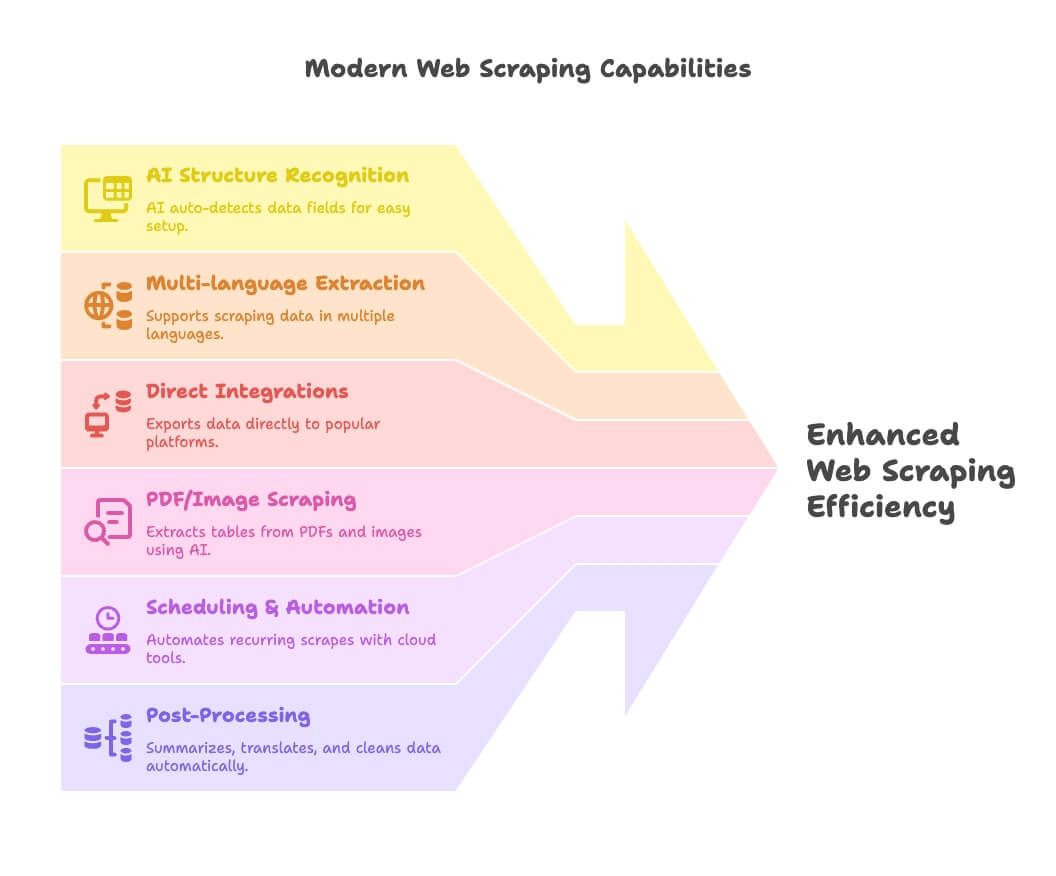
- AI อ่านโครงสร้างหน้าเว็บ: เครื่องมืออย่าง Thunderbit ใช้ AI ตรวจจับฟิลด์ข้อมูลอัตโนมัติ ทำให้คนไม่เขียนโค้ดตั้งค่าได้ง่ายมาก
- ดึงข้อมูลหลายภาษา: Thunderbit และบางเครื่องมือรองรับการสแครป/ประมวลผลหลายสิบภาษา
- อินทิเกรชันตรง: ส่งข้อมูลไป Google Sheets, Notion หรือ Airtable ได้ทันที ไม่ต้องมานั่งจัด CSV
- สแครป PDF/รูปภาพ: Thunderbit เด่นสุดในจุดนี้ เพราะดึงตารางจาก PDF และรูปด้วย AI ได้
- ตั้งเวลา & ออโตเมชัน: เครื่องมือคลาวด์ (Apify, Browse AI) ทำงานแบบตั้งแล้วลืมได้
- Post-Processing: สรุป แปล จัดหมวดหมู่ และทำความสะอาดข้อมูลระหว่างสแครป ลดปัญหาสเปรดชีตเละๆ
Thunderbit, Apify และ SerpAPI อยู่แนวหน้าของเทรนด์พวกนี้ แต่ Thunderbit เด่นตรงที่ทำให้การสแครปด้วย AI เข้าถึงได้สำหรับทุกคน ไม่ใช่เฉพาะนักพัฒนา
มากกว่าการสแครป: การประมวลผลข้อมูลและฟีเจอร์เพิ่มมูลค่า
ไม่ใช่แค่ “ดึงข้อมูลมา” แล้วจบ แต่ต้องทำให้ “เอาไปใช้ได้จริง” ด้วย ตารางนี้คือภาพรวมด้าน post-processing:
| Tool | Cleaning | Translation | Categorization | Summarization | Notes |
|---|---|---|---|---|---|
| Thunderbit | ได้ | ได้ | ได้ | ได้ | มี AI post-processing ในตัว |
| Apify | บางส่วน | บางส่วน | บางส่วน | บางส่วน | ขึ้นกับ actor ที่ใช้ |
| Browse AI | ไม่ได้ | ไม่ได้ | ไม่ได้ | ไม่ได้ | ได้ข้อมูลดิบเท่านั้น |
| Octoparse | บางส่วน | ไม่ได้ | บางส่วน | ไม่ได้ | มีการประมวลผลบางฟิลด์ |
| ParseHub | บางส่วน | ไม่ได้ | บางส่วน | ไม่ได้ | มีการประมวลผลบางฟิลด์ |
| Webscraper.io | ไม่ได้ | ไม่ได้ | ไม่ได้ | ไม่ได้ | ได้ข้อมูลดิบเท่านั้น |
| Scrapy | ได้* | ได้* | ได้* | ได้* | ถ้านักพัฒนาเขียนเพิ่ม |
| Puppeteer | ได้* | ได้* | ได้* | ได้* | ถ้านักพัฒนาเขียนเพิ่ม |
| Selenium | ได้* | ได้* | ได้* | ได้* | ถ้านักพัฒนาเขียนเพิ่ม |
| Zyte | บางส่วน | ไม่ได้ | บางส่วน | ไม่ได้ | มีฟีเจอร์ auto-extraction บางอย่าง |
| SerpAPI | ไม่ได้ | ไม่ได้ | ไม่ได้ | ไม่ได้ | ได้เฉพาะข้อมูลเสิร์ชแบบมีโครงสร้าง |
| Diffbot | ได้ | ได้ | ได้ | ได้ | ขับเคลื่อนด้วย AI แต่เป็น API เท่านั้น |
- *นักพัฒนาต้องเขียนตรรกะการประมวลผลเอง
Thunderbit เป็นเครื่องมือเดียวที่ทำให้คนไม่สายเทคนิคขยับจากข้อมูลเว็บดิบๆ ไปเป็น insight ที่จัดรูปแบบพร้อมใช้งานได้ในเวิร์กโฟลว์เดียว
ชุมชน ซัพพอร์ต และแหล่งเรียนรู้: เริ่มต้นให้ไว
เอกสารและ onboarding สำคัญมาก ตารางนี้คือภาพรวม:
| Tool | Docs & Tutorials | Community | Templates | Learning Curve |
|---|---|---|---|---|
| Thunderbit | ยอดเยี่ยม | กำลังเติบโต | มี | ต่ำมาก |
| Browse AI | ดี | ดี | มี | ต่ำ |
| Octoparse | ยอดเยี่ยม | ใหญ่ | มี | ปานกลาง |
| ParseHub | ยอดเยี่ยม | ใหญ่ | มี | ปานกลาง |
| Webscraper.io | ดี | ฟอรั่ม | มี | ปานกลาง |
| Apify | ยอดเยี่ยม | ใหญ่ | มี | ปานกลาง-สูง |
| Scrapy | ยอดเยี่ยม | ใหญ่มาก | N/A | สูง |
| Puppeteer | ดี | ใหญ่ | N/A | สูง |
| Selenium | ดี | ใหญ่มาก | N/A | สูง |
| Zyte | ดี | ใหญ่ | มี | ปานกลาง-สูง |
| SerpAPI | ดี | ปานกลาง | N/A | สูง |
| Diffbot | ดี | ปานกลาง | N/A | สูง |
Thunderbit และ Browse AI เหมาะกับมือใหม่ที่สุด Octoparse และ ParseHub มีทรัพยากรดีแต่ต้องใช้ความอดทนมากขึ้น ส่วน Apify และเครื่องมือสาย dev เรียนยากกว่าแต่เอกสารค่อนข้างครบ
สรุป: เลือก Data Scraper ฟรีที่ใช่สำหรับปี 2026
สรุปให้ชัดๆ: เครื่องมือ Data Scraper “ฟรี” ไม่ได้เท่ากันทั้งหมด และตัวเลือกที่ใช่ควรขึ้นกับบทบาท ความถนัดด้านเทค และงานที่คุณต้องทำจริง
- ถ้าคุณเป็นผู้ใช้สายธุรกิจหรือคนไม่เขียนโค้ด ที่อยากได้ข้อมูลเร็ว โดยเฉพาะจากเว็บที่จุกจิก PDF หรือรูปภาพ—เริ่มที่ Thunderbit ดีที่สุด แนวทางที่ขับเคลื่อนด้วย AI พรอมป์ต์ภาษาคน และฟีเจอร์ post-processing ทำให้มันใกล้เคียง “ผู้ช่วยข้อมูล AI” ที่ใช้งานได้จริง ลอง ฟรี แล้วคุณจะเห็นว่าจาก “ฉันต้องการข้อมูลนี้” ไปเป็น “นี่คือสเปรดชีตของฉัน” ได้เร็วแค่ไหน
- ถ้าคุณเป็นนักพัฒนา หรืออยากได้ความยืดหยุ่น/ไม่จำกัดแบบปรับแต่งได้ เครื่องมือโอเพ่นซอร์สอย่าง Scrapy, Puppeteer และ Selenium คือคำตอบ
- ถ้าคุณทำงานเป็นทีม หรือเป็นผู้ใช้กึ่งเทคนิค Apify และ Zyte ให้โซลูชันที่สเกลได้ ทำงานร่วมกันได้ และมีแพ็กเกจฟรีที่พอสำหรับงานเล็กๆ
ไม่ว่าคุณทำงานแบบไหน เริ่มจากเครื่องมือที่เข้ากับทักษะและความต้องการของคุณไว้ก่อน และจำไว้ว่าในปี 2026 คุณไม่จำเป็นต้องเป็นโปรแกรมเมอร์ถึงจะใช้พลังของข้อมูลบนเว็บได้—แค่มีผู้ช่วยที่ถูกตัว (และอาจต้องมีอารมณ์ขันนิดหน่อยเวลาบอททำงานไวกว่าเรา)
อยากอ่านต่อ? ดูไกด์และบทความเปรียบเทียบเพิ่มเติมได้ที่ เช่น: