
ทุกวันนี้ เว็บไซต์ไม่ได้เป็นแค่พื้นที่เล่นสนุกในโลกออนไลน์อีกต่อไป แต่กลายเป็นขุมทรัพย์ข้อมูลขนาดมหึมาที่ทั้งทีมเซลส์และนักวิเคราะห์ตลาดต่างแห่กันมาใช้ประโยชน์กันสุดตัว แต่พูดกันแบบตรงไปตรงมา การเก็บข้อมูลจากเว็บด้วยมือก็เหมือนประกอบเฟอร์นิเจอร์ IKEA โดยไม่มีคู่มือ แถมยังเหลือน็อตเต็มไปหมด! ในยุคที่ธุรกิจต้องการข้อมูลตลาดแบบเรียลไทม์ ตั้งราคาสู้คู่แข่ง และล่าลูกค้าใหม่ เครื่องมือดึงข้อมูลที่ทั้งแม่นยำและไว้ใจได้จึงกลายเป็นของจำเป็นมากกว่าที่เคย มีรายงานว่า เพื่อขับเคลื่อนการตัดสินใจ และตลาดเว็บ 스크래퍼 ทั่วโลกก็กำลังโตวันโตคืน คาดว่าจะ .
ถ้าคุณเบื่อกับการก็อปวางข้อมูลทีละบรรทัด พลาดโอกาสหาลูกค้าใหม่ หรืออยากรู้ว่าปล่อยให้ระบบอัตโนมัติช่วยงานจะเปลี่ยนชีวิตยังไง คุณมาถูกที่แล้ว ผมใช้เวลาหลายปีในการสร้างและทดสอบเครื่องมือดึงข้อมูล (และเป็นหัวหน้าทีมที่ ) เลยรู้ดีว่าเครื่องมือที่ใช่สามารถเปลี่ยนงานน่าเบื่อที่กินเวลาหลายชั่วโมงให้เหลือแค่คลิกเดียว ไม่ว่าคุณจะไม่มีพื้นฐานโค้ดเลย หรือเป็นสาย dev ที่อยากคุมทุกขั้นตอน รายการ 10 เครื่องมือดึงข้อมูลที่ดีที่สุดนี้จะช่วยให้คุณเจอคู่แท้แน่นอน
ทำไมการเลือกเครื่องมือดึงข้อมูลที่เหมาะสมจึงสำคัญ
ความต่างระหว่างเครื่องมือดึงข้อมูลที่ดี กับเครื่องมือธรรมดา ไม่ใช่แค่เรื่องความสะดวก แต่ส่งผลโดยตรงต่อการเติบโตของธุรกิจ การใช้ระบบอัตโนมัติช่วยดึงข้อมูลจากเว็บ ไม่ได้แค่ประหยัดเวลา (มีรีวิวใน G2 บอกว่า ) แต่ยังลดข้อผิดพลาด เปิดโอกาสใหม่ ๆ และทำให้ทีมของคุณได้ข้อมูลที่สดใหม่และแม่นยำอยู่เสมอ การค้นหาข้อมูลด้วยมือช้า เสี่ยงผิดพลาด และมักล้าสมัยตั้งแต่ยังไม่เสร็จงาน แต่ถ้าใช้เครื่องมือที่เหมาะสม คุณจะติดตามคู่แข่ง อัปเดตราคา หรือสร้างรายชื่อลูกค้าได้ในไม่กี่นาที
ตัวอย่างจริง: ร้านเครื่องสำอางแห่งหนึ่งใช้เว็บ 스크래퍼 เพื่อติดตามสต็อกและราคาคู่แข่ง นี่คือผลลัพธ์ที่คุณไม่มีวันได้จากแค่สเปรดชีตกับแรงงานคน
วิธีที่เราเลือกเครื่องมือดึงข้อมูลที่ดีที่สุด
ตัวเลือกเยอะจนเลือกไม่ถูก ผมเลยใช้เกณฑ์เหล่านี้ในการคัดเครื่องมือที่โดดเด่นที่สุด:
- ใช้งานง่าย: เริ่มต้นได้โดยไม่ต้องเป็นเซียน Python มีหน้าตาแบบลากวางหรือ AI ช่วยเหลือสำหรับคนไม่เขียนโค้ดไหม?
- ความสามารถอัตโนมัติ: จัดการหน้าเพจย่อย เนื้อหาไดนามิก ตั้งเวลาทำงาน และรันบนคลาวด์ได้หรือเปล่า?
- ราคาและการขยายขนาด: มีแพ็กเกจฟรีหรือราคาย่อมเยาไหม? ถ้าต้องการข้อมูลมากขึ้น ราคาจะเพิ่มแค่ไหน?
- ฟีเจอร์และการเชื่อมต่อ: ส่งออกข้อมูลไป Excel, Google Sheets, API ได้ไหม? มีเทมเพลต ตั้งเวลา หรือฟีเจอร์ทำความสะอาดข้อมูลในตัวหรือเปล่า?
- เหมาะกับใคร: เครื่องมือนี้ออกแบบมาเพื่อใคร—ผู้ใช้ธุรกิจ นักพัฒนา หรือทีมองค์กร?
ท้ายบทความมีตารางเปรียบเทียบให้ดูง่าย ๆ ว่าแต่ละเครื่องมือเด่นด้านไหน
ต่อไปนี้คือ 10 เครื่องมือดึงข้อมูลจากเว็บที่ดีที่สุดสำหรับปี 2025
1. Thunderbit
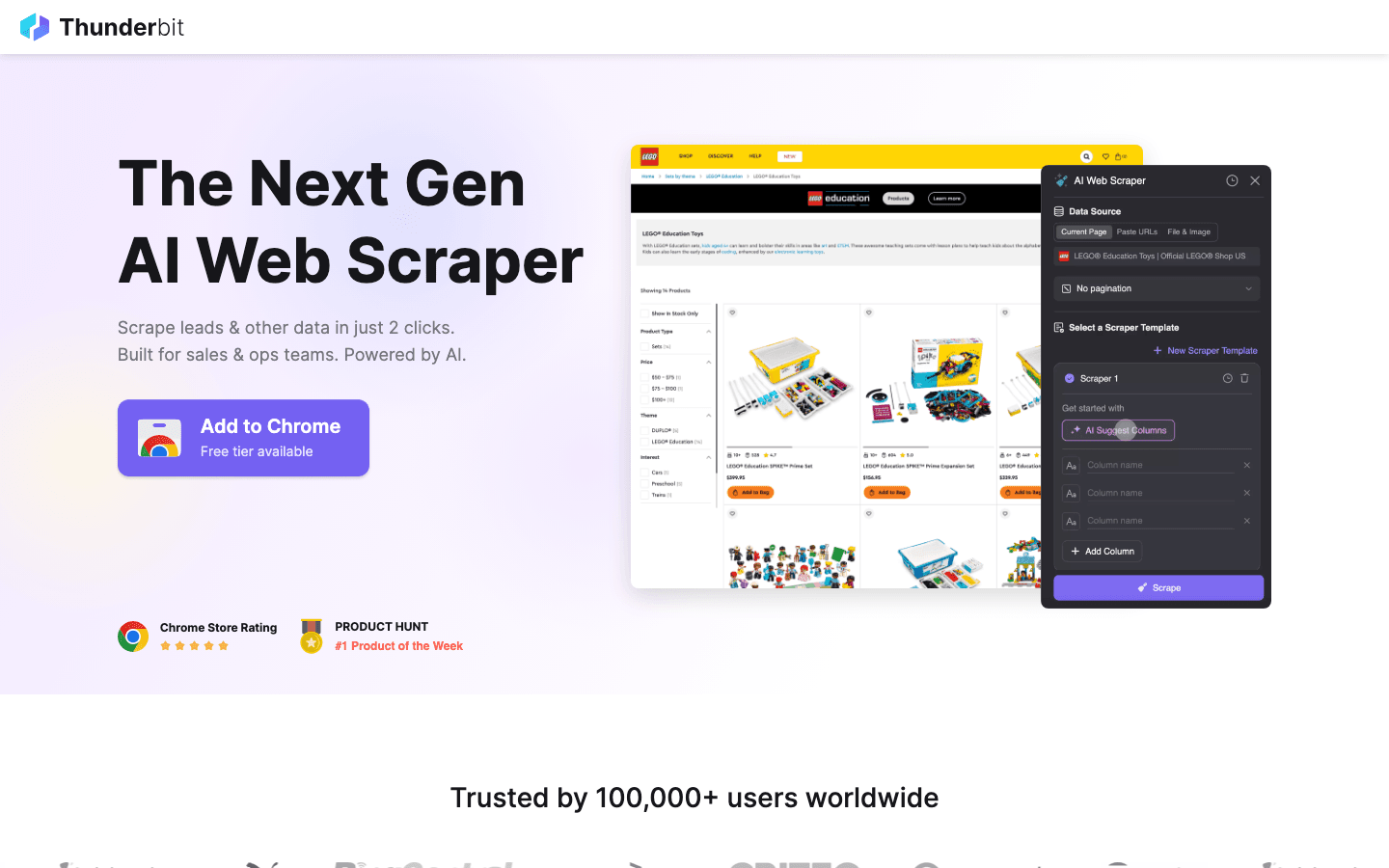 คือคำแนะนำอันดับหนึ่งสำหรับใครที่อยากดึงข้อมูลจากเว็บให้ง่ายเหมือนสั่งอาหารออนไลน์ ด้วยปลั๊กอิน Chrome ที่ขับเคลื่อนด้วย AI Thunderbit เน้นความง่ายแบบ คลิก 2 ครั้ง: แค่กด “AI Suggest Fields” ให้ AI วิเคราะห์ข้อมูลในหน้าเว็บ แล้วคลิก “Scrape” เพื่อดึงข้อมูลออกมา ไม่ต้องเขียนโค้ด ไม่ต้องตั้งค่าซับซ้อน ได้ผลลัพธ์ทันที
คือคำแนะนำอันดับหนึ่งสำหรับใครที่อยากดึงข้อมูลจากเว็บให้ง่ายเหมือนสั่งอาหารออนไลน์ ด้วยปลั๊กอิน Chrome ที่ขับเคลื่อนด้วย AI Thunderbit เน้นความง่ายแบบ คลิก 2 ครั้ง: แค่กด “AI Suggest Fields” ให้ AI วิเคราะห์ข้อมูลในหน้าเว็บ แล้วคลิก “Scrape” เพื่อดึงข้อมูลออกมา ไม่ต้องเขียนโค้ด ไม่ต้องตั้งค่าซับซ้อน ได้ผลลัพธ์ทันที
ทำไม Thunderbit ถึงถูกใจทีมขาย การตลาด และอีคอมเมิร์ซ? เพราะออกแบบมาเพื่อการใช้งานจริงในธุรกิจ:
- AI Suggest Fields: AI อ่านหน้าเว็บแล้วแนะนำคอลัมน์ที่ควรดึง เช่น ชื่อ ราคา อีเมล ฯลฯ
- ดึงข้อมูลจากเพจย่อย: ถ้าต้องการรายละเอียดเพิ่ม Thunderbit จะเข้าไปยังเพจย่อย (เช่น หน้าสินค้าหรือโปรไฟล์ LinkedIn) แล้วเติมข้อมูลให้อัตโนมัติ
- ส่งออกทันที: ส่งข้อมูลไป Excel, Google Sheets, Airtable หรือ Notion ได้ฟรี
- เทมเพลตสำเร็จรูป: สำหรับเว็บยอดนิยม (Amazon, Zillow, Instagram) มีเทมเพลตให้ใช้ทันที
- ส่งออกข้อมูลฟรี: ไม่มีค่าใช้จ่ายแอบแฝงในการดึงข้อมูลออก
- ตั้งเวลาทำงาน: ตั้งให้ดึงข้อมูลซ้ำ ๆ ได้ เช่น “ทุกวันจันทร์ 9 โมง” เหมาะกับการติดตามราคา หรืออัปเดตรายชื่อลูกค้า
Thunderbit ใช้ระบบเครดิต (1 เครดิต = 1 แถวข้อมูล) โดยมี สำหรับ 6 หน้า (หรือ 10 หน้าหากใช้โปรโมชันทดลอง) แพ็กเกจเริ่มต้นเพียง $15/เดือน สำหรับ 500 เครดิต เหมาะกับทุกขนาดทีม
อยากเห็น Thunderbit ใช้งานจริง ดูได้ที่ หรือ ของเรา นี่คือเครื่องมือที่ผมอยากมีตั้งแต่สมัยต้องกรอกข้อมูลเอง
2. Octoparse
 เป็นเครื่องมือดึงข้อมูลระดับองค์กรที่เน้นพลังและความยืดหยุ่น มีอินเทอร์เฟซแบบลากวาง (รองรับ Windows และ Mac) ให้คุณสร้างเวิร์กโฟลว์ดึงข้อมูลได้โดยไม่ต้องเขียนโค้ด แต่เบื้องหลัง Octoparse จัดการทั้งล็อกอิน สกรอลล์ไม่รู้จบ พร็อกซีหมุนเวียน และแก้ CAPTCHA ได้ด้วย
เป็นเครื่องมือดึงข้อมูลระดับองค์กรที่เน้นพลังและความยืดหยุ่น มีอินเทอร์เฟซแบบลากวาง (รองรับ Windows และ Mac) ให้คุณสร้างเวิร์กโฟลว์ดึงข้อมูลได้โดยไม่ต้องเขียนโค้ด แต่เบื้องหลัง Octoparse จัดการทั้งล็อกอิน สกรอลล์ไม่รู้จบ พร็อกซีหมุนเวียน และแก้ CAPTCHA ได้ด้วย
- เทมเพลตสำเร็จรูปกว่า 500 แบบ: เริ่มต้นเร็วกับเทมเพลตสำหรับ Amazon, Twitter, LinkedIn ฯลฯ
- ดึงข้อมูลบนคลาวด์: รันงานบนเซิร์ฟเวอร์ Octoparse ตั้งเวลา และขยายขนาดได้
- API เชื่อมต่อ: ส่งข้อมูลเข้าแอปหรือฐานข้อมูลของคุณโดยตรง
- ระบบอัตโนมัติขั้นสูง: จัดการเนื้อหาไดนามิก การแบ่งหน้า และเวิร์กโฟลว์หลายขั้นตอน
มี สำหรับ 10 งาน แต่ธุรกิจส่วนใหญ่จะเลือก Standard (~$83/เดือน) หรือ Professional (~$299/เดือน) แม้จะต้องเรียนรู้เพิ่มขึ้นบ้าง แต่ถ้าต้องดึงข้อมูลจำนวนมาก Octoparse คือหนึ่งในตัวเลือกที่ดีที่สุด
3. Scrapy
 คือมาตรฐานทองคำสำหรับนักพัฒนาที่ต้องการควบคุมทุกขั้นตอนของการดึงข้อมูล เป็นเฟรมเวิร์ก Python แบบโอเพ่นซอร์สที่ให้คุณเขียนโค้ดสร้างสไปเดอร์ (crawler) ได้ตามใจชอบ
คือมาตรฐานทองคำสำหรับนักพัฒนาที่ต้องการควบคุมทุกขั้นตอนของการดึงข้อมูล เป็นเฟรมเวิร์ก Python แบบโอเพ่นซอร์สที่ให้คุณเขียนโค้ดสร้างสไปเดอร์ (crawler) ได้ตามใจชอบ
- ปรับแต่งได้เต็มที่: เขียน Python เพื่อกำหนดวิธีดึงและแยกข้อมูลจากเว็บใดก็ได้
- เร็วและรองรับงานขนาดใหญ่: ดึงข้อมูลหลายพันหน้าแบบขนาน
- ขยายฟีเจอร์ได้: เพิ่มมิดเดิลแวร์สำหรับพร็อกซี เบราว์เซอร์ไร้หัว หรือฟังก์ชันพิเศษ
- ชุมชนแข็งแกร่ง: มีคู่มือ ปลั๊กอิน และตัวอย่างมากมาย
Scrapy ฟรีและโอเพ่นซอร์ส แต่ต้องมีทักษะเขียนโปรแกรม เหมาะกับทีมเทคนิคหรือโปรเจกต์ที่ต้องการความยืดหยุ่นสูง สำหรับคนไม่เขียนโค้ดอาจจะยากไป
4. ParseHub
 เป็นเครื่องมือดึงข้อมูลแบบไม่ต้องเขียนโค้ด เหมาะกับคนที่ต้องเจอเว็บซับซ้อน อินเทอร์เฟซแบบลากวางช่วยให้เลือกข้อมูล ตั้งค่าการแบ่งหน้า และสร้างเวิร์กโฟลว์ได้ง่าย แม้กับเว็บที่มีเนื้อหาไดนามิกหรือเมนูซับซ้อน
เป็นเครื่องมือดึงข้อมูลแบบไม่ต้องเขียนโค้ด เหมาะกับคนที่ต้องเจอเว็บซับซ้อน อินเทอร์เฟซแบบลากวางช่วยให้เลือกข้อมูล ตั้งค่าการแบ่งหน้า และสร้างเวิร์กโฟลว์ได้ง่าย แม้กับเว็บที่มีเนื้อหาไดนามิกหรือเมนูซับซ้อน
- สร้างเวิร์กโฟลว์ด้วยภาพ: คลิกเลือกข้อมูล ตั้งค่าการแบ่งหน้า จัดการป๊อปอัปหรือดรอปดาวน์
- รองรับเนื้อหาไดนามิก: ใช้ได้กับเว็บที่ใช้ JavaScript หรือมีการโต้ตอบ
- รันบนคลาวด์และตั้งเวลา: ดึงข้อมูลซ้ำ ๆ ได้อัตโนมัติ
- ส่งออกเป็น CSV, Excel หรือ API: เชื่อมต่อกับเครื่องมือที่คุณใช้
ParseHub มีแพ็กเกจฟรี (5 โปรเจกต์) และแบบเสียเงินเริ่มที่ แม้ราคาสูงกว่าคู่แข่งบางราย แต่เหมาะกับนักวิเคราะห์ นักการตลาด และนักวิจัยที่ต้องการมากกว่าแค่ปลั๊กอิน Chrome
5. Apify
 เป็นทั้งแพลตฟอร์มและมาร์เก็ตเพลสสำหรับการดึงข้อมูล มีคลัง “Actors” (สคริปต์ดึงข้อมูลสำเร็จรูป) มากมายสำหรับเว็บยอดนิยม และยังให้คุณสร้าง crawler เองบนคลาวด์ได้ด้วย
เป็นทั้งแพลตฟอร์มและมาร์เก็ตเพลสสำหรับการดึงข้อมูล มีคลัง “Actors” (สคริปต์ดึงข้อมูลสำเร็จรูป) มากมายสำหรับเว็บยอดนิยม และยังให้คุณสร้าง crawler เองบนคลาวด์ได้ด้วย
- Actors สำเร็จรูปกว่า 5,000 รายการ: ดึงข้อมูลจาก Google Maps, Amazon, Twitter ฯลฯ ได้ทันที
- เขียนสคริปต์เอง: นักพัฒนาสามารถใช้ JavaScript หรือ Python สร้าง crawler ขั้นสูง
- ขยายขนาดบนคลาวด์: รันงานพร้อมกัน ตั้งเวลา และจัดการข้อมูลบนคลาวด์
- API และการเชื่อมต่อ: ส่งผลลัพธ์เข้าแอปหรือเวิร์กโฟลว์ของคุณ
Apify มี และแบบเสียเงินเริ่มที่ $29/เดือน (คิดตามการใช้งาน) แม้ต้องเรียนรู้บ้าง แต่ถ้าต้องการทั้งความง่ายและความยืดหยุ่น Apify คือทางเลือกที่ทรงพลัง
6. Data Miner
 เป็นปลั๊กอิน Chrome สำหรับดึงข้อมูลแบบใช้เทมเพลต เหมาะกับผู้ใช้ธุรกิจที่ต้องการดึงข้อมูลจากตารางหรือรายการอย่างรวดเร็ว
เป็นปลั๊กอิน Chrome สำหรับดึงข้อมูลแบบใช้เทมเพลต เหมาะกับผู้ใช้ธุรกิจที่ต้องการดึงข้อมูลจากตารางหรือรายการอย่างรวดเร็ว
- คลังเทมเพลตขนาดใหญ่: มีสูตรสำเร็จกว่าพันแบบสำหรับเว็บยอดนิยม (LinkedIn, Yelp ฯลฯ)
- ดึงข้อมูลแบบคลิกเดียว: เลือกเทมเพลต ดูตัวอย่าง แล้วส่งออกได้ทันที
- ใช้งานผ่านเบราว์เซอร์: ดึงข้อมูลจากเว็บที่ต้องล็อกอินได้
- ส่งออกเป็น CSV หรือ Excel: ได้ข้อมูลในสเปรดชีตในไม่กี่วินาที
รองรับ 500 หน้า/เดือน แบบเสียเงินเริ่มที่ $20/เดือน เหมาะกับงานเล็ก ๆ หรือดึงข้อมูลด่วน ไม่เหมาะกับงานขนาดใหญ่หรืออัตโนมัติซับซ้อน
7. Import.io
 คือแพลตฟอร์มระดับองค์กรสำหรับธุรกิจที่ต้องการข้อมูลเว็บที่สดใหม่และเชื่อถือได้ตลอดเวลา ไม่ใช่แค่ crawler แต่เป็นบริการที่ดูแลทุกขั้นตอนจนได้ข้อมูลที่พร้อมใช้
คือแพลตฟอร์มระดับองค์กรสำหรับธุรกิจที่ต้องการข้อมูลเว็บที่สดใหม่และเชื่อถือได้ตลอดเวลา ไม่ใช่แค่ crawler แต่เป็นบริการที่ดูแลทุกขั้นตอนจนได้ข้อมูลที่พร้อมใช้
- ดึงข้อมูลแบบไม่ต้องเขียนโค้ด: ตั้งค่าด้วยภาพว่าต้องการข้อมูลอะไร
- ฟีดข้อมูลเรียลไทม์: ส่งข้อมูลเข้าแดชบอร์ด เครื่องมือวิเคราะห์ หรือฐานข้อมูล
- รองรับกฎหมายและความน่าเชื่อถือ: จัดการ IP หมุนเวียน ป้องกันบอท และปฏิบัติตามข้อกฎหมาย
- บริการครบวงจร: ทีม Import.io ช่วยตั้งค่าและดูแลระบบให้
ราคาจะเป็นแบบ มีทดลองใช้ SaaS ฟรี 14 วัน เหมาะกับธุรกิจที่ต้องการข้อมูลเว็บสดใหม่ตลอดเวลา เช่น ค้าปลีก การเงิน หรือวิจัยตลาด
8. WebHarvy
 เป็นโปรแกรมสำหรับ Windows ที่เน้นใช้งานง่ายแบบคลิกเลือก เหมาะกับธุรกิจขนาดเล็กหรือผู้ใช้ที่ต้องการซื้อขาดครั้งเดียว
เป็นโปรแกรมสำหรับ Windows ที่เน้นใช้งานง่ายแบบคลิกเลือก เหมาะกับธุรกิจขนาดเล็กหรือผู้ใช้ที่ต้องการซื้อขาดครั้งเดียว
- ตรวจจับรูปแบบข้อมูลอัตโนมัติ: คลิกเลือกข้อมูล WebHarvy จะหาข้อมูลที่ซ้ำกันให้เอง
- ดึงข้อมูลได้หลากหลาย: ทั้งข้อความ รูปภาพ อีเมล ลิงก์ ฯลฯ
- แบ่งหน้าและตั้งเวลา: ดึงข้อมูลจากหลายหน้าและตั้งเวลาทำงานได้
- ส่งออกหลายรูปแบบ: Excel, CSV, XML, JSON, SQL
ไลเซนส์ผู้ใช้เดี่ยว คุ้มค่าสำหรับการใช้งานประจำ แต่รองรับเฉพาะ Windows
9. Mozenda
 เป็นแพลตฟอร์มดึงข้อมูลบนคลาวด์สำหรับธุรกิจที่ต้องการข้อมูลต่อเนื่อง มีทั้งโปรแกรมออกแบบบน Windows และระบบรันงานบนคลาวด์
เป็นแพลตฟอร์มดึงข้อมูลบนคลาวด์สำหรับธุรกิจที่ต้องการข้อมูลต่อเนื่อง มีทั้งโปรแกรมออกแบบบน Windows และระบบรันงานบนคลาวด์
- สร้าง Agent ด้วยภาพ: ออกแบบขั้นตอนดึงข้อมูลแบบคลิกเลือก
- ขยายขนาดบนคลาวด์: รันงานพร้อมกันหลายตัว ตั้งเวลา และจัดการข้อมูลศูนย์กลาง
- คอนโซลจัดการข้อมูล: รวม กรอง และทำความสะอาดข้อมูลหลังดึงเสร็จ
- บริการสำหรับองค์กร: มีผู้จัดการบัญชีและบริการดูแลสำหรับทีมใหญ่
ราคาเริ่มที่ เหมาะกับบริษัทที่ต้องการข้อมูลเว็บที่เชื่อถือได้เป็นประจำ
10. BeautifulSoup
 คือไลบรารี Python สำหรับแยกข้อมูล HTML และ XML แม้จะไม่ใช่ crawler เต็มรูปแบบ แต่เป็นที่นิยมในหมู่นักพัฒนาสำหรับงานขนาดเล็กหรือโปรเจกต์เฉพาะทาง
คือไลบรารี Python สำหรับแยกข้อมูล HTML และ XML แม้จะไม่ใช่ crawler เต็มรูปแบบ แต่เป็นที่นิยมในหมู่นักพัฒนาสำหรับงานขนาดเล็กหรือโปรเจกต์เฉพาะทาง
- แยกข้อมูล HTML ได้ง่าย: ดึงข้อมูลจากเว็บเพจแบบสแตติกได้สะดวก
- ใช้ร่วมกับ Python Requests: ผสานกับไลบรารีอื่นเพื่อดึงและแยกข้อมูล
- ยืดหยุ่นและน้ำหนักเบา: เหมาะกับสคริปต์เล็ก ๆ หรือใช้เพื่อการศึกษา
- ชุมชนใหญ่: มีตัวอย่างและคำตอบใน Stack Overflow เพียบ
BeautifulSoup แต่ต้องเขียนโค้ดและจัดการการดึงข้อมูลเอง เหมาะกับนักพัฒนาหรือผู้เรียนที่อยากเข้าใจการดึงข้อมูลเชิงลึก
ตารางเปรียบเทียบ: เครื่องมือดึงข้อมูลในมุมมองเดียว
| เครื่องมือ | ใช้งานง่าย | ระดับอัตโนมัติ | ราคา | ตัวเลือกส่งออก | เหมาะกับใคร |
|---|---|---|---|---|---|
| Thunderbit | ง่ายมาก ไม่ต้องโค้ด | สูง (AI, เพจย่อย) | ทดลองฟรี, เริ่ม $15/เดือน | Excel, Sheets, Airtable, Notion, CSV | ทีมขาย, การตลาด, อีคอมเมิร์ซ, คนไม่เขียนโค้ด |
| Octoparse | ปานกลาง, UI ภาพ | สูงมาก, คลาวด์ | ฟรี, $83–$299/เดือน | CSV, Excel, JSON, API | องค์กร, ทีมข้อมูล, เว็บไดนามิก |
| Scrapy | ต่ำ (ต้องใช้ Python) | สูง (ปรับแต่งได้) | ฟรี, โอเพ่นซอร์ส | อะไรก็ได้ (ผ่านโค้ด) | นักพัฒนา, โปรเจกต์ขนาดใหญ่ |
| ParseHub | สูง, ภาพ | สูง (เว็บซับซ้อน) | ฟรี, เริ่ม $189/เดือน | CSV, Excel, JSON, API | คนไม่เขียนโค้ด, เว็บซับซ้อน |
| Apify | ปานกลาง, ยืดหยุ่น | สูงมาก, คลาวด์ | ฟรี, $29–$999/เดือน | CSV, JSON, API, คลาวด์สตอเรจ | นักพัฒนา, ธุรกิจ, Actors สำเร็จรูปหรือปรับแต่งเอง |
| Data Miner | ง่ายมาก, เบราว์เซอร์ | ต่ำ (ทำเอง) | ฟรี, $20–$99/เดือน | CSV, Excel | งานด่วน, ข้อมูลน้อย, ดึงข้อมูลเฉพาะกิจ |
| Import.io | ปานกลาง, บริหารจัดการ | สูงมาก, องค์กร | กำหนดเองตามปริมาณ | CSV, JSON, API, เชื่อมต่อโดยตรง | องค์กร, ดึงข้อมูลต่อเนื่อง |
| WebHarvy | สูง, เดสก์ท็อป | กลาง (ตั้งเวลาได้) | $129 จ่ายครั้งเดียว | Excel, CSV, XML, JSON, SQL | SMB, ผู้ใช้ Windows, ใช้งานประจำ |
| Mozenda | ปานกลาง, ภาพ | สูงมาก, คลาวด์ | $250–$450+/เดือน | CSV, Excel, JSON, คลาวด์, ฐานข้อมูล | ธุรกิจที่ต้องการข้อมูลต่อเนื่อง |
| BeautifulSoup | ต่ำ (ต้องใช้ Python) | ต่ำ (ต้องโค้ดเอง) | ฟรี, โอเพ่นซอร์ส | อะไรก็ได้ (ผ่านโค้ด) | นักพัฒนา, ผู้เรียน, สคริปต์ขนาดเล็ก |
วิธีเลือกเครื่องมือดึงข้อมูลที่เหมาะกับทีมของคุณ
การเลือกเครื่องมือดึงข้อมูลที่ดีที่สุด ไม่ใช่แค่หาเครื่องมือที่ทรงพลังที่สุด แต่ต้องเหมาะกับทักษะ ความต้องการ และงบประมาณของทีมคุณ คำแนะนำของผม:
- คนไม่เขียนโค้ดหรือผู้ใช้ธุรกิจ: เริ่มที่ Thunderbit, ParseHub หรือ Data Miner ใช้งานง่าย เห็นผลเร็ว
- องค์กรหรือโปรเจกต์ขนาดใหญ่: Octoparse, Mozenda หรือ Import.io เหมาะกับงานอัตโนมัติ ตั้งเวลา และมีทีมซัพพอร์ต
- นักพัฒนาหรือโปรเจกต์เฉพาะทาง: Scrapy, Apify หรือ BeautifulSoup ให้คุณควบคุมได้เต็มที่
- งบจำกัดหรือใช้งานเฉพาะกิจ: WebHarvy (Windows) หรือ Data Miner (เบราว์เซอร์) ประหยัดและใช้งานง่าย
อย่าลืมทดลองใช้กับเว็บเป้าหมายจริงก่อนตัดสินใจ เพราะเครื่องมือที่เวิร์กกับเว็บหนึ่ง อาจไม่เวิร์กกับอีกเว็บ และถ้าต้องการเชื่อมต่อข้อมูลกับ Sheets, Notion หรือฐานข้อมูล ตรวจสอบให้แน่ใจว่าเครื่องมือรองรับ
สรุป: ปลดล็อกศักยภาพธุรกิจด้วยเครื่องมือดึงข้อมูลที่ใช่
ข้อมูลจากเว็บคือทรัพยากรใหม่ของธุรกิจ แต่จะมีค่าได้ก็ต่อเมื่อคุณมีเครื่องมือที่เหมาะสมในการดึงและแปลงข้อมูลเหล่านั้น เครื่องมือดึงข้อมูลยุคใหม่ช่วยเปลี่ยนงานค้นหาด้วยมือหลายชั่วโมง ให้กลายเป็นข้อมูลพร้อมใช้ในไม่กี่นาที—ช่วยให้ทีมขาย การตลาด และการดำเนินงานคล่องตัวขึ้น ไม่ว่าคุณจะสร้างรายชื่อลูกค้า ติดตามคู่แข่ง หรือแค่เบื่อการก็อปวางข้อมูล รับรองว่ามีเครื่องมือในลิสต์นี้ที่ช่วยให้ชีวิตคุณง่ายขึ้นแน่นอน
ลองสำรวจความต้องการของทีม ทดลองใช้เครื่องมือเหล่านี้ แล้วคุณจะเห็นว่าการปล่อยให้อัตโนมัติช่วยงานจะเพิ่มศักยภาพได้แค่ไหน และถ้าอยากสัมผัสประสบการณ์ดึงข้อมูลด้วย AI แบบคลิกเดียว ขอให้ดึงข้อมูลได้สดใหม่ โครงสร้างดี พร้อมใช้งานเสมอ!
คำถามที่พบบ่อย
1. เครื่องมือดึงข้อมูลคืออะไร และทำไมต้องใช้?
เครื่องมือดึงข้อมูลช่วยให้คุณเก็บข้อมูลจากเว็บไซต์โดยอัตโนมัติ ประหยัดเวลา ลดข้อผิดพลาด และช่วยให้ทีมได้ข้อมูลที่อัปเดตสำหรับงานขาย การตลาด วิจัย และการดำเนินงาน—เร็วกว่าการก็อปวางด้วยมือมาก
2. เครื่องมือไหนเหมาะกับคนไม่เขียนโค้ด?
Thunderbit, ParseHub และ Data Miner คือทางเลือกยอดนิยม Thunderbit เด่นเรื่องเวิร์กโฟลว์ AI คลิกเดียว ส่วน ParseHub เหมาะกับเว็บซับซ้อนที่ต้องการอินเทอร์เฟซภาพ
3. ราคาเครื่องมือดึงข้อมูลแต่ละตัวต่างกันอย่างไร?
แต่ละเครื่องมือมีโมเดลราคาต่างกัน บางตัว (เช่น Thunderbit, Data Miner) มีแพ็กเกจฟรีและรายเดือนราคาย่อมเยา ส่วนแพลตฟอร์มองค์กร (Import.io, Mozenda) จะคิดราคาตามปริมาณหรือแบบกำหนดเอง ควรตรวจสอบให้แน่ใจว่าราคาคุ้มกับปริมาณข้อมูลที่ต้องการ
4. ใช้เครื่องมือเหล่านี้ดึงข้อมูลแบบตั้งเวลาได้ไหม?
ได้—Thunderbit, Octoparse, Apify, Mozenda และ Import.io รองรับการตั้งเวลาหรือดึงข้อมูลซ้ำ เหมาะกับการติดตามราคา หาลูกค้าใหม่ หรือวิจัยตลาดต่อเนื่อง
5. ก่อนเลือกเครื่องมือดึงข้อมูลควรพิจารณาอะไรบ้าง?
ดูทักษะของทีม ความซับซ้อนของเว็บที่ต้องดึงข้อมูล ปริมาณข้อมูลที่ต้องการ การเชื่อมต่อกับระบบอื่น และงบประมาณ ทดลองใช้กับงานจริงก่อนตัดสินใจซื้อ
อ่านบทความและคู่มือเพิ่มเติมได้ที่
อ่านเพิ่มเติม