
Amazon มี และมี อยู่ในแคตตาล็อก ถ้าคุณเคยพยายามก็อปปี้ชื่อสินค้า ราคา เรตติ้ง และ ASIN ลงในสเปรดชีตด้วยตัวเอง คุณจะรู้เลยว่ามันน่าปวดหัวแค่ไหน ยิ่งข้อมูลเยอะ ความปวดหัวก็ยิ่งทวีคูณเร็วมาก
ฉันทำงานที่ ซึ่งเราพัฒนาเครื่องมือดึงข้อมูลเว็บด้วย AI เลยใช้เวลาคิดเรื่องวิธีที่คนดึงข้อมูลจากเว็บไซต์ค่อนข้างเยอะ แต่สำหรับบทความนี้ ฉันอยากลองทำอะไรที่สรุปรวมอื่น ๆ ไม่ค่อยทำกัน: เอาส่วนขยาย Chrome ของจริง 7 ตัวที่ติดตั้งแล้วใช้กับ Amazon ได้มาวางเทียบกัน ทดสอบบนหน้าเดียวกัน และบอกกันตรง ๆ ว่าอะไรใช้ได้ อะไรใช้ไม่ได้ และแต่ละตัวเหมาะกับงานแบบไหน ฉันประเมินแต่ละส่วนขยายด้วย 8 เกณฑ์ที่สะท้อนปัญหาจริงจากฟอรัมและจากผู้ใช้ของเราเอง เช่น การตรวจจับฟิลด์ด้วย AI การดึงข้อมูลจากหน้าย่อย ความเสี่ยงโดนบล็อก แพ็กเกจฟรี และตัวเลือกการส่งออก ถ้าคุณเป็นผู้ขาย Amazon นักการตลาด หรือแค่คนที่เบื่อการคัดลอกวาง คู่มือนี้ทำมาเพื่อคุณ
ทำไมต้องดึงข้อมูลสินค้าจาก Amazon ตั้งแต่แรก?
แล้วใครกันแน่ที่ดึงข้อมูลจาก Amazon และเพื่ออะไร?
คำตอบสั้น ๆ คือแทบทุกคนที่ขาย ทำการตลาด หรือวิจัยสินค้าออนไลน์ Amazon บอกว่า ในร้านมาจากผู้ขายอิสระ และผู้ขายเหล่านี้ก็คอยจับตากันอยู่ตลอด นี่คือกรณีใช้งานที่พบบ่อยที่สุดที่ฉันเจอ:
| กรณีใช้งาน | ใครใช้ | ได้อะไร |
|---|---|---|
| ติดตามราคาคู่แข่ง | ผู้ขาย ทีมกำหนดราคา เอเจนซี | ข้อมูลราคาและสต็อกแบบเรียลไทม์ของสินค้าคู่แข่ง |
| วิจัยสินค้าและติดตามเทรนด์ | ผู้ขาย Amazon นักวิจัยตลาด | มองเห็นหมวดหมู่ที่กำลังโต ผู้เล่นใหม่ และการเปลี่ยนแปลงของความต้องการ |
| วิเคราะห์ความรู้สึกจากรีวิว | ผู้ขายแบรนด์ส่วนตัว ทีมแบรนด์ | ข้อร้องเรียนที่เกิดซ้ำ จุดที่ฟีเจอร์ยังขาด และโอกาสใหม่ ๆ |
| หาลีด (ข้อมูลผู้ติดต่อผู้ขาย) | ทีมขายส่ง เอเจนซี | ชื่อผู้ขาย หน้าร้าน และข้อมูลติดต่อ |
| ติดตามแคตตาล็อกและสต็อก | ทีมปฏิบัติการอีคอมเมิร์ซ การคุ้มครองแบรนด์ | ติดตามระดับสต็อก การเปลี่ยนแปลงลิสต์สินค้า และผู้ขายที่ไม่ได้รับอนุญาต |
| ปรับคีย์เวิร์ดและลิสต์สินค้า | เจ้าของแบรนด์ ผู้ดูแลมาร์เก็ตเพลส | ข้อมูลคำค้น คำโฆษณาลิสต์สินค้า และคีย์เวิร์ดของคู่แข่ง |
ผลตอบแทนคุ้มค่าจับต้องได้จริง กรณีศึกษาของ Amazon เองแสดงให้เห็นว่า หลังจากปรับให้เหมาะกับคำค้นหาหลักโดยใช้ข้อมูลแบบมีโครงสร้าง และ พบว่าพนักงานใช้เวลากว่า 9 ชั่วโมงต่อสัปดาห์กับการป้อนข้อมูลซ้ำ ๆ ถ้าคุณทำให้งานส่วนนี้อัตโนมัติได้ คุณก็จะคืนเวลาให้กับการตัดสินใจจริง ๆ ได้อย่างมหาศาล
อะไรทำให้ส่วนขยาย Chrome สำหรับ Amazon Scraper ดีจริง ๆ? (เกณฑ์ที่ฉันทดสอบ)
ส่วนขยาย Chrome ไม่ได้ดีเท่ากันทุกตัว และบทความเปรียบเทียบส่วนใหญ่ก็มักเอา API แอปเดสก์ท็อป และส่วนขยายบราวเซอร์มารวมกันราวกับใช้แทนกันได้ ทั้งที่จริงไม่ใช่ นี่คือกรอบการทดสอบที่ฉันใช้ และเหตุผลว่าทำไมแต่ละข้อถึงสำคัญ:
- ติดตั้งง่ายแค่ไหน - ผู้ใช้ที่ไม่ถนัดเทคนิคจะได้ผลลัพธ์ภายใน 5 นาทีไหม? (ฟอรัมยืนยันว่าข้อนี้เป็นความกังวลอันดับต้น ๆ)
- การตรวจจับฟิลด์ด้วย AI - เครื่องมือเดาฟิลด์สินค้าให้อัตโนมัติได้ไหม หรือคุณต้องตั้งค่า selector เอง? (แทบไม่มีบทความเปรียบเทียบอื่นพูดถึงประเด็นนี้เลย)
- การดึงข้อมูลหน้าย่อย / หน้ารายละเอียด - เอาข้อมูลจากหน้าลิสต์ไปเติมหน้ารายละเอียดสินค้าได้ในเวิร์กโฟลว์เดียวไหม?
- การรับมือบอท / ความเสี่ยงโดนแบน - มันจัดการกับระบบตรวจจับบอทที่เข้มงวดของ Amazon ยังไง? (เป็น ในฟอรัมผู้ใช้)
- รองรับการแบ่งหน้าไหม - ดึงข้อมูลข้ามหลายหน้าของผลลัพธ์ได้อัตโนมัติหรือไม่?
- แพ็กเกจฟรี / ราคา - ได้อะไรจริง ๆ โดยไม่จ่ายเงิน? (ผู้ใช้ถามเรื่องตัวเลือกฟรีโดยตรง และแทบไม่มีคู่แข่งตอบแบบใช้งานได้จริง)
- ตัวเลือกการส่งออก - CSV, Excel, Google Sheets, Airtable, Notion ได้ไหม?
- การตั้งเวลารันและอัตโนมัติ - ตั้งให้ทำงานเป็นรอบ ๆ ได้ไหม?
ฉันทดสอบส่วนขยายแต่ละตัวบนหน้าผลการค้นหา Amazon US และหน้ารายละเอียดสินค้า โดยใช้คำค้นเดียวกันและเงื่อนไขเดียวกัน

ดึงข้อมูลแบบใช้ AI กับแบบใช้ Selector: ทำไมมันสำคัญกับ Amazon
มีความต่างอย่างหนึ่งที่ไม่มีบทสรุป Amazon scraper เจ้าไหนพูดถึง และนี่แหละคือปัจจัยที่ใหญ่ที่สุดว่าคุณจะต้องคอยดูแล scraper มากแค่ไหน
ส่วนขยาย Chrome scraper ส่วนใหญ่ทำงานโดยจับคู่ CSS selector กับฟิลด์ข้อมูล คุณ (หรือเทมเพลตของเครื่องมือ) ชี้ไปที่ element ของ HTML สำหรับคำว่า “ราคา” หรือ “ชื่อสินค้า” แล้ว scraper ก็จะดึงข้อมูลที่อยู่ตรงนั้นออกมา ปัญหาก็คือ Amazon เปลี่ยน HTML และ CSS พื้นฐาน เพื่อทำให้ scraper ใช้ไม่ได้ ผู้ใช้ในฟอรัมอธิบายว่าชื่อคลาสที่ถูกแฮชหรือเปลี่ยนไปเรื่อย ๆ เป็น
นี่คือภาพเปรียบเทียบแนวทางหลัก 3 แบบ:
| แนวทาง | วิธีทำงาน | เมื่อ Amazon เปลี่ยนเลย์เอาต์ |
|---|---|---|
| ใช้ selector (แบบดั้งเดิม) | ผู้ใช้แมป CSS selector กับฟิลด์เอง | พัง — ผู้ใช้ต้องตั้งค่าใหม่ |
| ใช้เทมเพลต | สูตรสำเร็จที่เตรียมไว้ล่วงหน้าสำหรับหน้า Amazon | พังจนกว่านักพัฒนาจะอัปเดตเทมเพลต |
| ใช้ AI (เช่น Thunderbit) | AI อ่านเนื้อหาหน้าและตรวจจับฟิลด์ให้อัตโนมัติ | ปรับตัวอัตโนมัติ — ไม่ต้องดูแล |
จากส่วนขยายทั้ง 7 ตัวที่ฉันทดสอบ มีแค่ Thunderbit ตัวเดียวที่ใช้การตรวจจับฟิลด์ด้วย AI เป็นเส้นทางตั้งค่าเริ่มต้น ที่เหลือพึ่ง selector หรือเทมเพลต ซึ่งหมายถึงต้องดูแลมากกว่าเมื่อ Amazon ปรับหน้าเว็บอยู่เรื่อย ๆ การเข้าใจความต่างนี้จะช่วยลดความหงุดหงิดได้เยอะในระยะยาว
1. Thunderbit - ส่วนขยาย Chrome สำหรับ Amazon Scraper ที่ขับเคลื่อนด้วย AI
คือเครื่องมือที่เราสร้างขึ้นในบริษัท ดังนั้นขอพูดตรง ๆ ไว้ก่อน แต่ฉันก็เชื่อจริง ๆ ว่านี่คือเครื่องมือที่เหมาะที่สุดสำหรับผู้ใช้ที่ไม่ถนัดเทคนิค และอยากได้ข้อมูล Amazon ที่เร็ว แม่นยำ โดยไม่ต้องมานั่งปวดหัวกับ selector หรือโค้ด
จุดต่างหลักคือ AI Suggest Fields เมื่อคุณเปิดหน้าผลการค้นหา Amazon แล้วกดปุ่ม AI ของ Thunderbit จะอ่านหน้าและเสนอชื่อคอลัมน์ให้อัตโนมัติ เช่น ชื่อสินค้า ราคา เรตติ้ง ASIN จำนวนรีวิว URL สินค้า และอื่น ๆ คุณไม่ต้องตั้งค่าอะไรเลย AI จะดูว่าในหน้ามีอะไรบ้างและเสนอฟิลด์กับชนิดข้อมูลที่เหมาะสมให้
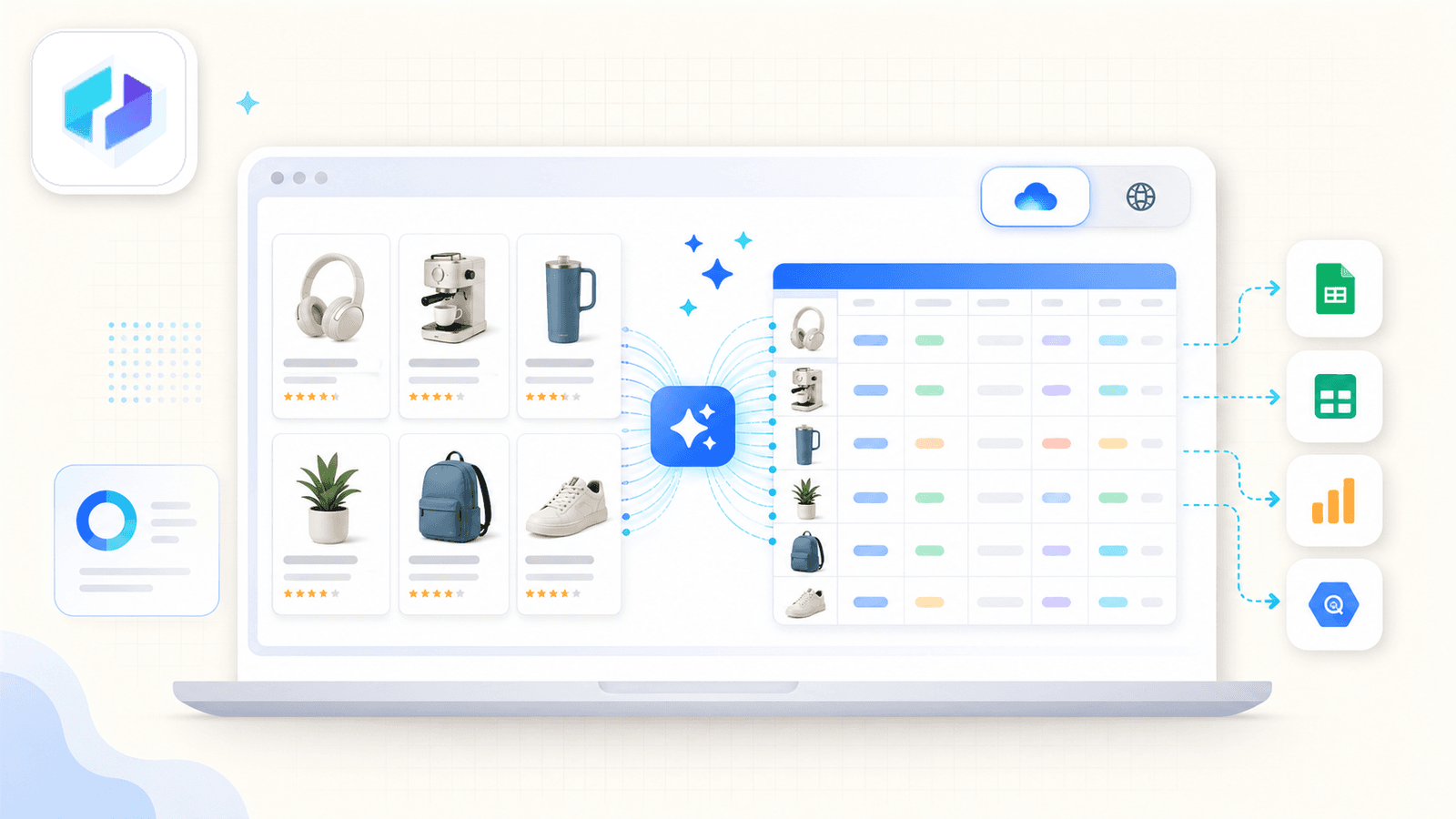
นี่คือลำดับการใช้งานดึงข้อมูล Amazon แบบทั่วไป:
- ติดตั้ง แล้วเปิดหน้าผลการค้นหา Amazon
- กด AI Suggest Fields - AI จะตรวจจับและเสนอคอลัมน์ให้
- กด Scrape - ข้อมูลจะถูกเติมเข้ามาทันที
- สำหรับหน้า Amazon ยอดนิยม คุณยังใช้ ที่เตรียมไว้ล่วงหน้า เพื่อประสบการณ์แบบกดครั้งเดียวจริง ๆ ได้ด้วย
สิ่งที่ทำให้ Thunderbit แตกต่างจริง ๆ คือ การดึงข้อมูลหน้าย่อย หลังจากดึงหน้าลิสต์แล้ว กด Scrape Subpages - Thunderbit จะเข้าไปยัง URL ของสินค้าแต่ละรายการ และเติมข้อมูลรายละเอียด (คำอธิบายฉบับเต็ม จุดเด่นเป็นข้อ ๆ ข้อมูลผู้ขาย URL รูปภาพ) ลงในตารางเดิม ส่วนขยายคู่แข่งส่วนใหญ่ไม่มีฟีเจอร์นี้เลย
ยังมีโหมดสลับ cloud กับ browser ด้วย โหมด cloud ดึงได้พร้อมกันสูงสุด 50 หน้า สำหรับลิสต์สินค้าสาธารณะ ส่วนโหมด browser ใช้เซสชัน Chrome ของคุณเอง เหมาะมากเวลาคุณล็อกอิน Seller Central หรืออยากลดความเสี่ยงการถูกจับได้
การตั้งเวลาอธิบายแบบภาษาคน: แค่บอกช่วงเวลา แล้ว AI จะแปลงเป็นตารางเวลาให้
ตัวเลือกการส่งออกมีทั้ง Excel, Google Sheets, Airtable, Notion, CSV และ JSON — รวมอยู่ในแพ็กเกจฟรีทั้งหมด
ข้อดีและข้อเสียของ Thunderbit
ข้อดี:
- AI ตรวจจับฟิลด์อัตโนมัติ — ไม่ต้องตั้งค่า selector และไม่ต้องคอยดูแลเมื่อ Amazon เปลี่ยนเลย์เอาต์
- เติมข้อมูลจากหน้าย่อยได้ในคลิกเดียว
- สลับ cloud/browser ได้ เพิ่มความยืดหยุ่นและลดความเสี่ยงโดนแบน
- ตัวเลือกการส่งออกครบที่สุด (Sheets, Airtable, Notion, Excel, CSV, JSON)
- ตั้งเวลาทำงานได้ด้วยภาษาธรรมชาติ
- มีเทมเพลต Amazon ที่เตรียมไว้ให้ใช้งานทันที
ข้อเสีย:
- ระบบคิดตามเครดิต ทำให้ผู้ใช้หนัก ๆ ต้องมีแพ็กเกจแบบเสียเงิน
- การตรวจจับฟิลด์ด้วย AI มีขั้นตอนประมวลผลสั้น ๆ เพิ่มเข้ามา (ไม่กี่วินาที)
- เป็นเครื่องมือที่ค่อนข้างใหม่ จึงมีเอกสารชุมชนน้อยกว่าตัวเลือกเก่า ๆ
ราคา Thunderbit
- แพ็กเกจฟรี: 6 หน้า (10 หน้าเมื่อมี trial boost) รวมฟีเจอร์ AI และฟอร์แมตการส่งออกทั้งหมด
- แพ็กเกจเสียเงิน: เริ่มราว 9 ดอลลาร์/เดือน (รายปี) สำหรับ 500 เครดิต; 1 เครดิต = 1 แถวผลลัพธ์
- ดูรายละเอียดล่าสุดได้ที่
2. Instant Data Scraper - ตัวเลือกฟรีแบบไม่เน้นลูกเล่น
Instant Data Scraper เป็นส่วนขยาย Chrome ที่ตรวจจับข้อมูลแบบตารางบนหน้าเว็บโดยอัตโนมัติด้วยอัลกอริทึมแบบ heuristic มันมีมาหลายปีแล้ว และยังคงเป็นหนึ่งใน scraper ฟรีที่ถูกดาวน์โหลดมากที่สุดบน Chrome Web Store
บน Amazon คุณเปิดส่วนขยายบนหน้าผลการค้นหา แล้วมันจะพยายามตรวจจับตารางข้อมูลให้อัตโนมัติ บางครั้งคุณต้องกด “try another table” ถ้าการตรวจจับครั้งแรกไม่ตรงจุด สำหรับงานดึงข้อมูลแบบง่าย ๆ ครั้งคราวเดียว มันก็ใช้งานได้ค่อนข้างโอเค
แต่สำหรับปี 2026 มีข้อควรระวังสำคัญ: หน้า landing page อย่างเป็นทางการระบุแล้วว่า Instant Data Scraper ไม่ได้เป็นของ ไม่ได้พัฒนา และไม่ได้รับการสนับสนุนโดย Web Robots อีกต่อไป นั่นหมายความว่าไม่มีอัปเดต ไม่มีการแก้บั๊ก และไม่มีฟีเจอร์ใหม่ ๆ ใน มี ว่ามันใช้กับหน้า overview ได้ แต่จะติดขัดเมื่อจำเป็นต้องคลิกเข้าไปที่รายละเอียด
ข้อดีและข้อเสียของ Instant Data Scraper
ข้อดี:
- ฟรี 100% ไม่ต้องมีบัญชี
- เบาและเร็วสำหรับตารางง่าย ๆ
- รองรับการแบ่งหน้าแบบพื้นฐาน (กดปุ่ม “Next”)
ข้อเสีย:
- ไม่มีการตรวจจับฟิลด์ด้วย AI (อาศัย pattern matching ซึ่งอาจอ่านเลย์เอาต์ซับซ้อนของ Amazon ผิด)
- ไม่มีการดึงข้อมูลหน้าย่อย
- ส่งออกได้แค่ CSV/Excel
- ไม่มีการตั้งเวลา ไม่มีโหมด cloud
- ไม่ได้รับการดูแลแล้ว — พอ Amazon เปลี่ยนเลย์เอาต์ก็พัง และไม่มีใครแก้
3. Web Scraper - ส่วนขยายรุ่นเก๋าสำหรับการตั้งค่าแบบแมนนวล
Web Scraper เป็นหนึ่งใน scraper แบบส่วนขยาย Chrome ที่อยู่มานานและมีชื่อเสียงที่สุด สร้างบนตัวสร้าง sitemap แบบเห็นภาพ คุณเปิด DevTools สร้าง “sitemap” ด้วยการชี้และคลิกเพื่อกำหนด selector ตั้งค่าการแบ่งหน้า และสามารถตามลิงก์ไปยังหน้ารายละเอียดสินค้าได้
Web Scraper ยังมีเทมเพลต Amazon Products Listings Scraper ใน marketplace ของตัวเอง ซึ่งจัดการเรื่องการนำทาง การแบ่งหน้า และการดึงข้อมูลหน้าสินค้า คู่มือทีละขั้นจะพาคุณผ่านขั้นตอนตั้งค่า 8 ขั้นตอน — ติดตั้ง สร้าง selector ตั้งค่าการแบ่งหน้า ตามลิงก์สินค้า รันบนเครื่องหรือบนคลาวด์
เวอร์ชัน cloud เพิ่มการตั้งเวลา การเข้าถึง API การหมุน proxy การข้าม CAPTCHA และการเชื่อม Google Sheets

ข้อดีและข้อเสียของ Web Scraper
ข้อดี:
- รุ่นเก๋า เอกสารดี และมีชุมชนคอยสนับสนุน
- ส่วนขยายเบราว์เซอร์ใช้ฟรี (ใช้บนเครื่องได้ไม่จำกัด)
- มีเทมเพลตใน marketplace สำหรับ Amazon
- มีตัวเลือก cloud สำหรับขยายการใช้งาน (ตั้งเวลา หมุน IP เชื่อมต่อเครื่องมืออื่น)
- รองรับการตามลิงก์ไปยังหน้ารายละเอียดสินค้า (เติมข้อมูลหน้าย่อยได้บางส่วน)
ข้อเสีย:
- ต้องตั้งค่า selector เอง ทำให้เรียนรู้ยากกว่าสำหรับผู้ใช้ไม่ถนัดเทคนิค
- ไม่มีการตรวจจับฟิลด์ด้วย AI อัตโนมัติ
- เทมเพลตอาจพังเมื่อ Amazon อัปเดตเลย์เอาต์
- ฟีเจอร์ขั้นสูงถูกล็อกไว้ในแพ็กเกจ cloud แบบเสียเงิน
ราคา Web Scraper
- ฟรี: ส่วนขยาย Chrome ใช้งานบนเครื่องได้ไม่จำกัด
- แพ็กเกจ Cloud: เริ่มที่ 50 ดอลลาร์/เดือน (Project), 100 ดอลลาร์/เดือน (Professional), ตั้งแต่ 200 ดอลลาร์/เดือน (Scale)
4. Octoparse - แพลตฟอร์มฟีเจอร์แน่น แต่มีข้อสังเกตเรื่องส่วนขยาย Chrome
Octoparse เป็นแพลตฟอร์มดึงข้อมูลแบบ no-code ที่ทรงพลัง พร้อมเทมเพลต Amazon สำเร็จรูปสำหรับรายละเอียดสินค้า ค้นหาด้วยคีย์เวิร์ด และรีวิว รองรับการดึงข้อมูลบน cloud การตั้งเวลา และเวิร์กโฟลว์หลายขั้นตอน
แต่มีจุดสำคัญที่ต้องเข้าใจ: ส่วนขยาย Chrome Web Store ของ Octoparse ตอนนี้แสดงชื่อว่า Octoparse AI Web Automation และระบุชัดว่าใช้ได้เมื่อทำงานร่วมกับ Octoparse AI Bot บน Windows เท่านั้น ดังนั้นประสบการณ์ดึงข้อมูลจริงจึงเป็นแบบแพลตฟอร์มก่อน ส่วนขยายเป็นตัวช่วยตาม ถ้าคุณกำลังมองหาเวิร์กโฟลว์แบบ “ติดตั้งแล้วใช้ใน Chrome เลย” จริง ๆ Octoparse จะเหมือนแอปเดสก์ท็อปที่มีผู้ช่วยบราวเซอร์มากกว่า
ถึงอย่างนั้น เทมเพลตก็ทำได้ดีมาก คุณใส่ URL ค้นหา Octoparse จะดึงข้อมูลสินค้าให้อัตโนมัติ และคุณสามารถสร้างเวิร์กโฟลว์เองด้วยตัวชี้และคลิก ตั้งค่าการแบ่งหน้า และตามลิงก์ไปยังหน้ารายละเอียดได้
ข้อดีและข้อเสียของ Octoparse
ข้อดี:
- ฟีเจอร์ครบและมีเทมเพลต Amazon
- โหนด cloud ช่วยเรื่องความเร็ว การตั้งเวลา และการดึงข้อมูลหน้าย่อยผ่านเวิร์กโฟลว์
- จัดการการแบ่งหน้าได้ดี
- เหมาะกับไปป์ไลน์การดึงข้อมูลหลายขั้นตอนที่ซับซ้อน
ข้อเสีย:
- การใช้งานเต็มความสามารถต้องพึ่งแอปเดสก์ท็อป — ไม่ใช่ประสบการณ์ส่วนขยาย Chrome แบบล้วน ๆ
- ไม่มีฟิลด์ auto-suggest ด้วย AI (มีผลิตภัณฑ์ Chat4Data แยกต่างหาก แต่เป็นส่วนขยายคนละตัว)
- แพ็กเกจฟรีจำกัดการส่งออกที่ประมาณ 50,000 แถวต่อเดือน และ 10,000 แถวต่อการส่งออกหนึ่งครั้ง
- อินเทอร์เฟซอาจดูซับซ้อนสำหรับมือใหม่
ราคา Octoparse
- ฟรี: จำกัด (ดึงข้อมูลบนเครื่อง, จำกัดการส่งออก 50K)
- Standard: ราว 75-83 ดอลลาร์/เดือน
- Professional: ราว 208-249 ดอลลาร์/เดือน
- ส่วนเสริม: หมุน IP ที่ 3 ดอลลาร์/GB, แก้ CAPTCHA ที่ 2-2.50 ดอลลาร์ต่อ 1,000 ครั้ง
5. Axiom.ai - ตัวสร้างบอทแบบ No-Code
Axiom.ai เป็นส่วนขยาย Chrome สำหรับสร้างบอทอัตโนมัติบนบราวเซอร์ด้วยตัวสร้างแบบเห็นภาพที่ไม่ต้องเขียนโค้ด มันเป็นเครื่องมืออัตโนมัติอเนกประสงค์มากกว่าจะเป็น scraper เฉพาะทาง แต่ก็มีเทมเพลตดึงข้อมูล Amazon และคู่มือการดึง ASIN
คุณสร้างบอทขึ้นมา (หรือหยิบเทมเพลตมาใช้) ที่วนลูปผ่าน URL สินค้าใน Google Sheet เปิดแต่ละหน้า ดึงข้อมูลด้วยตัวชี้และคลิก แล้วเขียนผลกลับไปยังชีต การตั้งเวลามีในแพ็กเกจแบบเสียเงิน และตอนนี้มีการรันบน cloud เริ่มตั้งแต่ 1 บอทใน cloud บนแพ็กเกจ Starter และ Pro ไปจนถึง 20 cloud bots พร้อมกันบน Ultimate
ข้อดีและข้อเสียของ Axiom.ai
ข้อดี:
- อัตโนมัติแบบ no-code ใช้งานได้หลากหลาย ไม่ได้มีไว้แค่ดึงข้อมูล
- เชื่อมต่อกับ Google Sheets ได้แบบเนทีฟ
- มีการตั้งเวลาและรันบน cloud ในแพ็กเกจเสียเงิน
- มีเทมเพลตสำหรับ Amazon
- เหมาะกับเวิร์กโฟลว์หลายขั้นตอนที่มากกว่าการดึงข้อมูล
ข้อเสีย:
- ต้องตั้งค่าค่อนข้างมากสำหรับงานดึงข้อมูลง่าย ๆ (ต้องออกแบบบอท ตั้งค่า Google Sheet ทดสอบลูป)
- ไม่มีการตรวจจับฟิลด์ด้วย AI
- ไม่มีการเติมข้อมูลหน้าย่อยแบบกดครั้งเดียว (ต้องสร้างขั้นตอนบอทแยก)
- ส่งออกได้จำกัดแค่ Google Sheets หรือ CSV
ราคา Axiom.ai
- ฟรี: รันได้ 2 ชั่วโมง
- Starter: 15 ดอลลาร์/เดือน
- Pro: 50 ดอลลาร์/เดือน
- Pro Max: 150 ดอลลาร์/เดือน
- Ultimate: 250 ดอลลาร์/เดือน
6. Data Miner - ส่วนขยายที่ขับเคลื่อนด้วย Recipe
Data Miner เป็นส่วนขยาย Chrome ที่เน้นการดึงข้อมูลด้วย “recipes” ซึ่งเป็นเทมเพลตการสครัปที่กำหนดไว้ล่วงหน้าหรือสร้างเอง คุณค้นหา recipe สำหรับ Amazon ที่มีอยู่ในคลังสาธารณะ หรือสร้างของตัวเองโดยเลือกองค์ประกอบบนหน้าเว็บ
Data Miner รองรับการแบ่งหน้าผ่านฟีเจอร์ Next Page Automation และยังมีเวิร์กโฟลว์ Crawl Scrape สำหรับไปยัง URL รายละเอียดสินค้าและใช้ recipe ตัวที่สอง ดังนั้นมันไม่ใช่ “ไม่มีการดึงหน้าย่อย” แต่เป็นกระบวนการหลายขั้นตอนที่ต้องทำเองมากกว่าเติมข้อมูลแบบคลิกครั้งเดียว
ข้อจำกัดใหญ่คือแพ็กเกจฟรี: 500 หน้า/เดือน และบางโดเมนถูกจำกัดในแพ็กเกจฟรี recipes จะผูกกับแต่ละเว็บไซต์ และเอกสารของ Data Miner เองก็เตือนว่า ถ้าไซต์เปลี่ยนและโค้ด HTML อ้างอิงเปลี่ยนไป recipe จะไม่ทำงาน
ข้อดีและข้อเสียของ Data Miner
ข้อดี:
- ใช้ recipe ที่มีอยู่แล้วได้ง่าย
- มีคลัง recipe จากชุมชน
- รองรับการแบ่งหน้าและการ crawl หน้ารายละเอียด (ต้องตั้งค่าเอง)
- อินเทอร์เฟซเรียบง่าย
ข้อเสีย:
- แพ็กเกจฟรีจำกัด 500 หน้า/เดือน
- ไม่มีการตรวจจับฟิลด์ด้วย AI
- recipe พังเมื่อ Amazon เปลี่ยนเลย์เอาต์
- ไม่มีการดึงข้อมูลบน cloud และไม่มีการตั้งเวลาบนเอกสารสาธารณะ
- ส่งออกได้: CSV, Excel, คลิปบอร์ด; Google Sheets เฉพาะแพ็กเกจเสียเงิน
ราคา Data Miner
- ฟรี: 500 หน้า/เดือน
- เสียเงิน: 19.99, 49, 99, 200 ดอลลาร์/เดือน โดยเพิ่มขีดจำกัดและฟีเจอร์ตามระดับ
7. Helium 10 - ชุดเครื่องมืออินไซต์สำหรับผู้ขาย Amazon
Helium 10 เป็นชุดเครื่องมือแบบครบวงจรสำหรับผู้ขาย Amazon ไม่ใช่เว็บ scraper อเนกประสงค์ ส่วนขยาย Chrome ของมัน (Xray) แสดงข้อมูลซ้อนทับตรงหน้าผลการค้นหา Amazon โดยตรง เช่น ยอดขายโดยประมาณ รายได้ เทรนด์รีวิว BSR และอื่น ๆ มันถูกออกแบบมาสำหรับผู้ขาย Amazon ที่ทำวิจัยสินค้า ไม่ใช่สำหรับดึงข้อมูลดิบจากหน้าเว็บ
Helium 10 มีแพ็กเกจฟรีในปี 2026 แต่การเข้าถึง Chrome Extension มีข้อจำกัดในแพ็กเกจฟรี ส่วนขยายสามารถส่งออกผลลัพธ์เป็น CSV หรือ Excel และรองรับเวิร์กโฟลว์ผ่านคลิปบอร์ด
ข้อดีและข้อเสียของ Helium 10
ข้อดี:
- อินไซต์เฉพาะ Amazon ลึกมาก (ยอดขายโดยประมาณ ข้อมูลคีย์เวิร์ด เทรนด์ BSR)
- ได้รับความไว้วางใจจากผู้ขายมืออาชีพ
- ข้อมูลและการตั้งเวลาบน cloud สำหรับติดตามคีย์เวิร์ด/อันดับ
- มีแพ็กเกจฟรีให้ใช้ (แต่จำกัด)
ข้อเสีย:
- ไม่ใช่ scraper ทั่วไป — ดึงฟิลด์ข้อมูลแบบกำหนดเองจากหน้าอะไรก็ได้ไม่ได้
- ราคาแพงเมื่อเทียบกับเครื่องมือที่โฟกัสดึงข้อมูล
- ฟอร์แมตการส่งออกมีจำกัด (CSV, Excel)
- ไม่มีการตรวจจับฟิลด์ด้วย AI และไม่มีการเติมข้อมูลหน้าย่อยในความหมายของ scraper
ราคา Helium 10
- ฟรี: เข้าถึงได้แบบจำกัด รวมถึง Chrome Extension
- Starter: 49 ดอลลาร์/เดือน
- Platinum: 229 ดอลลาร์/เดือน
- Diamond: 359 ดอลลาร์/เดือน
เปรียบเทียบส่วนขยาย Chrome สำหรับ Amazon Scraper แบบครบทุกด้าน
นี่คือตารางเปรียบเทียบแบบตรงไปตรงมา ฉันได้แก้ความเข้าใจบางจุดจากร่างก่อนหน้าหลังจากทดสอบจริงและยืนยันข้อมูลปี 2026:
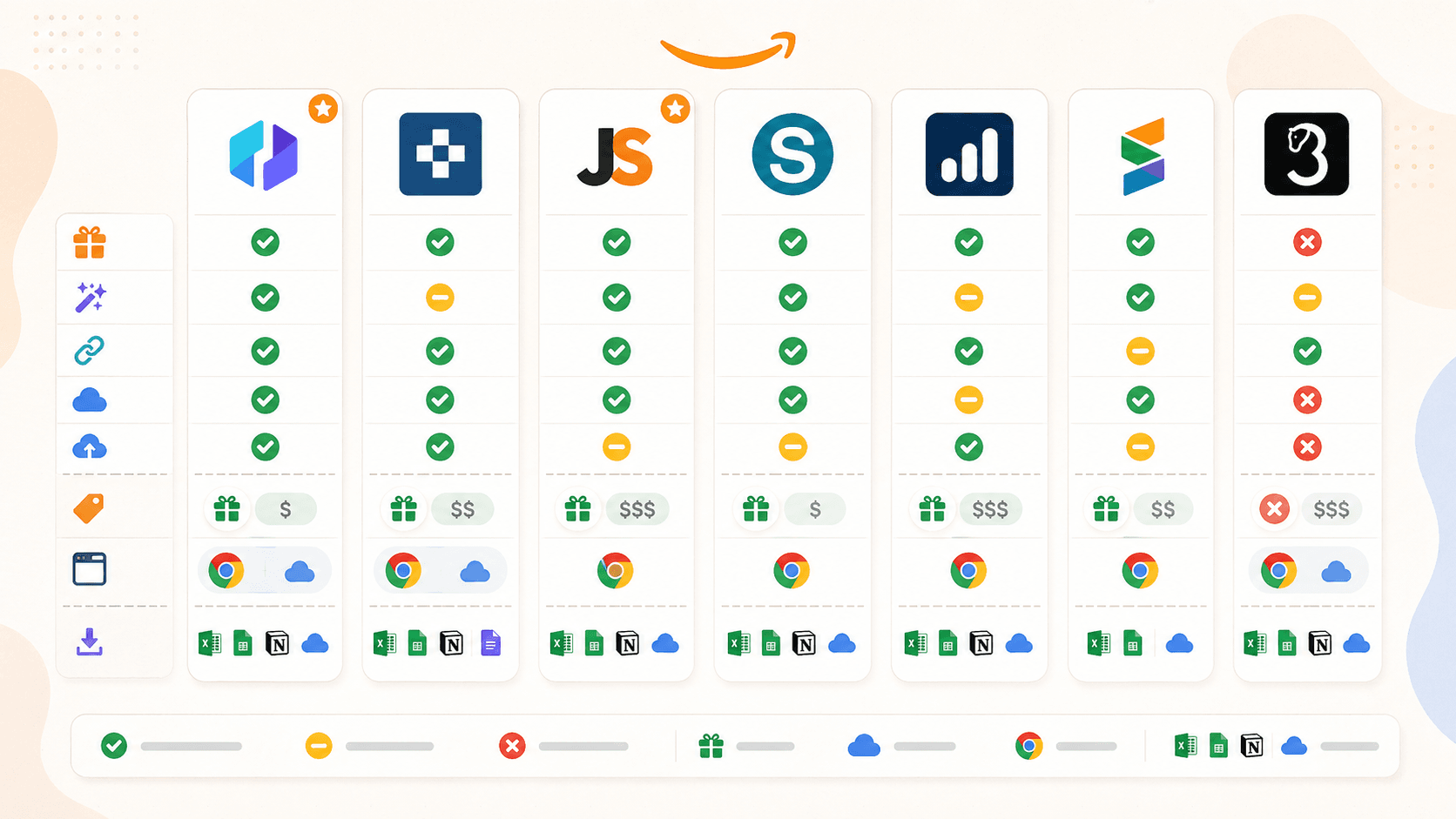
| ฟีเจอร์ | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| หมวดหลัก | ส่วนขยาย scraper แบบ AI | scraper แบบ heuristic ฟรี | scraper แบบ selector/เทมเพลต | แพลตฟอร์มดึงข้อมูล no-code | ตัวสร้างบอทอัตโนมัติบนบราวเซอร์ | ส่วนขยาย scraper แบบ recipe | เลเยอร์อินไซต์สำหรับผู้ขาย |
| ฟิลด์ auto-suggest ด้วย AI | มี | ไม่มี | ไม่มี | ไม่มี (มี Chat4Data แยกต่างหาก) | ไม่มี | ไม่มี | ไม่มี |
| เติมข้อมูลหน้าย่อย | มี (คลิกเดียว) | ไม่มี | มี (sitemap แบบแมนนวล) | มี (workflow) | มี (ขั้นตอนบอทแบบแมนนวล) | มี (crawl แบบแมนนวล) | ไม่รองรับ |
| ดึงข้อมูลบน cloud | มี | ไม่มี | มี (เสียเงิน) | มี (เสียเงิน) | มี (เสียเงิน) | ไม่มี | ข้อมูลวิเคราะห์บน cloud |
| การตั้งเวลา | มี | ไม่มี | มี (เสียเงิน) | มี (เสียเงิน) | มี (เสียเงิน) | ไม่มี | มี (ติดตามคีย์เวิร์ด/อันดับ) |
| แพ็กเกจฟรี | มี (6-10 หน้า) | มี (ฟรีเต็มรูปแบบ) | มี (ใช้บนบราวเซอร์เท่านั้น) | มี (จำกัด) | มี (รันได้ 2 ชม.) | มี (500 หน้า/เดือน) | มี (จำกัด) |
| เทมเพลต Amazon สำเร็จรูป | มี | ไม่มี | มี | มี | มี (คู่มือ) | คลัง recipe | ไม่รองรับ |
| ส่งออกไป Sheets/Airtable/Notion | มี (ครบ) | CSV/Excel เท่านั้น | CSV, Excel, JSON; Sheets ผ่าน cloud | CSV, Excel, JSON และอื่น ๆ | Google Sheets, CSV | CSV, Excel; Sheets ในแพ็กเกจเสียเงิน | CSV, Excel |
มีหลายอย่างที่เด่นชัด Thunderbit เป็นส่วนขยายเดียวที่มีการตรวจจับฟิลด์ด้วย AI และมีตัวเลือกการส่งออกที่หลากหลายที่สุดในแพ็กเกจฟรี Instant Data Scraper เป็นตัวเลือกฟรีที่ง่ายที่สุด แต่ไม่ได้รับการดูแลแล้ว Web Scraper และ Octoparse ทรงพลังสำหรับคนที่พร้อมลงแรงตั้งค่า แต่ก็ไม่ใช่ประสบการณ์แบบ “ติดตั้งแล้วใช้ได้ทันที” Axiom.ai เหมาะที่สุดสำหรับอัตโนมัติแบบหลายขั้นตอนที่มากกว่าการสครัป Data Miner ใช้งาน recipe เดิมได้ง่าย แต่แพ็กเกจฟรีค่อนข้างตึง Helium 10 เป็นเครื่องมืออินไซต์สำหรับผู้ขาย ไม่ใช่ scraper ทั่วไป
ดึงข้อมูล Amazon บน Cloud กับบน Browser: เรื่องความเสี่ยงโดนแบนที่คุณต้องรู้
นี่คือช้างตัวโตในห้อง Amazon ตรวจจับและบล็อกการดึงข้อมูลอัตโนมัติอย่างจริงจัง ผู้ใช้ใน Reddit รายงานว่า และ ระบุชัดว่าใบอนุญาตไม่ได้ครอบคลุม “การใช้ data mining, robots หรือเครื่องมือเก็บและดึงข้อมูลลักษณะคล้ายกัน” ใด ๆ
แล้วความต่างจริง ๆ ระหว่างการสครัปบน browser กับบน cloud คืออะไร?
- Browser scraping ทำงานในเซสชัน Chrome ของคุณเอง — คุกกี้จริง สถานะล็อกอินจริง พฤติกรรมการท่องเว็บธรรมชาติ ดูเหมือนคนมากกว่าเมื่อปริมาณไม่สูง แต่จะกินเบราว์เซอร์ของคุณไปด้วย
- Cloud scraping ใช้เซิร์ฟเวอร์ระยะไกลเพื่อความเร็ว (Thunderbit จัดการได้ 50 หน้าพร้อมกันในโหมด cloud) แต่ต้องมีการจำกัดอัตราและหมุน proxy เพื่อหลีกเลี่ยงการตรวจจับ
นี่คือเมทริกซ์การตัดสินใจที่ฉันใช้:
| สถานการณ์ | โหมดที่แนะนำ | เหตุผล |
|---|---|---|
| ดึงข้อมูลสินค้า 20 หน้าเพื่อวิจัย | Browser | ปริมาณน้อย พฤติกรรมดูเป็นธรรมชาติ |
| ติดตาม SKU ของคู่แข่ง 500 รายการทุกสัปดาห์ | Cloud | ความเร็วสำคัญ และเป็นข้อมูลสาธารณะ |
| ดึงข้อมูลขณะล็อกอิน Seller Central | Browser | ต้องใช้เซสชันล็อกอินของคุณ |
| ส่งออกข้อมูลหมวดหมู่จำนวนมากครั้งเดียว | Cloud | รันแบบขนานเพื่อความเร็ว |
ในบรรดา 7 ส่วนขยาย โหมด cloud มีใน Thunderbit, Web Scraper (เสียเงิน), Octoparse (เสียเงิน), Axiom.ai (เสียเงิน) และ Helium 10 (สำหรับการวิเคราะห์) ส่วน Instant Data Scraper และ Data Miner ใช้ได้เฉพาะบนบราวเซอร์
เคล็ดลับลดความเสี่ยงโดนแบนแบบใช้งานจริง: เว้นช่วงคำขอให้เหมาะสม เลี่ยงการสครัปช่วงชั่วโมงพีค และหมุน user agent ถ้าเครื่องมือของคุณรองรับ และอย่าบอกตัวเองว่า “ปลอดภัย 100%” — แค่บริหารความเสี่ยงให้ดี
จากหน้าลิสต์ไปหน้ารายละเอียดสินค้า: การดึงข้อมูลหน้าย่อยบน Amazon ทำงานยังไง
เวิร์กโฟลว์นี้มักถูกมองข้าม และไม่มีบทความเปรียบเทียบอื่นสาธิตตั้งแต่ต้นจนจบ
เวลาคุณดึงข้อมูลจากหน้าผลการค้นหา Amazon คุณจะได้ข้อมูลสรุป เช่น ชื่อสินค้า ราคา เรตติ้ง ASIN และ URL สินค้า แต่บ่อยครั้งคุณก็ต้องการข้อมูลจากหน้ารายละเอียดด้วย — คำอธิบายเต็ม จุดเด่นเป็นข้อ ๆ URL รูปภาพ ข้อมูลผู้ขาย รายละเอียดการแยกรีวิว นี่คือจุดที่การดึงข้อมูลหน้าย่อยเข้ามามีบทบาท
ด้วย Thunderbit เวิร์กโฟลว์คือ:
- ดึงข้อมูลหน้าผลการค้นหา Amazon -> ได้ตารางสินค้า (ชื่อ ราคา เรตติ้ง ASIN URL สินค้า)
- กด “Scrape Subpages” -> Thunderbit เข้าไปที่ URL ของสินค้าแต่ละรายการ แล้วเติมฟิลด์รายละเอียด (คำอธิบาย จำนวนรีวิว ชื่อผู้ขาย URL รูปภาพ ฯลฯ) ลงในตารางเดิม
- ส่งออกตารางที่เติมข้อมูลแล้ว ไปยัง Google Sheets, Airtable, Notion หรือ Excel
AI จะตรวจจับโครงสร้างของหน้าย่อยและเติมข้อมูลลงตารางให้อัตโนมัติ — ไม่ต้องตั้งค่าเอง จากประสบการณ์ของฉัน วิธีนี้ประหยัดเวลาอย่างน้อยชั่วโมงต่อชุดงาน เมื่อเทียบกับการเปิดหน้าสินค้าแต่ละหน้าแล้วก็อปปี้ฟิลด์เอง
เครื่องมืออื่นก็ทำได้เช่นกัน แต่ต้องใช้แรงมากกว่า:
- Web Scraper: คุณต้องตั้ง sitemap ให้ตามลิงก์สินค้า และกำหนด selector สำหรับแต่ละฟิลด์รายละเอียด มันใช้งานได้ แต่เป็นกระบวนการแมนนวลหลายขั้นตอน
- Octoparse: คุณสร้างเวิร์กโฟลว์ด้วยขั้นตอนตามลิงก์ ทรงพลัง แต่ไม่ใช่แบบคลิกครั้งเดียว
- Axiom.ai: คุณออกแบบลูปบอทให้เข้า URL แต่ละรายการและดึงข้อมูล ยืดหยุ่น แต่ต้องมีทักษะการสร้างบอท
- Data Miner: คุณใช้ฟีเจอร์ Crawl Scrape เพื่อเข้า URL ที่บันทึกไว้และใช้ recipe ตัวที่สอง เป็นงานที่ต้องทำเองและผูกกับ recipe
- Instant Data Scraper และ Helium 10: ไม่มีเวิร์กโฟลว์เติมข้อมูลหน้าย่อย
ถ้าคุณต้องใช้ทั้งข้อมูลระดับลิสต์และระดับรายละเอียดของ Amazon เป็นประจำ เครื่องมือที่เลือกควรทำให้เวิร์กโฟลว์นี้ง่าย ไม่ใช่แค่ทำได้
แยกให้ชัดแบบตรงไปตรงมา: แพ็กเกจฟรีได้อะไรจริงบ้างโดยไม่ต้องจ่าย
ผู้ใช้ในฟอรัมถามเรื่องนี้มากกว่าสิ่งอื่นใด และไม่มีบทความเปรียบเทียบอื่นตอบอย่างโปร่งใส
| ส่วนขยาย | แพ็กเกจฟรี | ได้อะไรฟรีบ้าง | เมื่อไหร่ที่ต้องอัปเกรด |
|---|---|---|---|
| Thunderbit | มี (6 หน้า, 10 หน้าพร้อมทดลอง) | แนะนำฟิลด์ด้วย AI, ฟอร์แมตการส่งออกทั้งหมด (Excel, Sheets, Airtable, Notion), เครื่องมือดึงอีเมล/เบอร์โทร | ต้องการดึงมากกว่านี้ หรือสครัปตามกำหนดเวลา |
| Instant Data Scraper | มี (ฟรีเต็มรูปแบบ) | ตรวจจับตารางพื้นฐาน, ส่งออก CSV/Excel | ไม่จำเป็น (ไม่มีแพ็กเกจเสียเงิน แต่ก็ไม่มีอัปเดต) |
| Web Scraper | มี (ใช้ได้เฉพาะบนบราวเซอร์) | สครัปบนบราวเซอร์, ส่งออก CSV | ต้องใช้ cloud, การตั้งเวลา, การเชื่อมต่อเครื่องมืออื่น |
| Octoparse | มี (จำกัด) | ส่งออกได้ราว 50K แถว/เดือน, ดึงข้อมูลบนเครื่อง | ต้องการข้อมูลมากขึ้น, โหนด cloud |
| Axiom.ai | มี (รันได้ 2 ชม.) | ระบบอัตโนมัติพื้นฐาน, Google Sheets | ต้องการรันเพิ่ม, ตั้งเวลา, cloud |
| Data Miner | มี (500 หน้า/เดือน) | recipes, CSV/Excel, Next Page Automation | ต้องการหน้ามากขึ้น, Sheets, ฟีเจอร์ crawl |
| Helium 10 | มี (จำกัด) | การเข้าถึง Chrome Extension แบบจำกัด | Xray เต็มรูปแบบ, เครื่องมือคีย์เวิร์ด, การตั้งเวลา |
ประเด็นสำคัญคือ แพ็กเกจฟรีของ Thunderbit มีทั้งฟีเจอร์ AI และฟอร์แมตการส่งออกครบ — คู่แข่งส่วนใหญ่มักล็อกการส่งออกขั้นสูงหรือ AI ไว้ในแพ็กเกจเสียเงิน Instant Data Scraper ฟรีแบบเต็มรูปแบบ แต่ไม่มี AI ไม่มีหน้าย่อย และไม่มีการตั้งเวลา (และไม่ได้รับการดูแลแล้ว) Helium 10 มีแพ็กเกจฟรีจริง แต่การเข้าถึงส่วนขยายมีข้อจำกัด และมันไม่ใช่ scraper ทั่วไป
คำแนะนำของฉันตามสถานการณ์:
- “แค่ลองดูเฉย ๆ” -> Instant Data Scraper (ฟรีเต็มรูปแบบ) หรือแพ็กเกจฟรีของ Thunderbit
- “ต้องการดึงข้อมูลสม่ำเสมอและเชื่อถือได้” -> Thunderbit หรือแพ็กเกจเสียเงินของ Web Scraper
- “ผู้ขาย Amazon ที่ต้องการข้อมูลเชิงตลาด” -> Helium 10
แล้วควรเลือกส่วนขยาย Chrome สำหรับ Amazon Scraper ตัวไหน?
หลังจากทดสอบครบทั้ง 7 ตัว มุมมองตรง ๆ ของฉันคือ:
- ดีที่สุดสำหรับผู้ใช้ไม่ถนัดเทคนิคที่อยากได้ผลเร็วด้วย AI: Thunderbit AI ตรวจจับฟิลด์อัตโนมัติ เติมข้อมูลหน้าย่อยได้ในคลิกเดียว ตัวเลือกการส่งออกครบที่สุด และสลับ cloud/browser ได้ ถ้าคุณอยากไปจากหน้า Amazon สู่สเปรดชีตภายในไม่ถึง 2 นาที ตัวนี้คือคำตอบ
- ตัวฟรีที่ดีที่สุดสำหรับงานดึงข้อมูลเร็ว ๆ แบบครั้งคราว: Instant Data Scraper ไม่มีค่าใช้จ่าย ไม่ต้องมีบัญชี แต่ฟีเจอร์จำกัดและไม่ได้รับการดูแลแล้ว
- ดีที่สุดสำหรับคนที่ถนัดตั้งค่าเอง: Web Scraper ตัวสร้าง sitemap ยืดหยุ่น มี cloud ให้ใช้ และมีเอกสารดี
- ดีที่สุดสำหรับไปป์ไลน์ดึงข้อมูลหลายขั้นตอนที่ซับซ้อน: Octoparse (เดสก์ท็อป + ส่วนขยาย) หรือ Axiom.ai (บอทบนบราวเซอร์) ทั้งคู่ทรงพลัง แต่ไม่ใช่ส่วนขยาย Chrome แบบ “ติดตั้งแล้วใช้ทันที” ล้วน ๆ
- ดีที่สุดสำหรับการดึงแบบ recipe ง่าย ๆ: Data Miner ใช้ recipe ที่มีอยู่ได้สะดวก แต่แพ็กเกจฟรีจำกัดและไม่มี AI
- ดีที่สุดสำหรับอินไซต์ผู้ขาย Amazon ไม่ใช่การสครัปทั่วไป: Helium 10 ออกแบบมาเฉพาะทาง มีข้อมูล proprietary ลึก แต่แพงและไม่ใช่ scraper ทั่วไป
ถ้าคุณอยากเห็นว่าการดึงข้อมูล Amazon ด้วย AI หน้าตาเป็นยังไง ฉันคิดว่าคุณจะประหลาดใจว่าทำอะไรได้มากแค่ไหนในไม่กี่คลิก และถ้า Thunderbit ยังไม่ใช่คำตอบที่พอดี ลองตัวอื่นจากลิสต์นี้ดูบ้าง — ตอนนี้เป็นช่วงเวลาที่ดีที่สุดที่จะเลิกก็อปปี้วาง และเริ่มดึงข้อมูลอย่างฉลาดขึ้น
สำหรับทิปเพิ่มเติมเรื่องการดึงข้อมูล Amazon ดูคู่มือของเราเกี่ยวกับ, , และ คุณยังสามารถดูวิดีโอสอนบน ได้ด้วย
คำถามที่พบบ่อย
1. การดึงข้อมูลสินค้าจาก Amazon ถูกกฎหมายไหม?
โดยทั่วไปการดึงข้อมูลที่มองเห็นได้สาธารณะถือว่าสามารถทำได้ แต่ ระบุชัดว่าห้าม data mining และการดึงข้อมูลอัตโนมัติโดยไม่ได้รับความยินยอมเป็นลายลักษณ์อักษร บทความนี้ไม่ใช่คำแนะนำทางกฎหมาย — ควรตรวจสอบเงื่อนไขของ Amazon ทุกครั้งก่อนดึงข้อมูลในระดับใหญ่
2. Amazon ตรวจจับและบล็อกส่วนขยาย Chrome สำหรับ scraper ได้ไหม?
ได้ Amazon มีระบบป้องกันบอทที่สามารถทำให้เกิด CAPTCHA จำกัดอัตราคำขอ หรือบล็อก IP ได้ การใช้อัตราคำขอที่เหมาะสม สครัปบน browser สำหรับงานเล็ก ๆ และใช้ cloud scraping พร้อมจำกัดอัตราสำหรับงานใหญ่จะช่วยลดความเสี่ยง ดูเมทริกซ์การตัดสินใจในส่วน cloud vs. browser ด้านบน
3. ด้วยส่วนขยาย Chrome จะดึงข้อมูลอะไรจาก Amazon ได้บ้าง?
ฟิลด์ที่พบบ่อยคือชื่อสินค้า ราคา เรตติ้ง จำนวนรีวิว ASIN ชื่อผู้ขาย คำอธิบาย URL รูปภาพ ความพร้อมจำหน่าย และข้อมูลการจัดส่ง เครื่องมือที่ขับเคลื่อนด้วย AI อย่าง Thunderbit สามารถตรวจจับและแนะนำฟิลด์เหล่านี้ให้อัตโนมัติโดยไม่ต้องตั้งค่าเอง
4. ต้องมีทักษะเขียนโค้ดไหมถึงจะใช้ส่วนขยาย Amazon scraper Chrome ได้?
ไม่ต้อง — เครื่องมือทั้ง 7 ตัวที่ทดสอบมาถูกออกแบบมาสำหรับผู้ใช้ไม่ถนัดเทคนิค บางตัวต้องตั้งค่ามากกว่า (Web Scraper, Octoparse, Axiom.ai) ขณะที่บางตัวแทบไม่ต้องตั้งค่าเลย (Thunderbit, Instant Data Scraper) โดยทั่วไปแลกกันระหว่างความยืดหยุ่นกับความง่ายในการใช้งาน
5. ส่วนขยาย Amazon scraper Chrome ตัวไหนมีแพ็กเกจฟรีดีที่สุด?
แพ็กเกจฟรีของ Thunderbit มีการตรวจจับฟิลด์ด้วย AI และฟอร์แมตการส่งออกทั้งหมด (Sheets, Airtable, Notion, Excel, CSV, JSON) ซึ่งคู่แข่งส่วนใหญ่มักล็อกไว้ในแพ็กเกจเสียเงิน Instant Data Scraper ฟรีเต็มรูปแบบแต่ไม่มี AI ไม่มีหน้าย่อย และไม่มีการตั้งเวลา Data Miner ให้ 500 หน้าใช้ฟรีต่อเดือน ส่วน Helium 10 มีแพ็กเกจฟรีที่จำกัดและเน้นงานวิจัยผู้ขาย ไม่ใช่การสครัปทั่วไป
ดูเพิ่มเติม