ปี 2015 ถ้าพูดถึงการสแครปข้อมูล ภาพจำคือ “ต้องไปขอให้นักพัฒนาช่วยเขียนสคริปต์ Python” ไม่ก็ต้องยอมเสียทั้งสุดสัปดาห์ไปนั่งเรียน XPath แบบกัดฟัน แต่พอมาถึงปี 2026 แค่พิมพ์ว่า “ดึงชื่อสินค้าและราคาทั้งหมด” แล้วปล่อยให้ AI จัดการที่เหลือให้จบๆ ไป
การเปลี่ยนผ่านรอบนี้มาไวแบบแทบไม่ทันตั้งตัว ตอนนี้มีบริษัทมากกว่า ที่พึ่งพาการสแครปข้อมูลจากเว็บ ตลาดก็ทะลุ และมีแนวโน้มจะโตเป็นสองเท่าภายในปี 2030
ตัวเร่งที่สำคัญสุดๆ คือ AI web crawler เพราะมัน “อ่านเกม” ได้มากกว่าเดิม—ปรับตัวตามเลย์เอาต์ที่เปลี่ยนได้ เข้าใจ “เนื้อหา” ของหน้าเว็บ ไม่ได้มองแค่แท็ก HTML และที่สำคัญคือคนที่ไม่เคยเขียนโค้ดก็หยิบไปใช้ได้เลย
ผมใช้เวลาหลายเดือนลองของอยู่ 15 ตัวเต็มๆ นี่คือสิ่งที่เจอ—รวมถึงเหตุผลว่าทำไม Thunderbit (ใช่ครับ บริษัทที่ผมร่วมก่อตั้ง) ถึงได้อันดับหนึ่ง
ทำไม AI ถึงกำลังเปลี่ยนโลกของการสแครปหน้าเว็บ: ยุคใหม่ของเครื่องมือ Web Scraper
พูดกันแบบไม่อ้อมค้อม: การสแครปแบบดั้งเดิมมันไม่เคยถูกออกแบบมาเพื่อผู้ใช้ธุรกิจทั่วไปเลย มันเต็มไปด้วยโค้ด selectors และการลุ้นให้สคริปต์ไม่พังตอนเว็บเปลี่ยนหน้าตา แต่พอ AI กับ LLMs เข้ามา เกมมันเปลี่ยนไปคนละเรื่อง
สิ่งที่เปลี่ยนไปมีประมาณนี้:
- สั่งงานด้วยภาษาคน (Natural Language): แทนที่จะต้องไปงมโค้ด คุณแค่บอก AI ว่าอยากได้อะไร เครื่องมืออย่าง จะตีความคำสั่งภาษาอังกฤษธรรมดาแล้วตั้งค่าการดึงข้อมูลให้เอง ().
- เรียนรู้และปรับตัวได้ (Adaptive Learning): AI scraper สามารถ ทำให้ภาระการดูแลรักษาลดลงเยอะมาก
- รับมือคอนเทนต์แบบไดนามิก: เว็บยุคนี้ชอบ JavaScript กับ infinite scroll เครื่องมือที่ขับเคลื่อนด้วย AI สามารถโต้ตอบกับองค์ประกอบพวกนี้และเก็บข้อมูลที่ scraper แบบเก่าอาจหลุดไป
- ได้ผลลัพธ์เป็นโครงสร้างด้วย AI Parsing: scraper ที่ใช้ LLM จะ แล้วส่งออกข้อมูลที่สะอาดและเป็นระเบียบ
- หลบระบบกันบอทแบบอัตโนมัติ: AI scraper สามารถ และใช้ proxy/headless browser เพื่อลดโอกาสโดนบล็อก IP
- เวิร์กโฟลว์ข้อมูลแบบครบวงจร: เครื่องมือที่ดีไม่ได้แค่ “ดึงข้อมูล” แต่ส่งต่อไปยังที่ที่คุณใช้งานจริงได้ทันที เช่น export ไป Google Sheets, Airtable, Notion และอื่นๆ แบบคลิกเดียว ().
ผลลัพธ์คือ การสแครปเว็บกลายเป็นประสบการณ์แบบ point-and-click (หรือเหมือนคุยแชต) เปิดทางให้ทีมขาย การตลาด และโอเปอเรชัน—ไม่ใช่แค่นักพัฒนา—เข้าถึงข้อมูลจากเว็บได้โดยตรง
15 AI Web Crawler ที่น่าจับตาในปี 2026
มาดู 15 AI web crawler ตัวท็อปกัน โดยเริ่มจาก Thunderbit ผมจะสรุปฟีเจอร์หลัก กลุ่มผู้ใช้ ราคา และจุดเด่นของแต่ละตัวให้ครบ และแน่นอน—จะพูดตรงๆ ว่าตัวไหนเด่นเรื่องอะไร (และตัวไหนอาจไม่เหมาะ)
1. Thunderbit: AI Web Scraper ที่ใครๆ ก็ใช้ได้
ผมยอมรับว่ามีอคติเล็กน้อย แต่ Thunderbit คือ AI web scraper ที่ผมอยากให้มีตั้งแต่หลายปีก่อน และนี่คือเหตุผลว่าทำไมมันถึงเป็นอันดับ 1:
- ดึงข้อมูลด้วยภาษาธรรมชาติ: คุณ “คุย” กับ Thunderbit ได้ แค่บอกว่าต้องการข้อมูลอะไร เช่น “สแครปชื่อสินค้าและราคาทั้งหมดจากหน้านี้” แล้ว AI จะจัดการให้ (). ไม่ต้องเขียนโค้ด ไม่ต้องตั้ง selector ไม่ต้องปวดหัว
- ไล่สแครปซับเพจและหลายชั้น: Thunderbit สามารถ ได้ เช่น สแครปรายการสินค้า แล้วคลิกเข้าไปเก็บรายละเอียดของแต่ละสินค้าในรอบเดียว
- ได้ข้อมูลแบบมีโครงสร้างทันที: AI จะ แนะนำฟิลด์ที่เกี่ยวข้อง ปรับรูปแบบให้สม่ำเสมอ และยังสรุป/จัดหมวดหมู่ข้อความได้
- รองรับแหล่งข้อมูลหลากหลาย: Thunderbit ไม่ได้จำกัดแค่ HTML—ยังดึงข้อมูลจาก PDF และรูปภาพได้ด้วย OCR และ vision AI ในตัว ().
- เชื่อมต่อเครื่องมือธุรกิจ: export ไป Google Sheets, Airtable, Notion หรือ Excel ได้ในคลิกเดียว (). ตั้งเวลาสแครปและส่งข้อมูลเข้ากระบวนการทำงานของทีมได้
- มีเทมเพลตสำเร็จรูป: สำหรับเว็บอย่าง Amazon, LinkedIn, Zillow ฯลฯ Thunderbit มี ให้ดึงข้อมูลได้แบบคลิกเดียว
- ใช้ง่ายและเข้าถึงได้: อินเทอร์เฟซเป็นแบบ point-and-click พร้อมผู้ช่วยที่เข้าใจง่าย ผู้ใช้จำนวนมากบอกว่าเริ่มใช้งานได้ภายในไม่กี่นาที

Thunderbit ได้รับความไว้วางใจจากผู้ใช้มากกว่า รวมถึงทีมจาก Accenture, Grammarly และ Puma ทีมขายใช้เพื่อ นายหน้าอสังหาฯ ใช้รวบรวมประกาศขาย/เช่า และนักการตลาดใช้ติดตามคู่แข่ง—ทั้งหมดนี้โดยไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียว
ราคา: มี (สแครปได้สูงสุด 100 steps/เดือน) และแพ็กเกจเสียเงินเริ่มที่ $14.99/เดือน แม้แผนโปรก็ยังคุ้มสำหรับบุคคลและทีมเล็ก
Thunderbit คือสิ่งที่ใกล้เคียงที่สุดกับ “เปลี่ยนเว็บให้เป็นฐานข้อมูล” เท่าที่ผมเคยเห็น—และมันสร้างมาเพื่อทุกคน ไม่ใช่แค่วิศวกร
2. Crawl4AI
เหมาะกับใคร: นักพัฒนาและทีมเทคนิคที่ต้องการสร้าง pipeline แบบกำหนดเอง
Crawl4AI เป็นเฟรมเวิร์กโอเพนซอร์สบน Python ที่เน้นความเร็วและการ crawl ขนาดใหญ่ โดย . เร็วมาก รองรับ headless browser สำหรับคอนเทนต์ไดนามิก และจัดโครงสร้างข้อมูลเพื่อป้อนเข้าเวิร์กโฟลว์ AI ได้สะดวก
- เด่นสุดสำหรับ: นักพัฒนาที่ต้องการเอนจิน crawl ที่แรงและปรับแต่งได้
- ราคา: ฟรี (MIT license) แต่ต้องโฮสต์และรันเอง
3. ScrapeGraphAI
เหมาะกับใคร: นักพัฒนาและนักวิเคราะห์ที่สร้าง AI agent หรือ data pipeline ซับซ้อน
ScrapeGraphAI เป็นไลบรารี Python แบบโอเพนซอร์สที่ขับเคลื่อนด้วย prompt ใช้ LLM แปลงเว็บไซต์ให้เป็น “กราฟ” ของข้อมูลแบบมีโครงสร้าง คุณสามารถเขียน prompt เช่น “ดึงชื่อสินค้า ราคา และเรตติ้งจาก 5 หน้าแรก” แล้วมันจะสร้างเวิร์กโฟลว์สแครปให้ ().
- เด่นสุดสำหรับ: ผู้ใช้สายเทคนิคที่อยากได้ความยืดหยุ่นแบบสั่งด้วย prompt
- ราคา: ไลบรารีโอเพนซอร์สฟรี; Cloud API เริ่มที่ $20/เดือน
4. Firecrawl
เหมาะกับใคร: นักพัฒนาที่สร้าง AI agent หรือ pipeline ข้อมูลขนาดใหญ่
Firecrawl เป็นแพลตฟอร์มและ API สำหรับ crawl ที่โฟกัส AI โดยแปลงทั้งเว็บไซต์ให้เป็นข้อมูลแบบ “พร้อมป้อน LLM” (). ส่งออกเป็น Markdown หรือ JSON จัดการคอนเทนต์ไดนามิก และเชื่อมกับเฟรมเวิร์กอย่าง LangChain และ LlamaIndex ได้
- เด่นสุดสำหรับ: นักพัฒนาที่ต้องการป้อนข้อมูลเว็บสดเข้าโมเดล AI
- ราคา: แกนโอเพนซอร์สฟรี; Cloud เริ่มที่ $19/เดือน
5. Browse AI
เหมาะกับใคร: ผู้ใช้ธุรกิจ growth hacker และนักวิเคราะห์
Browse AI เป็นแพลตฟอร์ม no-code ที่มี . คุณ “สอน” หุ่นยนต์ด้วยการคลิกข้อมูลที่ต้องการ แล้ว AI จะเรียนรู้แพตเทิร์นเพื่อใช้สแครปครั้งต่อๆ ไป รองรับล็อกอิน infinite scroll และติดตามการเปลี่ยนแปลงของเว็บได้
- เด่นสุดสำหรับ: คนไม่สายเทคนิคที่อยากทำ data collection และ monitoring แบบอัตโนมัติ
- ราคา: ฟรี (50 credits/เดือน); แผนเสียเงินเริ่ม $19/เดือน
6. LLM Scraper
เหมาะกับใคร: นักพัฒนาที่อยากให้ AI ช่วยทำ parsing
LLM Scraper เป็นไลบรารี JavaScript/TypeScript แบบโอเพนซอร์ส ที่ให้คุณ แล้วให้ LLM ดึงข้อมูลตามนั้นจากหน้าเว็บใดก็ได้ สร้างบน Playwright รองรับผู้ให้บริการ LLM หลายเจ้า และยังสร้างโค้ดที่นำกลับมาใช้ซ้ำได้
- เด่นสุดสำหรับ: นักพัฒนาที่อยากแปลงหน้าเว็บเป็นข้อมูลแบบมีโครงสร้างด้วย LLM
- ราคา: ฟรี (MIT license)
7. Reader (Jina Reader)
เหมาะกับใคร: นักพัฒนาที่ทำแอป LLM แชตบอท หรือระบบสรุปเนื้อหา
Jina Reader เป็น API ที่ดึง แล้วส่งกลับเป็น Markdown หรือ JSON ที่พร้อมใช้กับ LLM ขับเคลื่อนด้วยโมเดล AI เฉพาะทาง และยังทำคำบรรยายภาพได้
- เด่นสุดสำหรับ: ดึงคอนเทนต์ให้อ่านง่ายเพื่อใช้กับ LLM หรือระบบ Q&A
- ราคา: API ฟรี (ใช้งานพื้นฐานไม่ต้องใช้คีย์)
8. Bright Data
เหมาะกับใคร: องค์กรและผู้ใช้มืออาชีพที่ต้องการสเกล ความถูกต้องตามข้อกำกับ และความเสถียร
Bright Data เป็นตัวใหญ่ในวงการข้อมูลเว็บ มีเครือข่าย proxy ขนาดมหาศาลและ . มีทั้ง scraper สำเร็จรูป Web Scraper API แบบทั่วไป และ data feed ที่ “พร้อมใช้กับ LLM”
- เด่นสุดสำหรับ: องค์กรที่ต้องการข้อมูลเว็บเชื่อถือได้ในระดับสเกลใหญ่
- ราคา: คิดตามการใช้งาน ระดับพรีเมียม มีทดลองใช้
9. Octoparse
เหมาะกับใคร: ผู้ใช้ตั้งแต่ไม่สายเทคนิคไปจนถึงกึ่งเทคนิค
Octoparse เป็นเครื่องมือ no-code ที่อยู่มานาน มี และระบบ auto-detect ด้วย AI รองรับล็อกอิน infinite scroll และ export ได้หลายรูปแบบ
- เด่นสุดสำหรับ: นักวิเคราะห์ เจ้าของธุรกิจเล็ก หรือสายวิจัย
- ราคา: มีฟรี; แผนเสียเงินเริ่ม $119/เดือน
10. Apify
เหมาะกับใคร: นักพัฒนาและทีมเทคนิคที่ต้องการสแครป/ออโตเมชันแบบกำหนดเอง
Apify เป็นแพลตฟอร์มคลาวด์สำหรับรันสคริปต์สแครป (“actors”) และมี . สเกลได้ เชื่อมกับ AI ได้ และมีระบบจัดการ proxy
- เด่นสุดสำหรับ: นักพัฒนาที่อยากรันสคริปต์แบบกำหนดเองบนคลาวด์
- ราคา: มีฟรี; แผนเสียเงินแบบคิดตามการใช้งานเริ่ม $49/เดือน
11. Zyte (Scrapy Cloud)
เหมาะกับใคร: นักพัฒนาและบริษัทที่ต้องการสแครประดับองค์กร
Zyte คือบริษัทผู้อยู่เบื้องหลัง Scrapy มีแพลตฟอร์มคลาวด์และ . รองรับการตั้งเวลา proxy และโปรเจกต์ขนาดใหญ่
- เด่นสุดสำหรับ: ทีม dev ที่ทำโปรเจกต์สแครประยะยาว
- ราคา: มีทดลองใช้ ไปจนถึงแพ็กเกจองค์กรแบบกำหนดเอง
12. Webscraper.io
เหมาะกับใคร: มือใหม่ นักข่าว และนักวิจัย
เป็น สำหรับดึงข้อมูลแบบคลิกเลือก ใช้ง่าย ฟรีสำหรับใช้งานบนเครื่อง และมีบริการคลาวด์สำหรับงานใหญ่ขึ้น
- เด่นสุดสำหรับ: งานสแครปเร็วๆ แบบครั้งคราว
- ราคา: extension ฟรี; Cloud เริ่มราว ~$50/เดือน
13. ParseHub
เหมาะกับใคร: ผู้ใช้ไม่สายเทคนิคที่ต้องการพลังมากกว่าเครื่องมือพื้นฐาน
ParseHub เป็นแอปเดสก์ท็อปที่มีเวิร์กโฟลว์แบบภาพสำหรับสแครปคอนเทนต์ไดนามิก รวมถึงแผนที่และฟอร์ม สามารถรันงานบนคลาวด์และมี API
- เด่นสุดสำหรับ: นักการตลาดดิจิทัล นักวิเคราะห์ และนักข่าว
- ราคา: ฟรี (200 หน้า/รัน); แผนเสียเงินเริ่ม $189/เดือน
14. Diffbot
เหมาะกับใคร: องค์กรและบริษัท AI ที่ต้องการข้อมูลเว็บแบบมีโครงสร้างในสเกลใหญ่
Diffbot ใช้ computer vision และ NLP เพื่อ จากหน้าเว็บใดก็ได้ มี API สำหรับบทความ สินค้า และ knowledge graph ขนาดใหญ่
- เด่นสุดสำหรับ: market intelligence การเงิน และข้อมูลสำหรับเทรน AI
- ราคา: พรีเมียม เริ่มราว ~$299/เดือน
15. DataMiner
เหมาะกับใคร: ผู้ใช้ไม่สายเทคนิค โดยเฉพาะสายขาย การตลาด และสื่อ
DataMiner เป็น สำหรับดึงข้อมูลแบบคลิกเลือกอย่างรวดเร็ว มีคลัง “สูตร” สำเร็จรูป และ export ไป Google Sheets ได้โดยตรง
- เด่นสุดสำหรับ: งานเร็วๆ เช่น export ตารางหรือรายการไปสเปรดชีต
- ราคา: ฟรี (500 หน้า/วัน); Pro เริ่มราว ~$19/เดือน
เปรียบเทียบเครื่องมือ AI Web Scraper ชั้นนำ: ตัวไหนเหมาะกับคุณ?
นี่คือภาพรวมแบบย่อเพื่อช่วยให้คุณเลือกได้ง่ายขึ้น:
| Tool | AI/LLM Usage | Ease of Use | Output/Integration | Ideal For | Pricing |
|---|---|---|---|---|---|
| Thunderbit | UI ภาษาธรรมชาติ; AI แนะนำฟิลด์ | ง่ายที่สุด (แชต no-code) | export ไป Sheets, Airtable, Notion | ทีมไม่สายเทคนิค | มีฟรี; Pro ~ $30/เดือน |
| Crawl4AI | crawl พร้อมต่อ LLM; ผสาน LLM ได้ | ยาก (ต้องเขียน Python) | ไลบรารี/CLI; ต่อผ่านโค้ด | dev ที่ต้องการ pipeline ข้อมูล AI เร็วๆ | ฟรี |
| ScrapeGraphAI | pipeline สแครปด้วย prompt LLM | กลาง (ต้องโค้ดบางส่วนหรือใช้ API) | API/SDK; JSON | dev/analyst ที่สร้าง AI agent | OSS ฟรี; API $20+/เดือน |
| Firecrawl | crawl เป็น Markdown/JSON พร้อมใช้กับ LLM | กลาง (ใช้ API/SDK) | SDK (Py, Node ฯลฯ); ต่อ LangChain | dev ที่ดึงข้อมูลเว็บสดเข้า AI | ฟรี + คลาวด์เสียเงิน |
| Browse AI | AI ช่วยคลิกเลือก | ง่าย (no-code) | อินทิเกรชัน 7000+ แอป (Zapier) | ผู้ใช้ไม่สายเทคนิคทำ monitoring | ฟรี 50 runs; เสียเงิน $19+/เดือน |
| LLM Scraper | ใช้ LLM แปลงหน้าเว็บตาม schema | ยาก (ต้องเขียน TS/JS) | ไลบรารีโค้ด; JSON | dev ที่อยากให้ AI ทำ parsing | ฟรี (ใช้ LLM API ของตัวเอง) |
| Reader (Jina) | โมเดล AI ดึงข้อความ/JSON | ง่าย (เรียก API) | REST API ส่งกลับ Markdown/JSON | dev ที่เพิ่มเว็บเสิร์ช/คอนเทนต์ให้ LLM | API ฟรี |
| Bright Data | API สแครปเสริม AI; proxy network ใหญ่ | ยาก (เชิงเทคนิค) | APIs/SDKs; data stream/dataset | ระดับองค์กร | คิดตามการใช้งาน |
| Octoparse | AI auto-detect รายการ | ปานกลาง (แอป no-code) | CSV/Excel, API | ผู้ใช้กึ่งเทคนิค | ฟรีจำกัด; $59–$166/เดือน |
| Apify | มีฟีเจอร์ AI บางส่วน (Actors, tutorial) | ยาก (ต้องเขียนสคริปต์) | API ครบ; ต่อ LangChain ได้ | dev ที่ต้องการสแครปแบบกำหนดเองบนคลาวด์ | มีฟรี; pay-as-you-go |
| Zyte (Scrapy) | ML ดึงข้อมูลอัตโนมัติ; เฟรมเวิร์ก Scrapy | ยาก (ต้องเขียน Python) | API, UI ของ Scrapy Cloud; JSON/CSV | ทีม dev งานระยะยาว | ราคากำหนดเอง |
| Webscraper.io | ไม่มี AI (เทมเพลตทำมือ) | ง่าย (ส่วนขยายเบราว์เซอร์) | ดาวน์โหลด CSV, Cloud API | มือใหม่ งานครั้งคราว | extension ฟรี; Cloud ~ $50/เดือน |
| ParseHub | ไม่ได้เน้น LLM; ตัวสร้างแบบภาพ | ปานกลาง (แอป no-code) | JSON/CSV; API สำหรับคลาวด์ | ผู้ใช้ไม่ใช่ dev ที่สแครปเว็บซับซ้อน | ฟรี 200 หน้า; เสียเงิน $189+/เดือน |
| Diffbot | AI vision/NLP สำหรับทุกหน้า; knowledge graph | ง่าย (เรียก API) | APIs (Article/Prod/...) + query Knowledge Graph | องค์กร ข้อมูลเว็บแบบมีโครงสร้าง | เริ่ม ~ $299/เดือน |
| DataMiner | ไม่มี LLM; สูตรจากชุมชน | ง่ายที่สุด (UI บนเบราว์เซอร์) | export Excel/CSV; Google Sheets | ผู้ใช้ไม่สายเทคนิคสแครปลงสเปรดชีต | ฟรีจำกัด; Pro ~ $19/เดือน |
จัดกลุ่มเครื่องมือ: ตั้งแต่สาย dev สุดโหด ไปจนถึง Web Scraper สำหรับทีมธุรกิจ
เพื่อให้ย่อยรายการนี้ได้ง่ายขึ้น ลองแบ่งเป็นหมวดๆ แบบนี้:
1. สายพลังนักพัฒนา & โอเพนซอร์ส
- ตัวอย่าง: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- จุดแข็ง: ยืดหยุ่น สเกลได้ และปรับแต่งได้สูง เหมาะกับการสร้าง pipeline เองหรือเชื่อมกับโมเดล AI
- ข้อแลกเปลี่ยน: ต้องมีทักษะโค้ดและต้องเซ็ตอัปเยอะกว่า
- กรณีใช้งาน: สร้าง data pipeline เฉพาะทาง สแครปเว็บซับซ้อน หรือเชื่อมกับระบบภายใน
2. เอเจนต์สแครปที่ผสาน AI
- ตัวอย่าง: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- จุดแข็ง: ลดช่องว่างระหว่าง “ดึงข้อมูล” กับ “เข้าใจข้อมูล” อินเทอร์เฟซภาษาธรรมชาติทำให้เข้าถึงง่าย
- ข้อแลกเปลี่ยน: บางตัวกำลังพัฒนา อาจคุมรายละเอียดเชิงลึกได้น้อย
- กรณีใช้งาน: ได้คำตอบ/ชุดข้อมูลเร็วๆ สร้างเอเจนต์อัตโนมัติ หรือป้อนข้อมูลสดให้ LLM
3. เครื่องมือสแครปแบบ No-code/Low-code ที่เป็นมิตรกับธุรกิจ
- ตัวอย่าง: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- จุดแข็ง: ใช้ง่าย แทบไม่ต้องเขียนโค้ด เหมาะกับงานธุรกิจประจำวัน
- ข้อแลกเปลี่ยน: อาจไม่ถนัดเว็บที่ซับซ้อนมากหรือสเกลมหาศาล
- กรณีใช้งาน: หา lead ติดตามคู่แข่ง งานวิจัย และดึงข้อมูลครั้งคราว
4. แพลตฟอร์ม/บริการข้อมูลระดับองค์กร
- ตัวอย่าง: Bright Data, Diffbot, Zyte
- จุดแข็ง: โซลูชันครบวงจร มีบริการดูแลให้ ความสอดคล้องตามข้อกำกับ และความเสถียรในสเกลใหญ่
- ข้อแลกเปลี่ยน: ราคาแรงกว่า และต้อง onboarding มากกว่า
- กรณีใช้งาน: data pipeline ขนาดใหญ่แบบ always-on, market intelligence และข้อมูลเทรน AI
วิธีเลือก AI Web Crawler ให้เหมาะกับงานสแครปหน้าเว็บของคุณ
เครื่องมือเยอะจนตาลายเป็นเรื่องปกติ นี่คือแนวทางทีละขั้นที่ผมใช้:
- กำหนดเป้าหมายและความต้องการข้อมูล: ต้องการเว็บไหน ข้อมูลอะไร บ่อยแค่ไหน ปริมาณเท่าไร และจะเอาไปทำอะไรต่อ
- ประเมินทักษะด้านเทคนิค: ไม่เขียนโค้ดเลย? ลอง Thunderbit, Browse AI หรือ Octoparse เขียนสคริปต์ได้บ้าง? LLM Scraper หรือ DataMiner เก่ง dev? Crawl4AI, Apify หรือ Zyte
- ดูความถี่และสเกล: ทำครั้งเดียว? ใช้เครื่องมือฟรี งานประจำ? มองหาฟีเจอร์ตั้งเวลา สเกลใหญ่? ใช้เครื่องมือองค์กรหรือโอเพนซอร์สที่สเกลได้
- งบประมาณและโมเดลราคา: แผนฟรีเหมาะสำหรับลองของ เลือกระหว่างรายเดือนกับคิดตามการใช้งานให้เข้ากับรูปแบบงาน
- ทดลองจริง (PoC): ลองกับข้อมูลจริงของคุณ เครื่องมือส่วนใหญ่มีให้ลองฟรี
- การดูแลรักษาและซัพพอร์ต: ถ้าเว็บเปลี่ยน ใครจะเป็นคนแก้? no-code ที่มี AI อาจรับมือการเปลี่ยนเล็กๆ ได้เอง ส่วนโอเพนซอร์สต้องพึ่งคุณหรือชุมชน
- จับคู่เครื่องมือกับสถานการณ์: ทีมขายสแครป lead? Thunderbit หรือ Browse AI นักวิจัยเก็บทวีต? DataMiner หรือ โมเดล AI ต้องการข่าว? Jina Reader หรือ Zyte ทำเว็บเปรียบเทียบราคา? Apify หรือ Zyte
- เตรียมแผนสำรอง: บางเว็บอาจไม่เข้ากับเครื่องมือบางตัว ควรมีตัวเลือกสำรองไว้
เครื่องมือที่ “ใช่” คือเครื่องมือที่ทำให้คุณได้ข้อมูลที่ต้องการด้วยแรงเสียดทานน้อยที่สุด และอยู่ในงบประมาณ บางทีคำตอบอาจเป็นการใช้มากกว่าหนึ่งเครื่องมือร่วมกัน
Thunderbit เทียบกับเครื่องมือ Web Scraper แบบเดิม: อะไรทำให้มันโดดเด่น?
มาดูแบบชัดๆ ว่า Thunderbit ต่างยังไง:
- อินเทอร์เฟซภาษาธรรมชาติ: ไม่ต้องเขียนโค้ด ไม่ต้องคลิกตั้งค่าซับซ้อน แค่บอกสิ่งที่ต้องการ ().
- แทบไม่ต้องตั้งค่า + แนะนำเทมเพลต: ตรวจจับ pagination ซับเพจ และยังแนะนำเทมเพลตสำหรับเว็บยอดนิยมได้เอง ().
- ทำความสะอาด/เพิ่มคุณค่าข้อมูลด้วย AI: สรุป จัดหมวดหมู่ แปล และ enrich ข้อมูลไปพร้อมการสแครป ().
- ปวดหัวเรื่องบำรุงรักษาน้อยลง: AI ของ Thunderbit ทนต่อการเปลี่ยนแปลงเล็กๆ ของเว็บ ลดโอกาสพัง
- เชื่อมเครื่องมือธุรกิจ: export ไป Google Sheets, Airtable, Notion ได้ตรงๆ ไม่ต้องมานั่งจัดการ CSV ().
- เห็นผลเร็ว: จากไอเดียไปเป็นข้อมูล ใช้เวลาเป็นนาที ไม่ใช่เป็นวัน
- เส้นโค้งการเรียนรู้ต่ำ: ถ้าคุณท่องเว็บได้และอธิบายสิ่งที่ต้องการได้ คุณก็ใช้ Thunderbit ได้
- ยืดหยุ่น: สแครปได้ทั้งเว็บ PDF รูปภาพ และอื่นๆ ด้วยเครื่องมือเดียว
Thunderbit ไม่ใช่แค่ scraper แต่มันคือผู้ช่วยด้านข้อมูลที่เข้ากับเวิร์กโฟลว์ของคุณ ไม่ว่าคุณจะอยู่ทีมขาย การตลาด อีคอมเมิร์ซ หรืออสังหาฯ
แนวทางปฏิบัติที่ดีในการสแครปหน้าเว็บด้วยเครื่องมือ AI Web Scraper
ถ้าอยากรีดประสิทธิภาพจาก AI web scraper ให้สุด นี่คือทิปส์ที่ผมแนะนำ:
- กำหนดข้อมูลที่ต้องการให้ชัด: ต้องการฟิลด์อะไร กี่หน้า และต้องการรูปแบบแบบไหน
- ใช้ประโยชน์จากคำแนะนำของ AI: ใช้การตรวจจับฟิลด์และคำแนะนำของ AI เพื่อไม่พลาดข้อมูลสำคัญ ().
- เริ่มจากเล็กๆ แล้วตรวจสอบ: ทดลองกับตัวอย่างเล็กๆ เช็กผลลัพธ์ แล้วค่อยปรับ
- จัดการคอนเทนต์ไดนามิก: ตรวจให้แน่ใจว่าเครื่องมือรองรับ pagination, infinite scroll และการโต้ตอบต่างๆ
- เคารพนโยบายเว็บไซต์: ตรวจ robots.txt หลีกเลี่ยงข้อมูลอ่อนไหว และเคารพ rate limit
- เชื่อมเพื่อทำออโตเมชัน: ใช้ฟีเจอร์ export และ webhook เพื่อส่งข้อมูลเข้ากระบวนการทำงานโดยตรง
- รักษาคุณภาพข้อมูล: ตรวจความสมเหตุสมผล ทำ post-processing และเฝ้าระวังข้อผิดพลาด
- เขียน prompt ให้กระชับและชัด: เครื่องมือที่ขับเคลื่อนด้วย AI จะให้ผลดีขึ้นเมื่อคำสั่งเฉพาะเจาะจง
- เรียนรู้จากชุมชน: เข้าฟอรัม/คอมมูนิตี้เพื่อทิปส์และการแก้ปัญหา
- อัปเดตอยู่เสมอ: เครื่องมือ AI เปลี่ยนเร็ว คอยตามฟีเจอร์ใหม่ๆ ไว้จะได้ไม่ตกขบวน
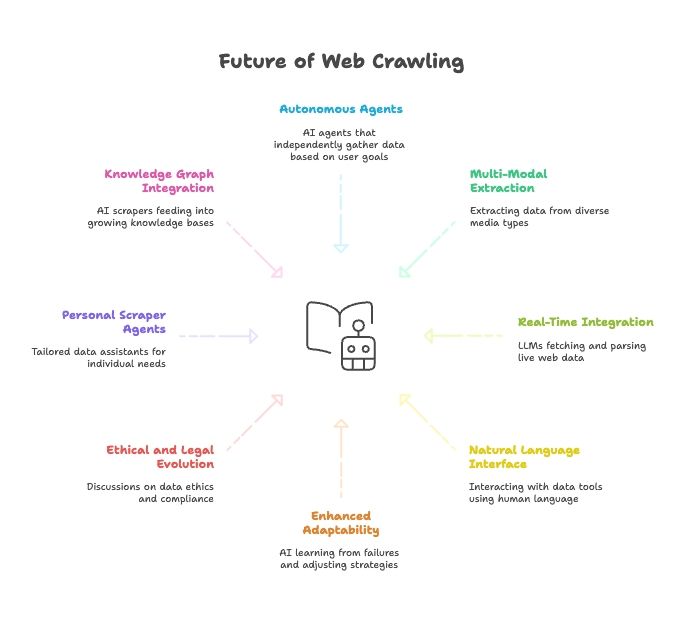
อนาคตของการสแครปเว็บ: AI, LLMs และยุคของเอเจนต์ Web Scraper ที่สั่งด้วยภาษาธรรมชาติ
ถ้ามองไปข้างหน้า การบรรจบกันของ AI กับการสแครปเว็บจะยิ่งเร่งสปีดขึ้นอีก:
- เอเจนต์สแครปแบบอัตโนมัติเต็มรูปแบบ: อีกไม่นานคุณแค่บอกเป้าหมายปลายทาง แล้วเอเจนต์ AI จะหาวิธีเอาข้อมูลมาให้เอง
- การดึงข้อมูลแบบหลายโมดัล: ดึงได้ทั้งข้อความ รูปภาพ PDF และแม้แต่วิดีโอ
- เชื่อมกับโมเดล AI แบบเรียลไทม์: LLM จะมีโมดูลในตัวสำหรับดึงและแปลงข้อมูลเว็บสด
- ทุกอย่างสั่งด้วยภาษาธรรมชาติ: เราจะคุยกับเครื่องมือข้อมูลเหมือนคุยกับคน ทำให้การเก็บและแปลงข้อมูลเข้าถึงได้สำหรับทุกคน
- ปรับตัวเก่งขึ้น: AI scraper จะเรียนรู้จากความล้มเหลวและปรับกลยุทธ์เอง
- วิวัฒนาการด้านจริยธรรมและกฎหมาย: จะมีการถกเถียงเรื่องจริยธรรม ความสอดคล้อง และ fair use มากขึ้น
- เอเจนต์ส่วนตัว: ผู้ช่วยข้อมูลส่วนตัวที่คอยรวบรวมข่าว งาน และอื่นๆ ตามความต้องการของคุณ
- เชื่อมกับ knowledge graph: AI scraper จะป้อนข้อมูลเข้าสู่ฐานความรู้ที่เติบโตต่อเนื่อง ทำให้ AI ฉลาดขึ้น
สรุปคือ อนาคตของการสแครปเว็บผูกกับอนาคตของ AI แบบแยกกันไม่ออก เครื่องมือจะฉลาดขึ้น อัตโนมัติมากขึ้น และใช้ง่ายขึ้นทุกวัน
สรุป: ปลดล็อกมูลค่าทางธุรกิจด้วย AI Web Crawler ที่ใช่
การสแครปเว็บกำลังเปลี่ยนจากทักษะเฉพาะทางของสายเทคนิค มาเป็นความสามารถหลักของธุรกิจ—ด้วยพลังของ AI เครื่องมือทั้ง 15 ตัวที่ผมเล่ามาคือภาพรวมของสิ่งที่ทำได้จริงในปี 2026 ตั้งแต่สาย dev ที่ทรงพลัง ไปจนถึงผู้ช่วยที่เป็นมิตรกับทีมธุรกิจ
เคล็ดลับจริงๆ คือ เลือกเครื่องมือให้เหมาะ แล้วมูลค่าที่คุณได้จากข้อมูลเว็บจะกระโดดขึ้นแบบเห็นได้ชัด สำหรับทีมที่ไม่ใช่สายเทคนิค Thunderbit คือทางที่ง่ายสุดในการเปลี่ยนเว็บให้เป็นฐานข้อมูลแบบมีโครงสร้าง พร้อมเอาไปวิเคราะห์ต่อ—ไม่ต้องโค้ด ไม่ต้องวุ่นวาย เน้นผลลัพธ์ล้วนๆ
ไม่ว่าคุณจะเก็บ lead ติดตามคู่แข่ง หรือป้อนข้อมูลให้โมเดล AI รุ่นถัดไป ลองประเมินความต้องการของคุณ ทดลองสักสองสามเครื่องมือ แล้วดูว่าอะไรเข้ามือที่สุด และถ้าคุณอยากสัมผัสอนาคตของการสแครปเว็บตั้งแต่วันนี้ ลองใช้ Thunderbit ได้เลยที่ อินไซต์ที่คุณต้องการอยู่ห่างแค่ prompt เดียว
อยากอ่านเพิ่ม? เข้าไปที่ เพื่ออ่านบทความเชิงลึก คู่มือ และอัปเดตล่าสุดด้านการดึงข้อมูลด้วย AI
อ่านต่อ:
คำถามที่พบบ่อย (FAQs)
1. AI web crawler คืออะไร และต่างจาก web scraper แบบเดิมอย่างไร?
AI web crawler ใช้การประมวลผลภาษาธรรมชาติและแมชชีนเลิร์นนิงเพื่อทำความเข้าใจ ดึง และจัดโครงสร้างข้อมูลจากเว็บ ต่างจาก scraper แบบเดิมที่ต้องเขียนโค้ดและตั้ง XPath/selector ด้วยมือ เครื่องมือ AI รับมือคอนเทนต์ไดนามิก ปรับตามเลย์เอาต์ที่เปลี่ยน และเข้าใจคำสั่งภาษาคนได้
2. ใครควรใช้เครื่องมือ AI web scraping อย่าง Thunderbit?
Thunderbit ออกแบบมาสำหรับทั้งผู้ใช้ไม่สายเทคนิคและสายเทคนิค เหมาะกับงานขาย การตลาด โอเปอเรชัน งานวิจัย และอีคอมเมิร์ซ ที่ต้องการดึงข้อมูลแบบมีโครงสร้างจากเว็บไซต์ PDF หรือรูปภาพ—โดยไม่ต้องเขียนโค้ด
3. ฟีเจอร์อะไรที่ทำให้ Thunderbit เด่นกว่า AI web crawler ตัวอื่น?
Thunderbit มีอินเทอร์เฟซภาษาธรรมชาติ การ crawl หลายชั้น การจัดโครงสร้างข้อมูลอัตโนมัติ รองรับ OCR และ export ไป Google Sheets/Airtable ได้ลื่นไหล นอกจากนี้ยังมีการแนะนำฟิลด์ด้วย AI และเทมเพลตสำเร็จรูปสำหรับเว็บยอดนิยม
4. ปี 2026 ยังมีตัวเลือกฟรีสำหรับ AI web scraping ไหม?
มี หลายเครื่องมืออย่าง Thunderbit, Browse AI และ DataMiner มีแผนฟรีแบบจำกัดการใช้งาน สำหรับนักพัฒนา ตัวเลือกโอเพนซอร์สอย่าง Crawl4AI และ ScrapeGraphAI ให้ความสามารถครบโดยไม่เสียค่าใช้จ่าย แต่ต้องตั้งค่าทางเทคนิคเอง
5. จะเลือก AI web crawler ให้เหมาะกับงานของตัวเองได้อย่างไร?
เริ่มจากระบุเป้าหมายข้อมูล ทักษะด้านเทคนิค งบประมาณ และสเกลที่ต้องการ ถ้าต้องการแบบ no-code ใช้ง่าย Thunderbit หรือ Browse AI เป็นตัวเลือกที่ดี หากต้องการสเกลใหญ่หรือปรับแต่งสูง เครื่องมืออย่าง Apify หรือ Bright Data จะเหมาะกว่า