
พูดกันตรงๆ—Amazon แทบจะกลายเป็นทั้งห้างสรรพสินค้า ซูเปอร์มาร์เก็ต และร้านเครื่องใช้ไฟฟ้าของทั้งอินเทอร์เน็ตไปแล้ว ถ้าคุณทำงานด้านเซลส์ อีคอมเมิร์ซ หรือโอเปอเรชัน คุณก็คงรู้ดีว่าสิ่งที่เกิดบน Amazon ไม่ได้หยุดอยู่แค่บน Amazon แต่มันกระทบถึงราคาของคุณ สต็อกของคุณ และแม้แต่การเปิดตัวสินค้าชิ้นใหญ่ครั้งต่อไปของคุณด้วย แต่ปัญหาคือ รายละเอียดสินค้า ราคา เรตติ้ง และรีวิวดีๆ ทั้งหมดนั้นถูกล็อกไว้หลังหน้าเว็บที่ออกแบบมาสำหรับคนช้อป ไม่ใช่สำหรับทีมที่ต้องการข้อมูลแบบจริงจัง แล้วเราจะดึงข้อมูลพวกนั้นออกมายังไง โดยไม่ต้องใช้วันหยุดสุดสัปดาห์ไปกับการก็อปปี้วางเหมือนยุค 1999?
นั่นแหละคือจุดที่การทำเว็บสแครปปิ้งเข้ามาช่วย ในคู่มือนี้ ผมจะพาคุณดูสองวิธีในการดึงข้อมูลสินค้าจาก Amazon: วิธีคลาสสิกแบบ “ลุยเขียนโค้ด Python เอง” และวิธีสมัยใหม่แบบ “ให้ AI ทำงานหนักแทน” ด้วยเครื่องมือดึงข้อมูลเว็บแบบไม่ต้องเขียนโค้ดอย่าง ผมจะไล่ให้ดูโค้ด Python จริงๆ (พร้อมจุดที่มักพลาดและวิธีแก้) จากนั้นจะโชว์ว่า Thunderbit ดึงข้อมูลชุดเดียวกันให้คุณได้ในแค่ไม่กี่คลิก—ไม่ต้องเขียนโค้ดเลย ไม่ว่าคุณจะเป็นนักพัฒนา นักวิเคราะห์ธุรกิจ หรือแค่คนที่เบื่อการป้อนข้อมูลด้วยมือ ผมช่วยคุณได้ครบ
ทำไมต้องดึงข้อมูลสินค้าจาก Amazon? (amazon scraper python, web scraping with python)
Amazon ไม่ได้เป็นแค่ร้านค้าปลีกออนไลน์ที่ใหญ่ที่สุดในโลกเท่านั้น แต่ยังเป็นตลาดเปิดขนาดมหึมาที่สุดในโลกสำหรับข้อมูลเชิงแข่งขันด้วย ด้วย และ Amazon คือขุมทองสำหรับคนที่อยากจะ:

- ติดตามราคา (แล้วปรับราคาของตัวเองแบบเรียลไทม์)
- วิเคราะห์คู่แข่ง (ติดตามสินค้าที่เปิดตัวใหม่ เรตติ้ง และรีวิวของพวกเขา)
- หาลีด (ค้นหาผู้ขาย ซัพพลายเออร์ หรือแม้แต่พาร์ตเนอร์ที่อาจเป็นไปได้)
- คาดการณ์ดีมานด์ (ดูระดับสต็อกและอันดับการขาย)
- จับเทรนด์ตลาด (ขุดข้อมูลจากรีวิวและผลการค้นหา)
และนี่ไม่ใช่แค่ทฤษฎี—ธุรกิจจริงกำลังเห็นผลตอบแทนจริง ตัวอย่างเช่น ร้านขายอุปกรณ์อิเล็กทรอนิกส์รายหนึ่งใช้ข้อมูลราคาจาก Amazon ที่สแครปมาเพื่อ ขณะที่อีกแบรนด์หนึ่งเห็น หลังจากทำระบบติดตามราคาคู่แข่งแบบอัตโนมัติ
นี่คือตารางสั้นๆ ของกรณีการใช้งานและผลตอบแทนที่คุณคาดหวังได้:
| กรณีใช้งาน | ใครใช้ | ผลตอบแทน / ประโยชน์โดยทั่วไป |
|---|---|---|
| การติดตามราคา | อีคอมเมิร์ซ, โอเปอเรชัน | เพิ่มอัตรากำไร 15%+, ยอดขายเพิ่ม 4%, ลดเวลาในงานวิเคราะห์ 30% |
| การวิเคราะห์คู่แข่ง | เซลส์, ผลิตภัณฑ์, โอเปอเรชัน | ปรับราคาได้เร็วขึ้น, แข่งขันได้ดีขึ้น |
| วิจัยตลาด (รีวิว) | ผลิตภัณฑ์, การตลาด | ปรับปรุงสินค้าได้เร็วขึ้น, เขียนโฆษณาได้ดีขึ้น, ได้อินไซต์ด้าน SEO |
| การหาลีด | เซลส์ | ลีดมากกว่า 3,000 ราย/เดือน, ประหยัดเวลาได้มากกว่า 8 ชั่วโมง/คน/สัปดาห์ |
| สต็อกสินค้าและการคาดการณ์ดีมานด์ | โอเปอเรชัน, ซัพพลายเชน | ลดสต็อกล้น 20%, ของขาดสต็อกน้อยลง |
| จับเทรนด์ | การตลาด, ผู้บริหาร | ตรวจพบสินค้าหรือหมวดหมู่ที่กำลังมาแรงได้เร็ว |
และที่สำคัญคือ รายงานแล้วว่าการวิเคราะห์ข้อมูลสร้างคุณค่าได้จริง ถ้าคุณยังไม่สแครป Amazon คุณก็กำลังทิ้งอินไซต์ (และเงิน) ไว้บนโต๊ะ
ภาพรวม: Amazon Scraper Python เทียบกับเครื่องมือดึงข้อมูลเว็บแบบไม่ต้องเขียนโค้ด
มีอยู่สองวิธีหลักในการดึงข้อมูล Amazon ออกจากเบราว์เซอร์แล้วเอาเข้าไปในสเปรดชีตหรือแดชบอร์ดของคุณ:
-
Amazon Scraper Python (web scraping with python):
เขียนสคริปต์ของคุณเองด้วยไลบรารี Python อย่าง Requests และ BeautifulSoup วิธีนี้ให้คุณควบคุมได้เต็มที่ แต่คุณต้องเขียนโค้ดเป็น จัดการมาตรการป้องกันบอท และดูแลสคริปต์เมื่อ Amazon เปลี่ยนเว็บไซต์
-
เครื่องมือดึงข้อมูลเว็บแบบไม่ต้องเขียนโค้ด (เช่น Thunderbit):
ใช้เครื่องมือที่ให้คุณชี้ คลิก และดึงข้อมูลได้เลย ไม่ต้องเขียนโปรแกรม เครื่องมือสมัยใหม่อย่าง ยังใช้ AI ช่วยเดาว่าควรดึงข้อมูลอะไร จัดการหน้าย่อยและการแบ่งหน้า และส่งออกตรงไปยัง Excel หรือ Google Sheets ได้ด้วย
นี่คือการเทียบกันแบบชัดๆ:
| เกณฑ์ | Python Scraper | แบบไม่ต้องเขียนโค้ด (Thunderbit) |
|---|---|---|
| เวลาตั้งค่า | สูง (ติดตั้ง, เขียนโค้ด, ดีบัก) | ต่ำ (ติดตั้งส่วนขยาย) |
| ทักษะที่ต้องใช้ | ต้องเขียนโค้ด | ไม่ต้องมี (ชี้แล้วคลิก) |
| ความยืดหยุ่น | ไม่จำกัด | สูงสำหรับกรณีใช้งานทั่วไป |
| การดูแลรักษา | คุณต้องแก้โค้ดเอง | เครื่องมืออัปเดตตัวเอง |
| การรับมือบอท | คุณต้องจัดการพร็อกซีและเฮดเดอร์เอง | มีในตัวและจัดการให้แล้ว |
| การขยายสเกล | ทำเองแบบแมนนวล (เธรด, พร็อกซี) | สแครปบนคลาวด์, ทำงานแบบขนาน |
| การส่งออกข้อมูล | ปรับเองได้ (CSV, Excel, DB) | คลิกเดียวไป Excel, Sheets |
| ค่าใช้จ่าย | ฟรี (แต่เสียเวลา + พร็อกซี) | ฟรีเมียม, จ่ายเมื่อขยายสเกล |
ในส่วนถัดไป ผมจะพาคุณไปทีละขั้นทั้งสองแนวทาง—เริ่มจากวิธีสร้าง Amazon scraper ด้วย Python (พร้อมโค้ดจริง) แล้วค่อยดูวิธีทำแบบเดียวกันด้วย AI web scraper ของ Thunderbit
เริ่มต้นกับ Amazon Scraper Python: สิ่งที่ต้องมีและการตั้งค่า
ก่อนจะลงมือเขียนโค้ด มาจัดสภาพแวดล้อมให้พร้อมกันก่อน
คุณจะต้องมี:
- Python 3.x (ดาวน์โหลดได้จาก )
- ตัวแก้ไขโค้ด (ผมชอบ VS Code แต่ใช้ตัวไหนก็ได้)
- ไลบรารีต่อไปนี้:
requests(สำหรับส่งคำขอ HTTP)beautifulsoup4(สำหรับแยกวิเคราะห์ HTML)lxml(ตัวแยกวิเคราะห์ HTML ที่เร็ว)pandas(สำหรับตารางข้อมูล/การส่งออก)re(regular expressions, มีมาในตัว)
ติดตั้งไลบรารี:
1pip install requests beautifulsoup4 lxml pandasการตั้งค่าโปรเจกต์:
- สร้างโฟลเดอร์ใหม่สำหรับโปรเจกต์ของคุณ
- เปิดตัวแก้ไขโค้ด สร้างไฟล์ Python ใหม่ (เช่น
amazon_scraper.py) - พร้อมเริ่มได้เลย!
ทีละขั้นตอน: การทำเว็บสแครปปิ้งด้วย Python สำหรับข้อมูลสินค้าจาก Amazon
มาดูวิธีสแครปหน้าสินค้าหนึ่งหน้าของ Amazon กันก่อน (ไม่ต้องห่วง เดี๋ยวเราจะไปต่อเรื่องการสแครปหลายสินค้าและหลายหน้าต่อในอีกสักครู่)
1. ส่งคำขอและดึง HTML
ก่อนอื่น มาดึง HTML ของหน้าสินค้ากัน (เปลี่ยน URL เป็นสินค้าของ Amazon หน้าไหนก็ได้)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)ระวังไว้: คำขอพื้นฐานแบบนี้มีโอกาสสูงที่จะถูก Amazon บล็อก คุณอาจเห็นข้อผิดพลาด 503 หรือ CAPTCHA แทนหน้าสินค้า ทำไมถึงเป็นแบบนั้น? เพราะ Amazon รู้ว่าคุณไม่ใช่เบราว์เซอร์จริง
จัดการมาตรการป้องกันบอทของ Amazon
Amazon ไม่ค่อยเป็นมิตรกับบอทเท่าไหร่ ถ้าไม่อยากถูกบล็อก คุณต้อง:
- ตั้งค่าเฮดเดอร์ User-Agent (ปลอมตัวเป็น Chrome หรือ Firefox)
- สลับ User-Agent (อย่าใช้ตัวเดิมทุกครั้ง)
- หน่วงคำขอ (ใส่ดีเลย์แบบสุ่ม)
- ใช้พร็อกซี (สำหรับการสแครปขนาดใหญ่)
นี่คือตัวอย่างการตั้งค่าเฮดเดอร์:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)อยากให้ดูโปรขึ้นอีกหน่อยไหม? ใช้ลิสต์ของ User-Agent แล้วสลับใช้แต่ละครั้ง สำหรับงานใหญ่ คุณจะอยากใช้บริการพร็อกซี (มีให้เลือกเยอะมาก) แต่ถ้าเป็นการสแครปเล็กๆ เฮดเดอร์กับดีเลย์ก็มักจะพอ
ดึงฟิลด์สำคัญของสินค้า
เมื่อได้ HTML มาแล้ว ก็ถึงเวลาแยกวิเคราะห์ด้วย BeautifulSoup
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")ต่อไปมาดึงข้อมูลสำคัญกัน:
ชื่อสินค้า
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else Noneราคา
ราคาของ Amazon อาจอยู่หลายที่ ลองตามนี้:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textเรตติ้งและจำนวนรีวิว
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # เช่น "1,554 ratings"URL รูปภาพหลัก
บางครั้ง Amazon ซ่อนภาพความละเอียดสูงไว้ใน JSON ภายใน HTML นี่คือวิธีใช้ regex แบบเร็วๆ:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else Noneหรือจะดึงแท็กรูปภาพหลักโดยตรงก็ได้:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else Noneรายละเอียดสินค้า
สเปกอย่างแบรนด์ น้ำหนัก และขนาด มักอยู่ในตาราง:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueหรือถ้า Amazon ใช้รูปแบบ “detailBullets”:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()พิมพ์ผลลัพธ์ออกมาดู:
1print("Title:", product_title)
2print("Price:", price)
3print("Rating:", rating, "based on", reviews_count, "reviews")
4print("Main image URL:", main_image_url)
5print("Details:", details)สแครปหลายสินค้าและจัดการการแบ่งหน้า
สินค้าเดียวอาจจะพอได้ แต่ส่วนใหญ่คุณน่าจะต้องการเป็นลิสต์ยาวๆ วิธีดึงผลการค้นหาและหลายหน้าทำได้แบบนี้
ดึงลิงก์สินค้าออกจากหน้าค้นหา
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)จัดการการแบ่งหน้า
URL ค้นหาของ Amazon ใช้ &page=2, &page=3 เป็นต้น
1for page in range(1, 6): # สแครป 5 หน้าแรก
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... ดึงลิงก์สินค้าเหมือนด้านบน ...วนลูปผ่านหน้าสินค้าและส่งออกเป็น CSV
รวบรวมข้อมูลสินค้าไว้ในลิสต์ของดิกชันนารี แล้วใช้ pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # list of dicts
3df.to_csv("amazon_products.csv", index=False)หรือส่งออกเป็น Excel:
1df.to_excel("amazon_products.xlsx", index=False)แนวปฏิบัติที่ดีที่สุดสำหรับโปรเจกต์ Amazon Scraper Python
พูดกันตามจริง—Amazon เปลี่ยนเว็บไซต์ตัวเองตลอดเวลาและคอยสู้กับสแครปเปอร์อยู่เสมอ วิธีทำให้โปรเจกต์ของคุณยังใช้งานได้มีดังนี้:
- สลับเฮดเดอร์และ User-Agent (ใช้ไลบรารีอย่าง
fake-useragent) - ใช้พร็อกซี สำหรับการสแครปขนาดใหญ่
- หน่วงคำขอ (สุ่ม
time.sleep()ระหว่างแต่ละคำขอ) - จัดการข้อผิดพลาดอย่างนุ่มนวล (ลองใหม่เมื่อเจอ 503, ถอยกลับเมื่อถูกบล็อก)
- เขียนตรรกะการแยกข้อมูลให้ยืดหยุ่น (มองหาหลายตัวเลือกสำหรับแต่ละฟิลด์)
- เฝ้าดูการเปลี่ยนแปลงของ HTML (ถ้าสคริปต์จู่ๆ คืนค่า
Noneทุกอย่าง ให้เช็กหน้าเว็บ) - เคารพ robots.txt (Amazon ไม่อนุญาตให้สแครปหลายส่วน—ทำอย่างรับผิดชอบ)
- ทำความสะอาดข้อมูลไปพร้อมกัน (ตัดสัญลักษณ์สกุลเงิน เครื่องหมายจุลภาค และช่องว่าง)
- เชื่อมต่อกับคอมมูนิตี้ไว้เสมอ (ฟอรัม, Stack Overflow, Reddit r/webscraping)
เช็กลิสต์สำหรับดูแลสแครปเปอร์ของคุณ:
- [ ] สลับ User-Agent และเฮดเดอร์
- [ ] ใช้พร็อกซีถ้าสแครปในสเกลใหญ่
- [ ] ใส่ดีเลย์แบบสุ่ม
- [ ] แยกโค้ดเป็นโมดูลเพื่ออัปเดตง่าย
- [ ] เฝ้าดูการแบนหรือ CAPTCHA
- [ ] ส่งออกข้อมูลเป็นประจำ
- [ ] บันทึก selectors และตรรกะของคุณไว้
ถ้าอยากเจาะลึกกว่านี้ ลองดู ของผม
ทางเลือกแบบไม่ต้องเขียนโค้ด: สแครป Amazon ด้วย Thunderbit AI Web Scraper
โอเค ตอนนี้คุณเห็นวิธีแบบ Python แล้ว แต่ถ้าคุณไม่อยากเขียนโค้ด—หรือแค่อยากได้ข้อมูลในสองคลิกแล้วไปใช้ชีวิตต่อ Thunderbit ก็คือตัวเลือกนั้น
Thunderbit คือส่วนขยาย Chrome แบบ AI web scraper ที่ให้คุณดึงข้อมูลสินค้าจาก Amazon (และเกือบทุกเว็บไซต์) ได้โดยไม่ต้องเขียนโค้ดเลย นี่คือเหตุผลที่ผมชอบมัน:
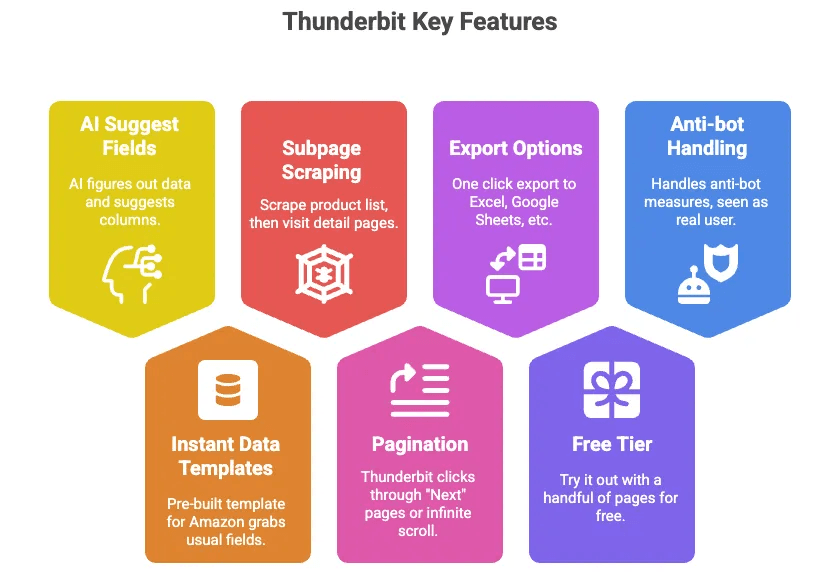
- AI Suggest Fields: แค่คลิกปุ่มเดียว AI ของ Thunderbit จะดูว่าในหน้ามีข้อมูลอะไร แล้วแนะนำคอลัมน์ให้ เช่น ชื่อ, ราคา, เรตติ้ง ฯลฯ
- เทมเพลตข้อมูลพร้อมใช้ทันที: สำหรับ Amazon มีเทมเพลตสำเร็จรูปที่ดึงฟิลด์มาตรฐานให้ครบ—ไม่ต้องตั้งค่าอะไรเพิ่ม
- การสแครปหน้าย่อย: ดึงลิสต์สินค้า แล้วให้ Thunderbit เข้าไปที่หน้ารายละเอียดของแต่ละสินค้าเพื่อดึงข้อมูลเพิ่มให้อัตโนมัติ
- การแบ่งหน้า: Thunderbit คลิกหน้า “ถัดไป” หรือเลื่อนแบบไม่สิ้นสุดให้คุณได้
- ส่งออกไปยัง Excel, Google Sheets, Airtable, Notion: คลิกครั้งเดียว ข้อมูลก็พร้อมใช้งาน
- ใช้ฟรีได้: ทดลองกับหลายหน้าฟรีได้
- จัดการเรื่องบอทให้คุณ: เพราะมันรันในเบราว์เซอร์ของคุณ (หรือบนคลาวด์) Amazon จึงมองว่าเป็นผู้ใช้จริง
ทีละขั้นตอน: ใช้ Thunderbit ดึงข้อมูลสินค้าจาก Amazon
ง่ายมากแบบนี้:
-
ติดตั้ง Thunderbit:
ดาวน์โหลด แล้วลงชื่อเข้าใช้
-
เปิด Amazon:
ไปที่หน้า Amazon ที่คุณต้องการสแครป (ผลการค้นหา, หน้าสินค้า, อะไรก็ได้)
-
คลิก “AI Suggest Fields” หรือใช้เทมเพลต:
Thunderbit จะเสนอคอลัมน์ให้ดึงข้อมูล (หรือคุณจะเลือกเทมเพลต Amazon Product ก็ได้)
-
ตรวจสอบคอลัมน์:
ปรับคอลัมน์ได้ตามต้องการ (เพิ่ม/ลบฟิลด์, เปลี่ยนชื่อ ฯลฯ)
-
คลิก “สแครป”:
Thunderbit จะดึงข้อมูลจากหน้าแล้วแสดงเป็นตาราง
-
จัดการหน้าย่อยและการแบ่งหน้า:
ถ้าคุณสแครปลิสต์สินค้า ให้คลิก “สแครปหน้าย่อย” เพื่อเข้าไปดูหน้ารายละเอียดแต่ละสินค้าและดึงข้อมูลเพิ่ม Thunderbit ยังคลิก “ถัดไป” ให้เองได้ด้วย
-
ส่งออกข้อมูลของคุณ:
คลิก “ส่งออกไปยัง Excel” หรือ “ส่งออกไปยัง Google Sheets” เสร็จเรียบร้อย
-
(ทางเลือก) ตั้งเวลาสแครป:
ต้องการข้อมูลนี้ทุกวันไหม? ใช้ตัวตั้งเวลาของ Thunderbit เพื่อทำอัตโนมัติได้
แค่นั้นเอง ไม่ต้องเขียนโค้ด ไม่ต้องดีบัก ไม่ต้องใช้พร็อกซี ไม่ต้องปวดหัว ถ้าอยากดูแบบภาพ ลองดู หรือ
เปรียบเทียบแบบข้างต่อข้าง: Amazon Scraper Python vs. Web Scraper แบบไม่ต้องเขียนโค้ด
มารวมทุกอย่างเข้าด้วยกัน:
| เกณฑ์ | Python Scraper | Thunderbit (ไม่ต้องเขียนโค้ด) |
|---|---|---|
| เวลาตั้งค่า | สูง (ติดตั้ง, เขียนโค้ด, ดีบัก) | ต่ำ (ติดตั้งส่วนขยาย) |
| ทักษะที่ต้องใช้ | ต้องเขียนโค้ด | ไม่ต้องมี (ชี้แล้วคลิก) |
| ความยืดหยุ่น | ไม่จำกัด | สูงสำหรับกรณีใช้งานทั่วไป |
| การดูแลรักษา | คุณต้องแก้โค้ดเอง | เครื่องมืออัปเดตตัวเอง |
| การรับมือบอท | คุณต้องจัดการพร็อกซีและเฮดเดอร์เอง | มีในตัวและจัดการให้แล้ว |
| การขยายสเกล | ทำเองแบบแมนนวล (เธรด, พร็อกซี) | สแครปบนคลาวด์, ทำงานแบบขนาน |
| การส่งออกข้อมูล | ปรับเองได้ (CSV, Excel, DB) | คลิกเดียวไป Excel, Sheets |
| ค่าใช้จ่าย | ฟรี (แต่เสียเวลา + พร็อกซี) | ฟรีเมียม, จ่ายเมื่อขยายสเกล |
| เหมาะที่สุดสำหรับ | นักพัฒนา, ความต้องการเฉพาะทาง | ผู้ใช้ธุรกิจ, ต้องการผลลัพธ์เร็ว |
ถ้าคุณเป็นนักพัฒนาที่ชอบปรับแต่งและต้องการอะไรที่เฉพาะตัวสุดๆ Python คือเพื่อนของคุณ แต่ถ้าคุณอยากได้ความเร็ว ความง่าย และไม่ต้องเขียนโค้ด Thunderbit คือทางที่เหมาะกว่า
ควรเลือก Python, แบบไม่ต้องเขียนโค้ด หรือ AI web scraper สำหรับข้อมูล Amazon เมื่อไร
เลือก Python ถ้า:
- คุณต้องการตรรกะแบบกำหนดเอง หรืออยากเชื่อมการสแครปเข้ากับระบบแบ็กเอนด์
- คุณสแครปในสเกลใหญ่มาก (หลักหมื่นสินค้า)
- คุณอยากเรียนรู้ว่าเบื้องหลังการสแครปทำงานยังไง
เลือก Thunderbit (ไม่ต้องเขียนโค้ด, AI web scraper) ถ้า:
- คุณต้องการข้อมูลเร็ว โดยไม่ต้องเขียนโค้ด
- คุณเป็นผู้ใช้ธุรกิจ นักวิเคราะห์ หรือมาร์เก็ตเตอร์
- คุณอยากให้ทีมของคุณดึงข้อมูลเองได้
- คุณอยากเลี่ยงความยุ่งยากเรื่องพร็อกซี มาตรการป้องกันบอท และการดูแลรักษา
ใช้ทั้งสองอย่างถ้า:
- คุณอยากทำต้นแบบเร็วๆ ด้วย Thunderbit แล้วค่อยสร้างโซลูชัน Python แบบกำหนดเองสำหรับใช้งานจริง
- คุณอยากใช้ Thunderbit สำหรับเก็บข้อมูล และใช้ Python สำหรับทำความสะอาด/วิเคราะห์ข้อมูล
สำหรับผู้ใช้ธุรกิจส่วนใหญ่ Thunderbit ตอบโจทย์ความต้องการสแครป Amazon ได้ 90% ภายในเวลาเพียงเศษเสี้ยวของวิธีแบบโค้ด ส่วนอีก 10% ที่ต้องการความเฉพาะสูง ขนาดใหญ่ หรือเชื่อมต่อเชิงลึก Python ก็ยังเป็นตัวจริงอยู่ดี
สรุปและประเด็นสำคัญ
การสแครปข้อมูลสินค้าจาก Amazon คือพลังพิเศษสำหรับทีมเซลส์ อีคอมเมิร์ซ หรือโอเปอเรชันทุกทีม ไม่ว่าคุณจะกำลังติดตามราคา วิเคราะห์คู่แข่ง หรือแค่พยายามช่วยทีมให้พ้นจากงานก็อปปี้วางไม่รู้จบ ก็มีโซลูชันให้คุณแน่นอน
- การสแครปด้วย Python ให้คุณควบคุมได้เต็มที่ แต่ก็มีเส้นทางการเรียนรู้และต้องดูแลต่อเนื่อง
- เครื่องมือดึงข้อมูลเว็บแบบไม่ต้องเขียนโค้ดอย่าง Thunderbit ทำให้ทุกคนเข้าถึงการดึงข้อมูลจาก Amazon ได้—ไม่ต้องเขียนโค้ด ไม่ต้องปวดหัว แค่ได้ผลลัพธ์
- แนวทางที่ดีที่สุดคืออะไร? ใช้เครื่องมือที่เหมาะกับทักษะ เวลาที่มี และเป้าหมายทางธุรกิจของคุณ
ถ้าคุณอยากลอง ลองใช้ Thunderbit ดูได้เลย—เริ่มต้นฟรี และคุณจะทึ่งว่าดึงข้อมูลที่ต้องการได้เร็วแค่ไหน และถ้าคุณเป็นนักพัฒนา ก็อย่ากลัวที่จะผสมวิธีเข้าด้วยกัน: บางครั้งวิธีสร้างงานได้เร็วที่สุด คือให้ AI จัดการส่วนที่น่าเบื่อให้คุณ
คำถามที่พบบ่อย
1. ทำไมธุรกิจถึงอยากสแครปข้อมูลสินค้าจาก Amazon?
การสแครป Amazon ช่วยให้ธุรกิจติดตามราคา วิเคราะห์คู่แข่ง รวบรวมรีวิวเพื่อวิจัยสินค้า คาดการณ์ดีมานด์ และหาลีดการขายได้ ด้วยสินค้ามากกว่า 600 ล้านรายการและผู้ขายเกือบ 2 ล้านรายบน Amazon ที่นี่จึงเป็นแหล่งข้อมูลเชิงแข่งขันชั้นเยี่ยม
2. ความแตกต่างหลักระหว่างการใช้ Python กับเครื่องมือแบบไม่ต้องเขียนโค้ดอย่าง Thunderbit ในการสแครป Amazon คืออะไร?
สแครปเปอร์ Python ให้ความยืดหยุ่นสูงสุด แต่ต้องใช้ทักษะการเขียนโค้ด เวลาในการตั้งค่า และการดูแลรักษาอย่างต่อเนื่อง ส่วน Thunderbit ซึ่งเป็น AI web scraper แบบไม่ต้องเขียนโค้ด ให้ผู้ใช้ดึงข้อมูล Amazon ได้ทันทีผ่านส่วนขยาย Chrome—ไม่ต้องเขียนโค้ด พร้อมการจัดการบอทในตัวและตัวเลือกส่งออกไปยัง Excel หรือ Sheets
3. การสแครปข้อมูลจาก Amazon ถูกกฎหมายไหม?
โดยทั่วไปข้อกำหนดการใช้งานของ Amazon ห้ามการสแครป และพวกเขาก็มีมาตรการป้องกันบอทอย่างจริงจัง อย่างไรก็ตาม หลายธุรกิจยังคงสแครปข้อมูลสาธารณะที่เข้าถึงได้ โดยดำเนินการอย่างรับผิดชอบ เช่น เคารพอัตราการร้องขอและหลีกเลี่ยงการส่งคำขอมากเกินไป
4. ฉันสามารถดึงข้อมูลอะไรจาก Amazon ด้วยเครื่องมือเว็บสแครปปิ้งได้บ้าง?
ฟิลด์ข้อมูลที่พบบ่อยได้แก่ ชื่อสินค้า ราคา เรตติ้ง จำนวนรีวิว รูปภาพ สเปกสินค้า ความพร้อมจำหน่าย และแม้แต่ข้อมูลผู้ขาย Thunderbit ยังรองรับการสแครปหน้าย่อยและการแบ่งหน้า เพื่อเก็บข้อมูลจากหลายรายการและหลายหน้าได้ด้วย
5. เมื่อไรควรเลือกการสแครปด้วย Python แทนเครื่องมืออย่าง Thunderbit หรือกลับกัน?
ใช้ Python ถ้าคุณต้องการการควบคุมเต็มรูปแบบ ตรรกะเฉพาะทาง หรือวางแผนจะเชื่อมการสแครปเข้ากับระบบแบ็กเอนด์ ใช้ Thunderbit ถ้าคุณต้องการผลลัพธ์เร็วโดยไม่เขียนโค้ด ต้องการขยายสเกลได้ง่าย หรือเป็นผู้ใช้ธุรกิจที่มองหาโซลูชันที่ดูแลรักษาง่าย
อยากลงลึกกว่านี้ไหม? ลองดูแหล่งข้อมูลเหล่านี้:
ขอให้สแครปกันอย่างมีความสุข—and may your spreadsheets always be up to date.