Substack-scraper
Används av proffs på ledande företag














Lås upp Substack-data med Thunderbit
Skicka Substack-data direkt till dina appar
Sluta kopiera och klistra in publikationsdetaljer från Substack manuellt, som författarnamn, artikelrubrik och prenumerantantal. Med Thunderbit räcker ett klick för att skicka din extraherade data direkt till Google Sheets, Notion eller Airtable. Analysera publikationstrender och innehållsprestanda utan det tidskrävande manuella arbetet.
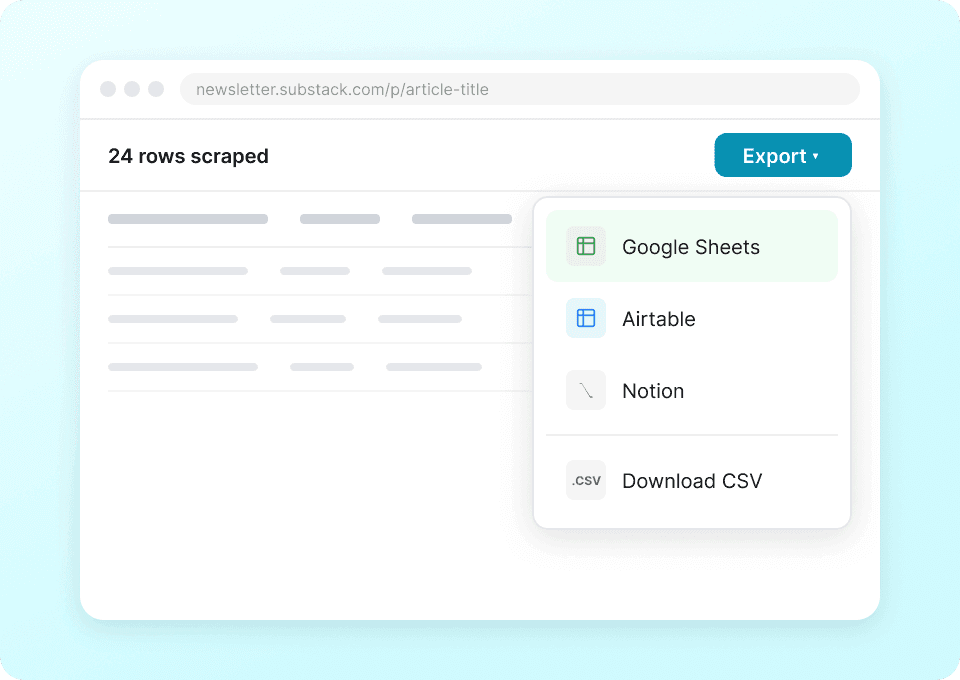
En scraper för Substack och mer
Fastna inte med en annan scraper för varje webbplats. Thunderbit fungerar direkt med Substack och innehåller över 50 färdiga mallar för andra populära plattformar. Extrahera publikationsbeskrivningar, artikelinnehåll och mer, och använd sedan samma verktyg för att samla data var som helst annars.
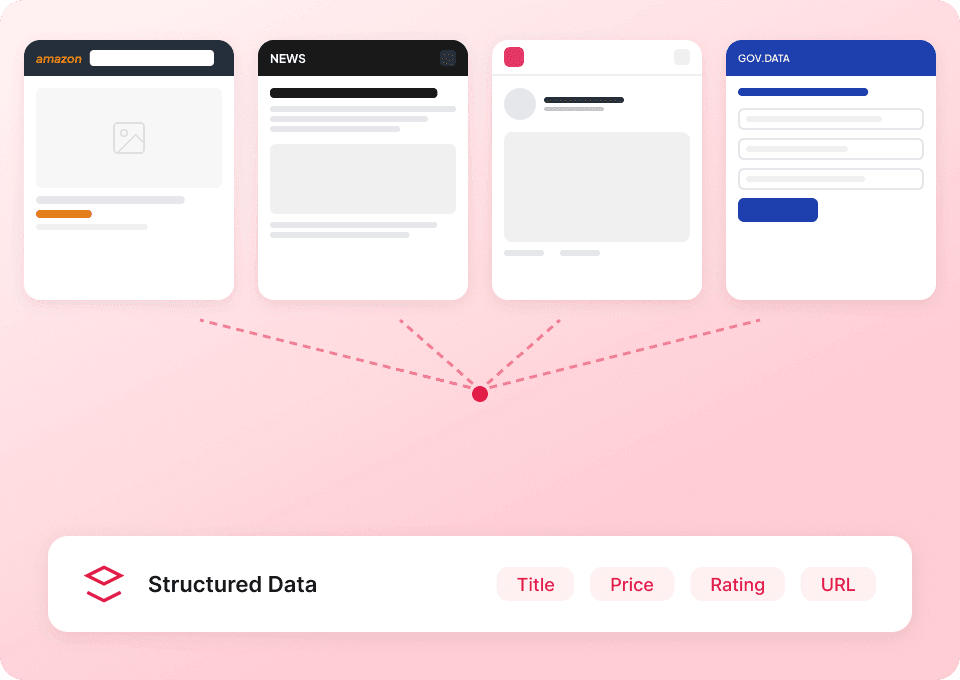
Få hela Substack-historien
Substacks listningssidor visar bara sammanfattningar. Thunderbit besöker automatiskt varje artikels undersida för att extrahera hela innehållet, så att du får ett komplett dataset. Få hela artikelrubriken, författarnamnet, publikationsnamnet och artikelinnehållet i ett svep.
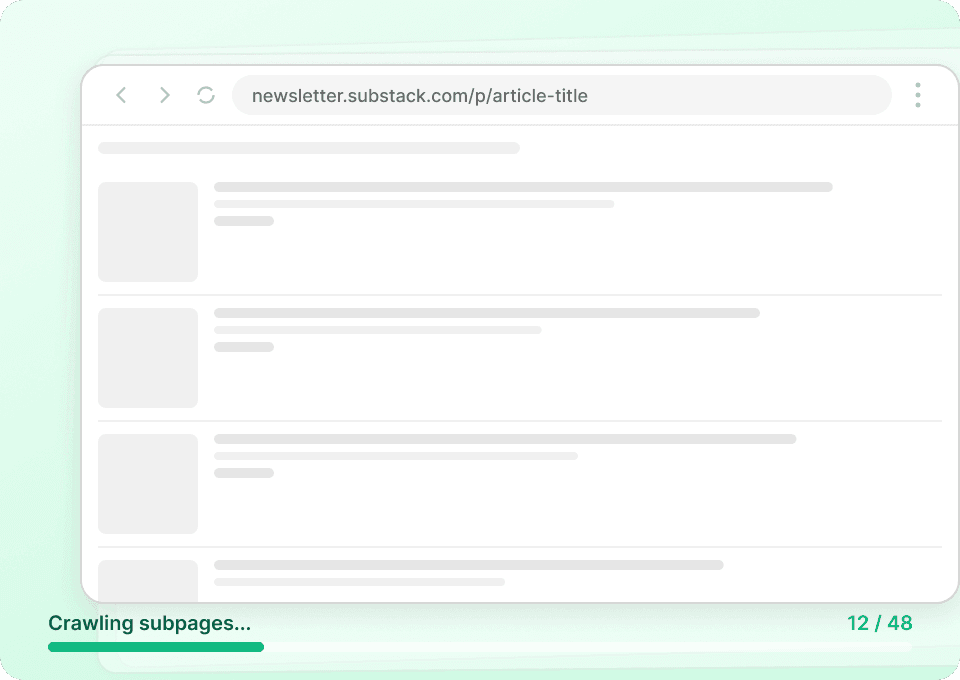
Har du svårt att skrapa Substack effektivt?
Se varför Thunderbit slår traditionella scrapers för Substack-data.
Traditionella scrapers
Det gamla sättet att göra saker påThunderbit
Det smartare sättetTa inte bara vårt ord för det
Se vad våra användare säger om Thunderbit.





Vanliga frågor
Relaterat användningsområden
Utforska fler användningsområden för Thunderbits webbscraper.

PubMed Scraper
Thunderbits PubMed Scraper hjälper dig att med AI hämta strukturerad data från PubMeds sökresultat och artikelsidor. Skrapa trendande medicinsk forskning, evidens från kliniska prövningar, abstrakt, författare, affiliationer, publiceringsdatum och länkar – och exportera till Excel, Google Sheets, Airtable eller Notion.
Läs mer ->
PlayStation Scraper
Lås upp PlayStation-speldata som titel, genre och rabatterat pris med bara några klick – utan mer manuell kopiering och inklistring.
Läs mer ->
Craigslist-skrapa telefonnummer
Thunderbits Craigslist-skrapa för telefonnummer hjälper dig att med AI hämta telefonnummer och annonsdetaljer från Craigslists sökresultat. Skrapa annonser, låt verktyget öppna varje inlägg för att få kontaktuppgifter och fler fält, och exportera sedan till Excel, Google Sheets, Airtable, Notion, CSV eller JSON.
Läs mer ->
HKTVmall Scraper
Samla in produktnamn, priser och till och med kundbetyg från HKTVmall-listningar med bara några få klick — utan någon komplicerad installation.
Läs mer ->
Trivago-skrapare
Skrapa hotellnamn, priser och betyg från Trivago med bara några klick — ingen kod eller installation behövs.
Läs mer ->
Priceline-scraper
Hämta hotellnamn, priser och betyg från Priceline med bara några klick tack vare Thunderbits AI.
Läs mer ->Redo att lyfta din datautvinning till nästa nivå?
Gå med över 100 000 proffs som redan använder Thunderbit för att automatisera sina webbscrapingflöden.
Den kostnadsfria testperioden ger obegränsade krediter för 8 webbsidor.