IDCrawl Scraper
Används av proffs på ledande företag














Icrawl-data som förblir användbar
Använd idcrawl för att extrahera data snabbare, renare och i större skala med Thunderbit.
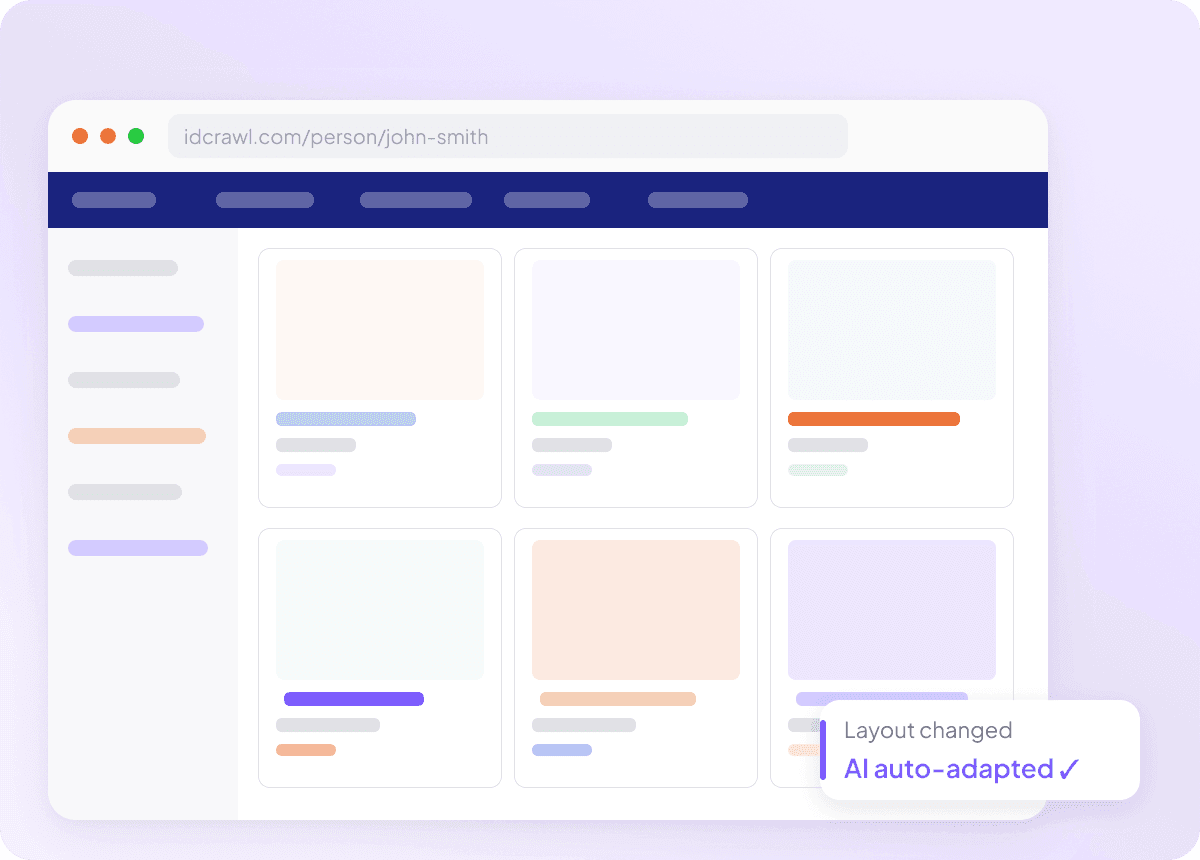
Anpassar sig när Idcrawl ändras
Scrapers som går sönder vid varje webbplatsuppdatering är värdelösa, särskilt när du försöker hämta fullständigt namn, jobbtitel, företagsnamn, e-postadress, telefonnummer och LinkedIn-profil från idcrawl. Thunderbit läser sidan efter innebörd, inte efter fasta selektorer, så den kan anpassa sig när layouten förändras. Du lägger mindre tid på att fixa scrapers och mer tid på att få fram datan du behöver.
Ren data från början
Rådata är bara början på det riktiga arbetet, och resultat från idcrawl behöver ofta städas upp innan de blir användbara. Thunderbit strukturerar och formaterar datan under extraheringen, så det du exporterar är redan rent och redo att använda. Det betyder mindre sortering, mindre omarbete och en smidigare överlämning till ditt team.
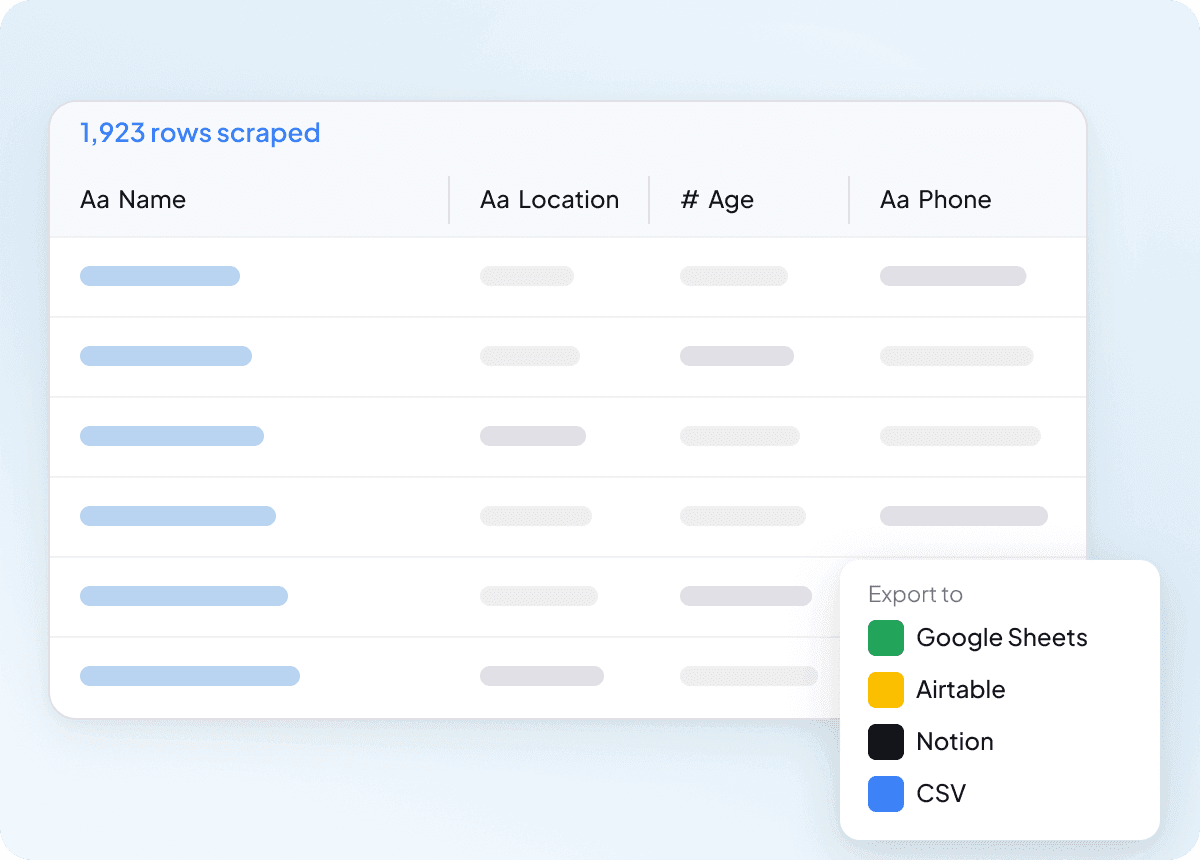
Skrapa Idcrawl i bulk på en gång
Att skrapa en idcrawl-sida i taget skalar inte när du behöver en lång lista med kontakter. Thunderbit kan skrapa hundratals sidor i bulk på en gång, så du kan mata in en lista med URL:er och extrahera fullständigt namn, jobbtitel, företagsnamn, e-postadress, telefonnummer och LinkedIn-profil över alla. Det är ett mycket enklare sätt att omvandla en stor lista till användbar data.

Varför skiljer sig Thunderbit från traditionella idcrawl-scrapers?
Ett enklare sätt att extrahera idcrawl-data utan ständiga fixar.
Traditionella scrapers
Det gamla sättet att göra saker påThunderbit AI
Det smartare tillvägagångssättetTa inte bara vårt ord för det
Se vad våra användare säger om Thunderbit.





Vanliga frågor
Relaterat användningsområden
Utforska fler användningsområden för Thunderbits webbscraper.
Video Scraper
Thunderbits Video Scraper gör det enkelt att hämta video- och kreatörsdata med AI på bara några klick. Skrapa videolistor, prestationsmått och profildetaljer och exportera sedan till Excel, Google Sheets, Airtable eller Notion för uppföljning och influencer-research.
Läs mer ->
HKTVmall Scraper
Samla in produktnamn, priser och till och med kundbetyg från HKTVmall-listningar med bara några få klick — utan någon komplicerad installation.
Läs mer ->
UNIQLO Scraper
Samla in produktdata från UNIQLO, som namn, priser och tillgängliga storlekar, med bara 2 klick tack vare Thunderbits Chrome-tillägg.
Läs mer ->
Coupang-scraper
Hämta produktnamn, priser och rabattnivåer från Coupang med två klick — ingen kodning behövs.
Läs mer ->
Spokeo Scraper
Sluta kopiera Spokeo-data manuellt — använd Thunderbit för att hämta namn, åldrar, adresser och mer med bara ett par klick.
Läs mer ->
Wikipedia-skrapare
Hämta infoboxdata, referenser och artikeltext från Wikipedia till ett rent kalkylark — ingen kod behövs, AI sköter struktureringen åt dig.
Läs mer ->Redo att lyfta din datautvinning till nästa nivå?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Den kostnadsfria testperioden ger obegränsade krediter för 8 webbsidor.