

Om du behöver webbdata 2026 är den svåra frågan inte längre ”går det här att skrapa?” utan ”vilket verktyg ger mig användbar data med minst spill på setup, underhåll och infrastrukturkostnader?” Därför är den här sidan upplagd utifrån vad som passar bäst först: ai-webbskrapare för snabbhet, no-code-verktyg för återkommande webbläsarjobb, API:er för skala och anti-bot-hantering, samt Python-bibliotek för team som vill ha full kontroll.
Det korta svaret
- Välj en ai-webbskrapare om du vill gå snabbast från sida till kalkylark med minimal setup.
- Välj en no-code-skrapare om du behöver tydligare sidnumrering, schemaläggning, inloggningshantering eller återkommande kontroll över uppgifter.
- Välj ett skrapnings-API om rendering, anti-bot-skydd, samtidighet och hög blockeringstolerans är viktigare än ett enkelt gränssnitt.
- Välj ett Python-bibliotek om ditt team vill äga hela kedjan själv: förfrågningar, parsing, webbläsarautomatisering, omförsök och driftsättning.
För de flesta affärsteam är misstaget att gå för långt ner i stacken för tidigt. Börja med det enklaste verktyg som faktiskt klarar jobbet pålitligt, och gå sedan från AI till no-code till API:er till kod först när arbetsflödet verkligen kräver det.
Ladda ner hela det visuella paketet här: visuellt paket för webbskrapningsverktyg.
Snabb jämförelsetabell: verktyg för webbskrapning i översikt
Prissignalerna nedan kontrollerades mot officiella produkt-, pris- eller dokumentationssidor den 12 maj 2026. När leverantörer använder anpassad eller användningsbaserad fakturering beskriver jag prissättningsmodellen i stället för att tvinga fram ett falskt månadsbelopp som går att jämföra direkt.
| Verktyg | Kategori | Bäst för | Varför det kom med på 2026 års lista | Prissignal (kontrollerad i maj 2026) |
|---|---|---|---|---|
| Thunderbit | ai-webbskrapare | Försäljning, drift, e-handel, fastigheter | Snabbaste icke-tekniska vägen från webbsida till strukturerad tabell | Gratis plan, betalda nivåer, företagspriser |
| Kadoa | AI-extraktionsplattform | Datateam och större återkommande program | Stark matchning för självhelande extraktionsflöden i agentstil | Gratis utvärdering, användningsbaserade och företagsplaner |
| Octoparse | No-code-skrapare | Analytiker och återkommande driftuppgifter | Mogen molnskrapning och visuell uppgiftsbyggare | Gratis plan, Standard från 69 USD/månad, högre nivåer |
| ParseHub | Low-code-skrapare | Tekniska icke-kodare och forskare | Flexibel navigeringslogik för svårare webbplatser | Gratis plan, betalda planer från 189 USD/månad |
| Web Scraper | No-code-skrapare i webbläsaren | Nybörjare och lätta återkommande jobb | Enkel sitemap-modell med valfritt molnlager | Gratis tillägg, Cloud från 50 USD/månad |
| Browse AI | No-code-robot-skrapare | Övervakning och kalkylarksfokuserade team | Stark för återkommande övervakning och ändringslarm | Gratis plan, betalda planer, hanterad nivå |
| Bardeen | AI-webbläsarautomatisering | GTM- och revops-automatisering | Bäst när skrapning bara är ett steg i ett större arbetsflöde | Gratis plan, Basic från 10 USD/månad, Premium och Enterprise |
| ScrapeStorm | AI-assisterad visuell skrapare | Användare som vill ha snabb visuell setup | Bra mellanläge mellan manuella väljare och AI-assistans | Gratis provperiod, betalda planer, företagspriser |
| ScraperAPI | Skrapnings-API | Utvecklare som skalar upp begärandevolym | Enkelt API plus proxy, CAPTCHA och rendering avlastas | 7-dagars provperiod, betalt från 49 USD/månad |
| Bright Data Web Scraper | Enterprise-plattform för skrapning | Upphandlingsintensiva och compliance-fokuserade program | Brett datainsamlingsstack i gruppen | Produktbaserad och användningsbaserad prissättning |
| Zyte | API + anti-bot-stack | Utvecklar- och datateam | Starka webbläsaråtgärder, JS-rendering och IP-rotering | 5 USD i gratis provkredit, användningsbaserade planer |
| ZenRows | Skrapnings-API | Startups och utvecklarteam | Rent anti-bot-API med lägre friktion vid införande | Gratis provperiod, Developer från 69 USD/månad |
| ScrapingBee | Skrapnings-API | Team som skrapar JS-tunga sajter | Användbart när rendering är det största problemet | Gratis provperiod, betalt från 49 USD/månad |
| Selenium | Öppen källkod för webbläsarautomatisering | QA-liknande flöden och interaktionsintensiv skrapning | Fortfarande relevant där exakt användarinteraktion spelar roll | Gratis och öppen källkod |
| Beautiful Soup | Python-bibliotek för parsing | Lättviktig Python-skrapning | Den enklaste parsern i stacken för stökig HTML | Gratis och öppen källkod |
| Playwright | Modern webbläsarautomatisering | Moderna webbappar och utvecklarteam | Bästa moderna valet för skriptad webbläsarskrapning | Gratis och öppen källkod |
| urllib3 | Python HTTP-bibliotek | Utvecklare som vill ha kontroll på låg nivå över förfrågningar | Bra grund när du vill äga transportbeteendet direkt | Gratis och öppen källkod |
Så väljer du rätt verktyg för webbskrapning
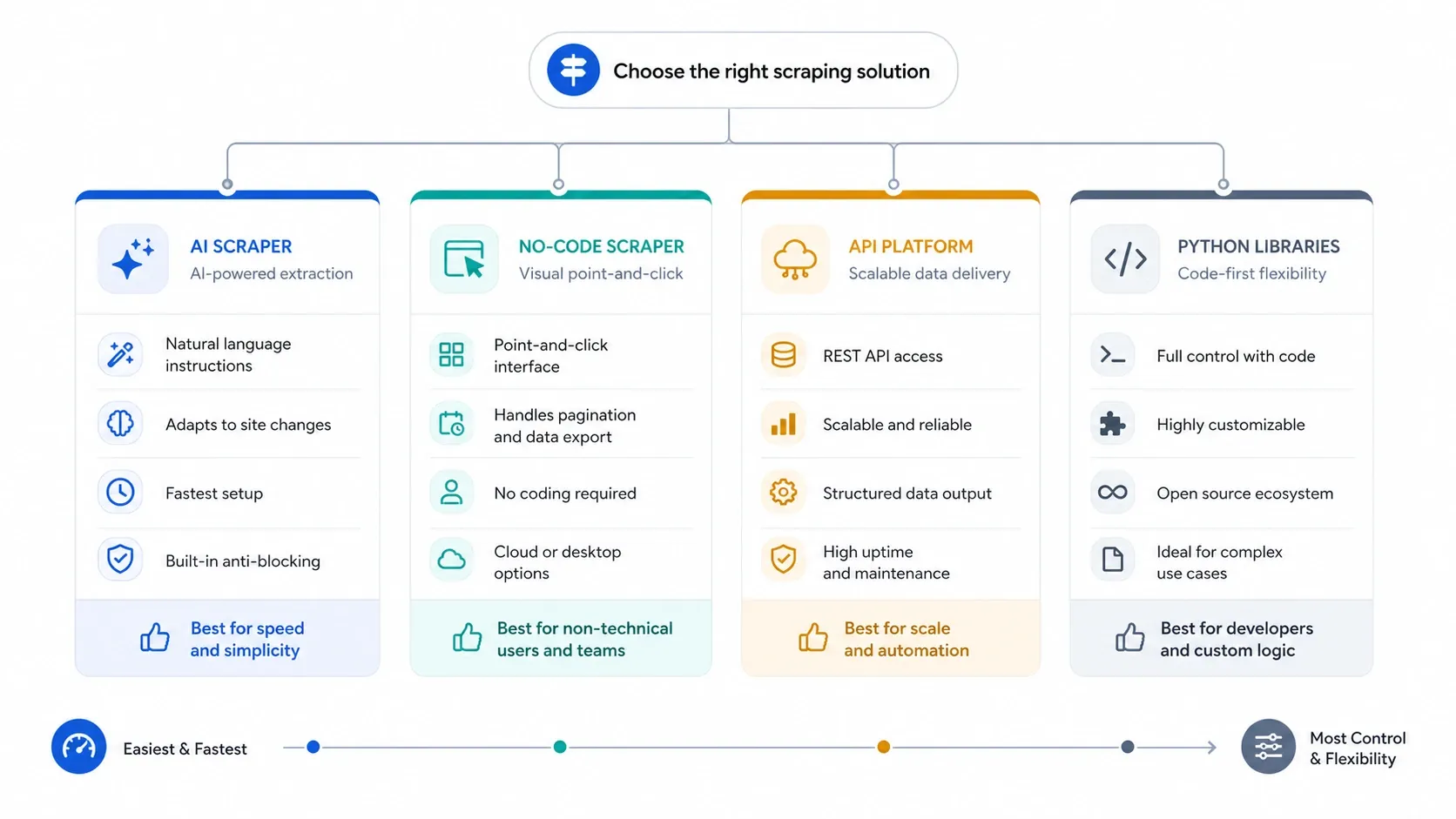
Använd fyra filter innan du jämför varumärken:
- Tid till första användbara resultat
Om verktyget inte snabbt kan få ut en riktig tabell, förlorar det redan för de flesta affärsfall. - Underhållsbehov
En billig skrapare som går sönder varje gång layouten ändras är inte egentligen billig. - Skalgräns
Ett webbläsartillägg kan vara perfekt för 50 sidor i veckan och katastrofalt för 5 miljoner förfrågningar per månad. - Passform för arbetsflödet
Den bästa skraparen för revops är sällan den bästa för en plattformsingenjör.
Beslutsramverket är oftast enklare än team tror:
- Om du vill skrapa leads, listningar eller produktsidor utan att röra väljare, börja med AI.
- Om du behöver återkommande uppgifter, molnkörningar och tydligare kontroll, gå till no-code-baserade visuella byggare.
- Om anti-bot, JavaScript-rendering och samtidighet är det verkliga problemet, hoppa till API:er.
- Om du vill äga varje lager själv, använd Python-bibliotek och acceptera underhållsbyrden.
Bästa ai-webbskrapare för snabba affärsflöden
Det här är den första kategori jag skulle testa om du vill ha data som går direkt att använda i kalkylark, med så lite konfiguration som möjligt.
1. Thunderbit
Thunderbit är fortfarande den enklaste startpunkten här för icke-kodare. Kärnfördelen är inte bara "AI" i abstrakt mening, utan att produkten komprimerar hela setup-loopen. Du öppnar en sida, ber AI föreslå fält, berikar via undersidor vid behov och skickar resultatet direkt till de verktyg teamet redan använder.
- Bäst för: prospektering inom försäljning, övervakning av e-handel, insamling inom fastigheter och driftteam som lever i webbläsaren.
- Det som gör den unik: snabbaste vägen från stökig sida till strukturerad tabell.
- Att tänka på: om du behöver logik på crawler-nivå eller mycket anpassade tekniska flöden kommer du till slut att gå vidare till API:er eller kod.
- Prissignal: gratis plan, självbetjänade betalda nivåer och företagspriser.
Den här genomgången är fortfarande det snabbaste sättet att avgöra om AI-först-skrapning räcker för ditt arbetsflöde:
Prova Thunderbit ai-webbskrapare gratis
2. Kadoa
Kadoa är det mer infrastrukturorienterade AI-alternativet i den här gruppen. Det passar när du vill ha självhelande extraktion och återkommande jobb i större operativ skala än vad de flesta webbläsartillägg är byggda för att hantera.
- Bäst för: datateam, interna intelligenprogram och större återkommande extraktionsarbetslaster.
- Det som gör den unik: agentlik orkestrering och en starkare berättelse kring minskat underhåll.
- Att tänka på: tyngre än vad de flesta affärsanvändare behöver för snabba engångsskrapningar.
- Prissignal: gratis utvärdering, användningsbaserade och företagsplaner.
Bästa no-code-verktyg för webbskrapning för återkommande jobb
När skrapningsjobbet blir återkommande börjar visuella arbetsflödesbyggare och molnkörning spela större roll än ren snabbhet i ett klick.
3. Octoparse
Octoparse är fortfarande ett av de mest trovärdiga no-code-verktygen när jobbet är större än ett webbläsartillägg men ännu inte ett skräddarsytt utvecklingsprojekt. Dess styrka ligger i kombinationen av molnkörningar, mallar och en mogen visuell byggare för uppgifter.
- Bäst för: analytiker, pristeam och återkommande insamlingsjobb med verklig operativ betydelse.
- Det som gör den unik: mer djup än webbläsarplugins, utan att tvinga dig in i kod.
- Att tänka på: den flexibiliteten kostar i form av brantare inlärningskurva än AI-först-verktyg.
- Prissignal: gratis plan, Standard från 69 USD/månad, högre betalda nivåer.
Om du vill utvärdera en mer traditionell no-code-miljö innan du satsar på AI-först-verktyg är den här officiella översikten av Octoparse fortfarande användbar:
4. ParseHub
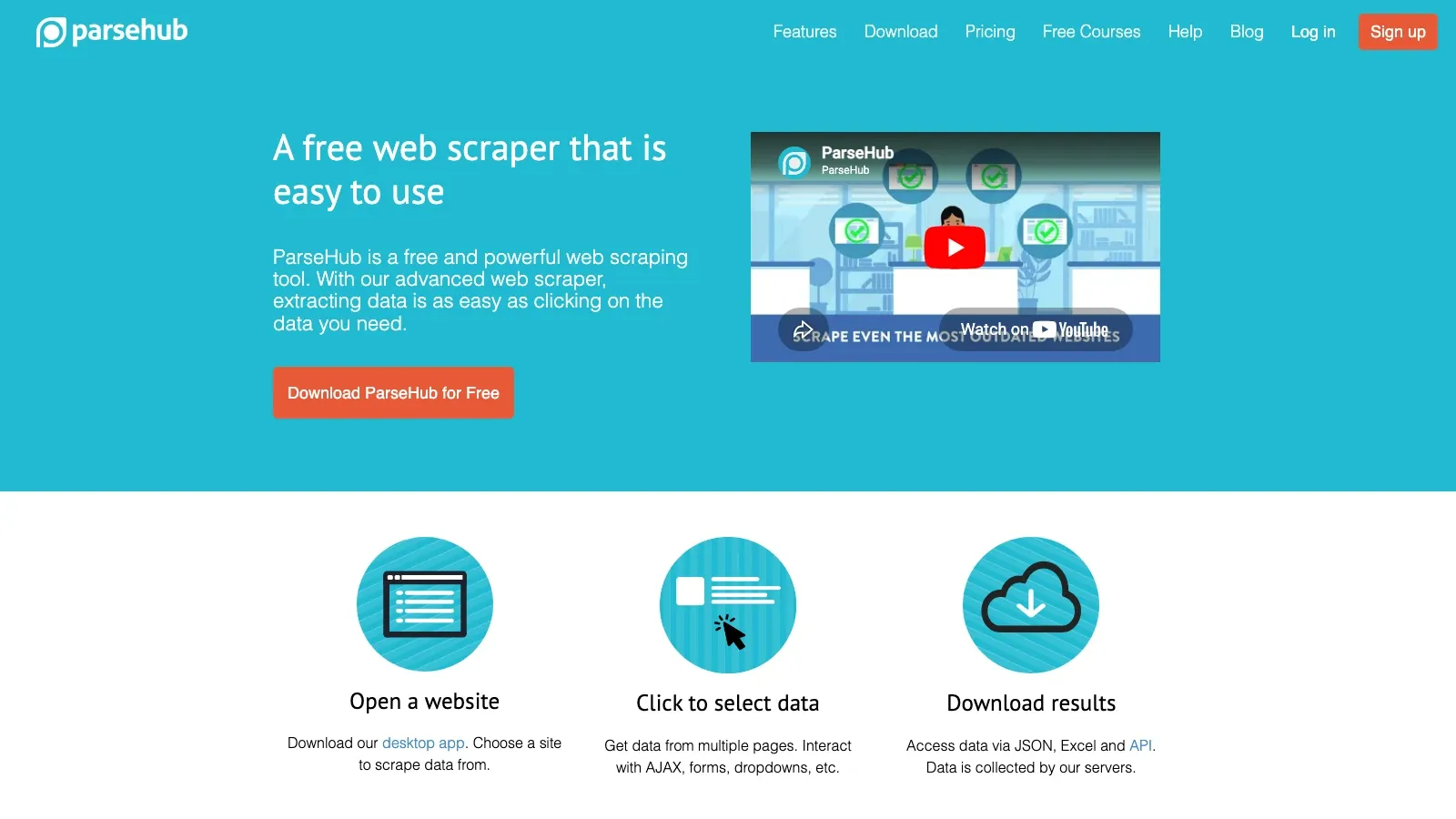
ParseHub är fortfarande relevant eftersom det finns gott om team som vill ha mer steg-för-steg-logik än vad en lätt AI-skrapare erbjuder. Det är inte produktens snyggaste i kategorin, men den är fortfarande flexibel.
- Bäst för: forskare, journalister och tekniska icke-kodare som kan tolerera mer setup.
- Det som gör den unik: starkare villkorlig logik och navigationskontroll än många nybörjarverktyg.
- Att tänka på: långsammare att lära sig och känns mindre modern än nyare alternativ.
- Prissignal: gratis plan, betalda planer från 189 USD/månad.
5. Web Scraper
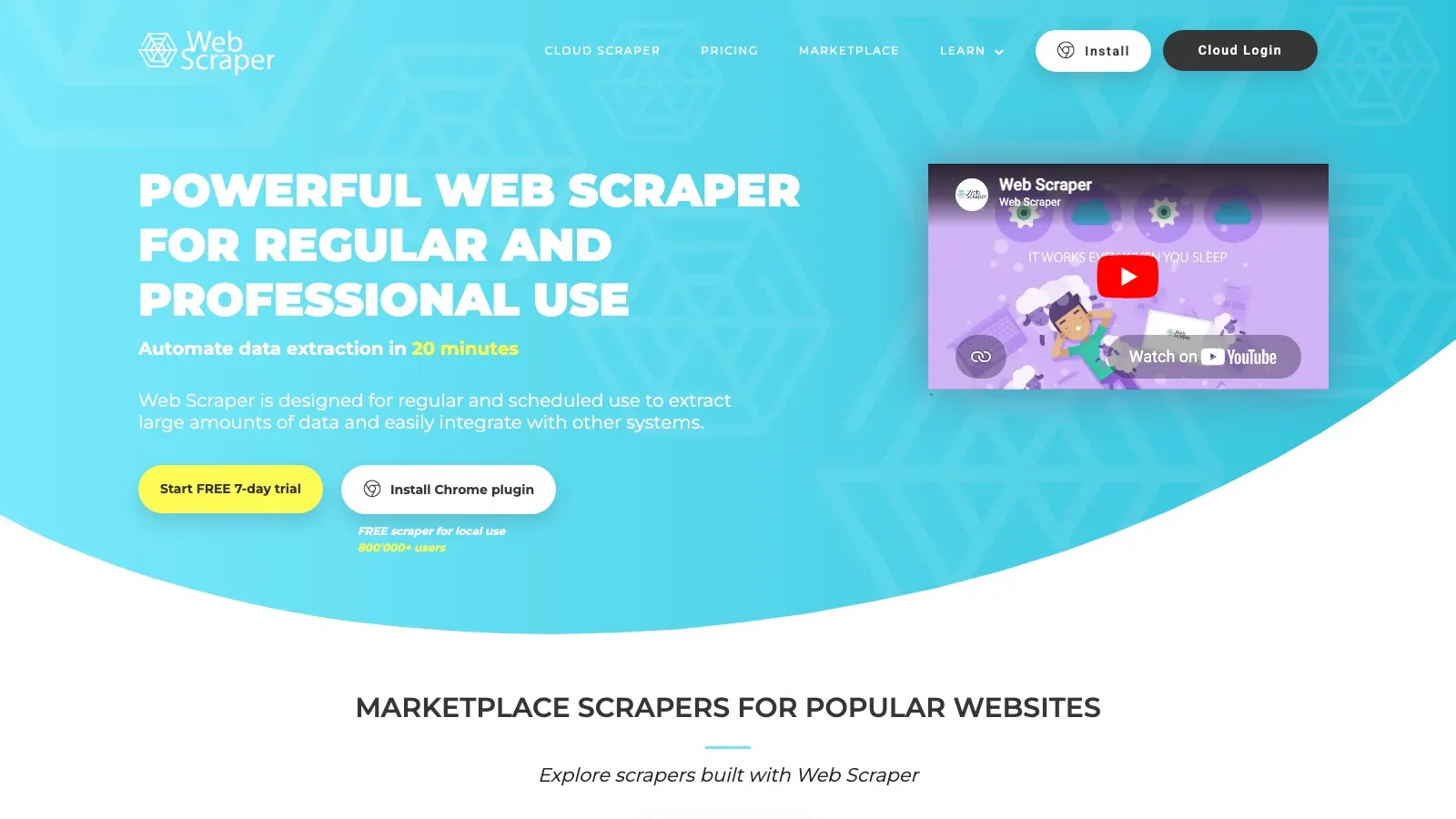
Web Scraper är ett av de tydligare ”lär dig grunderna utan att köpa en plattform”-alternativen. Om du gillar sitemap-modellen är det fortfarande en rimlig startpunkt.
- Bäst för: nybörjare, hobbyprojekt och mindre jobb som styrs via webbläsaren.
- Det som gör den unik: enkel setup och smidig väg från lokal tilläggsmodul till molnplaner.
- Att tänka på: blir begränsande när du behöver mer adaptiv logik eller starkare hantering av blockeringar.
- Prissignal: gratis tillägg, Cloud från 50 USD/månad.
6. Browse AI
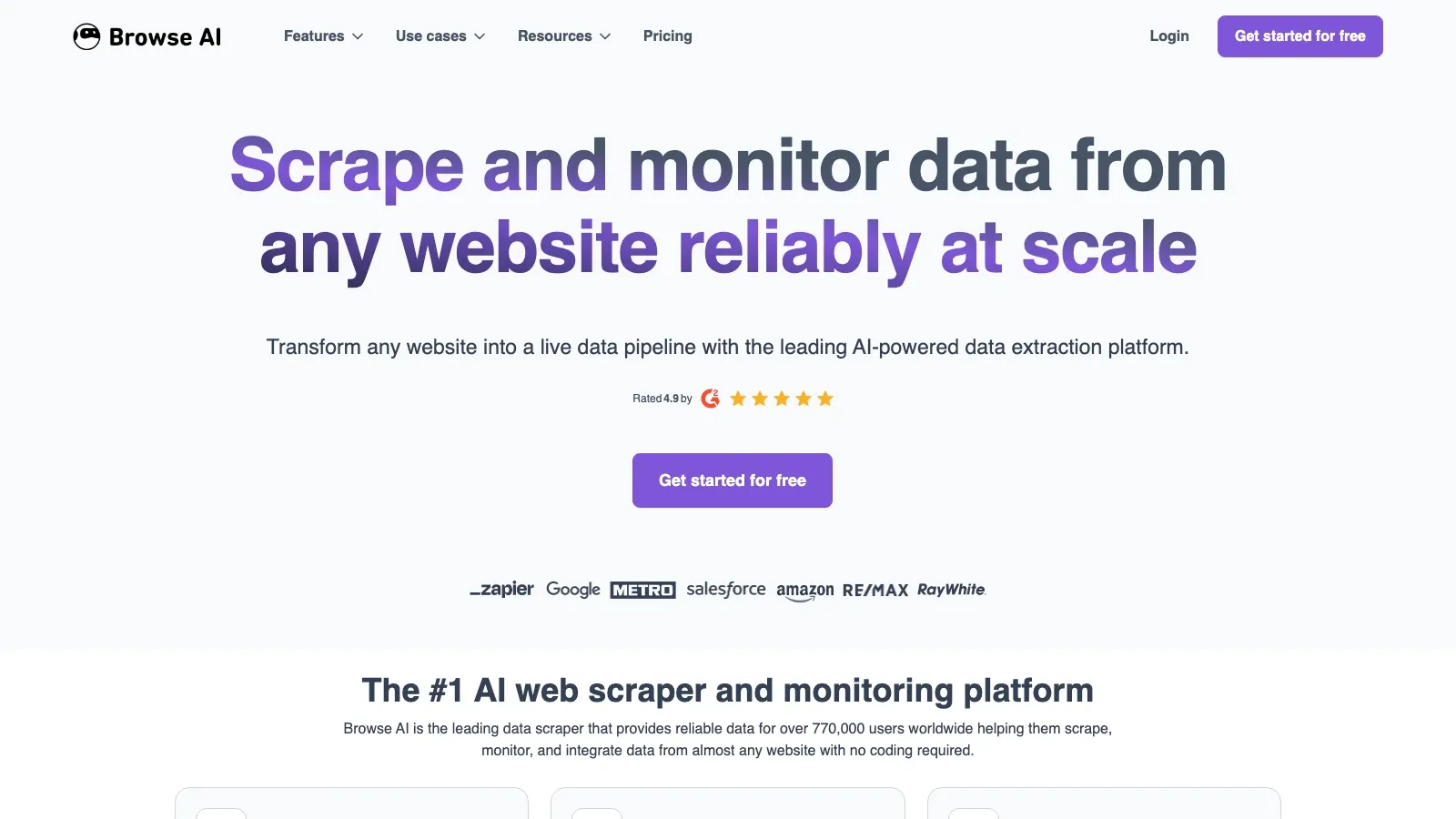
Browse AI är fortfarande ett starkt val när skrapning och övervakning är lika viktiga. Robotmodellen är intuitiv för affärsanvändare som tänker i termer av ”bevaka den här sidan och säg vad som ändrades”.
- Bäst för: konkurrentövervakning, prisbevakning och team som arbetar kalkylarksfokuserat.
- Det som gör den unik: välputsad onboarding, återkommande övervakning och automationsvänliga resultat.
- Att tänka på: komplexa jobb i hög volym kan bli dyra snabbare än API-först-stackar.
- Prissignal: gratis plan, betalda planer, hanterad nivå.
För team som utvärderar sidövervakning snarare än engångsextraktion är den här korta officiella översikten fortfarande en bra signalcheck:
7. Bardeen
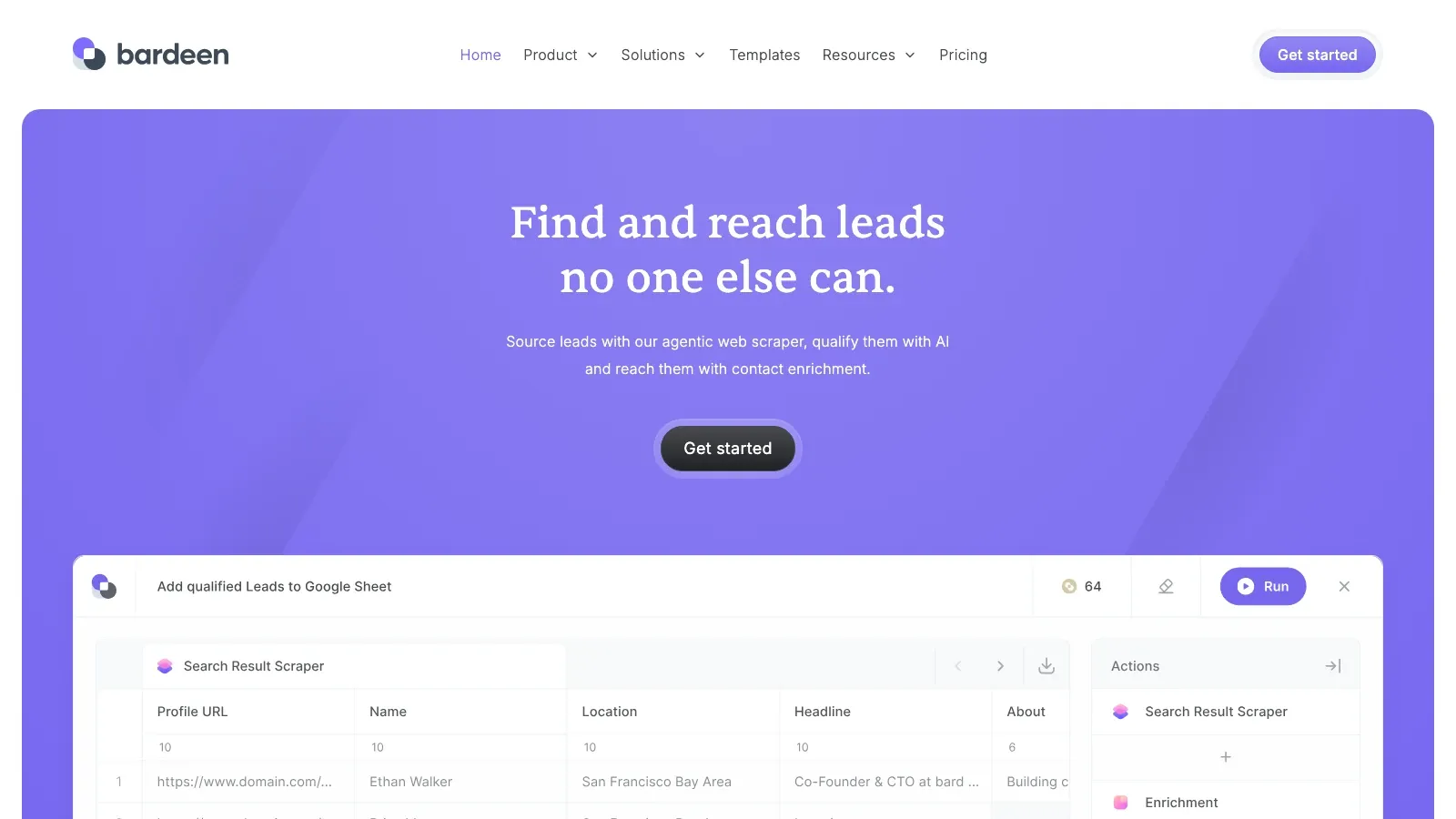
Bardeen handlar mindre om ren skrapdjup och mer om vad som händer efter skrapningen. Den är som starkast när webbutvinning bara är ett steg i ett större webbläsarautomationsflöde.
- Bäst för: GTM-drift, lead-routing, CRM-överlämning och webbläsarnativ automatisering.
- Det som gör den unik: stark berättelse kring arbetsflödesautomatisering runt själva skrapningen.
- Att tänka på: inte det renaste valet när extraktionsprecision är det enda som spelar roll.
- Prissignal: gratis plan, Basic från 10 USD/månad, Premium- och Enterprise-nivåer.
8. ScrapeStorm
ScrapeStorm fyller fortfarande ett användbart mellanläge för användare som vill ha AI-stöd men samtidigt förväntar sig en mer traditionell visuell skrapmiljö.
- Bäst för: katalogskrapning, insamling av e-handelssidor och visuellt konfigurerade återkommande jobb.
- Det som gör den unik: enklare att komma igång med än många äldre visuella verktyg.
- Att tänka på: mindre putsad än kategoriledarna och kan kännas smalare på svårare webbplatser.
- Prissignal: gratis provperiod, betalda planer, företagspriser.

Bästa skrapnings-API:er när skala och anti-bot-hantering spelar roll
Det här är kategorin du ska gå in i när den verkliga begränsningen inte längre är ”hur väljer jag data?” utan blir ”hur håller jag detta stabilt under belastning?”
9. ScraperAPI
ScraperAPI är fortfarande en av de mest lättillgängliga API-först-produkterna för utvecklare som vill sluta tänka på proxies och svarsfrekvens på förfrågningar.
- Bäst för: utvecklare som snabbt behöver skala från prototyp till produktion.
- Det som gör den unik: enkelt API plus stöd för proxy, CAPTCHA och rendering.
- Att tänka på: du äger fortfarande parsing, omförsök och nedströms datakvalitet.
- Prissignal: 7-dagars provperiod, betalt från 49 USD/månad.
10. Bright Data Web Scraper
Bright Data är tungviktsvalet när förmåga att kringgå blockeringar, proxyinventarier, compliance-nivå och hanterade alternativ är viktigare än enkelhet.
- Bäst för: insamling i enterprise-skala och compliance-känsliga program.
- Det som gör den unik: den bredaste stacken i jämförelsen, från proxies till hanterade insamlingsprodukter.
- Att tänka på: lätt att köpa mer än du behöver om teamets arbetsflöde fortfarande är ganska enkelt.
- Prissignal: produktbaserad och användningsbaserad prissättning.
11. Zyte
Zyte är fortfarande ett seriöst alternativ för utvecklarteam som vill ha webbläsaråtgärder, JS-rendering, roterande IP-adresser och anti-bot-hantering under en och samma plattformsberättelse.
- Bäst för: ingenjörsledda skrapningsprogram och återkommande extraktionssystem.
- Det som gör den unik: stark anti-detekteringsstack och API-först-arbetsflöden.
- Att tänka på: bättre för team med tekniskt ägarskap än för affärsanvändare.
- Prissignal: 5 USD i gratis provkredit, användningsbaserade planer.
12. ZenRows
ZenRows är en av de renare utvecklarupplevelserna i API-kategorin om du vill ha anti-bot-hantering utan en enterprise-liknande inköpsprocess.
- Bäst för: startups, utvecklare och slimmade interna verktygsteam.
- Det som gör den unik: relativt låg friktion vid införande och stark positionering kring anti-bot.
- Att tänka på: fortfarande en API-produkt, så du ansvarar för applikationslogik och QA-börda.
- Prissignal: gratis provperiod, Developer från 69 USD/månad.
13. ScrapingBee
ScrapingBee passar när ditt verkliga behov är en renderad sida och mindre infrastrukturarbete, särskilt för JS-tunga webbplatser.
- Bäst för: utvecklare som skrapar dynamiska webbplatser och vill avlasta rendering.
- Det som gör den unik: enkelt API kring headless browsing och proxies.
- Att tänka på: det tar bort infrastrukturarbete, inte behovet av bra skraplogik.
- Prissignal: gratis provperiod, betalt från 49 USD/månad.
Bästa Python-bibliotek för webbskrapning för anpassade stackar
Den här gruppen är fortfarande rätt svar när kontroll betyder mer än bekvämlighet och teamet är redo att äga underhållet.
14. Selenium
Selenium är inte det nyaste webbläsarverktyget, men det är fortfarande relevant där precision i användarinteraktion är viktigare än ren skrapkapacitet.
- Bäst för: interaktionsintensiva flöden, överlapp med QA och webbplatser där webbläsarbeteende är den centrala utmaningen.
- Det som gör den unik: mogen ekosystem och brett webbläsarstöd.
- Att tänka på: tyngre och långsammare än nyare automationsstackar för många skrapjobb.
- Prissignal: gratis och öppen källkod.
15. Beautiful Soup

Beautiful Soup är fortfarande den enklaste parsern i Python-stacken för skrapning. Det är inte en komplett skrapplattform, men det är fortfarande det enklaste sättet att göra om rörig HTML till användbar struktur.
- Bäst för: lätta Python-jobb, statiska HTML-sidor och snabba prototyper.
- Det som gör den unik: låg kognitiv belastning och förlåtande parsing.
- Att tänka på: kombinera den med
requests, ett webblager eller en crawler; på egen hand parsar den bara. - Prissignal: gratis och öppen källkod.
16. Playwright
Playwright är min standardrekommendation för moderna utvecklarteam som behöver robust webbläsarautomatisering på dagens web.
- Bäst för: JavaScript-tunga webbplatser, modern webbläsarautomatisering och team som redan är bekväma med att skriva kod.
- Det som gör den unik: stark väntelogik, stöd för flera webbläsare och rena API:er.
- Att tänka på: du äger fortfarande samtidighet, väljare, webbläsarinfrastruktur och datavalidering.
- Prissignal: gratis och öppen källkod.
17. urllib3
urllib3 hör hemma på listan eftersom vissa team vill ha direkt kontroll över transportbeteendet snarare än en högre abstraktion. Det är inte en nybörjarvänlig skrapare, men det är ett användbart grundbibliotek när du bygger din egen stack.
- Bäst för: utvecklare som vill ha tät kontroll över omförsök, proxies, sessioner och HTTP-beteende.
- Det som gör den unik: lättviktig, pålitlig och mycket använd som infrastruktur.
- Att tänka på: du bygger i stort sett hela stacken själv.
- Prissignal: gratis och öppen källkod.
Gratis verktyg för webbskrapning som är värda att testa först
Om du vill testa innan du köper är de bästa gratisstartpunkterna i den här listan Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright och urllib3. Den gratis upplevelsen räcker gott för att lära dig vilken typ av skrapare du faktiskt behöver, vilket oftast är viktigare än att på dag ett fastna i en perfekt funktionschecklista.
Min kortlista efter teamtyp

- Försäljning, drift och e-handelsteam: börja med Thunderbit och jämför sedan Browse AI om övervakning är viktigare än berikning via undersidor.
- Analytiker och återkommande manuella användare: Octoparse först, sedan ParseHub om du behöver mer anpassad uppgiftslogik.
- GTM-automatiseringsteam: Bardeen om skrapningen behöver flöda direkt in i CRM, Sheets eller webbläsarflöden.
- Utvecklarteam som bygger interna verktyg: ScraperAPI, ZenRows, Zyte eller Playwright beroende på hur mycket av stacken du vill äga.
- Enterprise-dataprogram: Bright Data och Zyte är de mer seriösa infrastruktursamtalen här, med Kadoa som ett AI-ledt alternativ när minskat underhåll är huvudmålet.
När du ska gå längre ner i stacken
Använd den här uppgraderingsvägen:
- Stanna med ai-webbskrapare tills du når gränser för återupprepbarhet eller specialfall.
- Gå till no-code-byggare när schemaläggning, sidnumrering och molnkörning är viktigare än enkelhet i ett klick.
- Gå till API:er när blockeringstakt, rendering och samtidighet blir flaskhalsen.
- Gå till Python-bibliotek när leverantörens abstraktion kostar mer än att äga hela systemet själv.
De flesta team gör detta i fel ordning. De bygger för stort först och inser först senare att ett lättare verktyg hade kunnat lösa det verkliga arbetsflödet.
Slutligt omdöme
Det bästa verktyget för webbskrapning 2026 är inte det med längst funktionslista. Det är det som får korrekt data in i nästa arbetsflöde med minst underhållsarbete för ditt team. Därför fortsätter AI-först-verktyg att vinna för operativa användare, no-code-verktyg förblir värdefulla för återkommande webbläsarjobb, API:er dominerar när skala och blockering spelar roll, och Python-bibliotek äger fortfarande den del av stacken där maximal kontroll krävs.
Om målet är att få fram användbar data den här veckan, börja enkelt. Om din arbetsbelastning redan visar att blockeringstakt, webbläsarrendering och teknisk kontroll är det verkliga problemet, gå längre ner i stacken medvetet i stället för av vana.
Börja med den enklaste skraparen som faktiskt kan göra jobbet Get Started Free
Vanliga frågor
1. Vilket är det bästa verktyget för webbskrapning för icke-tekniska användare 2026?
För de flesta icke-tekniska team är AI-först-verktyg som Thunderbit och Browse AI fortfarande snabbaste vägen eftersom de minskar setup-tid, behovet av väljare och underhållsarbete.
2. Vad ska jag välja för webbplatser med mycket JavaScript eller anti-bot-skydd?
Det är oftast där ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright eller Selenium börjar bli mer rimliga än webbläsartillägg.
3. Är no-code-verktyg för skrapning fortfarande relevanta nu när AI-skrapare blivit bättre?
Ja. Octoparse, ParseHub, Web Scraper och Browse AI är fortfarande viktiga när du behöver tydligare uppgiftskontroll, återkommande körningar eller felsökning som syns i webbläsaren.
4. Vilka verktyg passar bäst för utvecklarteam?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup och urllib3 är de mest naturliga valen när utvecklingsteamet äger arbetsflödet.
Relaterad läsning




