

Om du utvärderar web scraping-verktyg 2026 letar du oftast inte efter en filosofilektion. Du vill ha en kortlista du kan lita på, ett snabbt sätt att skilja verktyg för affärsanvändare från tekniktyngda stackar och tillräckligt med konkreta bevis för att slippa köpa fel sak. Det är vad den här sidan är till för.
Jag är Shuai Guan, medgrundare och vd för Thunderbit. Jag arbetar med AI-driven scraping och webbläsarautomatisering varje dag, så jag bryr mig mindre om generiska topplistor och mer om passform: vilka verktyg hjälper ett sälj- eller driftsteam att komma vidare redan den här veckan, vilka hör hemma i ett utvecklarflöde och vilka som först blir riktigt meningsfulla när skala och anti-bot-infrastruktur är det stora problemet.
Det korta svaret
Om du bara behöver riktningen, använd det här:
- Välj en AI-webbskrapare om du vill gå snabbast från webbplats till kalkylark med minimal konfiguration.
- Välj en no-code-skrapare om du behöver mer kontroll över uppgifter, schemaläggning eller molnkörningar utan att skriva kod.
- Välj en API-plattform om ditt team behöver rendering, proxyrotation, anti-bot-hantering eller integration i en intern produkt.
- Välj ett öppen källkod-bibliotek om du vill ha full kontroll och själv kan ta ansvar för underhåll, selectors, infrastruktur och felhantering.
Den här artikeln behåller alla 20 verktyg, men rekommendationslogiken är medvetet enkel: börja med det enklaste verktyget som pålitligt klarar ditt arbetsflöde, och gå längre ned i stacken först när underhåll, blockering eller skala tvingar dig att göra det.
Snabb jämförelsetabell: de bästa web scraping-verktygen 2026
Priser och planmodeller nedan kontrollerades mot officiella produkt- eller prissidor den 7 maj 2026. Där leverantörer använder användningsbaserad debitering eller skräddarsydd företagsprissättning beskriver jag prismodellen i stället för att låtsas att det finns ett universellt tillförlitligt listpris.
| Verktyg | Typ | Bäst för | Varför det kom med på listan 2026 | Prismodell (kontrollerad maj 2026) |
|---|---|---|---|---|
| Thunderbit | AI Web Scraper | Sälj, drift, e-handel, fastigheter | Snabbaste vägen för icke-kodare; AI-förslag på fält, undersidor, export, webbläsar- och molnarbetsflöde | Gratisnivå, betalda planer, anpassad företagsprissättning |
| Browse AI | AI Web Scraper | Affärsanvändare som övervakar webbplatser | Starka no-code-robotar, övervakning och utdata i kalkylark/API-stil | Gratisplan, betalda planer, premiumstyrd nivå |
| Bardeen | AI-automatisering + scraping | Revenue operations och webbläsarflöden | Bäst när scraping bara är ett steg i ett större automationsflöde | Gratisplan och betalda planer |
| Diffbot | AI-extraktionsplattform | Företag och datateam | Starkast när du vill ha AI-extraktion plus strukturerade datainflöden i stor skala | Företagslik prissättning |
| Instant Data Scraper | Lättviktig webbläsarskrapare | Tillfälliga användare och snabba tabelluttag | Fortfarande ett av de enklaste sätten att snabbt få ut en synlig lista eller tabell till CSV | Gratis |
| Octoparse | No-code-skrapare | Analytiker och driftteam med större återkommande jobb | Mogen visuell byggare med molnextraktion, anti-blockering och mallar | Gratisplan, betalt från $69/månad, anpassat för företag |
| ParseHub | Low-code-skrapare | Analytiker som behöver logik och kontroll i skrivbordsmiljö | Flexibel projektlogik och nästlad navigering, med brantare inlärningskurva än nyare AI-först-verktyg | Gratisplan och betalda planer |
| Web Scraper | No-code-skrapare | Nybörjare och lättare molnjobb | Bra ingång om du gillar sitemap-baserad scraping och webbläsarförst-upplägg | Gratis tillägg, betalda molnplaner |
| Data Miner | Webbläsarskrapare | Forskare och tillväxtansvariga | Fortfarande användbar för snabb extraktion baserad på recept direkt i webbläsaren | Gratisplan och betalda planer |
| Apify | API- och Actor-plattform | Tekniska team och hybrida operatörer | Utmärkt ekosystem av Actors plus egen körmiljö när du vuxit ur webbläsartillägg | Gratisplan, start från $29/månad plus användning, större betalda nivåer |
| ScrapingBee | Scraping API | Utvecklare som skrapar JS-tunga sajter | Bra val när du vill ha rendering och proxyhantering utan att bygga webbläsarlagret själv | Gratis provperiod och betalda planer |
| ScraperAPI | Scraping API | Utvecklare som snabbt skalar förfrågningar | Enkelt API, provkrediter, strukturerade produkter och enklare avlastning av infrastruktur | 7 dagars provperiod med 5 000 krediter, betalt från $49/månad |
| Bright Data | Företags-API + proxyplattform | Högvolymprogram med höga compliance-krav | Mest omfattande datainsamlingsstacken när unblock, proxy och hanterad insamling väger tyngre än enkelhet | Användningsbaserad och produktbaserad prissättning |
| Oxylabs | Företags-API + proxyplattform | Team som köper scraping som infrastruktur | Stark för insamling i stor skala, särskilt pris-, SEO- och marknadsundersökningar | Web Scraper API från $49/månad; bredare proxypriser varierar |
| Zyte | API + anti-bot-stack | Utvecklar- och datateam | Bra val om du vill ha API-först-extraktion med starka byggstenar för webbläsare, rotation och anti-detektion | Provperiod med $5 i gratis kredit, användningsbaserade åtaganden |
| Selenium | Öppen källkod för webbläsarautomatisering | QA-lik automatisering och svåra interaktionsflöden | Fortfarande användbart när trohet i användarinteraktion är viktigare än skrapningsgenomströmning | Gratis och öppen källkod |
| BeautifulSoup4 | Öppen källkod-parser | Nybörjare och lätt parsing | Bäst som parser i en enkel stack, inte som en fullständig scrapingplattform | Gratis och öppen källkod |
| Scrapy | Ramverk för crawling med öppen källkod | Produktionsklara egna crawlers | Bästa balansen mellan kraft och mognad om du vill äga pipelinen själv | Gratis och öppen källkod |
| Puppeteer | Öppen källkod för webbläsarautomatisering | Node-först-scraping och webbläsarskript | Perfekt om teamet redan är bekvämt i Chrome/Node-ekosystemet | Gratis och öppen källkod |
| Playwright | Öppen källkod för webbläsarautomatisering | Modern automatisering i flera webbläsare | Ofta det mest eleganta valet för modern webbläsarautomatisering med stark utvecklarergonomi | Gratis och öppen källkod |
Så här utvärderade jag verktygen
Jag använde fyra filter:
- Tid till första lyckade scraping
Om en icke-teknisk användare inte snabbt kan få fram användbar data spelar det stor roll. - Underhållsbehov
Snabb konfiguration betyder inget om arbetsflödet går sönder varje gång en webbplats ändras. - Skalbarhetstak
Vissa verktyg är perfekta för 50 sidor i veckan och usla för 5 miljoner förfrågningar i månaden. - Passform för arbetsflödet
Det bästa verktyget för ett revenue ops-team är sällan det bästa för ett dataplattformsteam.
Resultatet är ingen universell ranking. Det är en beslutssida för att först välja rätt typ av verktyg och sedan rätt produkt inom den typen.
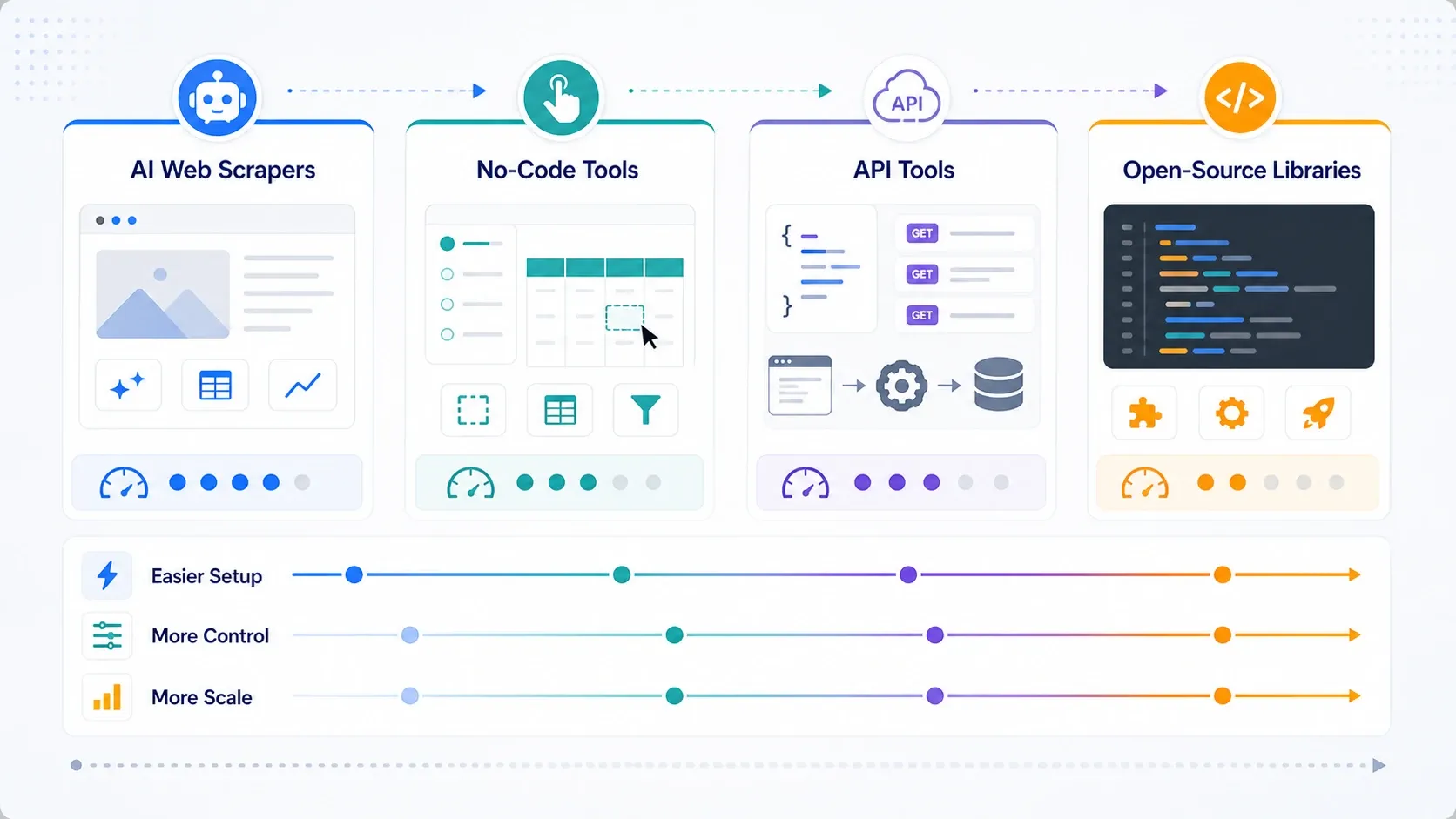
Vilken typ av web scraping-verktyg behöver du egentligen?
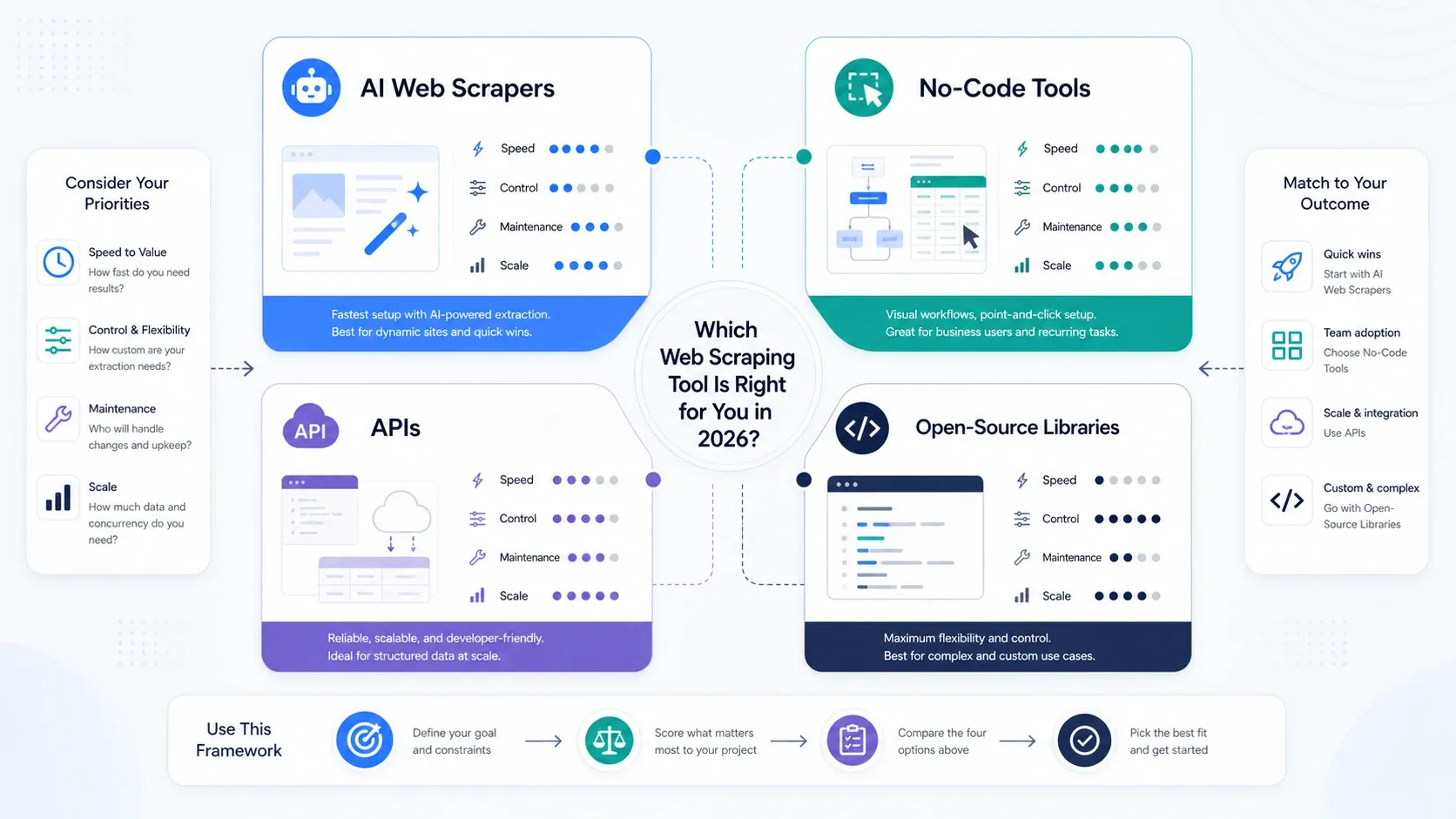
- Välj AI-webbskrapare om ditt främsta mål är operativ hastighet.
- Välj no-code-verktyg om du behöver mer paginering, schemaläggning och upprepningsbar kontroll över uppgifter.
- Välj API:er och scrapingplattformar om rendering, rotation och förmåga att kringgå blockering nu är flaskhalsen.
- Välj bibliotek med öppen källkod om ditt team värderar kontroll högre än bekvämlighet och kan stödja stacken internt.
Om ditt team fortfarande försöker avgöra om scraping ska ligga hos drift eller utveckling, börja med ett AI- eller no-code-verktyg först. Du lär dig snabbare vad som faktiskt spelar roll genom att köra riktiga jobb än genom att överdesigna stacken i förväg.
Bästa AI-webbskraparna för affärsteam
Det här är verktygen jag skulle titta på först om målet är data redo för kalkylark med så lite konfiguration som möjligt.
1. Thunderbit
Thunderbit är det enklaste alternativet här om ditt team vill extrahera strukturerad data utan att lära sig selectors, webbläsarskript eller scrapinginfrastruktur. Arbetsflödet bygger på AI-förslag på fält, berikning av undersidor och direkt export till de verktyg affärsanvändare redan lever i.
- Bäst för: sälj, drift, e-handel, fastigheter och andra webbläsartunga team.
- Varför det sticker ut: det kapar konfigurationstid bättre än allt annat på den här listan för icke-kodare.
- Att tänka på: om du behöver djup, anpassad crawlerlogik eller mycket specialiserad teknisk kontroll kommer du så småningom att gå längre ned i stacken.
- Prismodell: gratisnivå, betalda självbetjäningsplaner och företagsprissättning.
Prova Thunderbit på en live-sida
2. Browse AI
Browse AI är fortfarande ett starkt val för affärsanvändare som vill ha klick-för-klick-konfiguration och återkommande övervakning. Robotmodellen är särskilt användbar när scraping och förändringsdetektering är lika viktiga.
- Bäst för: övervakning av prissidor, konkurrenters sidor och upprepningsbar listextraktion.
- Varför det sticker ut: välpolerad onboarding, färdiga robotar och en tydlig väg från webbplats till kalkylark eller API-lik utdata.
- Att tänka på: komplexa jobb med hög volym kan bli dyra eller operativt klumpiga snabbare än API-först-stackar.
- Prismodell: gratisplan, betalda planer, premium/hanterad nivå.
3. Bardeen
Bardeen är mest intressant när scraping bara är ett steg i ett bredare flöde för webbläsarautomatisering. Om du flyttar data till CRM-system, kalkylark eller outbound-flöden spelar dess automationsvinkel större roll än ren extraktionsdjup.
- Bäst för: revenue ops, lead-flöden och webbläsarnativ uppgiftsautomatisering.
- Varför det sticker ut: starkare berättelse kring arbetsflödesautomatisering än rena extraktionsverktyg.
- Att tänka på: det är inte det smidigaste valet när själva scrapingdelen är komplex och affärskritisk.
- Prismodell: gratisplan och betalda planer.
4. Diffbot
Diffbot finns här för team som behöver AI-extraktion i företagskala, inte för användare som vill ha den billigaste eller enklaste vägen. Det blir mest meningsfullt när kvalitet på strukturerad data och storskalig inmatning är viktigare än praktisk kontroll.
- Bäst för: företagsdatateam, innehållsintelligens och stora extraktionsprogram.
- Varför det sticker ut: extraktion med en datorseende-liknande känsla och stark orientering mot strukturerad utdata.
- Att tänka på: överdrivet för små team och friktionsrikt om användningsfallet är lättviktigt.
- Prismodell: företagsanpassade planer och skräddarsydd försäljning.
5. Instant Data Scraper
Instant Data Scraper förtjänar fortfarande en plats eftersom det finns gott om situationer där du bara behöver den synliga tabellen, katalogen eller listan direkt. Det är ingen plattform, men ofta tillräckligt.
- Bäst för: engångsextraktion, snabba leadlistor, enkla kataloger och synliga tabeller.
- Varför det sticker ut: nästan ingen friktion på rätt sidor.
- Att tänka på: begränsad automatisering, begränsat djup och svag passform för avancerade flöden.
- Prismodell: gratis.
Bästa no-code-verktyg för återkommande scrapingjobb
När jobbet är mer än en tillfällig scraping blir visuella byggare och molnkörning viktiga.
6. Octoparse
Octoparse är fortfarande en av de starkaste no-code-plattformarna om du behöver molnkörningar, malltäckning och mer sofistikerad uppgiftshantering än vad ett webbläsartillägg kan erbjuda.
- Bäst för: analytiker, pris-team och operatörer som kör återkommande insamlingsjobb.
- Varför det sticker ut: mogen uppgiftsbyggare, molnextraktion, anti-blockeringsfunktioner och ett stort mallekosystem.
- Att tänka på: det är kraftfullare än AI-först-webbverktyg, men det innebär också mer konfigurationsarbete.
- Prismodell: gratisplan, betalt från $69/månad, anpassat för företag.
7. ParseHub
ParseHub är fortfarande relevant för användare som vill ha mer kontroll än en AI-skrapare men inte vill bygga en kodbas. Det belönar tålamod, inte hastighet.
- Bäst för: analytiker och tekniskt nyfikna operatörer som kan acceptera en brantare inlärningskurva.
- Varför det sticker ut: flexibel navigationslogik och bättre kontroll än lätta webbläsarverktyg.
- Att tänka på: produktupplevelsen känns tyngre än nyare aktörer, särskilt för snabbrörliga affärsteam.
- Prismodell: gratisplan och betalda planer.
8. Web Scraper
Web Scraper är fortfarande en rimlig ingång om du gillar sitemap-modellen och vill ha något som börjar i webbläsaren och sedan kan växa till molnschemaläggning längre fram.
- Bäst för: nybörjare, hobbyprojekt och mindre återkommande jobb.
- Varför det sticker ut: lättillgängligt sitemap-flöde och enkel webbläsarförst-användning.
- Att tänka på: blir begränsande när du behöver mer anpassningsbar extraktionslogik.
- Prismodell: gratis webbläsartillägg och betalda molnplaner.
9. Data Miner
Data Miner är bäst att se som ett snabbt extraktionsverktyg snarare än en komplett scrapingplattform. Det förtjänar fortfarande en plats eftersom receptdrivet arbete är användbart för många research- och prospekteringsuppgifter.
- Bäst för: forskare, tillväxtteam och snabba exportjobb direkt i webbläsaren.
- Varför det sticker ut: receptmodell, låg friktion och enkel export från webbläsaren.
- Att tänka på: inte rätt verktyg för seriös scraping i plattformsskala.
- Prismodell: gratisplan och betalda planer.
Bästa API-plattformar när skala och blockering blir det verkliga problemet
Det här är lagret där utvecklingsteam slutar tänka “hur skrapar jag den här sidan?” och börjar tänka “hur gör jag detta pålitligt i volym?”
10. Apify
Apify är den mest flexibla plattformen i den här gruppen om du både vill ha en marknadsplats med återanvändbara scrapers och en plats att köra egen kod. Den bygger en bättre brygga mellan no-code-upptäckt och utvecklarexekvering än de flesta konkurrenter.
- Bäst för: hybrida team, utvecklarstyrd scraping och återanvändbara automationsflöden.
- Varför det sticker ut: Actor-ekosystemet plus egen körmiljö ger ovanlig bredd.
- Att tänka på: när du går över till egen kod är du tillbaka i utvecklarvärlden och enkelhetsfördelen bleknar.
- Prismodell: gratisplan, start från $29/månad plus användning, större användningsnivåer och företag.
11. ScrapingBee
ScrapingBee är ett bra val när ditt verkliga behov är “ge mig en renderad sida och hantera den jobbiga infrastrukturen åt mig”. Det passar JS-tunga mål väl.
- Bäst för: utvecklare som skrapar dynamiska sajter men vill lägga minimalt med tid på infrastruktur.
- Varför det sticker ut: enkelt API för rendering, proxies och webbläsarautomatisering.
- Att tänka på: det är en infrastrukturtjänst, så du ansvarar fortfarande för parsing, retry-logik och datakvalitet nedströms.
- Prismodell: provperiod och betalda planer.
12. ScraperAPI
ScraperAPI är fortfarande ett av de enklaste sätten att avlasta proxyhantering och förbättra träffsäkerheten i förfrågningar när du vill skala snabbt.
- Bäst för: utvecklare som snabbt behöver gå från prototyp till volym.
- Varför det sticker ut: enkelt API, provkrediter, strukturerade produkter och skalningsnivåer.
- Att tänka på: som alla API-först-produkter tar det inte bort behovet av tekniskt omdöme kring parsing och datavalidering.
- Prismodell: 7 dagars provperiod med 5 000 krediter, betalt från $49/månad.
13. Bright Data
Bright Data är tungviktsalternativet när förmåga att kringgå blockering, proxyinventarium och hanterad insamling väger tyngre än enkelhet.
- Bäst för: företagsprogram, stora insamlingar med compliance-krav och hanterad datainsamling.
- Varför det sticker ut: bredden i proxy-, scraper-, browser- och datasetprodukter.
- Att tänka på: dyrt och lätt att köpa mer än du behöver om kärnflödet fortfarande är relativt enkelt.
- Prismodell: användningsbaserad och produktbaserad prissättning över API:er, proxies och hanterade tjänster.
14. Oxylabs
Oxylabs är fortfarande ett starkt val för team som köper scraping som infrastruktur snarare än som ett webbläsarverktyg. Det är särskilt relevant när tillförlitlighet och inköpsmognad spelar roll.
- Bäst för: företagsinsamling, prisövervakning, SEO-övervakning och marknadsundersökningar.
- Varför det sticker ut: robust infrastrukturbeskrivning, djup proxykapacitet och en tydligare företagsköpresa.
- Att tänka på: inte idealiskt om ditt team vill ha ett avslappnat självbetjäningsflöde.
- Prismodell: Web Scraper API från $49/månad; andra produkter varierar per enhet och användning.
15. Zyte
Zyte förtjänar fortfarande seriös uppmärksamhet från utvecklar- och datateam som vill ha anti-detektion, webbläsaråtgärder, JS-rendering och roterande IP:er bakom en enda API-först-berättelse.
- Bäst för: tekniska team som bygger upprepningsbara extraktionssystem.
- Varför det sticker ut: webbläsaråtgärder, JS-rendering, IP-rotation och anti-bot-hållning i en och samma stack.
- Att tänka på: bättre för team med eget tekniskt ägarskap än för icke-tekniska operatörer.
- Prismodell: provperiod med $5 i gratis kredit och månatliga åtaganden baserade på användning.
Testa ett enklare arbetsflöde innan du överbygger
Bästa bibliotek med öppen källkod för utvecklare som vill ha full kontroll
Om du vill äga hela scrapingstacken från början till slut är de här de mest användbara byggstenarna 2026.
16. Selenium
Selenium är fortfarande användbart när du behöver interaktionsnoggrannhet i QA-stil, äldre arbetsflöden för webbläsarautomatisering eller mycket tydlig kontroll över användarflöden.
- Bäst för: interaktionstunga automationer, överlapp med QA och sajter där webbläsarbeteende är viktigare än crawl-genomströmning.
- Varför det sticker ut: moget ekosystem och brett webbläsarstöd.
- Att tänka på: tyngre och långsammare än nyare webbläsarverktyg för många scrapingjobb.
- Prismodell: gratis och öppen källkod.
17. BeautifulSoup4

BeautifulSoup är ingen fullständig scrapingplattform, men det är fortfarande ett av de enklaste sätten att parsa rörig HTML i lätta arbetsflöden.
- Bäst för: nybörjare, snabba skript och parser-först-uppgifter.
- Varför det sticker ut: enkelt API och låg kognitiv belastning.
- Att tänka på: kombinera det med request-, webbläsar- eller crawlerverktyg; ensamt är det bara en parser.
- Prismodell: gratis och öppen källkod.
18. Scrapy
Scrapy är fortfarande det bästa svaret när du behöver ett riktigt crawler-ramverk i stället för ett gäng skript.
- Bäst för: produktionsklara egna crawlers och internt ägda datapipelines.
- Varför det sticker ut: hög prestanda, pipelines, middleware och långsiktig utbyggbarhet.
- Att tänka på: det finns ett verkligt utvecklingspåslag, och JS-tunga mål kräver ofta kompletterande verktyg.
- Prismodell: gratis och öppen källkod.
19. Puppeteer
Puppeteer är fortfarande ett starkt val för Node-först-team som vill ha direkt kontroll över Chromium och webbläsarskript.
- Bäst för: Node-baserad scraping, skärmdumpar och webbläsarautomatisering.
- Varför det sticker ut: direkt och kraftfull kontroll över Chromium-beteende.
- Att tänka på: snävare webbläsarbild än Playwright och fortfarande resurskrävande i stor skala.
- Prismodell: gratis och öppen källkod.
20. Playwright
Playwright är mitt förstahandsval för modern webbläsarautomatisering om ditt team skriver kod och vill ha en nyare abstraktion än Selenium.
- Bäst för: modern webbläsarautomatisering, JS-tunga sajter och team som bryr sig om utvecklarergonomi.
- Varför det sticker ut: stark modell för flera webbläsare, pålitligt väntbeteende och rena API:er.
- Att tänka på: du ansvarar fortfarande för webbläsarinfrastruktur, samtidighet, förändrade selectors och datavalidering.
- Prismodell: gratis och öppen källkod.
Min shortlist efter teamtyp
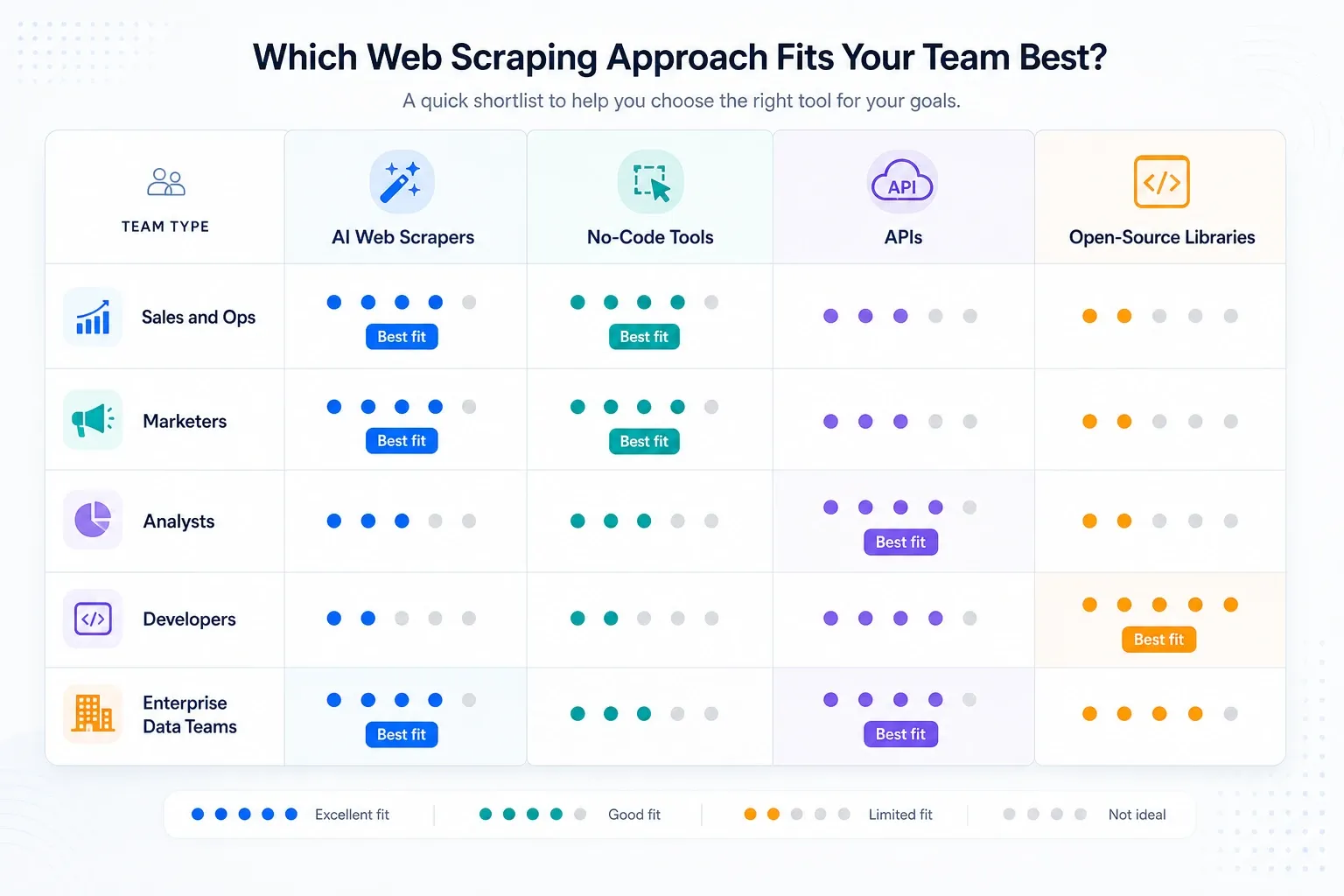
- Sälj- och driftteam: börja med Thunderbit och titta sedan på Browse AI om övervakning är viktigare än berikning av undersidor.
- Analytiker och researchteam: Octoparse först om återkommande jobb är större än vad webbläsartillägg bekvämt kan hantera.
- GTM-team med mycket automatisering: Bardeen om scraping bara är ett steg i ett större arbetsflöde.
- Utvecklingsteam som bygger interna verktyg: Apify, Zyte, ScraperAPI eller Playwright beroende på hur mycket ägarskap över stacken du vill ha.
- Företagsprogram för data: Bright Data, Oxylabs, Diffbot och Zyte är de seriösa infrastruktursamtalen.
När du ska gå längre ned i stacken
Använd den här regeln:
- Stanna kvar med AI-verktyg tills du stöter på begränsningar i upprepningsbarhet eller specialfall.
- Gå över till no-code-verktyg när schemaläggning, paginering, anti-blockering eller molnkörningar blir viktigare än enkelheten med ett klick.
- Gå över till API:er när lyckandefrekvens för unblock, JS-rendering och samtidighet blir de verkliga flaskhalsarna.
- Gå över till bibliotek med öppen källkod när kostnaden för leverantörsabstraktion blir högre än kostnaden för att äga hela stacken.
De flesta team går längre ned i stacken för tidigt. Det är ett av de vanligaste misstag jag ser.
Slutlig slutsats
För de flesta icke-tekniska team är rätt svar 2026 inte “den mest kraftfulla skraparen”. Det är verktyget som får in korrekt data i nästa arbetsflöde med minst underhåll. Därför fortsätter AI-först-verktyg att vinna för operativa användare, medan API:er och öppen källkod-stackar fortfarande passar bättre för tekniska team med tydliga skalningskrav.
Om du vill ha den kortaste vägen från sida till strukturerad utdata, börja med Thunderbit. Om du redan vet att ditt jobb kräver tung infrastruktur, hoppa direkt till API- och utvecklarnivåerna. Bara blanda inte ihop komplexitet med sofistikering.
Börja med det enklaste verktyget som faktiskt kan göra jobbet Get Started Free
Vanliga frågor
1. Vad är det bästa web scraping-verktyget för icke-tekniska användare 2026?
För de flesta icke-tekniska användare erbjuder AI-först-verktyg som Thunderbit och Browse AI den snabbaste vägen till användbar data eftersom de minskar arbetet med selectors, minskar konfigurationsfriktion och sänker underhållsbehovet.
2. Vad ska jag välja om mina webbplatser är JavaScript-tunga eller blockerar förfrågningar aggressivt?
Rör dig mot ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright eller Selenium beroende på om du vill ha en hanterad tjänst eller direkt teknisk kontroll.
3. Är no-code-verktyg fortfarande relevanta nu när AI-webbskrapare är bättre?
Ja. No-code-verktyg som Octoparse och ParseHub spelar fortfarande roll när du behöver mer explicit kontroll över uppgiftslogik, molnkörning och hantering av återkommande jobb.
4. Vilka verktyg är mest logiska för utvecklingsteam?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer och Selenium är de mest naturliga valen när utvecklare äger arbetsflödet.
5. Hur gör jag en snabb kortlista i stället för att överforska?
Välj först typ av verktyg, inte leverantör. Avgör om du behöver AI-enkelhet, no-code-kontroll, API-infrastruktur eller ägarskap med öppen källkod. Jämför sedan produkter inom det lagret.
Relaterad läsning




