Efter att ha kört långt över tusen scrapingkörningar med Simplescraper slutade jag räkna lyckade körningar och började i stället katalogisera misslyckanden. Skiftet — från "funkade det?" till "varför gick det sönder den här gången?" — lärde mig mer än någon dokumentationssida någonsin kunde göra.
Simplescraper är ett stabilt Chrome-tillägg för att hämta data från webbplatser utan att skriva kod. Med i Chrome Web Store och ett faktiskt lättanvänt klickgränssnitt har det förtjänat sin plats i verktygslådan för no-code-webbscraping. Men här är det ingen berättar på landningssidan: för att få konsekventa och tillförlitliga resultat i stor skala behöver du förstå var visuella skrapare blir sköra. En att anställda lägger mer än nio timmar i veckan på repetitiv datainmatning — precis den typen av problem som driver människor till verktyg som Simplescraper. Men om du inte känner till verktygets egenheter kommer du att lägga de där nio timmarna på felsökning i stället för på något nyttigt. Den här artikeln går igenom de fem bästa metoder jag har destillerat från verklig driftserfarenhet: felsökning av markeringsproblem, val av rätt skrapningsläge, hur du maxar gratisnivån, hur du undviker blockeringar och när det är dags att gå vidare.

Vad är Simplescraper (och varför spelar bästa praxis roll)?
Simplescraper är ett Chrome-tillägg som låter dig visuellt välja element på en webbsida — produkttitlar, priser, bilder, kontaktuppgifter — och extrahera dem till strukturerad data utan att skriva en rad kod. Du pekar, du klickar, och verktyget bygger ett "recept" som kan återanvändas på liknande sidor.
Grundmodellen fungerar så här:
- Visuellt elementval: Klicka på det du vill ha. Simplescraper identifierar automatiskt återkommande mönster (produktlistor, sökresultat, platsannonser).
- Recept: Spara din extraheringsinställning för att använda den senare eller köra den på batcher av URL:er.
- Två skrapningslägen: Browser (lokalt, körs i din Chrome) och Cloud (körs på Simplescrapers servrar, utan att du behöver övervaka det).
- Integrationer: Exportera till Google Sheets, Airtable, webhooks, Zapier, Make, CSV och JSON.
- AI-extraktion: En nyare som genererar CSS-selectors utifrån en schema-prompt.
Målgruppen är bred — marknadsförare, säljteam, e-handelsansvariga, forskare — alla som behöver hämta strukturerad data från webbplatser utan att anlita en utvecklare. Och på enkla sidor levererar Simplescraper snabbt.
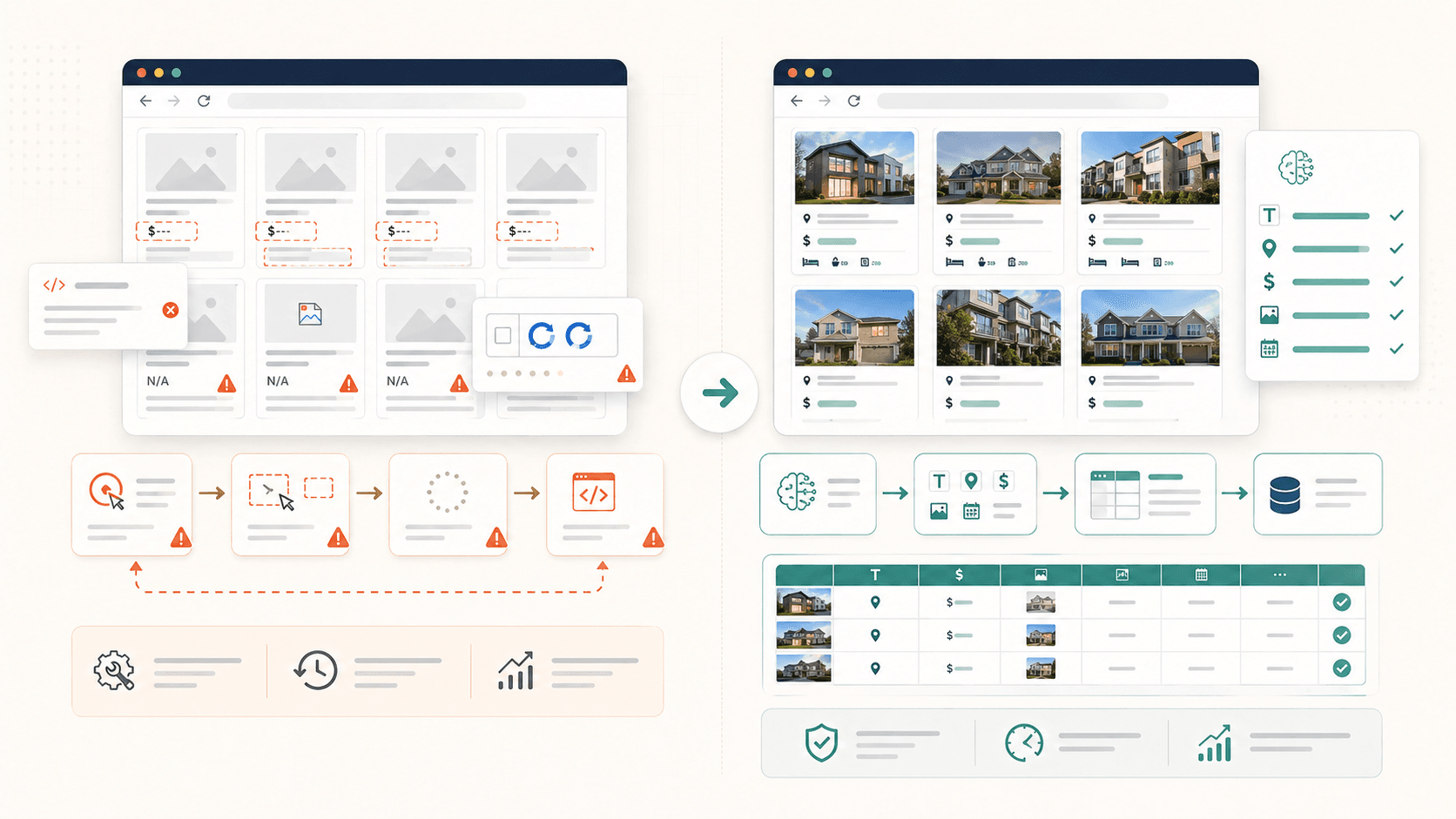
Så varför spelar bästa praxis roll? Därför att i samma ögonblick som du går bortom en enkel produktlista eller en ren katalogsida uppstår friktion. Dynamiskt innehåll, anti-bot-skydd, bilder som laddas lazy, nästlade HTML-strukturer — det här är de verkliga förhållanden som skiljer en frustrerande upplevelse från en produktiv. Om du känner till rätt angreppssätt i förväg sparar du timmar av trial and error.
Bästa praxis 1: Vad du gör när Simplescraper misslyckas med att välja element
Det här är den absolut vanligaste frustrationen jag har sett. Du klickar på ett element, Simplescraper markerar det, du känner dig nöjd — och sedan saknas halva datan i resultatet. Bilderna är tomma. Bion saknas. Platsinformationen försvann.
Själv medgav grundaren tidigt "element/css-selectorn fortfarande inte är 100 %." Den ärliga tonen är uppfriskande, men den löser inte din trasiga scrapingkörning klockan 23 en onsdagskväll.
Vanliga markeringsfel (och varför de uppstår)
Fyra mönster ställer oftast till det för Simplescraper:
- Bilder som laddas lazy: Själva bildelementet förrän du scrollar fram till det. Om du skrapar innan du scrollat får du tomma bildfält.
- Nästlade eller grupperade containrar: Simplescrapers automatiska identifiering , vilket ibland betyder att den bara hämtar ett avsnitt av sidan i stället för hela den upprepade uppsättningen. Användare rapporterar tabeller som "inte vill välja alla rader på en gång".
- Dynamiskt JavaScript-innehåll: Element som renderas efter den första sidladdningen via React, Vue eller AJAX-anrop finns helt enkelt inte där när skraparen går för tidigt.
- Paginering med oändlig scroll: Datan du vill ha har ännu inte laddats in i HTML:en eftersom den kräver scrollning eller ett klick på "ladda mer".
Praktiska felsökningssteg
Innan du går över till manuella selectors, testa detta:
- Scrolla igenom hela sidan först. Det tvingar fram lazy-loaded bilder och innehåll i DOM:en.
- Använd "Include Similar" när antalet träffar ser misstänkt lågt ut. Simplescrapers egen dokumentation rekommenderar detta för grupperat innehåll.
- Vänta tills sidan har renderats helt på JS-tunga webbplatser. Ge det några extra sekunder innan du startar scrapingkörningen.
- Börja med ett litet urval. Bekräfta radantalet på 2–3 sidor innan du kör en batch på 500 sidor.
Växla till manuella CSS-selectors
När det visuella valet fortsätter att fallera är det dags att gå manuellt. Det här är power move:en som skiljer tillfälliga användare från effektiva.
Så här gör du:
- Högerklicka på elementet du vill ha i Chrome → Inspect.
- I DevTools identifierar du elementets klassnamn eller dataattribut (t.ex.
.product-card .priceeller[data-test="location"]). - I Simplescraper växlar du till fliken och klistrar in din selector.
- Testa selectorn genom att köra en liten scrapingkörning.
Tips för robusta selectors:
- Föredra klassnamn (
.listing-title) framför positionsselectors (div:nth-child(3)) - Använd när de finns — de är oftast stabilare mellan uppdateringar av sajten
- Undvik djupt nästlade sökvägar som går sönder när sajtens HTML-struktur ändras
AI-alternativet: låt Thunderbit autoidentifiera fält
Jag ska vara tydlig — mitt team byggde just för att vi tröttnade på det här exakta problemet. Thunderbits "AI Suggest Fields" läser sidans struktur och föreslår kolumner och extraheringslogik automatiskt. Du behöver ingen CSS-kunskap. AI:n anpassar sig till varje sajts layout, inklusive nästlat innehåll och bilder som laddas lazy.
Om du lägger mer än några minuter per scrapingkörning på att felsöka selectors är det värt att prova ett helt annat angreppssätt.
Bästa praxis 2: Välja mellan cloud scraping och browser scraping
De flesta Simplescraper-användare väljer ett läge per rutin — oftast det de testade först — utan att tänka på vilket läge som faktiskt passar användningsfallet. Det leder till onödiga fel.
När du ska använda Browser-scraping (lokal)
- Sidor som kräver inloggning: LinkedIn, CRM-instrumentpaneler, interna verktyg — allt bakom autentisering kräver din aktiva webbläsarsession.
- Snabba engångsjobb: Du är redan på sidan och vill bara ha datan nu.
- Spara gratis krediter: Browser-scraping förbrukar inga cloud-krediter.
Nackdelen: datorn måste vara på, och stora jobb blir långsamma jämfört med cloud.
När du ska använda Cloud scraping
- Publika sidor (e-handelslistor, kataloger, fastighetssajter) där ingen inloggning behövs.
- Schemalagd övervakning: Körs utan övervakning på återkommande basis.
- Batchjobb: i en enda cloud-batch.
- Leverans till integrationer: Automatiska pushar till Google Sheets, Airtable eller webhooks.
Nackdelen: cloud scraping — 2 per sida med JavaScript, 1 per sida utan JS — och äter snabbt upp gratisnivåns 100 krediter.
Beslutsram
| Scenario | Rekommenderat läge | Varför | Risk om du väljer fel |
|---|---|---|---|
| Sidor som kräver inloggning (LinkedIn, instrumentpaneler) | Browser | Kräver din autentiserade session | Cloud-läget fastnar vid inloggningsväggar |
| Publika e-handelsproduktlistor | Cloud | Snabbare, körs utan övervakning | Browser-läget binder upp din dator |
| Schemalagd återkommande övervakning | Cloud | Körs utan att du behöver vara där | Browser kräver att du är närvarande |
| Sajter med tungt anti-bot-skydd (Amazon, Yelp) | Browser (reservval) eller Cloud med proxy | IP-rotering eller återanvändning av session krävs | Cloud utan proxy blockeras snabbt |
| Snabb engångsextraktion | Browser | Omedelbart, ingen kreditkostnad | Överdrivet att sätta upp cloud för en sida |

Så förenklar Thunderbit detta
I är valet bara en enkel växel i samma gränssnitt. Cloud-läget kan processa upp till 50 sidor samtidigt — ingen separat betalnivå för cloud-åtkomst. Browser-läget hanterar sidor som kräver inloggning utan extra konfiguration. Den mentala kostnaden för "vilket läge behöver jag?" sjunker rejält när båda lägena finns i samma arbetsflöde.
Bästa praxis 3: Få ut det mesta av Simplescrapers gratisnivå
Pristrassel är på riktigt. Jag har sett foruminlägg där folk antar att "gratis Chrome-tillägg" betyder "allt är gratis". Det gör det inte. Och åt andra hållet har jag sett folk anta att Simplescraper är dyrt eftersom betalnivåerna inte visas särskilt tydligt. Ingen av de antagandena hjälper.
Vad Simplescrapers gratisplan faktiskt innehåller
Enligt :
- Browser-scraping: Obegränsad (körs lokalt i din Chrome)
- Cloud-krediter: 100 per månad
- Sparade recept: 3
- Exportformat: CSV och JSON
- Det som INTE ingår: Prioriterad support, avancerade proxyalternativ, högre tilldelning av cloud-krediter
Ett realistiskt scenario för gratisnivån
Säg att du behöver skrapa 50 produktsidor från en publik e-handelsplats.
- Browser-läge (gratis): Du kan göra detta helt gratis. Öppna varje sida (eller använd en lista), kör receptet, exportera till CSV. Tidsåtgång: beror på tålamod och internethastighet, men räkna med 15–30 minuters aktivt arbete för 50 sidor med manuell navigation.
- Cloud-läge (gratisnivå): Med JavaScript-rendering aktiverad kostar varje sida 2 krediter. 50 sidor = 100 krediter. Det är hela din månatliga molnkvot i ett enda jobb. Ingen schemaläggning, inga retries om något går fel.
Gratisnivån är verkligen användbar för små, sporadiska scrapingjobb. Men den tar snabbt slut när du behöver molnautomatisering eller skala.
Jämförelse av gratisnivåer: Simplescraper vs. Thunderbit
| Funktion | Simplescraper gratis | Thunderbit gratis |
|---|---|---|
| Sidor/krediter | Obegränsad browser + 100 cloud-krediter | 6 sidor med fulla AI-funktioner |
| AI-driven extraktion | Begränsad (Smart Extract använder krediter) | Full AI Suggest Fields ingår |
| Exportmål | CSV, JSON | Excel, Google Sheets, Airtable, Notion — helt gratis |
| Sparade konfigurationer | 3 recept | Mallar tillgängliga |
| Scraping av undersidor | Manuell receptuppsättning | Ingår i sidantalet |
Modellerna är verkligen olika. Simplescraper ger dig obegränsad lokal scraping med begränsad cloud-användning. ger dig färre sidor men packar in full AI-kapacitet i var och en, plus gratis export till de verktyg de flesta team faktiskt använder. Simplescrapers gratisnivå fungerar om du behöver enkel lokal scraping och kan leva med manuellt arbete. Men om du vill ha AI-driven extraktion med flexibla exports är Thunderbits gratisnivå mer kraftfull per sida.
Bästa praxis 4: Hur du undviker att bli blockerad under scraping
Ingen tänker på anti-bot-skydd förrän de stirrar på en CAPTCHA-vägg eller en tom datamängd. Då har du redan förlorat tid och kanske krediter.
Förebyggande skydd är alltid billigare än reaktiv felsökning.
Sätt rate limits och sprid ut dina anrop
Den vanligaste orsaken till blockering: att bomba en sajt med snabba förfrågningar. För en webbserver ser 50 förfrågningar på 10 sekunder från en IP inte ut som ett nyfiket forskningsprojekt, utan som en attack.
Tumregler:
- Lägg in 2–5 sekunder mellan sidförfrågningar för de flesta kommersiella sajter.
- För känsliga mål (marknadsplatser, recensionssajter), gå långsammare — 5–10 sekunder.
- Om du använder Simplescrapers API kan parametern hjälpa till att säkerställa att sidor laddas fullt innan extraktion, vilket också naturligt sänker takten.
När du ska aktivera proxy-rotering
Proxy-rotering byter din IP-adress mellan förfrågningar, så att du ser ut som flera olika användare. Du behöver det här för:
- Amazon, Yelp, TripAdvisor, LinkedIn (aggressiva anti-bot-system)
- Alla sajter som rate-limitar per IP
- Stora batchjobb (hundratals sidor från samma domän)
Simplescrapers plattform inklusive standard-, premium- och residential-alternativ. Däremot är tillgängligheten på exakt plannivå inte alltid kristallklar i den publika dokumentationen — verifiera innan du antar att gratisnivån täcker svåra mål. Residential proxies kostar oftast mer men är mindre benägna att flaggas.
Hantera JS-tunga sajter
Moderna sajter byggda med React, Vue eller Angular renderar innehåll efter den första sidladdningen. Om din skrapare agerar innan JavaScript har körts klart får du tomma fält.
Strategier:
- Använd cloud-läget för bättre rendering (Simplescrapers cloud kan köra JavaScript).
- Scrolla manuellt på sidan innan du kör en browser-scraping för att trigga lazy-loaded innehåll.
- Använd
waitForSelectori API-baserade arbetsflöden för att pausa tills mål-elementen visas. - Acceptera att vissa kraftigt dynamiska single-page-appar helt enkelt ligger bortom vad en visuell skrapare kan hantera tillförlitligt.
Det hands-off-alternativet
hanterar anti-bot-skydd, CAPTCHA:er och JavaScript-rendering automatiskt — ingen proxykonfiguration, inga delay-inställningar, ingen manuell scrollning. För användare som inte vill bli amatör-DevOps-ingenjörer bara för att skrapa en produktkatalog spelar det roll. Problemen försvinner inte — de blir bara någon annans problem.
Bästa praxis 5: Vet när Simplescraper har nått sin gräns
Jag önskar att någon hade skrivit det här avsnittet åt mig för två år sedan.
Det finns en punkt där verktyget slutar spara tid och börjar sluka tid. Att känna igen den gränsen tidigt räddar dig från sunk cost-fällan: "jag har redan byggt 15 recept, jag kan inte byta nu".
Simplescrapers praktiska begränsningar
- Dynamiska single-page-appar som laddar innehåll via AJAX utan traditionell sidnavigation
- Oändlig scroll som kräver kontinuerlig scrollning för att ladda alla objekt (inte vanlig klickbaserad paginering)
- Berikning av undersidor: skrapa en listningssida och besöka varje detaljsida för extra data. Simplescraper kan göra detta med , men komplexiteten i uppsättningen växer snabbt.
- Layoutändringar som bryter befintliga recept. När en sajt uppdaterar sin HTML-struktur slutar dina noggrant justerade CSS-selectors att fungera.
Tecken på att du har vuxit ur verktyget
Du har sannolikt nått gränsen när:
- Du justerar CSS-selectors manuellt vid varje körning eftersom autoidentifieringen fortsätter att misslyckas
- Recept går sönder efter sajtuppdateringar och måste byggas om
- Du behöver skrapa dussintals eller hundratals sidor samtidigt men stöter hela tiden på kredit- eller hastighetsgränser
- Data från undersidor kräver komplexa flerstegs-receptkedjor
- Du lägger mer tid på att underhålla scraping än på att faktiskt använda den extraherade datan
Det sista är det tydligaste tecknet. När underhåll blir jobbet har no-code-fördelarna försvunnit.
Gå över till ett AI-drivet arbetsflöde
Här vill jag prata om vad mitt team byggde med , eftersom det designades specifikt för de felmönster som beskrivs ovan:

- AI läser varje sida på nytt varje gång — inga sköra recept eller CSS-selectors att underhålla. Om en sajt ändrar layout anpassar sig AI:n vid nästa körning.
- Scraping av undersidor berikar din datatabell med ett klick. Skrapa en listning och besök sedan automatiskt varje detaljsida för ytterligare fält.
- Schemalagd scraping med naturligt språk ("varje måndag klockan 9") i stället för att konfigurera tidsförinställningar.
- Cloud scraping på 50 sidor samtidigt för högre hastighet på publika sajter.
- Inbyggd gratis export till Google Sheets, Airtable, Notion och Excel utan webhook-konfiguration.
Simplescraper vs. Thunderbit: Jämförelse sida vid sida
Här är allt samlat på ett ställe:

| Förmåga | Simplescraper | Thunderbit |
|---|---|---|
| Fältuppsättning | Manuella CSS-selectors / visuellt val | AI Suggest Fields (vanlig engelska) |
| Berikning av undersidor | Möjligt via batcharbetsflöden (komplicerad uppsättning) | Automatiskt berikande med 1 klick |
| Anpassar sig automatiskt till layoutändringar | Går sönder (manuell fix krävs) | AI läser om sidstrukturen varje gång |
| Samtidiga cloud-sidor | Batch upp till 5 000 URL:er (varierar per plan) | 50 sidor samtidigt |
| Export till Notion/Airtable | Via webhook (betalda nivåer) | Inbyggt, gratis |
| Schemaläggning | Förinställningar + egna tidskontroller | Beskrivning i naturligt språk |
| Anti-bot / CAPTCHA-hantering | Proxy-lägen finns (beror på plan) | Automatiskt, ingen konfiguration |
| Gratisnivå | 100 cloud-krediter + obegränsad browser + 3 recept | 6 sidor med fulla AI-funktioner + gratis export |
Kort sagt: Simplescraper glänser för enkel, visuell och lättkonfigurerad extraktion där ibland manuell finjustering är okej. Thunderbit tar vid där den modellen faller isär — och hanterar sidtolkning, layoutanpassning och arbetsflödeskomplexitet åt dig.
Inget av verktygen är universellt bättre. De ligger på olika punkter i komplexitetskurvan — och det är helt okej.
Snabbreferens: checklista för Simplescraper-bästa praxis
Bokmärk detta till din nästa scraping-session:
- Testa alltid på ett litet urval först. Bekräfta radantal och fältfullständighet på 2–3 sidor innan du skalar upp.
- Scrolla sidan innan du skrapar för att trigga lazy-loaded innehåll.
- Använd "Include Similar" när listidentifieringen verkar för snäv.
- Välj skrapningsläge medvetet. Browser för sidor som kräver inloggning; cloud för publika sidor och schemalagda jobb.
- Sätt fördröjningar mellan förfrågningar — minst 2–5 sekunder för kommersiella sajter, längre för mål med tungt anti-bot-skydd.
- Känn till matematiken bakom gratisnivån. 100 cloud-krediter = 50 sidor med JavaScript. Planera därefter.
- Spara bara recept för stabila sidor. Om en sajt uppdateras ofta kommer recepten att gå sönder.
- Lär dig grundläggande CSS-selectors som reserv. Klassnamn och dataattribut slår positionsselectors.
- Övervaka blockeringar proaktivt. Om du får tomma resultat eller CAPTCHA:er, sakta ner eller byt läge.
- Känn igen taket. När underhållstiden överstiger tiden du faktiskt använder datan, utvärdera alternativ.
Slutsats: Få varje scrapingkörning att räknas
Den övergripande lärdomen från mer än tusen scrapingkörningar handlar inte om något enskilt verktyg. Det är att angreppssättet är viktigare än mjukvaran. Att förstå varför en körning misslyckas — lazy loading, fel läge, aggressivt anti-bot-skydd, sköra selectors — är mer värdefullt än vilken funktionslista som helst.
Simplescraper fungerar verkligen bra för enkla extraheringsjobb. Om dina sidor är rena, dina behov är modest och du inte har något emot lite manuell justering då och då — då levererar det.
Men om du märker att du kämpar mer med verktyget än använder det — felsöker selectors, bygger om trasiga recept, konfigurerar proxies, scrollar sidor manuellt — då är det ett tecken, inte ett personligt misslyckande. Det betyder att du har vuxit ur det som visuell scraping ensam kan hantera.
Om det låter bekant, prova — sex sidor med fulla AI-funktioner, gratis export till Sheets, Airtable och Notion. Jämför med ditt nuvarande arbetsflöde och se vad som fastnar. Ibland är den bästa metoden att veta när det är dags att ta fram ett helt annat verktyg.
Vanliga frågor
Är Simplescraper gratis att använda?
Ja, Simplescraper har en gratisplan som inkluderar obegränsad lokal browser-scraping, , 3 sparade recept och export till CSV/JSON. Sidor i cloud-läge med JavaScript kostar 2 krediter vardera, så de 100 krediterna räcker till ungefär 50 sidor i cloud-läge. Betalda planer börjar på 39 USD/månad (Plus) för 6 000 krediter och 70 USD/månad (Pro) för 15 000 krediter.
Kan Simplescraper hantera webbplatser med mycket JavaScript?
Ibland. Simplescrapers cloud-läge kan rendera JavaScript, och verktyget marknadsför stöd för single-page-appar. Men komplexa SPA:er med tung dynamisk rendering, oändlig scroll eller aggressiva anti-bot-system kan ändå ge ofullständiga resultat. Cloud-läge med rätt väntetider förbättrar tillförlitligheten, men starkt dynamiska sajter är fortfarande en utmaning för alla visuella skrapare.
Vad är skillnaden mellan cloud- och browser-scraping i Simplescraper?
Browser-scraping körs lokalt i din Chrome-webbläsare — den använder din aktiva session (perfekt för sidor som kräver inloggning), kostar inga krediter, men kräver att datorn är på. körs på Simplescrapers servrar — det är snabbare, körs utan övervakning, stöder schemaläggning och integrationer, men kostar krediter per sida och kan inte nå sidor bakom din personliga inloggning.
När bör jag byta från Simplescraper till ett alternativ som Thunderbit?
Det tydligaste tecknet är när underhållstiden överstiger tiden du använder datan. Om du regelbundet måste fixa trasiga selectors efter sajtuppdateringar, konfigurera proxies manuellt, bygga om recept eller lägga mer tid på felsökning än på att analysera den extraherade datan, har du vuxit ur det som manuell visuell scraping kan ge effektivt. Verktyg som använder AI för att tolka sidstrukturen vid varje körning och tar bort det mesta av det underhållsbehovet.
Hur undviker jag att bli blockerad när jag skrapar med Simplescraper?
Tre nyckelmetoder: För det första, sprid ut dina förfrågningar med 2–5 sekunders fördröjning mellan sidorna (längre för sajter med tungt anti-bot-skydd som Amazon eller Yelp). För det andra, använd browser-läge som reserv för sajter som aggressivt blockerar cloud-IP:er — din webbläsarsession ser mer ut som normal trafik. För det tredje, aktivera proxy-rotering för stora batchjobb på känsliga mål, men kontrollera vilka proxyalternativ din plan faktiskt innehåller innan du förlitar dig på dem.
Läs mer