

Om du någon gång har försökt köpa data online för ditt företag känner du säkert igen känslan: du letar efter den perfekta datamängden, men det liknar mer att köpa avokado — ibland hittar du en klockren träff, ibland får du något mosigt och trist, och ibland undrar du bara om du ens står vid rätt hylla. I dagens datadrivna värld driver offentliga datamängder allt från smartare marknadsföring till skarpare konkurrensanalys. Men i takt med att allt fler företag jagar tillväxt med data är den verkliga utmaningen inte bara att hitta offentlig data — utan att se till att det du köper faktiskt är användbart, tillförlitligt och redo att kopplas in i ditt arbetsflöde.
Jag har arbetat mycket med team som vill använda offentlig data för tillväxt, och jag har sett på nära håll hur lätt det är att snubbla på dolda kostnader, tveksamma leverantörer eller data som ser bra ut på pappret men faller ihop i praktiken. I den här guiden går jag igenom de praktiska stegen (och några lärdomar från verkligheten) för att hitta, utvärdera och använda offentliga datamängder — så att du kan förvandla rå information till faktiska affärsresultat.
Värdet av att köpa offentliga datamängder för affärstillväxt
Låt oss börja med varför. Varför vill så många företag köpa data online, och vad skiljer betald offentlig data från gratisalternativen?
Det korta svaret: offentliga datamängder är i dag en central del av affärsstrategin och ROI. Enligt ny forskning anser 90 % av företagen att data och analys är avgörande för deras affärsstrategi, och ungefär en fjärdedel av organisationerna fattar nästan alla strategiska beslut med datastöd. Effekten är tydlig — datadrivna marknadsföringsstrategier ger i genomsnitt 15 % högre ROI än strategier som inte använder data.
Offentliga datamängder kan driva tillväxt på flera sätt:
- Leadgenerering: Berika ditt CRM med nya kontakter eller företagsprofiler.
- Marknadsundersökningar: Följ konkurrenters priser, produktlanseringar eller kundsentiment.
- Effektivare verksamhet: Automatisera manuella efterforskningar, övervaka trender eller jämföra lönenivåer.
Men här kommer poängen: gratis offentlig data (till exempel från myndighetsportaler eller öppna datakällor) levereras ofta ”som den är” — ofullständig, stökig eller inaktuell. Det är lite som att få en gratis valp: gullig, men du får lägga mycket tid på att städa efter den. Betalda datamängder, däremot, är bearbetade för att vara mer tillförlitliga, kompletta och enkla att använda. Leverantörer lägger resurser på att rensa, uppdatera och strukturera datan så att du slipper. För många företag är det betydligt mer kostnadseffektivt att betala för kvalitet än att själv brottas med gratis data — särskilt när alternativet är att lägga timmar (och lönekostnader) på rensning och sammanslagning.
Viktiga utmaningar när du köper data online
Om det bara vore lika enkelt att köpa data som att beställa mat. I verkligheten finns det flera hinder som även erfarna team stöter på:
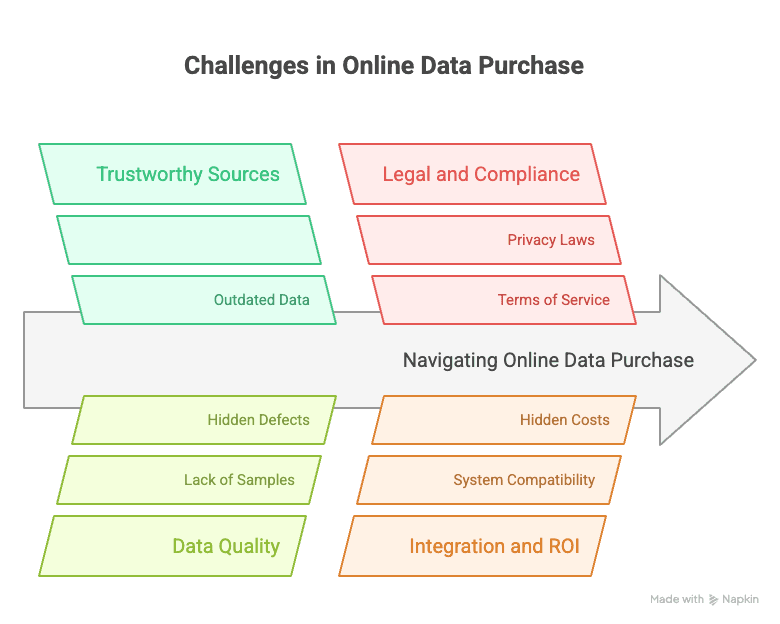
- Att hitta pålitliga källor: Internet kryllar av marknadsplatser och leverantörer av data, men alla håller inte samma nivå. Vissa säljer gammal eller dåligt källbelagd data, andra är helt enkelt tveksamma. Det är avgörande att granska leverantörer utifrån aktualitet, noggrannhet och transparens.
- Att verifiera datakvalitet: Många datamängder ser fantastiska ut i beskrivningen, men du ser inte det verkliga innehållet förrän efter köp. Vissa marknadsplatser erbjuder inte ens exempel, vilket gör att du riskerar att köpa grisen i säcken.
- Juridik och regelefterlevnad: Bara för att data är ”offentlig” betyder det inte att du får använda den hur som helst. Integritetsregler som GDPR eller CCPA, eller webbplatsers användarvillkor, kan begränsa vad du får göra. Alla leverantörer garanterar inte efterlevnad (och det är en verklig risk).
- Integrationsproblem: Även om datan är bra kanske den inte passar dina system eller processer. Du kan behöva formatera om, rensa eller slå ihop den — vilket kostar både tid och pengar.
- Osäker ROI: Prislappen är bara början. Det finns dolda kostnader för integration, rensning och löpande underhåll. Och datans värde blir inte alltid tydligt förrän du faktiskt börjar använda den.
Enligt min erfarenhet handlar den största utmaningen inte bara om att hitta data — utan om att se till att du faktiskt kan använda den för att skapa affärsresultat. Därför rekommenderar jag alltid en checklista för datautvärdering: aktualitet, täckning, fullständighet, efterlevnad och integration.
Var du hittar tillförlitliga offentliga datamängder
Så var går man egentligen för att köpa data online? Här är de vanligaste alternativen, alla med sina egna egenheter:
Datamarknadsplatser
Tänk på dessa som Amazon för datamängder. Plattformar som Snowflake Marketplace, AWS Data Exchange och Oracle Data Marketplace låter dig bläddra bland tusentals datamängder från olika leverantörer. Här hittar du allt från konsumentdemografi till B2B-firmografi och geografiska data.
Fördelar: Enorm variation, lätt att jämföra, ibland direkt integration med dina molnverktyg.
Nackdelar: Kvaliteten varierar, inte all data är granskad, och du måste ändå ta hand om integration och rensning. Köparen får vara vaksam — läs det finstilta.
Myndighets- och öppna dataportaler
Sajter som data.gov eller EU Open Data Portal erbjuder kostnadsfri, auktoritativ data om allt från ekonomi till sjukvård. Utmärkta för marknadsundersökningar eller benchmarking.
Fördelar: Gratis, ofta tillförlitlig och utan krångliga licensfrågor.
Nackdelar: Data kan vara inaktuell, dåligt strukturerad eller inte anpassad för affärsbehov. Du behöver sannolikt lägga mycket tid på rensning.
Specialiserade dataleverantörer
Företag som ZoomInfo, Dun & Bradstreet, Experian eller S&P Global Market Intelligence försörjer sig på att sälja kuraterade datamängder — till exempel B2B-kontakter, kreditdata eller finansiell information.
Fördelar: Hög kvalitet, god täckning och ofta stöd eller analysverktyg.
Nackdelar: Dyra, och du kan bli låst till en prenumeration. Se till att du inte betalar för mer än du faktiskt behöver.
Web scraping-tjänster eller egen scraping
Om du inte hittar datan du behöver kan du alltid samla in den själv — antingen med traditionella web scraping-verktyg eller genom att anlita en tjänst. Det är här det blir intressant (och ibland lite krångligt).
Fördelar: Full anpassning, du får exakt det du vill ha.
Nackdelar: Tekniska hinder, juridiska risker och underhållsproblem. Mer om det i nästa avsnitt.
Proffstips: Be alltid om ett exempel eller en förhandsvisning innan du köper. Om leverantören vägrar, är det en varningssignal.
Utvärdera offentliga datamängder innan köp
Här gäller det att gå från teori till praktik. Innan du spenderar en krona, gå igenom den här checklistan:
| Utvärderingskriterium | Vad du ska kontrollera |
|---|---|
| Aktualitet | Hur nyligen uppdaterades datan? Uppdateras den regelbundet? |
| Täckning och fullständighet | Täcker den hela ditt behov? Är viktiga fält (som e-post, pris, plats) i huvudsak ifyllda? |
| Noggrannhet och trovärdighet | Förklarar leverantören sina källor? Kan du kontrollera några poster själv? |
| Format och integrerbarhet | Finns datan i ett format som ditt team kan använda (CSV, JSON, API)? Är kolumnerna tydligt märkta och datatyperna konsekventa? |
| Juridisk efterlevnad | Finns det användningsbegränsningar? Uppfyller datan GDPR/CCPA? |
| Support och SLA från leverantören | Vad händer om det finns ett fel? Finns det supportkontakt eller återbetalningspolicy? |
Om möjligt, testa ett exempel i ditt eget arbetsflöde. Lägg in det i ditt CRM- eller analysverktyg och se om det fungerar smidigt. Jag har sett företag köpa enorma datamängder bara för att upptäcka att 90 % av posterna är skräp eller saknar viktiga fält. Lite förarbete sparar mycket huvudvärk senare.
Traditionella metoder för datainsamling: varför de inte räcker till
Nu till elefanten i rummet: traditionell web scraping. Jag har sett så många team försöka bygga egna scrapers, bara för att hamna i ett oändligt spel av slag-på-slag-mot-målet.
Varför har de gamla metoderna svårt att hänga med?
- Moderna webbplatser är komplexa: Dynamiskt innehåll, JavaScript, oändlig scroll och nästlade kommentarer gör det svårt för enkla scrapers att hänga med (ZenRows förklarar detta bra).
- Sajter förändras hela tiden: En liten ändring i HTML kan slå ut din scraper. Underhåll blir ett heltidsjobb.
- Motåtgärder mot scraping: CAPTCHA, IP-blockering och inloggningskrav kan stoppa dig direkt.
- Manuell uppsättning: Du måste hitta varje selector, skriva paginering och hantera undersidor. Det är tidskrävande och lätt att göra fel.
- Ofullständig data: Dold eller nästlad information, som recensioner eller bilder, missas ofta.
Resultatet? Även när det fungerar är lösningen skör och underhållskrävande. För de flesta affärsanvändare är det helt enkelt inte mödan värt.
Thunderbit: ett smartare sätt att köpa och samla in offentlig data
Extrahera data från vilken webbplats som helst med AI Get Started Free
Här blir jag riktigt engagerad — för på Thunderbit har vi valt ett annat angreppssätt. I stället för att förlita oss på ömtålig kod och CSS-selectors använder Thunderbit AI för att ”läsa” webbsidor semantiskt.
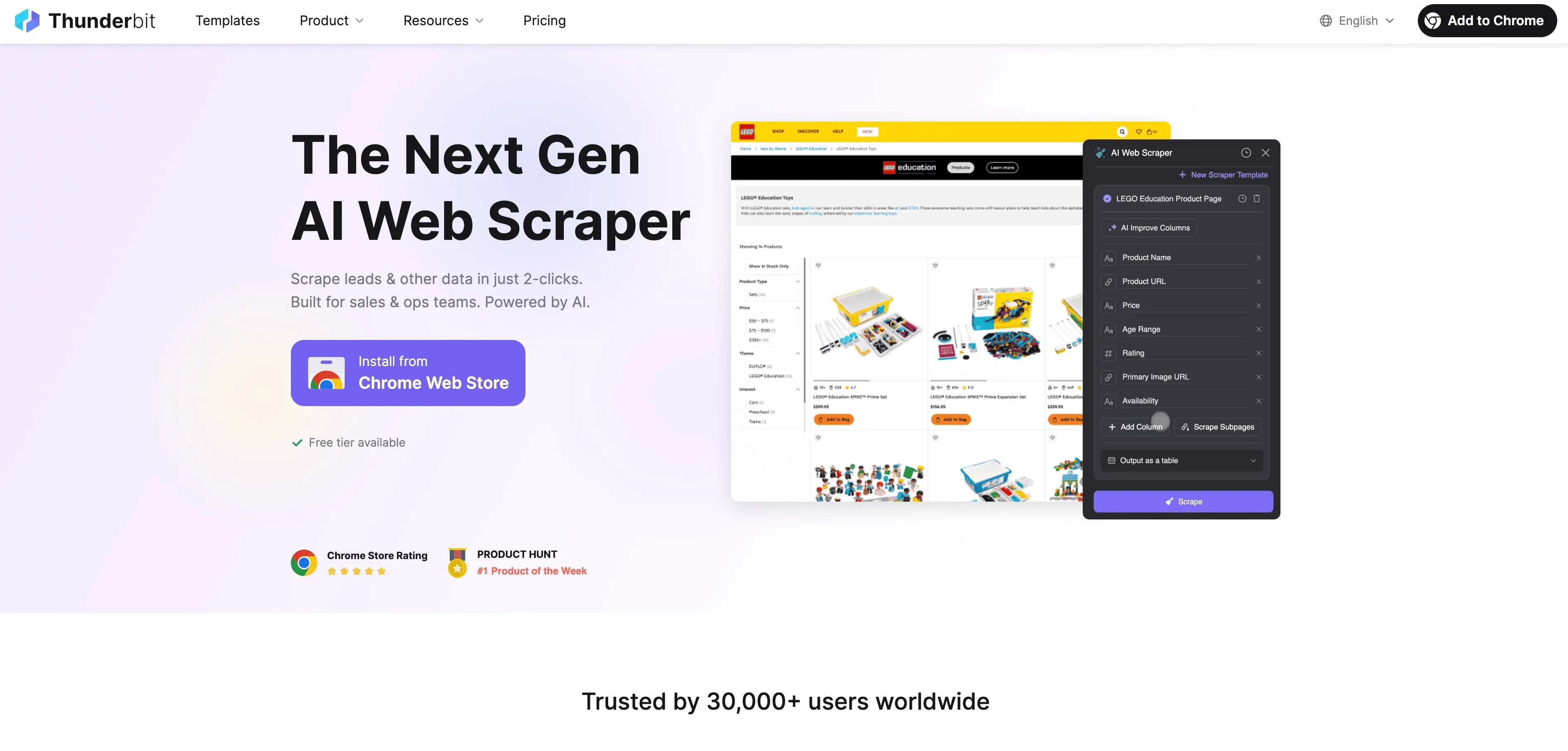
Så här fungerar det:
- Semantisk förståelse: Thunderbit omvandlar webbsidan till ett Markdown-liknande format som bevarar struktur och innebörd (rubriker, listor, tabeller osv.). AI:n tolkar sedan denna struktur och identifierar det som är viktigt — ungefär som en människa skulle göra (se detaljerna).
- Tål layoutändringar: Om en webbplats uppdaterar sin design kan Thunderbits AI fortfarande hitta rätt data, så länge betydelsen är densamma.
- Hanterar dynamiskt innehåll: Oändlig scroll, knappar som ”Load More” och JavaScript-element? Thunderbit upptäcker och interagerar med dem automatiskt.
- Scraping av undersidor: Thunderbit kan följa länkar till detaljsidor och berika din datamängd med extra fält — utan extra kodning.
- Ingen kod krävs: Affärsanvändare kan klicka på ”AI Suggest Fields”, granska de rekommenderade kolumnerna och sedan trycka på ”Scrape”. Så enkelt är det.
Den praktiska effekten: på sidor som ofta ändrar layout eller laddar innehåll dynamiskt lägger du mindre tid på att skriva om selectors och mer tid på att använda datan.
Standardisera din process för offentlig datainsamling med Thunderbit
Vad är data scraping och hur gör man det 2025 Get Started Free
En av de största utmaningarna jag ser är inkonsekvens. Varje ny datakälla innebär att man börjar om från början — nya fält, nya format, nya rensningssteg. Thunderbit hjälper dig att standardisera och automatisera hela processen:
- AI Suggest Fields: Thunderbit läser sidan och föreslår rätt kolumner och datatyper, så du slipper gissa vad som ska extraheras (se hur det fungerar).
- Scraping av undersidor: Behöver du mer detaljer? Thunderbit kan automatiskt besöka varje länkad undersida och hämta extra information — till exempel företagsprofiler, produktspecifikationer eller kontaktuppgifter.
- Paginering och oändlig scroll: Thunderbit upptäcker och hanterar dessa mönster, så att du alltid får hela datamängden.
- Inbyggd datarensning: Lägg till egna prompts för att normalisera, kategorisera eller formatera data medan du samlar in den.
- Enkel export: Skicka datan direkt till Excel, Google Sheets, Airtable eller Notion med ett klick. Slut på kopiera-klistra-gymnastik (mer här).
- Schemalagd scraping: Automatisera återkommande datainsamling — dagligen, veckovis, vad du än behöver.
Tillsammans gör detta att du kan samla in, berika och standardisera data i stor skala, utan att behöva ett team av ingenjörer eller en doktorsexamen i web scraping.
Räkna ut ROI för att köpa offentliga datamängder
Låt oss prata kronor och ören. Hur vet du om det är värt att köpa data online?
Den verkliga kostnaden
- Inköp: Priset för datamängden eller prenumerationen.
- Integration: Tid och arbete för att rensa, formatera och ladda in datan.
- Underhåll: Löpande uppdateringar, prenumerationer eller kostnader för scraping-verktyg.
Undersökningar varierar, men databeredning — att ladda, rensa och organisera — tar vanligtvis omkring 45 % av en dataexperts arbetstid, och själva rensningen kan ta ungefär en fjärdedel av dagen i sig (Anaconda State of Data Science). Att köpa en stökig datamängd flyttar bara ännu mer av veckan in i den kategorin.
Avkastningen
- Intäktsökning: Fler leads, bättre målgruppsstyrning, smartare prissättning.
- Kostnadsbesparingar: Automatiserad manuell research, lägre arbetsinsats.
- Bättre beslut: Färre misstag, snabbare upptäckt av möjligheter.
- Snabbare time-to-market: Lansera produkter eller kampanjer tidigare.
En enkel ROI-formel:
(Totala fördelar – totala kostnader) / totala kostnader x 100 %
Om du till exempel lägger 10 000 dollar på data (inklusive alla kostnader) och den hjälper dig att stänga nya affärer värda 50 000 dollar, blir din ROI 400 %. Inte illa.
Proffstips: Kör ett pilotprojekt först. Använd Thunderbits gratis export för att extrahera ett litet urval, testa det i ditt arbetsflöde och se om det ger värde innan du satsar stort.
Steg-för-steg: så köper och använder du offentliga datamängder med Thunderbit
Redo att omsätta detta i praktiken? Här är min praktiska, beprövade vägledning:
Steg 1: Definiera dina databehov
Börja med affärsmålet. Vill du generera leads? Bevaka konkurrenter? Jämföra löner? Var konkret med:
- De fält du behöver (t.ex. företagsnamn, e-post, pris, plats)
- Volymen (hur många poster?)
- Frekvensen (engångsinsamlings eller löpande?)
- Formatet (CSV, Excel, Google Sheets osv.)
Skriv ner det. Ju tydligare behov du har, desto enklare blir det att utvärdera alternativ och undvika onödiga kostnader.
Steg 2: Hitta och utvärdera datamängder
- Utforska datamarknadsplatser, leverantörskataloger och öppna dataportaler.
- Gör en shortlist: Leta efter datamängder som matchar dina kriterier.
- Be om exempel eller förhandsvisningar: Om det inte finns, använd Thunderbit för att extrahera ett litet urval från offentliga sajter.
- Gå igenom utvärderingschecklistan: Aktualitet, täckning, fullständighet, noggrannhet, format, efterlevnad och support.
- Testa i ditt arbetsflöde: Ladda in urvalet i ditt CRM eller analysverktyg. Passar det? Är viktiga fält ifyllda?
Om en datamängd klarar testet, gå vidare. Om inte, fortsätt leta — eller överväg att samla in datan själv med Thunderbit.
Steg 3: Använd Thunderbit för att samla in och strukturera data
Så här använder jag Thunderbit (och det kan du också göra):
- Installera Thunderbit Chrome Extension.
- Gå till målsajten (katalog, listor, sökresultat).
- Klicka på ”AI Suggest Fields”. Thunderbit föreslår kolumner och datatyper.
- Granska och justera fälten vid behov. Lägg till egna prompts för särskild formatering eller berikning.
- Aktivera Scraping av undersidor om du behöver detaljer från länkade sidor.
- Hantera paginering eller oändlig scroll — Thunderbit brukar upptäcka detta automatiskt.
- Klicka på ”Scrape”. Se hur Thunderbit fyller din datatabell.
- Exportera till Excel, Google Sheets, Airtable eller Notion — allt med ett klick.
- Granska din data. Om något behöver justeras, ändra och kör om.
Thunderbits gratisnivå låter dig testa detta på några sidor, så att du kan se resultatet innan du skalar upp.
Testa Thunderbit gratis för datainsamling
Steg 4: Testa, integrera och skala upp
- Testa datakvalitet och ROI: Kör en liten kampanj eller analys med din nya data. Är leadsen giltiga? Är insikterna användbara?
- Integrera med dina affärsverktyg: Importera till ditt CRM, BI-dashboard eller marketing automation-plattform.
- Automatisera för skala: Använd Thunderbits schemalagda scraping för att hålla din data färsk.
- Följ upp och förbättra: Håll koll på datakvaliteten och justera processen vid behov.
Slutsats och viktiga lärdomar
Att köpa offentliga datamängder online kan vara en kraftfull motor för affärstillväxt — men bara om du gör det med en tydlig plan och rätt verktyg. Här är vad jag har lärt mig, ibland den hårda vägen:
- Börja med ett tydligt mål. Vet vad du behöver och varför.
- Granska dina källor. Använd en checklista för att utvärdera datamängder innan du köper.
- Se upp för dolda kostnader. Räkna med rensning, integration och underhåll.
- Utnyttja avancerade verktyg. Thunderbits AI-drivna arbetssätt gör datainsamling snabbare, mer tillförlitlig och tillgänglig — även för dig som inte kodar.
- Standardisera och automatisera. Bygg ett återanvändbart arbetsflöde så att du slipper uppfinna hjulet varje gång.
- Mät ROI. Testa i liten skala och skala sedan upp det som fungerar.
Med rätt angreppssätt kan du förvandla offentlig data till en verklig konkurrensfördel — utan de vanliga huvudvärken. Om du vill se hur enkelt det kan vara, prova Thunderbit (gratisnivån är ett utmärkt sätt att komma igång).
Lycka till med datajakten — må dina avokador alltid vara perfekt mogna.
Vanliga frågor
1. Vad är skillnaden mellan gratis och betalda offentliga datamängder?
Gratis datamängder (till exempel från myndighetsportaler) är ofta ofullständiga, inaktuella eller dåligt strukturerade och kräver mycket rensning. Betalda datamängder är kuraterade för att vara tillförlitliga, kompletta och enkla att integrera, vilket sparar tid och arbete.
2. Hur vet jag om en datamängd håller hög kvalitet innan jag köper?
Be alltid om ett exempel eller en förhandsvisning. Använd en checklista: kontrollera aktualitet, fullständighet, noggrannhet, format och efterlevnad. Testa urvalet i ditt arbetsflöde för att säkerställa att det passar dina behov.
3. Vilka juridiska risker finns när man köper offentlig data online?
All ”offentlig” data är inte fri från begränsningar. Se till att leverantören följer integritetslagar (som GDPR eller CCPA) och att du har rätt att använda datan för ditt avsedda syfte.
4. Hur gör Thunderbit datainsamling enklare jämfört med traditionella scrapers?
Thunderbit använder AI för att förstå webbsidor semantiskt, hanterar dynamiskt innehåll och layoutändringar, automatiserar fältval och stödjer scraping av undersidor — allt via ett kodfritt gränssnitt med direkt export till dina favoritverktyg.
5. Hur kan jag räkna ut ROI för att köpa en offentlig datamängd?
Summera alla kostnader (inköp, integration, underhåll) och uppskatta fördelarna (intäktsökning, kostnadsbesparingar, bättre beslut). Kör ett pilotprojekt med ett litet urval för att testa verklig effekt innan du skalar upp. Använd formeln: (Totala fördelar – Totala kostnader) / Totala kostnader x 100 %.
Läs mer:
- 10 bästa verktygen och programvarorna för dataaggregering
- Så extraherar du enkelt data från en webbplats till Google Sheets
- Att köpa webbaserad data för bättre affärsbeslut 2025
- Att köpa webbaserad data för bättre affärsbeslut 2025
Testa AI Web Scraper för insamling av offentlig data Get Started Free




