

YouTube har över 2 miljarder månadsanvändare och 500+ timmar video laddas upp varje minut. Det är också en av de svåraste plattformarna att skrapa utan att springa in i en vägg av CAPTCHA:er, 429-fel eller rena IP-banningar.
Om du någon gång har försökt hämta kanaldata, kommentarer eller transkript i större skala vet du redan hur frustrerande det är. Du får några hundra träffar, och sedan slår YouTube igen dörren. Jag har lagt mycket tid på att utvärdera hur olika scrapers klarar sig mot YouTubes ständigt föränderliga antibot-försvar, och glappet mellan verktyg som fungerar tillförlitligt och verktyg som blir blockerade inom några minuter är enormt.
Den här guiden går igenom de 6 bästa YouTube-skriparna för 2026 — verktyg som faktiskt är byggda för att hantera YouTubes motstånd utan att bränna din IP eller ditt arbetsflöde. Oavsett om du är marknadsförare som bevakar konkurrentkanaler, ett säljteam som letar kreatörskontakter eller en utvecklare som bygger ett datapipeline, finns det ett alternativ här som passar.
Vad YouTube faktiskt blockerar 2026 (och varför de flesta scrapers misslyckas)
Youtubes antibot-försvar är inte en enda mur — det är ett lager på lager-system. Att förstå vad du möter är första steget för att slippa bli blockerad.
Här är vad YouTube gör 2026 för att upptäcka och stoppa automatiserad åtkomst:

- Kontroller av IP-rykte och hastighet: Upprepade förfrågningar från datacenter-IP:er, VPN:er eller delade proxyservrar flaggas snabbt. Du ser 403-fel, 429-rate limits eller skärmar med ”logga in för att bekräfta att du inte är en bot”.
- Fingerprinting av webbläsare och JavaScript: YouTube kontrollerar om klienten beter sig som en riktig webbläsare — kör skript, renderar element och behåller förväntat tillstånd. Headless-webbläsare och rena HTTP-klienter faller ofta igenom dessa kontroller utan tydliga fel (du får bara tom eller ofullständig data).
- Tillförlitlighet för cookies och sessioner: Om dina förfrågningar inte kommer från en igenkänd, långlivad webbläsarsession ökar YouTube verifieringen. Inloggade sessioner med webbhistorik får mer förtroende än nya, anonyma sessioner.
- Beteendeanalys: Enhetliga intervall mellan förfrågningar, för snabb scrollning eller upprepade sidmönster utlöser throttling. YouTube letar efter navigation som ingen människa skulle utföra.
- CAPTCHA-grindar: När risken är hög tvingar YouTube fram mänsklig verifiering — särskilt på sökresultat och kommentarsfält.
- API-kvotreglering: Det officiella YouTube Data API:t tillämpar dagliga projektkvoter (10 000 enheter/dag som standard), och söktunga arbetsflöden förbrukar dem på några minuter.
Den typiska användarupplevelsen: du börjar skrapa, får några hundra resultat och stöter sedan på fel 429, en CAPTCHA-vägg eller tyst försämrad data. Molnbaserade scrapers som körs från datacenter-IP:er är särskilt sårbara.
| Upptäcktsmetod | Vad den gör | Symtom för användaren | Verktyg som minskar risken |
|---|---|---|---|
| IP-rykte/hastighet | Flaggar datacenter-/VPN-/delade IP:er | 403, 429, bot-bekräftelse | Webbläsarsessions-skrapning, residential proxies |
| JS-fingerprinting | Kontrollerar riktig webbläsarkörning | Tyst saknad data, CAPTCHA | Riktig webbläsartillägg, full rendering |
| Cookie-/sessionsförtroende | Jämför med inloggade profiler | ”Logga in för att bekräfta” | Användarcookies, autentiserad session |
| Beteendeanalys | Upptäcker omänskliga mönster | Throttling efter ~200 rader | Mänskliga fördröjningar, randomisering, små batcher |
| API-kvotreglering | Begränsar dagliga API-enheter | 403 quotaExceeded | Använd scrapers för sök/kommentarer, API för riktade uppslag |
| CAPTCHA-grindar | Tvingar fram mänsklig verifiering | Extraktionen avbryts mitt i körningen | Webbläsarsession, proxy/unblocker, långsammare takt |
Kort sagt: verktyg som arbetar inne i en riktig webbläsarsession (som Thunderbit) kringgår naturligt många av dessa kontroller eftersom förfrågningen ser identisk ut med en människa som surfar på YouTube. Molnendast-scrapers behöver proxyrotation, CAPTCHA-lösning och noggrann pacing för att överleva.
Prova Thunderbit för YouTube-skrapning
YouTube API vs. bästa YouTube-scrapers: ett praktiskt beslutsramverk
YouTube Data API v3 är det ”officiella” sättet att komma åt YouTube-data programmässigt. Det är tillförlitligt för enkel metadata i låg volym — men kvotmodellen gör det opraktiskt för de flesta verkliga arbetsflöden inom konkurrensbevakning och research.
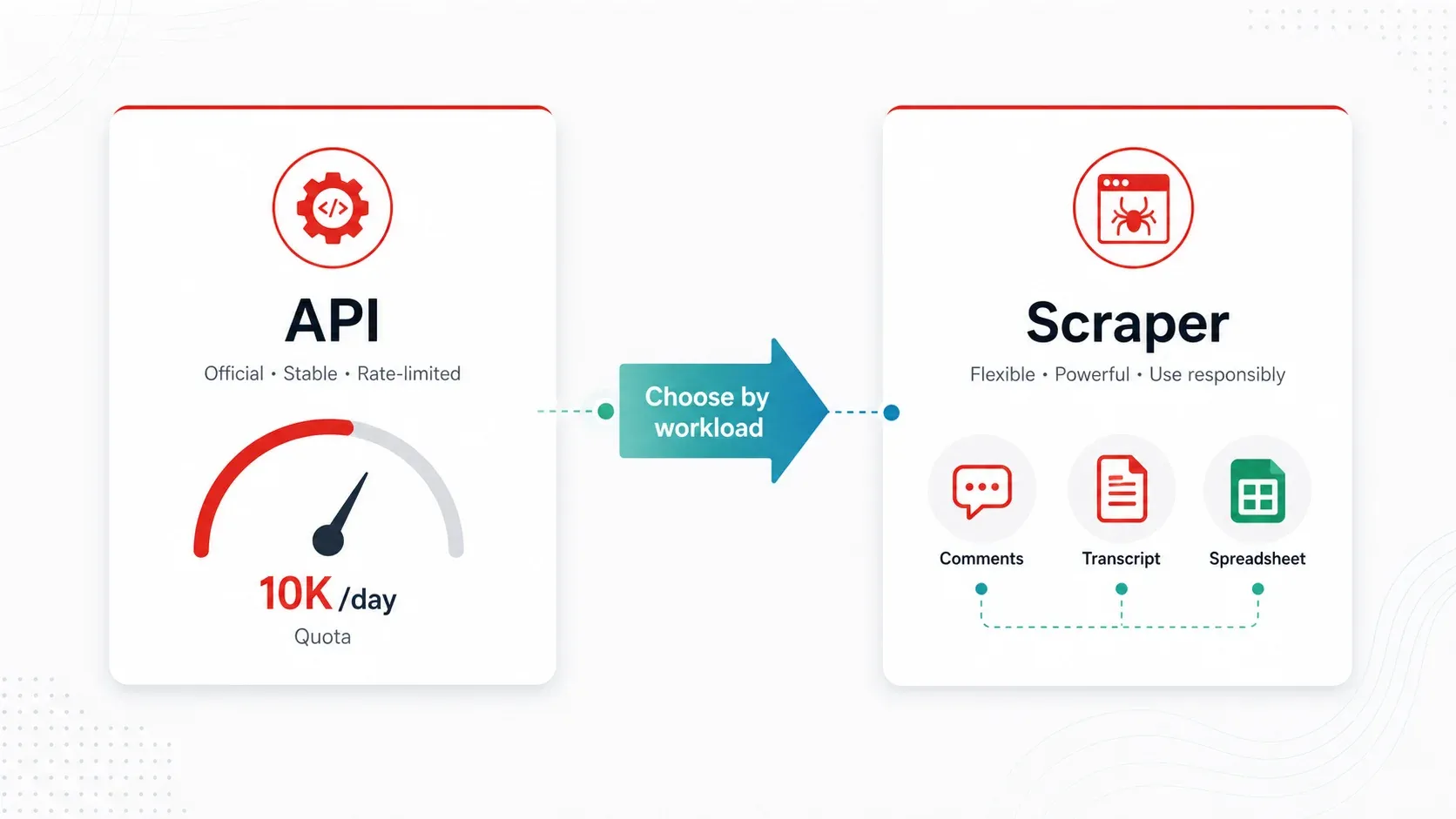
Så här ser matematiken ut. Varje API-projekt får 10 000 kvotenheter per dag. Viktiga endpoint-kostnader:
search.list= 100 enheter per sida (max 50 resultat per sida)videos.list= 1 enhet per anrop (upp till 50 video-ID:n per anrop)commentThreads.list= 1 enhet per anrop (upp till 100 trådar per anrop)
Så om du kör 100 sökningar med nyckelord per dag har du förbrukat hela din dagliga kvot innan du ens har berikat en enda video. Ett kommentartungt arbetsflöde är billigare per anrop, men verklig paginering, avstängda kommentarer och utökning av svar äter snabbt upp kapaciteten.
När API:t räcker:
- Du behöver färre än 100 videor/dag och bara publik metadata (titel, visningar, likes, längd)
- En utvecklare kan sätta upp OAuth och hantera kvoten
När en scraper är bättre:
- Du behöver kommentarer i stor skala (API:t fungerar, men kvotfriktionen är verklig)
- Du behöver transkript/textning som text (API:t exponerar inte caption-text enkelt för bulkbruk)
- Du övervakar 100+ kanaler regelbundet (kvoten tar slut snabbt, schemaläggning är manuell)
- Du behöver berikad eller märkt data (kategorisering, översättning eller AI-driven fältidentifiering)
- Du är en icke-teknisk användare som bara vill ha ett kalkylblad
API:t visar inte heller allt du ser på webben: data från Shorts-hyllan, offentliga e-postadresser från kanalbeskrivningar, community-inlägg och viss kanalmetadata går bara att komma åt genom att skrapa de faktiska YouTube-sidorna.
Skrapa YouTube-data med AI Get Started Free
För de flesta företagsanvändare som gör konkurrensresearch, kreatörssourcing eller innehållsstrategi är ett scraperverktyg mer praktiskt än API:t.
Så valde vi ut de 6 bästa YouTube-scraperserna
Varje verktyg på den här listan utvärderades utifrån samma kriterier — viktat mot det som faktiskt spelar roll när YouTube aktivt försöker blockera dig:
| Kriterium | Varför det är viktigt |
|---|---|
| Tillförlitlighet mot blockering | Användarnas största smärtpunkt — rate limiting och IP-banningar i stor skala |
| Kostnad per 1 000 resultat | Normaliserad prissättning gör att budgetmedvetna användare kan jämföra äpplen med äpplen |
| Datatyper som stöds | Metadata, kommentarer, transkript, Shorts, miniatyrbilder — varierar kraftigt mellan verktyg |
| Skalbarhet | Klarar det 100+ kanaler eller 10K+ videor utan att krascha? |
| Enkel uppsättning | Förstagångsanvändare behöver handfasta, no-code-vänliga alternativ |
| Exportformat | CSV, JSON, Google Sheets, Airtable — olika arbetsflöden kräver olika utdata |
| Underhållsbehov | YouTubes förändringar bryter verktyg; vem fixar dem? |
Alla verktyg utvärderades mot aktuella YouTube-blockeringsmönster som användare möter 2026.
1. Thunderbit
Thunderbit är ett AI-drivet Chrome-tillägg som förvandlar YouTube-sidor till strukturerad data på ungefär två klick. I stället för att köras från en molnserver (som YouTube lätt flaggar) arbetar Thunderbit inne i din egen webbläsarsession — så för YouTube ser det ut som att det är du som surfar som vanligt.
Det centrala arbetsflödet för YouTube: installera Thunderbit Chrome Extension, gå till en YouTube-kanal, en sökresultatsida eller en videosida och klicka på ”AI Suggest Fields”. AI:n läser sidan och föreslår kolumner — videotitel, URL, visningar, uppladdningsdatum, beskrivning, miniatyrbilds-URL, kommentarstext, författare, likes med mera. Du granskar, klickar på ”Scrape” och exporterar direkt till Google Sheets, Excel, Airtable, Notion, CSV eller JSON. Ingen kod, inga selektorer, inga API-nycklar.
Viktiga funktioner för YouTube-skrapning:
- AI-baserad fältidentifiering: Thunderbits AI läser vilken YouTube-sida du än är på och föreslår automatiskt relevanta kolumner. Du behöver inte manuellt mappa CSS-selektorer eller XPath.
- Skrapning av undersidor: Skrapa en kanals videolista och klicka sedan in på varje videosida för att berika med kommentarer, beskrivningar, taggar och transkript (om de är synliga).
- Schemalagd skrapning: Sätt upp återkommande jobb för att bevaka kanaler varje vecka utan manuell hantering.
- Browser Mode: Kör i din autentiserade webbläsarsession, vilket minskar fingeravtrycket av ”moln-datacenter-IP” som utlöser de flesta YouTube-blockeringar.
- Gratis export: Data går till Google Sheets, Excel, Airtable eller Notion utan att exporten låses bakom betalvägg.
Anti-ban-strategi: Webbläsarbaserad sessionsskrapning med användarens egna autentiserade session. YouTube ser en riktig webbläsare, riktiga cookies och riktig sessionshistorik. För jobb med hög volym minskar schemalagda små batcher risken ytterligare.
Prissättning: Gratis nivå (6 sidor), trial-boost (10 sidor). Betalda planer är kreditbaserade. Se Thunderbit Pricing för aktuella siffror.
Bäst för: Marknadsförare, säljteam, innehållsstrateger och operations-användare som vill göra snabb kanal-, sök- och kommentarresearch utan teknisk uppsättning.
Så skrapar du YouTube med Thunderbit (steg för steg)
- Installera Thunderbit Chrome Extension.
- Navigera till en YouTube-kanalsida, sökresultat, spellista eller videosida.
- Klicka på ”AI Suggest Fields” — AI:n läser sidan och föreslår kolumner (titel, URL, visningar, datum, beskrivning, miniatyrbild osv.).
- Granska och justera de föreslagna fälten vid behov.
- Klicka på ”Scrape” — data extraheras till en strukturerad tabell.
- Exportera till Google Sheets, Excel, Airtable, Notion, CSV eller JSON.
För djupare extraktion (t.ex. hämta kommentarer från varje video i en kanal), använd skrapning av undersidor: skrapa videolistan först och låt sedan Thunderbit besöka varje videosida och extrahera kommentar-data, beskrivningar eller tillgänglighet för transkript.
Hela processen tar under två minuter för ett typiskt kanalresearchjobb. Inga API-nycklar, ingen proxyuppsättning, ingen kod.
Testa Thunderbit på YouTube med 2 klick
2. Apify
Apify är en molnbaserad skrapplattform med förbyggda YouTube-”Actors” — specialiserade scrapers för videor, kommentarer, kanaler, Shorts och transkript. Den är byggd för utvecklare som vill skapa automatiserade datapipelines snarare än göra engångsresearch.
Apifys YouTube-ekosystem innehåller separata Actors för olika uppgifter. En väl underhållen Actor med titeln ”YouTube Scraper — Videos, Comments & Transcripts” accepterar kanaler, spellistor, sökningar och direkta video-URL:er. Den stöder filtrering av Shorts, kommentarskrapning och transkript med tidsstämplar.
Viktiga funktioner:
- Separata Actors för videor, kommentarer, kanaler, Shorts och transkript
- Accepterar söktermer, kanal-URL:er och spelliste-ID:n som indata
- Molnbaserad schemaläggning och webhook-integrationer
- Export till JSON, CSV, Excel eller push till databaser via API
- Actor-nivå för hastighetskontroll och proxyrotation
Anti-ban-strategi: Actor-specifik pacing, Apifys proxyinfrastruktur och YouTubes interna API (Innertube) där det är tillämpligt. Varje Actor implementerar egen retry- och rate-limit-logik.
Prissättning: Den citerade YouTube Scraper-Actorn anger ungefär 15 USD per 1 000 videor, 8 USD per 1 000 kommentarer och 5 USD per transkript. Plattformens planer börjar på 49 USD/månad.
Nackdelar: Användningskostnaderna skalar snabbt för stora jobb. Gränssnittet är utvecklarorienterat — icke-tekniska användare kan uppleva det som komplext. Utdata-scheman varierar mellan Actors, så datarensning behövs ofta. Actor-kvaliteten skiljer sig mellan olika marknadsplatsverktyg.
Bäst för: Utvecklare som bygger automatiserade datapipelines, team som behöver schemalagd extraktion till API:er eller databaser och marknadsföringsops-team som kör återkommande sentimentflöden från kommentarer.
3. Bright Data
Bright Data är en företagsanpassad data-infrastrukturplattform med branschens största residential proxy-nätverk och dedikerade YouTube-scrapers. Om du behöver skrapa YouTube i massiv skala över flera geografier är det här tungt artilleri.
Bright Data erbjuder flera YouTube-scrapers (kanalprofiler, videor, kommentarer) samt färdiga YouTube-dataset att köpa. Deras managed scraping-tjänst innebär att de bygger och underhåller scrapers åt dig.
Viktiga funktioner:
- 150M+ residential-IP:er i 195 länder
- YouTube-specifika scrapers för kanaler, videor och kommentarer
- Full webbläsarrendering och CAPTCHA-lösning
- Geo-targeted skrapning (jämför YouTube-resultat mellan länder)
- Alternativ med managed service (de hanterar underhållet)
- Batchbearbetning upp till 5K URL:er per förfrågan
Anti-ban-strategi: En enorm pool av residential proxies, automatiserad IP-rotation, emulering av webbläsarfingeravtryck och integrerad CAPTCHA-lösning. Det här är den starkaste anti-blockeringsinfrastrukturen på listan.
Prissättning: Gratis provperiod (1K förfrågningar i en vecka), pay-as-you-go på 3,50 USD per 1K poster, Scale-plan på 499 USD/månad med 384 000 poster inkluderade och 2,30 USD per 1K extra.
Nackdelar: Överdrivet för små projekt. Komplex prissättning (bandbredd + förfrågningar + IP:er kan ge en rejäl kostnadsöverraskning om gränser inte sätts). Plattformen kräver mer uppsättning än ett Chrome-tillägg.
Bäst för: Stora företag, byråer som övervakar hundratals kanaler och team som behöver geo-specifik YouTube-data i företagsklass.
4. Octoparse
Octoparse är ett skrivbords- och molnskrapverktyg med ett visuellt point-and-click-gränssnitt. Du bygger YouTube-flöden genom att klicka på element på sidan — ingen kod behövs, men med mer anpassning än ett enkelt tillägg.
Octoparse har förbyggda YouTube-mallar, inklusive en YouTube Comments & Replies Scraper som uppdaterades i april 2026. Den extraherar användarnamn, kommentarstext, likes, publiceringstid och svarstrådar från video-URL:er.
Viktiga funktioner:
- Visuell no-code-byggare — klicka på element för att definiera skraplogik
- Förbyggda YouTube-mallar för kommentarer, sökresultat och videometadata
- Molnschemaläggning med automatisk proxyrotation
- Export till Excel, CSV, JSON och databaskopplingar
- Inbyggd IP-rotation och anti-detektion på molnplaner
Anti-ban-strategi: Molnkörning med inbyggd IP-rotation och anti-detektion. Mallar hanterar oändlig scroll och dynamisk laddning för vanliga YouTube-sidor.
Prissättning: YouTube-kommentarmallen anges till 0,20 USD per 1 000 rader. Plattformens planer börjar runt 75 USD/månad (Standard, faktureras årligen) med molnservrar, schemaläggning och proxyalternativ.
Nackdelar: Komplexa YouTube-sidor (oändlig scroll, lazy-loaded kommentarer, Shorts-flikar) kan kräva justering av väntetider och scrollbeteende. Extraktion av transkript/textning är begränsad jämfört med yt-dlp eller dedikerade transcript-Actors. Inlärningskurva för avancerade flöden.
Bäst för: Marknadsanalytiker och affärsresearchare som föredrar visuella arbetsflöden men behöver mer anpassning än ett Chrome-tillägg.
5. YT-DLP
YT-DLP (finns på GitHub) är ett öppen källkod-verktyg i kommandoraden som extraherar videometadata, undertexter, transkript med mera från YouTube (och 1 000+ andra webbplatser). Det är det schweiziska armékniven för tekniska användare som vill ha maximal kontroll och noll prenumerationskostnad.
För skrapningsliknande arbete kan yt-dlp extrahera metadata utan att ladda ner videofiler med flaggor som --skip-download, --write-info-json, --dump-json och --flat-playlist. Det skiljer mellan auto-genererade och mänskligt skrivna captions — en skillnad som de flesta andra verktyg missar.
Viktiga funktioner:
- Extrahera videometadata (titel, visningar, likes, uppladdningsdatum, beskrivning, taggar) utan att ladda ner video
- Ladda ner kompletta spellistor och kanaler i bulk
- Få tillgång till undertexter/transkript (både auto-genererade och mänskligt skrivna, separat)
- Batchbearbetning med anpassade utdata-mallar
- Cookie-/autentiseringsstöd för sessionsbaserad åtkomst
- Helt gratis, aktivt community för öppen källkod
Anti-ban-strategi: Användarcookies för autentisering (--cookies-from-browser), konfigurerbara throttling-inställningar och community-underhållna extractor-uppdateringar som anpassas till YouTubes förändringar.
Prissättning: Gratis.
Nackdelar: Kräver vana vid kommandoraden. Inget visuellt gränssnitt. Bryts när YouTube ändras (communityn fixar det snabbt, men du behöver fortfarande uppdatera och felsöka). Ingen inbyggd schemaläggning eller export till kalkylblad — du bygger din egen pipeline.
Bäst för: Utvecklare, data scientists och tekniska team som behöver maximal kontroll över metadata- och transkriptextraktion och inte räds terminalkommandon.
6. Phantombuster
Phantombuster är en molnautomationsplattform med YouTube-specifika ”Phantoms” byggda för growth marketing och lead generation snarare än ren datalagring. Det är valet när målet är att hitta kreatörskontakter och bygga outreach-listor.
Phantombusters YouTube Channel Video Extractor hämtar kanalinfo, videolistor och offentliga e-postadresser från kanalbeskrivningar. Deras officiella dokumentation för rate limits säger att YouTube Channel Video Extractor stöder upp till 100 videor per körning och varnar för att ovanlig aktivitet fortfarande kan trigga YouTube-begränsningar.
Viktiga funktioner:
- YouTube-kanalskrapare (prenumerantantal, videolista, kanalinfo, offentliga e-postadresser)
- Extraktion av videor och kommentarer för konkurrentanalys
- Integration med CRM- och outreach-verktyg
- Schemaläggning och automatisering av arbetsflöden
- 14 dagars gratis provperiod, Start-plan från 56 USD/månad (faktureras årligen, 20 h/månad körning)
Anti-ban-strategi: Inbyggda fördröjningar mellan åtgärder, Phantom-webbläsarsessioner och molnkörning med jämn pacing. Designad för säkra arbetsflöden snarare än snabb bulkextraktion.
Prissättning: Start-plan 56 USD/månad (årligen), Grow 128 USD/månad, Scale 352 USD/månad. Kostnaden per 1 000 resultat varierar efter körtid snarare än per-post-prissättning.
Nackdelar: Långsammare än verktyg som är fokuserade på pipelines. Prissättningen baseras på körtimmar och credits, inte en tydlig kostnad per rad. Begränsat stöd för transkript/textning. Gränsen på 100 videor per körning betyder att stora kanaler kräver flera körningar.
Bäst för: Growth marketers som gör influencer-research, säljteam som extraherar kreatörskontakter och byråer som övervakar konkurrenters YouTube-aktivitet.
Alla datatyper du kan extrahera från YouTube (matris verktyg för verktyg)
Olika verktyg stöder olika YouTube-datatyper. Innan du bestämmer dig för ett verktyg behöver du veta exakt vad du får. Här är uppdelningen:
| Datatyp | Thunderbit | Apify | Bright Data | Octoparse | YT-DLP | Phantombuster |
|---|---|---|---|---|---|---|
| Videometadata (titel, visningar, likes, längd, datum) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Kommentarer (i bulk med författare, tidsstämpel, likes) | ✅ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Svar på kommentarer | ⚠️ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Transkript/textning | ⚠️ (beroende på sida) | ✅ | ⚠️ | ⚠️ | ✅ | ❌ |
| Auto- vs. manuella captions (skiljs åt) | ⚠️ | ✅ | ⚠️ | ❌ | ✅ | ❌ |
| Shorts-mått | ✅ | ✅ | ✅ | ⚠️ | ✅ | ⚠️ |
| Kanalanalys (prenumeranter, totala visningar, anslutningsdatum) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Miniatyrbilder/bilder | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Offentliga e-postadresser från kanalbeskrivningar | ✅ (om synliga) | Beror på Actor | ⚠️ | ⚠️ | ❌ | ✅ |
Mest värdefulla data per affärsanvändning:
- Kommentarer → sentimentanalys, invändningsanalys, konkurrentklagomål, målgruppsresearch
- Transkript → LLM/RAG-pipelines, analys av konkurrentbudskap, återanvändning av innehåll
- Kanalmetadata → kreatörssourcing, konkurrentspårning, prospektering av sälj/influencers
- Videometadata → innehållsstrategi, analys av titel/miniatyrbild, uppladdningstakt, SEO-idéer
- Offentliga e-postadresser → outreach till kreatörer (använd ansvarsfullt och i enlighet med regler för e-post och integritet)
Jämförelse av de bästa YouTube-scraperserna: tabell sida vid sida
| Verktyg | Typ | Anti-ban-strategi | Kostnad/1K resultat | Bäst för | Uppsättning | Exportformat | Skala |
|---|---|---|---|---|---|---|---|
| Thunderbit | AI Chrome-tillägg | Webbläsarsession, AI-fältidentifiering | Gratis nivå (6 sidor); betalning kreditbaserad | No-code research av kanal/sök | Mycket enkel | Sheets, Excel, Airtable, Notion, CSV/JSON | Liten–medel, schemalagd |
| Apify | Molnplattform för actors | Actor-specifik pacing, proxies, Innertube | ~5–15 USD/1K (varierar per Actor) | Utvecklarpipelines | Medel | JSON, CSV, Excel, API, webhooks | Medel–hög |
| Bright Data | Företagsscraper/proxy | 150M+ residential-IP:er, CAPTCHA-lösning | 3,50 USD/1K poster (PAYG) | Företagsextraktion | Medel-svår | JSON, NDJSON, CSV, webhooks | Mycket hög |
| Octoparse | Visuell arbetsflödesbyggare | Moln-IP-rotation, anti-detektion | ~0,20 USD/1K rader (mall) + plan | Visuella anpassade arbetsflöden | Medel | Excel, CSV, JSON, DB | Medel |
| YT-DLP | CLI med öppen källkod | Cookies, throttlinginställningar, community-uppdateringar | Gratis | Teknisk metadata- och transkriptextraktion | Svår (icke-teknisk) | JSON, undertexter, anpassad utdata | Beror på användarens uppsättning |
| Phantombuster | Molnbaserad growth automation | Inbyggda fördröjningar, jämna sessioner | Planbaserat (56+ USD/mån); ~100 videor/körning | Kreatörs-leadgenerering, growth workflows | Enkel–medel | CSV/JSON/API/CRM | Medel, jämn pacing |
Kategorivinnare:
- Bäst för icke-tekniska användare: Thunderbit
- Bäst för utvecklarpipelines: Apify
- Bäst för företagsnivå och skala: Bright Data
- Bästa visuella byggare: Octoparse
- Bästa gratis tekniska alternativet: YT-DLP
- Bästa growth marketing-flödet: Phantombuster
Gratis vs. betalda YouTube-scrapers: när gratisverktyg räcker
Gratisverktyg fungerar när uppgiften är snäv, sällsynt och du är bekväm med tekniskt underhåll. Så här vet du när du kan stanna gratis och när du bör investera:
| Scenario | Bästa gratisalternativ | När du bör uppgradera till betalt | Varför |
|---|---|---|---|
| Engångsnedladdning av transkript | YT-DLP | Behöver 500+ videor eller icke-tekniska teammedlemmar | CLI-uppsättning och cookie-hantering skapar friktion |
| Snabb kontroll av konkurrentkanal | Thunderbit gratisnivå (6 sidor) | Regelbunden bevakning eller mer än 10 sidor | Schemalagd skrapning sparar timmar/vecka |
| Bygga LLM-träningsdataset | YT-DLP + egna skript | Behöver filtrering av auto/manuella captions i stor skala | Apifys dedikerade Actors hanterar specialfall |
| Veckobevakning av 10+ kanaler | — | Omedelbart | Schemaläggning och återanvändning av schema sparar verklig tid |
| Marknadsteam som extraherar kreatörsleads | Thunderbit gratis provperiod | 10+ kanaler/vecka | Kreditbaserad skalning är billigare än tiden som går åt till skriptning |
Den ärliga bilden: gratisverktyg som YT-DLP är kraftfulla, men de kräver löpande tekniskt underhåll. YouTubes layoutändringar, cookieutgång, throttlingjusteringar och utdataformatering kräver alla manuellt arbete. Ett skript som går sönder varannan vecka kan kosta mer i ingenjörstid än en betald scraperprenumeration.
AI-drivna verktyg som Thunderbit läser sidor på nytt varje gång och anpassar sig automatiskt till layoutförändringar. Den där dolda underhållskostnaden är det som motiverar betalda verktyg för de flesta affärsteam.
Hur skrapad YouTube-data faktiskt ser ut (verkliga exempel på utdata)
En av de största luckorna i scraper-recensioner är att ingen visar vad du faktiskt får. Här är realistiska exempel på skrapad YouTube-data:
Exempel 1: Kanalmetadata
| channel_name | handle | subscribers | total_views | video_count | join_date | description_snippet | public_email |
|---|---|---|---|---|---|---|---|
| Example SaaS Tutorials | @examplesaas | 184K | 22.4M | 412 | 2018-06-14 | Veckovisa produktgenomgångar och arbetsflödesguider | partnerships@example.com |
| Data Ops Weekly | @dataopsweekly | 92K | 8.7M | 215 | 2020-01-03 | Demos av analys, automation och AI-arbetsflöden | Ej synlig |
Exempel 2: Export av kommentarer
| video_url | timestamp | author | comment_text | likes | reply_count |
|---|---|---|---|---|---|
| youtube.com/watch?v=abc123 | 2026-04-18 | @workflowfan | Det här besvarade prissättningsfrågan bättre än leverantörssidan. | 28 | 3 |
| youtube.com/watch?v=abc123 | 2026-04-18 | @opslead | Skulle gärna vilja se en uppföljning som jämför detta med Apify. | 11 | 0 |
| youtube.com/watch?v=abc123 | 2026-04-19 | @examplesaas | Bra poäng, vi testar det här härnäst. | 4 | 0 |
Exempel 3: Extraktion av transkript
00:00:00.000 - 00:00:04.200 Idag jämför vi sex YouTube-skrapflöden för marknadsförare.
00:00:04.200 - 00:00:09.800 Den största skillnaden är om du behöver metadata, kommentarer eller transkript.
00:00:09.800 - 00:00:15.300 För icke-tekniska användare är en webbläsarbaserad scraper oftast enklare att underhålla.
Vanliga rensningsproblem att räkna med:
- Visningsantal kan innehålla lokaliserade suffix (K, M) eller icke-engelska etiketter
- Uppladdningsdatum är ibland relativa (”för 3 år sedan”) i stället för ISO-datum
- Kommentarer kan sorteras efter Top i stället för Ny som standard
- Dolda svar och lazy-loaded kommentarer kräver scrollning eller paginering
- Offentliga e-postfält kan vara dolda bakom interaktion eller kontobegränsningar
- Transkript kan saknas, vara auto-genererade eller på ett oväntat språk
För Thunderbit specifikt är arbetsflödet: AI Suggest Fields → Scrape → Export to Google Sheets. AI:n hanterar fältidentifieringen, så du behöver inte manuellt definiera hur ”visningar” eller ”uppladdningsdatum” ser ut på sidan.
Är det lagligt att skrapa YouTube 2026?
Den korta versionen: att skrapa offentligt tillgänglig YouTube-data är generellt lägre risk än att komma åt privat data, men det är inte fritt fram att göra vad som helst.
YouTubes Användarvillkor förbjuder uttryckligen automatiserad åtkomst, med undantag för offentliga sökmotorer som följer robots.txt eller har YouTubes skriftliga förhandsgodkännande. Tillämpningen mot legitim affärsresearch är dock sällsynt — YouTube riktar sig främst mot storskaligt missbruk, innehållspiratkopiering och integritetsbrott.
Amerikansk rättspraxis ger viss vägledning. Ninth Circuits beslut i hiQ v. LinkedIn fann allvarliga frågor om huruvida skrapning av offentligt tillgänglig data bryter mot CFAA. EFF har argumenterat för att skrapning av offentliga webbplatser inte är ett brott. Men plattformarnas användarvillkor, upphovsrätt, integritet och anti-spamlagar gäller fortfarande.
Praktiska riktlinjer:
- Samla bara in offentlig data som ditt konto får se
- Skrapa inte personuppgifter i onödan i stor skala
- Gå inte runt åtkomstkontroller eller betalväggar
- Respektera upphovsrätt — återpublicera inte transkript eller videoinnehåll i sin helhet
- Rate-limita jobb och undvik att överbelasta YouTubes servrar
- För outreach, följ CAN-SPAM, GDPR och lokala regler
- Rådgör med juridisk expertis för användningsfall med hög risk
Verktygen på den här listan har alla rate limiting och respektfull pacing inbyggt från början. Det är inte bara god etik — det är det som gör att din skrapning fungerar långsiktigt.
Vilken YouTube-scraper ska du välja?
Här är den snabba beslutsguiden:
- Thunderbit → Bäst för icke-tekniska användare som vill ha snabb, ban-resistent YouTube-skrapning till kalkylblad. Börja här om du är marknadsförare, säljare eller innehållsstrateg.
- Apify → Bäst för utvecklare som bygger automatiserade pipelines med schemalagda jobb, webhooks och API-leverans.
- Bright Data → Bäst för extraktion i företagsklass över flera geografier med hanterad anti-blockeringsinfrastruktur.
- Octoparse → Bäst för analytiker som vill bygga visuella arbetsflöden med mer anpassning än ett Chrome-tillägg.
- YT-DLP → Bästa gratisalternativet för tekniska användare som behöver maximal kontroll över metadata och transkript.
- Phantombuster → Bäst för growth marketers som arbetar med kreatörssourcing och leadgenerering baserad på YouTube.
Nyckeln till att inte bli bannad är inte ett hemligt trick — det handlar om att välja ett verktyg med smart inbyggd detekteringsundvikning. Webbläsarbaserad sessionsskrapning, proxyrotation, pacing och schemalagda små batcher minskar alla risken. Att brute-forcea tusentals förfrågningar från en enda moln-IP är det som får dig blockerad.
Om du vill se hur modern YouTube-skrapning ser ut utan kod, prova Thunderbit:s gratisnivå. Två klick till strukturerad data. Och om dina behov är mer tekniska eller på företagsnivå har de andra verktygen på listan det du behöver. För mer om webbskrapningsmetoder, kolla in våra guider om bästa automatiserade webbskrapningsverktygen och skrapa data från webbplatser till Excel. Du kan också se tutorials på Thunderbits YouTube-kanal.
Prova Thunderbit för YouTube-skrapning Get Started Free
Vanliga frågor
Vilken data kan du skrapa från en YouTube-kanal?
Offentliga data som går att extrahera inkluderar videotitlar, URL:er, miniatyrbilder, visningar, likes (där de är synliga), uppladdningsdatum, beskrivningar, längd, kommentarer, svar, kommentatorers namn/handles, likes på kommentarer, transkript/textning (auto-genererade och mänskligt skrivna), Shorts-indikatorer, kanalnamn, handle, prenumerantantal, antal videor, totala visningar, beskrivning, länkar och offentliga e-postadresser om de är synliga på kanalsidan.
Hur många YouTube-videor kan jag skrapa per dag utan att bli bannad?
Det finns inget universellt antal. Webbläsarbaserade verktyg som Thunderbit innebär lägre risk för användarliknande arbetsflöden eftersom de arbetar inne i en riktig session. Phantombusters YouTube Channel Video Extractor stöder upp till 100 videor per körning. Molnplattformar med proxyrotation kan hantera tusentals med rätt pacing. Råa skript från molnservrar utan rate limiting blir snabbt blockerade. Det säkraste är mindre, schemalagda batcher i stället för en enda massiv körning.
Kan jag skrapa YouTube-kommentarer för sentimentanalys?
Ja. Thunderbit, Apify, Bright Data och Octoparse stöder alla bulkextraktion av kommentarer med författare, tidsstämpel, likes och antal svar. Exportera till Google Sheets eller CSV för analys. Apifys YouTube-actor stöder uttryckligen konfigurerbart maxantal kommentarer per video för det här användningsfallet.
Finns det en gratis YouTube-scraper som faktiskt fungerar 2026?
YT-DLP är det bästa gratisalternativet för tekniska användare — särskilt för metadata och transkript. Thunderbit erbjuder en gratis nivå för icke-tekniska användare (6 sidor, med en trial-boost till 10) som exporterar direkt till Google Sheets. Båda fungerar, men YT-DLP kräver kommandoradskunskap medan Thunderbit bara kräver en webbläsare.
Hur undviker YouTube-scrapers att bli blockerade?
Olika verktyg använder olika metoder: webbläsarbaserad sessionsskrapning (Thunderbit) använder användarens autentiserade webbläsarkontext; residential proxyrotation (Bright Data, Apify) fördelar förfrågningar över miljontals IP:er; cookieautentisering (YT-DLP) behåller sessionsförtroendet; inbyggda fördröjningar och pacing (Phantombuster) undviker beteendedetektion. Den mest tillförlitliga metoden kombinerar verklig webbläsarkontext med konservativ pacing och schemalagda mindre jobb.
Läs mer




