

O web scraping virou um trunfo estratégico para times modernos de negócios — seja em vendas, operações ou marketing, conseguir coletar dados da internet rapidinho pode ser o que separa o sucesso do fracasso no seu próximo projeto. Com a onda de decisões baseadas em dados, as empresas estão atrás de ferramentas que sejam não só rápidas, mas também confiáveis e que aguentem o tranco. É aí que o Rust entra em cena: uma linguagem de programação moderna que está conquistando espaço no universo do web scraping, principalmente para equipes que não abrem mão de desempenho e segurança.
E não é só papo — o Rust foi eleito a “linguagem de programação mais amada” na Stack Overflow Developer Survey por vários anos seguidos, e cada vez mais aparece em projetos de back-end e engenharia de dados. Mas, afinal, o que significa “fazer web scraping com Rust” para quem está no mundo dos negócios? E como ele se compara a soluções no-code como o Thunderbit, pensadas para quem não é da área técnica? Bora explicar tudo de um jeito simples — sem precisar ser programador.
O que é Web Scraping com Rust? O Básico Sem Mistério
No fim das contas, web scraping é o processo de puxar dados automaticamente de sites. Imagina ter um assistente digital que visita centenas (ou milhares) de páginas, copia as informações que você precisa — tipo preços, contatos ou avaliações — e entrega tudo organizadinho pra você. Isso economiza um tempo danado pra quem precisa de dados atualizados pra gerar leads, pesquisar o mercado, monitorar preços e por aí vai.
Rust é uma linguagem de programação de sistemas famosa pelo desempenho alto, segurança de memória e confiabilidade. Diferente de linguagens mais antigas, que podem dar bug ou travar, o Rust foi feito pra pegar erros antes mesmo do código rodar. Pra web scraping, isso significa ferramentas super rápidas e menos sujeitas a travar ou vazar memória — uma baita vantagem quando o assunto é extrair dados em grande escala.
E não são só os devs que ganham: pra equipes de negócios, scraping mais rápido e seguro significa dados mais frescos, menos erro e insights mais certeiros.
Por que Apostar no Rust para Web Scraping? Os Benefícios Pra Quem Toca Negócio
Então, por que cada vez mais equipes estão de olho no Rust pra web scraping, mesmo com Python e JavaScript sendo os queridinhos há anos? Olha só os diferenciais:
- Desempenho lá em cima: O Rust é compilado direto pra máquina, então é muito mais rápido que linguagens interpretadas como Python ou JavaScript. Pra scraping em grande escala — milhões de páginas — essa velocidade faz toda a diferença.
- Segurança de memória: O jeito que o Rust lida com memória (sem garbage collector, com regras rígidas) reduz bugs e travamentos. Suas tarefas de scraping têm menos chance de dar ruim no meio do caminho, poupando tempo e dor de cabeça.
- Confiabilidade: O compilador do Rust exige checagem de tipos e tratamento de erros bem rigorosos, pegando vários problemas antes de rodar. Isso deixa o scraping mais estável e previsível.
- Concorrência: O Rust facilita criar código que faz várias coisas ao mesmo tempo (já já falo mais disso), essencial pra raspar muitos sites em paralelo.
E como isso se compara ao Python ou JavaScript? Apesar dessas linguagens serem mais fáceis pra começar, podem travar ou ficar lentas quando o volume é grande. O Rust permite coletar mais dados, mais rápido e com menos dor de cabeça — dando vantagem competitiva pro seu negócio.
O Poder do Assíncrono no Rust: Web Scraping em Alta Escala
Aqui está um dos grandes diferenciais do Rust: programação assíncrona. Em resumo, código assíncrono permite que seu raspador colete dados de vários sites ao mesmo tempo, sem precisar esperar um terminar pra começar o outro. Isso é fundamental pra quem precisa montar grandes bases de dados rapidinho.
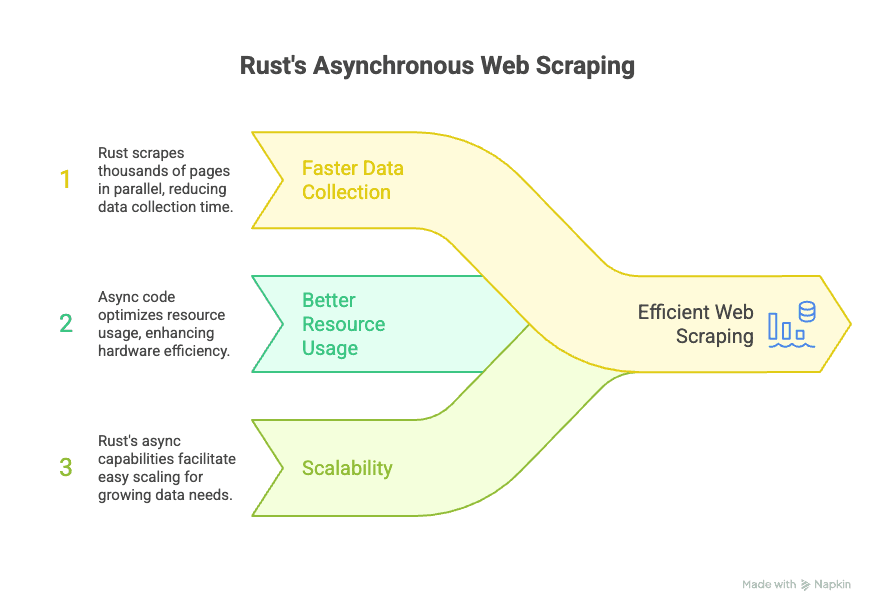
O ecossistema assíncrono do Rust tem bibliotecas como Tokio e async-std, que deixam seu raspador lidar com milhares de requisições ao mesmo tempo sem travar tudo. Pra empresas, isso significa:
- Coleta de dados mais rápida: Raspe milhares de páginas em paralelo, cortando o tempo pra montar seu banco de dados.
- Uso inteligente dos recursos: Código assíncrono é mais eficiente, então dá pra fazer mais com menos infraestrutura.
- Escalabilidade: Se a demanda por dados crescer, o Rust facilita escalar sem ter que refazer tudo do zero.
Na prática, sua equipe pode reagir rápido a mudanças de mercado, monitorar concorrentes ou gerar leads em tempo real — sem esperar horas (ou dias) pra baixar os dados.
Como Funciona o Web Scraping com Rust? Passo a Passo Simplificado
Curioso pra saber como é o fluxo de trabalho típico de web scraping com Rust? Olha só um resumo sem complicação:
- Configuração: Defina quais dados você quer puxar e de quais sites.
- Coleta dos dados: Use bibliotecas como Reqwest (pra requisições HTTP) pra baixar as páginas.
- Análise do conteúdo: Use Scraper ou Select pra extrair informações específicas (tipo nome de produto, preço, e-mail) do HTML.
- Paginação/Subpáginas: Implemente lógica pra navegar por várias páginas ou seguir links pra subpáginas (mais detalhes abaixo).
- Exportação dos dados: Salve os dados extraídos em CSV, Excel ou direto num banco de dados — pronto pra equipe usar.
Cada biblioteca tem sua função: Reqwest faz a “coleta”, Scraper/Select cuidam da “análise”, e o Rust ou bibliotecas de terceiros organizam e exportam os resultados.
Lidando com Sites Mais Complicados: Paginação e Subpáginas no Rust
Muitas tarefas de scraping vão além de puxar dados de uma página só. Às vezes você precisa:
- Raspar todos os produtos de um catálogo com várias páginas
- Coletar avaliações espalhadas por subpáginas
- Buscar contatos em diretórios aninhados
O Rust manda bem nesses desafios. Seu sistema de tipos e tratamento de erros facilitam criar código que:
- Detecta e segue botões “Próximo” ou links de paginação automaticamente
- Visita subpáginas (tipo detalhes de produtos ou perfis de autores) e integra esses dados ao conjunto principal
- Lida com imprevistos (como páginas ausentes ou links quebrados) sem travar o raspador
Por exemplo, um raspador em Rust pode começar numa listagem principal, seguir cada link de paginação e visitar todas as páginas de detalhes dos produtos — puxando preço, descrição e avaliações. O resultado? Um banco de dados completo e atualizado, pronto pra análise.
Thunderbit vs. Rust: O No-Code Que Facilita a Vida do Time de Negócios
Agora, o ponto chave: nem todo mundo tem tempo (ou conhecimento técnico) pra criar um raspador em Rust do zero. É aí que o Thunderbit faz toda a diferença.
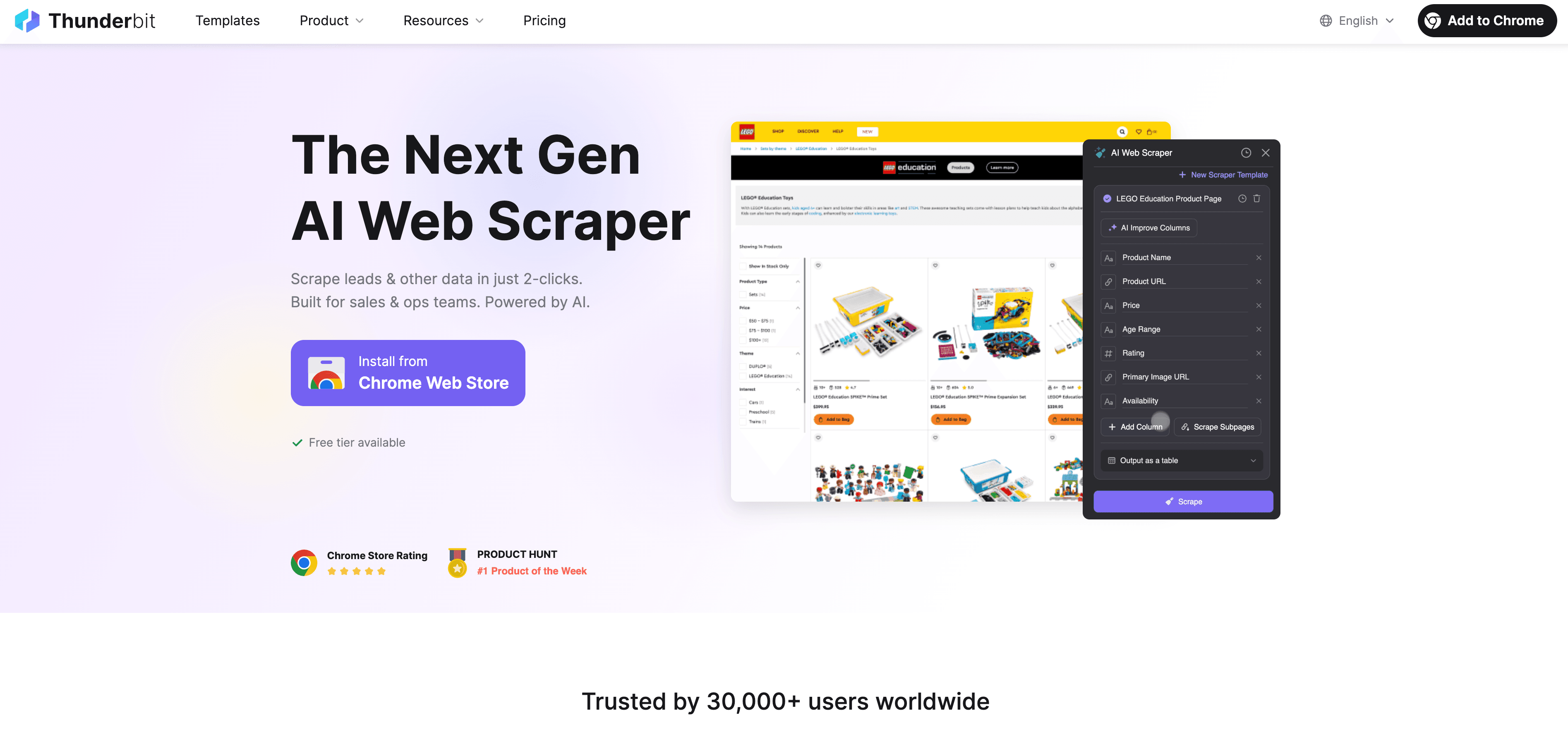
O Thunderbit é um Raspador Web IA sem código, feito pra quem é de negócios. Em vez de programar, é só:
- Abrir a Extensão do Thunderbit para Chrome
- Entrar no site que você quer raspar
- Clicar em “AI Sugere Campos” e deixar a IA do Thunderbit mostrar quais dados extrair
- Clicar em “Raspar” e exportar os resultados direto pro Excel, Google Sheets, Airtable ou Notion
Sem template, sem código, sem dor de cabeça. O Thunderbit ainda resolve paginação e subpáginas sozinho — igual um raspador em Rust, mas com uma interface super fácil.
Experimente o Raspador Web IA Thunderbit Gratuitamente
Quando Usar Thunderbit ou Rust? Qual Ferramenta Escolher
Qual caminho faz mais sentido pra sua equipe? Dá uma olhada nesse resumo:
| Cenário | Thunderbit | Rust |
|---|---|---|
| Geração rápida de leads para vendas | ✅ Mais fácil e rápido | Possível, mas exagerado |
| Monitoramento de preços de concorrentes (ecommerce) | ✅ Sem código, agendado | ✅ Para integrações personalizadas |
| Scraping de fluxos complexos e customizados | Possível, mas limitado | ✅ Controle total, altamente personalizável |
| Grandes pipelines de dados integrados | Possível (via API) | ✅ Melhor para integração profunda |
| Usuários não técnicos (vendas, operações, marketing) | ✅ Feito para você | ❌ Exige conhecimento em programação |
| Prototipagem rápida ou tarefas pontuais | ✅ Configuração em 2 cliques | Possível, mas mais demorado |
Resumindo: Thunderbit é perfeito pra quem quer extrair dados rápido e sem complicação técnica. Rust é a escolha pra quem precisa de controle total, lógica personalizada ou scraping em grande escala.
Exemplo Prático: Web Scraping com Rust na Vida Real
Vamos ilustrar com um caso real. Imagina que você é analista de mercado e precisa coletar dados de todos os notebooks listados num grande site de ecommerce. O site tem paginação (várias páginas de produtos) e cada produto tem uma página de detalhes com especificações e avaliações.
Com Rust, você faria assim:
- Usaria o Reqwest pra baixar a página principal de listagem
- Analisaria o HTML com o Scraper pra extrair os links dos produtos
- Detectaria e seguiria o botão “Próximo” pra raspar todas as páginas
- Pra cada produto, visitaria a página de detalhes e puxaria especificações/avaliações
- Trataria erros (tipo páginas ausentes) de forma robusta, tentando de novo se precisar
- Exportaria tudo pra CSV ou pra sua plataforma de análise
O valor pro negócio? Você ganha uma visão completa e atualizada do mercado — base pra decisões mais inteligentes de preço, estoque e marketing.
Principais Desafios e Cuidados ao Fazer Web Scraping com Rust
Mesmo com todas as vantagens do Rust, web scraping tem seus perrengues. Veja alguns desafios comuns (e como o Rust ajuda):
- Mudanças no site: Se o layout do site mudar, seu raspador pode parar de funcionar. O Rust ajuda a identificar esses problemas cedo, mas vai ser preciso ajustar o código.
- Bloqueios anti-bot: Muitos sites usam CAPTCHAs ou limitam o acesso. A velocidade do Rust pode ajudar a evitar bloqueios, mas talvez seja necessário usar proxies ou atrasos.
- Formatação dos dados: Nem sempre os dados vêm limpos — as ferramentas de parsing do Rust facilitam lidar com HTML bagunçado ou inconsistente.
- Manutenção: Raspadores feitos sob medida exigem manutenção constante. Pra equipes de negócios, isso significa trabalhar junto com o time técnico ou considerar ferramentas no-code como o Thunderbit pra tarefas do dia a dia.
O que é Data Scraping e Como Fazer em 2025 Get Started Free
Dica: Seja usando Rust ou Thunderbit, sempre respeite os termos de uso dos sites e as leis de privacidade ao coletar dados.
Conclusão: Extraindo Valor de Negócio com Web Scraping em Rust (e Além)
O web scraping virou peça-chave pra empresas que querem se destacar num mundo movido a dados. Rust entrega desempenho, segurança e confiabilidade de sobra pra quem precisa de soluções personalizadas e em grande escala — principalmente quando velocidade e estabilidade são essenciais. Mas, pra maioria dos times de negócios, a barreira técnica ainda pesa.
É aí que o Thunderbit brilha: ele democratiza o web scraping, trazendo uma interface no-code com IA que resolve até tarefas complexas como paginação e subpáginas. Seja pra montar listas de leads, monitorar preços ou coletar inteligência de mercado, o Thunderbit permite obter os dados que você precisa — rapidinho.
Resumo dos pontos principais:
- Rust é poderoso pra scraping personalizado e em larga escala — ideal pra equipes técnicas.
- Thunderbit deixa o web scraping acessível pra qualquer um, sem precisar programar.
- Escolha a ferramenta certa: Rust pra customização profunda, Thunderbit pra agilidade e simplicidade.
Raspe dados de qualquer site usando IA Get Started Free
Quer testar web scraping no seu negócio? Baixe o Thunderbit e veja como é fácil extrair dados. Ou, se busca uma solução sob medida, explore o ecossistema do Rust pra scraping de alta performance.
Experimente o Raspador Web IA Get Started Free
Perguntas Frequentes
1. O que é web scraping com Rust e como ele se diferencia de outras linguagens?
Web scraping com Rust é usar a linguagem Rust pra automatizar a extração de dados de sites. O Rust se destaca pela velocidade, segurança de memória e confiabilidade em relação a linguagens como Python ou JavaScript, sendo ideal pra scraping em grande escala ou tarefas críticas.
2. Rust é indicado pra quem não é técnico?
O Rust é super potente, mas exige saber programar. Pra quem não é da área, ferramentas como o Thunderbit oferecem uma solução no-code, com IA, deixando a extração de dados acessível pra todo mundo.
3. Como o Rust lida com tarefas complexas como paginação ou subpáginas?
O sistema de tipos e as bibliotecas assíncronas do Rust facilitam criar código que navega automaticamente por listagens paginadas, segue links de subpáginas e trata erros — resultando em conjuntos de dados mais completos e confiáveis.
4. Quando devo usar Thunderbit em vez de criar um raspador personalizado em Rust?
Use o Thunderbit quando quiser extrair dados rápido e fácil, sem programar — perfeito pra vendas, marketing e operações. Escolha Rust pra fluxos altamente customizados, em larga escala ou que exijam integração profunda e conhecimento técnico.
5. Quais os principais desafios do web scraping com Rust e como lidar com eles?
Os desafios mais comuns são mudanças nos sites, bloqueios anti-bot e manutenção constante. Os recursos de segurança do Rust ajudam a identificar erros cedo, mas vai ser preciso atualizar o código conforme os sites mudam. Pra tarefas do dia a dia, uma ferramenta no-code como o Thunderbit pode economizar tempo e evitar dor de cabeça.
Saiba mais:




