Deixa eu te contar como era o começo da minha vida como gerente de produto: “conseguir os dados” era basicamente convencer um programador com um café ou passar horas copiando e colando tabelas no Excel. (Até hoje tenho pesadelos com aquelas sessões intermináveis de Ctrl+C, Ctrl+V.) Hoje, estamos rodeados de dados por todos os lados — tanto que, até 2036, o mercado de softwares de raspagem web deve chegar a . Mas tem um porém: a maior parte dessas informações está presa atrás de telas, espalhada em sites, PDFs e apps que não facilitam em nada a exportação.
É aí que entra o screen scraping — uma técnica antiga que ganhou uma cara nova com IA. Seja você de vendas, e-commerce, mercado imobiliário ou só um apaixonado por planilhas (sem julgamentos!), entender como funciona o screen scraping moderno — e como ferramentas com IA como o democratizam o acesso — pode mudar seu dia a dia. Bora entender melhor.
O que é Screen Scraping? Como Funciona a Extração de Dados na Prática
Screen scraping, no fundo, é como olhar para a tela e anotar o que aparece — só que, em vez de fazer isso na mão, você coloca um robô para trabalhar por você. É extrair dados da interface visual de um app, site ou até PDF, transformando essas informações em algo que você pode usar em outros lugares ().
Pensa assim: se você já copiou uma tabela de um site para o Excel, já fez screen scraping manualmente. A diferença é que, com automação, você poupa o desgaste das teclas Ctrl e V. O software “lê” o que está na tela — às vezes usando visão computacional ou OCR, caso o texto não seja selecionável.
Screen scraping costuma ser confundido com web scraping e data scraping. Olha só as diferenças de forma simples:
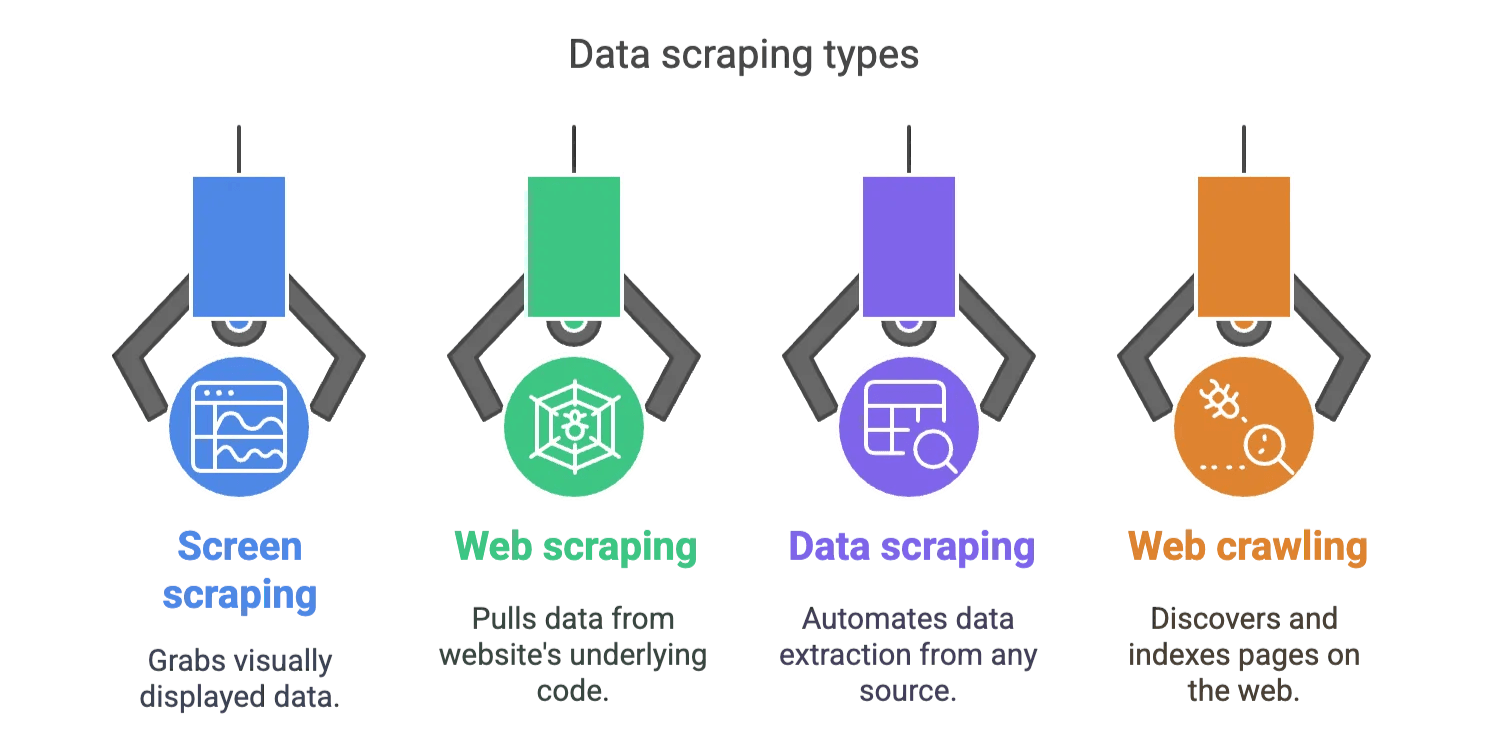
- Screen scraping: Pega o que está visível na tela.
- Web scraping: Extrai dados do código fonte (HTML, JSON, etc.) de um site.
- Data scraping: É um termo mais amplo para automação da extração de dados de qualquer fonte (web, apps, arquivos, etc.).
- Web crawling: Descobre e indexa páginas, sem necessariamente extrair dados delas.
Ou seja, se você precisa acessar informações de um sistema antigo, PDF bloqueado ou site que dificulta a exportação, o screen scraping é seu melhor amigo.
Screen Scraping vs. Web Scraping vs. Data Scraping: Qual a Diferença?
Esses nomes são usados como se fossem a mesma coisa, mas não são. Dá uma olhada nessa tabela para não se perder:
| Técnica | O que faz | Onde funciona | Como funciona | Principais usos |
|---|---|---|---|---|
| Screen Scraping | Extrai dados do que está na tela | Apps, sistemas antigos, PDFs, sites | Lê pixels, usa OCR ou automação de interface | Migração de dados, RPA, sistemas legados |
| Web Scraping | Extrai dados do código da página (HTML/DOM) | Sites | Analisa HTML, faz requisições HTTP, navega pelo DOM | Monitoramento de preços, geração de leads, pesquisas |
| Data Scraping | Automatiza extração de qualquer fonte de dados | Web, arquivos, bancos de dados, logs, etc. | Qualquer método automatizado (scraping, parsing, queries) | Integração de dados, análises |
| Web Crawling | Descobre e indexa páginas web | Internet | Segue links, constrói listas de URLs | Motores de busca, mapeamento de sites |
Por que tanta confusão? Porque essas técnicas muitas vezes se complementam. Por exemplo, um web crawler encontra todas as páginas de um site, depois um raspador web coleta os dados, e se as informações só aparecem visualmente (não no código), entra o screen scraping.
Por que Screen Scraping é Importante para Empresas: Exemplos do Mundo Real
Vamos ao que interessa: por que as empresas se preocupam com screen scraping, web scraping e data scraping? Porque informação é poder — e quase nunca ela vem pronta para uso.
Veja alguns exemplos práticos:
| Equipe | Uso | Benefício | Exemplo de ROI |
|---|---|---|---|
| Vendas | Geração de leads em diretórios | Mais leads, menos trabalho manual | 5+ horas/semana economizadas por representante (usuários Thunderbit) |
| E-commerce | Monitoramento de preços da concorrência | Precificação dinâmica, margens maiores | 4% de aumento nas vendas (John Lewis) |
| Imobiliário | Agregação de anúncios de imóveis | Análise de mercado mais ágil | Mais negócios, melhores decisões de investimento |
| Marketing | Raspagem de avaliações/redes sociais | Análise de sentimento, ROI de campanhas | Segmentação aprimorada, respostas mais rápidas |
| Operações | Extração de dados de portais de fornecedores | Relatórios automáticos, menos erros | Menos digitação manual, menos falhas |
E isso é só o começo. Já vi equipes usando scraping para migrar conteúdos, monitorar compliance e até criar dashboards internos de dar inveja a qualquer cientista de dados.
Ferramentas Tradicionais de Screen Scraping: Como Funcionam e Onde Travavam
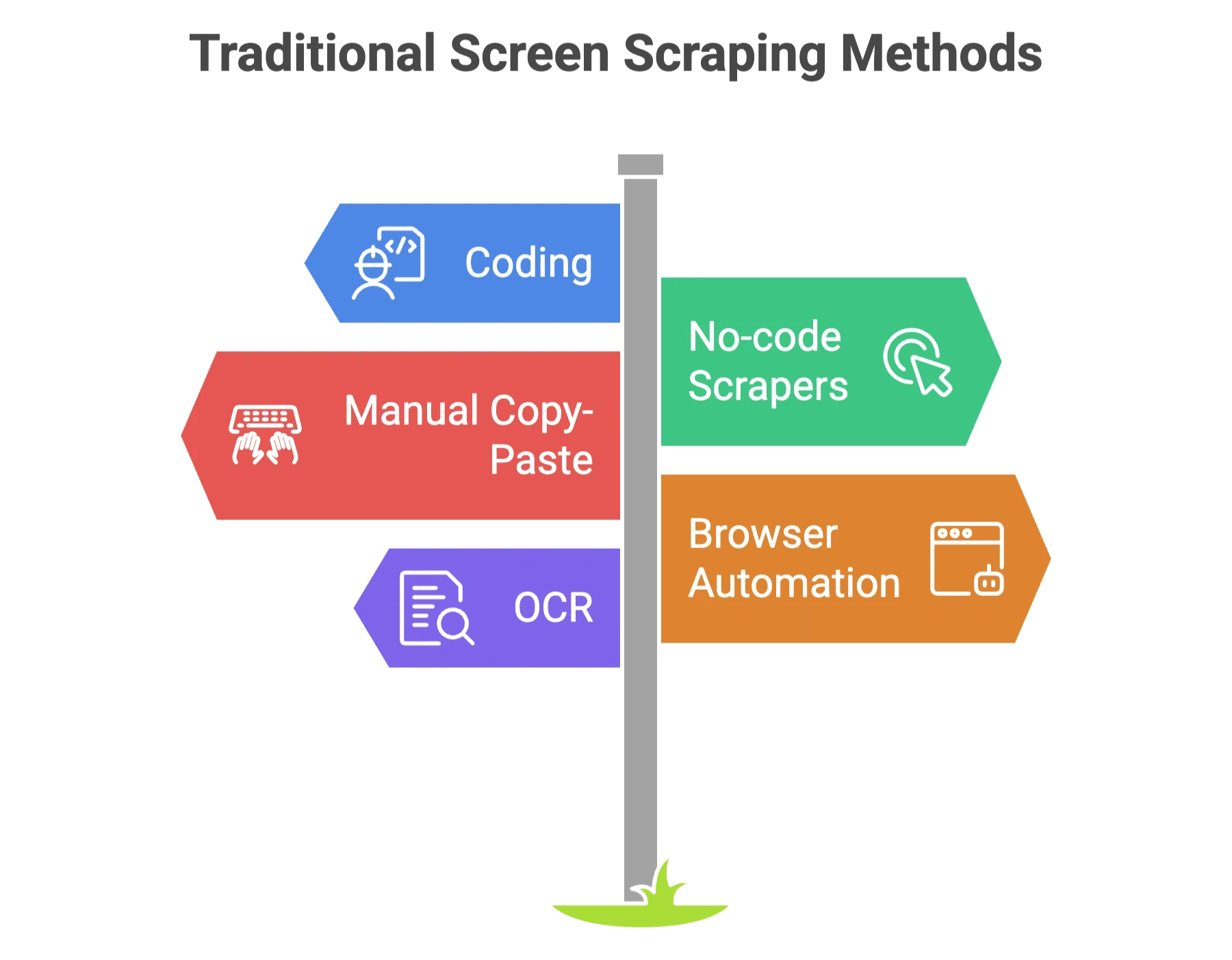
Antes da IA, screen scraping era tipo montar móvel sem manual. Você tinha basicamente duas opções:
- Codar na unha: Escrever scripts próprios (Python, JavaScript, etc.) para buscar e processar dados. Ótimo para quem curte virar a noite debugando.
- Scrapers no-code: Ferramentas de apontar e clicar, onde você seleciona manualmente o que extrair. Mais fácil, mas ainda trabalhoso — e se o site mudar, seu setup pode quebrar rapidinho.
Outros métodos clássicos:
- Copia e cola manual: Cansativo, sujeito a erros e nada motivador.
- Automação de navegador (Selenium, Playwright): Simula um usuário real, mas exige conhecimento técnico.
- OCR: Para dados presos em imagens ou PDFs escaneados.
Principais desafios:
- Configuração lenta e técnica.
- Manutenção complicada — qualquer mudança no site pode quebrar tudo.
- Transformação de dados limitada — você recebe dados crus e tem que tratar depois.
- Usuários não técnicos ficam de fora.
Se você já gastou mais tempo consertando um raspador do que usando os dados, sabe bem do que estou falando.
A Revolução da IA no Screen Scraping: O Que Mudou de Verdade?
Agora vem a parte boa. O screen scraping com IA mudou o jogo. Em vez de brigar com seletores ou códigos frágeis, você deixa um agente de IA fazer o trabalho pesado.
Como funciona na prática?
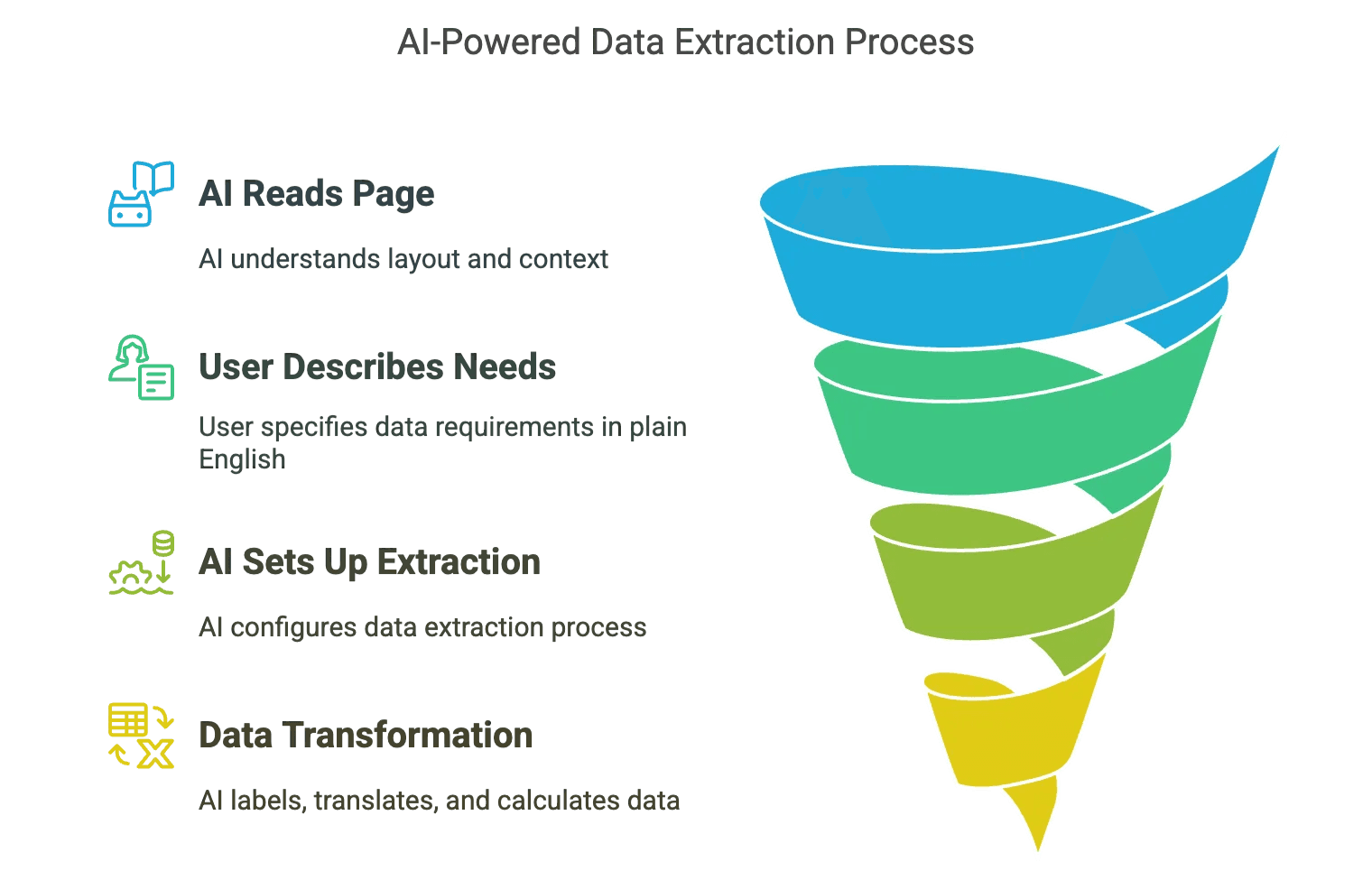
- A IA “lê” a página como um humano: Analisa o layout, entende o contexto e identifica o que é importante — mesmo que o site mude.
- Você só precisa dizer o que quer em português claro: “Quero todos os nomes de produtos, preços e imagens”, e a IA configura tudo.
- Transformação de dados em tempo real: Rotulagem, tradução, cálculos — a IA faz tudo enquanto raspa os dados.
Ou seja:
- Acabou a configuração manual.
- Acabou a manutenção constante.
- Qualquer pessoa pode usar — não só quem entende de código.
Por exemplo, com o , você pode raspar qualquer site, não importa o layout, porque o agente de IA se adapta sozinho. Precisa transformar ou rotular dados durante a extração? O Thunderbit resolve. E o melhor: é realmente fácil de usar.
Thunderbit: O Raspador Web IA Mais Fácil para Todo Mundo
Hora do merchan — mas é por isso que criamos o :
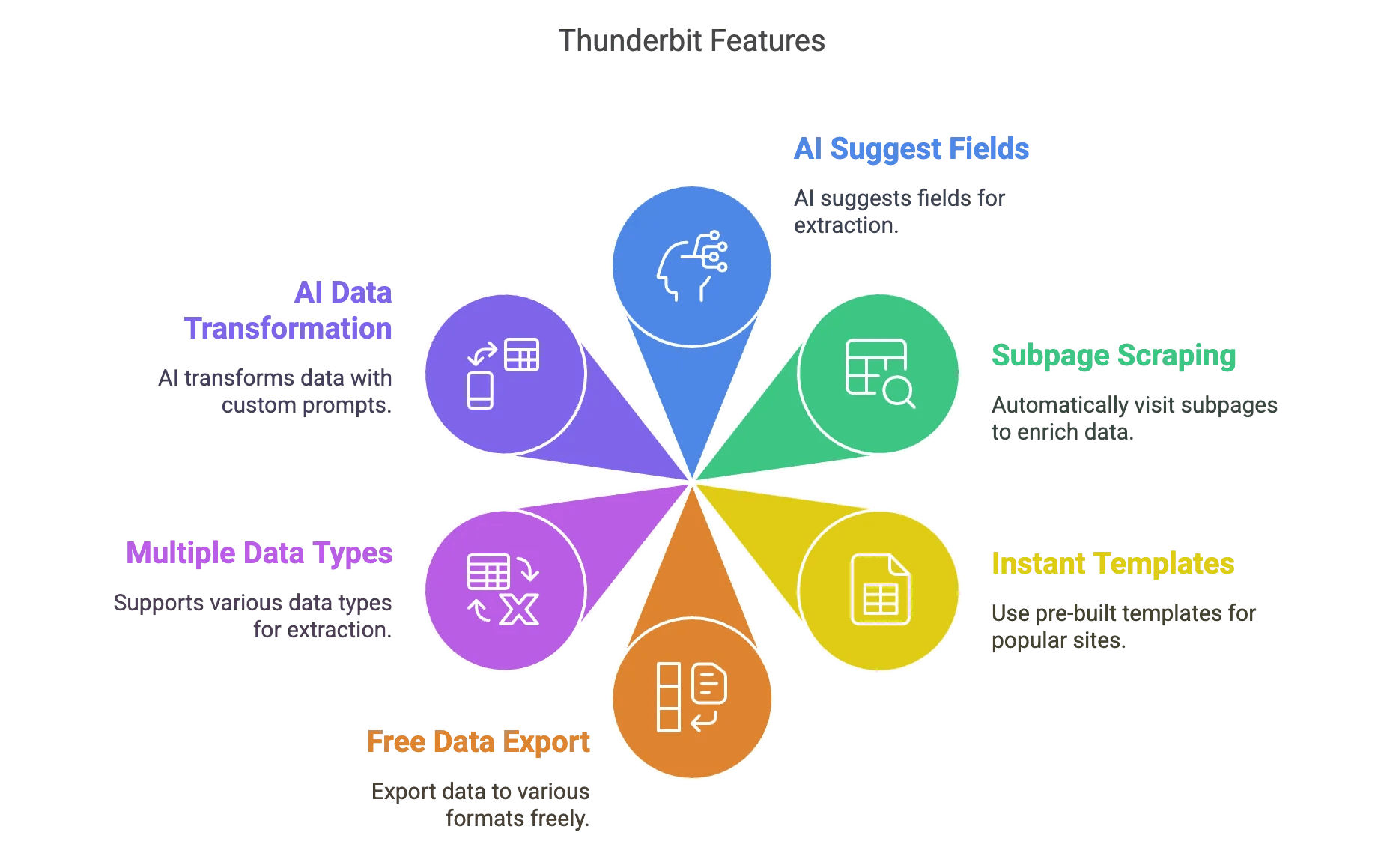
- Sugestão de Campos com IA: Um clique e a IA do Thunderbit analisa a página e sugere os melhores campos para extrair. Sem chute, sem ajuste manual.
- Raspagem de Subpáginas: Precisa de mais detalhes? O Thunderbit pode visitar automaticamente cada subpágina (tipo páginas de produtos ou perfis) e enriquecer seu conjunto de dados.
- Modelos Prontos: Para sites populares (Amazon, Zillow, Instagram, Shopify, etc.), use templates prontos e pegue os dados em um clique.
- Exportação Gratuita de Dados: Exporte para Excel, Google Sheets, Airtable, Notion, CSV ou JSON — sem pagar nada a mais.
- Vários Tipos de Dados: Texto, números, datas, URLs, e-mails, telefones, imagens — tudo junto.
- Transformação de Dados com IA: Adicione prompts personalizados para rotular, formatar ou até traduzir dados durante a raspagem.
E tudo isso numa que é realmente gostosa de usar. (Na medida do possível para extração de dados!)
Como Funciona o Screen Scraping com IA: Passo a Passo
Olha como é simples usar o Thunderbit para screen scraping com IA:
- Instale a extensão Thunderbit no Chrome.
- Baixe na .
- Abra o site ou PDF que quer raspar.
- O Thunderbit funciona com sites, PDFs e até imagens.
- Clique em “Sugestão de Campos com IA”.
- A IA analisa a página e sugere colunas (ex: Nome, Preço, E-mail, Imagem).
- Revise e ajuste os campos se quiser.
- Adicione ou renomeie colunas, defina tipos de dados ou insira prompts personalizados para rotulagem ou tradução.
- Clique em “Raspar”.
- O Thunderbit extrai os dados e mostra tudo em uma tabela organizada.
- (Opcional) Raspe Subpáginas.
- Se quiser mais detalhes, deixe o Thunderbit visitar cada link e trazer informações extras.
- Exporte seus dados.
- Baixe como CSV, Excel ou envie direto para Google Sheets, Airtable ou Notion.
Dicas para resultados melhores:
- Use nomes de campos claros (ex: “Nome do Produto”, “Preço em BRL”).
- Adicione prompts para formatação especial ou tradução.
- Escolha o tipo de dado certo para cada campo.
Para mais tutoriais passo a passo, dá uma olhada no nosso ou no .
Exemplo Prático: Raspando Leads de um Site com Thunderbit
Imagina que você trabalha com vendas e quer captar leads em um diretório do setor. Olha como eu faria:
- Abro a página do diretório.
- Clico na extensão Thunderbit e escolho “Sugestão de Campos com IA”.
- O Thunderbit sugere: Nome, Empresa, E-mail, Telefone, Site.
- Ajusto as colunas — talvez adicione “Localização” ou “Setor”.
- Clico em “Raspar”. O Thunderbit coleta todos os leads visíveis em uma tabela.
- Alguns leads têm links para perfis detalhados. Clico em “Raspar Subpáginas” e o Thunderbit visita cada um, trazendo informações extras como LinkedIn ou biografia.
- Exporto a lista para Excel ou Google Sheets, pronta para prospecção.
Sem código, sem dor de cabeça e sem precisar comprar café para o dev.
Além do Texto: Raspagem Avançada com IA (Imagens, Rótulos, Traduções e Mais)
Os raspadores modernos com IA vão muito além do texto. Com o Thunderbit, você pode:
- Extrair imagens: Perfeito para catálogos de produtos ou anúncios de imóveis.
- Capturar e-mails e telefones: O Thunderbit detecta e formata esses campos automaticamente.
- Traduzir dados em tempo real: Raspe um site em francês e receba os dados em português.
- Rotular ou categorizar dados: Use prompts de IA para marcar, resumir ou agrupar informações.
- Integrar com Notion, Airtable e outros: Envie seus dados direto para suas ferramentas favoritas.
Isso faz toda a diferença para equipes de negócios. Imagina enriquecer seu CRM com imagens, dados multilíngues ou leads categorizados — tudo de uma vez.
Para fluxos de trabalho avançados, veja e .
Legalidade e Segurança: O Que Empresas Precisam Ficar de Olho
Screen scraping é poderoso, mas exige responsabilidade. Sempre recomendo:
- Confira os termos de uso do site: Alguns proíbem raspagem. Se tiver dúvida, peça permissão ou procure uma API oficial.
- Respeite o robots.txt: Não é lei, mas é boa prática — e ajuda a evitar bloqueios.
- Evite raspar áreas protegidas por login (a não ser que sejam seus próprios dados): Aqui começam os problemas legais.
- Cuide de dados pessoais: GDPR, LGPD e outras leis de privacidade se aplicam se você coletar nomes, e-mails, etc.
- Não sobrecarregue servidores: Use limites de requisição e seja um bom cidadão digital.
Para se aprofundar, veja Scraping no LinkedIn é Legal? e .
Resumindo: O Futuro do Screen Scraping com IA
O screen scraping evoluiu muito — de um trabalho manual cansativo para uma automação inteligente com IA. Com ferramentas como o Thunderbit, qualquer pessoa pode extrair, transformar e usar dados de praticamente qualquer fonte, sem complicação e sem precisar programar.
O que você precisa lembrar:
- Screen scraping libera dados de lugares onde APIs não chegam.
- Ferramentas com IA tornam o processo acessível para todos, não só para desenvolvedores.
- Equipes de negócios podem automatizar geração de leads, monitoramento de preços, pesquisas de mercado e muito mais, em poucos cliques.
- Uso legal e ético é fundamental — sempre respeite a fonte e a legislação.
Se você quer deixar a coleta manual de dados no passado (onde ela merece ficar), experimente o . Suas teclas Ctrl e V vão agradecer.
Quer saber mais? Dá uma olhada no para conteúdos sobre , e muito mais. Ou instale a e veja na prática como screen scraping pode ser fácil.
E se você ainda está copiando e colando dados na mão... já passou da hora de mudar.
Perguntas Frequentes
-
Screen scraping funciona em aplicativos móveis? Sim, dá para aplicar screen scraping em apps móveis, principalmente em sistemas antigos ou fechados. Normalmente, é preciso usar automação de interface ou ferramentas específicas para extrair dados das telas dos aplicativos.
-
Screen scraping pode extrair imagens ou conteúdo visual? Sim, não fica só no texto — dá para capturar imagens, gráficos ou elementos da interface, seja por captura de tela ou usando visão computacional para identificar e rotular conteúdos visuais.
-
Quais ferramentas são necessárias para começar com screen scraping? Você pode começar com scripts em Python e bibliotecas como Selenium ou Playwright. Para quem não programa, há opções visuais ou ferramentas com IA que permitem extrair dados com poucos cliques e configuração mínima.
-
Quais são os riscos do screen scraping? Os riscos incluem questões legais, bloqueio de IP ou problemas de precisão dos dados. Mudanças no layout da tela podem quebrar o raspador, e a coleta de dados pessoais pode violar leis de privacidade se não for feita corretamente.
Saiba Mais