
Já tentou acompanhar centenas de sites de concorrentes e percebeu que precisaria de uma equipe inteira (ou litros de café) só para copiar e colar tudo na mão? Fica tranquilo, você não está sozinho nessa. Hoje em dia, dados da web são ouro puro — seja para vendas, marketing, pesquisa ou operações. Para ter uma ideia, a raspagem de dados já representa mais de um terço de todo o tráfego da internet, e 81% dos varejistas americanos usam raspadores automáticos para monitorar preços (scrap.io). Ou seja, tem muito robô fazendo o trabalho pesado por aí.
Mas como esses robôs funcionam de verdade? E por que tanta gente escolhe o Node.js — o motor JavaScript que está por trás de boa parte da web moderna — para criar seu próprio raspador web? Como alguém que já viveu o dia a dia de SaaS e automação (e CEO da Thunderbit), já vi como as ferramentas certas podem transformar o desafio de coletar dados em uma baita vantagem competitiva. Bora entender o que é um raspador web node, como ele funciona e como até quem não manja de programação pode tirar proveito dessa tecnologia.
Raspador Web Node: Conceitos Fundamentais
O que é Raspagem de Dados e Como Fazer em 2025 Get Started Free
Vamos direto ao ponto. Um raspador web node é um programa — feito com Node.js — que navega automaticamente por páginas da web, segue links e extrai informações. Imagina um estagiário digital que não cansa nunca: você passa uma URL inicial, ele vai navegando, pegando os dados que você pediu e segue até cobrir todo o site (ou só as partes que você quiser).
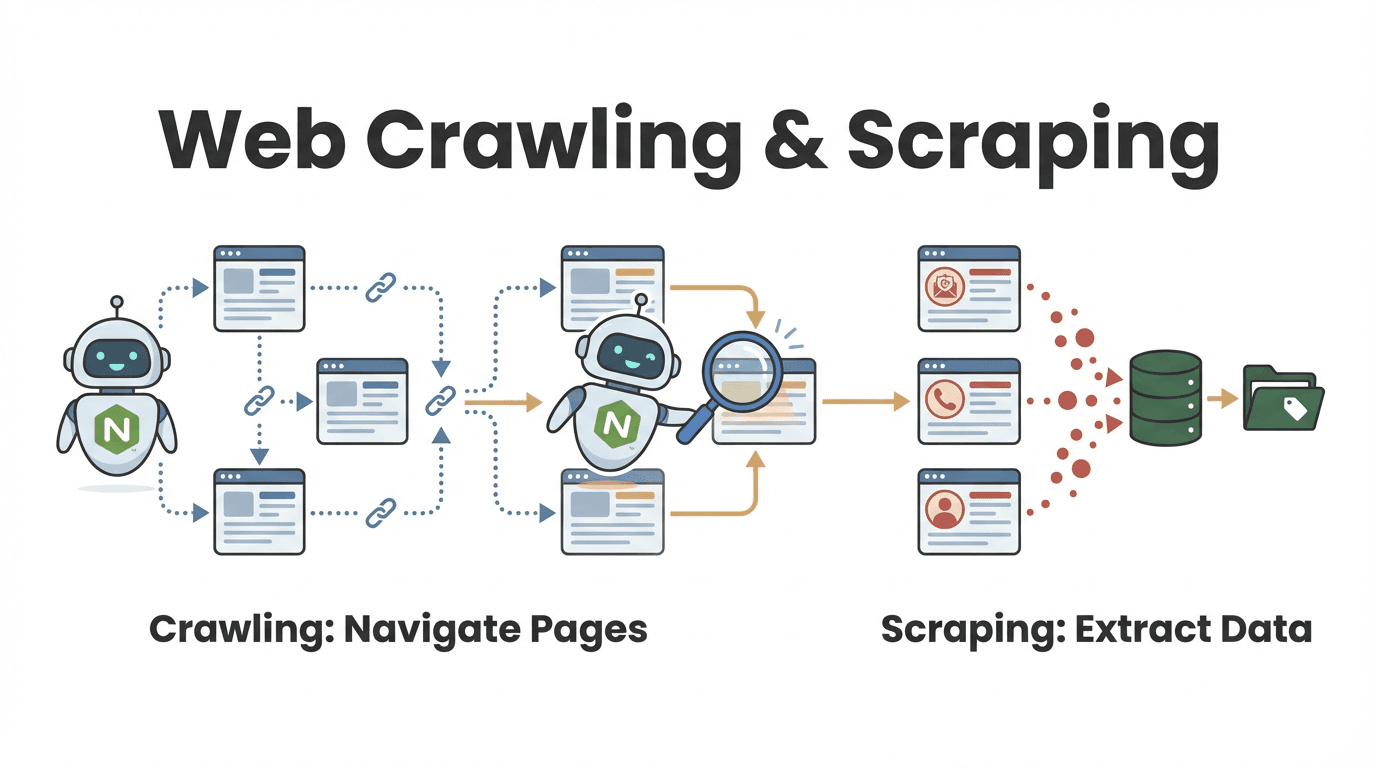
Mas qual a diferença entre web crawling e web scraping? Essa dúvida é super comum, principalmente para quem é de negócios:
- Web crawling é o processo de descobrir e navegar por várias páginas. Tipo folhear todos os livros de uma biblioteca para achar os que falam do seu assunto.
- Web scraping é extrair informações específicas dessas páginas — como copiar só os trechos importantes de cada livro.
Na prática, a maioria dos raspadores web node faz as duas coisas: encontra as páginas certas e extrai os dados que você precisa (oxylabs.io). Por exemplo, um time de vendas pode rastrear um diretório para achar todos os perfis de empresas e, depois, puxar os contatos de cada uma.
Como Funciona um Raspador Web Node?
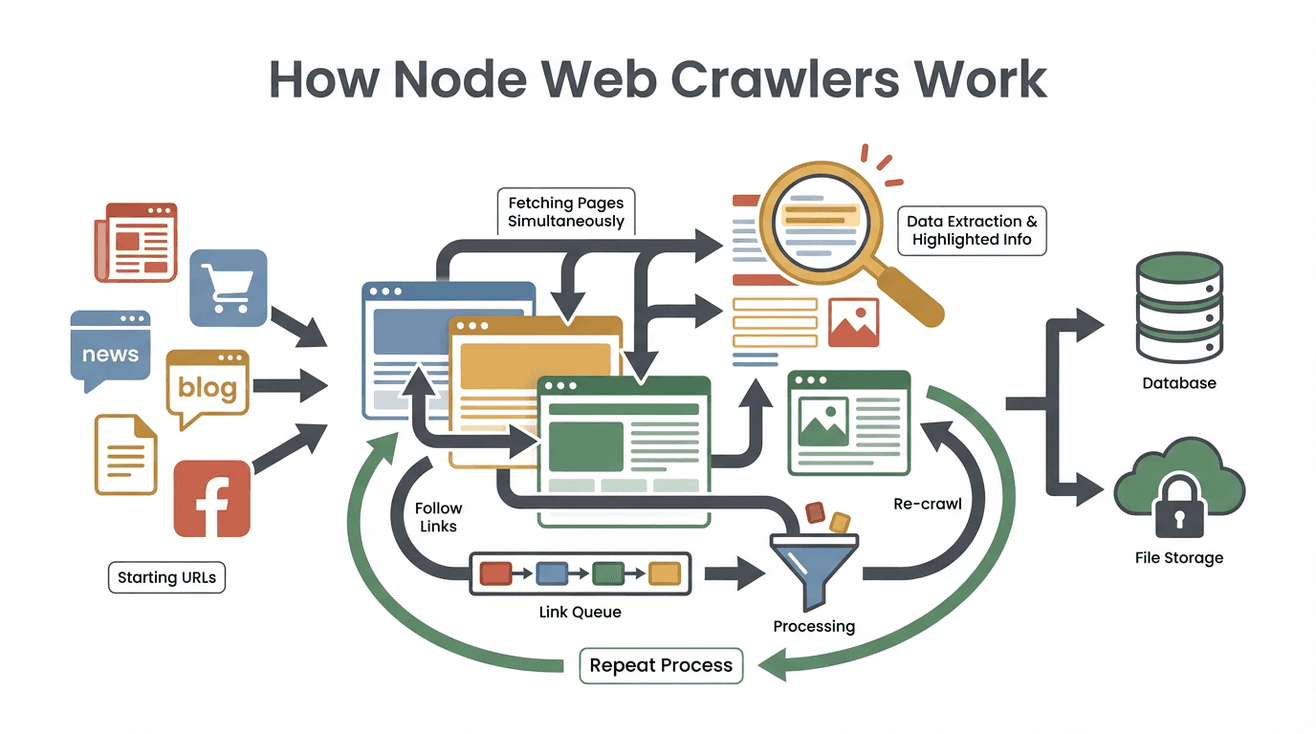
Vamos simplificar o processo. Olha só como um raspador web node normalmente trabalha, passo a passo:
- Defina as URLs iniciais: Você diz por onde o raspador começa (tipo a home ou uma lista de produtos).
- Busca do conteúdo da página: O raspador baixa o HTML de cada página — igual um navegador, mas sem carregar imagens ou estilos.
- Extração dos dados relevantes: Com ferramentas como Cheerio (um “jQuery” para Node), ele pega as informações que você quer — nomes, preços, e-mails, etc.
- Identificação e fila de novos links: O programa procura por links (tipo “Próxima página” ou detalhes de produtos) e adiciona à lista de tarefas (o tal do “frontier de rastreamento”).
- Repetição do processo: O raspador segue visitando novos links, extraindo dados e ampliando a cobertura até terminar o que foi pedido.
- Armazenamento dos resultados: Todos os dados extraídos são salvos — geralmente em CSV, JSON ou direto num banco de dados.
- Finalização: O processo acaba quando não tem mais links novos ou quando bate o limite definido.
Um exemplo prático: imagina que você quer pegar todas as vagas de emprego de um site de carreiras. Você começa pela página principal, extrai todos os links de vagas, visita cada um, coleta os detalhes e vai clicando em “Próxima” até ter a lista completa.
O segredo disso tudo? A arquitetura assíncrona e orientada a eventos do Node.js permite que o raspador processe várias páginas ao mesmo tempo, sem ficar esperando site lento. É como ter uma galera de estagiários trabalhando em paralelo — sem precisar pagar pizza.
Por Que Node.js é Tão Usado em Raspadores Web?
Mas por que Node.js? Por que não Python, Java ou outra linguagem? Olha só o que faz do Node.js uma escolha tão popular para raspador web:
- I/O assíncrono e orientado a eventos: O Node.js consegue lidar com dezenas (ou centenas) de requisições de páginas ao mesmo tempo, sem travar. Enquanto uma página carrega, ele já está processando outras (blog.apify.com).
- Alto desempenho: O Node roda no motor V8 do Google (o mesmo do Chrome), garantindo velocidade — especialmente para grandes volumes de dados.
- Ecossistema robusto: Tem biblioteca Node pra tudo: Cheerio para parsear HTML, Got para requisições HTTP, Puppeteer para navegação headless e frameworks como Crawlee para gerenciar grandes volumes (scrapingdog.com).
- Sinergia com JavaScript: Como a maioria dos sites usa JavaScript, o Node.js conversa nativamente com eles. E manipular dados em JSON é fácil e rápido.
- Capacidade em tempo real: Precisa monitorar vários sites por mudanças de preço ou notícias? O Node permite isso quase em tempo real.
Não é à toa que ferramentas baseadas em Node, como Crawlee e Cheerio, são usadas por mais de um terço dos desenvolvedores de raspador web.
Principais Recursos e Funções de um Raspador Web Node
Raspadores web node são tipo um canivete suíço para dados online. Olha só o que eles costumam oferecer — e como esses recursos ajudam de verdade no dia a dia das empresas:
| Recurso/Função | Como Funciona nos Raspadores Node | Exemplo de Uso Empresarial |
|---|---|---|
| Navegação Automática | Segue links e páginas paginadas automaticamente | Geração de leads: rastrear todas as páginas de um diretório online |
| Extração de Dados | Coleta campos específicos (nome, preço, contato) usando seletores ou padrões | Monitoramento de preços: extrair valores de produtos em sites concorrentes |
| Processamento Paralelo | Busca e processa várias páginas ao mesmo tempo (graças ao Node.js assíncrono) | Atualizações em tempo real: monitorar múltiplos sites de notícias simultaneamente |
| Saída de Dados Estruturada | Salva resultados em CSV, JSON ou direto em banco de dados | Análises: alimentar dashboards de BI ou CRMs com os dados extraídos |
| Lógica e Filtros Personalizáveis | Permite adicionar regras, filtros ou etapas de limpeza de dados no código | Controle de qualidade: ignorar páginas desatualizadas, transformar formatos de dados |
Por exemplo, um time de marketing pode usar um raspador node para coletar todos os posts de blogs do setor, extrair títulos e URLs e exportar para o Google Sheets para planejar conteúdo.
Thunderbit: Alternativa Sem Código aos Raspadores Node
Experimente o Raspador Web IA Thunderbit Extraia dados de qualquer site em 2 cliques — sem precisar programar. Get Started Free
Agora a coisa fica ainda mais interessante (e acessível para quem não programa). O Thunderbit é uma extensão Chrome de raspador web IA que permite extrair dados de sites — sem escrever uma linha de código.
Como funciona? Você abre a extensão, clica em “Sugerir Campos com IA” e a IA do Thunderbit lê a página, sugere quais dados extrair e já organiza tudo em uma tabela. Quer pegar todos os nomes e preços de produtos de um site? Só pedir em português, e o Thunderbit faz o resto. Precisa raspar subpáginas ou lidar com paginação? O Thunderbit resolve com um clique.
Alguns dos recursos que mais curto no Thunderbit:
- Interface em linguagem natural: Fala o que precisa; a IA resolve o resto.
- Sugestão automática de campos: O Thunderbit analisa a página e propõe as melhores colunas para extração.
- Raspagem de subpáginas sem código: Pega dados de páginas detalhadas (tipo produtos ou perfis) e junta tudo automaticamente.
- Exportação estruturada: Manda seus dados direto para Excel, Google Sheets, Airtable ou Notion.
- Exportação gratuita de dados: Baixe seus resultados sem taxas escondidas.
- Automação e agendamento: Programe raspagens recorrentes usando linguagem natural (“toda segunda às 9h”).
- Extração de contatos: Puxe e-mails, telefones e imagens com um clique — totalmente grátis.
Para quem trabalha com negócios, isso significa sair do “preciso desses dados” para “tá aqui minha planilha” em minutos, não dias. E, segundo avaliações de usuários, até quem não entende nada de tecnologia está montando listas de leads, monitorando preços e tocando projetos de pesquisa — sem precisar programar.
Experimente o Thunderbit Grátis no Chrome
Comparando Raspadores Node e Thunderbit para Empresas
Qual caminho faz mais sentido para você? Olha essa comparação lado a lado:
| Critério | Raspador Web Node.js (Código Personalizado) | Thunderbit (Raspador IA Sem Código) |
|---|---|---|
| Tempo de Configuração | Horas a dias (programação, testes, ajustes) | Minutos (instalar, clicar, raspar) |
| Habilidade Técnica | Exige programação (Node.js, HTML, seletores) | Não precisa programar; linguagem natural e cliques |
| Personalização | Extremamente flexível; qualquer lógica ou fluxo | Limitado aos recursos e à IA do Thunderbit |
| Escalabilidade | Escala massivamente (com esforço: servidores, proxies) | Raspagem em nuvem para trabalhos de pequeno a médio porte |
| Manutenção | Contínua (atualizar código conforme sites mudam) | Mínima (a IA do Thunderbit se adapta às mudanças) |
| Defesa Anti-Bot | Precisa implementar proxies, delays, navegação headless | Gerenciado automaticamente pelo Thunderbit |
| Integração | Integração profunda (APIs, bancos de dados, workflows) | Exporta para Sheets, Notion, Airtable, Excel, CSV |
| Custo | Ferramentas gratuitas, mas há custo de desenvolvimento | Plano gratuito, depois cobrança por uso ou assinatura |
Quando usar Node.js:
- Se precisa de lógica super personalizada ou integração avançada.
- Se tem devs disponíveis e quer controle total.
- Se vai raspar em grande escala ou criar um produto baseado em dados web.
Quando usar Thunderbit:
- Se quer resultado rápido, com configuração mínima.
- Se não é programador (ou não quer ser).
- Se precisa raspar diferentes sites para tarefas do dia a dia.
- Se valoriza facilidade de uso e adaptação via IA.
Muita gente começa com o Thunderbit para resultados rápidos e, se precisar, investe em raspadores node personalizados conforme as demandas aumentam.
Principais Desafios ao Usar Raspadores Node
Raspadores web node são potentes, mas têm seus perrengues. Veja os principais (e como driblar):
- Defesas anti-raspagem: Sites usam CAPTCHAs, bloqueio de IP e detecção de bots. Vai ser preciso rodar proxies, variar cabeçalhos e, às vezes, usar navegadores headless como o Puppeteer (blog.apify.com).
- Conteúdo dinâmico: Muitos sites carregam dados via JavaScript ou rolagem infinita. Só parsear HTML não basta — pode ser necessário simular navegação real ou acessar APIs.
- Limpeza e tratamento de dados: Nem toda página é organizada. Prepare-se para lidar com formatos bagunçados, dados faltando e codificações estranhas.
- Manutenção: Sites mudam. Seu código pode quebrar. Planeje revisões e tratamento de erros frequentes.
- Questões legais e éticas: Sempre respeite o
robots.txt, termos do site e leis de privacidade. Não raspe dados sensíveis ou protegidos por direitos autorais.
Boas práticas:
- Use frameworks como Crawlee, que já resolvem muitos desses problemas.
- Implemente tentativas, atrasos e logs de erro.
- Revise e atualize seus raspadores com frequência.
- Raspe com responsabilidade — não sobrecarregue sites nem viole regras.
Integrando Raspadores Node com Serviços em Nuvem
Para projetos sérios e contínuos de coleta de dados, rodar o raspador node no seu computador não dá conta. É aí que entra a integração com a nuvem:
- Funções serverless: Implemente seu raspador node como AWS Lambda ou Google Cloud Function. Programe execuções automáticas (diárias, horárias) e salve resultados em S3 ou BigQuery (docs.aws.amazon.com).
- Raspadores em containers: Empacote seu raspador em Docker e rode no AWS Fargate, Google Cloud Run ou Kubernetes. Assim, dá pra escalar para milhares de páginas em paralelo.
- Workflows automatizados: Use agendadores em nuvem (como AWS EventBridge) para disparar raspagens, armazenar resultados e alimentar dashboards ou modelos de machine learning.
As vantagens? Escalabilidade, confiabilidade e automação “esquece e deixa rodando”. Hoje, 68% da raspagem web já acontece na nuvem — e esse número só cresce.
Quando Escolher um Raspador Node ou uma Solução Sem Código
Ainda está na dúvida? Olha esse checklist rápido:
-
Precisa de personalização profunda, fluxos únicos ou integração com sistemas internos?
→ Raspador web node.js -
É um usuário de negócios que precisa de dados rápido, sem programar?
→ Thunderbit (ou outra ferramenta sem código) -
É uma tarefa pontual ou esporádica?
→ Thunderbit -
É uma operação crítica, contínua e em larga escala?
→ Node.js (com integração em nuvem) -
Tem desenvolvedores e tempo para manutenção?
→ Node.js -
Quer dar autonomia para equipes não técnicas coletarem dados?
→ Thunderbit
Minha dica? Comece pelo caminho sem código para resultados rápidos e prototipagem. Se as necessidades crescerem, invista em um raspador node personalizado depois. Muita gente descobre que o Thunderbit resolve 90% dos casos — economizando tempo e dor de cabeça.
Comece com o Raspador Web IA Thunderbit
Conclusão: Liberando o Potencial dos Dados Web para o Crescimento dos Negócios
A extração de dados da web deixou de ser “coisa de TI” e virou uma necessidade estratégica para empresas. Seja criando seu próprio raspador node ou usando uma solução com IA como o Thunderbit, o objetivo é o mesmo: transformar o caos da internet em informações organizadas e acionáveis.
O Node.js oferece flexibilidade e poder máximos, especialmente para projetos complexos ou de grande porte. Mas, para a maioria dos profissionais, a ascensão das ferramentas sem código e com IA permite obter os dados necessários — de forma rápida, confiável e sem programar.
Com quase 97% das organizações investindo em Big Data e IA, quem domina a coleta de dados web sai na frente. Seja você dev, profissional de marketing ou só cansado de copiar e colar, nunca foi tão fácil aproveitar o poder do raspador web.
Ficou curioso para testar? Baixe o Thunderbit de graça e veja como é simples extrair dados da web. E se quiser se aprofundar, dá uma olhada no Blog da Thunderbit para mais guias, dicas e histórias do universo da automação web.
Teste o Raspador Web IA Gratuitamente Get Started Free
Perguntas Frequentes
1. Qual a diferença entre um raspador web node e um raspador web comum?
Um raspador web node descobre e navega automaticamente por páginas (tipo uma aranha na web), enquanto um raspador web extrai dados específicos dessas páginas. A maioria dos raspadores node faz as duas coisas: encontra páginas e coleta as informações necessárias.
2. Por que o Node.js é tão usado para criar raspadores web?
O Node.js é assíncrono e orientado a eventos, ou seja, consegue lidar com muitas requisições ao mesmo tempo. É rápido, tem um ecossistema enorme de bibliotecas e é ótimo para extração de dados em tempo real ou em grande volume.
3. Quais os principais desafios dos raspadores web node?
Os problemas mais comuns são defesas anti-bot (CAPTCHAs, bloqueio de IP), conteúdo dinâmico (sites pesados em JavaScript), limpeza de dados e manutenção constante conforme os sites mudam. Usar frameworks e boas práticas ajuda, mas exige conhecimento técnico.
4. Como o Thunderbit é diferente de um raspador node?
O Thunderbit é um raspador web IA e sem código. Em vez de programar, você usa uma extensão Chrome e linguagem natural para extrair dados. É ideal para quem quer resultados rápidos sem precisar programar.
5. Quando devo usar um raspador node e quando usar o Thunderbit?
Use Node.js para projetos altamente personalizados, em larga escala ou que exijam integração profunda — especialmente se tiver desenvolvedores disponíveis. Use Thunderbit para tarefas rápidas do dia a dia ou para dar autonomia a equipes não técnicas.
Quer turbinar sua coleta de dados web? Experimente o Thunderbit ou explore mais no Blog da Thunderbit. Boas raspagens!
Saiba mais




