Já passou pela situação de encontrar uma página cheia de links, mas quase sem informação à vista, te obrigando a abrir vários deles só para achar o que procura? Isso acontece cada vez mais, já que muitos sites preferem esconder detalhes importantes em subpáginas. Para quem precisa coletar dados em grande escala, isso é um baita desafio: desenvolvedores gastam horas criando scripts para acessar cada subpágina, enquanto quem não programa acaba clicando manualmente em cada link. Mas calma, existem alternativas: o list crawling (raspagem em massa) e a raspagem de subpáginas.
List Crawling e Raspagem de Subpáginas em Resumo
| Ferramenta | Facilidade de Uso | Qualidade dos Dados | Melhor Aplicação |
|---|---|---|---|
| List Crawling | ★★ | ★★★ | Sites de grande porte |
| Raspagem de Subpáginas | ★★★★★ | ★★★★ | Raspagem leve, formatos de dados específicos |
Entendendo o List Crawling
O que é List Crawling?
List crawling, ou raspagem em massa, é uma técnica de raspagem web que coleta dados a partir de uma lista de URLs. O primeiro passo é montar essa lista de endereços, muitas vezes usando outro raspador para encontrá-los. O sucesso do processo depende muito da qualidade dessa lista inicial. Se as URLs apontarem para páginas com formatos diferentes, os resultados podem ficar inconsistentes e exigir mais trabalho. Esse método é ideal para empresas, pesquisadores e analistas de dados que precisam extrair grandes volumes de informações estruturadas e padronizadas. Porém, normalmente é necessário um ajuste manual para organizar e limpar os dados coletados.
Como Funciona

O processo de list crawling geralmente segue estas etapas:
- Preparar uma Lista de URLs: Comece reunindo os endereços das páginas que deseja coletar.
- Enviar Requisições HTTP: O sistema acessa cada URL para obter o conteúdo HTML.
- Extrair Dados: Utilize técnicas como BeautifulSoup, XPath ou expressões regulares para capturar informações como textos, imagens e links.
- Armazenar os Dados: Organize e salve os dados extraídos em uma planilha ou banco de dados para análise posterior.
Depois de coletar os dados, é fundamental limpá-los e analisá-los usando métodos como estatísticas descritivas, análise de séries temporais, correlação e agrupamento. A IA pode acelerar muito esse processo, automatizando tarefas e melhorando a qualidade dos dados.
Conheça o recurso de Raspagem em Massa do Raspador Web IA da Thunderbit para facilitar ainda mais esse trabalho.
Ferramentas Recomendadas
-
- Vantagens: Fácil de usar, flexível na extração, recursos avançados
- Desvantagens: Precisa rodar localmente e depende do navegador
- Ideal para: Coleta de dados com foco em qualidade
- Scrapy
- Vantagens: Potente, altamente customizável, ótimo para grandes volumes
- Desvantagens: Curva de aprendizado alta, exige conhecimento em programação
- Ideal para: Projetos de coleta de dados em larga escala
- Beautiful Soup
- Vantagens: Simples de usar, documentação completa, flexível
- Desvantagens: Performance mediana, não suporta operações assíncronas
- Ideal para: Projetos menores e análise de dados
- Selenium
- Vantagens: Suporta páginas dinâmicas, simula ações do usuário
- Desvantagens: Execução lenta, consome muitos recursos
- Ideal para: Páginas que usam JavaScript para exibir conteúdo
Explorando a Raspagem de Subpáginas

O que é Raspagem de Subpáginas?
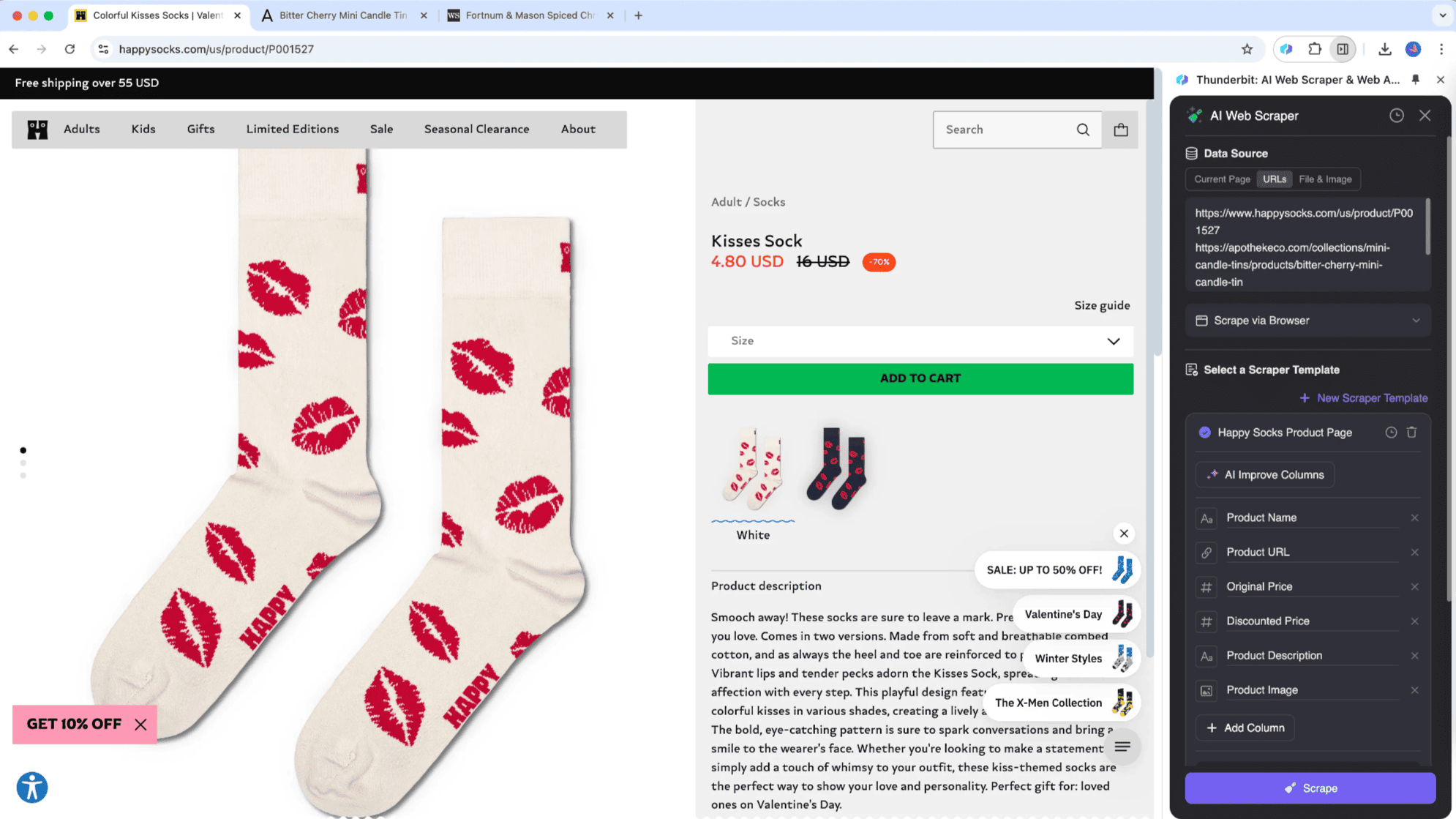
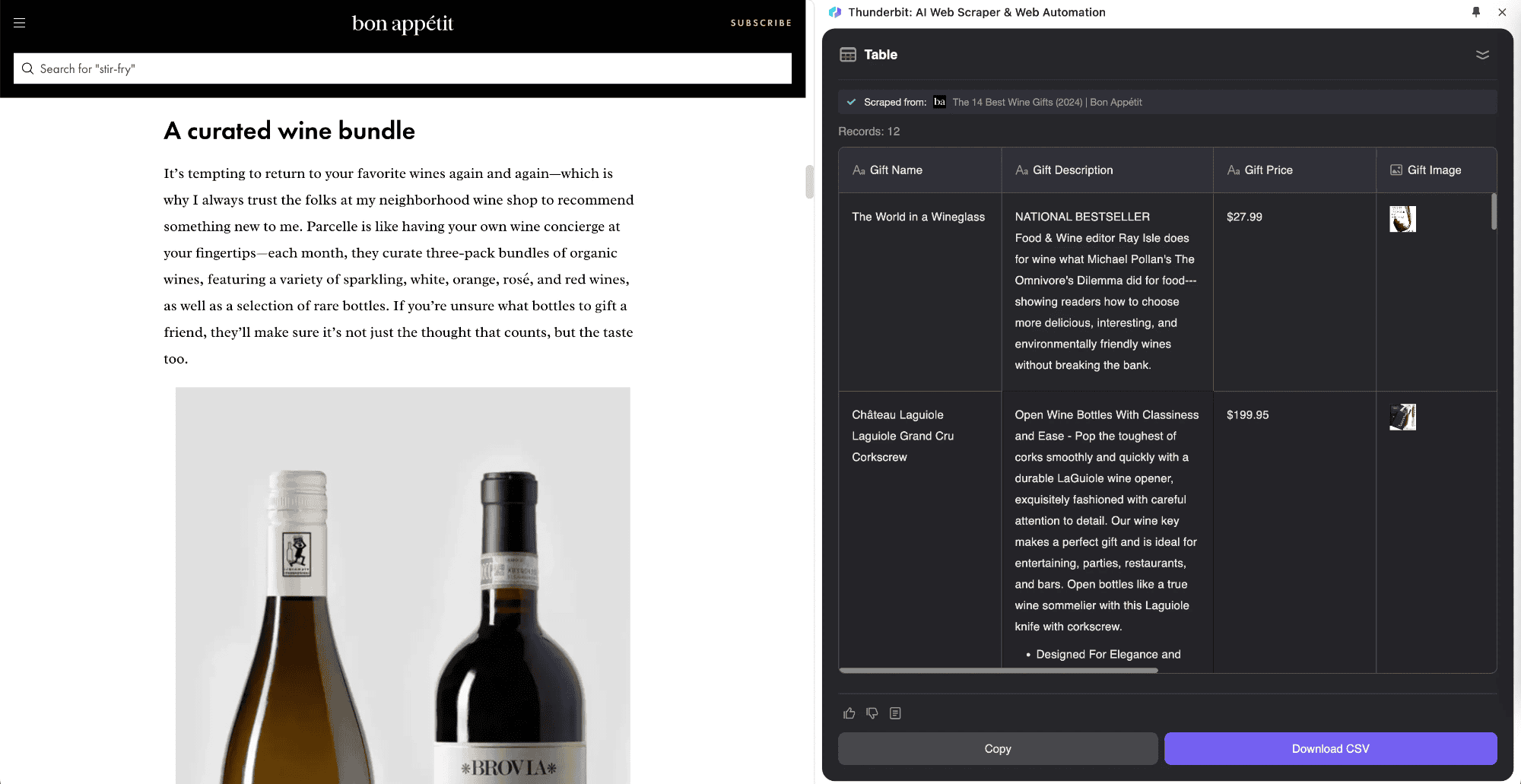
A raspagem de subpáginas é uma técnica que coleta dados de listas em uma página principal e integra informações das subpáginas em uma tabela central. A Thunderbit inovou ao trazer esse processo para o seu Raspador Web IA, aproveitando recursos de inteligência artificial. É ideal para páginas com subpáginas, como catálogos de produtos, blogs e sites de navegação. O diferencial é a capacidade de reunir e organizar automaticamente os dados das subpáginas na tabela principal.
Por exemplo, ao ler uma matéria sobre "Bolsa de Valores Hoje" e querer extrair todas as cotações, basta usar o . Defina sua tabela e a ferramenta extrai as cotações, acessa as páginas em tempo real e integra tudo na sua tabela principal. Assim, você registra informações precisas enquanto acompanha as notícias. O Raspador Web IA da Thunderbit se adapta a diferentes tipos de páginas, algo que ferramentas tradicionais não conseguem.
Por Que Usar?
O Raspador Web IA da Thunderbit traz recursos que aumentam a eficiência e a precisão na coleta de dados.
Extração Inteligente de Dados
A Thunderbit utiliza IA para extrair dados de forma inteligente, adaptando-se automaticamente a mudanças na estrutura das páginas. O usuário pode descrever o que precisa em linguagem natural e o sistema cria as regras de extração. Isso aumenta a precisão dos dados e torna a ferramenta acessível até para quem não tem conhecimento técnico. A Thunderbit suporta diferentes tipos de dados, como textos, links e imagens, atendendo a diversas necessidades.
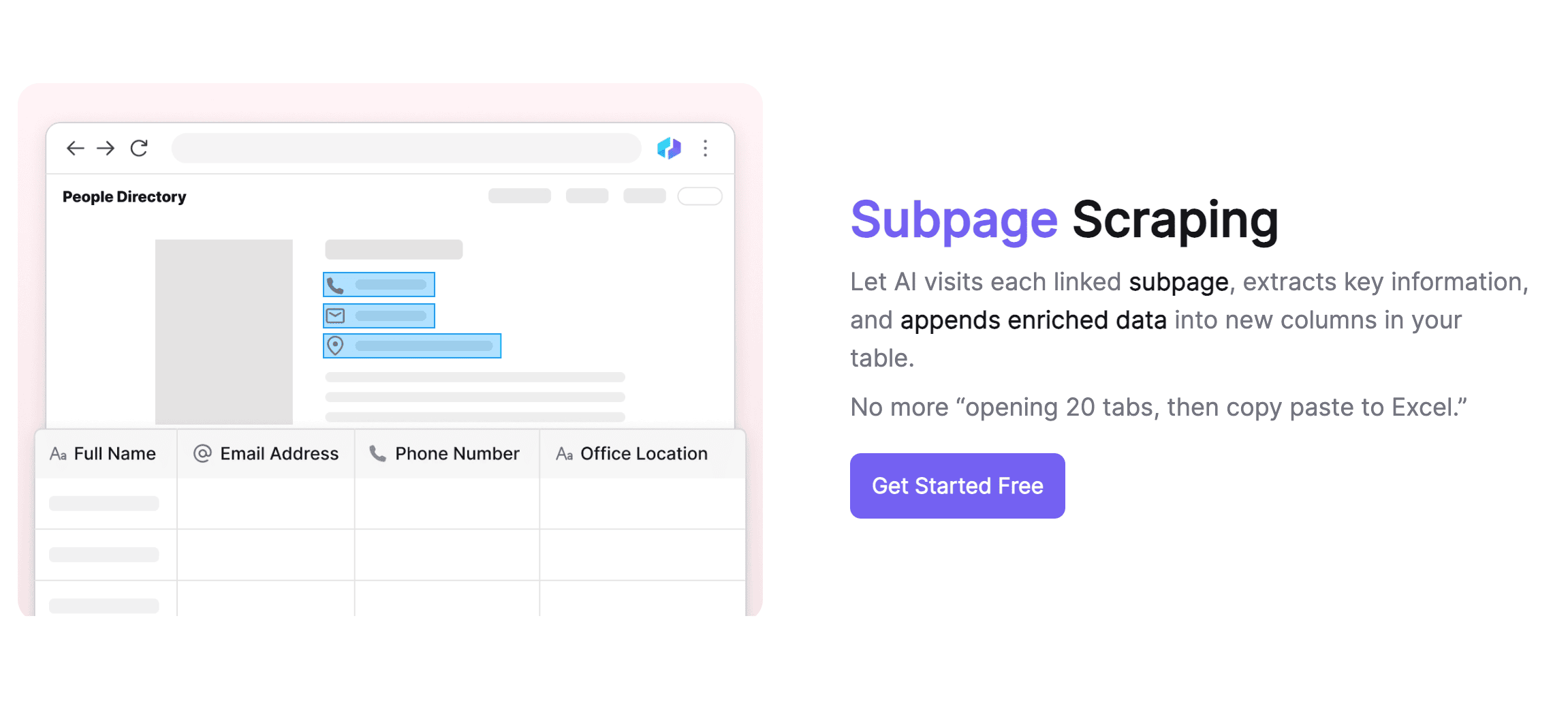
Gestão Inteligente de Subpáginas
A Thunderbit se destaca no processamento de subpáginas. Ela identifica e acessa subpáginas automaticamente, usando um único modelo para diferentes layouts. A IA se ajusta a mudanças na estrutura das páginas, eliminando a preocupação de extrair dados de subpáginas variadas. O conteúdo das subpáginas é integrado automaticamente à tabela principal, facilitando a organização das informações. Além disso, a Thunderbit atua como um assistente de IA, limpando e formatando os dados, automatizando tarefas repetitivas como rotulagem.
Gestão Eficiente de Dados
A Thunderbit oferece recursos avançados de gestão de dados, permitindo exportação em vários formatos e integração com plataformas como Google Sheets, Airtable e Notion. Você pode vincular um modelo de raspador a uma planilha do Google, centralizando os dados, ou ao Notion, organizando tudo no banco de dados da plataforma. Essas opções flexíveis permitem escolher o melhor formato de armazenamento para cada caso. A rotulagem e classificação dos dados também se adaptam automaticamente ao formato da plataforma de destino, tornando a gestão ainda mais eficiente.
Modelos Práticos Pré-definidos
Para agilizar o trabalho, a Thunderbit oferece diversos modelos prontos. Eles abrangem coleta de dados de e-commerce (como , ), informações imobiliárias (como ), análise de redes sociais (como , ) e coleta de dados empresariais (sites de empresas, diretórios de negócios). Esses modelos economizam tempo e garantem consistência e precisão na coleta.
Como Colocar em Prática
Raspagem de Subpáginas na Prática
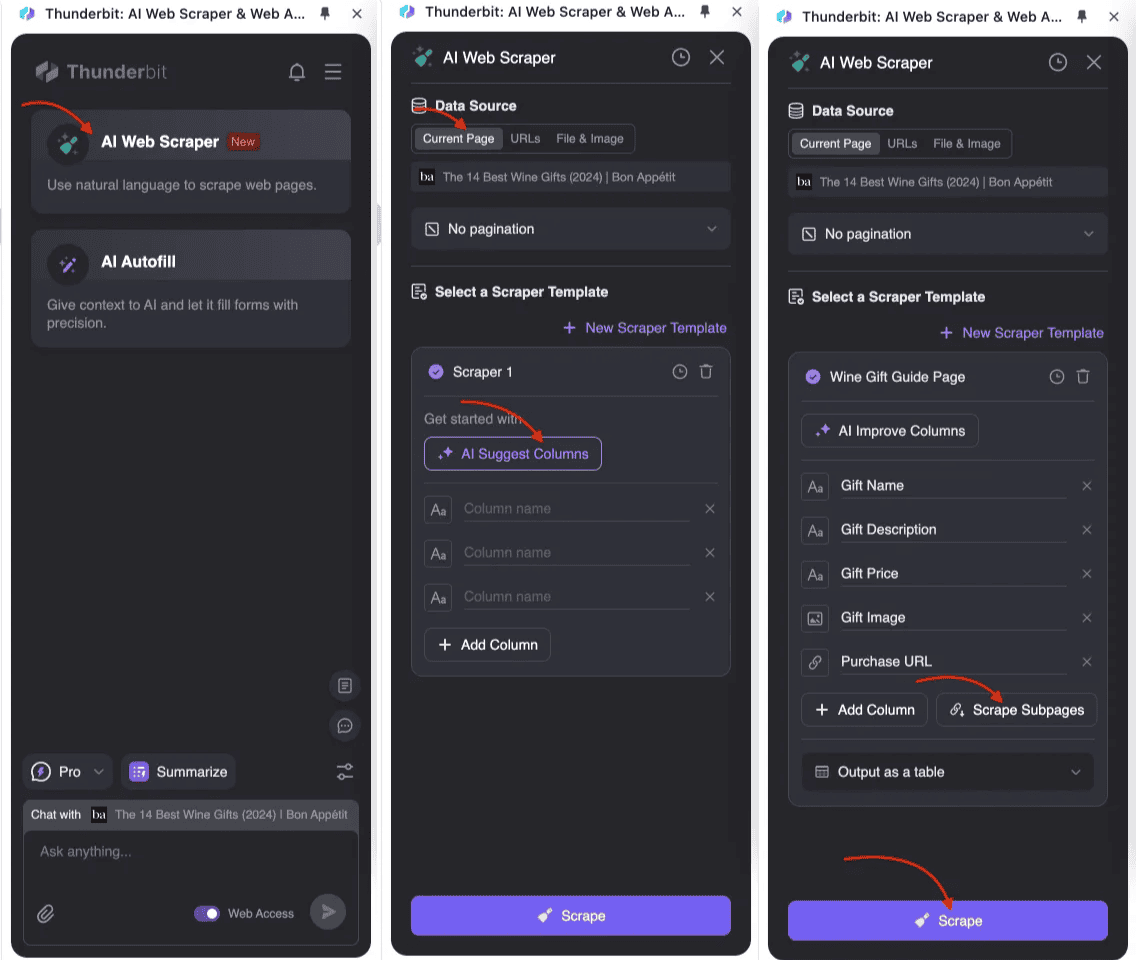
- : Abra o Raspador Web IA da Thunderbit e crie um novo modelo de raspagem.
- Defina a Estrutura da Tabela Principal: Nos ajustes da tabela, adicione os campos que deseja coletar, como título, preço e descrição. Para dados das subpáginas, crie campos correspondentes e ative a raspagem de subpáginas.
- Execute o Raspador: A Thunderbit vai extrair os dados da página principal, acessar automaticamente cada subpágina, coletar as informações relevantes e integrar tudo na tabela principal. Todo o processo é guiado por IA, sem necessidade de programação complexa.
Como Fazer List Crawling
Para quem programa, existem várias linguagens e ferramentas para implementar o list crawling. O Python é o queridinho da galera, por ser simples e ter uma biblioteca enorme. Olha só um exemplo básico usando requests e BeautifulSoup:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# Exemplo de uso
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)Conclusão
Hoje em dia, dados são o combustível das empresas. Quem consegue coletar e analisar informações de forma eficiente sai na frente. Os dados ajudam a entender tendências de mercado e necessidades dos clientes, trazendo insights valiosos para o desenvolvimento de produtos e estratégias de marketing. Mas reunir e organizar o enorme volume de dados espalhados pela internet é um baita desafio.
Com ferramentas como a Thunderbit, as empresas não precisam mais se preocupar com a coleta de dados. É como ter um assistente confiável que encontra informações relevantes em meio a grandes volumes de dados, tornando as decisões mais seguras. Com recursos inteligentes de coleta e processamento, é fácil acessar informações sobre concorrentes, tendências de mercado, avaliações de usuários e outros dados essenciais para decisões estratégicas.
A Thunderbit não só facilita a coleta, mas também oferece recursos avançados de processamento e análise. Ela limpa e estrutura os dados automaticamente, gerando relatórios intuitivos que ajudam a identificar oportunidades rapidamente. Para empresas que precisam monitorar o mercado com frequência, a coleta automatizada da Thunderbit é uma solução eficiente e que economiza tempo.
Nesse cenário cada vez mais orientado por dados, contar com uma ferramenta como a Thunderbit faz toda a diferença. Ela aumenta a produtividade na coleta de dados e apoia a transformação digital dos negócios. À medida que os dados se tornam cada vez mais estratégicos, soluções inteligentes como a Thunderbit serão indispensáveis para a competitividade das empresas.
Perguntas Frequentes
-
O que é a Thunderbit? é uma extensão para Chrome criada para automatizar tarefas online. Ela oferece recursos como Raspador Web IA, Área de Transferência IA e Chat Web IA para extrair dados, preencher formulários e usando inteligência artificial. É uma ferramenta de produtividade que economiza tempo e simplifica tarefas repetitivas na web.
-
Como funciona o Raspador Web IA da Thunderbit? O Raspador Web IA da Thunderbit utiliza IA para extrair dados estruturados de sites. O usuário pode clicar em "Sugerir Colunas com IA" para que o sistema indique como raspar o site atual e, em seguida, clicar em "Raspar" para coletar os dados. Ele consegue lidar com dados de qualquer site, PDF ou imagem em apenas dois cliques.
-
Qual a diferença entre list crawling e raspagem de subpáginas? List crawling, ou raspagem em massa, extrai dados de uma lista de URLs, sendo ideal para sites grandes. Já a raspagem de subpáginas coleta dados de uma página principal e suas subpáginas, integrando tudo em uma tabela central. O Raspador Web IA da Thunderbit é eficiente nos dois métodos, oferecendo extração e gestão inteligente dos dados.
-
Quem não programa pode usar a Thunderbit? Com certeza! A Thunderbit foi pensada para ser fácil de usar, mesmo para quem não tem experiência em programação. Com recursos baseados em IA, basta descrever os dados desejados em linguagem natural e o sistema cria as regras de extração, tornando a ferramenta acessível para todos.
-
Quais tipos de dados a Thunderbit suporta? A Thunderbit trabalha com diferentes tipos de dados, como textos, links e imagens. Isso permite atender a várias demandas, como coleta de dados de e-commerce, informações imobiliárias, análise de redes sociais e dados empresariais.
-
Como começar a usar a Thunderbit? Para começar, basta baixar a extensão Thunderbit para Chrome na . Depois de instalada, explore recursos como o Raspador Web IA, Área de Transferência IA e Chat Web IA para turbinar sua produtividade online.
-
A Thunderbit oferece modelos prontos? Sim, a Thunderbit disponibiliza vários para facilitar o trabalho. Eles abrangem áreas como e-commerce, imóveis, redes sociais e informações empresariais, economizando tempo e garantindo consistência e precisão na coleta.
-
Como a Thunderbit garante a qualidade dos dados? A Thunderbit utiliza IA para extrair e processar dados de forma inteligente, adaptando-se automaticamente a mudanças nas páginas. Também oferece recursos de limpeza e formatação, atuando como um assistente para automatizar tarefas repetitivas e melhorar a qualidade dos dados.
-
Casos de Uso de Raspagem Web Existem muitas aplicações práticas para . Por exemplo, é possível para pesquisas de mercado ou para análise de documentos. Muitas empresas precisam para análise. Com ferramentas baseadas em IA, agora é possível sem precisar programar. Para análise de redes sociais, você pode usar ferramentas específicas como ou para reunir dados relevantes para campanhas de marketing.
Saiba Mais: