

A internet ficou muito mais bagunçada — e, ao mesmo tempo, muito mais fascinante — do que nos tempos em que bastava clicar com o botão direito e salvar a página. Hoje em dia, os sites viraram verdadeiros labirintos cheios de conteúdos dinâmicos, links escondidos, pop-ups e navegação em vários níveis. Se você já tentou puxar todos os dados de produtos de um e-commerce moderno ou juntar todos os anúncios de um portal de imóveis, sabe que um raspador web básico não dá mais conta do recado. É aí que entram os deep crawlers — uma nova geração de ferramentas de raspagem feitas para ir mais fundo, explorar cada cantinho e trazer os dados que realmente importam.
Mas, afinal, o que é um deep crawler? Por que empresas — de equipes de vendas a analistas de mercado — estão cada vez mais de olho neles? E como uma solução como o Thunderbit pode deixar o deep crawling tão fácil quanto dois cliques, mesmo para quem não manja nada de programação? Vem comigo que vou explicar tudo, do conceito ao impacto nos negócios, e mostrar por que os deep crawlers estão virando o segredo do sucesso na extração de dados web.
O que é um Deep Crawler? Entendendo o Conceito
Extraia dados de qualquer site usando IA Get Started Free
No básico, um deep crawler é um tipo especial de raspador web criado para navegar e puxar dados de sites complexos, cheios de níveis e conteúdos dinâmicos. Diferente dos crawlers tradicionais — que só pegam o que está visível na página principal —, o deep crawler segue links, passa por várias camadas de navegação e encara de tudo: listas paginadas, informações escondidas em abas ou seções que só aparecem quando você clica.
Pensa num crawler tradicional como alguém que dá uma passada rápida na biblioteca e anota só os títulos das prateleiras da frente. Já o deep crawler é aquele que explora todos os corredores, abre cada livro, confere as notas de rodapé e até dá uma olhada atrás da porta “Somente Funcionários” (se estiver aberta, claro).
No mundo do web scraping, isso significa que um deep crawler consegue:
- Navegar por vários níveis de um site (categorias, subcategorias, páginas de detalhes)
- Extrair conteúdos dinâmicos carregados por JavaScript ou escondidos por interações do usuário
- Lidar com paginação complicada e rolagem infinita
- Seguir links internos para garantir que nenhum dado importante fique de fora
 Com o volume global de dados web chegando a 149 zettabytes em 2024 e os sites cada vez mais complexos, os deep crawlers viraram ferramenta obrigatória para quem precisa de mais do que uma varredura superficial.
Com o volume global de dados web chegando a 149 zettabytes em 2024 e os sites cada vez mais complexos, os deep crawlers viraram ferramenta obrigatória para quem precisa de mais do que uma varredura superficial.
Deep Crawler vs. Crawler Tradicional: O que Muda?
Vamos detalhar um pouco mais. O que faz um deep crawler ser diferente dos “crawlers comuns” que você já ouviu falar?
Crawlers Tradicionais: Só na Superfície
Os crawlers tradicionais (também chamados de “shallow crawlers”) são feitos para serem rápidos e cobrir o máximo possível. Eles passam voando pelo site, pegam o que está nas páginas principais e seguem em frente. É o método dos buscadores — o objetivo é indexar o máximo de páginas, no menor tempo, sem se aprofundar.
Limitações dos crawlers tradicionais:
- Costumam ignorar dados escondidos atrás de navegação, abas ou elementos dinâmicos
- Têm dificuldade com sites pesados em JavaScript ou conteúdos que aparecem só depois do carregamento inicial
- Não conseguem lidar com navegação em vários passos ou páginas muito complexas
- Retornam dados incompletos ou fragmentados
Deep Crawlers: Indo Muito Além
Já o deep crawler foi feito para explorar a fundo um site — seguindo todos os links relevantes, navegando por listas paginadas e puxando dados de subpáginas, pop-ups e conteúdos dinâmicos. Aqui, o foco é menos velocidade e mais completude e precisão.
Principais características dos deep crawlers:
- Navegação avançada: Segue links de forma recursiva, encara sites com vários níveis e evita páginas duplicadas ou becos sem saída (SEO-Wiki).
- Extração de conteúdo dinâmico: Interage com JavaScript, expande seções escondidas e coleta dados que só aparecem depois de alguma ação do usuário (Scientific Reports).
- Eficiência aprimorada: Vai direto ao que interessa, reduzindo dados duplicados ou irrelevantes e garantindo que nada importante fique de fora (Medium).
- Completude dos dados: Garante que todas as informações — listagens principais, páginas de detalhes, documentos relacionados — sejam capturadas de uma vez só.
Se você já tentou raspar todas as avaliações de um produto ou puxar todos os anúncios de um portal imobiliário (incluindo os contatos dos corretores em subpáginas), provavelmente já bateu nos limites dos crawlers tradicionais. É aí que os deep crawlers brilham.
Como Deep Crawlers Garantem Dados Completos e Navegação Avançada
Mas como, na prática, os deep crawlers conseguem ir tão longe? O segredo está em seguir links, navegação recursiva e lidar de forma inteligente com conteúdos dinâmicos.
Raspagem de Subpáginas e Navegação em Vários Níveis
Um deep crawler não para na primeira página. Ele:
- Identifica links internos (tipo “Ver Detalhes”, “Próxima Página” ou “Ver Mais”)
- Segue esses links para subpáginas, visualizações detalhadas ou até pop-ups
- Extrai dados de cada camada, juntando tudo em um único conjunto organizado
Essa estratégia, chamada de “crawling recursivo” ou “scraping em múltiplos níveis”, é essencial para sites onde as informações estão espalhadas em várias páginas — como listagens de produtos com páginas de detalhes ou diretórios em que o contato só aparece depois de um clique.
Lidando com Paginação e Conteúdo Dinâmico
Sites modernos adoram esconder dados atrás de botões “Carregar Mais”, rolagem infinita ou abas controladas por JavaScript. Deep crawlers são feitos para:
- Detectar e interagir com controles de paginação
- Rolar ou clicar em elementos dinâmicos
- Esperar o conteúdo carregar antes de puxar os dados
Assim, você consegue um conjunto de dados completo, e não só o que estava visível no início (Thunderbit Blog).
Rastreamento de Links Profundos e Scraping em Múltiplas Camadas
Um dos maiores desafios do deep crawling é garantir que nenhum dado escondido ou aninhado fique de fora. Deep crawlers usam algoritmos para:
- Controlar quais links já foram visitados (evitando duplicidade ou loops)
- Priorizar páginas importantes (como detalhes ou documentos para download)
- Lidar com casos especiais (pop-ups, seções expansíveis ou conteúdo carregado via AJAX)
Isso é fundamental para empresas — perder um contato ou especificação de produto pode significar oportunidades perdidas ou análises incompletas (Simplescraper).
Thunderbit: Deep Crawling Simplificado com IA
Antes, o deep crawling era coisa de desenvolvedor experiente e engenheiro de dados. Era preciso criar scripts próprios, tratar exceções e gastar horas ajustando o código a cada mudança no site. Com o Thunderbit, o deep crawling ficou acessível para todo mundo — até para quem nunca programou.
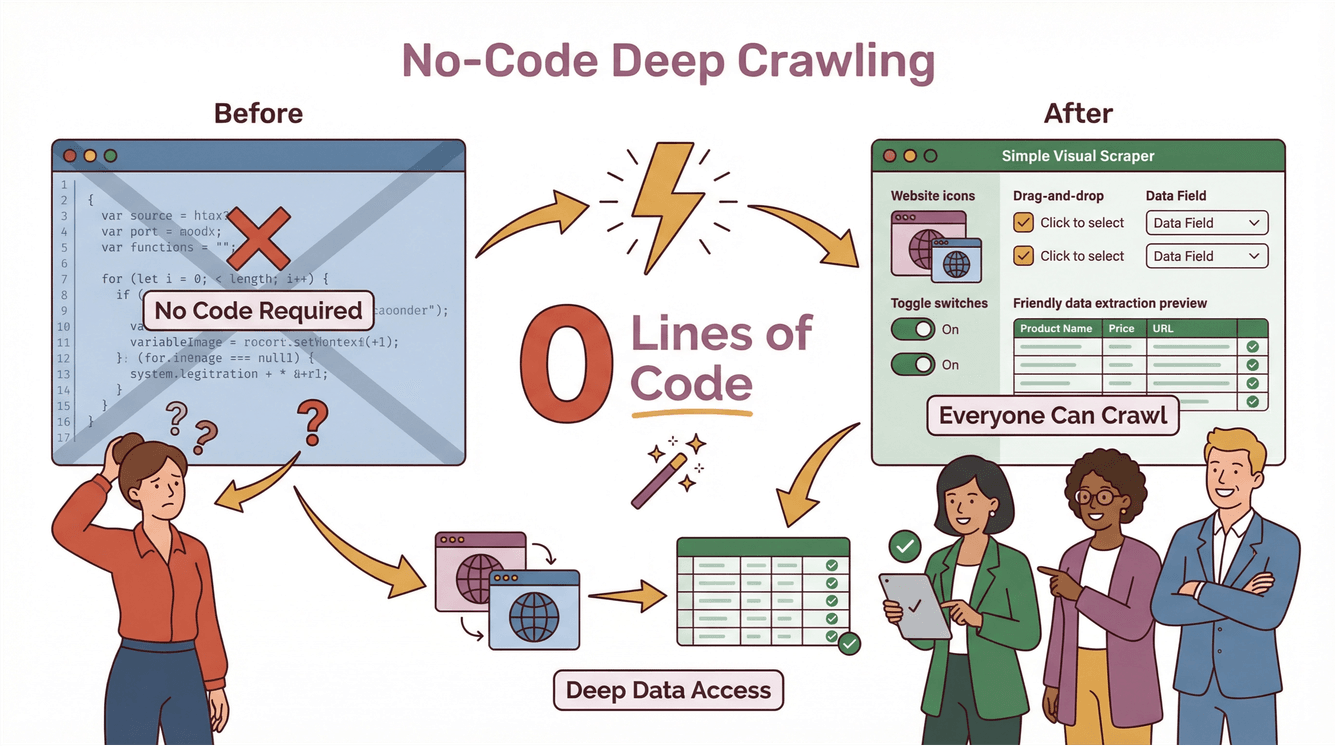
Como o Deep Crawler do Thunderbit Funciona na Prática
Veja como o Thunderbit facilita o deep crawling:
- AI Sugere Campos: Só clicar em “AI Sugere Campos” e a IA do Thunderbit analisa a página, sugere as melhores colunas para extrair e até cria prompts para cada campo.
- Raspagem de Subpáginas: Quer mais detalhes? O Thunderbit visita automaticamente cada subpágina (como detalhes de produtos, perfis de agentes ou abas de avaliações) e enriquece sua tabela com informações extras.
- Lida com Conteúdo Dinâmico: O Thunderbit interage com paginação, rolagem infinita e elementos dinâmicos — sem precisar configurar nada.
- Processo sem Código, em Dois Passos: Descreva o que quer, clique em “Raspar” e o Thunderbit faz o resto. Exporte seus dados direto para Excel, Google Sheets, Notion ou Airtable — sem taxas extras ou limites (Thunderbit Blog).
Teste o Deep Crawler do Thunderbit Gratuitamente
Exemplo Prático: Deep Crawling com Thunderbit
Imagina que você quer puxar todos os anúncios de imóveis de um site, incluindo os contatos dos corretores em subpáginas:
- Abra a página de listagens no Chrome.
- Clique na extensão Thunderbit.
- Use “AI Sugere Campos” para o Thunderbit recomendar colunas como “Título do Anúncio”, “Preço”, “Endereço” e “Link do Corretor”.
- Clique em “Raspar”. O Thunderbit coleta todas as listagens principais.
- Clique em “Raspar Subpáginas”. O Thunderbit visita cada perfil de corretor, extrai telefones, e-mails e outros dados, e integra tudo à sua tabela principal.
- Exporte os dados para Google Sheets ou Excel — pronto para sua equipe de vendas ou operações.
Sem código, sem templates, sem dor de cabeça. E se o site mudar, a IA do Thunderbit se adapta automaticamente (Thunderbit Docs).
Benefícios para Negócios: Como Deep Crawlers Impulsionam Vendas e Marketing
Legal, deep crawlers parecem interessantes — mas qual o valor real para o negócio? É aqui que a coisa fica boa.
Descobrindo Insights Valiosos em E-commerce, Imóveis e Concorrentes
Para equipes de vendas e marketing, deep crawlers são uma mina de ouro. Eles permitem:
- Extrair todos os produtos, preços e avaliações de e-commerces — mesmo que os dados estejam escondidos em várias camadas ou abas
- Agregação de anúncios imobiliários (incluindo informações escondidas de corretores ou detalhes de propriedades)
- Monitorar sites de concorrentes para novos produtos, mudanças de preço ou tendências de mercado (GetMonetizely)
- Construir listas de leads mais completas capturando contatos em diretórios, sites de eventos ou portais de nicho
Com o deep crawling, você não só coleta mais dados — mas dados melhores e mais úteis, que realmente fazem diferença nos resultados.
Deep Scraping para Inteligência Competitiva
Imagina que seu time de vendas quer abordar empresas que acabaram de lançar um novo produto. Um deep crawler pode:
- Vasculhar sites de concorrentes em busca de novas páginas de produtos
- Seguir links para comunicados de imprensa ou atualizações para investidores
- Extrair detalhes importantes (datas de lançamento, preços, funcionalidades)
- Enviar esses dados direto para seu CRM ou ferramentas de análise
O resultado? Decisões mais rápidas e inteligentes — e uma vantagem real sobre equipes que ainda dependem de raspagem superficial.
Conformidade e Boas Práticas: O que Observar ao Usar Deep Crawlers
Com grande poder de coleta vem grande responsabilidade. Deep crawlers podem acessar muitos dados — mas isso não significa que você deve puxar tudo. Fique de olho em:
Privacidade de Dados e Direitos Autorais
- Respeite os termos de uso dos sites: Muitos sites deixam claro o que pode ou não ser feito nos Termos de Serviço. Ignorar isso pode dar dor de cabeça jurídica (Apify Blog).
- Evite raspar dados pessoais ou confidenciais sem permissão explícita.
- Atenção aos direitos autorais: Não publique ou venda conteúdos raspados sem checar as permissões.
Raspagem Responsável
- Controle a frequência dos acessos: Não sobrecarregue os sites com muitas requisições ao mesmo tempo.
- Verifique o robots.txt: Não é obrigatório por lei, mas é uma boa prática respeitar as preferências de rastreamento dos sites.
- Esteja por dentro das leis: Regulamentos como GDPR e CCPA podem impactar o que você pode coletar e como usar os dados (Octoparse).
Para saber mais, veja Web Scraping é Legal em 2025?.
Como Escolher o Deep Crawler Ideal para sua Empresa
Veja os Preços do Thunderbit Deep crawling acessível para equipes de todos os tamanhos. Get Started Free
Como escolher o deep crawler certo? Olha o que vale a pena considerar:
- Facilidade de uso: Quem não é técnico consegue configurar rapidinho? (Thunderbit: sim.)
- Escalabilidade: Aguenta sites grandes, muitas páginas e conteúdo dinâmico?
- Ferramentas de conformidade: Ajuda a manter tudo dentro da lei?
- Integração: Dá para exportar os dados para as ferramentas que sua equipe já usa (Excel, Sheets, Notion, Airtable)?
- Manutenção: Se adapta automaticamente a mudanças nos sites ou você vai ter que ficar arrumando script toda semana?
O Thunderbit foi pensado para tudo isso. Já é usado por mais de 30.000 pessoas no mundo todo, de quem trabalha sozinho até grandes empresas, e tem preços acessíveis — a partir de só US$ 15/mês.
Comece o Deep Crawling com Thunderbit
Resumindo: O Futuro do Deep Crawling na Estratégia de Dados
Pra fechar:
- Deep crawlers são indispensáveis para extrair dados completos e precisos dos sites modernos e dinâmicos.
- Eles vão além dos crawlers tradicionais ao lidar com navegação em vários níveis, conteúdo dinâmico e dados escondidos.
- Equipes de negócios usam deep crawlers para obter insights, impulsionar vendas, monitorar concorrentes e tomar decisões mais rápidas.
- Conformidade é fundamental: Sempre raspe dados de forma responsável, respeite a privacidade e siga as regras.
- O Thunderbit democratiza o deep crawling, com IA, interface sem código e exportação fácil de dados.
Se você quer deixar a raspagem superficial para trás e começar a explorar mais fundo, baixe a extensão do Thunderbit para Chrome e veja como o deep crawling pode ser simples. Para mais dicas, acesse o Blog do Thunderbit e confira guias, boas práticas e novidades em web scraping com IA.
Perguntas Frequentes
1. O que é um deep crawler e como ele difere de um crawler comum?
Um deep crawler é uma ferramenta de raspagem web feita para navegar por várias camadas de um site, puxando dados de subpáginas, conteúdos dinâmicos e seções escondidas. Diferente dos crawlers tradicionais, que só pegam a superfície, os deep crawlers garantem uma coleta completa ao seguir links e lidar com estruturas complexas.
2. Por que empresas precisam de deep crawlers em 2025?
Os sites estão mais complexos do que nunca, com dados escondidos atrás de navegação, abas ou elementos dinâmicos. Deep crawlers ajudam empresas a extrair conjuntos de dados completos para vendas, marketing, pesquisa e inteligência competitiva — coisa que os crawlers básicos não conseguem.
3. Como o Thunderbit facilita o deep crawling para quem não é técnico?
O Thunderbit usa IA para sugerir campos, raspar subpáginas e lidar com conteúdo dinâmico — tudo numa interface simples, sem código. O usuário só descreve o que quer, clica em “Raspar” e exporta os resultados para suas ferramentas favoritas.
4. Quais questões de conformidade devo considerar ao usar um deep crawler?
Sempre respeite os termos de uso dos sites, evite raspar dados pessoais ou confidenciais sem permissão e fique atento a leis de privacidade como GDPR e CCPA. Raspagem responsável e uso ético dos dados são essenciais para evitar riscos legais.
5. Deep crawlers podem ajudar minha equipe de vendas e marketing a ter melhores resultados?
Com certeza. Deep crawlers liberam dados mais ricos e acionáveis de e-commerces, portais imobiliários e sites de concorrentes — impulsionando geração de leads, análise de mercado e decisões mais rápidas. Com ferramentas como o Thunderbit, até equipes não técnicas podem acessar os insights necessários para crescer.
Experimente o AI Deep Crawler do Thunderbit Get Started Free
Saiba Mais




