Se você já se perguntou como as empresas transformam uma montanha de dados brutos e espalhados em dashboards elegantes e insights com IA, não está sozinho. O segredo? Tudo começa com a ingestão de dados — o herói anônimo no início de todo processo de negócio orientado por dados. Num mundo em que estamos a gerar (isso são 21 zeros, se estiver a contar), levar dados do ponto A ao ponto B — de forma rápida, precisa e num formato utilizável — nunca foi tão crítico.
Passei anos a trabalhar com SaaS e automação e vi de perto como a estratégia certa de ingestão de dados pode fazer um negócio arrancar ou falhar. Seja para gerir leads de vendas, acompanhar tendências de mercado ou simplesmente manter as operações a funcionar sem atritos, perceber como a ingestão de dados funciona (e como está a evoluir) é o primeiro passo para desbloquear valor real para o negócio. Então, vamos lá: o que é ingestão de dados, porque é que isso importa e como ferramentas modernas — como — estão a mudar o jogo para toda a gente, de analistas a empreendedores?
O que é ingestão de dados? A base do negócio orientado por dados
No seu núcleo, ingestão de dados é o processo de recolher, importar e carregar dados de múltiplas fontes para um sistema central — pense num banco de dados, data warehouse ou data lake — para que possam ser analisados, visualizados ou usados para orientar decisões de negócio. Imagine isto como a “porta de entrada” do seu pipeline de dados: é assim que leva todos os ingredientes brutos (folhas de cálculo, APIs, logs, páginas web, feeds de sensores) para a cozinha antes de começar a preparar insights.
A ingestão de dados é a primeira etapa de qualquer pipeline de dados (), quebrando silos e garantindo que dados de alta qualidade e no momento certo estejam disponíveis para analytics, business intelligence e machine learning. Sem ela, as suas informações valiosas ficam presas em sistemas isolados — “invisíveis para as pessoas que delas precisam”, como disse um especialista do setor.
Veja como isto se encaixa no panorama geral:
- Ingestão de dados: recolhe dados brutos de várias fontes e leva-os para um repositório central.
- Integração de dados: combina e alinha dados de fontes diferentes, fazendo tudo funcionar em conjunto.
- Transformação de dados: limpa, formata e enriquece os dados para os deixar prontos para análise.
Pense na ingestão como trazer todas as compras para casa a partir de lojas diferentes. A integração é organizar tudo na despensa, e a transformação é preparar e cozinhar a refeição.
Por que a ingestão de dados importa para as organizações modernas
Vamos ser diretos: no mundo dos negócios de hoje, dados oportunos e bem ingeridos são um ativo estratégico. Empresas que dominam a ingestão de dados conseguem derrubar silos, viabilizar insights em tempo real e tomar decisões mais rápidas e inteligentes. No sentido oposto, uma ingestão fraca significa relatórios lentos, oportunidades perdidas e decisões baseadas em dados desatualizados ou incompletos.
Aqui estão algumas formas concretas de como uma ingestão eficiente gera valor para o negócio:
| Caso de uso | Como a ingestão eficiente de dados ajuda |
|---|---|
| Geração de leads de vendas | Consolida leads de formulários web, redes sociais e bases de dados num único sistema quase em tempo real — para que as equipas de vendas respondam mais depressa e aumentem as taxas de conversão. |
| Dashboards operacionais | Alimenta continuamente dados de sistemas de produção em plataformas de analytics, fornecendo KPIs atualizados para a gestão e permitindo ações corretivas rápidas. |
| Visão 360° do cliente | Integra dados de clientes em CRM, suporte, e-commerce e redes sociais para criar perfis unificados, possibilitando marketing personalizado e atendimento proativo (Cake.ai). |
| Manutenção preditiva | Ingere dados de sensores e IoT em alto volume, permitindo que modelos analíticos detetem anomalias e prevejam falhas antes de acontecerem — reduzindo tempo de inatividade e custos. |
| Análise de risco financeiro | Faz streaming de dados de transações e feeds de mercado para modelos de risco, oferecendo a bancos e traders uma visão em tempo real das exposições e viabilizando a deteção instantânea de fraudes. |
E os números não mentem: , mas esses investimentos só geram retorno se os dados puderem ser ingeridos e forem fiáveis.
Ingestão de dados vs. integração de dados e transformação de dados: esclarecendo a confusão
É fácil baralhar a terminologia — então vamos simplificar:
- Ingestão de dados: etapa inicial de recolher e importar dados brutos dos sistemas de origem. Pense: “Levar tudo para a cozinha”.
- Integração de dados: combinar e alinhar dados de fontes diferentes, garantindo consistência e uma visão unificada. Pense: “Organizar a despensa”.
- Transformação de dados: converter os dados de brutos para utilizáveis — limpando, formatando, agregando e enriquecendo. Pense: “Preparar e cozinhar a refeição”.
Um equívoco comum é achar que ingestão e ETL (Extract, Transform, Load) são a mesma coisa. Na prática, a ingestão é apenas a parte de “extract” — trazer os dados brutos para dentro. A integração e a transformação vêm depois, deixando os dados prontos para análise ().
Porque é que isto importa? Se só precisa de um conjunto de dados rápido a partir de uma página web, uma ferramenta leve de ingestão pode ser suficiente. Mas, se estiver a combinar e limpar dados de cinco sistemas diferentes, também vai precisar de integração e transformação.
Métodos tradicionais de ingestão de dados: ETL e as suas limitações
Durante décadas, o método padrão para ingestão de dados foi o ETL (Extract, Transform, Load). Engenheiros de dados escreviam scripts ou usavam software especializado para extrair periodicamente dados dos sistemas de origem, limpá-los e formatá-los e depois carregá-los num data warehouse. Isto normalmente corria em lote — pense em atualizações noturnas.
Mas, à medida que o volume e a variedade de dados explodiram, o ETL tradicional começou a mostrar a idade:
- Configuração complexa e demorada: construir e manter pipelines de ETL exigia muito código e competências especializadas. As equipas não técnicas tinham de esperar que a TI configurasse tudo ().
- Gargalos do processamento em lote: jobs de ETL corriam em lotes, atrasando a disponibilidade dos dados. Num mundo em que insights imediatos importam, esperar horas ou dias simplesmente não basta ().
- Problemas de escala e velocidade: pipelines legados muitas vezes lutavam para acompanhar os volumes massivos de dados de hoje, exigindo afinações e upgrades constantes.
- Rigidez e pouca flexibilidade: adicionar novas fontes de dados ou mudar esquemas era um problema, muitas vezes quebrando o pipeline ou exigindo muito retrabalho.
- Alto custo de manutenção: os pipelines podiam falhar por todo o tipo de motivos, exigindo atenção contínua dos engenheiros.
- Limitado a dados estruturados: o ETL clássico foi feito para linhas e colunas organizadas — não para os dados desarrumados e não estruturados (como páginas web ou imagens) que hoje representam .
Resumindo: o ETL foi ótimo para uma época mais simples, mas tem dificuldade em acompanhar a velocidade, a escala e a diversidade dos dados modernos.
A ascensão da ingestão moderna de dados: soluções automatizadas e orientadas por IA
Entra em cena a nova era: ferramentas modernas de ingestão de dados que usam automação, escalabilidade na nuvem e IA para tornar a recolha de dados mais rápida, fácil e flexível.
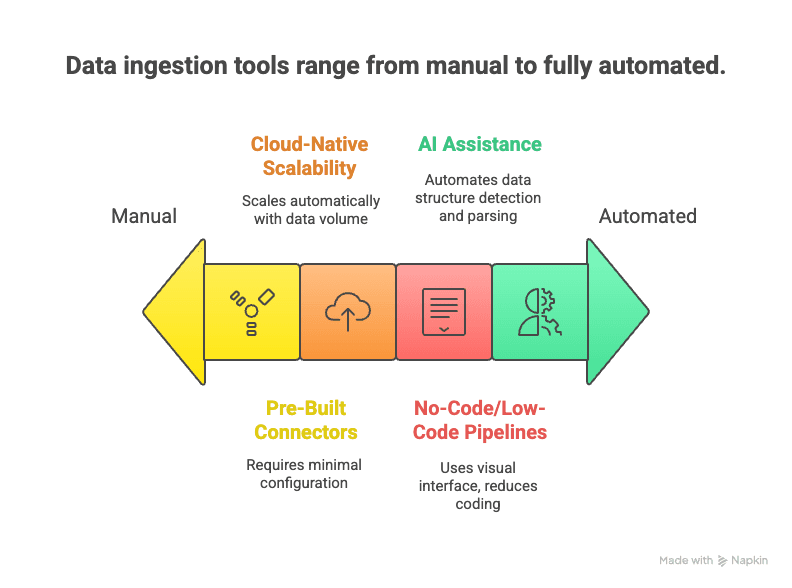
Veja o que as distingue:
- Pipelines no-code/low-code: interfaces de arrastar e largar e assistentes de IA permitem que os utilizadores configurem fluxos de dados sem escrever código ().
- Conectores prontos: centenas de conectores predefinidos para fontes populares de dados — basta introduzir as suas credenciais e avançar.
- Escalabilidade nativa da nuvem: serviços elásticos na nuvem conseguem lidar com enormes fluxos de dados em tempo real ().
- Suporte a tempo real e streaming: ferramentas modernas suportam ingestão por streaming e em lote, permitindo escolher o que faz mais sentido para a sua necessidade ().
- Assistência de IA: a IA pode detetar automaticamente estruturas de dados, recomendar regras de parsing e até fazer verificações de qualidade em tempo real ().
- Suporte a dados não estruturados: técnicas de NLP e visão computacional podem transformar páginas web, PDFs ou imagens desarrumadas em tabelas estruturadas.
- Menor manutenção: serviços geridos tratam da monitorização, da escala e das atualizações — para que se foque no uso dos dados, e não em andar a supervisionar pipelines.
O resultado? Uma ingestão de dados mais rápida de configurar, mais fácil de alterar e capaz de lidar com o mundo caótico dos dados de hoje.
Ingestão de dados em ação: aplicações por setor e desafios
Vamos ver como a ingestão de dados funciona no mundo real — e quais os desafios que diferentes setores enfrentam.
Varejo e e-commerce
Os retalhistas ingerem dados de sistemas de ponto de venda, lojas online, aplicações de fidelização e até sensores nas lojas físicas. Ao consolidar transações de vendas, cliques em sites e registos de stock, conseguem uma visão em tempo real dos níveis de inventário e das tendências de compra. O desafio? Lidar com o alto volume e a velocidade dos dados (especialmente em períodos de pico de compras) e integrar dados entre canais online e offline.
Finanças e bancos
Bancos e empresas de trading ingerem fluxos de dados de transações, feeds de mercado e interações com clientes. A ingestão em tempo real é crucial para deteção de fraude e gestão de riscos. Mas, com exigências rígidas de compliance e segurança, qualquer falha no processo de ingestão pode ter consequências sérias.
Empresas de tecnologia e internet
Gigantes da tecnologia ingerem enormes fluxos de eventos em tempo real (cada clique, like ou partilha) para analisar o comportamento do utilizador e alimentar motores de recomendação. A escala é gigantesca, e o desafio é separar o sinal do ruído — garantindo qualidade e consistência dos dados.
Saúde
Hospitais ingerem dados de registos eletrónicos de saúde, sistemas laboratoriais e dispositivos médicos para criar registos unificados de pacientes e permitir analytics preditivos. Os grandes obstáculos? Interoperabilidade (sistemas diferentes a falar “idiomas” diferentes) e privacidade do paciente.
Mercado imobiliário
Empresas do setor imobiliário ingerem dados de serviços de anúncios, sites de imóveis e registos públicos para construir bases de dados abrangentes. O desafio é combinar dados de várias fontes — muitas vezes não estruturadas — e mantê-los atualizados, já que os anúncios mudam rapidamente.
Desafios comuns entre setores incluem:
- Lidar com a variedade de dados (estruturados, semiestruturados, não estruturados)
- Equilibrar necessidades de tempo real e lote
- Garantir qualidade e consistência dos dados
- Cumprir requisitos de segurança e compliance
- Escalar para acompanhar o crescimento do volume de dados
Superar estes desafios é essencial para gerar melhores resultados de negócio — análises mais precisas, tomada de decisão em tempo real e compliance mais forte.
Thunderbit: simplificando a ingestão de dados com AI Web Scraper
Agora, vamos falar sobre onde o Thunderbit entra nesta história. é uma extensão Chrome de AI Web Scraper, desenvolvida para tornar a ingestão de dados da web acessível para toda a gente — mesmo que não saiba absolutamente nada de código.
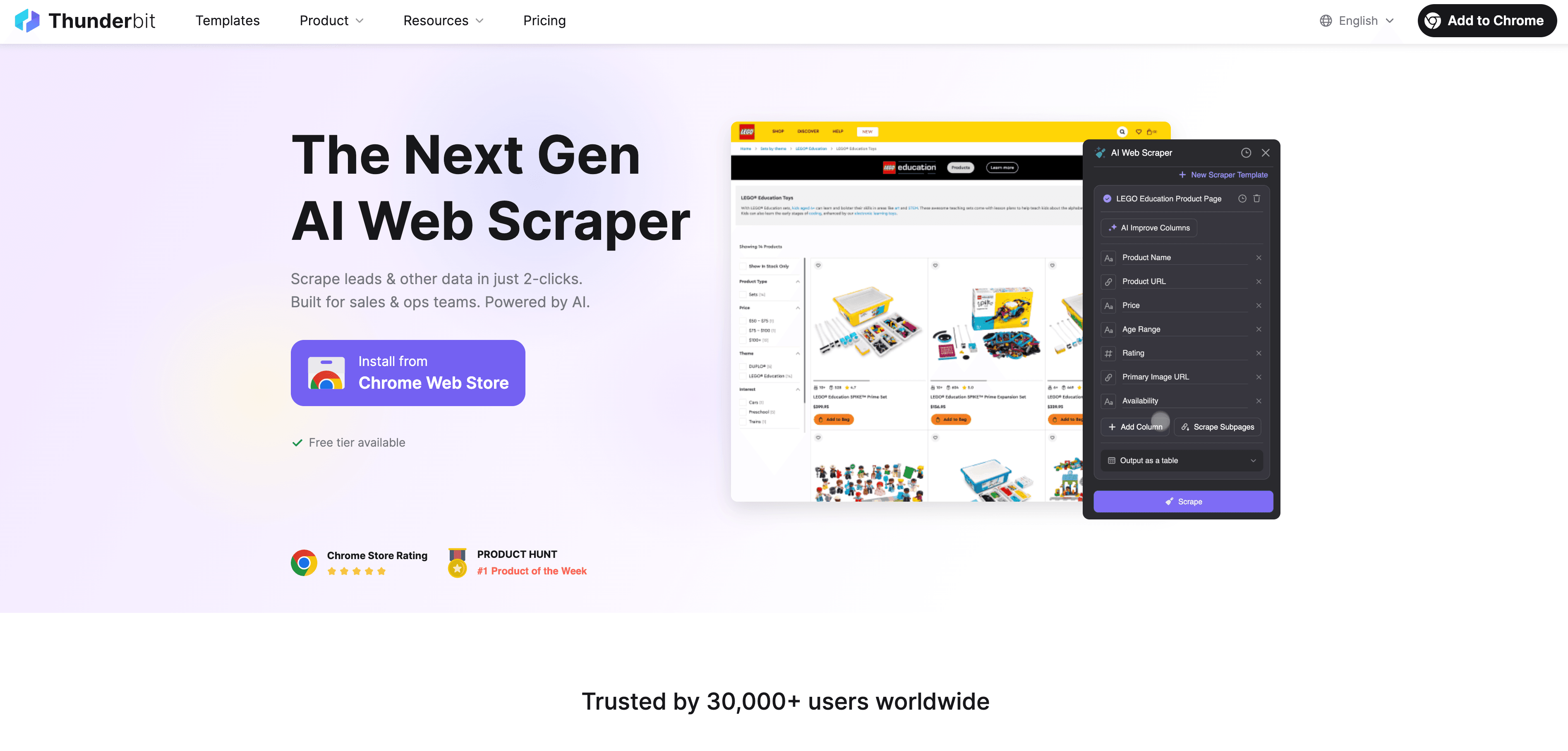
Veja por que o Thunderbit muda o jogo para utilizadores de negócio:
- Web scraping em 2 cliques: passe de uma página web desarrumada para um conjunto de dados estruturado em dois cliques. Clique em “AI Suggest Fields” e depois em “Scrape” — e já está.
- Sugestões de campos com IA: a IA do Thunderbit lê a página e recomenda as melhores colunas a extrair, quer esteja num diretório de empresas, numa listagem de produtos ou num perfil do LinkedIn.
- Scraping automático de subpáginas: precisa de mais detalhes? O Thunderbit pode visitar cada subpágina (como detalhes de produtos ou perfis individuais) e enriquecer a sua tabela automaticamente.
- Tratamento de paginação: lida com listas paginadas e páginas de rolagem infinita, para não perder nenhum dado.
- Modelos prontos: para sites populares como Amazon, Zillow ou Shopify, o Thunderbit oferece modelos de 1 clique — sem necessidade de configuração.
- Exportação gratuita de dados: exporte os seus dados diretamente para Excel, Google Sheets, Airtable ou Notion — sem custo extra.
- Scraping agendado: configure tarefas para correr automaticamente em qualquer intervalo (por exemplo, verificações diárias de preços da concorrência).
- AI Autofill: automatize também o preenchimento de formulários e tarefas repetitivas na web.
O Thunderbit é perfeito para equipas de vendas que extraem leads, analistas de e-commerce que monitorizam preços ou corretores imobiliários que recolhem listagens de imóveis. A proposta é transformar dados web não estruturados em insights acionáveis — rapidamente.
Se quiser ver o Thunderbit em ação, confira o nosso ou explore o nosso para mais guias.
Comparando soluções de ingestão de dados: abordagens tradicionais vs. modernas
Aqui vai uma comparação rápida lado a lado:
| Critério | Ferramentas ETL tradicionais | Ferramentas modernas de IA/nuvem | Thunderbit (AI Web Scraper) |
|---|---|---|---|
| Conhecimento do utilizador | Alto (exige código/TI) | Moderado (low-code, alguma configuração) | Baixo (2 cliques, sem código) |
| Fontes de dados | Estruturadas (bancos de dados, CSV) | Amplas (bancos de dados, SaaS, APIs) | Qualquer site, dados não estruturados |
| Velocidade de implementação | Lenta (semanas/meses) | Mais rápida (dias) | Instantânea (minutos) |
| Suporte em tempo real | Limitado (lote) | Forte (streaming/lote) | Sob demanda e agendado |
| Escalabilidade | Desafiadora | Alta (nativa da nuvem) | Moderada/alta (cloud scraping) |
| Manutenção | Alta (pipelines frágeis) | Média (serviços geridos) | Baixa (a IA adapta-se às mudanças) |
| Transformação | Rígida, antecipada | Flexível, pós-carga | Básica (prompts de campos por IA) |
| Melhor caso de uso | Integração interna em lote | Pipelines de analytics | Dados web, fontes externas |
A conclusão? Combine a ferramenta com a necessidade. Para dados da web ou fontes não estruturadas, o Thunderbit costuma ser a opção mais rápida e fácil.
O futuro da ingestão de dados: automação e estratégias cloud-first
Olhando para a frente, a ingestão de dados está a tornar-se cada vez mais inteligente e automatizada. Eis o que vem aí:
- Tempo real como padrão: o antigo paradigma em lote está a desaparecer. Mais pipelines estão a ser criados para dados em tempo real e orientados por eventos ().
- Cloud-first e “zero ETL”: plataformas em nuvem estão a tornar mais fácil ligar origens e destinos sem pipelines manuais.
- Automação orientada por IA: machine learning terá um papel maior na configuração, monitorização e otimização de pipelines — detetando anomalias, corrigindo erros e até enriquecendo dados em tempo real.
- No-code e autosserviço: mais ferramentas vão permitir que utilizadores de negócio configurem fluxos de dados com linguagem natural ou interfaces visuais.
- Ingestão na borda e IoT: à medida que mais dados são gerados na borda, a ingestão acontecerá mais perto da fonte, com filtragem e agregação inteligentes.
- Governança e metadados: tagging automático, rastreamento de linhagem e compliance estarão incorporados em cada etapa.
Em resumo: o futuro é tornar a ingestão de dados mais rápida, mais acessível e mais fiável — para que se foque nos insights, e não na infraestrutura.
Conclusão: principais aprendizados para utilizadores de negócio
- A ingestão de dados é a etapa inicial crítica em qualquer iniciativa orientada por dados. Se quer insights, precisa trazer os dados para dentro — de forma rápida e fiável.
- Ferramentas modernas com IA, como o Thunderbit, tornam a ingestão de dados acessível para todos, não apenas para profissionais de TI. Com scraping em 2 cliques, sugestões de campos por IA e tarefas agendadas, transforma dados web desarrumados em valor para o negócio.
- Escolher a ferramenta certa faz diferença: use ETL tradicional para dados internos estáveis e estruturados; ferramentas modernas de nuvem para analytics amplos; e o Thunderbit para dados web e não estruturados.
- Fique à frente da curva: automação, nuvem e IA estão a tornar a ingestão de dados mais inteligente e fácil. Não fique preso ao passado — explore novas soluções e prepare a sua estratégia de dados para o futuro.
Perguntas frequentes
1. O que é ingestão de dados, em palavras simples?
Ingestão de dados é o processo de recolher e importar dados de várias fontes (como sites, bases de dados ou ficheiros) para um sistema central, para que possam ser analisados ou usados em decisões de negócio. É a primeira etapa de qualquer pipeline de dados.
2. Qual é a diferença entre ingestão de dados, integração de dados e transformação?
Ingestão de dados é trazer os dados brutos para dentro. Integração de dados combina e alinha dados de diferentes fontes, enquanto transformação de dados limpa e formata esses dados para análise. Pense assim: ingestão = recolher; integração = organizar; transformação = preparar e cozinhar.
3. Quais são os maiores desafios dos métodos tradicionais de ingestão de dados?
Métodos tradicionais como ETL são lentos de configurar, exigem muito código, têm dificuldade com dados não estruturados e não acompanham as necessidades em tempo real de hoje. Além disso, dão bastante manutenção e são pouco flexíveis quando as fontes de dados mudam.
4. Como o Thunderbit torna a ingestão de dados mais fácil?
O Thunderbit usa IA para permitir que qualquer pessoa extraia e estruture dados da web em apenas dois cliques — sem necessidade de código. Lida com subpáginas, paginação e até tarefas recorrentes agendadas, exportando diretamente para Excel, Google Sheets, Airtable ou Notion.
5. Qual é o futuro da ingestão de dados?
O futuro está focado em automação, estratégias cloud-first e pipelines orientados por IA. Espere mais fluxos de dados em tempo real, tratamento de erros mais inteligente e ferramentas que permitam aos utilizadores de negócio configurar a ingestão de dados com linguagem natural ou interfaces visuais.
Saiba mais: