
Vamos falar a real: a internet é um verdadeiro labirinto que não para de crescer. Todos os dias, mais de 252.000 sites novos aparecem por aí, e só o Google já indexou mais de 30 bilhões de páginas. Se você já ficou curioso sobre como os buscadores conseguem acompanhar esse ritmo — ou como empresas acham informações valiosas nesse oceano de dados — saiba que não está sozinho. Mesmo depois de anos mexendo com SaaS e automação, ainda escuto muito: “Qual a diferença entre web crawling e web scraping? Não é tudo igual?” Já adianto: não é, e confundir os dois pode complicar (e muito) o seu projeto.
Seja você alguém de vendas atrás de leads, um gestor de e-commerce de olho nos preços da concorrência, ou só quer impressionar na próxima reunião, bora simplificar: o que faz um web crawler, como ele é diferente de um scraper e por que escolher a ferramenta certa (tipo a Thunderbit) pode te poupar muita dor de cabeça — e até salvar o seu fim de semana.
Web Crawler: O que é e para que serve?

Pensa naquele bibliotecário super detalhista, que não só organiza os livros, mas faz questão de passar por todas as prateleiras, todos os dias, só pra ver se tem novidade. É mais ou menos isso que um web crawler faz — só que, em vez de livros, ele navega por bilhões de páginas na internet. Um web crawler (também chamado de spider ou bot) é um programa automático que explora a web de forma organizada, pulando de link em link e catalogando tudo o que encontra. É assim que buscadores como Google e Bing montam seus enormes índices, deixando a web pesquisável pra todo mundo.
Se você já ouviu falar em “Googlebot” ou “Bingbot”, são exemplos clássicos de web crawlers trabalhando nos bastidores. Existem também soluções mais modernas, como a Firecrawl, que permitem a desenvolvedores e empresas rastrear sites inteiros e transformar tudo em dados organizados para IA ou análises.
Mas aqui está o ponto principal: crawling é sobre descobrir — encontrar e indexar páginas, não extrair dados específicos. É aí que entra o web scraping (já já falo disso).
Como funciona o Web Crawling?
Vamos acompanhar o “dia típico” de um web crawler. Imagina ele como um explorador digital com uma mochila cheia de “URLs sementes” — os pontos de partida. O processo é assim:
- URLs Sementes: O crawler começa com uma lista de endereços conhecidos.
- Buscar & Analisar: Ele visita cada URL, pega a página e procura por novos links.
- Seguir Links: Cada link novo vai pra lista de tarefas (a “fronteira” de URLs).
- Indexação: O crawler guarda informações sobre cada página — às vezes o conteúdo todo, às vezes só metadados.
- Respeito às Regras: Ele checa o arquivo robots.txt do site pra saber se pode rastrear, e faz pausas entre os acessos pra não sobrecarregar o servidor.
- Atualização Contínua: Como a web muda o tempo todo, crawlers revisitam páginas pra manter o índice atualizado.
É como mapear uma cidade andando por todas as ruas, anotando cada novo beco e loja, e atualizando o mapa sempre que algo muda.
Principais Componentes de um Web Crawler
Mesmo que você não seja da área técnica, vale a pena conhecer o básico:
- Fila de URLs (URL Frontier): A lista principal de endereços a serem visitados.
- Fetcher/Downloader: O componente que realmente baixa a página.
- Parser: O “leitor” que extrai links e, às vezes, outras informações da página.
- Filtro e Deduplicação: Evita que o crawler fique preso em loops ou visite a mesma página mais de uma vez.
- Armazenamento/Índice: Onde todo o conteúdo descoberto é guardado para uso futuro.
Pensa numa linha de montagem: um pega o jornal, outro destaca as manchetes, um terceiro arquiva os recortes, e alguém mantém a lista dos próximos jornais a buscar.
Como rastrear um site: Ferramentas e abordagens
Se você é do mundo dos negócios, pode até cogitar criar seu próprio crawler. Meu conselho? Não faça isso. A não ser que queira criar o próximo Google, já existem ferramentas prontas que fazem esse trabalho pesado.
Ferramentas populares de web crawling:
- Scrapy: Open source, voltada para desenvolvedores, ótima para projetos grandes.
- Apache Nutch: Usada para indexação de big data e pesquisas.
- Heritrix: Ferramenta da Internet Archive para arquivamento da web.
- Screaming Frog SEO Spider: Queridinha dos profissionais de SEO para rastrear e auditar sites.
- Firecrawl: Moderna, baseada em API, permite rastrear e extrair dados estruturados de sites inteiros.
Atenção: Muitas dessas ferramentas exigem configuração técnica. Mesmo as “no-code” podem ter uma curva de aprendizado — como selecionar elementos HTML, lidar com mudanças no site ou conteúdo dinâmico. Se você só quer extrair dados de algumas páginas, provavelmente não precisa de um crawler completo.
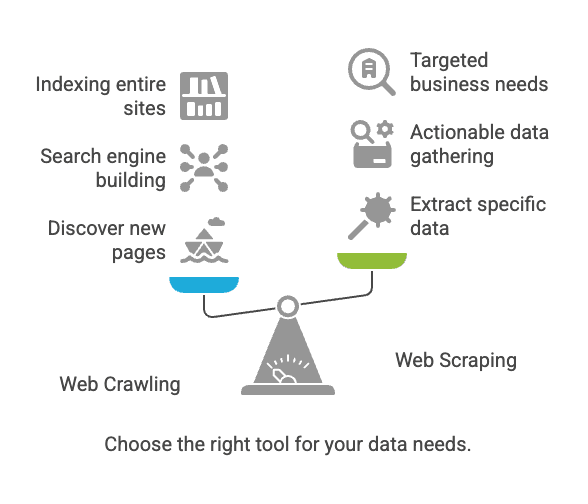
Web Crawling vs. Web Scraping: Qual a diferença?
Aqui começa a confusão. Crawling e scraping são parecidos, mas não são a mesma coisa.
| Aspecto | Web Crawling | Web Scraping |
|---|---|---|
| Objetivo | Descobrir e indexar páginas web | Extrair dados específicos das páginas |
| Analogia | Bibliotecário catalogando todos os livros | Copiando informações-chave de algumas páginas |
| Resultado | Lista de URLs, conteúdo das páginas, mapa do site | Dados estruturados (CSV, Excel, JSON etc.) |
| Usado por | Buscadores, ferramentas de SEO, arquivadores | Vendas, e-commerce, analistas, pesquisadores |
| Escala Típica | Bilhões de páginas (abrangente) | Dezenas a milhares de páginas (foco específico) |
Resumindo: Crawling serve para encontrar páginas; scraping serve para extrair os dados que você precisa (nimbleway.com).
Desafios comuns e boas práticas em Web Crawling e Scraping
Principais desafios
- Mudanças na estrutura do site: Pequenas alterações podem quebrar sua ferramenta (octoparse.com).
- Conteúdo dinâmico: Muitos sites carregam dados via JavaScript, o que crawlers básicos não conseguem acessar.
- Barreiras anti-bot: CAPTCHAs, bloqueios de IP e logins podem travar seu acesso.
- Escalabilidade: Rastrear milhares de páginas pode sobrecarregar seu computador (ou fazer seu IP ser bloqueado).
- Questões legais/éticas: Raspagem de dados públicos geralmente é permitida, mas sempre confira os termos do site e as leis de privacidade (web.instantapi.ai).
Boas práticas
- Escolha a ferramenta certa: Se não programa, comece com um raspador no-code.
- Defina seus objetivos de dados: Saiba exatamente o que precisa e por quê.
- Respeite as regras do site: Sempre confira o
robots.txte os termos de uso. - Evite sobrecarregar sites: Adicione intervalos entre os acessos; não sobrecarregue servidores.
- Planeje manutenção: Sites mudam — esteja pronto para ajustar sua configuração.
- Mantenha os dados limpos e seguros: Armazene resultados com segurança e revise duplicidades ou erros.
Principais usos: Crawling vs. Scraping
Web Crawling
- Indexação de buscadores: Googlebot e Bingbot rastreiam a web para manter os resultados atualizados (en.wikipedia.org).
- Arquivamento da web: A Internet Archive rastreia sites para o Wayback Machine.
- Auditoria de SEO: Ferramentas rastreiam seu site para encontrar links quebrados ou tags ausentes.
Web Scraping
- Monitoramento de preços: Lojas online extraem preços de concorrentes (nextgeninvent.com).
- Geração de leads: Equipes de vendas extraem contatos de diretórios.
- Agregação de conteúdo: Sites de notícias ou empregos reúnem listas de várias fontes.
- Pesquisa de mercado: Analistas extraem avaliações ou dados de redes sociais para análise de sentimento.
Curiosidade: Mais de 82% das empresas de e-commerce usam web scraping para obter dados externos. Se você não faz, seus concorrentes provavelmente fazem.
Quando usar Web Crawling ou Web Scraping?
Veja um checklist rápido:
-
Precisa descobrir novas páginas ou mapear um site inteiro?
→ Use web crawling.
-
Já sabe onde estão os dados (páginas ou seções específicas)?
→ Use web scraping.
-
Vai criar um buscador ou arquivar a web?
→ Crawling é o caminho.
-
Quer dados práticos para vendas, preços ou pesquisa?
→ Scraping é a melhor escolha.
-
Ainda está em dúvida?
→ Comece pelo scraping. A maioria das necessidades de negócios não exige crawling em larga escala.
Se você é do mundo dos negócios, provavelmente precisa de scraping — dados organizados e prontos pra usar.
Web Scraping para negócios: O diferencial da Thunderbit
Agora, vamos ao motivo pelo qual a maioria dos profissionais — especialmente quem não é técnico — deve focar em scraping, e por que a Thunderbit foi feita pra você.
Já vi muita equipe perder dias (ou semanas) tentando usar ferramentas de scraping “fáceis” que, na prática, são bem complicadas. Por isso criamos a Thunderbit: pra deixar a extração de dados web tão simples quanto dois cliques.
Veja o que a Thunderbit oferece:
- Fluxo em dois cliques: Clique em “AI Sugerir Campos” e depois em “Raspar”. Pronto. Sem códigos, sem ajustes manuais.
- Suporte a URLs e PDFs em massa: Precisa extrair dados de várias URLs ou até de PDFs? A Thunderbit resolve.
- Exportação para qualquer lugar: Envie seus dados direto para Google Sheets, Airtable, Notion ou baixe em CSV/JSON. Sem taxas extras.
- Raspagem de subpáginas: A Thunderbit visita subpáginas automaticamente (como detalhes de produtos) e enriquece sua tabela de dados.
- Preenchimento automático com IA: Automatize preenchimento de formulários e tarefas repetitivas — é como ter um assistente digital para o trabalho chato.
- Extratores gratuitos de e-mail e telefone: Capture todos os contatos de uma página com um clique.
- Raspagem na nuvem ou no navegador: Escolha o que preferir — a Thunderbit pode raspar na nuvem (super rápido) ou no navegador (ótimo para páginas logadas).
- Zero curva de aprendizado: Feita para equipes de vendas, e-commerce e marketing que querem resultado sem complicação.
Quer ver exemplos práticos? Confira nossos guias sobre raspar produtos da Amazon, raspar resultados do Google ou extrair dados para o Excel.
Raspe qualquer site com IA em 2 cliques
Thunderbit vs. Raspador Web Tradicional
Veja a comparação lado a lado pra quem busca praticidade:
| Funcionalidade/Objetivo | Thunderbit | Raspador Web Tradicional (ex: Scrapy, Nutch) |
|---|---|---|
| Configuração | 2 cliques, sem código | Configuração técnica, geralmente exige scripts |
| Curva de aprendizado | Mínima | Alta (principalmente para não programadores) |
| Subpáginas | Automático, com IA | Manual ou configuração avançada |
| URLs/PDFs em massa | Suporte nativo | Normalmente não suportado |
| Formatos de saída | Google Sheets, Airtable, Notion, CSV | CSV, JSON (integração manual) |
| Adaptação | IA se ajusta a mudanças no site | Atualização manual necessária |
| Casos de uso de negócios | Vendas, e-commerce, SEO, operações | Indexação de buscadores, pesquisa, arquivamento |
| Agendamento | Linguagem natural | Cron jobs ou agendadores externos |
| Preço | A partir de R$ 15/mês, plano gratuito disponível | Gratuito/open source, mas exige mais tempo e manutenção |
| Suporte | Foco no usuário, interface moderna | Suporte comunitário, voltado para desenvolvedores |
A Thunderbit foi feita pra te levar do “preciso desses dados” ao “aqui está minha planilha” no menor tempo possível — sem depender do pessoal de TI.
Conclusão: Como escolher a abordagem certa para seu negócio

Resumindo:
- Web crawling serve pra descobrir e indexar páginas — ideal pra buscadores e auditorias de sites.
- Web scraping é pra extrair dados específicos e práticos — como leads, monitoramento de preços ou agregação de conteúdo.
- Pra maioria dos negócios, scraping é o que resolve. E não precisa saber programar pra isso.
A web só cresce e fica mais complexa. Mas, com a abordagem e a ferramenta certas, você transforma esse caos em informação útil. Se está cansado de ferramentas complicadas ou de depender do TI, experimente a Thunderbit. Você vai se surpreender com o que dá pra fazer em só dois cliques (e, quem sabe, ainda sobra tempo pra curtir o fim de semana).
Quer ver a Thunderbit funcionando? Instale nossa extensão para Chrome ou confira mais dicas e tutoriais no Blog da Thunderbit.
Instalar extensão Thunderbit para Chrome
Boas raspagens (e só se aventure no crawling se for criar o próximo Google)!
Perguntas Frequentes
1. Preciso de um web crawler e de um scraper para minha empresa?
Nem sempre. Se você já sabe em quais páginas estão os dados que precisa, um raspador web como a Thunderbit resolve. Crawlers são úteis quando é preciso descobrir novas páginas — tipo mapear um site inteiro ou fazer auditorias de SEO.
2. Web scraping é legal?
No geral, raspar dados públicos é permitido — principalmente se você não está burlando logins, violando termos de uso ou coletando informações sensíveis. Mas sempre confira o arquivo robots.txt e a política de privacidade do site, principalmente para uso comercial.
3. O que diferencia a Thunderbit de outras ferramentas de scraping?
A Thunderbit foi feita pra quem não programa. Diferente dos raspadores tradicionais, que exigem conhecimento de HTML ou configuração manual, a Thunderbit usa IA pra identificar campos, navegar por subpáginas e entregar os dados no formato que você precisa — tudo em dois cliques.
4. A Thunderbit funciona com sites dinâmicos e páginas logadas?
Sim. A Thunderbit oferece raspagem via navegador para sessões logadas e conteúdo dinâmico, além de raspagem na nuvem para mais velocidade e escala. Você escolhe o modo ideal para o tipo de dado que busca.
Leituras recomendadas
- O que é Data Scraping e como fazer em 2025
- Quantos sites existem no mundo?
- O que é um web crawler? | Como funcionam os spiders | Cloudflare
Teste o Raspador Web IA gratuitamente Get Started Free




