
Sempre que você sincroniza seu CRM, puxa atualizações de envio ou conecta duas ferramentas SaaS, uma API REST está fazendo o trabalho pesado nos bastidores. A maioria das pessoas nem pensa nisso — até algo quebrar.
O curioso é que, até entre desenvolvedores, existe uma confusão real sobre o que torna uma API "RESTful". O termo é usado com tanta liberdade que um tópico no Reddit resumiu sem rodeios: "Não acho que tenha construído uma única API verdadeiramente RESTful com base na definição de Roy Fielding." E isso dito por um desenvolvedor, não por um usuário de negócios. O conceito surgiu na de Roy Fielding na UC Irvine, onde ele descreveu REST como um estilo arquitetural — um conjunto de restrições de design — e não um protocolo, não um produto, nem uma especificação para baixar.
Ainda assim, segundo o , o uso de REST chega a 93% entre profissionais de API. Ou seja, quase todo mundo usa, mas uma quantidade surpreendente de equipes não entende o que ele realmente exige. Este artigo vai explicar as 6 características centrais de uma API REST em linguagem simples, mostrar quais delas a maioria das equipes interpreta errado, apresentar um modelo de maturidade para você se avaliar e comparar REST com alternativas — SOAP, GraphQL e gRPC.
O que é uma API REST? (Uma definição em linguagem simples)
REST (Representational State Transfer) é um conjunto de regras de design sobre como sistemas de software devem se comunicar por uma rede.
Mais precisamente, trata-se de um estilo arquitetural que define restrições — como ausência de estado, capacidade de cache e interface uniforme — que orientam a forma como clientes (seu navegador, app móvel ou ferramenta de automação) interagem com servidores (onde os dados vivem). O REST normalmente roda sobre HTTP e costuma retornar JSON, mas o REST em si não está preso a um protocolo ou formato de dados específico.
Pense nisso como regras de etiqueta de um jantar. O REST não diz qual comida você serve nem qual idioma você fala — ele define como você passa os pratos, como pede mais uma porção e como sinaliza que terminou. Dois sistemas que seguem a mesma etiqueta conseguem se comunicar de forma previsível, mesmo sem nunca terem se encontrado.
O que REST NÃO é: REST não é um produto que você instala. Não é um protocolo como HTTP ou SOAP. E chamar uma API de "RESTful" não significa que ela cumpra totalmente as restrições originais de Fielding — normalmente só quer dizer que a API usa URLs de recursos e métodos HTTP. A diferença entre "REST-ish" e "verdadeiramente RESTful" é uma das maiores fontes de confusão do setor, e vamos abordar isso em seguida.
As 6 características de uma API REST em resumo
Antes de aprofundar, aqui vai o resumo rápido. Fielding definiu 6 restrições que uma API deve seguir para ser considerada RESTful. Cinco são obrigatórias; uma é opcional.
This paragraph contains content that cannot be parsed and has been skipped.
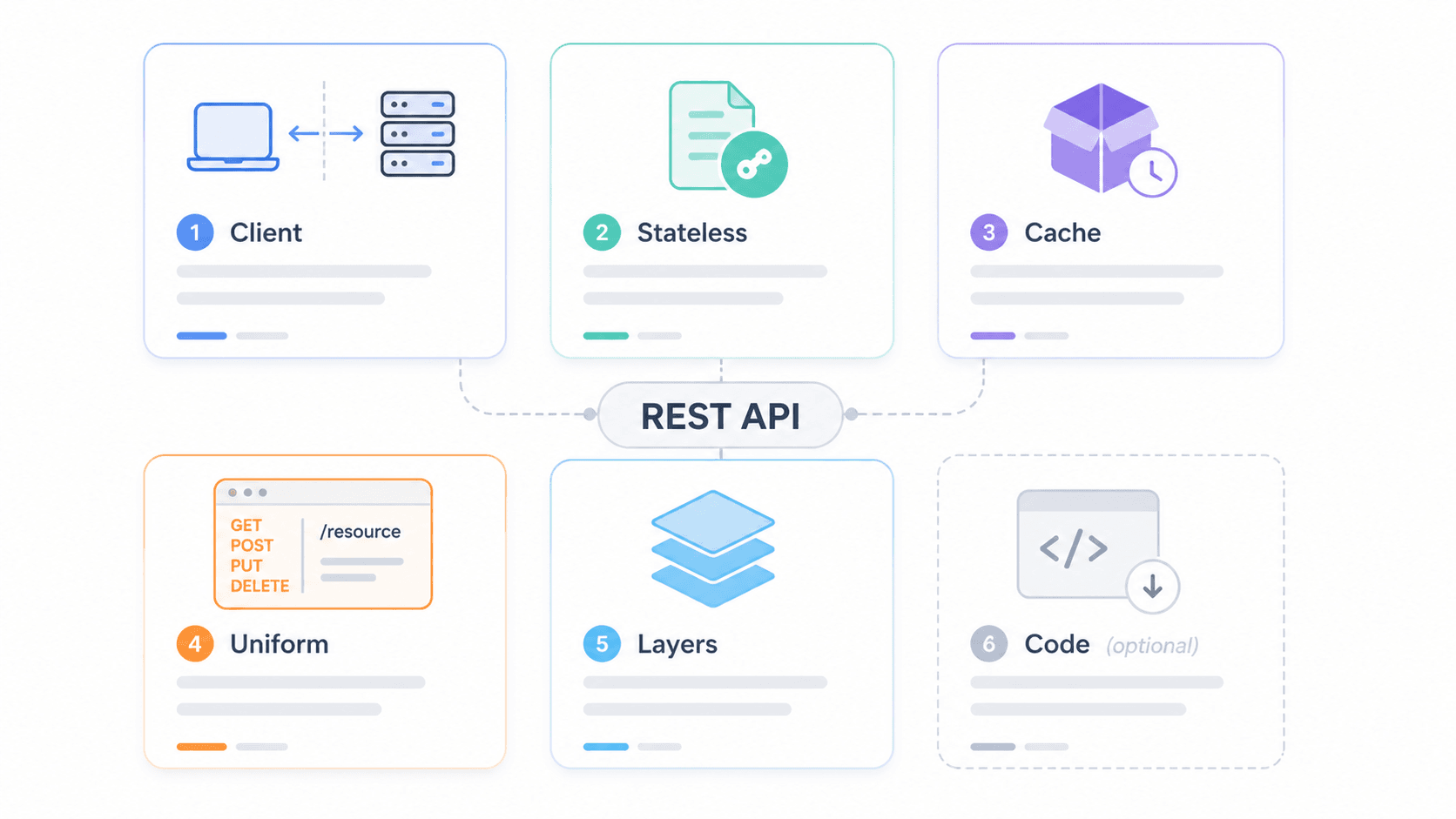
Para visualizar como essas restrições funcionam juntas em um sistema real, imagine esta arquitetura em camadas:
1Cliente / App móvel
2 ↓
3CDN / Cache de borda (por exemplo, Cloudflare)
4 ↓
5API Gateway (limitação de taxa, autenticação, CORS)
6 ↓
7Balanceador de carga
8 ↓
9Servidores de aplicação
10 ↓
11Banco de dados / Serviços internosO cliente fala apenas com a camada CDN. Ele não faz ideia de quantas camadas existem por trás. Essa é a restrição de sistema em camadas em ação — e também onde segurança, cache e escalabilidade acontecem sem que o cliente precise saber.
Agora, a análise detalhada.
As características de uma API REST explicadas, uma por uma
Separação cliente-servidor
A primeira restrição de Fielding: o cliente (com o que os usuários interagem) e o servidor (onde os dados vivem e a lógica é executada) precisam ser separados. Ele chamou isso de separação de responsabilidades.
Por que isso importa na prática? Porque significa que um app bancário móvel pode ganhar uma reformulação visual completa sem que o banco mexa no banco de dados de contas ou no motor de transações. A , por exemplo, expõe contatos, campanhas, jornadas e notificações push por meio de endpoints de recursos. Se você está construindo um painel personalizado, um app móvel ou conectando uma ferramenta de terceiros, o back-end permanece o mesmo.
Para equipes de negócios, isso se traduz em iteração mais rápida. Seus designers de front-end e engenheiros de back-end não precisam seguir o mesmo ciclo de lançamento. Enquanto o contrato da API estiver estável, os dois lados podem avançar de forma independente.
Sem estado
Sem memória entre requisições. Toda chamada do cliente ao servidor precisa incluir todas as informações de que o servidor precisa para processá-la — o servidor não guarda nada das interações anteriores.
Gosto de pensar nisso como ligar para uma central de suporte e ter que reexplicar seu problema toda vez. Chato? Sem dúvida. Mas a vantagem é enorme: qualquer atendente disponível pode ajudar, e o call center pode contratar mais 500 agentes sem precisar redesenhar nada. Isso é escalabilidade horizontal.
Em termos técnicos, ausência de estado significa não usar sticky sessions. Um balanceador de carga pode direcionar sua próxima requisição para qualquer servidor saudável. Se um servidor cair, outro assume sem perder o ritmo. A tese de Fielding que a ausência de estado melhora a visibilidade (ferramentas de monitoramento conseguem entender cada requisição isoladamente), a confiabilidade (falhas não corrompem o estado compartilhado da sessão) e a escalabilidade (os servidores podem liberar recursos entre requisições).
A ressalva prática: sistemas reais ainda têm tokens de autenticação, carrinhos de compra e fluxos OAuth. O ponto não é que nenhum estado exista em lugar nenhum — é que o servidor não armazena o estado de sessão do cliente na própria memória entre requisições. Em vez disso, quem lida com isso são tokens, bancos de dados e caches compartilhados.
Capacidade de cache
Esta resposta pode ser reutilizada? Essa é a pergunta que a cacheabilidade responde. As respostas devem declarar explicitamente se podem ser armazenadas em cache e, se sim, clientes e intermediários (como CDNs) as reutilizam em requisições futuras equivalentes — reduzindo a carga no servidor e melhorando a velocidade.
O mecanismo HTTP é simples: cabeçalhos como Cache-Control, ETag, Last-Modified e Expires dizem aos caches por quanto tempo uma resposta é válida e quando devem verificá-la novamente. Para quem lê de negócio, pense nisso como um rótulo na resposta dizendo "esta resposta vale pelas próximas horas" ou "sempre me pergunte de novo".
O impacto no desempenho é real. Os testes do relataram melhora de 50–100 ms nos tempos de resposta do cache em cauda longa. E a própria tese de Fielding documenta como o tráfego da Web cresceu de 100.000 requisições/dia em 1994 para 600.000.000 requisições/dia em 1999 — com o cache como fator crítico de design.
O que normalmente pode ser cacheado: catálogos de produtos, conteúdo público de blog, listas de países/moedas, documentação de API.
O que normalmente não pode ser cacheado: painéis pessoais, totais do checkout, saldos bancários, relatórios administrativos.
Interface uniforme
Esta é a restrição que o próprio Fielding chamou de principal característica que distingue REST de outros estilos arquiteturais. Ela padroniza como os clientes interagem com os recursos, tornando as APIs previsíveis.
Quatro sub-restrições fazem parte disso:
- Identificação de recursos: todo recurso recebe um URI estável.
/customers/123é um cliente./orders/456é um pedido. - Manipulação por meio de representações: os clientes trabalham com representações (JSON, XML, HTML) dos recursos, e não com os objetos internos do servidor.
- Mensagens autoexplicativas: requisições e respostas carregam metadados suficientes — método, código de status, tipo de conteúdo, detalhes do erro — para que qualquer intermediário ou cliente possa entendê-las.
- HATEOAS (Hypermedia as the Engine of Application State): as respostas incluem links para ações e recursos relacionados, permitindo que os clientes descubram o próximo passo sem precisar codificar manualmente cada endpoint.
O mapeamento dos métodos HTTP é a parte mais visível da interface uniforme:
| Método HTTP | Significado CRUD | É seguro? | É idempotente? | Exemplo |
|---|---|---|---|---|
| GET | Ler | Sim | Sim | GET /products/42 |
| POST | Criar / ação | Não | Não | POST /orders |
| PUT | Substituir o recurso inteiro | Não | Sim | PUT /users/42 |
| PATCH | Atualização parcial | Não | Não garantido | PATCH /users/42 |
| DELETE | Excluir | Não | Sim | DELETE /sessions/abc |
As afirmam explicitamente que GET deve ser seguro, e que GET, PUT e DELETE devem ser idempotentes. APIs conhecidas da GitHub, Stripe e Spotify seguem esses padrões de perto, e é por isso que desenvolvedores que aprendem uma conseguem pegar outra rapidamente.
Sistema em camadas
Seu cliente não faz ideia se está falando com o servidor de origem, um cache de CDN, uma API gateway ou um balanceador de carga. E esse é o ponto — cada componente vê apenas a camada adjacente.
Isso é o que permite:
- CDNs como a Cloudflare ficarem à frente da sua API para armazenar em cache e acelerar respostas
- API gateways (AWS API Gateway, Kong, Apigee) lidarem com autenticação, limitação de taxa e cotas
- Balanceadores de carga distribuírem requisições sem estado entre vários servidores de aplicação
O observa que usam AWS API Gateway, 26% usam o gateway da Azure e 31% usam múltiplos gateways ao mesmo tempo. Arquitetura em camadas não é teoria — é assim que sistemas de produção realmente funcionam.
A troca: cada camada adiciona uma pequena latência. Mas Fielding argumentava que o cache compartilhado em camadas intermediárias compensa amplamente esse custo na maioria dos sistemas do mundo real.
Código sob demanda (opcional)
Esta é a exceção. Código sob demanda é a única restrição opcional do REST: o servidor pode enviar código executável — como JavaScript — para ampliar a funcionalidade do cliente em tempo real.
O exemplo mais comum no mundo real é simplesmente uma página web carregando JavaScript de um servidor. Mas, para APIs REST JSON típicas consumidas por apps móveis, jobs de back-end ou ferramentas de automação, código sob demanda quase nunca é usado. Em geral, clientes de API não querem executar código arbitrário de um servidor remoto.
Para a maioria dos leitores, essa restrição é um detalhe. Ela existe no modelo de Fielding por completude, mas não vai pesar nas suas avaliações de API no dia a dia.
O que a maioria erra: a maioria das APIs REST é realmente RESTful?
Aqui está a parte que ninguém gosta de discutir: a maioria das APIs de produção que se chamam "RESTful" são, na verdade, APIs HTTP JSON com convenções parecidas com REST. Elas usam URLs de recursos, métodos HTTP e códigos de status — e só. Um tópico no Reddit em r/softwarearchitecture teve desenvolvedores admitindo que nunca tinham construído uma API REST realmente compatível com Fielding. Outra discussão em r/learnprogramming descambou para debates sobre se alguém consegue sequer concordar sobre o que "RESTful" significa.
Um estudo de 2026 entrevistando 16 especialistas em APIs REST descobriu que, embora as diretrizes melhorem a usabilidade, os desenvolvedores demonstram resistência significativa a regras REST rígidas — citando o tamanho das diretrizes e o baixo encaixe com suas organizações específicas como barreiras.
Então, como essas restrições se comportam na prática?
| Restrição | Adoção na prática | Por quê |
|---|---|---|---|
| Cliente-servidor | ✅ Quase universal | Fundamental para a arquitetura da web; difícil de evitar |
| Sem estado | ✅ Quase universal | Necessário para escalabilidade horizontal; prática padrão |
| Interface uniforme (básica) | ✅ Comum | URI de recursos + verbos HTTP são o padrão |
| Capacidade de cache | ⚠️ Inconsistente | Muitas equipes ignoram completamente cabeçalhos Cache-Control |
| Sistema em camadas | ⚠️ Implícito | CDNs e gateways existem, mas nem sempre são projetados de forma deliberada |
| HATEOAS | ❌ Raro | A maioria dos clientes codifica endpoints manualmente; descoberta por links adiciona complexidade |
| Código sob demanda | ❌ Muito raro | Opcional por definição; quase nunca implementado em APIs JSON |
Por que as equipes pulam o HATEOAS: desenvolvedores do cliente preferem ler documentação OpenAPI e usar SDKs em vez de seguir links dinamicamente em tempo de execução. HATEOAS exige tipos de mídia estáveis, definições de relações de links e modelagem de fluxo de trabalho — o custo de curto prazo é alto, e o retorno não é claro para a maioria das equipes.
A conclusão pragmática: uma API não precisa ser 100% compatível com Fielding para ser útil. Mas saber quais restrições você deixou de lado — e o que perde ao deixá-las de lado — ajuda a tomar decisões melhores de design e integração.
O modelo de maturidade Richardson: quão RESTful sua API realmente é?
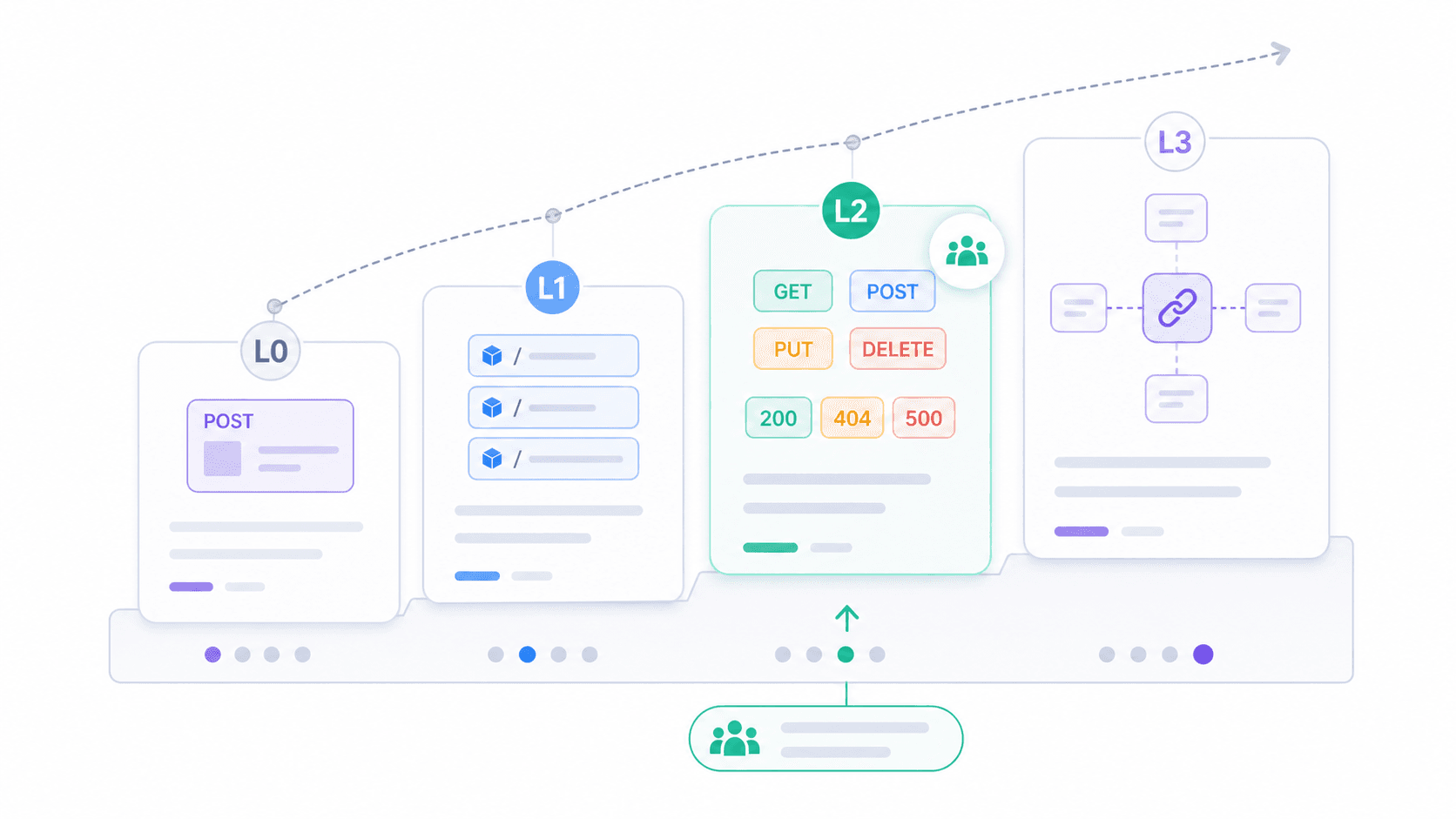
Se a pergunta binária "é RESTful ou não?" parece pouco útil, o Modelo de Maturidade Richardson oferece uma estrutura mais prática. Proposto por Leonard Richardson e , ele divide a adoção de REST em quatro níveis.
| Nível | Nome | Descrição | Exemplo no mundo real |
|---|---|---|---|
| 0 | O pântano de POX | URI única, verbo HTTP único (geralmente POST) | Endpoints legados SOAP-over-HTTP; POST /api com { "action": "getUser" } |
| 1 | Recursos | Vários URIs (um por recurso), mas ainda majoritariamente POST | POST /users/123/getProfile, POST /orders/456/cancel |
| 2 | Verbos HTTP | Uso correto de GET, POST, PUT, DELETE + códigos de status apropriados | A maioria das APIs "REST" em produção hoje |
| 3 | Hipermídia (HATEOAS) | As respostas incluem links para ações/recursos relacionados | Spring Data REST, APIs baseadas em HAL; poucas APIs públicas na prática |
A maioria das APIs que você encontrará no mundo real está no Nível 2. Elas usam recursos, verbos e códigos de status corretamente. Isso já é suficiente para ser prático, interoperável e bem suportado por ferramentas. O Nível 3 é a visão completa de Fielding, mas a adoção ainda é limitada.
Em que nível está a sua API? Pergunte a si mesmo:
- A API tem um endpoint único para tudo? (Nível 0)
- Cada objeto de negócio tem sua própria URI? (Nível 1+)
- Os métodos HTTP e códigos de status estão sendo usados corretamente? (Nível 2)
- As respostas dizem ao cliente o que ele pode fazer em seguida, sem depender de documentação externa? (Nível 3)
Esse modelo é a ferramenta mais útil que encontrei para cortar o debate sobre "é REST ou não". Ele troca um julgamento binário por um espectro.
Erros comuns em APIs REST (e como evitá-los)
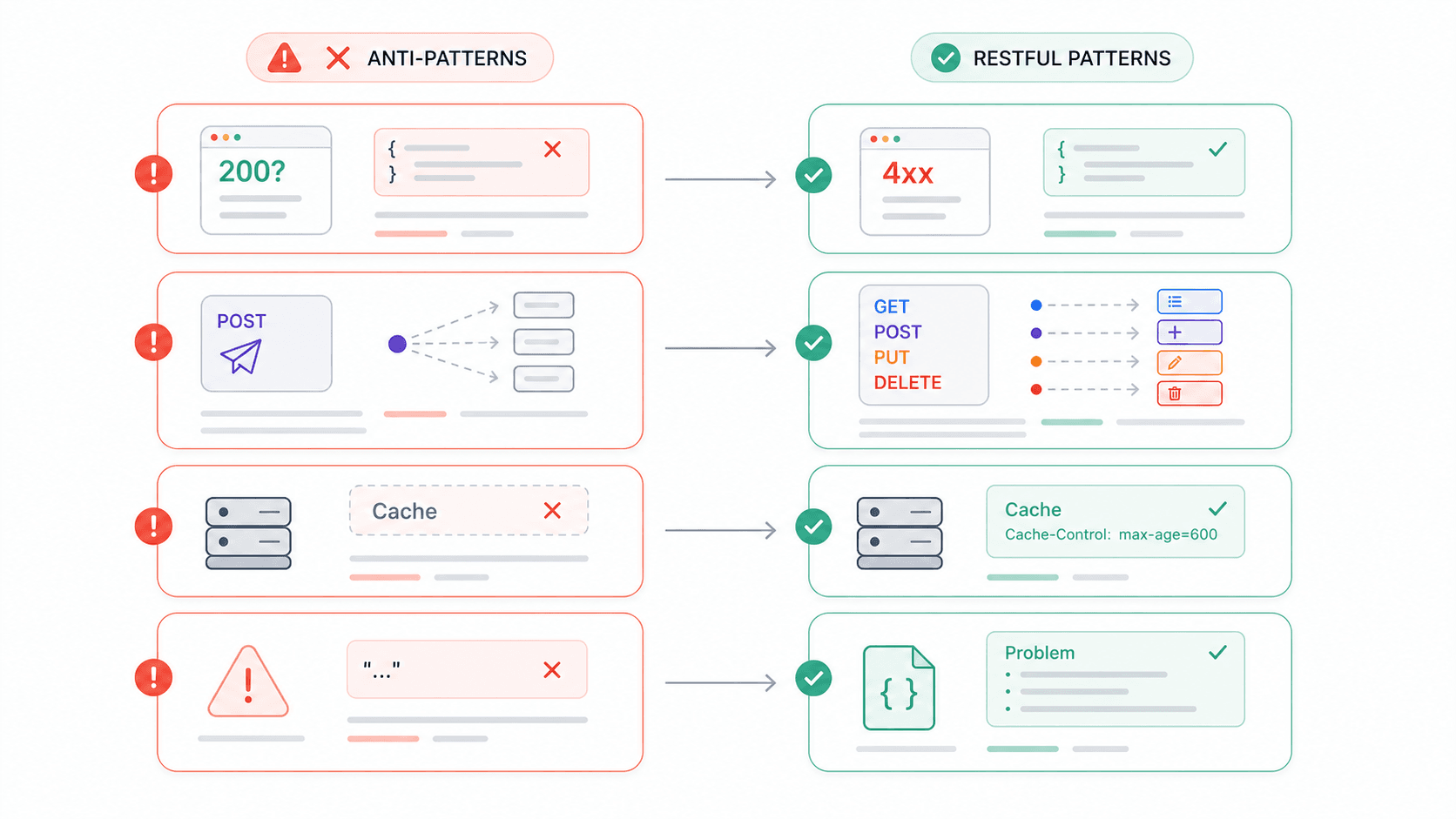
Já passei tempo suficiente integrando APIs de terceiros para ter uma lista viva de frustrações. E, pelos fóruns de desenvolvedores, não estou sozinho. Aqui estão os antipadrões que aparecem com mais frequência — e cada um se relaciona diretamente à violação de uma restrição REST.
| Antipadrão | Por que quebra o REST | O que fazer em vez disso |
|---|---|---|---|
| HTTP 200 com corpo de erro ({ "error": "Invalid username" }) | Viola mensagens autoexplicativas; os clientes não podem confiar nos códigos de status | Use códigos 4xx/5xx apropriados + um corpo de erro estruturado (por exemplo, application/problem+json) |
| POST para tudo | Ignora a interface uniforme; perde a semântica de segurança/idempotência | Mapeie CRUD para GET/POST/PUT(PATCH)/DELETE |
| Sem cabeçalhos Cache-Control | Desperdiça completamente a restrição de cacheabilidade | Defina diretivas de cache explícitas — até mesmo no-store para dados sensíveis |
| Respostas de erro vagas ("erro 409") | Humanos e máquinas não conseguem determinar o que deu errado | Inclua tipo de erro, mensagem legível e um link para a documentação |
| Não usar HTTPS | Tokens bearer e chaves de API trafegam em texto simples | Force TLS em tudo; as APIs do Google usam HTTPS por padrão |
| Versionamento no corpo da requisição | Quebra a identificação de recursos; gateways e caches não conseguem rotear corretamente | Use versionamento no caminho da URI (/v1/) ou versionamento via cabeçalho Accept |
As exigem códigos oficiais de status HTTP e recomendam Problem JSON para respostas de erro. As especificam que Problem Detail deve ser usado apenas para 4xx/5xx, nunca misturado com 2xx. Isso não é preferência acadêmica — são padrões de produção de equipes que operam APIs em escala.
Um tópico no Reddit em r/learnprogramming tinha um desenvolvedor perguntando seriamente se tudo bem retornar sempre HTTP 200 mesmo em caso de erro. O fato de essa pergunta ainda aparecer em 2026 mostra o quanto esses antipadrões continuam vivos.
REST vs SOAP vs GraphQL vs gRPC: como as características de uma API REST se comparam
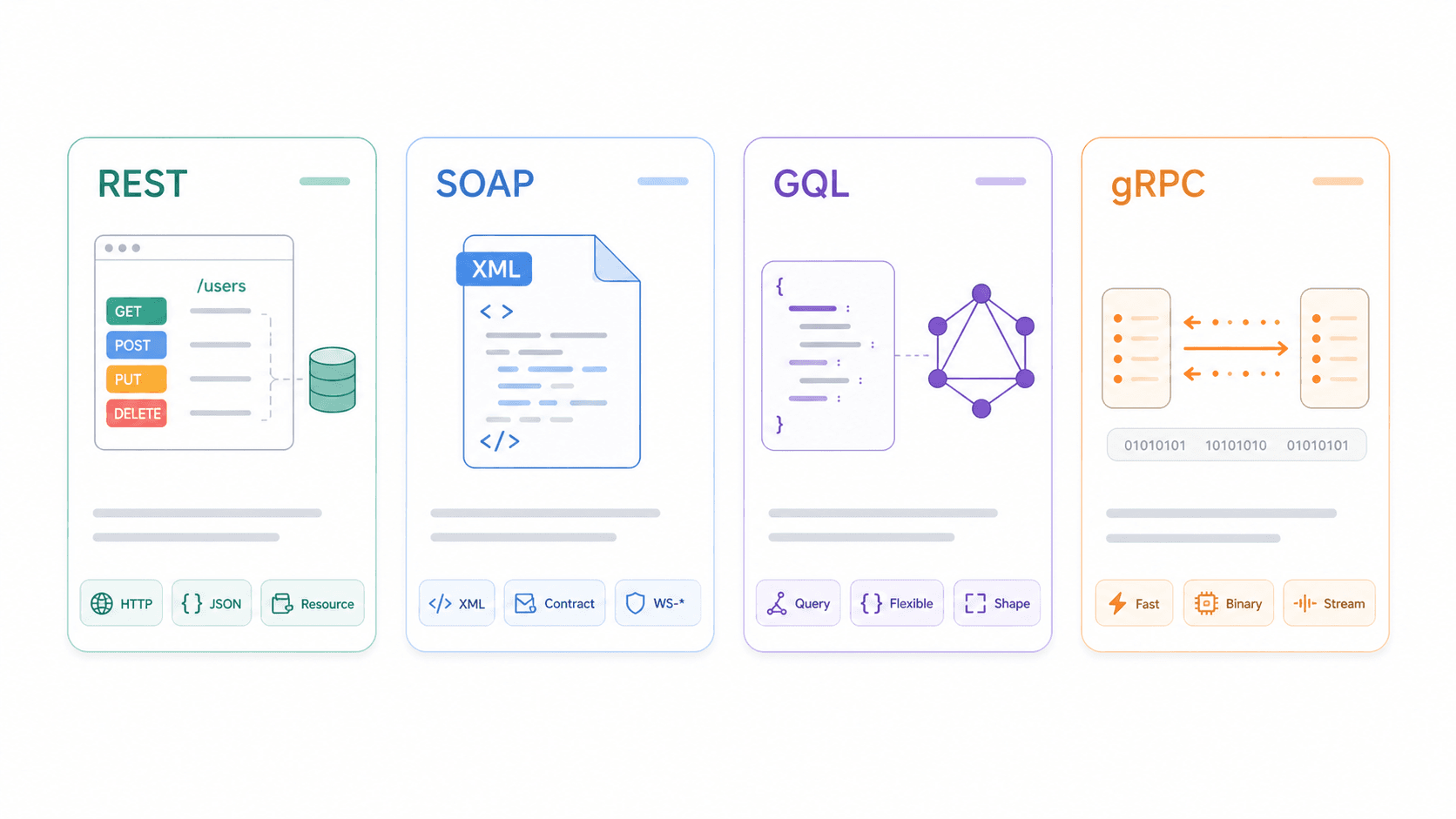
Entender REST isoladamente é útil. Entendê-lo em relação às alternativas é melhor.
| Dimensão | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| Protocolo / Transporte | Estilo arquitetural, geralmente HTTP | Protocolo de mensagens baseado em XML; HTTP, SMTP etc. | Linguagem/runtime de consulta, geralmente sobre HTTP | Framework RPC sobre HTTP/2 |
| Formato de dados | JSON (normalmente), também XML/HTML | Apenas XML (contratos WSDL) | JSON correspondente à forma da query | Protocol Buffers (binário) |
| Cache | ✅ Cache HTTP nativo quando bem projetado | ❌ Complexo; pouco amigável ao cache HTTP | ⚠️ Mais difícil (POST + endpoint único + variação de query) | ❌ Não orientado a cache HTTP |
| Suporte a tempo real | ❌ Polling/webhooks | ❌ Padrões de mensagens corporativas | ✅ Subscriptions | ✅ Streaming, baixa latência |
| Curva de aprendizado | Baixa a média | Alta | Média | Média a alta |
| Melhor para | APIs públicas, CRUD, integrações web/móveis | Enterprise/legado, contratos rígidos, conformidade | Consultas complexas, front-ends flexíveis, apps móveis | Comunicação entre microsserviços, alto desempenho interno |
A recomenda escolher com base em compatibilidade, formato dos dados, operações e ferramentas do usuário.
Quando escolher cada um:
- REST vence quando você precisa de ampla compatibilidade, operações CRUD simples e cache HTTP. É o padrão para APIs públicas e integrações web/móveis.
- SOAP ainda faz sentido para sistemas corporativos com contratos rígidos, exigências de WS-Security ou integrações legadas que não vão desaparecer tão cedo.
- GraphQL brilha quando o front-end precisa de consultas flexíveis e aninhadas e você quer evitar buscar dados demais ou de menos — algo comum em apps móveis complexos.
- gRPC foi feito para comunicação interna entre microsserviços, quando baixa latência e serialização binária importam mais do que compatibilidade com navegadores.
Como exemplo real de REST: a usa endpoints POST diretos (/distill e /extract), corpos de requisição/resposta em JSON, autenticação por bearer token e códigos HTTP padrão (400, 401, 402, 408, 422, 429, 500, 502, 503, 504). Ela mostra características REST em um produto de IA de produção sem exigir contratos SOAP nem a complexidade do gRPC. Não é uma vitrine de HATEOAS — mas é uma API prática de Nível 2, fácil de integrar para equipes de negócios e desenvolvedores.
Por que as características de uma API REST importam para equipes de negócios
Vendas, Operações, E-commerce — nenhuma dessas equipes escreve código de API. Mas você está escolhendo fornecedores, conectando ferramentas e construindo fluxos de automação — e a qualidade da API REST afeta diretamente o quão dolorosas (ou tranquilas) serão essas integrações.
Integração de ferramentas: quando seu CRM sincroniza com uma plataforma de automação de marketing, o design da API REST determina se essa sincronização será confiável ou frágil. A gerencia contatos, campanhas, jornadas e notificações push por meio de endpoints de recursos previsíveis. Se esses endpoints seguem convenções REST, sua equipe de RevOps consegue automatizar sem gambiarras.
Operações de e-commerce: os gerenciam pedidos de fulfillment, números de rastreamento e status de envio. Apps de frete e ferramentas de fulfillment dependem dessa camada. Quando a API é bem projetada — códigos de status corretos, dados de catálogo cacheáveis, mensagens de erro claras — sua cadeia logística flui bem. Quando não é, surgem falhas misteriosas às 2 da manhã.
Avaliação de fornecedores: conhecer as 6 restrições lhe dá uma lista prática de verificação:
- A API usa códigos de status padrão ou toda falha parece um 200 OK?
- Os erros são específicos o bastante para sua ferramenta de automação conseguir se recuperar?
- Há documentação clara sobre limites de taxa, paginação e autenticação?
- As respostas comuns podem ser cacheadas para reduzir a carga?
Extração de dados e automação: ferramentas como a usam uma arquitetura baseada em REST para permitir que usuários de negócios extraiam dados estruturados de sites, PDFs e imagens — e depois exportem para Google Sheets, Airtable, Notion ou Excel. A lida com a complexidade por trás de uma interface de 2 cliques, mas por baixo do capô são os princípios REST — requisições sem estado, respostas JSON, erros padrão — que tornam a camada de integração confiável.
Mais um dado que vale destacar: o relatório Postman 2025 descobriu que apenas projetam APIs ativamente pensando em agentes de IA, enquanto 51% se preocupam com chamadas de API não autorizadas ou excessivas por parte desses agentes. À medida que automação e fluxos orientados por IA se tornam padrão nas equipes de negócios, padrões REST previsíveis, chaves de API com menor privilégio e limites de taxa deixam de ser apenas preocupação de desenvolvedor — viram fatores de risco operacional.
Como a Thunderbit aplica princípios REST para usuários de negócios
Construímos a partindo do princípio de que a maioria dos nossos usuários jamais leria uma especificação REST — e não deveria precisar fazê-lo. Mas as decisões de design que tornam a Thunderbit fácil de usar estão enraizadas nas mesmas características REST que este artigo descreve.
Veja um resumo rápido de como funciona na prática:
- Instale a extensão Chrome na e abra qualquer site, PDF ou imagem da qual você queira extrair dados.
- Clique em "Sugerir campos com IA" e a IA da Thunderbit lê a página e propõe uma tabela estruturada de colunas — nomes de produtos, preços, e-mails, qualquer coisa que a página contenha.
- Ajuste as colunas, se necessário, e clique em "Extrair". A Thunderbit lida automaticamente com paginação, subpáginas e conteúdo dinâmico.
- Exporte seus dados para Google Sheets, Airtable, Notion, CSV ou Excel — grátis, sem paywall.
Para desenvolvedores e fluxos de automação, a expõe /distill (extração limpa em Markdown) e /extract (extração estruturada de dados) como endpoints POST em estilo REST, com corpos JSON e códigos HTTP padrão de erro. Em termos do Modelo de Maturidade Richardson, isso é um sólido Nível 2 — recursos, métodos adequados, códigos de status significativos.
Se você estiver explorando web scraping ou extração de dados de forma mais ampla, já publicamos guias mais profundos sobre , e .
Principais conclusões
- REST é um estilo arquitetural, não um protocolo. Ele define 6 restrições — cliente-servidor, sem estado, cacheável, interface uniforme, sistema em camadas e código sob demanda opcional — que orientam o design de APIs.
- A maioria das APIs "RESTful" não é totalmente RESTful. A maior parte está no Nível 2 de Richardson (recursos + verbos HTTP + códigos de status). HATEOAS e código sob demanda quase nunca são implementados.
- O Modelo de Maturidade Richardson é a melhor ferramenta de autoavaliação. Ele troca a pergunta binária "é REST ou não" por um espectro prático (Níveis 0–3).
- Erros comuns — 200 OK para erros, POST para tudo, ausência de cabeçalhos de cache — continuam muito frequentes. Conhecer as restrições ajuda a identificar e corrigir esses antipadrões.
- REST vs SOAP vs GraphQL vs gRPC não é sobre "o melhor" — é sobre o encaixe. REST domina APIs públicas e integrações CRUD. GraphQL é ideal para front-ends complexos. gRPC se destaca em microsserviços internos. SOAP persiste em contextos corporativos/legados.
- Equipes de negócios se beneficiam de entender as características REST ao avaliar fornecedores, conectar ferramentas e construir fluxos de automação. Ferramentas como a aplicam princípios REST para tornar a extração de dados acessível sem exigir conhecimento técnico.
Perguntas frequentes
Quais são as 6 características de uma API REST?
As 6 restrições REST são: (1) separação cliente-servidor, (2) ausência de estado, (3) capacidade de cache, (4) interface uniforme, (5) sistema em camadas e (6) código sob demanda (opcional). As cinco primeiras são obrigatórias para que uma API seja considerada RESTful pela definição original de Fielding.
Qual é a diferença entre REST e RESTful?
REST é o estilo arquitetural — o conjunto de restrições de design definido por Roy Fielding. "RESTful" descreve uma API que segue essas restrições. Na prática, muitas APIs rotuladas como "RESTful" cumprem apenas parte delas, geralmente implementando recursos, métodos HTTP e códigos de status, mas deixando HATEOAS e código sob demanda de lado.
Todas as APIs REST seguem todas as restrições REST?
Não. A maioria das APIs de produção segue a separação cliente-servidor, a ausência de estado e a interface uniforme básica (recursos + verbos HTTP). A capacidade de cache e o design em camadas são implementados de forma inconsistente. HATEOAS é raro, e código sob demanda quase nunca é usado em APIs JSON.
Qual é a diferença entre REST e GraphQL?
REST expõe recursos por meio de vários endpoints com métodos HTTP padrão (GET, POST, PUT, DELETE). GraphQL normalmente usa um único endpoint, no qual os clientes especificam exatamente quais campos querem em uma consulta. REST tem cache HTTP nativo mais forte; GraphQL oferece mais flexibilidade para necessidades complexas e aninhadas de dados e reduz o excesso de busca.
O que é HATEOAS, e alguém realmente usa isso?
HATEOAS (Hypermedia as the Engine of Application State) significa que as respostas da API incluem links que indicam quais ações estão disponíveis em seguida — assim, os clientes podem navegar pela API sem codificar manualmente cada endpoint. Isso é central na visão de REST de Fielding (Nível 3 de Richardson), mas, na prática, pouquíssimas APIs públicas o implementam. A maioria das equipes para no Nível 2 e depende de documentação e SDKs.
Saiba mais