
Se você já tentou extrair dados da web usando Python, sabe bem como é o drama: num momento você está de boa coletando preços de produtos ou leads de vendas, e no instante seguinte—pá!—seu script é barrado, seu IP toma um bloqueio e ainda aparece um CAPTCHA daqueles de tirar qualquer um do sério. Em 2025, isso já virou rotina para quem trabalha com vendas, marketing ou operações e depende de dados públicos da web para não ficar para trás.
Olha só esse dado: mais de acontecem por causa de defesas anti-bot, tipo bloqueio de IP e CAPTCHAs, e cerca de esbarram nesses obstáculos direto. Com quase metade do tráfego da internet vindo de bots, os sites estão cada vez mais espertos. Mas relaxa—seja você fera em Python ou só quer praticidade, vou te mostrar como driblar bloqueios, usar proxies do jeito certo e até turbinar sua coleta de dados com IA, tipo o .
Como Fazer Web Scraping em Python Sem Ser Bloqueado: O Básico
Vamos do começo. Web scraping nada mais é do que automatizar a coleta de informações de sites. Python é a linguagem queridinha pra isso— usam ferramentas baseadas em Python pra raspar dados. Só que os sites não facilitam a vida dos bots. Por quê? Porque muitos acessos automáticos podem sobrecarregar servidores, copiar conteúdo ou dar vantagem injusta pra concorrência.
E como os sites se defendem? Olha só as táticas mais comuns:
- Bloqueio de IP e Limite de Taxa: Se rolar muitos acessos do mesmo IP, pode se preparar pra bloqueio ou lentidão.
- CAPTCHAs: Aqueles desafios “prove que você é humano” que até gente de verdade odeia.
- Filtro de User-Agent e Headers: Se seu script se apresenta como “python-requests/2.x”, tá praticamente gritando “sou um bot!”
- Desafios em JavaScript e Fingerprinting: Alguns sites exigem execução de JavaScript ou fazem checagens sutis do navegador.
- Honeypots: Links ou campos escondidos que só bot cai.
Se não tomar cuidado, seu script em Python vai acionar esses alarmes rapidinho.
Por Que Evitar Bloqueio de IP é Essencial no Web Scraping com Python
Ser bloqueado não é só dor de cabeça técnica—pode travar o negócio. Imagina sua equipe de vendas sem acesso a novos leads, seu analista de preços perdendo promoções da concorrência, ou sua pesquisa de mercado baseada em dados furados. Isso pode custar caro.
Olha só o detalhe:
| Caso de Uso | Exemplo de Cenário | Risco se Bloqueado | Benefício de Raspar com Confiabilidade |
|---|---|---|---|
| Geração de Leads de Vendas | Extração de contatos em diretórios ou LinkedIn | Listas incompletas, oportunidades perdidas | Leads atualizados e contínuos para prospecção |
| Monitoramento de Preços | Acompanhamento diário de preços da concorrência | Dados desatualizados, mudanças de preço perdidas | Inteligência de preços em tempo real, reação rápida |
| Análise da Concorrência | Coleta de detalhes de produtos ou avaliações | Falta de visibilidade, lançamentos despercebidos | Visão completa do mercado, estratégia aprimorada |
| Pesquisa de Mercado & SEO | Agregação de notícias, fóruns ou SERPs | Insights distorcidos, tempo de analista desperdiçado | Dados abrangentes e atualizados para análise |
Pra , dados da web são o coração do negócio.
Como Sites Bloqueiam Web Scraping em Python: Principais Motivos
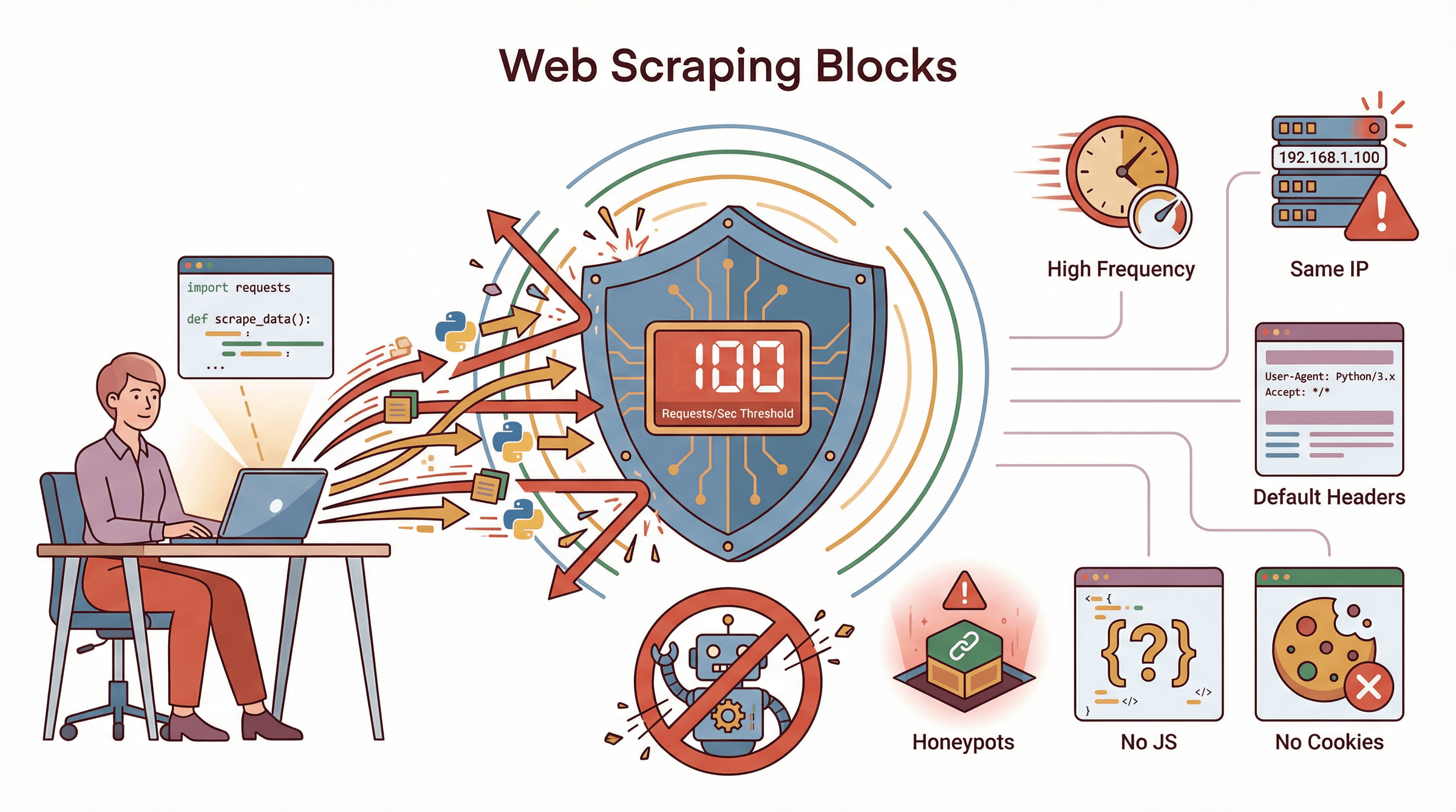 O que faz um scraper em Python ser bloqueado? Olha os motivos mais comuns:
O que faz um scraper em Python ser bloqueado? Olha os motivos mais comuns:
- Frequência Alta de Requisições: Humanos não acessam 100 páginas por segundo. Se fizer isso, vai ser pego na hora.
- Uso Repetido do Mesmo IP: Se todos os acessos vêm de um IP só, principalmente de datacenter, é bandeira vermelha.
- Headers Padrão: Usar user-agent padrão do Python ou headers faltando entrega o bot.
- Sem Cookies ou Sessões: Usuários reais acumulam cookies navegando. Bot sem cookie chama atenção.
- Ignorar Renderização de JavaScript: Se seu scraper não executa JS, pode perder dados ou falhar em checagens.
- Ignorar Robots.txt: Não é bloqueio técnico, mas chama atenção rapidinho.
- Honeypots: Clicar em link ou preencher campo invisível? Ban na hora.
Erro clássico de iniciante é bombardear site com requisições, não rotacionar proxies e esquecer de variar user-agents e intervalos. Já vi gente ter a faixa inteira de IP da faculdade banida da NASDAQ por mandar milhares de acessos em segundos. Tenso.
Usando Proxies em Python para Evitar Bloqueio de IP
É aí que entram os proxies: seu melhor amigo contra bloqueio de IP. Um proxy funciona como intermediário, mandando suas requisições por outro endereço IP. Pro site, parece que o acesso vem de outro lugar.
Tipos de Proxies
- Proxies de Datacenter: Baratos e rápidos, mas fáceis de detectar. Bom pra raspagem simples.
- Proxies Residenciais: IPs de casas reais—mais difíceis de bloquear, mas mais lentos e caros.
- Proxies Rotativos: Trocam de IP automaticamente a cada requisição. Ideais pra grandes volumes.
- Proxies Móveis: Usam IPs de operadoras de celular. Só precisa pra site muito restrito.
Pra maioria dos usos profissionais, proxies residenciais rotativos são o padrão ouro—confiáveis e mudam com frequência suficiente pra evitar bloqueio.
Como Integrar Proxies com Requests, Selenium e Beautiful Soup em Python
Vamos pra prática. Olha como adicionar proxies nos seus scripts Python:
Com Requests:
1import requests
2proxy = "http://USUARIO:SENHA@IP_PROXY:PORTA"
3proxies = {"http": proxy, "https": proxy}
4headers = {"User-Agent": "Mozilla/5.0 ..."}
5response = requests.get("https://target-website.com/data", proxies=proxies, headers=headers)
6html = response.textCom Beautiful Soup:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html, 'html.parser')
3data_items = soup.find_all('div', class_='item')Com Selenium:
1from selenium import webdriver
2proxy = "IP_PROXY:PORTA"
3chrome_options = webdriver.ChromeOptions()
4chrome_options.add_argument(f'--proxy-server=http://{proxy}')
5driver = webdriver.Chrome(options=chrome_options)
6driver.get("https://target-website.com")Pra proxies rotativos, é só percorrer uma lista ou usar um serviço que faz a rotação sozinho. Se um proxy falhar, captura o erro e tenta outro.
Boas Práticas para Gerenciar e Rotacionar Proxies
- Tenha um Pool Grande: Quanto mais proxies, melhor. Troque a cada requisição ou lote.
- Monitore a Saúde dos Proxies: Tire proxies ruins do pool. Refaça requisições com novo IP se falhar.
- Não Sobrecarregue um Proxy Só: Distribua as requisições. Não deixa um IP fazer tudo.
- Alvo Geográfico: Use proxies do mesmo país do site-alvo, se precisar.
- Misture Tipos de Proxy: Comece com datacenter, muda pra residencial se bloquear.
- Evite Proxies Gratuitos: São lentos, instáveis e geralmente já estão bloqueados.
- Respeite Limites do Fornecedor: Não gaste sua cota de proxies rápido demais.
Gerenciar proxies é quase uma arte. Mas nem o melhor setup de proxies resolve tudo sozinho.
Além dos Proxies: Técnicas Inteligentes para Evitar Bloqueios em Python
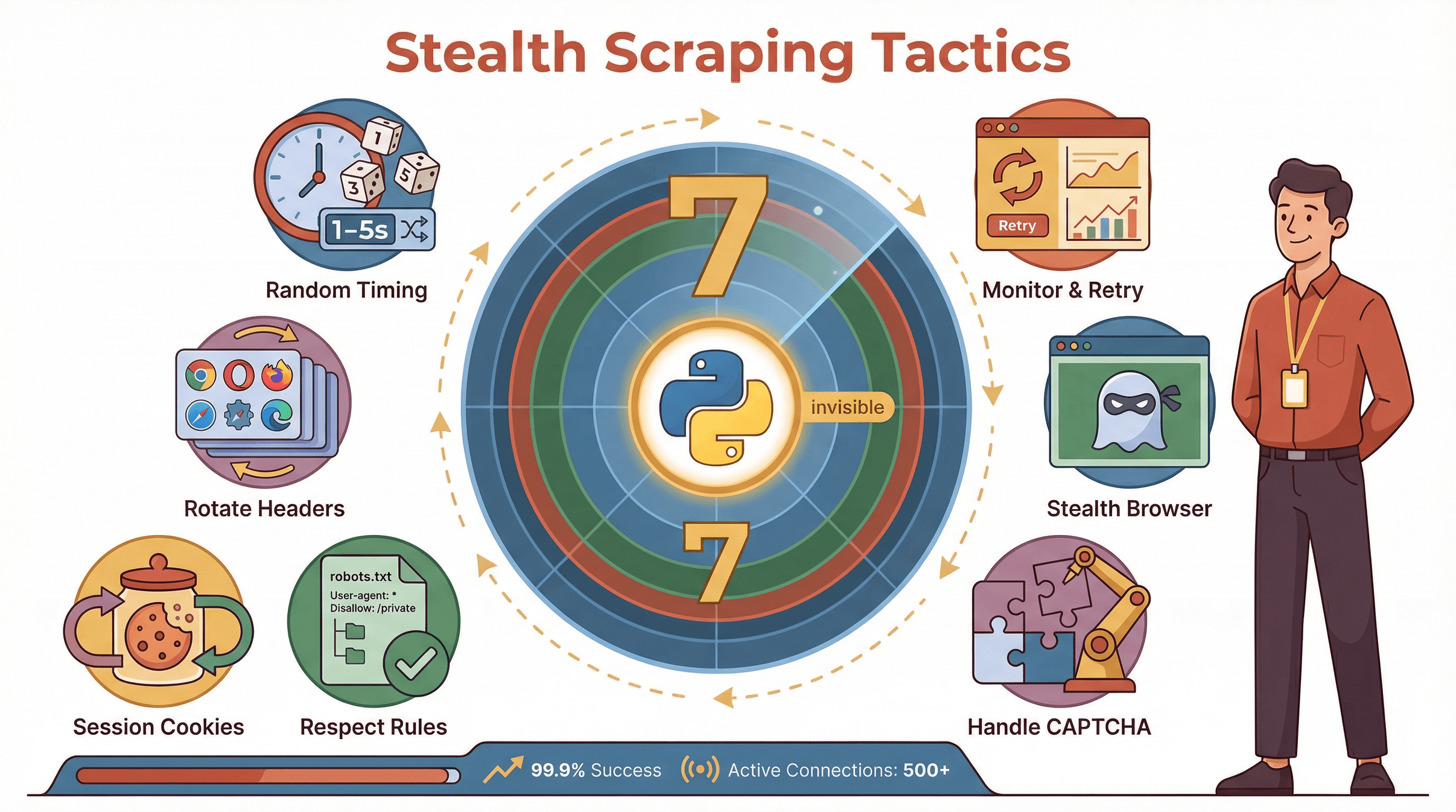 Quer passar batido mesmo? Misture essas táticas com o uso de proxies:
Quer passar batido mesmo? Misture essas táticas com o uso de proxies:
- Aleatorize o Tempo das Requisições: Não mande acessos em intervalos certinhos. Use delays aleatórios (tipo pausa de 1–5 segundos).
- Rotacione User-Agents e Headers: Use uma lista de user-agents reais de navegadores. Varie Accept-Language, Referer, etc.
- Use Sessões e Cookies: Mantenha cookies entre requisições pra simular navegação real.
- Respeite Robots.txt e Reduza a Velocidade em Erros: Não ignore regras do site. Se receber erro 429 ou 503, diminua o ritmo.
- Lide com CAPTCHAs: Integre um serviço de resolução de CAPTCHA ou troque de proxy se topar com um.
- Navegadores Headless Stealth: Use ferramentas como undetected-chromedriver ou plugins stealth do Playwright.
- Monitore e Refaça Requisições: Mantenha logs, monitore falhas e tente de novo com outros proxies.
Tem muita biblioteca Python boa pra isso—fake-useragent, requests.Session() e plugins stealth pra navegador são aliados de peso.
Turbine sua Raspagem: Ferramentas de IA vs. Métodos Tradicionais com Proxies em Python
Agora, a parte que todo mundo quer saber. E se desse pra pular toda a configuração de proxies, ajuste de headers e dor de cabeça com bloqueio? É aí que entra o .
Thunderbit é uma extensão Chrome de raspagem de dados com IA que permite extrair informações de qualquer site em poucos cliques—sem código, sem configuração de proxy, sem manutenção. Só clicar em “IA Sugere Campos”, deixar a IA identificar o que extrair e clicar em “Raspar”. O Thunderbit cuida dos proxies, bloqueios, paginação e até navegação em subpáginas sozinho.
Olha a comparação dos métodos:
| Aspecto | Raspagem em Python (Proxies) | Raspador Web IA Thunderbit |
|---|---|---|
| Tempo de Configuração | Horas (código, proxies, parsing) | Minutos (apontar, clicar, pronto) |
| Habilidade Técnica | Alta (código, HTTP, proxies) | Baixa (qualquer um pode usar) |
| Prevenção de Bloqueio | Manual (rotacionar proxies, headers) | Automática (IA + proxies integrados) |
| Manutenção | Constante (atualizar código, proxies) | Mínima (IA se adapta, templates prontos) |
| Paginação/Subpáginas | Precisa de código manual | Um clique, IA faz tudo |
| Exportação de Dados | Manual (CSV, Excel via código) | Um clique para Sheets, Excel, Notion, Airtable |
| Escalabilidade | Depende da infra/proxies | Alta (raspagem em nuvem, páginas paralelas) |
| Custo | Taxas de proxy + tempo de dev | Plano gratuito, depois opções acessíveis |
| Confiabilidade | Varia (depende do setup) | Alta (otimizado para negócios) |
Thunderbit é perfeito pra equipes não técnicas ou pra quem só quer os dados—rápido.
Passo a Passo: Raspando Sem Ser Bloqueado Usando Thunderbit
Veja como eu usaria o Thunderbit pra raspar um site que normalmente bloqueia scripts em Python:
- Instale a Extensão Thunderbit no Chrome: .
- Acesse o Site Alvo: Faça login se precisar—o Thunderbit usa sua sessão do navegador.
- Clique em “IA Sugere Campos”: O Thunderbit analisa a página e sugere colunas pra extrair (tipo “Nome”, “Preço”, “Email”).
- Clique em “Raspar”: O Thunderbit coleta os dados em uma tabela organizada.
- Lide com Paginação: Ative “Raspar Todas as Páginas” e o Thunderbit navega por todas, juntando os resultados.
- Raspe Subpáginas: Use “Raspar Subpáginas” pra visitar páginas de detalhes e enriquecer seus dados.
- Exporte: Com um clique, mande os dados pra Google Sheets, Excel, Notion ou Airtable.
O Thunderbit faz toda a mágica anti-bloqueio pra você—rotaciona IPs, controla o ritmo das requisições e até resolve CAPTCHAs simples. Pra maioria dos negócios, simplesmente funciona.
Como o Thunderbit Lida com Paginação e Subpáginas
O Thunderbit não pega só o que está na primeira página. Ele consegue:
- Rolar e Clicar Como um Humano: Pra scroll infinito ou botões de “próxima página”, o Thunderbit simula navegação real.
- Manter Sessões: Se você estiver logado, o Thunderbit mantém sua sessão entre as páginas.
- Distribuir a Carga: No modo nuvem, o Thunderbit raspa várias páginas em paralelo, cada uma de um IP diferente.
- Lidar com Conteúdo Dinâmico: O Thunderbit executa JavaScript, pegando todos os dados, até os que carregam depois.
- Raspagem de Subpáginas: O Thunderbit pode acessar páginas de detalhes de cada item, coletar campos extras e juntar tudo na tabela principal.
Pro site, parece um grupo de usuários reais navegando de boa—não um exército de bots.
Python com Proxies vs. Thunderbit: Qual o Melhor para Empresas?
Qual caminho seguir? Olha o resumo:
| Fator | Python + Proxies | Thunderbit |
|---|---|---|
| Velocidade | Mais lento pra configurar | Resultados instantâneos |
| Manutenção | Alta (código, proxies) | Baixa (IA se adapta, templates) |
| Habilidade | Desenvolvedor | Qualquer pessoa |
| Risco de Bloqueio | Médio (se não cuidar) | Baixo (IA/proxies automáticos) |
| Custo | Taxas de proxy + dev | Plano gratuito, depois R$ 15/mês+ |
| Melhor Para | Raspagem customizada | Equipes de vendas, marketing, pesquisa |
Se você é dev e curte personalizar tudo, Python com proxies ainda é uma ótima pedida. Mas pra maioria das empresas—principalmente quem quer evitar dor de cabeça com proxy—o Thunderbit é um baita ganho de produtividade.
Resumindo: Raspe de Forma Inteligente, Não Mais Difícil
Aqui vai o que aprendi (e queria ter ouvido antes):
- Proxies são essenciais pra evitar bloqueio de IP em Python, mas gerenciar dá trabalho.
- Táticas anti-bloqueio inteligentes (delays aleatórios, rotação de headers, sessões) fazem toda a diferença.
- Ferramentas com IA como o Thunderbit automatizam tudo—proxies, bloqueios, paginação, subpáginas e exportação—pra você focar no que importa: os dados.
- Escolha a ferramenta certa pra sua equipe: Se precisa de velocidade e confiabilidade, Thunderbit é imbatível. Se curte programar e precisa de fluxos customizados, Python + proxies ainda é poderoso.
Quer ver como pode ser fácil raspar dados? e teste no seu próximo projeto. E se quiser mais dicas, confere o .
Boas raspagens—que seus IPs fiquem livres e seus dados sempre atualizados.
Perguntas Frequentes
1. Qual o principal motivo para scrapers em Python serem bloqueados?
O mais comum é mandar muitas requisições de um único IP ou usar headers padrão que entregam o bot. Os sites sacam esses padrões rapidinho e bloqueiam ou limitam o acesso.
2. Como proxies ajudam a evitar bloqueio de IP no web scraping com Python?
Proxies mandam suas requisições por IPs diferentes, fazendo parecer que o tráfego vem de vários usuários. Proxies rotativos são especialmente bons pra grandes volumes.
3. Quais as melhores práticas para gerenciar proxies em Python?
Use um pool grande de proxies, rotacione sempre, monitore falhas, fuja de proxies gratuitos e escolha localizações próximas do site-alvo. Sempre varie o tempo e os headers das requisições.
4. Como o Thunderbit evita bloqueios sem configuração manual de proxies?
O Thunderbit automatiza a rotação de proxies, controla o ritmo das requisições e aplica técnicas anti-bloqueio nos bastidores. A IA simula comportamento real de usuário, lida com paginação e subpáginas, e exporta dados com um clique—sem precisar programar.
5. Devo usar Python ou Thunderbit para raspagem de dados no meu negócio?
Se você é dev e precisa de soluções customizadas, Python com proxies é flexível. Mas pra equipes de vendas, marketing e pesquisa que querem dados rápidos e confiáveis sem complicação técnica, Thunderbit é a escolha mais inteligente e prática.
Quer raspar de forma mais esperta? e deixe os bloqueios pra trás.
Saiba Mais