A web está cheia de dados valiosos — seja em vendas, ecommerce ou pesquisa de mercado, o web scraping é uma arma secreta para geração de leads, monitoramento de preços e análise da concorrência. Mas há um ponto importante: à medida que mais empresas adotam o scraping, os sites estão reagindo com mais força do que nunca. Na prática, mais de , e já viraram rotina. Se você já viu seu script em Python rodar liso por 20 minutos e, de repente, bater numa parede de erros 403, sabe bem como isso frustra.
Trabalho há anos com SaaS e automação, e vi de perto projetos de scraping passarem de “uau, isso é fácil” para “por que estou bloqueado em todo lugar?” num piscar de olhos. Então, vamos ao que interessa: vou mostrar como fazer web scraping sem ser bloqueado em Python, partilhar as melhores técnicas e trechos de código, e mostrar quando vale a pena considerar alternativas com IA, como . Seja você um profissional experiente em Python ou alguém que está só a tentar sobreviver no scraping (trocadilho intencional), vai sair daqui com um conjunto de ferramentas para extração de dados confiável e sem bloqueios.
O Que é Web Scraping Sem Ser Bloqueado em Python?
Na prática, web scraping sem ser bloqueado significa extrair dados de sites de um modo que não acione as suas defesas anti-bot. No universo Python, isso vai além de simplesmente escrever um loop com requests.get() — trata-se de se misturar ao tráfego normal, imitar utilizadores reais e ficar um passo à frente dos sistemas de deteção.
Por que Python? — graças à sintaxe simples, ao ecossistema enorme (pense em requests, BeautifulSoup, Scrapy, Selenium) e à flexibilidade para tudo, de scripts rápidos a crawlers distribuídos. Mas popularidade tem preço: muitos sistemas anti-bot já foram ajustados para identificar padrões de scraping em Python.
Então, se quer extrair dados de forma confiável, precisa ir além do básico. Isso significa entender como os sites detetam bots e como contorná-los — sem ultrapassar limites éticos ou legais.
Por Que Evitar Bloqueios é Importante em Projetos de Web Scraping em Python
Ser bloqueado não é só um contratempo técnico — pode comprometer fluxos inteiros de negócio. Veja o impacto:
| Caso de Uso | Impacto de Ser Bloqueado |
|---|---|
| Geração de Leads | Listas de prospects incompletas ou desatualizadas, perda de vendas |
| Monitoramento de Preços | Mudanças de preço dos concorrentes não detetadas, decisões de precificação ruins |
| Agregação de Conteúdo | Lacunas em notícias, avaliações ou dados de pesquisa |
| Inteligência de Mercado | Pontos cegos no acompanhamento de concorrentes ou do setor |
| Imóveis | Dados de imóveis imprecisos ou desatualizados, oportunidades perdidas |
Quando um scraper é bloqueado, não perde só dados — também desperdiça recursos, corre riscos de compliance e pode tomar decisões ruins com base em informações incompletas. Num mundo em que , confiabilidade é tudo.
Como os Sites Detectam e Bloqueiam Web Scrapers em Python
Os sites ficaram muito mais inteligentes a detetar bots. Estas são as defesas anti-scraping mais comuns que vai encontrar (, ):
- Blacklist de endereço IP: Muitas requisições do mesmo IP? Bloqueado.
- Verificação de User-Agent e cabeçalhos: Requisições sem cabeçalhos ou com cabeçalhos genéricos (como o padrão do Python
python-requests/2.25.1) chamam logo a atenção. - Limitação de taxa: Muitas requisições em pouco tempo acionam throttling ou banimento.
- CAPTCHAs: Quebra-cabeças de “prove que é humano” que bots não conseguem resolver facilmente.
- Análise comportamental: Os sites observam padrões robóticos — como clicar no mesmo botão sempre no mesmo intervalo.
- Honeypots: Links ou campos ocultos com os quais só bots interagem.
- Fingerprinting do navegador: Recolha de detalhes do navegador e do dispositivo para identificar ferramentas de automação.
- Rastreamento de cookies e sessões: Bots que não lidam corretamente com cookies ou sessões acabam sinalizados.
Pense nisto como a segurança de um aeroporto: se parece, age e se move como toda a gente, passa sem problemas. Se aparecer de sobretudo e óculos escuros, espere perguntas extra.
Técnicas Essenciais em Python para Web Scraping Sem Ser Bloqueado
Agora vamos ao que realmente interessa: como evitar bloqueios ao fazer scraping com Python. Aqui estão as estratégias centrais que todo scraper deveria conhecer:

Rotação de Proxies e Endereços IP
Por que isso importa: Se todas as suas requisições vierem do mesmo IP, vira um alvo fácil de bloqueio por IP. Proxies rotativos permitem distribuir as requisições por vários IPs, tornando muito mais difícil bloqueá-lo.
Como fazer em Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...mais proxies
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # processar respostaPode usar serviços pagos de proxy (como proxies residenciais ou rotativos) para ganhar mais confiabilidade ().
Definição de User-Agent e Cabeçalhos Personalizados
Por que isso importa: Os cabeçalhos padrão do Python gritam “bot”. Imite navegadores reais definindo user-agent e outros cabeçalhos.
Exemplo de código:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Alterne user-agents para ganhar mais discrição ().
Aleatorização do Tempo e dos Padrões das Requisições
Por que isso importa: Bots são rápidos e previsíveis; humanos são mais lentos e imprevisíveis. Adicione atrasos e varie a navegação.
Dica em Python:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Aguarde de 2 a 7 segundosTambém pode aleatorizar caminhos de clique e padrões de scroll se estiver a usar Selenium.
Gestão de Cookies e Sessões
Por que isso importa: Muitos sites exigem cookies ou tokens de sessão para libertar conteúdo. Bots que ignoram isso acabam bloqueados.
Como gerir em Python:
1import requests
2session = requests.Session()
3response = session.get(url)
4# a sessão tratará dos cookies automaticamentePara fluxos mais complexos, use Selenium para capturar e reutilizar cookies.
Simulação de Comportamento Humano com Navegadores Headless
Por que isso importa: Alguns sites usam JavaScript, movimento do rato ou scroll como sinais de utilizadores reais. Navegadores headless como Selenium ou Playwright podem imitar essas ações.
Exemplo com Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Isto ajuda a contornar análise comportamental e conteúdo dinâmico ().
Estratégias Avançadas: Bypass de CAPTCHAs e Honeypots em Python
CAPTCHAs foram feitos para parar bots de imediato. Embora algumas bibliotecas em Python consigam resolver CAPTCHAs simples, a maioria dos scrapers sérios depende de serviços de terceiros (como 2Captcha ou Anti-Captcha) para resolvê-los mediante pagamento ().
Exemplo de integração:
1# Pseudocódigo para usar a API do 2Captcha
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Aguarde a solução e depois envie com a sua requisiçãoHoneypots são campos ou links ocultos com os quais só bots interagem. Evite clicar ou enviar qualquer coisa que não esteja visível num navegador real ().
Como Projetar Cabeçalhos de Requisição Robustos com Bibliotecas Python
Além do user-agent, pode rotacionar e aleatorizar outros cabeçalhos (como Referer, Accept, Origin etc.) para se misturar ainda mais ao tráfego normal.
Com Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # Mais cabeçalhos
7 }
8 }Com Selenium: use perfis de navegador ou extensões para definir cabeçalhos, ou injete-os via JavaScript.
Mantenha a sua lista de cabeçalhos atualizada — copie requisições reais do navegador usando as DevTools como referência.
Quando o Scraping Tradicional em Python Não Basta: A Ascensão da Tecnologia Anti-Bot
A realidade é esta: quanto mais popular o scraping fica, mais os sistemas anti-bot evoluem. . Deteção com IA, limites dinâmicos de requisição e fingerprinting do navegador estão a tornar cada vez mais difícil até mesmo para scripts avançados em Python passarem despercebidos ().
Às vezes, não importa o quão esperto seja o seu código, vai bater numa parede. É nesse momento que vale a pena considerar uma abordagem diferente.
Thunderbit: Uma Alternativa de Raspador Web IA ao Scraping em Python
Quando o Python chega ao limite, o entra em cena como um raspador web com IA e sem código, feito para utilizadores de negócio — não apenas programadores. Em vez de lutar com proxies, cabeçalhos e CAPTCHAs, o agente de IA do Thunderbit lê o site, sugere os melhores campos para extrair e trata de tudo, desde a navegação em subpáginas até à exportação dos dados.
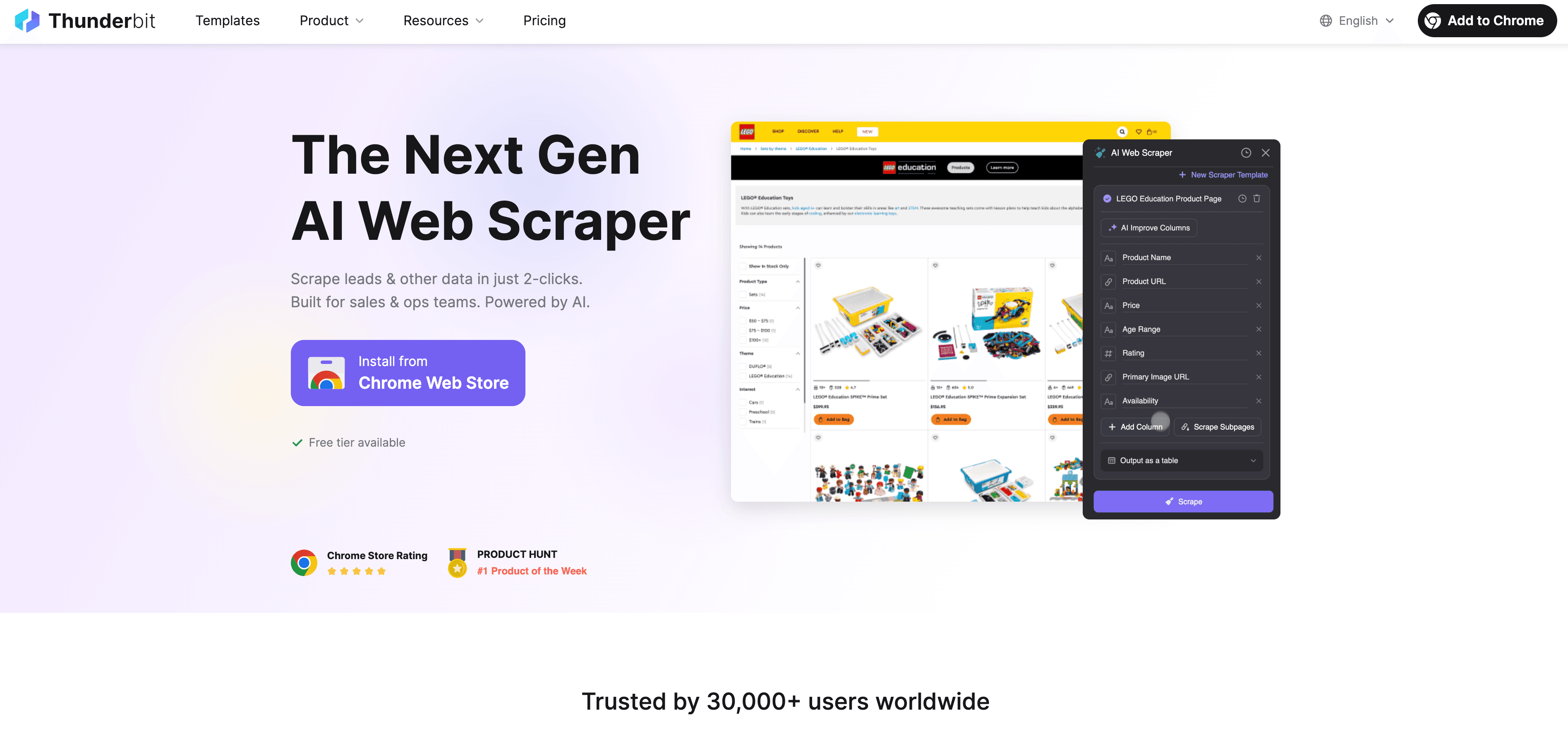
O que torna o Thunderbit diferente?
- Sugestão de campos com IA: clique em “AI Suggest Fields” e o Thunderbit analisa a página, recomenda colunas e até gera instruções de extração.
- Scraping de subpáginas: o Thunderbit pode visitar cada subpágina (como detalhes de produtos ou perfis do LinkedIn) e enriquecer a sua tabela automaticamente.
- Scraping em nuvem ou no navegador: escolha a opção mais rápida — nuvem para sites públicos, navegador para páginas protegidas por login.
- Scraping agendado: configure uma vez e esqueça — o Thunderbit pode fazer scraping em horários programados, mantendo os seus dados sempre atualizados.
- Modelos instantâneos: para sites populares (Amazon, Zillow, Shopify etc.), o Thunderbit oferece modelos com 1 clique — sem configuração.
- Exportação gratuita de dados: exporte para Excel, Google Sheets, Airtable ou Notion — sem taxas extras.
O Thunderbit é confiável para mais de , e você não precisa escrever uma única linha de código.
Como o Thunderbit ajuda os utilizadores a evitar bloqueios e automatizar a extração de dados
A IA do Thunderbit não só imita o comportamento humano — ela adapta-se a cada site em tempo real, reduzindo o risco de bloqueio. Veja como:
- A IA adapta-se a mudanças de layout: nada de scripts quebrados quando o site atualiza o design.
- Tratamento de subpáginas e paginação: o Thunderbit segue links e listas paginadas automaticamente, como um utilizador real.
- Scraping em nuvem em escala: extraia até 50 páginas por vez, em altíssima velocidade.
- Sem código, sem manutenção: passe o seu tempo a analisar os dados, não a corrigir bugs.
Para um mergulho mais profundo, confira .
Comparando Scraping em Python vs. Thunderbit: Qual Você Deve Escolher?
Vamos pôr lado a lado:
| Recurso | Scraping em Python | Thunderbit |
|---|---|---|
| Tempo de configuração | Médio a alto (scripts, proxies etc.) | Baixo (2 cliques, a IA faz o resto) |
| Habilidade técnica | Exige programação | Não exige programação |
| Confiabilidade | Variável (quebra com facilidade) | Alta (a IA adapta-se às mudanças) |
| Risco de bloqueio | Moderado a alto | Baixo (a IA imita o utilizador e adapta-se) |
| Escalabilidade | Precisa de código personalizado/configuração em nuvem | Scraping em nuvem/lotes integrado |
| Manutenção | Frequente (mudanças no site, bloqueios) | Mínima (a IA ajusta-se automaticamente) |
| Opções de exportação | Manual (CSV, base de dados) | Direto para Sheets, Notion, Airtable, CSV |
| Custo | Gratuito (mas consome muito tempo) | Plano gratuito, planos pagos para escala |
Quando usar Python:
- Precisa de controlo total, lógica personalizada ou integração com outros fluxos em Python.
- Está a extrair dados de sites com defesas anti-bot mínimas.
Quando usar Thunderbit:
- Quer velocidade, confiabilidade e zero configuração.
- Está a extrair dados de sites complexos ou que mudam com frequência.
- Não quer lidar com proxies, CAPTCHAs ou código.
Guia Passo a Passo: Configurando Web Scraping Sem Ser Bloqueado em Python
Vamos fazer um exemplo prático: extrair dados de produtos de um site de exemplo, aplicando boas práticas anti-bloqueio.
1. Instale as Bibliotecas Necessárias
1pip install requests beautifulsoup4 fake-useragent2. Prepare o Seu Script
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Substitua pelas suas URLs
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Extraia os dados aqui
16 print(soup.title.text)
17 else:
18 print(f"Bloqueado ou erro em \{url\}: \{response.status_code\}")
19 time.sleep(random.uniform(2, 6)) # Atraso aleatório3. Adicione Rotação de Proxies (Opcional)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Mais proxies
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...restante do código4. Lide com Cookies e Sessões
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...restante do código5. Dicas de Solução de Problemas
- Se vir muitos erros 403/429, diminua a velocidade das requisições ou tente novos proxies.
- Se encontrar CAPTCHAs, considere usar Selenium ou um serviço de resolução de CAPTCHA.
- Verifique sempre o
robots.txte os termos de serviço do site.
Conclusão e Principais Aprendizados
Fazer web scraping em Python é poderoso — mas o risco de bloqueio é constante à medida que a tecnologia anti-bot evolui. A melhor forma de evitar bloqueios? Combine boas práticas técnicas (proxies rotativos, cabeçalhos inteligentes, atrasos aleatórios, tratamento de sessões e navegadores headless) com respeito às regras e à ética de cada site.
Mas, às vezes, nem os melhores truques em Python chegam. É aí que ferramentas com IA como brilham — oferecendo uma forma sem código, resistente a bloqueios e amiga do negócio de extrair os dados de que precisa, rapidamente.
Quer ver como o scraping pode ser fácil? e teste você mesmo — ou confira o nosso para mais dicas e tutoriais de scraping.
FAQs
1. Por que os sites bloqueiam web scrapers em Python?
Os sites bloqueiam scrapers para proteger os seus dados, evitar sobrecarga nos servidores e impedir que bots automatizados abusem dos seus serviços. Scripts em Python são fáceis de identificar se usam cabeçalhos padrão, não lidam com cookies ou enviam muitas requisições em pouco tempo.
2. Quais são as formas mais eficazes de evitar bloqueios ao fazer scraping com Python?
Use proxies rotativos, defina user-agent e cabeçalhos realistas, randomize o tempo das requisições, faça a gestão de cookies/sessões e simule comportamento humano com ferramentas como Selenium ou Playwright.
3. Como o Thunderbit ajuda a evitar bloqueios em comparação com scripts em Python?
O Thunderbit usa IA para se adaptar ao layout dos sites, imitar a navegação humana e tratar automaticamente subpáginas e paginação. Reduz o risco de bloqueio ao misturar-se ao tráfego normal e ajustar a abordagem em tempo real — sem precisar de código ou proxies.
4. Quando devo usar scraping em Python vs. uma ferramenta de IA como o Thunderbit?
Use Python quando precisar de lógica personalizada, integração com outro código Python ou estiver a extrair dados de sites simples. Use o Thunderbit para um scraping rápido, confiável e escalável — especialmente quando os sites são complexos, mudam com frequência ou bloqueiam scripts de forma agressiva.
5. Web scraping é legal?
Web scraping é legal para dados publicamente disponíveis, mas precisa respeitar os termos de serviço, as políticas de privacidade e as leis aplicáveis de cada site. Nunca extraia dados sensíveis ou privados e faça sempre scraping de forma ética e responsável.
Pronto para fazer scraping de forma mais inteligente, e não mais difícil? Experimente o Thunderbit e deixe os bloqueios para trás.
Saiba mais:
- Web Scraping do Google News com Python: Um Guia Passo a Passo
- Crie uma Ferramenta de Rastreamento de Preços da Best Buy Usando Python
- 14 Maneiras de Fazer Web Scraping Sem Ser Bloqueado
- 10 Melhores Dicas de Como Não Ser Bloqueado ao Fazer Web Scraping