

Vou te levar de volta a um passado não tão distante: estou sentado na minha mesa, com café na mão, encarando uma planilha mais vazia do que a minha geladeira num domingo à noite. A equipe de vendas quer dados de preços da concorrência, o pessoal de marketing quer novos leads e o time de operações quer listas de produtos de uma dúzia de sites — para ontem. Sei que os dados estão lá fora, mas conseguir acessá-los? Esse é o verdadeiro desafio. Se você já sentiu que estava brincando de bater em mole com copiar e colar no mundo digital, saiba que não está sozinho.
Avançando para hoje, o cenário mudou. O web scraping deixou de ser um projeto paralelo de nerd e virou uma estratégia central de negócios. JavaScript e Node.js estão agora no centro dessa transformação, impulsionando tudo, de scripts pontuais a pipelines de dados completos. Mas tem um detalhe: embora as ferramentas estejam mais poderosas do que nunca, a curva de aprendizado ainda pode parecer escalar o Everest de chinelos. Então, seja você um usuário de negócios, um entusiasta de dados ou apenas alguém cansado de inserir dados manualmente, este guia é para você. Vou destrinchar o ecossistema, as bibliotecas essenciais, os pontos de dor e por que, às vezes, a jogada mais inteligente é deixar a IA fazer o trabalho pesado.
Por que Web Scraping com JavaScript e Node.js é importante para os negócios
Vamos começar pelo “por quê”. Em 2026, dados da web não são apenas um diferencial — são críticos para a missão. Segundo pesquisas recentes, 73% das empresas atribuem aos dados públicos da web decisões mais rápidas e precisas, e cerca de 42% dos orçamentos de dados corporativos já são dedicados à coleta de dados da web. O mercado de dados alternativos (que inclui web scraping) já é uma indústria de US$ 4,9 bilhões e cresce a um ritmo acelerado.
Então, o que está impulsionando essa corrida do ouro? Aqui estão alguns dos casos de uso mais comuns nos negócios:
- Precificação competitiva e e-commerce: varejistas extraem preços e estoque dos sites concorrentes, às vezes aumentando as vendas em 4% ou mais.
- Geração de leads e inteligência de vendas: equipes de vendas automatizam a coleta de e-mails, telefones e dados de empresas em diretórios e plataformas sociais.
- Pesquisa de mercado e agregação de conteúdo: analistas coletam notícias, avaliações e dados de sentimento para identificar tendências e fazer previsões.
- Publicidade e ad tech: empresas de ad tech acompanham posicionamentos de anúncios e campanhas concorrentes em tempo real.
- Imóveis e viagens: agências extraem anúncios de propriedades, preços e avaliações para alimentar modelos de avaliação e análises de mercado.
- Agregadores de conteúdo e dados: plataformas consolidam dados de várias fontes para abastecer ferramentas de comparação e dashboards.
JavaScript e Node.js viraram a stack preferida para essas tarefas, especialmente porque cada vez mais sites dependem de conteúdo dinâmico renderizado em JavaScript. O Node.js se destaca em operações assíncronas, o que o torna uma escolha natural para scraping em escala. E, com um ecossistema vibrante de bibliotecas, dá para construir de tudo: de scripts rápidos a scrapers robustos, prontos para produção.
O que é Data Scraping e como fazê-lo em 2025 Get Started Free
O fluxo principal: como funciona o Web Scraping com JavaScript e Node.js
Vamos desmistificar o fluxo típico de web scraping. Quer você esteja extraindo um blog simples ou um site de e-commerce cheio de JavaScript, as etapas são bem consistentes:
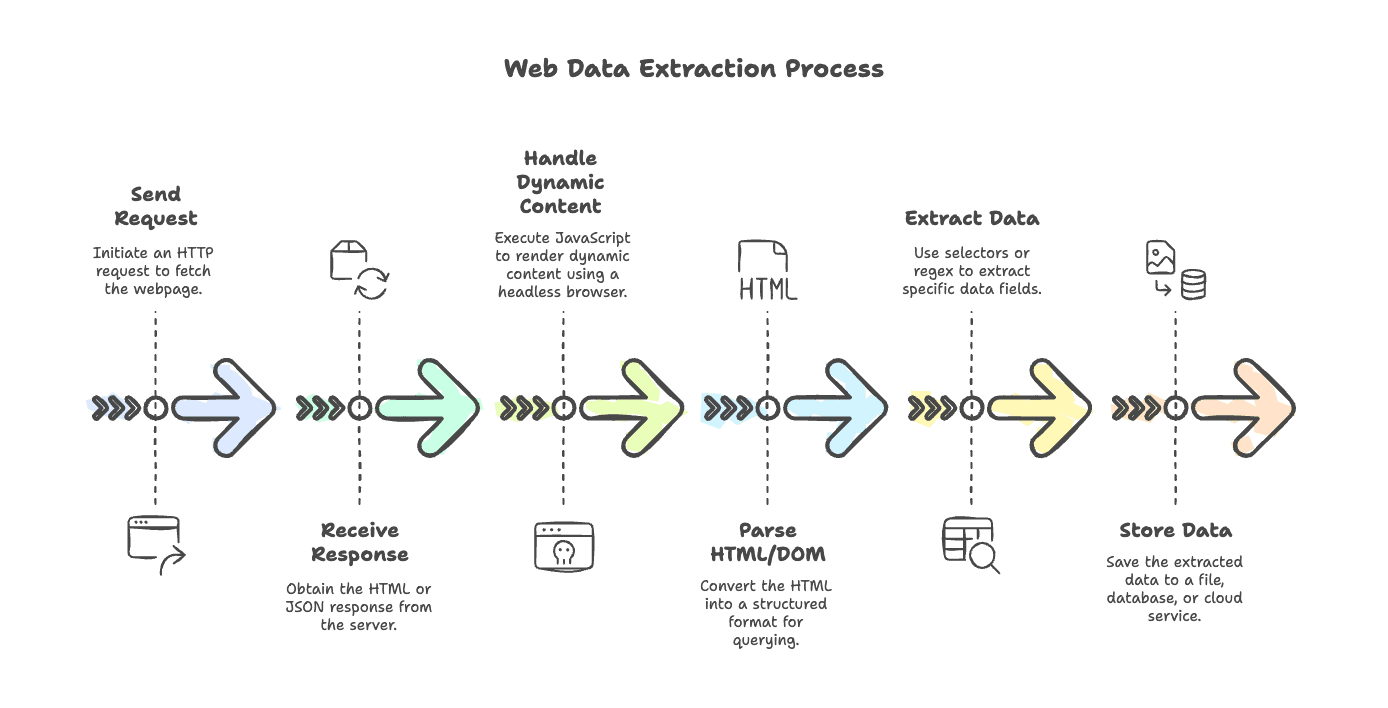
- Enviar a requisição: use um cliente HTTP para buscar a página (pense em
axios,node-fetchougot). - Receber a resposta: obtenha o HTML (ou às vezes JSON) de volta do servidor.
- Tratar conteúdo dinâmico: se a página for renderizada por JavaScript, use um navegador sem interface (como Puppeteer ou Playwright) para executar os scripts e obter o conteúdo final.
- Analisar HTML/DOM: use um parser (
cheerio,jsdom) para transformar o HTML em uma estrutura consultável. - Extrair os dados: use seletores ou regex para puxar os campos de que você precisa.
- Armazenar os dados: salve os resultados em um arquivo, banco de dados ou serviço em nuvem.
Cada etapa tem seu conjunto de ferramentas e boas práticas, que vamos explorar a seguir.
Bibliotecas HTTP essenciais para Web Scraping em JavaScript
O primeiro passo em qualquer scraper é fazer requisições HTTP. O Node.js oferece várias opções — algumas clássicas, outras modernas. Aqui vai um panorama das bibliotecas mais populares:
1. Axios
Um cliente HTTP baseado em promises para Node e navegadores. É o “canivete suíço” da maioria das necessidades de scraping.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
Prós: rico em recursos, suporta async/await, parsing automático de JSON, interceptors e proxy.
Contras: um pouco mais pesado, às vezes “mágico” na forma como lida com os dados.
2. node-fetch
Implementa a API fetch do navegador no Node.js. Minimalista e moderno.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
Prós: leve, API familiar para quem vem do JS de front-end.
Contras: poucos recursos, tratamento de erros manual, configuração de proxy mais verbosa.
3. SuperAgent
Uma biblioteca HTTP veterana com API encadeável.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
Prós: madura, suporta formulários, upload de arquivos e plugins.
Contras: a API parece um pouco datada, dependência maior.
4. Unirest
Um cliente HTTP simples e agnóstico em relação à linguagem.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
Prós: sintaxe fácil, bom para scripts rápidos.
Contras: menos recursos, comunidade menos ativa.
5. Got
Um cliente HTTP robusto e rápido para Node.js, com recursos avançados.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
Prós: rápido, suporta HTTP/2, retries e streams.
Contras: só para Node, a API pode parecer densa para iniciantes.
6. http/https nativos do Node
Sempre dá para voltar ao básico:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Comprimento da resposta:', data.length);
});
});
Prós: sem dependências.
Contras: verboso, muito baseado em callbacks, sem promises.
Veja aqui uma comparação detalhada de recursos e exemplos de código.
Como escolher o cliente HTTP certo para o seu projeto
Como decidir a ferramenta certa para a tarefa? Eu costumo olhar para isto:
- Facilidade de uso: Axios e Got são ótimos para async/await e sintaxe limpa.
- Desempenho: Got e node-fetch são leves e rápidos para scraping com alta concorrência.
- Suporte a proxy: Axios e Got facilitam a rotação de proxies.
- Tratamento de erros: por padrão, Axios lança erro em respostas HTTP com falha; o node-fetch exige checagens manuais.
- Comunidade: Axios e Got têm comunidades ativas e muitos exemplos.
Minhas recomendações rápidas:
- Scripts rápidos ou protótipos: node-fetch ou Unirest.
- Scraping em produção: Axios (pelos recursos) ou Got (pelo desempenho).
- Automação de navegador: Puppeteer ou Playwright lidam com as requisições internamente.
Análise de HTML e extração de dados: Cheerio, jsdom e mais
Depois de buscar o HTML, você precisa transformá-lo em algo realmente utilizável. É aí que entram os parsers.
Cheerio
Pense no Cheerio como o jQuery do servidor. É rápido, leve e perfeito para HTML estático.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
Prós: muito rápido, API familiar, lida bem com HTML bagunçado.
Contras: não executa JavaScript — vê apenas o que está no HTML.
Saiba mais sobre a velocidade e os casos de uso do Cheerio.
jsdom
O jsdom simula um DOM parecido com o de navegador dentro do Node.js. Ele consegue executar scripts simples e é mais “parecido com navegador” do que o Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Olá</p><script>document.querySelector('#greet').textContent += ", mundo!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
Prós: consegue executar scripts, suporta a API completa de DOM.
Contras: mais lento e pesado que o Cheerio, não é um navegador completo.
Compare Cheerio e jsdom em detalhes.
Quando usar expressões regulares ou outros métodos de análise
Regex em web scraping é como molho de pimenta: ótimo com moderação, mas não despeje em tudo. Regex é útil para:
- Extrair padrões de texto (e-mails, números de telefone, preços).
- Limpar ou validar dados extraídos.
- Puxar dados de blocos de texto ou tags de script.
Exemplo: extraindo um número de um texto
const text = "Vendas totais: 1,234 unidades";
const match = text.match(/([\d,]+)\s*unidades/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("Unidades vendidas:", units);
}
Mas não tente analisar HTML completo com regex — use um parser de DOM para isso. Mais dicas de regex para scraping.
Lidando com sites dinâmicos: Puppeteer, Playwright e navegadores sem interface
Os sites modernos adoram JavaScript. Às vezes, os dados que você quer não estão no HTML inicial — eles são renderizados por scripts depois que a página carrega. É aí que entram os navegadores sem interface.
Puppeteer
Uma biblioteca Node.js do Google que controla o Chrome/Chromium. É como ter um robô clicando e rolando páginas para você.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
Prós: renderização completa do Chrome, API fácil, excelente para conteúdo dinâmico.
Contras: só Chromium, mais pesado em recursos.
Leia mais sobre os pontos fortes do Puppeteer.
Playwright
Uma biblioteca mais nova da Microsoft, o Playwright suporta Chromium, Firefox e WebKit. É como o primo do Puppeteer, mais moderno e compatível com vários navegadores.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
Prós: multiplataforma entre navegadores, contextos paralelos, espera automática por elementos.
Contras: curva de aprendizado um pouco mais íngreme, instalação maior.
Por que o Playwright está ganhando espaço.
Nightmare
Uma ferramenta de automação baseada em Electron que foi popular há alguns anos. O repositório foi movido para a organização segment-boneyard no GitHub — o estacionamento de projetos que a Segment deixou de apoiar — e o último lançamento no npm foi em 2019. Eu não escolheria isso para nada novo em 2026; se você herdar um script que ainda usa essa ferramenta, tudo bem, mas, para um projeto novo, vá direto para Playwright ou Puppeteer.
Comparando soluções de navegador sem interface
| Aspecto | Puppeteer (Chrome) | Playwright (multi-navegador) | Nightmare (Electron) |
|---|---|---|---|
| Suporte a navegadores | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (antigo) |
| Desempenho e escala | Rápido, mas pesado | Rápido, melhor paralelismo | Mais lento, menos estável |
| Scraping dinâmico | Excelente | Excelente + mais recursos | OK para sites simples |
| Manutenção | Bem mantido | Muito ativo | Arquivado (segment-boneyard, último publish no npm em 2019) |
| Melhor para | Scraping no Chrome | Casos complexos e multiplataforma | Tarefas simples e legadas |
Meu conselho: use Playwright para projetos novos e complexos. O Puppeteer ainda é ótimo para tarefas focadas só no Chrome. O Nightmare serve mais para nostalgia ou scripts antigos.
Ferramentas de apoio: agendamento, ambiente, CLI e armazenamento de dados
Um scraper do mundo real é mais do que apenas buscar e analisar. Aqui estão algumas ferramentas de apoio das quais eu dependo:
Agendamento: node-cron
Programe scrapers para rodarem automaticamente.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Extraindo às 9h toda segunda-feira');
});
O node-cron é perfeito para automatizar tarefas repetitivas.
Gerenciamento de ambiente: dotenv
Mantenha segredos e configurações fora do seu código.
require('dotenv').config();
const apiKey = process.env.API_KEY;
Ferramentas de CLI: chalk, commander, inquirer
- chalk: colore a saída do console.
- commander: interpreta opções de linha de comando.
- inquirer: prompts interativos para entrada do usuário.
Armazenamento de dados
- fs: grava em arquivos (JSON, CSV).
- lowdb: banco JSON leve.
- sqlite3: banco SQL local.
- mongodb: banco NoSQL para projetos maiores.
Exemplo: salvar dados em JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
Os pontos dolorosos do Web Scraping tradicional com JavaScript e Node.js
Vamos ser sinceros: scraping tradicional não é só flores. Aqui estão as maiores dores de cabeça que eu já vi (e senti):

- Curva de aprendizado alta: é preciso entender DOM, seletores, lógica assíncrona e, às vezes, particularidades do navegador.
- Peso de manutenção: os sites mudam, os seletores quebram e você vive corrigindo código.
- Escalabilidade fraca: cada site precisa do seu próprio script; nada é realmente “tamanho único”.
- Complexidade na limpeza de dados: dados extraídos vêm bagunçados — limpar, formatar e remover duplicidades é um trabalho à parte.
- Limites de desempenho: automação de navegador é lenta e consome muitos recursos em tarefas de grande escala.
- Bloqueios e medidas anti-bot: sites bloqueiam scrapers, exibem CAPTCHAs ou escondem dados atrás de login.
- Zonas cinzentas legais e éticas: é preciso navegar por termos de uso, privacidade e conformidade.
Leia mais sobre esses pontos dolorosos e estatísticas do mundo real.
Thunderbit vs. Web Scraping tradicional: uma revolução de produtividade
Agora, vamos falar do elefante na sala: e se você pudesse pular todo o código, os seletores e a manutenção?
É aí que o Thunderbit entra. Como cofundador e CEO, sou um pouco tendencioso, mas me escute — o Thunderbit foi feito para usuários de negócios que querem dados, não dor de cabeça.
Como o Thunderbit se compara
| Aspecto | Thunderbit (IA sem código) | Web scraping tradicional em JS/Node |
|---|---|---|
| Configuração | 2 cliques, sem código | Escrever scripts, depurar |
| Conteúdo dinâmico | Tratado no navegador | Script com navegador sem interface |
| Manutenção | A IA se adapta às mudanças | Atualizações manuais de código |
| Extração de dados | IA sugere campos | Seletores manuais |
| Scraping de subpáginas | Integrado, 1 clique | Loop e código por site |
| Exportação | Excel, Sheets, Notion | Integração manual com arquivo/banco |
| Pós-processamento | Resumir, marcar, formatar | Código ou ferramentas extras |
| Quem pode usar | Qualquer pessoa com navegador | Apenas desenvolvedores |
A IA do Thunderbit lê a página, sugere campos e extrai os dados em apenas alguns cliques. Ele lida com subpáginas, se adapta a mudanças de layout e ainda pode resumir, classificar ou traduzir os dados enquanto faz a extração. Você pode exportar para Excel, Google Sheets, Airtable ou Notion — sem configuração técnica.
Casos de uso em que o Thunderbit brilha:
- Equipes de e-commerce acompanhando SKUs e preços da concorrência
- Equipes de vendas extraindo leads e informações de contato
- Pesquisadores de mercado agregando notícias ou avaliações
- Corretores de imóveis coletando anúncios e detalhes dos imóveis
Para scraping frequente e crítico para o negócio, o Thunderbit economiza muito tempo. Para projetos personalizados, em grande escala ou profundamente integrados, a programação tradicional ainda tem seu espaço — mas, para a maioria das equipes, o Thunderbit é o caminho mais rápido de “preciso de dados” para “já tenho os dados”.
Veja a extensão do Thunderbit em ação ou confira mais casos de uso no Thunderbit Blog.
Experimente o AI Web Scraper do Thunderbit
Referência rápida: bibliotecas populares de Web Scraping com JavaScript e Node.js
Aqui está sua cola para o ecossistema de scraping em JavaScript em 2026:
Requisições HTTP
- Axios: cliente HTTP baseado em promises e cheio de recursos.
- node-fetch: API Fetch para Node.js.
- Got: cliente HTTP rápido e avançado.
- SuperAgent: requisições HTTP maduras e encadeáveis.
- Unirest: cliente simples e agnóstico em relação à linguagem.
Análise de HTML
- Cheerio: analisador de HTML rápido, no estilo jQuery.
- jsdom: DOM semelhante ao de navegador no Node.js.
Conteúdo dinâmico
- Puppeteer: automação do Chrome sem interface.
- Playwright: automação multi-navegador.
- Nightmare: automação baseada em Electron, legada.
Agendamento
- node-cron: tarefas cron no Node.js.
CLI e utilitários
- chalk: estilização de texto no terminal.
- commander: parser de argumentos de CLI.
- inquirer: prompts interativos de CLI.
- dotenv: carregador de variáveis de ambiente.
Armazenamento
- fs: sistema de arquivos nativo.
- lowdb: banco JSON local pequeno.
- sqlite3: banco SQL local.
- mongodb: banco de dados NoSQL.
Frameworks
- Crawlee: framework de crawling e scraping de alto nível da Apify. A versão em JavaScript/TypeScript está na v3.16 em maio de 2026 e é a trilha mais madura (o port em Python é mais recente). Ele encapsula Puppeteer, Playwright, Cheerio e JSDOM em uma única API, com rotação de proxy e fila já integradas — útil se você se pega reconstruindo a mesma infraestrutura em torno dos seus scrapers.
(Sempre confira a documentação e os repositórios no GitHub para ver as atualizações mais recentes.)
Recursos recomendados para dominar Web Scraping em JavaScript
Quer ir mais fundo? Aqui vai uma lista curada de recursos para elevar seu nível em scraping:
Documentação oficial e guias
- MDN Web Docs: Web Scraping
- Documentação do Puppeteer
- Documentação do Playwright
- Documentação do Crawlee
- Apify Web Scraping Academy
Tutoriais e cursos
- freeCodeCamp: O guia definitivo para Web Scraping com Node.js
- YouTube: Web Scraping com Node.js (freeCodeCamp)
- DigitalOcean: como fazer scrape de um site usando Node.js e Puppeteer
Projetos e exemplos open source
Comunidade e fóruns
Livros e guias completos
- “Web Scraping with Python” da O’Reilly (para conceitos entre linguagens)
- Cursos na Udemy/Coursera: “Web Scraping in Node.js”
(Sempre verifique as edições e atualizações mais recentes.)
Como extrair qualquer site usando IA Get Started Free
Conclusão: escolhendo a abordagem certa para a sua equipe
Em resumo: JavaScript e Node.js oferecem poder e flexibilidade incríveis para web scraping. Dá para construir de tudo — de scripts rápidos e improvisados a crawlers robustos e escaláveis. Mas com grande poder vem uma grande... manutenção. A programação tradicional é melhor para projetos personalizados, pesados em engenharia, em que você precisa de controle total e está preparado para manutenção contínua.
Para todo o resto — para usuários de negócios, analistas, profissionais de marketing e qualquer pessoa que só queira os dados — soluções modernas sem código como o Thunderbit são um sopro de ar fresco. A extensão para Chrome com IA do Thunderbit permite extrair, estruturar e exportar dados em minutos, não em dias. Sem código, sem seletores, sem dor de cabeça.
Então, qual é a abordagem certa? Se a sua equipe tem força de engenharia e requisitos únicos, mergulhe na caixa de ferramentas do Node.js. Se você quer velocidade, simplicidade e liberdade para focar nos insights em vez da infraestrutura, experimente o Thunderbit. De qualquer forma, a web é o seu banco de dados — vá buscar esses dados.
E, se você ficar travado, lembre-se: até os melhores scrapers começaram com uma página em branco e uma boa xícara de café. Boa extração.
Quer aprender mais sobre scraping com IA ou ver o Thunderbit em ação?
- Site oficial do Thunderbit
- Baixar a extensão Thunderbit para Chrome
- Thunderbit Blog
- Como extrair qualquer site usando IA
- O que é Data Scraping e como fazê-lo em 2025
Se você tiver dúvidas, histórias ou causos favoritos de scraping, deixe nos comentários ou fale comigo. Adoro ver como as pessoas estão transformando a web no próprio playground de dados.
Fique curioso, mantenha-se cafeinado e continue extraindo de forma mais inteligente — não mais difícil.
Baixar a extensão Thunderbit para Chrome
Experimente o Raspador Web IA Get Started Free
FAQ:
1. Por que usar JavaScript e Node.js para web scraping em 2025?
Porque a maioria dos sites modernos é construída com JavaScript. O Node.js é rápido, funciona bem com assincronia e tem um ecossistema rico (por exemplo, Axios, Cheerio, Puppeteer) que dá suporte a tudo, desde buscas simples até a extração de conteúdo dinâmico em escala.
2. Qual é o fluxo típico para extrair um site com Node.js?
Geralmente, ele se parece com isto:
Requisição → Tratamento da resposta → (Execução opcional de JS) → Análise do HTML → Extração de dados → Salvamento ou exportação
Cada etapa pode ser executada por ferramentas específicas como axios, cheerio ou puppeteer.
3. Como extrair páginas dinâmicas renderizadas em JavaScript?
Use navegadores sem interface como Puppeteer ou Playwright. Eles carregam a página completa (incluindo JS), o que torna possível extrair o que os usuários realmente veem.
4. Quais são os maiores desafios do scraping tradicional?
- Mudanças na estrutura do site
- Detecção anti-bot
- Custo de recursos do navegador
- Limpeza manual dos dados
- Alta manutenção ao longo do tempo
Isso torna difícil sustentar scraping em larga escala ou sem apoio de desenvolvedores.
5. Quando devo usar algo como o Thunderbit em vez de código?
Use o Thunderbit se você precisa de velocidade, simplicidade e não quer escrever nem manter código. Ele é ideal para equipes de vendas, marketing ou pesquisa que querem extrair e estruturar dados rapidamente — especialmente em sites complexos ou com várias páginas.




