Lembro perfeitamente da primeira vez que tentei puxar dados de produtos de um site. Estava diante de uma página lotada de tênis de corrida e pensei: “Será que é tão difícil assim colocar todos esses nomes e preços numa planilha?” Algumas horas depois, já estava perdido em erros de JavaScript, seletores que não faziam sentido e uma admiração enorme por quem já montou um raspador web do zero.
Se você já passou por isso—seja no comercial, ecommerce ou operações, só querendo coletar dados fresquinhos para tomar decisões melhores—fica tranquilo, você não está sozinho. A procura por raspagem de dados online explodiu nos últimos anos. Para ter uma ideia, o e deve dobrar até 2030. Mas tem um porém: a maioria das ferramentas tradicionais exige um bom conhecimento técnico. Por isso, quero te mostrar dois caminhos: um método prático, com código usando Cypress, e uma alternativa sem código, baseada em IA, com o . Vamos usar a como exemplo.
Se você é dev e quer praticar JavaScript ou trabalha com negócios e não quer nem ouvir falar de código, este guia vai te ajudar a pegar os dados que precisa—sem perder a paciência (nem o fim de semana).
O que é Web Scraping e Por Que Isso é Importante para Empresas?
Resumindo: web scraping é o processo de puxar dados automaticamente de sites. Em vez de copiar e colar nome de produto, preço ou contato na mão, você usa um software para fazer esse trabalho pesado.
Mas por que isso é importante para negócios? Bom, dados são o novo ouro (ou leite de aveia, se preferir). Empresas de vendas, ecommerce e operações usam web scraping para:
- Gerar leads puxando contatos de diretórios ou redes sociais.
- Monitorar preços e tendências dos concorrentes—cerca de .
- Analisar a opinião dos clientes coletando avaliações e notas.
- Automatizar pesquisas repetitivas que levariam horas (ou dias) na mão.
E o retorno é real: dizem que dados públicos da web ajudam a tomar decisões mais rápidas e certeiras. Ou seja, se você não está usando web scraping, provavelmente está deixando dinheiro—e oportunidades—escaparem.
Apresentando o Cypress: Uma Ferramenta Popular para Web Scraping
Agora, vamos falar de ferramentas. Cypress é um framework open-source criado originalmente para testes automatizados de aplicações web. Pense nele como um robô que clica em botões, preenche formulários e confere se o site está funcionando. Mas aqui está o pulo do gato: como o Cypress roda num navegador de verdade e interage com sites cheios de JavaScript, ele também virou uma opção interessante (embora não tão convencional) para web scraping.
Como o Cypress se compara a outras ferramentas, especialmente as feitas em Python (tipo BeautifulSoup ou Scrapy)? Olha só:
- Cypress: Excelente para extrair conteúdo dinâmico, renderizado por JavaScript. Precisa saber JavaScript e ter noção de Node.js. É flexível e potente, mas voltado para devs.
- Raspadores em Python: Ferramentas como BeautifulSoup ou Scrapy são ótimas para grandes volumes e HTML estático. Têm um ecossistema gigante, mas podem sofrer com sites que só carregam conteúdo num navegador real.
Se você já manja de JavaScript ou testes de QA, o Cypress pode ser uma solução eficiente para scraping. Mas se não curte chaves e ponto e vírgula, calma—já já mostro uma alternativa sem código.
Passo a Passo: Web Scraping com Cypress (Exemplo com Tênis Adidas)
Vamos botar a mão na massa e criar um raspador Cypress para a . Nosso objetivo: puxar nomes, preços, imagens e links dos produtos para um arquivo organizado.
1. Preparando o Ambiente do Cypress
Primeiro, você precisa do e do npm instalados. Depois, abre o terminal e roda:
1mkdir adidas-scraper
2cd adidas-scraper
3npm init -y
4npm install cypress --save-devIsso cria um novo projeto e instala o Cypress localmente. Para abrir o Cypress pela primeira vez:
1npx cypress openO Cypress vai criar uma pasta cypress/ com testes de exemplo. Pode apagar esses arquivos e criar o seu próprio, por exemplo, cypress/e2e/adidas-scraper.cy.js.
2. Inspecionando o Site e Identificando os Dados para Extrair
Hora de investigar. Abra a no navegador, clique com o botão direito em um produto e escolha “Inspecionar”. Você vai ver que cada produto está num card, com elementos para nome, preço, imagem e link.
Por exemplo:
1<div class="product-card">
2 <a href="/us/adizero-sl2-running-shoes/XYZ123.html">
3 <img src="..." alt="Adizero SL2 Running Shoes"/>
4 <div class="product-price">$130</div>
5 <div class="product-name">Adizero SL2 Running Shoes -- Men's Running</div>
6 </a>
7</div>Fique de olho em classes como .gl-price para preços e procure padrões no HTML. É isso que você vai indicar ao Cypress para capturar.
3. Escrevendo o Código Cypress para Extrair Dados
Veja um exemplo de script Cypress para começar:
1// cypress/e2e/adidas-scraper.cy.js
2describe('Scrape Adidas Running Shoes', () => {
3 it('collects product name, price, image, and link', () => {
4 cy.visit('<https://www.adidas.com/us/men-running-shoes>');
5 const products = [];
6 cy.get('a[href*="/us/"][href*="running-shoes"]').each(($el) => {
7 const name = $el.find('*:contains("Running Shoes")').text().trim();
8 const price = $el.find('.gl-price').text().trim();
9 const imageUrl = $el.find('img').attr('src');
10 const link = $el.attr('href');
11 products.push({ name, price, image: imageUrl, link: `https://www.adidas.com$\{link\}` });
12 }).then(() => {
13 cy.writeFile('cypress/output/adidas_products.json', products);
14 });
15 });
16});O que está rolando aqui?
cy.visit()carrega a página.cy.get()seleciona todos os links de produtos que seguem o padrão da Adidas..each()percorre cada produto, pegando nome, preço, imagem e link.- Os dados vão para um array e são salvos num arquivo JSON.
Talvez você precise ajustar os seletores se a Adidas mudar o site, mas isso já cobre boa parte do processo.
4. Exportando e Usando os Dados Extraídos
Depois de rodar o script (pelo Cypress GUI ou npx cypress run), confira o arquivo cypress/output/adidas_products.json. Você vai ver um array de objetos assim:
1[
2 {
3 "name": "Adizero SL2 Running Shoes Men's Running",
4 "price": "$130",
5 "image": "<https://assets.adidas.com/images/w_280,h_280,f_auto,q_auto:sensitive/.../adizero-SL2-shoes.jpg>",
6 "link": "<https://www.adidas.com/us/adizero-sl2-running-shoes/XYZ123.html>"
7 },
8 ...
9]A partir daí, você pode converter o JSON para CSV, analisar no Excel ou importar para sua ferramenta de BI favorita. Se quiser ir além, pode até automatizar para rodar todo dia e monitorar preços.
Desafios Comuns ao Fazer Web Scraping com Cypress
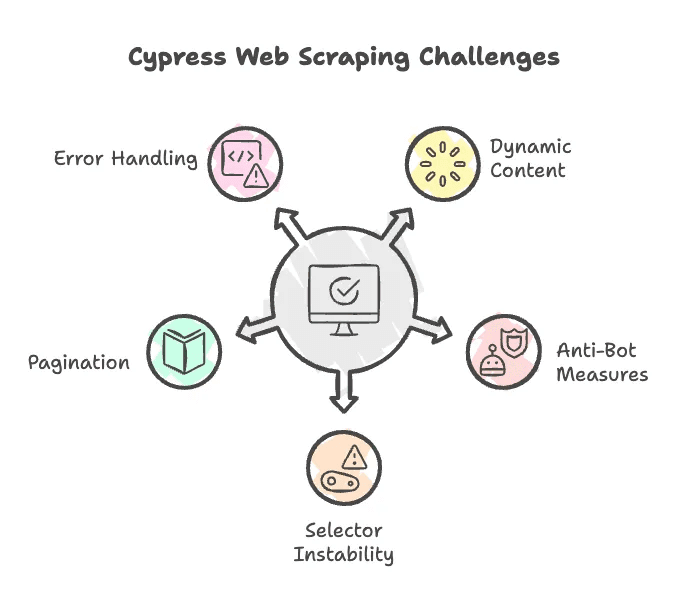
Vamos ser sinceros: web scraping nem sempre é moleza. Veja alguns obstáculos comuns ao usar Cypress (e dicas para driblar):
- Conteúdo Dinâmico em JavaScript: O Cypress lida bem com conteúdo dinâmico, mas às vezes é preciso esperar elementos carregarem ou rolar a página para ativar o carregamento. Use
cy.wait()ou comandos de rolagem quando necessário. - Defesas Anti-bot: Alguns sites bloqueiam bots verificando o user agent ou limitando requisições. O Cypress roda num navegador real, o que ajuda, mas bloqueios persistentes podem exigir táticas mais avançadas (tipo proxies rotativos ou alteração de cabeçalhos).
- Seletores Instáveis: Se a Adidas mudar o HTML ou nomes de classes, seu script pode quebrar. Fique pronto para atualizar os seletores com frequência.
- Paginação: Muitas páginas de produtos têm várias páginas. Vai ser preciso criar lógica para clicar em “Próximo” e juntar os resultados.
- Tratamento de Erros: O Cypress foi feito para testes, então costuma falhar de forma explícita se algo estiver faltando. Adicione verificações para lidar com elementos ausentes sem travar tudo.
Se você está achando que precisa de diploma em computação só para listar tênis, relaxa. Foi justamente por isso que criamos o Thunderbit.
Achou Complicado? Experimente o Thunderbit para Web Scraping em 2 Cliques
Se você não quer esquentar a cabeça com Node.js, seletores ou depuração de JavaScript, conheça o , nossa extensão Chrome de raspagem web com IA. Ela foi feita para quem só quer os dados—sem código, sem configuração, sem dor de cabeça.
O que faz o Thunderbit ser diferente:
- Sem código ou ajuste de seletores: Só apontar, clicar e deixar a IA fazer o resto.
- Um template, vários sites: A IA do Thunderbit se adapta a diferentes layouts, sem precisar reconfigurar para cada página.
- Raspagem no navegador ou na nuvem: Escolha o modo que melhor atende sua necessidade de velocidade e precisão.
- Lida com paginação e subpáginas: O Thunderbit navega por várias páginas e pode acessar páginas de detalhes para enriquecer seus dados.
- Exportação gratuita: Baixe seus dados para Excel, Google Sheets, Airtable ou Notion—sem surpresas ou taxas escondidas.
Veja como raspar a página da Adidas com o Thunderbit.
Passo a Passo: Web Scraping com Thunderbit (Exemplo Adidas)
1. Instalando a Extensão Thunderbit no Chrome
Primeiro, instale o . Leva menos de um minuto—mais rápido do que achar minha caneca de café de manhã.
Crie uma conta gratuita—o Thunderbit oferece teste grátis (10 páginas) e um plano gratuito (6 páginas por mês), então você pode testar em tarefas reais sem precisar de cartão de crédito.
2. Extraindo Dados com o AI Suggest Fields
- Abra a .
- Clique no ícone do Thunderbit no navegador. A barra lateral será aberta.
- Clique em “AI Suggest Fields”. A IA do Thunderbit analisa a página e identifica automaticamente os campos de nome, preço, imagem e link dos produtos. Você vê uma prévia dos primeiros resultados.
- Quer ajustar as colunas? É só renomear ou adicionar novos campos com um clique. Se quiser ir além, pode dar comandos em português, tipo “também extraia o número de cores disponíveis”.
- Clique em “Scrape”. O Thunderbit coleta todos os dados, navegando automaticamente por várias páginas se precisar. Para pegar mais detalhes de cada produto, use o recurso de subpáginas—o Thunderbit visita cada item e enriquece sua tabela.
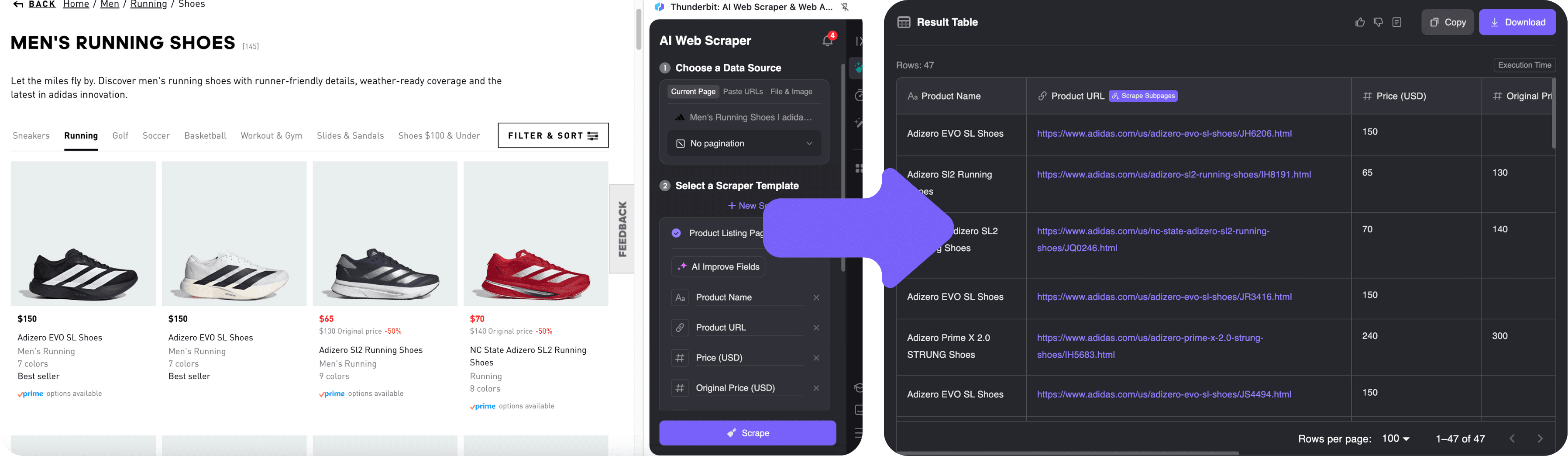
3. Exportando e Usando Seus Dados
Quando a extração terminar, revise a tabela na barra lateral do Thunderbit. Você pode:
- Exportar para Excel, Google Sheets, Airtable ou Notion com um clique.
- Baixar como CSV ou JSON.
- Exportar imagens, e-mails, telefones e mais—o Thunderbit suporta todos os tipos de dados comuns.
E sim, exportar é totalmente grátis. Sem pegadinhas ou taxas escondidas.
Para mais dicas, confira nosso ou acesse o para mais tutoriais de scraping.
Comparando Cypress e Thunderbit: Qual Ferramenta de Web Scraping é Melhor para Você?
Vamos colocar Cypress e Thunderbit lado a lado. Veja a tabela comparativa:
| Aspecto | Cypress (Raspador com Código) | Thunderbit (Raspador Web IA sem Código) |
|---|---|---|
| Dificuldade de Configuração | Requer Node.js, npm e conhecimento em JavaScript. A configuração inicial pode ser trabalhosa para quem não é dev. | Instale a extensão do Chrome, faça login e comece em minutos. Não precisa programar. |
| Habilidades Técnicas Necessárias | É preciso saber JavaScript e seletores DOM/CSS. Barreiras altas para quem não programa. | Não exige programação. Interface intuitiva e comandos em linguagem natural. |
| Velocidade de Implementação | Escrever e depurar scripts pode levar horas, especialmente em páginas complexas ou com paginação. | Configure e execute a extração em poucos cliques. Lida com paginação e subpáginas automaticamente. |
| Flexibilidade | Extremamente flexível—permite qualquer lógica, logins, captchas e integração com APIs. | Focado em padrões comuns. A IA cobre a maioria dos sites, mas fluxos muito específicos podem exigir ajustes manuais. |
| Robustez a Mudanças | Scripts são frágeis—se o HTML do site mudar, será preciso atualizar o código. | Mais robusto—a IA se adapta a pequenas mudanças de layout. O Thunderbit é atualizado constantemente para novos padrões. |
| Escalabilidade | Suporta volume moderado, mas a raspagem via navegador é mais lenta em grande escala. | Raspagem em nuvem pode lidar com centenas de páginas. O sistema de créditos mantém o uso sob controle para empresas. |
| Indicado Para | Desenvolvedores ou usuários técnicos que precisam de precisão e lógica personalizada. Ótimo para coletas pontuais ou fluxos complexos. | Profissionais de negócios que querem rapidez e praticidade para tarefas repetitivas como monitoramento de preços, geração de leads ou extração de listas. Ideal para prototipagem e sites de ecommerce, diretórios ou avaliações. |
Resumindo: Cypress oferece controle, Thunderbit oferece agilidade e simplicidade. Se você é dev e gosta de personalizar tudo, o Cypress é seu laboratório. Se só quer os dados (e seu chefe tem pressa), o Thunderbit é seu parceiro.
Principais Pontos: Como Escolher a Melhor Abordagem de Web Scraping para Você
- Web scraping é indispensável para empresas modernas—seja para acompanhar concorrentes, gerar leads ou analisar tendências de mercado.
- Cypress é uma ferramenta poderosa e flexível para devs que querem criar seus próprios raspadores. Ótima para sites dinâmicos e fluxos personalizados, mas exige curva de aprendizado e manutenção constante.
- Thunderbit foi feito para todo mundo. É uma que deixa a extração de dados tão fácil quanto dois cliques—sem código, sem configuração, sem dor de cabeça. Lida com paginação, subpáginas e exporta para suas ferramentas favoritas, de graça.
- Escolha o Cypress se precisa de máxima flexibilidade e não se importa em programar.
- Escolha o Thunderbit se quer economizar tempo, evitar complicação técnica e pegar dados limpos rapidinho—especialmente se trabalha com vendas, ecommerce, marketing ou operações.
Quer ver mais exemplos? Dá uma olhada no para tutoriais sobre , e muito mais.
E se um dia você topar com uma página cheia de tênis de corrida e se perguntar como colocar tudo aquilo numa planilha—lembre-se, você tem opções. Boa raspagem!
Perguntas Frequentes
1. O que é Cypress e como pode ser usado para web scraping?
Cypress é uma ferramenta de testes baseada em JavaScript que pode interagir com sites dinâmicos, sendo útil para extrair conteúdo gerado por JavaScript.
2. Quais os principais desafios ao raspar sites com Cypress?
Os problemas mais comuns incluem mudanças na estrutura do HTML, carregamento dinâmico, defesas anti-bot e lidar com paginação ou elementos ausentes em páginas complexas.
3. Existe uma forma mais fácil de raspar sites sem programar?
Sim, o Thunderbit é uma extensão Chrome com IA que extrai dados em poucos cliques—sem código, configuração ou ajustes de seletores.
Saiba Mais: