

Tem uma coisa meio fora do tempo em abrir o terminal, digitar um comando só e ver os dados brutos da web brotarem ali na tela, como se você tivesse acabado de espiar a Matrix por dentro. Pra devs e usuários mais técnicos, o cURL é essa varinha de condão — uma ferramenta de linha de comando discreta que, sem alarde, roda em bilhões de dispositivos, de servidores na nuvem a geladeiras inteligentes. E, mesmo em 2026, com todo o arsenal de scrapers sem código e com IA por aí, o web scraping com cURL segue sendo aposta certa pra quem quer velocidade, controle e automação via script.
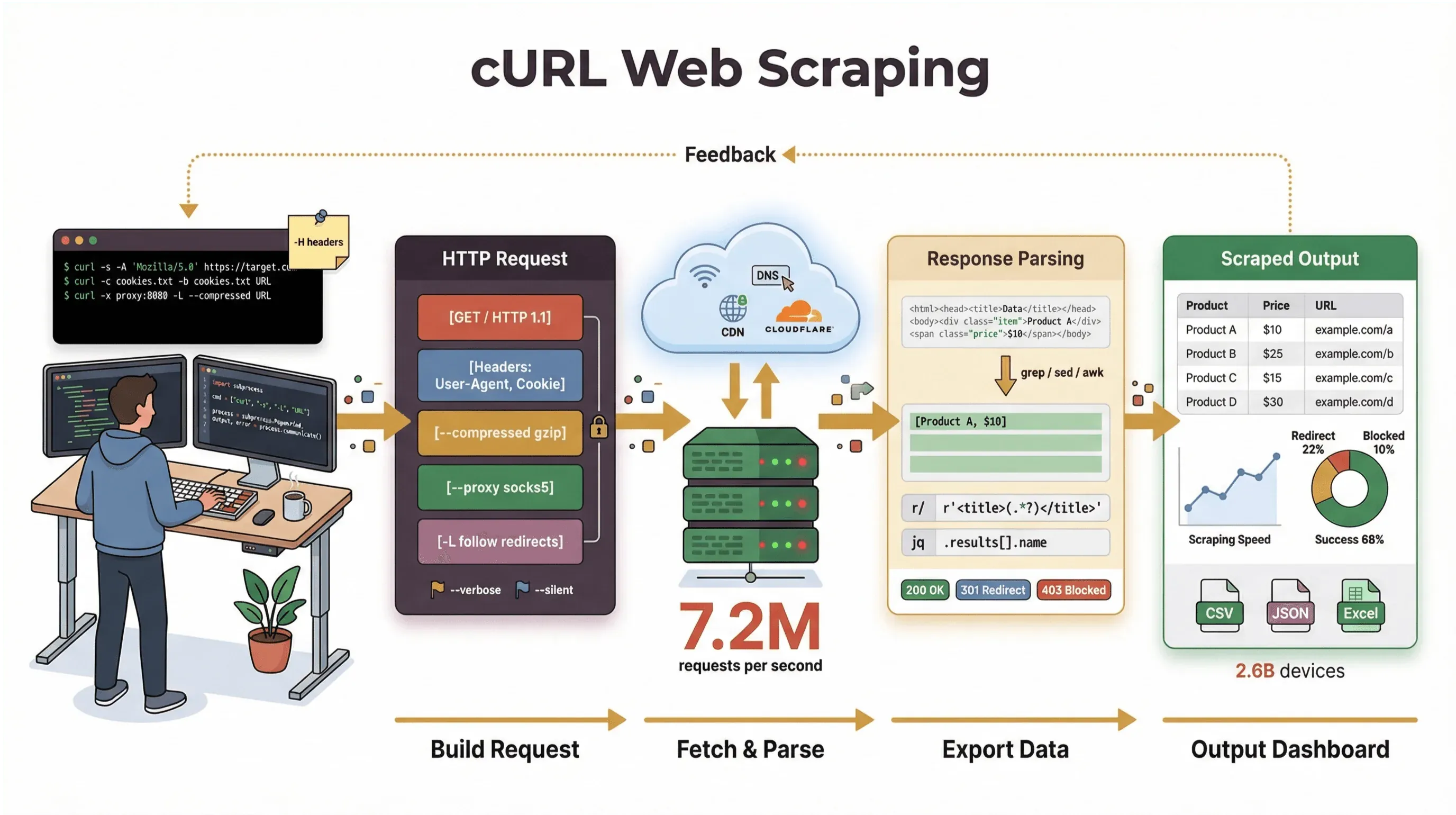 Passei anos construindo ferramentas de automação e ajudando equipes a lidar com dados da web, e ainda recorro ao cURL toda vez que preciso capturar uma página, depurar uma API ou montar um protótipo de fluxo de scraping. Neste guia, vou te levar por um tutorial de web scraping com cURL que vai do básico até uns truques mais avançados — com comandos reais, dicas de quem usa e uma visão honesta de onde o cURL arrasa e onde começa a mostrar os limites. E, se você é mais do tipo usuário de negócios e prefere nem encostar na linha de comando, vou mostrar como o Thunderbit, o nosso raspador web com IA, leva você de "preciso desses dados" pra "tá aqui a minha planilha" em dois cliques — sem programar nada.
Passei anos construindo ferramentas de automação e ajudando equipes a lidar com dados da web, e ainda recorro ao cURL toda vez que preciso capturar uma página, depurar uma API ou montar um protótipo de fluxo de scraping. Neste guia, vou te levar por um tutorial de web scraping com cURL que vai do básico até uns truques mais avançados — com comandos reais, dicas de quem usa e uma visão honesta de onde o cURL arrasa e onde começa a mostrar os limites. E, se você é mais do tipo usuário de negócios e prefere nem encostar na linha de comando, vou mostrar como o Thunderbit, o nosso raspador web com IA, leva você de "preciso desses dados" pra "tá aqui a minha planilha" em dois cliques — sem programar nada.
Bora ver por que o cURL continua relevante pra web scraping em 2026, como usá-lo de um jeito eficiente e quando vale a pena chamar algo ainda mais parrudo.
O que é o cURL? A base do web scraping com cURL
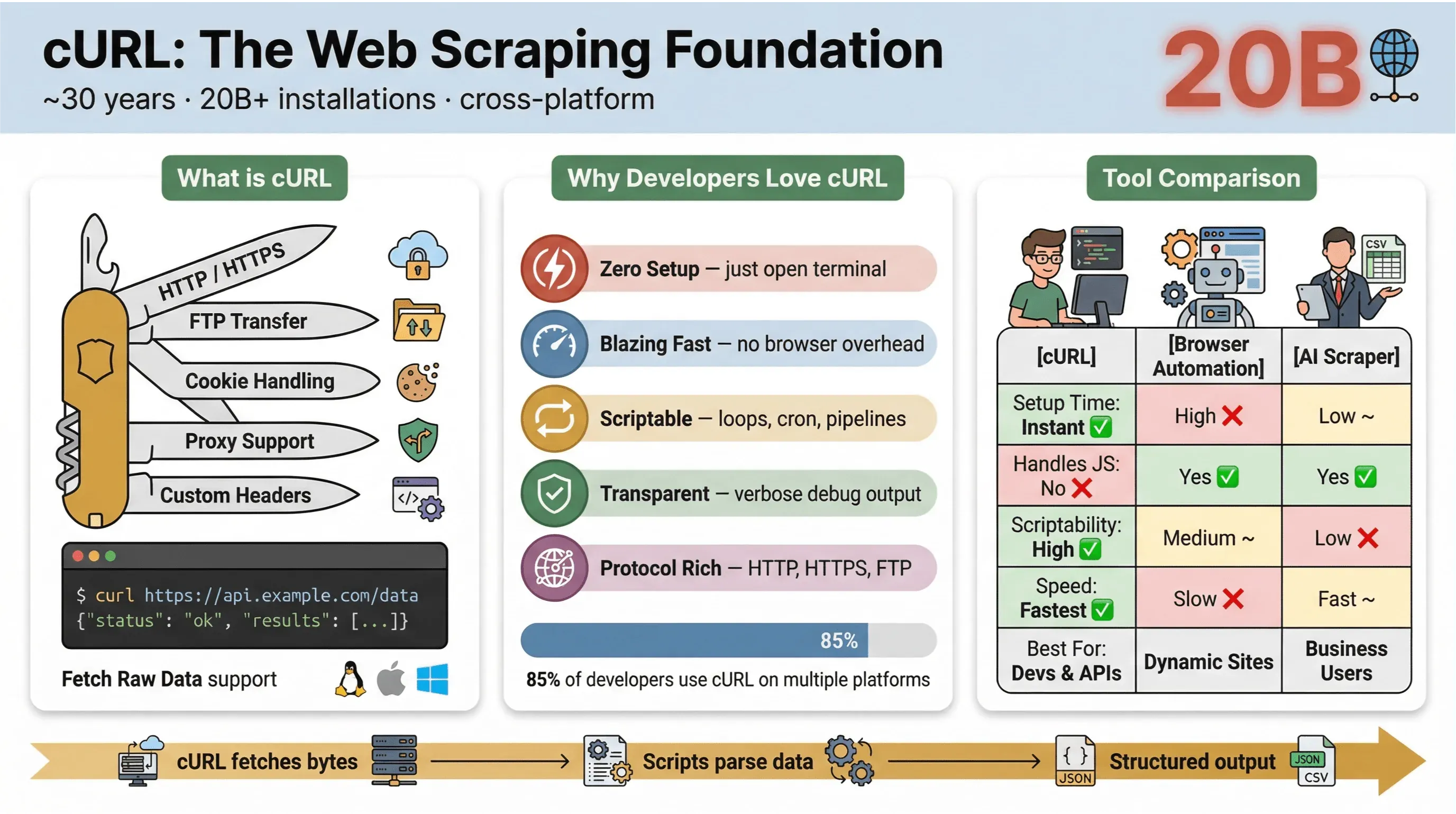
No fundo, o cURL é uma ferramenta de linha de comando (e também uma biblioteca) pra transferir dados via URLs. Existe há quase 30 anos (sim, é isso mesmo) e está em todo lugar — embutido nos sistemas operacionais, movendo scripts e cuidando, sem ninguém perceber, de transferências de dados em mais de vinte bilhões de instalações. Se você já rodou um comando rápido pra buscar uma página, testar uma API ou baixar um arquivo, tem grande chance de ter usado o cURL.
 O que torna o cURL tão querido pra web scraping:
O que torna o cURL tão querido pra web scraping:
- Leve e multiplataforma: roda no Linux, macOS, Windows e até em dispositivos embarcados.
- Suporte a protocolos: dá conta de HTTP, HTTPS, FTP e muito mais.
- Automatizável por script: perfeito pra automação, cron jobs e código de integração.
- Não exige interação: foi pensado pra uso não interativo — ótimo pra tarefas em lote e pipelines.
Mas tem um ponto que precisa ficar claro: a função principal do cURL é buscar dados brutos — HTML, JSON, imagem, enfim, qualquer coisa. Ele não faz parsing, não renderiza nem estrutura esses dados sozinho. Pense no cURL como a "primeira etapa" do web scraping: ele entrega os bytes, mas você ainda vai precisar de outras ferramentas (script em Python, grep/sed/awk ou um raspador web com IA) pra transformar isso em informação estruturada.
Se quiser ver a documentação oficial, dá uma olhada no guia de scripting HTTP do cURL.
Por que usar cURL para Web Scraping? (tutorial de web scraping com cURL)
Então por que devs e usuários técnicos seguem voltando ao cURL pra web scraping, mesmo com tanta ferramenta nova surgindo? Olha o que faz o cURL se destacar:
- Configuração mínima: sem instalação, sem dependência — abre o terminal e parte pra cima.
- Velocidade: os dados chegam na hora, sem ficar esperando o navegador carregar.
- Automação por script: dá pra iterar sobre URLs, automatizar requisições e encadear comandos numa boa.
- Suporte a protocolos e recursos: cookies, proxies, redirecionamentos, cabeçalhos personalizados e por aí vai.
- Transparência: você vê exatamente o que está rolando com a saída verbosa/de depuração.
Na pesquisa de usuários do cURL de 2025, 85,7% dos respondentes disseram usar a ferramenta de linha de comando do cURL e 96,2% indicaram usá-la no Linux — de longe a plataforma mais comum pro cURL.
--- Ele segue sendo o canivete suíço das requisições HTTP, das coletas rápidas de dados e do troubleshooting.
Aqui vai uma comparação rápida entre o cURL e outros métodos de scraping:
| Funcionalidade | cURL | Automação de navegador (ex.: Selenium) | Raspador Web com IA (ex.: Thunderbit) |
|---|---|---|---|
| Tempo de configuração | Instantâneo | Alto | Baixo |
| Automatizável por script | Alto | Médio | Baixo (sem necessidade de código) |
| Lida com JavaScript | Não | Sim | Sim (Thunderbit: via navegador) |
| Suporte a cookies/sessão | Manual | Automático | Automático |
| Estruturação dos dados | Manual (fazer parsing depois) | Manual (fazer parsing depois) | Baseado em IA/modelos |
| Melhor para | Devs, coletas rápidas | Sites complexos e dinâmicos | Usuários de negócios, exportação estruturada |
Resumindo: o cURL é imbatível em coletas rápidas e automatizáveis — ainda mais em páginas estáticas, APIs ou quando você quer automatizar fluxos simples. Mas, na hora de interpretar HTML complexo, lidar com JavaScript ou exportar dados estruturados, é melhor partir pra uma ferramenta mais especializada.
Como começar: exemplos básicos de comandos de web scraping com cURL
Bora pôr a mão na massa. Veja como usar o cURL pra tarefas básicas de web scraping, passo a passo.
Capturar HTML bruto com cURL
O caso mais simples: pegar o HTML de uma página.
curl https://books.toscrape.com/
Esse comando vai buscar a página inicial do Books to Scrape, um site público de demonstração pra web scraping. Você vai ver a saída HTML bruta no terminal — procure por tags como <title> ou trechos como "In stock".
Salvar a saída num arquivo
Quer guardar esse HTML pra analisar depois? Use a flag -o:
curl -o page.html https://books.toscrape.com/
Agora você tem um arquivo page.html com todo o conteúdo HTML. Perfeito pra análise posterior ou pra fazer parsing com outras ferramentas.
Enviar requisições POST com cURL
Precisa enviar um formulário ou conversar com uma API? Use a flag -d pra requisições POST. Aqui vai um exemplo com o httpbin, um site feito pra testes HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Você vai receber uma resposta JSON refletindo os dados enviados — ótimo pra teste e prototipagem.
Inspecionar cabeçalhos e depurar
Às vezes você quer ver os cabeçalhos da resposta ou depurar a requisição:
-
Só os cabeçalhos (requisição HEAD):
curl -I https://books.toscrape.com/ -
Incluir os cabeçalhos junto com o corpo:
curl -i https://httpbin.org/get -
Saída verbosa/de depuração:
curl -v https://books.toscrape.com/
Essas flags ajudam você a entender o que rola por baixo dos panos — coisa essencial pra troubleshooting.
Segue uma tabela de referência rápida pra esses comandos:
| Tarefa | Exemplo de comando | Observações |
|---|---|---|
| Obter HTML | curl URL | Mostra o HTML no terminal |
| Salvar num arquivo | curl -o arquivo.html URL | Grava a saída num arquivo |
| Inspecionar cabeçalhos | curl -I URL ou curl -i URL | -I só HEAD, -i inclui cabeçalhos com o corpo |
| Enviar dados de formulário | curl -d "a=1&b=2" URL | Envia dados codificados como formulário |
| Depurar requisição/resposta | curl -v URL | Mostra informação detalhada da requisição/resposta |
Pra mais exemplos, veja a documentação oficial de scripting do cURL.
Subir de nível: web scraping avançado com cURL (web scraping com cURL)
Depois de pegar o jeito do básico, o cURL abre um leque de recursos avançados pra tarefas de scraping mais complexas.
Lidar com cookies e sessões
Muitos sites exigem cookies pra manter a sessão de login ou rastrear o usuário. Com o cURL, dá pra salvar e reaproveitar cookies entre as requisições:
# Salvar cookies após o login
curl -c cookies.txt https://example.com/login
# Usar cookies nas requisições seguintes
curl -b cookies.txt https://example.com/account
Isso deixa você simular sessão de navegador e acessar páginas atrás de login (desde que não tenha nenhum desafio em JavaScript no caminho).
Falsificar User-Agent e cabeçalhos personalizados
Alguns sites mostram conteúdo diferente conforme o seu User-Agent ou outros cabeçalhos. Por padrão, o cURL se identifica como "curl/VERSÃO", o que pode disparar bloqueios ou um conteúdo alternativo. Pra fingir ser um navegador:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Dá também pra definir cabeçalhos personalizados, tipo preferência de idioma:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Isso ajuda a receber o mesmo conteúdo que um navegador de verdade veria.
Usar proxies para web scraping
Precisa rotear suas requisições por um proxy (pra testar por região ou fugir de bloqueio de IP)? Use a flag -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Só vá com responsabilidade: use proxies dentro dos termos de serviço do site.
Automatizar scraping de várias páginas
Quer raspar várias páginas — tipo listas de produtos paginadas? Use um loop simples no shell:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Isso vai capturar as páginas 2 a 5 do catálogo do Books to Scrape e salvar cada uma num arquivo separado. (A página 1 é a página inicial.)
Limitações do web scraping com cURL: o que você precisa saber
Por mais que eu goste do cURL, ele não faz milagre. Olha onde ele deixa a desejar:
- Não executa JavaScript: o cURL não dá conta de páginas que dependem de JavaScript pra renderizar conteúdo ou passar por desafios anti-bot (developers.cloudflare.com).
- Parsing fica por sua conta: ele te entrega HTML ou JSON bruto, mas você vai ter que interpretar isso sozinho — muitas vezes com script ou ferramenta extra.
- Gestão de sessão limitada: login complexo, token ou formulário em várias etapas viram uma confusão rapidinho.
- Sem estruturação nativa de dados: o cURL não transforma página da web em linha, tabela ou planilha.
- Vulnerável à detecção anti-bot: muitos sites hoje usam defesas avançadas contra bots (JavaScript, fingerprinting, CAPTCHAs) que o cURL simplesmente não consegue contornar (datadome.co).
Aqui vai uma tabela comparativa rápida:
| Limitação | Apenas cURL | Ferramentas modernas de scraping (ex.: Thunderbit) |
|---|---|---|
| Suporte a JavaScript | Não | Sim |
| Estruturação dos dados | Manual | Automática (IA/modelo) |
| Gestão de sessão | Manual | Automática |
| Contorno de anti-bot | Limitado | Avançado (baseado em navegador/IA) |
| Facilidade de uso | Técnico | Sem necessidade de conhecimento técnico |
Pra página estática e API, o cURL é fantástico. Pra qualquer coisa mais dinâmica ou protegida, é melhor subir um degrau na cadeia de ferramentas.
Thunderbit vs. cURL: a melhor abordagem de web scraping para quem não é técnico
Agora vamos falar do Thunderbit, a nossa extensão do Chrome de raspador web com IA. Se você é de vendas, marketing ou operações e só quer levar dados de um site pro Excel, Google Sheets ou Notion — sem nem chegar perto do terminal — o Thunderbit foi feito pra você.
Veja como o Thunderbit se compara ao cURL:
| Funcionalidade | cURL | Thunderbit |
|---|---|---|
| Interface | Linha de comando | Clicar e selecionar (extensão Chrome) |
| Sugestão de campos por IA | Não | Sim (a IA lê a página e sugere colunas) |
| Lida com paginação/subpáginas | Script manual | Automático (a IA detecta e extrai) |
| Exportação de dados | Manual (fazer parsing + salvar) | Direto para Excel, Google Sheets, Notion, Airtable |
| Páginas com JavaScript/protegidas | Não | Sim (scraping via navegador) |
| Sem necessidade de código | Não (exige scripts) | Sim (qualquer pessoa consegue usar) |
| Plano gratuito | Sempre grátis | Grátis para até 6 páginas (10 com impulso de teste) |
Com o Thunderbit, é só abrir a extensão, clicar em "AI Suggest Fields" e deixar a IA descobrir quais dados extrair. Dá pra raspar tabelas, listas, detalhes de produto e até visitar subpáginas no automático. Depois, exporte os dados direto pras suas ferramentas de negócio favoritas — sem parsing, sem dor de cabeça.
O Thunderbit já tem a confiança de mais de 100.000 usuários no mundo todo e faz especial sucesso entre equipes de vendas, e-commerce e imobiliário que precisam de dados estruturados rapidinho.
Experimente a Extensão Chrome do Thunderbit para Web Scraping
Quer testar? Baixe a Extensão Chrome aqui.
Combinar cURL e Thunderbit: estratégias flexíveis de web scraping
Se você é um usuário técnico, não precisa escolher só uma ferramenta. Na prática, muita equipe usa cURL e Thunderbit juntos pra ter o máximo de flexibilidade:
- Prototipe com cURL: use o cURL pra testar endpoints rapidinho, inspecionar cabeçalhos e sacar como o site responde.
- Escale com o Thunderbit: quando precisar de dados estruturados, scraping de várias páginas ou de um fluxo que se repete, mude pro Thunderbit pra extração com um clique e exportação direta.
Aqui vai um exemplo de fluxo de trabalho pra pesquisa de mercado:
- Use o cURL pra buscar algumas páginas e inspecionar a estrutura do HTML.
- Identifique os campos de dados que você quer (por exemplo: nome de produto, preço, avaliação).
- Abra o Thunderbit, clique em "AI Suggest Fields" e deixe a IA configurar o raspador.
- Raspe todas as páginas (inclusive subpáginas ou listas paginadas) e exporte pro Google Sheets.
- Analise, compartilhe e aja sobre os dados — sem precisar de parsing manual.
E uma tabela rápida pra te ajudar a decidir:
| Cenário | Usar cURL | Usar Thunderbit | Usar ambos |
|---|---|---|---|
| Captura rápida de API ou página estática | ✅ | ||
| Precisa de dados estruturados em planilha | ✅ | ||
| Depuração de cabeçalhos/cookies | ✅ | ||
| Scraping de páginas dinâmicas/pesadas em JS | ✅ | ||
| Construir um fluxo repetível, sem código | ✅ | ||
| Prototipar e depois escalar | ✅ | ✅ | Fluxo híbrido |
Desafios comuns e armadilhas no web scraping com cURL
Antes de sair usando o cURL sem freio, vale falar dos perrengues reais que você vai encontrar:
- Sistemas anti-bot: muitos sites hoje usam defesas avançadas (desafios em JavaScript, CAPTCHAs, fingerprinting) que o cURL não consegue contornar (developers.cloudflare.com).
- Problemas de qualidade de dados: mudança no HTML, campo faltando ou layout inconsistente podem quebrar os seus scripts.
- Custo de manutenção: toda vez que o site muda, você vai ter que atualizar a sua lógica de parsing.
- Riscos legais e de conformidade: confira sempre os termos de serviço do site, o robots.txt e as leis aplicáveis antes de fazer scraping. Só porque o dado é público não quer dizer que o uso seja livre (calawyers.org, polsinelli.com).
- Limites de escala: o cURL é ótimo pra tarefa pequena, mas, pra scraping em larga escala, você vai ter que gerenciar proxies, limite de taxa e tratamento de erro.
Dicas pra depurar e ficar em conformidade:
- Comece sempre por sites com permissão ou de demonstração (como o Books to Scrape).
- Respeite os limites de taxa — não sobrecarregue os endpoints.
- Evite raspar dado pessoal, a menos que tenha uma base legal pra isso.
- Se esbarrar em barreira de JavaScript ou CAPTCHA, considere migrar pra uma ferramenta baseada em navegador, como o Thunderbit.
Resumo passo a passo: como fazer scraping de sites com cURL
Aqui vai a sua checklist de consulta rápida pra web scraping com cURL:
- Identifique o(s) seu(s) URL(s) de destino: comece com uma página estática ou endpoint de API.
- Busque a página:
curl URL - Salve a saída num arquivo:
curl -o file.html URL - Inspecione cabeçalhos/depure:
curl -I URL,curl -v URL - Envie dados via POST:
curl -d "a=1&b=2" URL - Gerencie cookies/sessões:
curl -c cookies.txt ...,curl -b cookies.txt ... - Defina cabeçalhos/User-Agent personalizados:
curl -A "..." -H "..." URL - Siga os redirecionamentos:
curl -L URL - Use proxies (se precisar):
curl -x proxy:port URL - Automatize o scraping de várias páginas: use loops de shell ou scripts.
- Faça parsing e estruture os dados: use ferramentas/scripts extras conforme a necessidade.
- Mude pro Thunderbit pra scraping estruturado, sem código, ou pra páginas dinâmicas.
Conclusão e principais aprendizados: escolher a ferramenta certa de web scraping
Extraia dados de qualquer site usando IA Get Started Free
O web scraping com cURL segue sendo uma habilidade poderosa pra usuários técnicos em 2026 — principalmente pra coletas rápidas, prototipagem e automação. A velocidade, a capacidade de automatizar por script e a onipresença do cURL fazem dele um item básico na caixa de ferramentas de qualquer dev. Mas, conforme a web fica mais dinâmica e protegida, e os usuários de negócios passam a exigir dados estruturados sem código, ferramentas como o Thunderbit estão redefinindo o que é possível.
Principais aprendizados:
- Use o cURL pra páginas estáticas, APIs e protótipos rápidos — especialmente quando quiser controle total.
- Mude pro Thunderbit (ou outros raspadores web com IA parecidos) quando precisar de dados estruturados, lidar com páginas dinâmicas/pesadas em JavaScript ou quiser um fluxo de trabalho sem código e voltado pra negócios.
- Combine os dois pra ter o máximo de flexibilidade: prototipe com cURL, escale e estruture com o Thunderbit.
- Faça scraping sempre com responsabilidade — respeite os termos do site, os limites de taxa e os limites legais.
Curioso pra ver como o web scraping pode ser simples? Experimente a extensão gratuita do Thunderbit para Chrome e veja na prática a extração de dados com IA. E, se quiser se aprofundar, dá uma olhada no Blog do Thunderbit pra mais tutoriais, dicas e insights do setor. Você também pode curtir:
- Como Fazer Scraping de Qualquer Site Usando IA
- Como Extrair Dados de Sites para o Excel usando IA
- O que é Data Scraping e Como Fazer Isso em 2025
Boas coletas — e que os seus dados estejam sempre limpos, estruturados e a só um comando (ou clique) de distância.
Conheça os planos do Thunderbit para web scraping escalável
FAQs
1. O cURL consegue lidar com páginas renderizadas em JavaScript?
Não, o cURL não executa JavaScript. Ele busca o HTML bruto que o servidor entrega. Se uma página precisa de JavaScript pra renderizar conteúdo ou resolver desafio anti-bot, o cURL não vai conseguir acessar os dados. Nesses casos, use ferramentas baseadas em navegador, como o Thunderbit.
2. Como salvo a saída do cURL direto num arquivo?
Use a flag -o: curl -o nome-do-arquivo.html URL. Isso grava o corpo da resposta num arquivo, em vez de jogar no terminal.
3. Qual é a diferença entre cURL e Thunderbit para web scraping?
O cURL é uma ferramenta de linha de comando pra buscar dados brutos da web — ótima pra usuários técnicos e automação. O Thunderbit é uma extensão do Chrome com IA, feita pra usuários de negócios que querem extrair dados estruturados de qualquer site, lidar com páginas dinâmicas e exportar direto pra ferramentas como Excel ou Google Sheets — sem precisar programar.
4. É legal fazer scraping de sites com cURL?
Em geral, extrair dado público é legal nos EUA, com base em decisões judiciais recentes, mas confira sempre os termos de serviço do site, o robots.txt e as leis aplicáveis. Evite raspar dado pessoal ou protegido sem permissão e respeite os limites de taxa e as diretrizes éticas (calawyers.org, polsinelli.com).
5. Quando devo trocar o cURL por uma ferramenta mais avançada, como o Thunderbit?
Se você precisa raspar páginas dinâmicas/pesadas em JavaScript, quer dados estruturados numa planilha ou prefere um fluxo sem código, o Thunderbit é a melhor pedida. Use o cURL pra tarefa rápida e técnica; use o Thunderbit pra extração de dados repetível e voltada pra negócios.
Pra mais dicas e tutoriais sobre web scraping, passe no Blog do Thunderbit ou veja o nosso canal no YouTube.
Experimente o Raspador Web IA do Thunderbit Get Started Free




