
Sejamos honestos: se você já tentou acessar dados de negócios, provavelmente já esbarrou no debate “web scraping vs. data mining”. Já vi equipes darem voltas e mais voltas — um lado quer extrair cada pedaço de informação da web, o outro quer analisá-la em busca de insights mais profundos, e às vezes os dois acabam olhando para uma planilha pensando: “Espera aí, afinal, o que estamos fazendo aqui?” Se isso soa familiar, você não está sozinho.
Como alguém que passou anos construindo SaaS e ferramentas de automação (e hoje é cofundador da ), vi essa confusão acontecer em todo tipo de lugar, de equipes comerciais a salas de diretoria. Então, vamos deixar o jargão de lado e ir direto ao ponto: qual é a diferença real entre web scraping e data mining, quem de fato usa cada um e — mais importante — como fazer os dois trabalharem juntos para gerar resultados para a sua equipe?
Web Scraping vs. Data Mining: definições rápidas para equipes ocupadas
Vamos começar pelo básico, sem precisar de dicionário técnico.
- Web Scraping: é o processo de coletar dados de sites — pense nele como uma forma automatizada de copiar e colar informações da web para uma planilha. Ferramentas de Web Scraper percorrem páginas, extraem informações específicas (como preços de produtos, nomes de empresas ou artigos) e organizam tudo em um formato estruturado, com linhas e colunas. Nesta etapa, não há análise — o foco é obter os dados brutos de que você precisa.
- Data Mining: aqui é onde a mágica acontece (ok, não é mágica, mas é valor real) depois que você já tem os dados. Data mining significa analisar conjuntos de dados — usando estatística, algoritmos ou IA — para descobrir tendências, padrões e insights. É como pegar aquela planilha enorme e entender o que ela quer dizer: segmentar clientes, prever vendas ou detectar fraudes.
A analogia que eu sempre uso:
Web scraping é ir ao mercado buscar ingredientes; data mining é cozinhar esses ingredientes até virarem uma refeição. Você precisa dos dois se quiser que o jantar seja mais do que apenas uma pilha de compras.
Quem usa Web Scraping vs. Data Mining — e por quê?
Aqui é que a coisa fica interessante. A diferença não é só “coletar vs. analisar” — é sobre quem faz o quê e com qual objetivo.
Quem usa Web Scraping?
Usuários típicos:
- Equipes de vendas (montando listas de leads, capturando contatos)
- Equipes de marketing (inteligência de mercado, monitoramento de concorrentes)
- Operações (acompanhamento de preços, insights da cadeia de suprimentos)
- Equipes de pesquisa (imóveis, finanças etc.)
Objetivo:
Conseguir dados novos e externos — rapidamente. Seja extraindo milhares de preços de produtos, fazendo scraping do LinkedIn para gerar leads ou acompanhando lançamentos de concorrentes, essas pessoas precisam de informações atualizadas para alimentar decisões do dia a dia (, ).
Quem usa Data Mining?
Usuários típicos:
- Analistas de dados e equipes de business intelligence (BI)
- Cientistas de dados
- Gerentes de produto e equipes de estratégia
Objetivo:
Encontrar significado nos dados. Essas pessoas pegam as informações brutas — sejam extraídas da web ou retiradas de sistemas internos — e buscam padrões, tendências e insights acionáveis. Elas se preocupam menos com como os dados foram coletados e mais com o que eles podem revelar ().
Tabela de cenários: quem faz o quê?
| Função | Exemplo de Web Scraping | Exemplo de Data Mining |
|---|---|---|
| Vendas | Extrair diretórios de empresas para gerar leads | Analisar quais leads convertem melhor |
| Marketing | Extrair lançamentos de produtos de concorrentes | Segmentar clientes por comportamento de compra |
| Operações | Extrair preços de fornecedores todos os dias | Prever demanda e otimizar estoque |
| BI/Data Science | (Geralmente não fazem scraping sozinhos) | Criar modelos preditivos e identificar tendências |
| Gestão de Produto | Extrair avaliações na app store para obter feedback | Identificar lacunas de funcionalidades e priorizar o roadmap |
Web Scraping: transformando sites em dados prontos para negócios
Vamos encarar a realidade: a internet é um verdadeiro tesouro de dados de negócios, mas a maior parte deles está presa em páginas web bagunçadas e não estruturadas. O web scraping é a chave que permite desbloquear esses dados e transformá-los em algo que sua equipe realmente possa usar.
Por que Web Scraping importa (especialmente para equipes não técnicas)
- Economiza tempo: chega de estagiários copiando e colando por dias. Um scraper pode coletar milhares de pontos de dados em minutos.
- Escala: quer monitorar 50 sites de concorrentes todos os dias? O scraping torna isso possível.
- Mantém você atualizado: receba atualizações em tempo real sobre preços, estoque ou notícias — sem esforço manual.
O panorama geral: o estima o mercado de web scraping em US$ 1,17 bi em 2026, chegando a US$ 2,23 bi até 2031. E, segundo uma pesquisa da BrowserCat de 2024 citada nesse relatório, 65% das empresas já usavam web scraping para alimentar projetos de IA e machine learning — exatamente a etapa do fluxo que leva a adoção para fora da TI e para dentro das equipes de vendas, marketing e operações.
Casos de uso práticos
-
Geração de leads: extraia diretórios públicos ou redes sociais para obter nomes, e-mails e telefones.
-
Monitoramento de preços: acompanhe preços da concorrência ou disponibilidade de produtos em tempo real. A adoção já virou padrão — a informa que 81% dos varejistas dos EUA agora usam automação de scraping de preços para reajuste dinâmico, ante 34% em 2020 (pesquisa originalmente conduzida pela Actowiz Solutions).
-
Pesquisa de mercado: agregue avaliações online, faça scraping de redes sociais para análise de sentimento ou monitore sites de notícias em busca de tendências.
-
Enriquecimento de dados: complemente seu CRM com informações novas de sites corporativos ou do LinkedIn.
-
Imóveis e finanças: extraia anúncios de imóveis, notícias financeiras ou dados alternativos para pesquisa de investimentos ().
E aqui está o ponto-chave: você não precisa mais ser programador. Uma fatia crescente das ferramentas mais novas de scraping — Octoparse, Browse AI, Bardeen, Thunderbit — já vem com configuração por arrastar e soltar ou clicar para apontar como padrão, e não como uma opção secundária para modo dev. Só isso já tirou o scraping da fila da engenharia e levou a prática para as mesas de vendas e operações.
Como a Thunderbit simplifica o Web Scraping para todos
Admito: quando começamos a construir a , nosso objetivo era simples — tornar o web scraping tão fácil quanto pedir a um estagiário para copiar e colar dados. A diferença é que esse “estagiário” é um agente de IA que nunca dorme, nunca reclama e nunca se distrai com vídeos de gatinhos.
Veja como a Thunderbit faz a ponte entre coleta de dados e análise de negócios:
- IA Sugere Campos: basta clicar em “IA Sugere Campos” e a IA da Thunderbit analisa a página, recomenda quais campos de dados extrair e propõe nomes de colunas. Chega de mexer em HTML ou seletores — é só escolher o que você precisa ().
- Scraping de subpáginas: precisa de mais detalhes em subpáginas (como informações de produtos ou descrições de vagas)? A Thunderbit pode clicar automaticamente, coletar as informações extras e adicioná-las ao conjunto de dados.
- Exportação instantânea de dados: exporte com um clique para Excel, Google Sheets, Airtable, Notion ou CSV/JSON. Sem taxas escondidas, sem burocracia — seus dados ficam prontos para uso na hora.
- Sem código, no clique: a Thunderbit funciona no navegador. Selecione o que quer e pronto. Mesmo que você nunca tenha feito scraping antes, estará operando em minutos.
- Resiliência com IA: os sites mudam o tempo todo, mas a IA da Thunderbit se adapta automaticamente a muitas alterações de layout. Menos manutenção, menos frustração.
- Scraping agendado e AI Autofill: programe coletas recorrentes ou deixe a IA preencher formulários e logins para você. A Thunderbit ainda lida com PDFs, imagens, e-mails e números de telefone em um único clique.
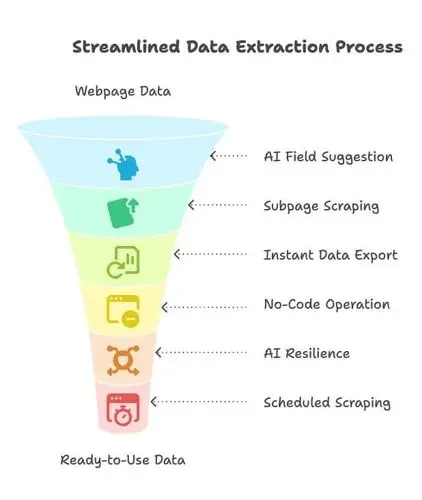
O resultado? A Thunderbit reduz a barreira de habilidades. Agora, operações de vendas, marketing ou até mesmo o seu CEO podem configurar uma coleta sem chamar a TI. Ela é a “camada intermediária” que conecta dados bagunçados da web às ferramentas que você realmente usa para análise.
Quer ver na prática? Confira nossa ou explore mais casos de uso no .
Data Mining: descobrindo insights a partir dos dados coletados
Certo, você já fez scraping de uma montanha de dados. E agora? É aqui que entra o data mining.
O que é Data Mining, em português claro?
Data mining é o processo de analisar grandes conjuntos de dados para encontrar padrões ocultos, correlações ou anomalias que possam gerar insights de negócio. É transformar números brutos em conhecimento acionável — como descobrir que clientes que compram o produto A também tendem a comprar o produto B, ou que certos comportamentos indicam alto risco de churn.
Objetivos comuns de negócio
- Descoberta de tendências e previsão: identificar tendências de vendas, sazonalidade ou mudanças de mercado — e prever o que vem a seguir.
- Segmentação de clientes: agrupar clientes por comportamento ou dados demográficos para marketing direcionado.
- Detecção de anomalias: encontrar valores fora do padrão que possam indicar fraude, risco ou novas oportunidades.
- Insights estratégicos: combinar múltiplos conjuntos de dados (internos + extraídos) para orientar grandes decisões — como entrar em um novo mercado ou ajustar preços.
Mas há um detalhe: o data mining só é tão bom quanto os dados que você alimenta nele. O velho ditado “lixo entra, lixo sai” é dolorosamente verdadeiro. De fato, analistas muitas vezes gastam até apenas limpando e preparando dados antes de conseguirem realmente analisá-los.
É por isso que o web scraping estruturado (como o que a Thunderbit gera) é tão valioso — ele entrega um conjunto de dados limpo e pronto para análise, para que seus analistas possam ir direto ao que importa.
Web Scraping vs. Data Mining: comparação lado a lado
Vamos colocar os dois frente a frente para que você veja exatamente onde diferem — e onde se sobrepõem.
| Aspecto | Web Scraping | Data Mining |
|---|---|---|
| Objetivo principal | Coletar dados brutos de sites (extração de dados) | Analisar conjuntos de dados para descobrir padrões e insights (análise de dados) |
| Usuários típicos | Vendas, marketing, operações, pesquisa (muitas vezes não técnicos, especialistas de domínio) | Analistas de dados, equipes de BI, cientistas de dados, gestores de estratégia (funções analíticas/técnicas) |
| Fontes de dados | Páginas web, fontes online, diretórios públicos, APIs | Conjuntos de dados estruturados: dados extraídos, bancos internos, CSVs, data warehouses |
| Processo e ferramentas | Rastreamento, extração (ferramentas no-code como Thunderbit, extensões de navegador) | Análise de dados (ferramentas de BI, Python/R, SQL, plataformas de machine learning) |
| Resultado | Conjunto de dados estruturado (CSV, planilha, tabela de banco de dados) | Insights, relatórios, dashboards, modelos preditivos |
| Exemplos de uso | Compilar preços de concorrentes, fazer scraping de menções sociais, coletar anúncios | Segmentar clientes, prever churn, pontuar leads |
| Principais desafios | Mudanças no site, defesas anti-scraping, qualidade dos dados, questões legais/éticas | Dados sujos/incompletos, escolha dos modelos certos, privacidade, interpretação dos resultados |
Principal conclusão:
Web scraping é o “combustível” (dados), e data mining é o “motor” (insight). Você precisa dos dois para sair do lugar.
Como Web Scraping e Data Mining funcionam juntos nos negócios
É aqui que a verdadeira mágica acontece: web scraping e data mining não são concorrentes — são parceiros. Pense neles como o upstream e o downstream do seu fluxo de dados.
Cenário 1: inteligência de mercado
- Etapa 1: extraia anúncios de produtos, preços e avaliações de concorrentes em vários sites.
- Etapa 2: faça data mining dos dados para identificar tendências — encontrar lacunas no mercado, descobrir reclamações recorrentes de clientes ou acompanhar mudanças de preço ao longo do tempo.
- Resultado: você obtém insights acionáveis para orientar a estratégia de produto ou a precificação.
Cenário 2: pontuação de leads de vendas
- Etapa 1: extraia o LinkedIn ou diretórios de empresas para enriquecer sua base de leads com porte da empresa, setor e notícias recentes.
- Etapa 2: analise quais atributos se correlacionam com taxas de conversão mais altas e, então, priorize os leads de acordo com isso.
- Resultado: sua equipe comercial foca nos prospects com melhor fit, e não apenas na maior lista.
Cenário 3: otimização de preços
- Etapa 1: extraia preços e estoque da concorrência em tempo real.
- Etapa 2: alimente esses dados nos seus algoritmos de precificação para ajustar seus próprios preços dinamicamente.
- Resultado: você continua competitivo e maximiza a receita.
O risco de tratar essas atividades como isoladas?
Se você só faz scraping e nunca analisa, afoga-se em dados, mas morre de fome por insights. Se só analisa dados internos, perde o contexto mais amplo do mercado. As melhores equipes usam os dois — scraping para montar um conjunto de dados completo, mining para gerar insights significativos ().
Superando desafios comuns em Web Scraping e Data Mining
Vamos falar a verdade: tanto web scraping quanto data mining trazem suas próprias dores de cabeça. Veja como lidar com as principais — e como a Thunderbit ajuda:
1. Qualidade e limpeza de dados
- Problema: os dados coletados podem vir bagunçados — campos ausentes, formatos inconsistentes, duplicatas.
- Solução: use ferramentas que permitam limpeza durante a extração. A Thunderbit consegue formatar e categorizar dados em tempo real usando IA, deixando a saída pronta para análise (). Sempre faça uma verificação manual em uma amostra dos dados antes de mergulhar na análise.
2. Mudanças no site e medidas anti-scraping
- Problema: sites mudam o layout, adicionam CAPTCHAs ou bloqueiam bots.
- Solução: use scrapers com IA, como a Thunderbit, que se adaptam automaticamente às mudanças de layout. Respeite o
robots.txt, evite sobrecarregar sites e, se necessário, considere usar proxies ().
3. Questões legais e éticas
- Problema: extrair dados públicos é geralmente legal, mas leis de privacidade e termos de serviço importam.
- Solução: revise sempre os termos do site, concentre-se em dados públicos, anonimize quando possível e cumpra o GDPR/CCPA. Seja um “cidadão ético de dados” — sua reputação vale mais do que qualquer conjunto de dados ().
4. De dados a insights acionáveis
- Problema: as equipes coletam dados, mas têm dificuldade para transformá-los em decisões.
- Solução: comece com perguntas de negócio claras, use visualização e envolva especialistas de domínio na interpretação dos resultados. Integre os insights aos fluxos de trabalho (por exemplo, sinalizar clientes em risco no CRM).
5. Ferramentas e lacuna de habilidades
- Problema: nem toda equipe tem programadores ou cientistas de dados.
- Solução: aproveite ferramentas amigáveis e no-code, como a Thunderbit, para scraping, e plataformas modernas de BI para mining. Invista em treinamento básico de alfabetização em dados — às vezes uma simples tabela dinâmica é tudo de que você precisa.
Escolhendo a abordagem certa: Web Scraping, Data Mining ou ambos?
Então, como decidir o que você precisa? Aqui vai um guia rápido:
- Você já tem os dados de que precisa?
- Não: comece com web scraping para coletá-los.
- Sim: vá para data mining para extrair insights.
- Suas perguntas são sobre o mundo externo ou sobre padrões internos?
- Externas (concorrentes, mercado, leads): web scraping.
- Internas (comportamento de clientes, tendências de vendas): data mining.
- Você precisa dos dois?
- A maioria dos projetos do mundo real precisa! Faça scraping de dados externos e depois aplique mining neles (além dos dados internos) para ter o panorama completo.
- Capacidades da equipe:
- Sem habilidades de programação? Use ferramentas de scraping no-code como a Thunderbit.
- Sem cientistas de dados? Use ferramentas de BI amigáveis ou comece com análises básicas.
- Sensibilidade ao tempo:
- Precisa de tempo real? Configure scraping e análise contínuos.
- Projeto pontual? Faça uma coleta única e depois analise.
Checklist:
- “Tenho todos os dados de que preciso internamente?” Se não, faça scraping.
- “Entendo os dados que tenho?” Se não, faça mining.
- “O problema é grande o suficiente para combinar abordagens?” Se sim, faça os dois.
- “Minha equipe tem as habilidades necessárias?” Se não, use ferramentas no-code ou peça ajuda.
E lembre-se: você não precisa fazer tudo de uma vez. Comece pequeno, rode um piloto e escale à medida que vir resultados.
Principais conclusões: fazendo os dados trabalharem para sua equipe
Vamos recapitular o essencial:
- Web scraping e data mining são duas etapas da mesma jornada. O scraping coleta os dados (especialmente de fontes externas), e o mining os analisa para gerar insights.
- Funções diferentes, objetivos diferentes: vendas, marketing e operações usam scraping para obter dados; analistas e equipes de BI fazem mining para extrair significado.
- Eles se complementam, não competem: os melhores resultados vêm da combinação dos dois — scraping para um conjunto de dados rico, mining para insights acionáveis.
- Ferramentas no-code e IA reduziram a barreira: Thunderbit e ferramentas semelhantes tornam o scraping acessível a todos. Plataformas modernas de BI também facilitam o mining.
- Qualidade e ética dos dados importam: limpe seus dados, respeite a privacidade e aja sempre com ética.
- Deixe o caso de uso guiar a abordagem: comece pela sua pergunta de negócio e, então, decida de quais dados você precisa e como analisá-los.
- Comece pequeno, depois escale: use planos gratuitos, projetos-piloto e vitórias rápidas para ganhar tração.
No fim das contas, o objetivo é capacitar sua equipe a tomar decisões melhores com dados. Talvez isso signifique sua equipe de vendas gastando menos tempo com pesquisa manual (graças ao scraping) ou suas reuniões de estratégia sendo guiadas por insights reais (graças ao mining). De qualquer forma, combinar as duas abordagens é como as equipes modernas ganham vantagem competitiva.
Então, junte esses ingredientes de dados da web, cozinhe alguns insights e sirva à sua equipe a inteligência acionável de que ela precisa. E, se precisar de ajuda na cozinha, está aqui para deixar o preparo muito mais fácil.
Curioso para testar? Baixe a e veja como o web scraping pode ser simples. Para mais dicas e histórias da linha de frente dos dados, confira o .
FAQs
1. Qual é a principal diferença entre web scraping e data mining?
Web scraping é o processo de coletar dados brutos de sites, enquanto data mining envolve analisar esses dados para descobrir padrões, insights ou tendências. Pense no scraping como juntar ingredientes e no mining como cozinhar a refeição.
2. Quem normalmente usa web scraping versus data mining?
O web scraping é usado principalmente por equipes de vendas, marketing, operações e pesquisa que precisam de dados externos novos com rapidez. Já o data mining é usado por analistas, cientistas de dados e equipes de produto que buscam derivar insights estratégicos a partir dos dados.
3. Preciso saber programar para fazer web scraping?
Não mais. Ferramentas como a oferecem interfaces sem código, com IA, que permitem a qualquer pessoa — independentemente da formação técnica — fazer scraping com ações de clicar e apontar, além de exportação instantânea.
4. Como web scraping e data mining funcionam juntos?
O web scraping fornece os dados brutos e estruturados de que o data mining depende. Juntos, eles criam um fluxo: coletar dados externos com scraping e depois analisá-los com mining para orientar decisões de negócio.
5. Quais são alguns casos de uso reais de cada um?
O web scraping é usado em tarefas como geração de leads, monitoramento de preços e acompanhamento de concorrentes. O data mining apoia segmentação de clientes, previsão de tendências, detecção de fraudes e planejamento estratégico com base nos dados coletados.