A raspagem web é ilegal? Essa é a pergunta de um milhão de dólares que ouço toda semana de fundadores, profissionais de marketing e entusiastas de dados.
Com — a primeira vez que o tráfego automatizado superou a atividade humana — e uma fatia enorme disso dedicada à raspagem web para inteligência de mercado, vendas e treino de IA, não é de admirar que toda a gente esteja a tentar perceber onde ficam os limites legais.
Num dia, vê uma manchete sobre uma decisão judicial a dizer que raspar dados públicos é permitido. No dia seguinte, os reguladores alertam para a recolha "ilícita" de dados em redes sociais. É confuso até para quem, como eu, passa os dias a construir ferramentas de raspagem web com IA na .
Então, a raspagem web é ilegal? A resposta não é um simples sim ou não. Depende do que está a raspar, de onde está a raspar, de como usa os dados e do que a lei diz no seu país.
Nesta análise aprofundada, vou explicar o enquadramento jurídico, desmontar alguns mitos comuns e partilhar dicas práticas — além de algumas histórias de bastidores — para manter a conformidade, seja você um fundador em nome próprio ou uma equipa de dados de uma empresa da Fortune 500.
Raspagem Web e a Lei: Existe uma Linha Clara?
Se está à espera de uma resposta em uma frase, poupo-lhe tempo: a lei ainda não traçou uma linha clara e objetiva sobre raspagem web.
Em vez disso, há um mosaico de regras sobrepostas — propriedade dos dados, privacidade, propriedade intelectual, leis antifurto/hacking e os famosos Termos de Serviço (ToS). Cada uma pode entrar em jogo, e a resposta depende muitas vezes do seu caso específico ().
Vamos dividir isto em três grandes blocos jurídicos:
- Propriedade dos dados: Em geral, factos e informações públicas (como preços ou números de telefone) não estão protegidos por direitos de autor. Mas conteúdo criativo (artigos, imagens) e bases de dados proprietárias podem estar — especialmente na UE, onde existem os "direitos sobre bases de dados" ().
- Privacidade: Leis modernas de privacidade (pense na GDPR na Europa, na PIPL na China) tratam os dados pessoais como um ativo regulado — mesmo quando foram publicados abertamente. Raspar nomes, e-mails ou perfis sociais sem base legal pode dar problemas ().
- Contratos (Termos de Serviço): Muitos sites proíbem explicitamente a raspagem nos ToS. Embora os ToS não sejam leis, os tribunais podem tratá-los como contratos vinculativos. Violar estas regras pode resultar em processos e, em alguns casos, até acionar estatutos antifurto/hacking se contornar bloqueios técnicos ().
Então, a raspagem web é ilegal? Às vezes sim, às vezes não, e muitas vezes "depende". O diabo está nos detalhes.
Comparando Perspectivas Jurídicas: EUA, UE, Reino Unido, China
Aqui fica uma tabela rápida para mostrar como regiões importantes encaram a raspagem web:
| Região | Raspagem de Dados Públicos | Raspagem de Dados Pessoais/Privados | Aplicação e Pontos Notáveis |
|---|---|---|---|
| EUA | Em geral, permitida para dados públicos (veja hiQ v. LinkedIn). Violar ToS pode gerar processos civis. | Restrita/ilegal se violar logins ou fizer uso indevido de dados pessoais. Leis estaduais (como a CCPA) podem aplicar-se. | Cartas de cessação e desistência, bloqueio de IP, processos. A CFAA aplica-se se contornar barreiras técnicas. |
| UE | Permitida com condições para dados públicos e não pessoais. Os direitos sobre bases de dados podem aplicar-se. A Lei de IA da UE (2026) acrescenta exigências de transparência para dados de treino de IA. | Fortemente regulada pela GDPR — até dados pessoais públicos precisam de base legal. | As autoridades de proteção de dados podem multar por violações de privacidade. Direitos de autor/direitos sobre bases de dados também são aplicados. A Lei de IA da UE proíbe a raspagem de imagens faciais para IA. |
| Reino Unido | Semelhante à UE. Dados públicos e não pessoais podem ser raspados, mas é preciso respeitar os direitos sobre os dados e os contratos. | Rigoroso com dados pessoais — a UK GDPR aplica-se. O Computer Misuse Act criminaliza o acesso não autorizado. | A ICO pode penalizar violações de proteção de dados. Os tribunais podem aplicar os ToS. |
| China | Fortemente controlada. Dados públicos e não pessoais podem ser raspados para uso interno, mas o ambiente é cauteloso. | Altamente restrito — a PIPL exige consentimento para dados pessoais. Aplicam-se leis contra concorrência desleal. | Casos criminais por raspagem em larga escala. Os tribunais usam a lei de concorrência desleal para impedir raspagem não autorizada. |
(, )
A Raspagem Web é Ilegal? Principais Fatores Jurídicos a Considerar
Então, o que é que realmente determina se o seu projeto de raspagem é legal ou arriscado? Aqui estão os principais fatores:
- Dados públicos vs. privados: Raspar dados que qualquer pessoa pode ver na web aberta é, em geral, mais seguro. Está a raspar algo atrás de login, paywall ou barreira técnica? Isso provavelmente é ilegal ().
- Natureza dos dados: Dados pessoais (nomes, e-mails, perfis) acionam leis de privacidade. Conteúdo protegido por direitos de autor (artigos, imagens) não pode ser copiado em massa. Factos puros (preços, clima) normalmente estão liberados ().
- Uso pretendido: Análise interna ou investigação costuma ser vista com mais tolerância do que republicar ou vender dados raspados. Usar dados raspados para competir diretamente com a fonte? É uma ação judicial à espera de acontecer ().
- Conformidade com as regras do site: Verifique sempre o robots.txt e os ToS. O robots.txt não tem força legal, mas é boa prática respeitá-lo. Violar os ToS pode significar processos civis ou coisa pior ().
- Medidas técnicas: Raspagem a velocidades semelhantes às humanas e sem contornar medidas de segurança é essencial. Sobrecarregar um servidor ou driblar CAPTCHAs pode cruzar a linha para hacking ().
O que Mudou entre 2024 e 2026: Principais Casos e Regulamentações
O cenário jurídico da raspagem web mudou bastante desde 2023. Veja os acontecimentos que todo scraper precisa conhecer:
Principais Decisões Judiciais
-
Meta v. Bright Data (2024): Um tribunal federal dos EUA . O juiz concluiu que "um visitante não é considerado um 'usuário' a menos que tenha uma conta". A Meta retirou as restantes alegações logo depois. Esta é uma vitória histórica para a raspagem de dados públicos.
-
X Corp v. Bright Data (2024): O Twitter (agora X) perdeu um processo semelhante, reforçando o mesmo princípio: raspar dados publicamente acessíveis sem fazer login não viola os ToS, porque o scraper nunca concordou com esses termos.
-
Reddit v. Perplexity AI (outubro de 2025): O Reddit , invocando o DMCA e alegando burla a sistemas anti-bot. Isto sinaliza uma nova estratégia jurídica: as plataformas estão a recorrer a alegações de direitos de autor e de anti-circumvenção em vez da CFAA.
-
NYT v. OpenAI (março de 2025): Um juiz federal , rejeitando a moção da OpenAI para arquivamento. Isto pode criar um precedente importante sobre se raspar conteúdo para treinar modelos de IA conta como "uso justo".
-
Acordo da Anthropic (setembro de 2025): A Anthropic concordou em pagar US$ 1,5 bilhão para encerrar uma ação coletiva nos EUA sobre o uso de textos protegidos por direitos de autor para treinar o seu modelo de IA — um sinal claro de que os custos de raspar para IA são bem reais.
A Grande Tendência: Da CFAA para Contratos e Direitos de Autor
O padrão é claro: a CFAA (Computer Fraud and Abuse Act) está a perder força como arma contra raspadores de dados públicos. Empresas que tentaram usar a CFAA contra a raspagem de dados públicos — Meta, X, LinkedIn — falharam em grande parte. Em vez disso, o campo jurídico está a migrar para:
- Direito contratual (violações de ToS — mas os tribunais estão a dizer que não utilizadores não ficam vinculados aos ToS)
- Ações de direitos de autor (especialmente para dados de treino de IA)
- Leis de anti-circumvenção (DMCA Secção 1201)
Para quem raspa dados, isto significa que o risco jurídico não desapareceu — apenas mudou de lugar.
Mudanças Regulatórias
- Atualizações da CCPA em 2026: As regras revistas da CCPA da Califórnia , acrescentando novas normas para tecnologia de tomada de decisão automatizada (ADMT), avaliações de risco e obrigações de data brokers.
- Novas leis estaduais de privacidade nos EUA: Indiana, Kentucky e Rhode Island aprovaram leis abrangentes de privacidade com entrada em vigor em 2026.
- Lei de IA da UE: A aplicação integral começa em — exigindo que os desenvolvedores de IA divulguem as fontes dos dados de treino, respeitem exclusões de direitos de autor e proíbam a raspagem de imagens faciais para sistemas de IA.
- AI Accountability for Publishers Act (fevereiro de 2026): Proposta de lei nos EUA que exigiria que empresas de IA obtivessem permissão e pagassem aos publishers antes de raspar o seu conteúdo.
Políticas de Raspagem das Principais Plataformas: O que Você Precisa Saber
Nem todo site trata a raspagem da mesma forma. Aqui está uma análise plataforma por plataforma do que os maiores sites permitem, bloqueiam e o que os tribunais disseram:
| Plataforma | ToS sobre Raspagem | Defesas Técnicas | Aplicação Jurídica | O que é Praticamente Seguro |
|---|---|---|---|---|
| Google (Busca e Maps) | Proíbe acesso automatizado nos ToS. A plataforma Maps tem uma cláusula explícita de "No Scraping". | Desafios SearchGuard JS, CAPTCHAs, limitação de taxa. robots.txt atualizado em 2025 para bloquear crawlers de IA. | Processou scrapers em dezembro de 2025 usando o DMCA. Bloqueia ativamente crawlers de IA (Anthropic, Meta, OpenAI). | Raspar dados públicos de empresas no Google Maps é juridicamente defensável (precedente hiQ), mas espere bloqueios técnicos. Use APIs oficiais sempre que possível. |
| Amazon | Proíbe explicitamente toda raspagem nas Condições de Uso ("nenhum robô, spider, scraper ou outro meio automatizado"). | Detecção agressiva de bots, CAPTCHA, bloqueio de IP. robots.txt bloqueia todos os bots, exceto Googlebot/Bingbot. Bloqueia explicitamente crawlers de IA desde 2025. | Processou a Perplexity AI em novembro de 2025. Envia cartas de cessação e desistência com frequência. Atualizou o BSA em março de 2026 com regras para agentes de IA. | Dados públicos de produtos (preços, listagens) são factos e podem ser raspados sob a lei dos EUA, mas a Amazon reage com força. Limite a taxa de requisições e evite dados pessoais. |
| Proíbe raspagem nos ToS; exige concordância do utilizador para aceder aos serviços. | Barreiras de login para a maioria dos dados de perfil, deteção anti-bot, limitação de taxa. | O caso hiQ confirmou que raspar perfis públicos não viola a CFAA, mas o LinkedIn venceu em alegações contratuais/concorrência desleal quando foram usadas contas falsas. | Perfis públicos (visíveis sem login) são juridicamente defensáveis para raspagem. Nunca crie contas falsas nem raspe dados após login. | |
| Meta (Facebook e Instagram) | Os ToS proíbem raspagem; regras separadas para dados com e sem login. | Barreiras de login para a maior parte do conteúdo, deteção avançada de bots. | Perdeu para a Bright Data em 2024 — o tribunal decidiu que os ToS não se aplicam a scrapers sem login. Abandonou as restantes alegações. | Dados públicos (páginas de negócios, publicações públicas) visíveis sem login estão em terreno mais seguro. Nunca raspe perfis privados ou dados atrás de login. |
| X (Twitter) | Atualizou os ToS em 2023 para proibir toda raspagem e crawling sem consentimento por escrito. Eliminou a antiga exceção do robots.txt. | robots.txt bloqueia todos os crawlers (Disallow: /). Desafios Cloudflare Turnstile. Limites rígidos de taxa (300 req/h). Pontuação de reputação de IP. | Perdeu para a Bright Data em dados públicos, mas limita agressivamente o acesso técnico. | Tweets e perfis públicos são juridicamente defensáveis, mas as barreiras técnicas do X estão entre as mais difíceis em 2026. Espere bloqueios sem uma infraestrutura premium de proxy. |
Em resumo: os tribunais têm decidido de forma consistente que raspar dados publicamente visíveis sem fazer login não viola a CFAA. Mas as plataformas ainda podem tentar enquadrar o caso por direito contratual, direitos de autor ou anti-circumvenção — e vão dificultar a sua vida com barreiras técnicas. Raspe com responsabilidade.
Dados de Treino de IA e Raspagem Web: A Nova Fronteira Jurídica
Se tem acompanhado as notícias em 2026, já sabe que raspar dados para treinar modelos de IA se tornou o campo de batalha jurídico mais quente. Veja o que está a acontecer:
- Os processos de direitos de autor estão a acumular-se. O New York Times, autores e publishers processaram a OpenAI, a Anthropic e outras empresas, alegando que a raspagem em massa de conteúdo protegido por direitos de autor para treinar LLMs não é "uso justo". A Anthropic fechou um grande acordo coletivo por US$ 1,5 bilhão em 2025 — um sinal claro de que os custos de raspar para IA são reais.
- A defesa de "uso justo" é instável. Os tribunais dos EUA ainda não emitiram uma decisão definitiva sobre se treinar IA com dados raspados é uso justo. As decisões iniciais sugerem que isso depende muito de como os dados foram obtidos e do que é feito com a saída da IA.
- Nova legislação está a caminho. O (apresentado em fevereiro de 2026) pretende exigir que empresas de IA obtenham permissão e paguem aos publishers antes de raspar o seu conteúdo.
- A Lei de IA da UE (aplicação integral em ) exige que os desenvolvedores de IA divulguem as fontes dos dados de treino, respeitem exclusões de direitos de autor legíveis por máquina (na exceção de TDM da Diretiva de Direitos de Autor) e identifiquem conteúdo gerado por IA. Também proíbe sistemas de IA que raspem imagens faciais da internet.
- Crawlers de IA/LLM estão a explodir. Os crawlers de IA quadruplicaram a sua participação no tráfego da web, de 2,6% para 10,1%, em apenas oito meses. O GPTBot da OpenAI sozinho cresceu 305%. Em resposta, grandes sites (Amazon, Reddit, NYT) estão a atualizar o robots.txt para bloquear explicitamente crawlers de IA.
O que isto significa para você: se está a raspar dados para fins tradicionais de negócio (geração de leads, monitorização de preços, pesquisa de mercado), estas regras específicas para IA podem não se aplicar diretamente. Mas se estiver a alimentar modelos de IA com dados raspados, redobre a cautela — e procure orientação jurídica.
Leis de Raspagem Web pelo Mundo: Uma Comparação Rápida
Vamos ampliar a perspetiva e ver como as regras se comportam globalmente:
- Estados Unidos: Não há proibição geral. A raspagem de sites públicos é, em geral, legal (), e as decisões de 2024 sobre Meta e X Corp reforçaram ainda mais o caso para a raspagem de dados públicos. Mas raspar atrás de logins ou barreiras técnicas ainda pode acionar a CFAA. A tendência agora é as empresas recorrerem a direito contratual e direitos de autor. As leis de privacidade estão a expandir-se rapidamente: a CCPA recebeu grandes atualizações com entrada em vigor em 1 de janeiro de 2026, incluindo novas regras para tomada de decisão automatizada e obrigações de data brokers. Indiana, Kentucky e Rhode Island também aprovaram leis abrangentes de privacidade em 2026.
- União Europeia: Leis de privacidade rígidas. A GDPR aplica-se até a dados pessoais públicos. Os direitos sobre bases de dados podem bloquear a raspagem em grande escala de dados estruturados (). NOVO: a entra em aplicação integral em 2 de agosto de 2026, exigindo que os desenvolvedores de IA divulguem as fontes dos dados de treino e respeitem exclusões de direitos de autor. A lei proíbe a raspagem de imagens faciais da internet para sistemas de IA.
- Reino Unido: Reflete as regras da UE após o Brexit. Dados públicos podem ser raspados, mas a raspagem de informações pessoais é fortemente regulada. O Computer Misuse Act pode criminalizar o acesso não autorizado.
- China: Muito restritiva. A PIPL e a Data Security Law exigem consentimento para dados pessoais. Os tribunais usam a lei de concorrência desleal para bloquear raspagem que prejudique empresas ().
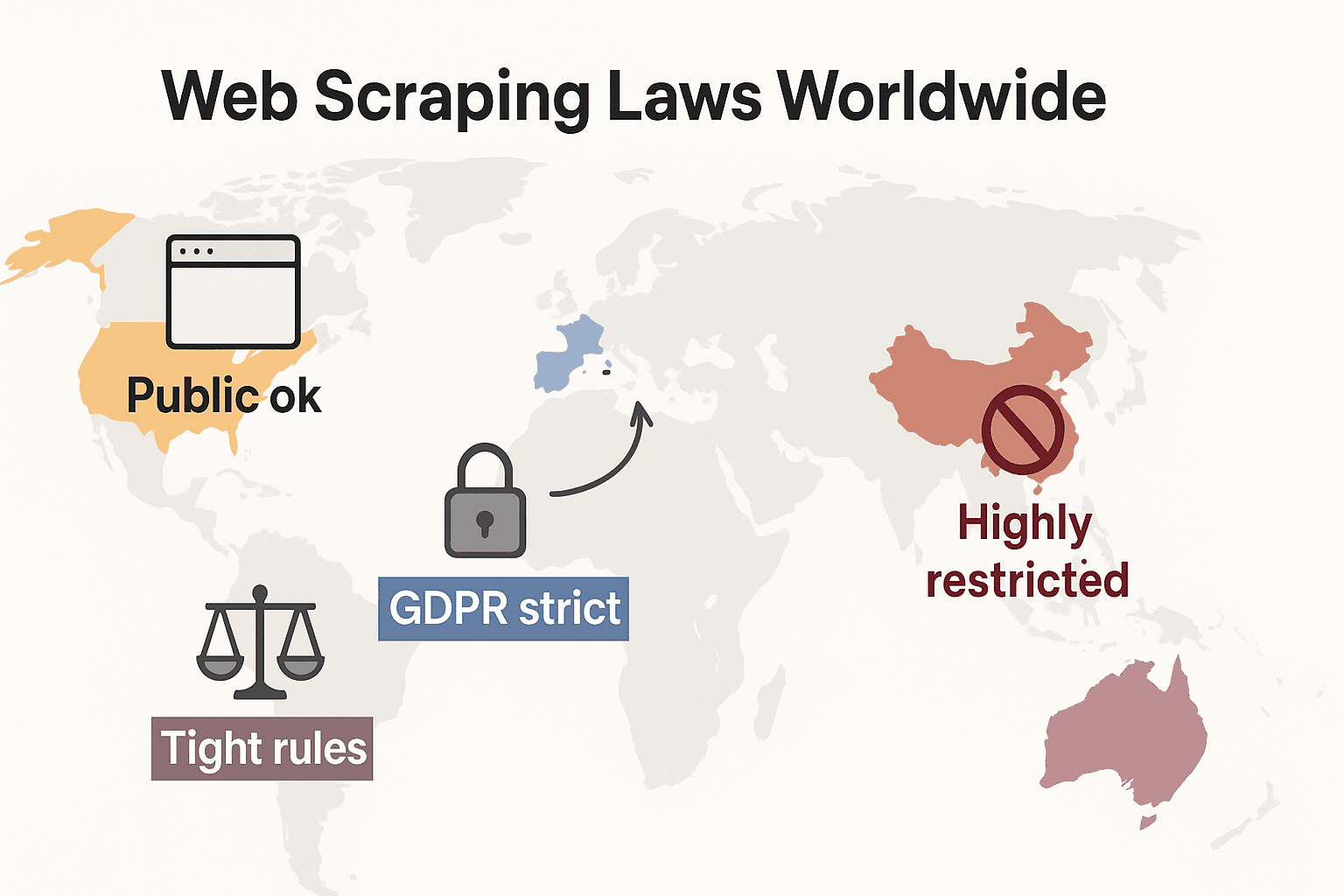
Em resumo: raspar dados públicos e não pessoais para uso interno é, em geral, o caminho mais seguro. Qualquer outra coisa? Verifique as leis locais e avance com cautela.
Mitos Comuns Sobre a Legalidade da Raspagem Web
Vamos derrubar alguns mitos que ouço o tempo todo:
- Mito 1: "Raspagem web é ilegal, ponto final."
Falso. Não existe uma lei que proíba toda a raspagem web. O que importa é como e o que raspa (). - Mito 2: "Se os dados são públicos, posso fazer o que quiser com eles."
Não exatamente. Os dados públicos ainda podem estar protegidos por leis de privacidade ou direitos de autor, e os ToS podem restringir certos usos (). - Mito 3: "Raspagem web é a mesma coisa que hacking."
Não. Raspar páginas públicas da web não é hacking. Contornar logins ou barreiras técnicas é outra história (). - Mito 4: "Se eu não for apanhado, tudo bem."
Pensamento arriscado. Muitos sites usam tecnologia anti-bot e vão reparar. Silêncio não é consentimento. - Mito 5: "Dar crédito ou usar os dados internamente torna tudo permitido."
Atribuição não se sobrepõe a direitos de autor ou privacidade. Uso interno é mais seguro, mas não é passe livre. - Mito 6: "Toda a raspagem web viola a privacidade."
Nem toda a raspagem envolve dados pessoais. Mas raspar grandes volumes de informações pessoais sem salvaguardas quase sempre é ilegal (). - Mito 7: "Se os ToS de um site proíbem raspagem, então raspá-lo é sempre ilegal."
Não necessariamente. Em 2024, tribunais decidiram em Meta v. Bright Data e X Corp v. Bright Data que os ToS não podem vincular utilizadores que nunca concordaram com eles — ou seja, se estiver a raspar sem fazer login ou criar uma conta, os ToS do site podem não se aplicar a si. Ainda é uma área em evolução, mas é uma mudança importante.
Como Raspar Dados Legalmente: Melhores Práticas de Conformidade
Aqui está a minha lista de verificação preferida para raspagem web legal e ética:
- Leia e respeite os Termos de Serviço do site. Se disserem "não faça scraping", considere parar ou pedir permissão ().
- Fique nos dados públicos. Se precisar de palavra-passe, o conteúdo é restrito — não raspe ().
- Verifique o robots.txt e faça crawling com educação. Não é vinculativo legalmente, mas é boa etiqueta. Não sobrecarregue servidores — distribua as suas requisições ().
- Evite dados pessoais, a menos que tenha base legal. Se precisar de os recolher, cumpra a GDPR/CCPA e minimize o que recolhe.
- Não republicar conteúdo raspado em massa. Acrescente valor ou análise, ou obtenha permissão ().
- Não alimente modelos de IA com conteúdo raspado sem verificar os direitos de autor. O cenário jurídico está a mudar rapidamente — procure orientação se esse for o seu caso de uso.
- Use APIs oficiais ou exportações de dados quando disponíveis. Foram feitas para isso e normalmente são mais seguras ().
- Seja transparente e responsável. Se recolher dados pessoais, informe as pessoas e mantenha um registo das suas atividades.
- Minimize e proteja os seus dados. Recolha apenas o necessário, mantenha a precisão e armazene com segurança.
- Mantenha-se informado e procure orientação jurídica em casos limítrofes. Leis e decisões judiciais estão a mudar rapidamente — especialmente a Lei de IA da UE e as leis estaduais de privacidade dos EUA. Na dúvida, fale com um profissional.
Usando Ferramentas de Raspagem Web Legalmente: O que as Empresas Precisam Saber
Ferramentas de raspagem web como a tornam a recolha de dados acessível até para quem não programa, mas ainda é preciso usá-las com responsabilidade:
- Escolha ferramentas focadas em conformidade. A Thunderbit, por exemplo, raspa apenas o que consegue ver no navegador — sem truques de API nem acesso não autorizado ().
- Fique em casos de uso legítimos. Análises internas, pesquisa de mercado e monitorização competitiva de preços são, em geral, seguros. Republicar ou vender dados raspados? Muito mais arriscado.
- Configure as ferramentas para conformidade. Defina atrasos de crawl, obedeça ao robots.txt e use modelos que coletem apenas o necessário.
- Mantenha o uso interno. Usar os dados raspados internamente é mais seguro do que republicá-los.
- Eduque a sua equipa. Garanta que todos entendem as regras e as melhores práticas.
- Aproveite recursos de conformidade já integrados. A Thunderbit alerta os utilizadores sobre sites arriscados, raspa a velocidades semelhantes às humanas e não armazena os seus dados em servidores próprios.
- Não force a barra. Se uma ferramenta não conseguir raspar um site, não tente contornar isso. Nem todo o dado pode ser obtido sem risco.
A Abordagem da Thunderbit: Habilitando Raspagem Web com IA em Conformidade
Na , passamos bastante tempo a pensar em conformidade. Veja como o nosso Raspador Web IA ajuda os utilizadores a ficarem do lado certo da lei:
- Raspa apenas o que consegue ver. A Thunderbit funciona na sua sessão do navegador, por isso não acede a dados que você não conseguiria copiar manualmente.
- Orienta os utilizadores com avisos. Se tentar raspar um site com políticas rígidas contra scraping, a Thunderbit avisa-o.
- Velocidades de raspagem semelhantes às humanas. Seja localmente ou na nuvem, a Thunderbit evita sobrecarregar servidores.
- Seleção de dados personalizável. A nossa IA sugere colunas relevantes, ajudando-o a recolher só o necessário.
- Tratamento de subpáginas e paginação. A Thunderbit navega pelos sites como um utilizador real, respeitando a sua estrutura.
- Privacidade e segurança. Os seus dados ficam consigo — a Thunderbit não os armazena nem reutiliza.
- Exportações amigas da conformidade. Exporte diretamente para Google Sheets, Airtable, Notion ou CSV para uso interno e seguro.
- Agendamento e automação. Configure raspagens recorrentes em intervalos responsáveis.
- Suporte multilíngue. A interface da Thunderbit oferece suporte a 34 idiomas, tornando a conformidade acessível globalmente.
- Atualizações regulares de modelos. Os nossos modelos instantâneos para sites populares são mantidos atualizados com mudanças legais e técnicas.
Ao incorporar a conformidade no produto, a Thunderbit ajuda as equipas a recolher os dados de que precisam — sem dores de cabeça jurídicas.
Mantendo-se à Frente: Adaptando-se às Mudanças Legais e Técnicas na Raspagem Web
Raspagem web não é algo para configurar e esquecer. As leis e as estruturas dos sites estão sempre a evoluir. Veja como manter-se à frente:
- Acompanhe os desenvolvimentos jurídicos. O ritmo de mudança acelerou em 2024–2026 — siga notícias de direito digital, atualizações de reguladores e blogs do setor (como o ). Fique atento à aplicação da Lei de IA da UE (agosto de 2026), às novas leis estaduais de privacidade dos EUA e aos processos em curso sobre direitos de autor em IA.
- Adapte-se às mudanças técnicas. Os sites atualizam as suas estruturas e defesas anti-bot o tempo todo. Grandes plataformas (Amazon, X, Google) reforçaram bastante as suas defesas em 2025–2026. A IA e os modelos da Thunderbit foram feitos para se adaptar automaticamente.
- Adote APIs oficiais quando disponíveis. Se um site passar para um modelo de API paga, considere a mudança pela fiabilidade e pela conformidade.
- Audite a sua raspagem regularmente. Documente as suas fontes, verifique mudanças nos ToS ou nas políticas e ajuste a sua estratégia conforme necessário.
- Aproveite as atualizações dos modelos da Thunderbit. A nossa equipa mantém os modelos atualizados, por isso não precisa de se preocupar com mudanças que partem fluxos ou novos requisitos de conformidade.
- Mantenha-se flexível. Se uma fonte de dados ficar demasiado arriscada, mude para outra ou procure uma parceria.
Com as ferramentas e a mentalidade certas, pode manter o seu pipeline de dados a funcionar — sem pisar minas jurídicas.
Conclusão: Navegando pelo Cenário Jurídico da Raspagem Web
Raspagem web não é inerentemente ilegal — é uma ferramenta poderosa para negócios, pesquisa e inovação. Mas, como qualquer ferramenta, traz regras. O ponto principal é perceber o que está a raspar, como está a raspar e o que vai fazer com os dados. Respeite as leis locais, siga as políticas dos sites e use ferramentas focadas em conformidade como a para manter as suas operações dentro das regras.
As decisões judiciais de 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) fortaleceram o caso para a raspagem de dados públicos, mas novos riscos estão a surgir em torno de dados de treino de IA, alegações de direitos de autor e da Lei de IA da UE. As políticas específicas de cada plataforma variam bastante — Google, Amazon, LinkedIn, Meta e X aplicam as suas regras de formas diferentes — portanto conheça o cenário antes de raspar.
Se algum dia estiver em dúvida, procure orientação jurídica — especialmente em projetos grandes ou sensíveis. E lembre-se: o cenário legal está sempre a mudar, por isso mantenha-se informado e ágil.
Quer aprender mais sobre raspagem web, conformidade e automação? Confira o para mais guias ou experimente você mesmo a .
FAQs
1. A raspagem web é ilegal em todo o lado?
Não. A raspagem web não é inerentemente ilegal, mas a sua legalidade depende do que raspa, de como raspa e de onde está. Raspar dados públicos e não pessoais para uso interno geralmente é permitido na maioria das regiões, mas raspar dados pessoais ou protegidos por direitos de autor, ou violar os termos do site, pode ser ilegal ().
2. O robots.txt torna a raspagem ilegal se eu o ignorar?
O robots.txt não é juridicamente vinculativo, mas é uma boa prática respeitá-lo. Ignorá-lo, por si só, não vai gerar um processo, mas pode fazer com que pareça um "ator de má-fé" se houver disputa ().
3. Posso raspar Google, Amazon ou LinkedIn?
É complicado. Os três proíbem a raspagem nos seus ToS, mas tribunais decidiram que os ToS podem não vincular utilizadores sem login (veja Meta v. Bright Data e X Corp v. Bright Data, ambos de 2024). Raspar dados publicamente visíveis (preços de produtos, listagens de empresas, perfis públicos) geralmente é juridicamente defensável nos EUA. Ainda assim, cada plataforma aplica as suas regras de forma diferente: a Amazon é a mais agressiva em ações legais (processou a Perplexity AI em novembro de 2025); o LinkedIn depende de barreiras técnicas e alegações contratuais; o Google está a usar cada vez mais a aplicação baseada no DMCA. Raspe sempre com responsabilidade e espere contramedidas técnicas.
4. Posso raspar Facebook ou Instagram?
Após Meta v. Bright Data (2024), raspar dados públicos do Facebook e do Instagram sem fazer login está em base jurídica mais forte. O tribunal decidiu que os ToS da Meta não se aplicam a não utilizadores. Mas nunca crie contas falsas nem raspe dados atrás de barreiras de login — isso cruza a linha.
5. Posso raspar o X (Twitter)?
O X atualizou os seus ToS em 2023 para proibir toda a raspagem sem consentimento por escrito e implementou defesas técnicas agressivas (Cloudflare Turnstile, limites de 300 requisições por hora, pontuação de reputação de IP). No entanto, a Bright Data venceu em tribunal em base semelhante — dados públicos raspados sem conta não ficam vinculados aos ToS do X. Tecnicamente, o X é uma das plataformas mais difíceis de raspar em 2026.
6. Raspagem de dados para treinar modelos de IA é legal?
Esta é a maior questão em aberto em 2026. Grandes processos (NYT v. OpenAI, acordo de US$ 1,5 bilhão da Anthropic) sugerem risco jurídico significativo. A Lei de IA da UE exige divulgação das fontes dos dados de treino e respeito pelas exclusões de direitos de autor. A proposta AI Accountability for Publishers Act exigiria permissão e pagamento. Se está a raspar para treinar IA, procure orientação jurídica antes de continuar.
7. Qual é a forma mais segura de usar ferramentas de raspagem web como a Thunderbit?
Fique nos dados públicos, respeite os termos do site, evite informações pessoais a menos que tenha base legal e use os dados internamente. A Thunderbit foi criada para ajudar a manter a conformidade, raspando apenas o que está visível no navegador e alertando sobre sites arriscados ().
8. Posso raspar dados para uso comercial?
Depende. Usar dados raspados para análises internas ou investigação é, em geral, mais seguro. Republicar ou vender dados raspados, especialmente se forem protegidos por direitos de autor ou pessoais, é muito mais arriscado e pode exigir permissão ou licença.
9. Como acompanhar mudanças jurídicas e técnicas na raspagem web?
Siga notícias de direito digital, acompanhe os seus sites-alvo para mudanças nos ToS ou políticas e use ferramentas como a Thunderbit, que atualizam regularmente os seus modelos e recursos de conformidade. Pontos principais a observar em 2026: aplicação da Lei de IA da UE (agosto), processos contínuos sobre direitos de autor em IA e novas leis estaduais de privacidade nos EUA. Na dúvida, consulte um profissional jurídico.