Imagine só: já estamos em 2025, você acorda, toma aquele café e quer saber se o preço da TV de 65 polegadas no Walmart finalmente caiu — ou talvez você gerencie um e-commerce e precisa monitorar preços, estoque e avaliações dos clientes do Walmart em tempo real. Ficar entrando no site do Walmart todo dia, produto por produto? Isso seria um trampo sem fim (e nada divertido). Mas, com um pouco de Python e técnicas de raspagem de dados, dá pra automatizar tudo e transformar horas de pesquisa em poucos minutos.
Tenho bastante experiência criando ferramentas de automação e IA para empresas. Raspar dados do Walmart é um desses “truques de bastidor” que transformam pesquisas cansativas em algumas linhas de código — e vou te mostrar como fazer isso na prática. Neste guia, você vai entender o que é scraping no Walmart, por que isso é tão valioso para negócios em 2025 e como montar um raspador Walmart robusto em Python — passo a passo, com exemplos reais e dicas de quem já apanhou bastante. Pega seu café (ou aquele snack de programador) e bora começar.
O que é Scraping no Walmart? Conceitos Básicos para 2025
Resumindo: scraping no Walmart é extrair automaticamente dados de produtos, preços e avaliações do site do Walmart usando um software — normalmente um script que simula um navegador super-rápido. Em vez de copiar e colar tudo na mão (ninguém merece), você cria um script em Python que acessa as páginas do Walmart, coleta os dados que você quer e salva para análise.
Por que Python? Porque é a ferramenta coringa do raspador Walmart: fácil de aprender, cheia de bibliotecas boas (Requests, BeautifulSoup, pandas) e uma comunidade gigante sempre compartilhando dicas e códigos. Seja você um pesquisador solo ou parte de um time, Python deixa o scraping do Walmart acessível — mesmo pra quem não é programador profissional.
Vale lembrar a diferença entre raspar para uso pessoal (acompanhar preços de alguns produtos para suas compras) e para negócios (monitorar milhares de SKUs para inteligência competitiva). O desafio técnico cresce rápido para empresas — principalmente porque o Walmart não oferece uma API pública de produtos em 2025 ().
Por que Fazer Scraping no Walmart? Valor Real para Negócios
O Walmart não é só o maior varejista físico dos EUA — virou um gigante digital, com vendas online passando de e o e-commerce já representa quase 18% das vendas totais (). São milhares de produtos, preços, avaliações e tendências — um prato cheio para análise.
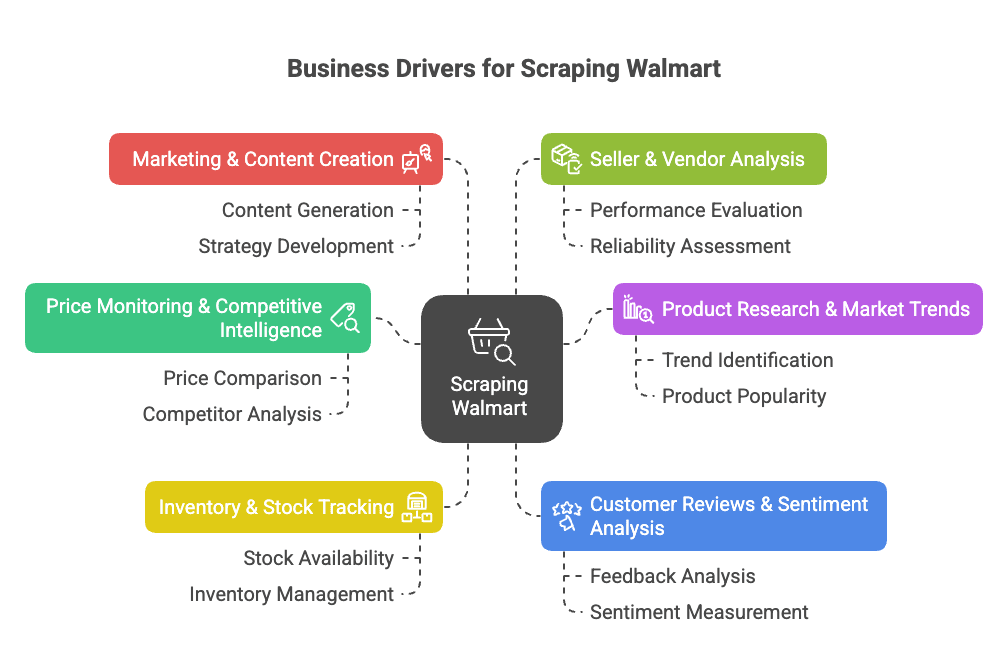
Por que raspar dados do Walmart? Olha só os principais motivos para empresas:
- Monitoramento de Preços & Inteligência Competitiva: Fique de olho nos preços, promoções e mudanças de catálogo do Walmart em tempo real para ajustar suas estratégias de preço e produto ().
- Pesquisa de Produtos & Tendências de Mercado: Analise o portfólio, especificações e tendências de categorias para achar oportunidades ou lacunas ().
- Acompanhamento de Estoque: Monitore disponibilidade para otimizar sua cadeia de suprimentos ou aproveitar rupturas dos concorrentes ().
- Avaliações de Clientes & Análise de Sentimento: Junte e analise avaliações para melhorar produtos ou identificar pontos críticos ().
- Marketing & Criação de Conteúdo: Veja quais produtos são “Mais Vendidos”, como são apresentados e que tipo de conteúdo converte ().
- Análise de Vendedores & Fornecedores: Descubra os melhores vendedores terceiros ou ofertas não autorizadas ().
Dá uma olhada nesse resumo dos casos de uso, quem se beneficia e os ganhos:
| Caso de Uso | Quem se Beneficia | Benefícios & ROI |
|---|---|---|
| Monitoramento de Preços | Equipes de Preço & Vendas | Preços da concorrência em tempo real, precificação dinâmica, proteção de margem |
| Análise de Portfólio & Catálogo | Gestão de Produto, Merchandising | Identifique lacunas, lance novos produtos, melhore o catálogo |
| Acompanhamento de Estoque | Operações & Supply Chain | Previsão de demanda, evite rupturas, otimize distribuição |
| Avaliações & Sentimento | Produto, Experiência do Cliente | Melhorias baseadas em dados, satisfação do cliente |
| Tendências de Mercado & Analytics | Estratégia & Pesquisa de Mercado | Identifique tendências, tome decisões estratégicas, entre em novos segmentos |
| Estratégia de Conteúdo & Preço | Marketing & E-commerce | Refine preços, aprenda com conteúdos de alta performance |
| Monitoramento de Vendedores | Vendas & Parcerias | Encontre parceiros, proteja a marca, monitore vendedores não autorizados |
Resumindo: scraping no Walmart economiza tempo, aumenta receita e dá vantagem competitiva. Em vez de checar 50 páginas na mão, seu script pode coletar milhares de listagens em minutos ().
O raspador Walmart é um divisor de águas para times de e-commerce, vendas e pesquisa de mercado. Com as ferramentas certas, você automatiza a coleta de dados e foca no que realmente importa: os insights.
Scraping do Walmart com Python: O que Você Precisa
Antes de começar, bora preparar o ambiente Python. Você vai precisar de:
- Python 3.9+ (recomendo 3.11 ou 3.12 em 2025)
- Requests: Para buscar páginas web
- BeautifulSoup (bs4): Para analisar HTML
- pandas: Para organizar e exportar dados
- json: Para manipular dados JSON (já vem com Python)
- Navegador com DevTools: Para inspecionar a estrutura das páginas do Walmart (F12 é seu melhor amigo)
- pip: Para instalar pacotes Python
Comando rápido pra instalar tudo:
1pip install requests beautifulsoup4 pandasSe quiser deixar o projeto organizado, crie um ambiente virtual:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Mac/Linux
3# ou
4walmart-scraper\\Scripts\\activate.bat # WindowsTeste se está tudo certo:
1import requests, bs4, pandas
2print("Bibliotecas carregadas com sucesso!")Se aparecer essa mensagem, pode seguir.
Passo 1: Estruturando seu Raspador Walmart em Python
Organize seu projeto assim:
- Crie uma pasta para o projeto (ex:
walmart_scraper/). - Abra seu editor de código (VSCode, PyCharm ou até Notepad++ — sem preconceito).
- Comece um novo script (ex:
walmart_scraper.py).
Modelo inicial:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonAgora você já pode buscar as páginas de produtos do Walmart.
Passo 2: Buscando Páginas de Produtos do Walmart com Python
Pra raspar o Walmart, você precisa pegar o HTML da página do produto. Mas atenção: o Walmart é bem rígido com bloqueio de bots. Se usar só requests.get(url), provavelmente vai receber um “Você é um robô?” antes de terminar de falar “rollback”.
O segredo? Simular um navegador de verdade. Ou seja, definir headers como User-Agent e Accept-Language pra parecer o Chrome ou Firefox.
Exemplo:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textDica: Use requests.Session() pra manter cookies e parecer ainda mais humano:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Visite a home pra pegar cookies
4response = session.get(product_url)Sempre confira response.status_code (tem que ser 200). Se aparecer uma página estranha ou CAPTCHA, diminua a velocidade, troque de IP ou faça uma pausa. O anti-bot do Walmart é pesado ().
Lidando com o Anti-Bot do Walmart
O Walmart usa ferramentas como Akamai e PerimeterX pra identificar bots analisando IP, headers, cookies e até o fingerprint do navegador. Pra evitar bloqueios:
- Sempre defina headers realistas (veja acima).
- Diminua a frequência dos acessos — espere 3–6 segundos entre as requisições.
- Alterne os intervalos pra não parecer um robô acelerado.
- Use proxies se for raspar em grande escala (mais adiante).
- Se aparecer CAPTCHA, pare — não tente forçar.
Se quiser ir além, bibliotecas como curl_cffi deixam as requisições Python ainda mais parecidas com o Chrome (). Mas, pra maioria dos casos, headers e paciência resolvem.
Passo 3: Extraindo Dados de Produtos do Walmart com BeautifulSoup
Agora vem a parte legal: extrair os dados que você quer. O site do Walmart usa Next.js, então a maioria das informações está numa tag <script id="__NEXT_DATA__"> como um JSONzão.
Veja como pegar:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)Agora você tem um dicionário Python com todas as informações do produto. Normalmente, os detalhes estão em:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]Depois, é só extrair o que quiser:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")Por que usar o JSON? Porque é estruturado, estável e menos sujeito a quebras se o HTML mudar. Além disso, traz detalhes que nem sempre aparecem na página ().
Lidando com Conteúdo Dinâmico e Dados JSON
Às vezes, avaliações ou status de estoque são carregados via JavaScript ou APIs separadas. A boa notícia: o JSON inicial geralmente já traz o que você precisa. Se não, use o DevTools do navegador pra achar os endpoints de API e simular as requisições.
Mas, pra maioria dos dados, o JSON do __NEXT_DATA__ resolve.
Passo 4: Salvando e Exportando os Dados do Walmart
Com os dados em mãos, salve em um formato organizado — CSV, Excel ou JSON são ótimas opções. Com pandas, é fácil:
1import pandas as pd
2product_record = {
3 "Nome do Produto": name,
4 "Preço (USD)": current_price,
5 "Avaliação": average_rating,
6 "Qtd. Avaliações": review_count,
7 "Descrição": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)Se for raspar vários produtos, adicione cada registro a uma lista e crie o DataFrame no final.
Quer exportar pra Excel? Use df.to_excel("walmart_products.xlsx", index=False) (instale o openpyxl). Pra JSON: df.to_json("walmart_products.json", orient="records", indent=2).
Dica: Sempre confira os dados exportados pra garantir que estão corretos. Nada pior do que raspar 1.000 preços e perceber que todos vieram “None” porque o Walmart mudou um campo.
Passo 5: Escalando seu Raspador Walmart
Quer raspar vários produtos? Olha só:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...mais URLs
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...parse e extraia como antes...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # Seja educado!Se não tiver uma lista de URLs, comece por uma página de busca, extraia os links dos produtos e depois raspe cada um ().
Atenção: Raspar centenas ou milhares de páginas rápido demais pode bloquear seu IP. É aí que entram os proxies.
Usando Proxies e APIs de Scraper para Walmart
Proxies permitem alternar seu IP, dificultando o bloqueio pelo Walmart. Você pode comprar proxies residenciais (que parecem usuários reais) ou usar pools de proxies. Exemplo de uso com requests:
1proxies = {
2 "http": "<http://seu.proxy.endereco>:porta",
3 "https": "<https://seu.proxy.endereco>:porta"
4}
5response = session.get(url, proxies=proxies)Pra grandes volumes, considere uma API de scraper — esses serviços cuidam dos proxies, CAPTCHAs e até do JavaScript pra você. Basta enviar a URL do Walmart e receber os dados prontos (às vezes já em JSON).
Veja a comparação:
| Abordagem | Vantagens | Desvantagens | Ideal para |
|---|---|---|---|
| Python + Proxies | Controle total, baixo custo para poucos dados | Manutenção, custo de proxy, risco de bloqueio | Desenvolvedores, necessidades customizadas |
| API de Scraper | Fácil, lida com anti-bot, escala bem | Custo em larga escala, menos flexibilidade, dependência de terceiros | Usuários de negócios, grandes volumes, resultados rápidos |
Se você não é desenvolvedor ou quer dados rápido, ferramentas como a fazem tudo em poucos cliques — sem código, sem proxies, sem dor de cabeça. (Mais sobre isso já já.)
Principais Desafios no Scraping do Walmart (e Como Resolver)
Scraping no Walmart não é só flores e preços baixos. Veja os problemas mais comuns — e como contornar:
- Anti-bot agressivo: O Walmart usa detecção avançada (IP, headers, cookies, fingerprint, JavaScript). Solução: headers realistas, sessões, delays e proxies ().
- CAPTCHAs: Se aparecer, faça uma pausa e tente depois. Para casos persistentes, há serviços que resolvem CAPTCHAs, mas aumentam custo e complexidade ().
- Mudanças no site: O Walmart atualiza o site com frequência. Se o raspador quebrar, revise a estrutura do JSON e ajuste o código. Código modular ajuda.
- Paginação & Subpáginas: Para grandes volumes, trate a paginação com loops e condições de parada. Sempre verifique se chegou ao fim ().
- Volume de dados & limites: Para grandes volumes, faça requisições em lotes e salve resultados parciais. Não tente carregar 100 mil produtos na memória de uma vez.
- Questões legais & éticas: Raspe só dados públicos, respeite os termos do Walmart e não sobrecarregue os servidores. Se for usar comercialmente, revise a conformidade.
Quando migrar para uma solução gerenciada? Se você passa mais tempo lidando com CAPTCHAs do que analisando dados, talvez seja hora de usar uma ferramenta como Thunderbit ou uma API de scraper. Pra quem não é técnico, ferramentas no-code são a escolha mais inteligente ().
Scraping do Walmart com Python: Exemplo Completo de Código
Vamos juntar tudo. Olha só um script Python completo e comentado pra raspar páginas de produtos do Walmart:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# Configura sessão e headers
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# Visite a home pra pegar cookies
14session.get("<https://www.walmart.com/>")
15# Lista de URLs de produtos
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # Adicione mais URLs
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"Erro na requisição para \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"Falha ao buscar \{url\} (status \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"Script de dados não encontrado para \{url\} - possivelmente bloqueado ou formato alterado.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"Erro ao ler JSON em \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"Dados do produto não encontrados no JSON para \{url\}.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "Nome": name,
59 "Marca": brand,
60 "Preço": price,
61 "Moeda": currency,
62 "PreçoOriginal": orig_price,
63 "NotaMédia": avg_rating,
64 "QtdAvaliações": review_count,
65 "Descrição": desc
66 }
67 all_products.append(product_record)
68 # Delay aleatório pra evitar bloqueio
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)Personalize:
- Adicione mais URLs em
product_urls. - Ajuste os campos conforme sua necessidade.
- Modifique o delay conforme o risco.
Conclusão & Principais Lições
Resumo do que rolou:
- Scraping no Walmart é uma forma poderosa de acessar dados de preços, produtos e avaliações — essencial pra inteligência competitiva, precificação e desenvolvimento de produtos em 2025.
- Python é a ferramenta ideal: Com Requests, BeautifulSoup e pandas, você monta um raspador robusto — mesmo sem ser expert em código.
- Anti-bot é realidade: Simule headers de navegador, use sessões, adicione delays e proxies conforme escalar.
- Extraia dados do JSON
__NEXT_DATA__: É mais limpo, estável e menos sujeito a quebras do que HTML. - Exporte pra análise: Use pandas pra salvar em CSV, Excel ou JSON.
- Escale com cuidado: Pra grandes volumes, use proxies ou APIs de scraper. Se não for técnico, o resolve tudo em poucos cliques — sem código. Dá pra exportar direto pra Excel, Google Sheets, Airtable ou Notion de graça ().
Minha dica:
Comece pequeno — raspe um produto, depois alguns. Garanta que os dados estão corretos. Respeite os termos do Walmart e não sobrecarregue os servidores. Se a demanda crescer, considere ferramentas gerenciadas ou APIs pra economizar tempo e evitar dor de cabeça. E se cansar de debugar Python, lembre: com Thunderbit, você raspa o Walmart (e quase qualquer site) em dois cliques, com IA cuidando de tudo ().
Quer se aprofundar em scraping, automação de dados ou produtividade com IA? Dá uma olhada nos outros guias do .
Boas raspagens — que seus dados sejam sempre fresquinhos, precisos e livres de CAPTCHAs.
P.S. Se um dia você se pegar raspando o Walmart às 2h da manhã e resmungando pra tela, relaxa: até os melhores já passaram por isso. Debugar é só mais um treino pra quem trabalha com dados.
Perguntas Frequentes
1. É legal raspar dados do site do Walmart usando Python?
Raspar dados públicos pra uso pessoal ou análise não comercial geralmente é permitido, mas pra uso comercial pode ter questões legais e éticas. Sempre confira os termos de uso do Walmart e garanta que sua raspagem não viole limites de acesso, sobrecarregue os servidores ou colete dados sensíveis.
2. Que tipo de dados posso extrair do Walmart com Python?
Dá pra extrair nomes de produtos, preços, marcas, descrições, avaliações de clientes, notas, status de estoque e mais — especialmente analisando o JSON estruturado na tag <script id="__NEXT_DATA__"> do Walmart.
3. Como evitar bloqueios ao raspar o Walmart?
Use headers realistas, mantenha sessões, adicione delays aleatórios entre as requisições (3–6 segundos), alterne proxies e evite muitos acessos em pouco tempo. Pra grandes projetos, considere APIs de scraper ou ferramentas como Thunderbit, que já lidam com anti-bot automaticamente.
4. Posso escalar pra raspar centenas ou milhares de páginas de produtos do Walmart?
Sim, mas vai precisar gerenciar proxies, controlar a frequência das requisições e, talvez, usar uma API de scraper pra eficiência. O Walmart tem defesas anti-bot robustas, então escalar sem preparo pode resultar em bloqueios ou CAPTCHAs.
5. Qual a forma mais fácil de raspar o Walmart se não sei programar?
Ferramentas como a Extensão Thunderbit AI Web Scraper para Chrome permitem raspar páginas de produtos do Walmart sem escrever código. Ela lida com anti-bot, exporta dados pra Excel, Notion e Sheets, e é ideal pra quem não é desenvolvedor ou times de negócios que precisam de insights rápidos.