
Se você precisa de dados da web em 2026, a parte difícil já não é mais “isso pode ser extraído?”. Agora, a pergunta é: “qual camada de ferramentas me entrega dados utilizáveis com o menor desperdício de configuração, manutenção e custo de infraestrutura?” Por isso, esta página está organizada, antes de tudo, por adequação: Raspador Web IA para velocidade, ferramentas no-code para tarefas repetíveis no navegador, APIs para escala e combate a bloqueios, e bibliotecas Python para equipes que querem controle total.
Resposta rápida
- Escolha um Raspador Web IA se quiser o caminho mais rápido da página até a planilha, com configuração mínima.
- Escolha um raspador no-code se precisar de paginação mais explícita, agendamento, login ou controle repetível da tarefa.
- Escolha uma API de scraping se renderização, proteção anti-bot, concorrência e taxa de desbloqueio forem mais importantes do que a simplicidade da interface.
- Escolha uma biblioteca Python se sua equipe quiser controlar totalmente requisições, parsing, automação de navegador, tentativas e implantação.
Para a maioria das equipes de negócio, o erro é descer a stack cedo demais. Comece com a ferramenta mais leve que consiga fazer o trabalho com confiabilidade e só evolua de IA para no-code, de no-code para APIs e de APIs para código quando o fluxo realmente exigir isso.
Baixe aqui o pacote visual completo: .
Tabela rápida de comparação: ferramentas de scraping de sites em um relance
Os sinais de preço abaixo foram conferidos nas páginas oficiais de produto, preços ou documentação em 12 de maio de 2026. Quando os fornecedores usam cobrança personalizada ou por uso, descrevo o modelo de preço em vez de forçar um valor mensal fictício comparável entre todos.
| Ferramenta | Categoria | Melhor uso | Por que entrou nesta lista de 2026 | Sinal de preço (verificado em mai. 2026) |
|---|---|---|---|---|
| Thunderbit | Raspador Web IA | Vendas, operações, e-commerce, imóveis | Caminho mais rápido, sem parte técnica, da página web para uma tabela estruturada | Plano gratuito, planos pagos, preços para empresas |
| Kadoa | Plataforma de extração com IA | Equipes de dados e programas recorrentes maiores | Ótima opção para fluxos de extração com estilo agente e autorrecuperação | Avaliação gratuita, planos por uso e corporativos |
| Octoparse | Raspador no-code | Analistas e operações recorrentes | Scraping em nuvem maduro e construtor visual de tarefas | Plano gratuito, Standard a partir de US$ 69/mês, níveis superiores |
| ParseHub | Raspador low-code | Não programadores técnicos e pesquisadores | Lógica de navegação flexível para sites mais difíceis | Plano gratuito, planos pagos a partir de US$ 189/mês |
| Web Scraper | Raspador no-code para navegador | Iniciantes e tarefas leves repetíveis | Modelo de sitemap direto, com camada opcional na nuvem | Extensão gratuita, Cloud a partir de US$ 50/mês |
| Browse AI | Raspador robô no-code | Monitoramento e equipes que trabalham a partir de planilhas | Forte para monitoramento repetível e alertas de mudanças | Plano gratuito, planos pagos, nível gerenciado |
| Bardeen | Automação de navegador com IA | Automação de GTM e revops | Brilha quando o scraping é só uma etapa dentro de um fluxo maior | Plano gratuito, Basic a partir de US$ 10/mês, Premium e Enterprise |
| ScrapeStorm | Raspador visual assistido por IA | Usuários que querem configuração visual rápida | Ponte útil entre seletores manuais e assistência de IA | Teste gratuito, planos pagos, preços corporativos |
| ScraperAPI | API de scraping | Desenvolvedores escalando volume de requisições | API simples com proxy, CAPTCHA e offload de renderização | Teste de 7 dias, planos pagos a partir de US$ 49/mês |
| Bright Data Web Scraper | Plataforma corporativa de scraping | Programas pesados em compras e focados em conformidade | Pilha de coleta de dados mais ampla do grupo | Preços por produto e por uso |
| Zyte | API + stack anti-bot | Desenvolvedores e equipes de dados | Ações de navegador fortes, renderização JS e rotação de IP | Crédito grátis de US$ 5, planos por uso |
| ZenRows | API de scraping | Startups e equipes de desenvolvimento | API anti-bot limpa, com adoção menos friccionada | Teste gratuito, Developer a partir de US$ 69/mês |
| ScrapingBee | API de scraping | Equipes que raspam sites pesados em JS | Útil quando renderização é o principal gargalo | Teste gratuito, planos pagos a partir de US$ 49/mês |
| Selenium | Automação de navegador open source | Fluxos no estilo QA e scraping com muita interação | Ainda relevante onde a interação exata do usuário importa | Gratuito e open source |
| Beautiful Soup | Biblioteca Python de parsing | Scraping leve em Python | O parser mais fácil da pilha para HTML bagunçado | Gratuito e open source |
| Playwright | Automação moderna de navegador | Apps web modernos e equipes de desenvolvimento | Melhor escolha moderna para scraping de navegador com script | Gratuito e open source |
| urllib3 | Biblioteca HTTP em Python | Desenvolvedores que querem controle de requisição em baixo nível | Base útil quando você quer controlar diretamente o comportamento de transporte | Gratuito e open source |
Como escolher a ferramenta certa de scraping de sites
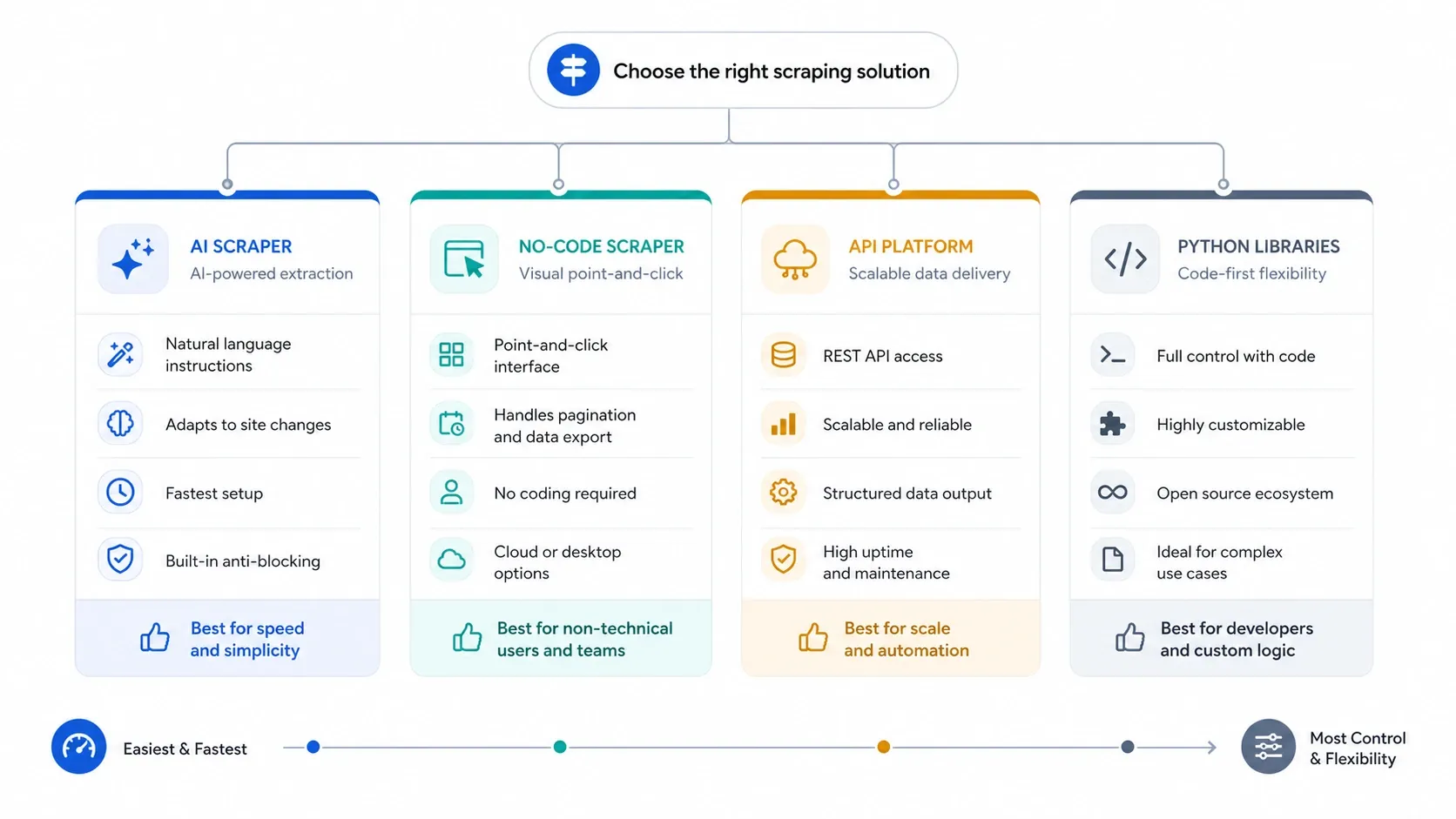
Use quatro filtros antes de comparar marcas:
- Tempo até a primeira saída útil
Se a ferramenta não consegue gerar uma tabela real rapidamente, ela já está perdendo para a maioria dos casos de negócio. - Carga de manutenção
Um raspador barato que quebra sempre que o layout muda não é, na prática, barato. - Limite de escala
Uma extensão de navegador pode ser perfeita para 50 páginas por semana e péssima para 5 milhões de requisições mensais. - Ajuste ao fluxo de trabalho
O melhor raspador para revops raramente é o melhor para um engenheiro de plataforma.
A estrutura de decisão costuma ser mais simples do que as equipes imaginam:
- Se você quer raspar leads, listagens ou páginas de produto sem mexer em seletores, comece com IA.
- Se precisa de tarefas repetíveis, execuções na nuvem e controle mais explícito, vá para construtores visuais no-code.
- Se anti-bot, renderização JavaScript e concorrência forem o problema real, pule para APIs.
- Se quiser controlar cada camada por conta própria, use bibliotecas Python e aceite a carga de manutenção.
Melhores raspadores web IA para fluxos de trabalho rápidos de negócio
Esta é a primeira categoria que eu testaria se o resultado desejado for dados prontos para planilha, com o mínimo possível de configuração.
1. Thunderbit
O Thunderbit continua sendo o ponto de partida mais fácil aqui para quem não programa. A principal vantagem não é só “IA” em abstrato; é que o produto encurta o ciclo de configuração. Você abre uma página, pede para a IA sugerir campos, enriquece via subpáginas quando necessário e envia o resultado direto para as ferramentas que sua equipe já usa.
- Melhor para: prospecção de vendas, monitoramento de e-commerce, coleta de dados imobiliários e equipes de operações que vivem no navegador.
- Por que se destaca: caminho mais rápido de uma página confusa para uma tabela estruturada.
- Atenção: se você precisa de lógica em nível de crawler ou fluxos de engenharia altamente personalizados, eventualmente vai migrar para APIs ou código.
- Sinal de preço: plano gratuito, planos pagos self-service e preços para empresas.
Este passo a passo ainda é a maneira mais rápida de avaliar se o scraping com IA é suficiente para o seu fluxo:
2. Kadoa
O Kadoa é a opção de IA mais voltada à infraestrutura neste grupo. Faz sentido quando você quer extração com autorrecuperação e tarefas recorrentes em uma escala operacional maior do que a maioria das extensões de navegador consegue suportar.
- Melhor para: equipes de dados, programas internos de inteligência e cargas recorrentes de extração maiores.
- Por que se destaca: orquestração com estilo agente e uma proposta mais forte de redução de manutenção.
- Atenção: é mais pesado do que a maioria dos usuários de negócio precisa para raspagens pontuais rápidas.
- Sinal de preço: avaliação gratuita, planos por uso e corporativos.
Melhores ferramentas no-code de scraping de sites para tarefas repetíveis
Quando a tarefa de scraping se torna recorrente, construtores visuais de fluxo e execução na nuvem passam a importar mais do que a velocidade de um clique.
3. Octoparse
O Octoparse continua sendo uma das ferramentas no-code mais confiáveis quando a tarefa é maior do que uma extensão de navegador, mas ainda não chega a ser um projeto de engenharia personalizado. Seu valor está na combinação de execuções em nuvem, modelos prontos e um construtor visual de tarefas maduro.
- Melhor para: analistas, equipes de precificação e tarefas recorrentes de coleta com importância operacional real.
- Por que se destaca: mais profundidade do que plugins de navegador, sem obrigar você a programar.
- Atenção: você paga essa flexibilidade com uma curva de aprendizado mais íngreme do que nas ferramentas centradas em IA.
- Sinal de preço: plano gratuito, Standard a partir de US$ 69/mês, níveis pagos mais altos.
Se você quiser avaliar um ambiente no-code mais tradicional antes de investir em ferramentas centradas em IA, esta visão geral oficial do Octoparse ainda é útil:
4. ParseHub
O ParseHub continua relevante porque há muitas equipes que querem uma lógica de tarefas passo a passo mais rica do que um raspador IA leve consegue oferecer. Não é o produto mais bonito da categoria, mas continua flexível.
- Melhor para: pesquisadores, jornalistas e não programadores técnicos que toleram mais configuração.
- Por que se destaca: lógica condicional e controle de navegação mais fortes do que em muitas ferramentas para iniciantes.
- Atenção: mais lento para aprender e com sensação menos moderna do que concorrentes mais novos.
- Sinal de preço: plano gratuito, planos pagos a partir de US$ 189/mês.
5. Web Scraper
O Web Scraper é uma das opções mais limpas para “aprender o básico sem comprar uma plataforma”. Se você gosta do modelo de sitemap, ele ainda é uma boa porta de entrada.
- Melhor para: iniciantes, projetos hobby e tarefas menores lideradas pelo navegador.
- Por que se destaca: configuração direta e evolução fácil da extensão local para planos em nuvem.
- Atenção: fica limitado quando você precisa de lógica mais adaptativa ou de um bloqueio mais forte.
- Sinal de preço: extensão gratuita, Cloud a partir de US$ 50/mês.
6. Browse AI
O Browse AI continua sendo uma escolha forte quando scraping e monitoramento são igualmente importantes. Seu modelo de robô é intuitivo para usuários de negócio que pensam em termos de “vigie esta página e me diga o que mudou”.
- Melhor para: monitoramento de concorrentes, acompanhamento de preços e equipes que trabalham a partir de planilhas.
- Por que se destaca: onboarding refinado, monitoramento recorrente e saídas amigáveis para automação.
- Atenção: tarefas complexas e de alto volume podem ficar caras mais rápido do que em stacks centradas em API.
- Sinal de preço: plano gratuito, planos pagos, nível gerenciado.
Para equipes que avaliam monitoramento de páginas em vez de extração única, esta breve visão geral oficial ainda é um bom termômetro:
7. Bardeen
O Bardeen fala menos de profundidade bruta de scraping e mais do que acontece depois do scraping. Ele é mais forte quando a extração web é só uma etapa dentro de um fluxo maior de automação no navegador.
- Melhor para: operações de GTM, roteamento de leads, repasse para CRM e automação nativa do navegador.
- Por que se destaca: narrativa forte de automação de fluxo em torno do scraping em si.
- Atenção: não é a escolha mais limpa quando a única prioridade é precisão de extração.
- Sinal de preço: plano gratuito, Basic a partir de US$ 10/mês, níveis Premium e Enterprise.
8. ScrapeStorm
O ScrapeStorm ainda ocupa um meio-termo útil para usuários que querem assistência de IA, mas também esperam um ambiente de scraping visual mais tradicional.
- Melhor para: raspagem de diretórios, coleta de páginas de e-commerce e tarefas recorrentes configuradas visualmente.
- Por que se destaca: mais fácil de começar do que muitas ferramentas visuais antigas.
- Atenção: é menos refinado do que os líderes da categoria e pode parecer mais limitado em sites difíceis.
- Sinal de preço: teste gratuito, planos pagos, preços corporativos.

Melhores APIs de scraping quando escala e anti-bot são o que importam
Esta é a categoria para entrar quando a restrição real deixa de ser “como seleciono os dados?” e passa a ser “como mantenho isso confiável sob carga?”
9. ScraperAPI
O ScraperAPI continua sendo um dos produtos API-first mais acessíveis para desenvolvedores que querem parar de pensar em proxies e taxas de sucesso de requisições.
- Melhor para: desenvolvedores que precisam escalar do protótipo à produção rapidamente.
- Por que se destaca: API direta com suporte a proxy, CAPTCHA e renderização.
- Atenção: você ainda é responsável pelo parsing, pelas tentativas e pela qualidade dos dados a jusante.
- Sinal de preço: teste de 7 dias, planos pagos a partir de US$ 49/mês.
10. Bright Data Web Scraper
A Bright Data é a opção pesada quando capacidade de desbloqueio, inventário de proxies, postura de conformidade e opções gerenciadas importam mais do que simplicidade.
- Melhor para: coleta em escala corporativa e programas sensíveis a conformidade.
- Por que se destaca: a pilha mais ampla desta comparação, de proxies a produtos gerenciados de coleta.
- Atenção: é fácil comprar mais do que o necessário se sua equipe ainda tiver um fluxo relativamente simples.
- Sinal de preço: preços por produto e por uso.
11. Zyte
O Zyte continua sendo uma opção séria para equipes de desenvolvimento que querem ações de navegador, renderização JS, IPs rotativos e postura anti-bot em uma única proposta de plataforma.
- Melhor para: programas de scraping liderados por engenharia e sistemas repetíveis de extração.
- Por que se destaca: stack forte contra detecção e fluxos API-first.
- Atenção: funciona melhor para equipes com responsabilidade de engenharia do que para usuários de negócio.
- Sinal de preço: crédito gratuito de US$ 5, planos por uso.
12. ZenRows
O ZenRows é uma das experiências de desenvolvedor mais limpas na categoria de API se você quer lidar com anti-bot sem um processo de compra no estilo enterprise.
- Melhor para: startups, desenvolvedores e equipes internas enxutas.
- Por que se destaca: adoção com baixa fricção e posicionamento forte em anti-bot.
- Atenção: ainda é um produto de API, então você continua com a lógica da aplicação e a carga de QA.
- Sinal de preço: teste gratuito, Developer a partir de US$ 69/mês.
13. ScrapingBee
O ScrapingBee faz sentido quando sua necessidade real é uma página renderizada e menos trabalho de infraestrutura, especialmente em sites pesados em JavaScript.
- Melhor para: desenvolvedores que raspam sites dinâmicos e querem offload de renderização.
- Por que se destaca: API simples para navegação sem interface e proxies.
- Atenção: ele tira o trabalho de infraestrutura, não a necessidade de uma boa lógica de scraping.
- Sinal de preço: teste gratuito, planos pagos a partir de US$ 49/mês.
Melhores bibliotecas Python de scraping de sites para stacks personalizadas
Este grupo ainda é a resposta certa quando controle importa mais do que conveniência e sua equipe está pronta para assumir a manutenção.
14. Selenium
O Selenium não é a ferramenta de navegador mais nova, mas continua relevante onde a fidelidade da interação do usuário importa mais do que a taxa bruta de scraping.
- Melhor para: fluxos com muita interação, sobreposição com QA e sites em que o comportamento do navegador é o principal desafio.
- Por que se destaca: ecossistema maduro e amplo suporte a navegadores.
- Atenção: é mais pesado e lento do que stacks de automação mais novas para muitas cargas de scraping.
- Sinal de preço: gratuito e open source.
15. Beautiful Soup

O Beautiful Soup continua sendo o parser mais fácil da pilha de scraping em Python. Não é uma plataforma completa de scraping, mas ainda é a forma mais simples de transformar HTML bagunçado em estrutura utilizável.
- Melhor para: tarefas leves em Python, páginas HTML estáticas e protótipos rápidos.
- Por que se destaca: baixa carga cognitiva e parsing tolerante.
- Atenção: combine com
requests, uma camada de navegador ou um crawler; sozinho, ele apenas faz parsing. - Sinal de preço: gratuito e open source.
16. Playwright
O Playwright é minha recomendação moderna padrão para equipes de desenvolvimento que precisam de automação de navegador robusta na web atual.
- Melhor para: sites pesados em JavaScript, automação moderna de navegador e equipes já confortáveis escrevendo código.
- Por que se destaca: comportamento forte de espera, suporte a múltiplos navegadores e APIs limpas.
- Atenção: você ainda é responsável por concorrência, seletores, infraestrutura de navegador e validação de dados.
- Sinal de preço: gratuito e open source.
17. urllib3
urllib3 entra na lista porque algumas equipes querem controle direto do comportamento de transporte em vez de uma abstração de nível mais alto. Não é um raspador amigável para iniciantes, mas é uma biblioteca de base útil quando você está construindo sua própria stack.
- Melhor para: desenvolvedores que querem controle rígido sobre tentativas, proxies, sessões e comportamento HTTP.
- Por que se destaca: leve, confiável e muito usado como infraestrutura.
- Atenção: você estará construindo a maior parte da stack por conta própria.
- Sinal de preço: gratuito e open source.
Ferramentas gratuitas de scraping de sites que valem testar primeiro
Se quiser testar antes de comprar, os melhores pontos de partida gratuitos desta lista são Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright e urllib3. A experiência gratuita é boa o bastante para você descobrir de que tipo de raspador realmente precisa, e isso costuma ser mais importante do que ficar obcecado com uma lista perfeita de recursos logo no primeiro dia.
Minha seleção curta por tipo de equipe

- Equipes de vendas, operações e e-commerce: comece com Thunderbit e depois compare com Browse AI se monitoramento importar mais do que enriquecimento de subpáginas.
- Analistas e operadores manuais recorrentes: Octoparse primeiro, depois ParseHub se precisar de lógica de tarefa mais personalizada.
- Equipes de automação de GTM: Bardeen se o scraping precisar fluir diretamente para CRM, Sheets ou fluxos no navegador.
- Equipes de desenvolvimento construindo ferramentas internas: ScraperAPI, ZenRows, Zyte ou Playwright, dependendo de quanto controle de stack você quer assumir.
- Programas corporativos de dados: Bright Data e Zyte são as conversas de infraestrutura mais sérias aqui, com Kadoa como alternativa liderada por IA quando reduzir manutenção for o objetivo principal.
Quando descer na stack
Use este caminho de evolução:
- Continue com raspadores web IA até esbarrar em limites de repetibilidade ou casos de borda.
- Vá para construtores no-code quando agendamento, paginação e execução na nuvem importarem mais do que a simplicidade de um clique.
- Vá para APIs quando taxa de desbloqueio, renderização e concorrência virarem o gargalo.
- Vá para bibliotecas Python quando o custo da abstração do fornecedor for maior do que manter todo o sistema por conta própria.
A maioria das equipes faz isso na ordem errada. Constroem demais logo de início e só depois percebem que uma ferramenta mais leve poderia ter resolvido o fluxo real.
Conclusão final
A melhor ferramenta de scraping de sites em 2026 não é a que tem a lista mais longa de recursos. É a que coloca dados precisos no próximo fluxo de trabalho com o menor custo de manutenção para sua equipe. É por isso que ferramentas centradas em IA continuam ganhando para operadores, ferramentas no-code seguem valiosas para tarefas repetíveis no navegador, APIs dominam quando escala e bloqueio importam, e bibliotecas Python ainda ocupam a ponta de maior controle da stack.
Se o seu objetivo é obter dados úteis nesta semana, comece simples. Se a sua carga de trabalho já está mostrando que taxa de desbloqueio, renderização no navegador e controle de engenharia são o problema real, desça na stack de forma deliberada, e não por hábito.
FAQs
1. Qual é a melhor ferramenta de scraping de sites para usuários não técnicos em 2026?
Para a maioria das equipes não técnicas, ferramentas centradas em IA como Thunderbit e Browse AI ainda são o caminho mais rápido porque reduzem o tempo de configuração, o trabalho com seletores e a carga de manutenção.
2. O que devo escolher para sites pesados em JavaScript ou protegidos por anti-bot?
Normalmente é aí que ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright ou Selenium começam a fazer mais sentido do que extensões de navegador.
3. Ferramentas de scraping no-code ainda são relevantes agora que os raspadores IA melhoraram?
Sim. Octoparse, ParseHub, Web Scraper e Browse AI ainda importam quando você precisa de mais controle explícito da tarefa, execuções recorrentes ou depuração visível no navegador.
4. Quais ferramentas fazem mais sentido para equipes de desenvolvimento?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup e urllib3 são as opções mais naturais quando a engenharia é dona do fluxo.
Leituras relacionadas