A extração de dados do Facebook ainda vale a pena em 2026, mas só se você escolher o modelo de coleta certo. O Pew Research Center informou em 20 de novembro de 2025 que , e a Meta disse em 29 de abril de 2026 que sua em março de 2026. Essa escala mantém o Facebook útil para monitorar o Marketplace, pesquisar páginas públicas, gerar leads e acompanhar concorrentes. A parte difícil não é encontrar casos de uso. A parte difícil é obter dados limpos sem esbarrar em barreiras de login, carregamentos dinâmicos, bloqueios temporários ou configurações frágeis de scraping.
Esta seleção anual foi feita para acelerar decisões. Reavaliei as páginas oficiais dos produtos, a documentação e os sinais de preço em 8 de maio de 2026 e mantive a lista focada em ferramentas que ainda fazem sentido para usuários reais de negócios. Se o seu fluxo é basicamente “pegar os dados desta página e enviar para uma planilha”, comece pela Thunderbit. Se você precisa de infraestrutura em escala de API, Bright Data, Apify e Nimble by Nimbleway ficam no topo da lista. Se o seu trabalho inclui automações em nuvem ou ações de acompanhamento depois da coleta, o PhantomBuster merece uma análise mais atenta.
Escolhas rápidas por tipo de trabalho
- Precisa da exportação mais rápida, sem código, do Facebook ou Marketplace? Comece com .
- Precisa de escala corporativa de API e desbloqueio gerenciado? Inclua na lista.
- Precisa de fluxos flexíveis de scraping em nuvem? Veja com atenção .
- Precisa de coleta da web pública com API-first e menos manutenção de scraper? Considere .
- Precisa de uma API económica para trabalhos menores? ainda é relevante.
- Precisa de scraping com mais automação de fluxo de trabalho? é a melhor opção.
- Precisa de um construtor visual com agendamento? continua a ser uma opção sólida, sem código.
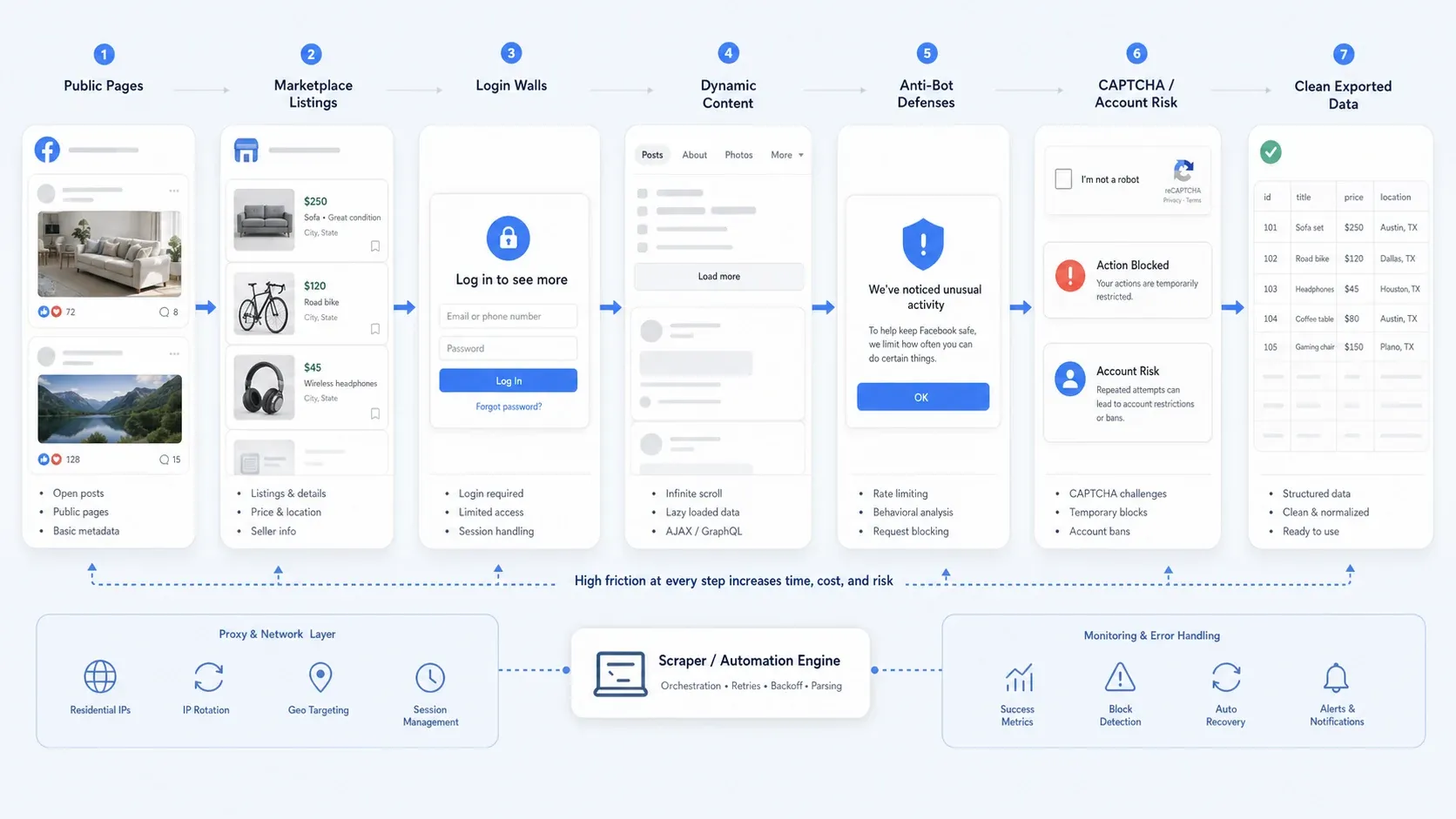
Por que extrair dados do Facebook ainda é difícil em 2026
A coleta de dados do Facebook raramente é só um problema de seletores hoje em dia. Na prática, a maioria das equipas esbarra num ou mais destes pontos:
- Acesso público parcial: algumas páginas continuam públicas, enquanto outros fluxos empurram você para o login para ver mais detalhes.
- Conteúdo dinâmico: visões do Marketplace, longas sequências de comentários e conteúdo de páginas muitas vezes carregam aos poucos.
- Defesas anti-bot: limitação de taxa, verificações comportamentais, CAPTCHAs e bloqueios temporários quebram automações ingênuas.
- Risco operacional: coletar apenas com login é muito mais arriscado do que extrair páginas públicas, especialmente se você se importa com a segurança da conta e com a repetibilidade.
Como avaliei estas ferramentas
Otimizei esta página para ajudar a montar uma lista curta, não para encher com funcionalidades. As ferramentas aqui foram comparadas com base em:
- Aderência ao fluxo de trabalho: o produto realmente atende a trabalhos de coleta no Facebook e Marketplace que equipas reais executam?
- Facilidade de uso: pessoas sem desenvolvimento ou equipas enxutas conseguem chegar a um resultado útil rapidamente?
- Escala e confiabilidade: a ferramenta ainda faz sentido quando você sai de uma coleta pontual?
- Tratamento de anti-bot e sessão: quanto atrito de infraestrutura o produto elimina?
- Qualidade da saída: é possível levar dados estruturados para CSV, Sheets ou sistemas downstream sem muita limpeza?
- Sinal de preço: o produto é prático para avaliar ou exige um movimento corporativo mais pesado?
- Postura de compliance: a ferramenta é claramente orientada para coleta de dados públicos e uso responsável?
Que tipo de extrator de dados do Facebook você precisa?
A forma mais rápida de acertar é escolher primeiro a categoria certa. As ferramentas de extração de dados do Facebook normalmente se encaixam em quatro modelos de operação:
- Ferramentas sem código no navegador: melhores quando você quer extrair rapidamente da página que já está aberta à sua frente.
- APIs de scraping: melhores quando você precisa de coleta confiável e repetível em maior volume.
- Fluxos de automação: melhores quando o scraping é apenas uma etapa num processo maior de go-to-market.
- Stacks DIY para desenvolvedores: melhores quando a sua equipa quer controlo máximo e está preparada para assumir a manutenção.
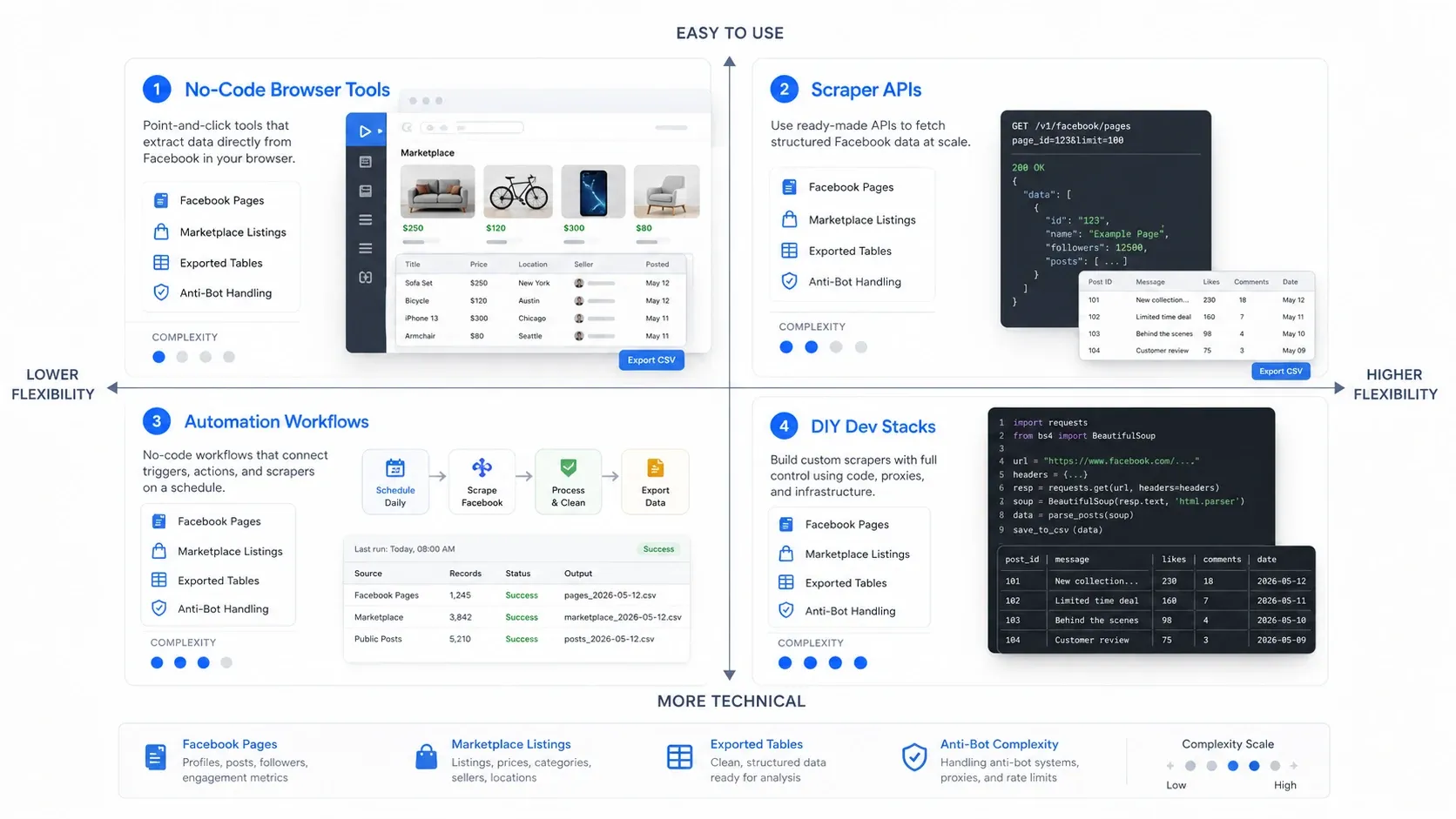
Tabela comparativa
| Ferramenta | Melhor para | Por que entrou na seleção | Sinal de preço |
|---|---|---|---|
| Thunderbit | Equipas não técnicas e trabalhos rápidos e pontuais | Detecção de campos por IA, tratamento de páginas dinâmicas no próprio navegador, exportações rápidas | Teste gratuito; planos pagos baseados em créditos |
| Bright Data | Pipelines de dados sociais públicos em larga escala | APIs dedicadas para extração de redes sociais, desbloqueio gerenciado, forte capacidade de escala | Preço por uso e corporativo |
| Apify | Fluxos flexíveis de scraping em nuvem | Actors prontos para Facebook, agendamento, acesso por API, espaço para personalização | Planos pagos da plataforma mais uso medido |
| Nimble by Nimbleway | Coleta de web pública com API-first | Fluxo de API baseado em URL e menor carga de manutenção do scraper | Preço conduzido por vendas |
| ScrapingBot | Trabalhos pequenos com dados públicos e protótipos | API simples, suporte a renderização, preço inicial mais baixo | Plano gratuito; planos pagos a partir de cerca de US$ 22/mês |
| PhantomBuster | Fluxos de automação de GTM | Automações em nuvem, fluxos de ação no navegador, bom encaixe para geração de leads | Teste gratuito; planos pagos a partir de cerca de US$ 56/mês |
| Octoparse | Scraping visual sem código com agendamento | Construtor ponto a ponto, extração em nuvem, fluxos repetíveis | Plano gratuito; planos pagos a partir de cerca de US$ 119/mês |
1. Thunderbit
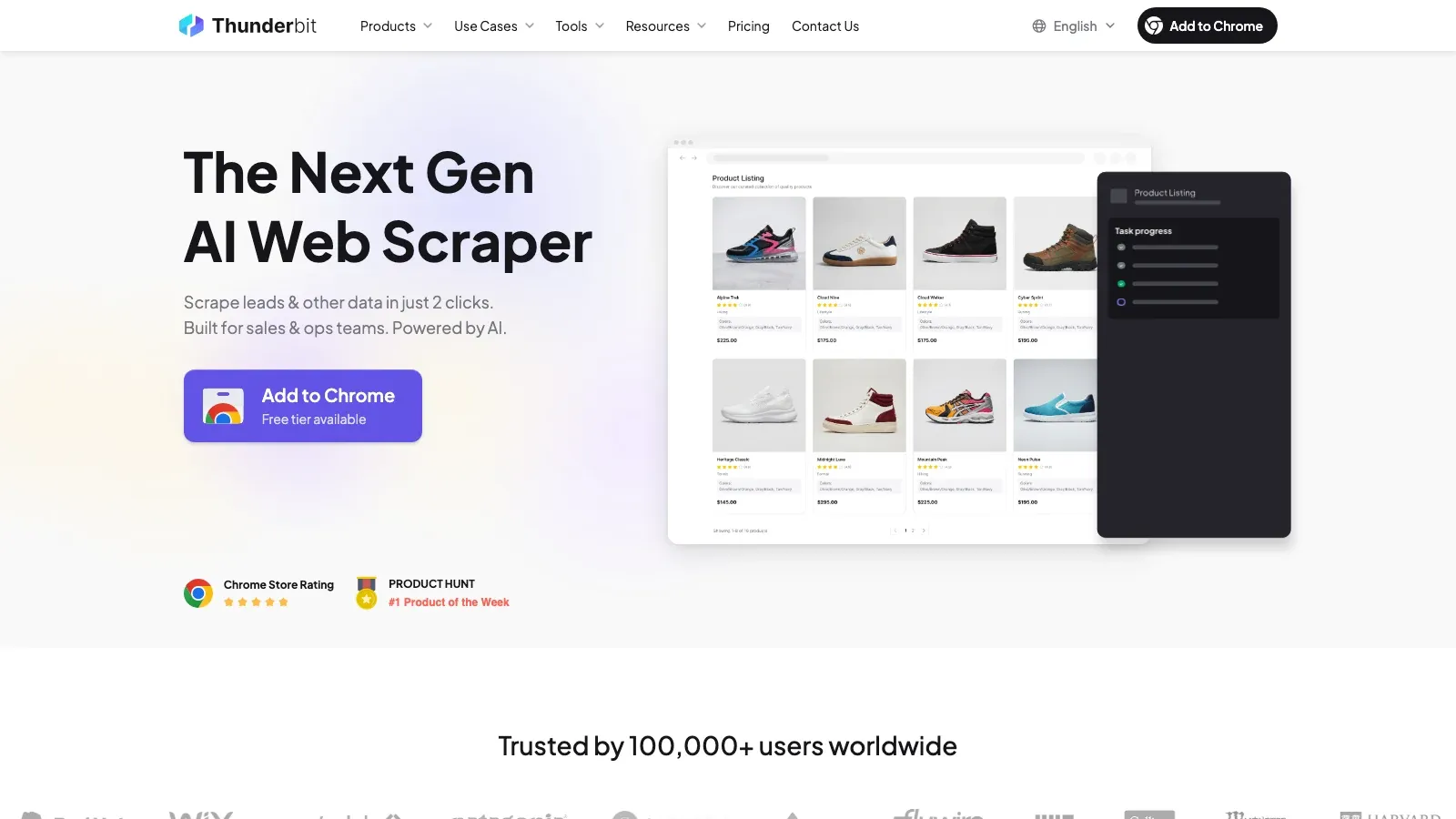
é a melhor opção aqui se o seu objetivo é transformar uma página do Facebook ou uma lista de resultados do Marketplace em dados estruturados rapidamente, sem criar ou manter um scraper. A principal vantagem é a extração semântica: ela lê a página, sugere campos úteis e permite exportar o resultado sem lidar com seletores, proxies ou código.
Por que se destaca:
- AI Suggest Fields: a Thunderbit identifica campos prováveis como título, preço, vendedor, localização, contactos e URLs.
- Tratamento nativo no navegador: como roda onde a página é renderizada, funciona bem em páginas dinâmicas e com muito scroll.
- Enriquecimento de subpáginas: você pode recolher primeiro os dados da lista e depois abrir cada anúncio ou página para obter mais detalhes.
- Exportações úteis: Excel, Google Sheets, Airtable e Notion são destinos naturais.
Se você quiser ver um vídeo antes de testar sozinho um fluxo nativo do navegador, este tutorial prático da Thunderbit é o melhor ponto de partida, porque mostra o fluxo real de extração em vez de ficar só na promessa de funcionalidades:
Ideal para: usuários sem perfil técnico, equipas de vendas, operações e investigadores que querem resultados rápidos.
Sinal de preço: teste gratuito disponível; os planos pagos são baseados em créditos. Consulte os .
2. Bright Data
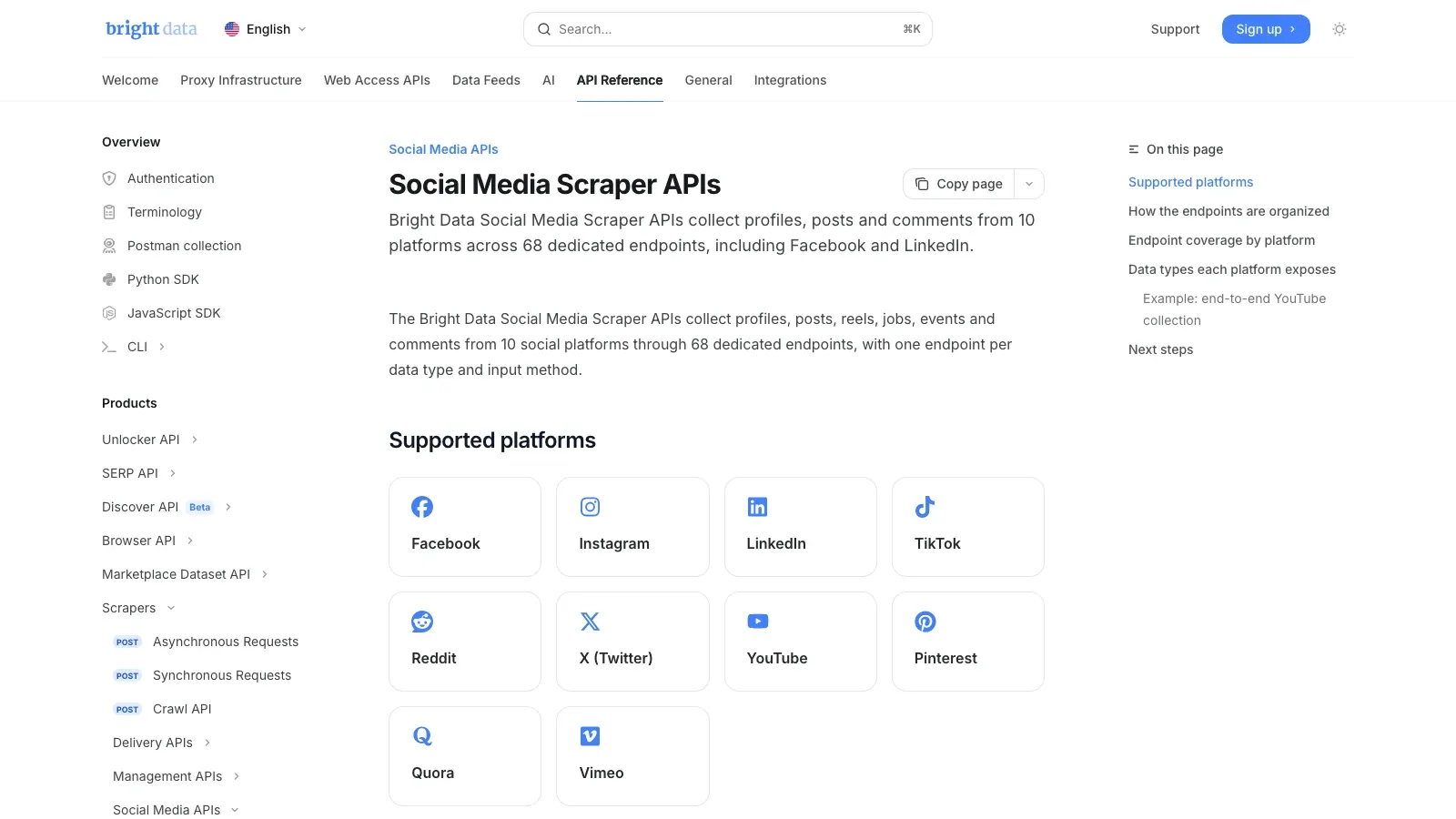
é a escolha focada em infraestrutura. A própria documentação da Bright Data informa que suas cobrem 10 plataformas e 68 endpoints dedicados, incluindo o Facebook. Se o seu trabalho é coleta de dados públicos em grande escala, esse tipo de stack de API gerenciada costuma ser muito mais realista do que tentar escalar uma extensão de navegador ou um scraper feito à mão.
Por que entra na lista:
- Endpoints dedicados para scraping de redes sociais
- Desbloqueio e extração gerenciados
- Entrega de saída estruturada para pipelines de dados
- Melhor encaixe para tarefas de monitoramento e analytics sensíveis à confiabilidade
Ideal para: analistas, equipas de dados, grandes projetos de monitoramento e conjuntos de dados sociais públicos em escala.
Sinal de preço: o preço varia por produto e volume. Verifique os .
3. Apify
continua relevante porque oferece um bom meio-termo entre modelos prontos e personalização total. Seu actor Facebook Pages Scraper é um ponto de partida útil, enquanto a plataforma mais ampla da Apify oferece execuções em nuvem, agendamento, APIs e espaço para estender o fluxo conforme as necessidades se tornam mais complexas.
Por que entrou na lista:
- Actors prontos para Facebook
- Execução em nuvem e agendamentos recorrentes
- Exportações flexíveis e acesso por API
- Mais fácil de estender do que um fluxo puramente visual sem código
Ideal para: profissionais de marketing com perfil técnico, agências, equipas de operações e trabalhos recorrentes de coleta em vários sites.
Sinal de preço: os planos da plataforma são pagos e o uso dos actors é medido separadamente. Consulte os .
4. Nimble by Nimbleway
é a opção API-first para equipas que querem enviar uma URL e deixar a plataforma cuidar de acesso, renderização e entrega. A Nimble posiciona sua como coleta de dados da web pública de ponta a ponta, o que a torna útil quando a extração do Facebook é apenas uma parte de uma stack de dados maior.
Por que vale avaliar:
- Fluxo de API baseado em URL
- Menor carga de manutenção do scraper para equipas de engenharia
- Bom encaixe para extração resiliente da web pública
- Útil quando os dados extraídos alimentam produtos internos ou dashboards
Ideal para: equipas lideradas por engenharia, pipelines de dados de produto e organizações que querem abstração de infraestrutura em vez de ferramentas pontuais.
Sinal de preço: a Nimble não destaca preços públicos de autoatendimento nas páginas principais da API, então espere um modelo conduzido por vendas e confirme diretamente com .
5. ScrapingBot
é a opção de API mais económica desta lista. Não é a plataforma mais profunda e especializada em Facebook aqui, mas ainda faz sentido para trabalhos menores com dados públicos, nos quais você quer uma API, suporte à renderização e um custo inicial menor do que o de uma infraestrutura corporativa de scraping.
Onde se encaixa:
- Scraping público simples via API
- Preço inicial mais baixo
- Renderização e tratamento de proxy incluídos
- Melhor para protótipos e extrações leves recorrentes do que para grandes programas de inteligência
Ideal para: startups, pequenas empresas e desenvolvedores testando casos de uso mais leves de coleta de páginas públicas.
Sinal de preço: há plano gratuito; a página pública atual começa os planos pagos em cerca de .
6. PhantomBuster
trata menos de infraestrutura bruta de scraping e mais do que acontece depois da coleta. Se o seu caso de uso é “coletar os dados e depois disparar outreach, enriquecimento ou ações de acompanhamento”, o PhantomBuster costuma ser mais útil do que um simples extrator, porque foi desenhado em torno de automações em nuvem e fluxos de ação no navegador.
Por que as equipas ainda o colocam na shortlist:
- Fluxos de automação baseados em nuvem
- Útil para geração de leads e operações de GTM
- Melhor encaixe quando o scraping é apenas uma etapa de um processo maior
- Prático para operadores que se importam com ações, não só exportações
Ideal para: equipas de GTM, growth, recrutadores e operadores que encadeiam a coleta com ações posteriores.
Sinal de preço: teste gratuito disponível; os planos pagos na página atual de preços começam em cerca de .
7. Octoparse
continua a ser uma das melhores ferramentas visuais sem código para quem quer fluxos repetíveis e execuções em nuvem agendadas. Ela não é tão leve quanto a Thunderbit para trabalhos rápidos e pontuais no Facebook, mas oferece aos não desenvolvedores um controlo mais explícito sobre como a lógica de extração é construída e repetida.
Por que continua relevante:
- Construtor visual ponto a ponto
- Extração em nuvem e agendamento
- Boa para tarefas estruturadas e repetidas
- Mais adequada para analistas que querem repetibilidade sem código
Ideal para: analistas sem perfil técnico, equipas de operações de PMEs e tarefas repetitivas de coleta com lógica de fluxo mais explícita.
Sinal de preço: a página pública de preços da Octoparse lista planos pagos a partir de cerca de .
Lista curta por equipe
Se você já sabe que tipo de equipa vai assumir o fluxo, comece aqui:
- Operador solo ou pequena empresa: Thunderbit, ScrapingBot ou Octoparse
- Equipe de vendas / GTM: Thunderbit ou PhantomBuster
- Analista de operações: Thunderbit, Apify ou Octoparse
- Equipe de automação de growth: PhantomBuster ou Apify
- Equipe de engenharia de dados: Bright Data, Nimble ou Apify

Como escolher o extrator de dados do Facebook certo
- Escolha Thunderbit se velocidade e simplicidade importam mais do que escala máxima.
- Escolha Bright Data se você precisa de escala de dados públicos e confiabilidade gerenciada.
- Escolha Apify se quiser flexibilidade de plataforma e fluxos baseados em actors.
- Escolha Nimble se quiser uma camada de abstração API-first com menos manutenção de scraper.
- Escolha PhantomBuster se o scraping for apenas uma etapa de um fluxo maior de automação de GTM.
- Escolha Octoparse se quiser repetibilidade visual sem código.
- Escolha ScrapingBot se o orçamento importar e o trabalho for relativamente simples.
Conclusão
A divisão do mercado está mais clara em 2026 do que estava há um ano. Você não está realmente escolhendo um único “melhor extrator de Facebook” universal. Está escolhendo um modelo de coleta: extração rápida sem código, escala gerenciada por API, automação em nuvem ou controlo visual prático do fluxo. Comece por aí e a lista curta fica muito mais fácil.
Se a sua equipa quer o caminho mais rápido de uma página do Facebook ou de um anúncio do Marketplace até dados estruturados úteis, a Thunderbit ainda é o lugar mais fácil para começar. Se o volume ou os requisitos de engenharia forem bem maiores, Bright Data, Apify e Nimble fazem mais sentido. Se o seu fluxo começa com scraping, mas termina em ações de acompanhamento, PhantomBuster é a shortlist mais inteligente.
Perguntas frequentes
1. Qual é a ferramenta mais fácil para extrair dados do Facebook para usuários sem perfil técnico?
A Thunderbit é o ponto de partida mais fácil para a maioria dos usuários sem perfil técnico, porque funciona no navegador, sugere campos automaticamente e exporta dados rapidamente sem código.
2. Qual ferramenta de extração do Facebook é melhor para coleta de dados públicos em grande escala?
A Bright Data é a opção de infraestrutura mais forte desta lista quando o trabalho é coleta de dados sociais públicos em grande escala e a confiabilidade importa mais do que a facilidade de uso.
3. E se eu precisar de scraping com mais automação de acompanhamento?
O PhantomBuster é a melhor opção quando a coleta de dados é apenas uma etapa num fluxo maior de geração de leads ou de GTM.
4. Extrair dados do Facebook ainda é difícil em 2026?
Sim. Conteúdo dinâmico, barreiras de login, limites de taxa, sistemas anti-bot e riscos à conta ainda tornam o Facebook mais difícil do que sites públicos mais simples.
5. Como as equipas devem pensar sobre compliance?
Mantenha o foco em dados públicos, use taxas razoáveis, evite abuso de credenciais e reveja os termos da plataforma e as regras de privacidade aplicáveis antes de escalar um fluxo.
Leituras adicionais: