Depois de fazer mais de mil raspagens com o Simplescraper, parei de contar sucessos e comecei a catalogar falhas. Essa mudança — de “funcionou?” para “por que quebrou desta vez?” — me ensinou mais do que qualquer página de documentação jamais poderia.
Simplescraper é uma extensão sólida do Chrome para extrair dados de sites sem escrever código. Com na Chrome Web Store e uma interface ponto a ponto realmente acessível, ele conquistou seu espaço no kit de ferramentas de raspagem sem código. Mas aqui vai o que ninguém conta na landing page: conseguir resultados consistentes e confiáveis em escala exige entender onde os raspadores visuais se tornam frágeis. Uma que os trabalhadores passam mais de nove horas por semana em entrada repetitiva de dados — exatamente o tipo de dor que leva as pessoas a ferramentas como o Simplescraper. Mas, se você não conhece as particularidades da ferramenta, vai gastar essas nove horas depurando problemas em vez de fazer algo útil. Este artigo cobre as cinco melhores práticas que sintetizei com base em experiência operacional real: resolver falhas de seleção, escolher o modo de raspagem certo, aproveitar ao máximo o plano gratuito, evitar bloqueios e saber quando seguir em frente.

O que é o Simplescraper (e por que as melhores práticas importam)
O Simplescraper é uma extensão do Chrome que permite selecionar visualmente elementos em uma página da web — títulos de produtos, preços, imagens, informações de contato — e extraí-los como dados estruturados sem escrever uma linha de código. Você aponta, clica e ele monta uma “receita” que pode ser reutilizada em páginas semelhantes.
O modelo central funciona assim:
- Seleção visual de elementos: clique no que você quer. O Simplescraper detecta automaticamente padrões repetitivos (listas de produtos, resultados de busca, vagas de emprego).
- Receitas: salve sua configuração de extração para reutilizar depois ou executar em lotes de URLs.
- Dois modos de raspagem: Browser (local, roda no seu Chrome) e Cloud (roda nos servidores do Simplescraper, sem supervisão).
- Integrações: exporte para Google Sheets, Airtable, webhooks, Zapier, Make, CSV e JSON.
- Extração com IA: um recurso mais recente, o , que gera seletores CSS a partir de um prompt de esquema.
O público-alvo é amplo — profissionais de marketing, equipes de vendas, operações de e-commerce, pesquisadores — qualquer pessoa que precise extrair dados estruturados de sites sem contratar um desenvolvedor. E, para páginas simples, o Simplescraper entrega rápido.
Então por que as melhores práticas importam? Porque, no momento em que você sai de uma listagem simples de produtos ou de um diretório bem organizado, a fricção aparece. Conteúdo dinâmico, medidas anti-bot, imagens carregadas sob demanda, estruturas HTML aninhadas — são essas condições do mundo real que separam uma experiência frustrante de uma produtiva. Saber a abordagem certa desde o início economiza horas de tentativa e erro.
Melhor prática 1: o que fazer quando o Simplescraper falha ao selecionar elementos
Essa é, de longe, a frustração mais comum que já vi. Você clica em um elemento, o Simplescraper o destaca, você fica animado — e então a saída vem sem metade dos dados. As fotos ficam em branco. As biografias desaparecem. As localizações somem.
O próprio fundador que “o elemento/seletor CSS ainda não é 100%”. Essa honestidade é refrescante, mas não resolve sua raspagem quebrada às 23h de uma quarta-feira.
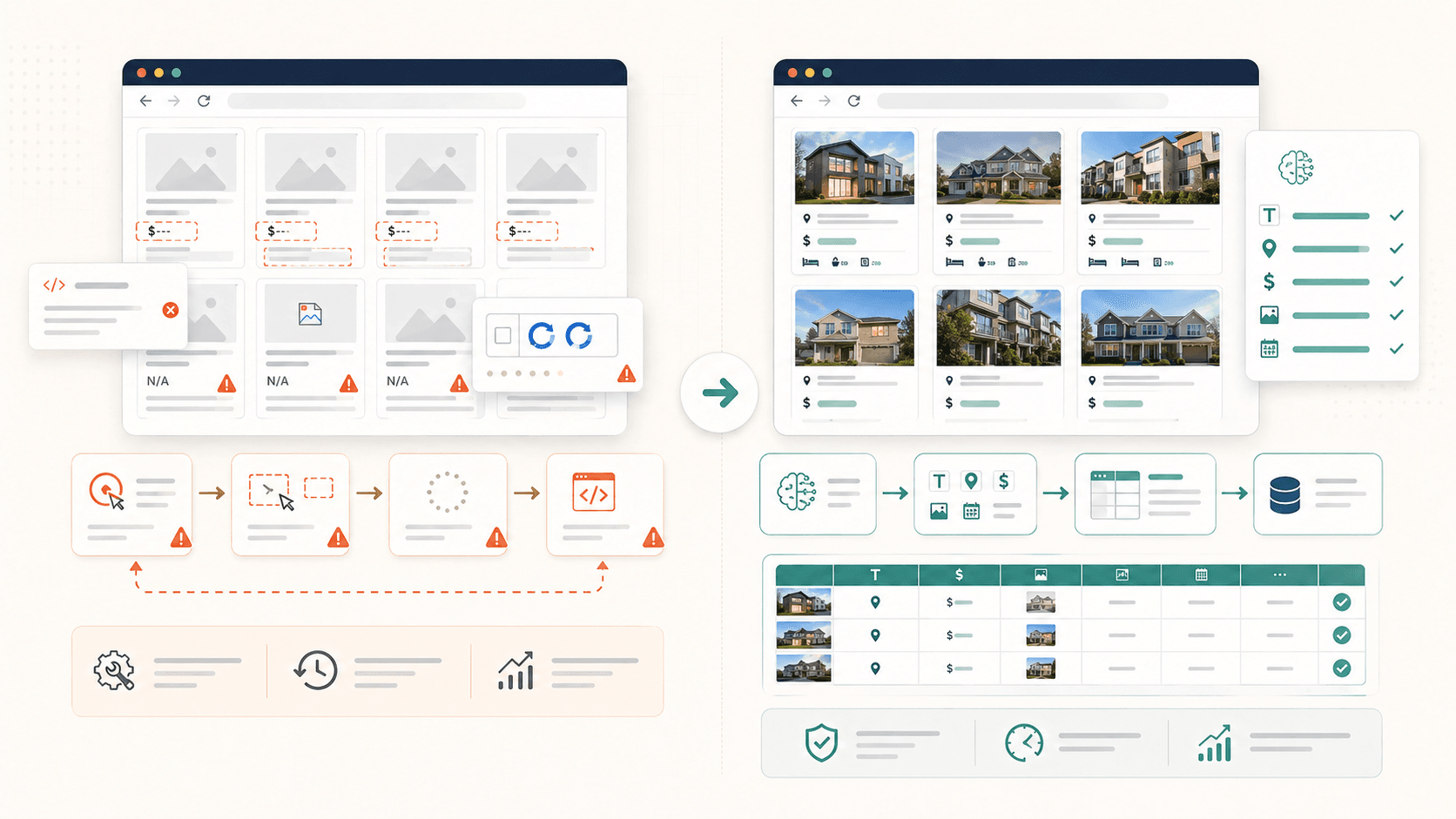
Falhas comuns de seleção (e por que acontecem)
Quatro padrões derrubam o Simplescraper com mais frequência:
- Imagens carregadas sob demanda: o elemento de imagem literalmente até você rolar até ele. Se você raspar antes de rolar, recebe campos de imagem vazios.
- Contêineres aninhados ou agrupados: a detecção automática do Simplescraper , o que às vezes significa capturar apenas uma seção da página em vez do conjunto repetido inteiro. Usuários relatam tabelas que “não selecionam todas as linhas de uma vez”.
- Conteúdo dinâmico em JavaScript: elementos renderizados depois do carregamento inicial da página via React, Vue ou chamadas AJAX simplesmente não estão lá quando o raspador age cedo demais.
- Paginação por rolagem infinita: os dados que você quer ainda não foram carregados no HTML porque exigem rolagem ou clique em “carregar mais”.
Passos práticos de solução de problemas
Antes de recorrer a seletores manuais, tente isto:
- Role a página inteira primeiro. Isso força imagens e conteúdo carregados sob demanda a entrar no DOM.
- Use “Include Similar” quando a contagem da lista parecer suspeitamente baixa. A própria documentação do Simplescraper recomenda isso para conteúdo agrupado.
- Aguarde a renderização completa da página em sites com muito JavaScript. Dê alguns segundos extras antes de disparar a raspagem.
- Comece com uma amostra pequena. Confirme a contagem de linhas em 2 ou 3 páginas antes de partir para um lote de 500.
Mudando para seletores CSS manuais
Quando a seleção visual continua falhando, é hora de ir para o manual. Esse é o movimento avançado que separa usuários casuais de usuários realmente eficientes.
O fluxo é este:
- Clique com o botão direito no elemento desejado no Chrome → Inspecionar.
- No DevTools, identifique a classe ou o atributo de dados do elemento (por exemplo,
.product-card .priceou[data-test="location"]). - No Simplescraper, vá para a aba e cole o seletor.
- Teste o seletor executando uma raspagem pequena.
Dicas para seletores robustos:
- Prefira nomes de classe (
.listing-title) em vez de seletores posicionais (div:nth-child(3)) - Use quando disponíveis — eles costumam ser mais estáveis entre atualizações do site
- Evite caminhos profundamente aninhados que quebram quando a estrutura HTML muda
A alternativa com IA: deixe o Thunderbit detectar os campos automaticamente
Vou ser direto — minha equipe construiu o justamente porque estava cansada desse problema exato. O “AI Suggest Fields” do Thunderbit lê a estrutura da página e recomenda colunas e lógica de extração automaticamente. Não é preciso saber CSS. A IA se adapta ao layout de cada site, inclusive a conteúdo aninhado e imagens carregadas sob demanda.
Se você passa mais do que alguns minutos por raspagem depurando seletores, vale a pena tentar uma abordagem totalmente diferente.
Melhor prática 2: escolhendo entre raspagem na nuvem e no navegador
A maioria dos usuários do Simplescraper escolhe um modo por padrão — normalmente o primeiro que testou — sem pensar em qual modo realmente combina com o caso de uso. Isso causa falhas que poderiam ser evitadas.
Quando usar raspagem no navegador (local)
- Páginas que exigem login: LinkedIn, painéis de CRM, ferramentas internas — qualquer coisa atrás de autenticação precisa da sua sessão ativa no navegador.
- Extrações rápidas e pontuais: você já está na página e só quer os dados agora.
- Preservar créditos gratuitos: a raspagem no navegador não consome créditos da nuvem.
A desvantagem: seu computador precisa permanecer ligado, e trabalhos grandes ficam muito mais lentos do que na nuvem.
Quando usar raspagem na nuvem
- Páginas públicas (listas de e-commerce, diretórios, sites imobiliários) em que não é necessário login.
- Monitoramento agendado: executa de forma autônoma em base recorrente.
- Lotes grandes: em um único lote na nuvem.
- Entrega para integrações: envio automático para Google Sheets, Airtable ou webhooks.
A desvantagem: a raspagem na nuvem — 2 por página com JavaScript e 1 por página sem JavaScript — e esgota rápido a cota de 100 créditos do plano gratuito.
Estrutura de decisão
| Cenário | Modo recomendado | Por quê | Risco se escolher errado |
|---|---|---|---|
| Páginas que exigem login (LinkedIn, painéis) | Navegador | Precisa da sessão autenticada | O modo na nuvem encontra barreiras de login |
| Listagens públicas de produtos em e-commerce | Nuvem | Mais rápido, roda sem supervisão | O modo no navegador prende sua máquina |
| Monitoramento recorrente agendado | Nuvem | Roda sem você | O navegador exige sua presença |
| Sites com forte anti-bot (Amazon, Yelp) | Navegador (como alternativa) ou nuvem com proxy | É preciso rotação de IP ou reutilização de sessão | A nuvem sem proxy é bloqueada rapidamente |
| Extração rápida e pontual | Navegador | Imediato, sem custo de créditos | Configurar a nuvem para uma única página é exagero |

Como o Thunderbit simplifica isso
No , a escolha é apenas um alternador dentro da mesma interface. O modo na nuvem processa até 50 páginas simultaneamente — sem tier pago separado para acesso à nuvem. O modo navegador lida com sites que exigem login sem configuração extra. O peso mental de “qual modo eu preciso?” cai bastante quando os dois modos vivem no mesmo fluxo de trabalho.
Melhor prática 3: aproveitando ao máximo o plano gratuito do Simplescraper
A confusão com preços é real. Já vi posts em fóruns em que as pessoas assumem que “extensão gratuita do Chrome” significa “tudo grátis”. Não é assim. E, no outro extremo, já vi gente achar que o Simplescraper é caro porque os planos pagos não aparecem com destaque. Nenhuma dessas suposições ajuda.
O que o plano gratuito do Simplescraper realmente inclui
De acordo com os :
- Raspagem no navegador: ilimitada (executa localmente no seu Chrome)
- Créditos na nuvem: 100 por mês
- Receitas salvas: 3
- Formatos de exportação: CSV e JSON
- O que NÃO está incluído: suporte prioritário, opções avançadas de proxy, maior quantidade de créditos na nuvem
Um cenário realista do plano gratuito
Suponha que você precise raspar 50 páginas de produto de um site público de e-commerce.
- Modo navegador (gratuito): você consegue fazer tudo sem pagar nada. Abra cada página (ou use uma lista), execute a receita e exporte para CSV. Tempo necessário: depende da sua paciência e da velocidade da internet, mas espere 15 a 30 minutos de trabalho ativo para 50 páginas com navegação manual.
- Modo nuvem (plano gratuito): com a renderização de JavaScript ativada, cada página custa 2 créditos. 50 páginas = 100 créditos. Isso consome toda a sua cota mensal de nuvem em um único trabalho. Sem agendamento, sem tentativas automáticas se algo falhar.
O plano gratuito é realmente útil para raspagens pequenas e ocasionais. Mas ele acaba rápido assim que você precisa de automação na nuvem ou escala.
Comparação do plano gratuito: Simplescraper vs. Thunderbit
| Recurso | Simplescraper grátis | Thunderbit grátis |
|---|---|---|
| Páginas/créditos | Navegador ilimitado + 100 créditos na nuvem | 6 páginas com recursos completos de IA |
| Extração com IA | Limitada (o Smart Extract usa créditos) | Inclui o AI Suggest Fields completo |
| Destinos de exportação | CSV, JSON | Excel, Google Sheets, Airtable, Notion — tudo grátis |
| Configurações salvas | 3 receitas | Modelos disponíveis |
| Raspagem de subpáginas | Configuração manual da receita | Incluída na contagem de páginas |
Os modelos são realmente diferentes. O Simplescraper oferece raspagem local ilimitada com nuvem limitada. O oferece menos páginas, mas entrega capacidade total de IA em cada uma, além de exportações gratuitas para as ferramentas que a maioria das equipes realmente usa. O plano gratuito do Simplescraper funciona se você precisa de raspagem local básica e aceita trabalho manual. Mas, se você quer extração com IA e exportações flexíveis, o plano gratuito do Thunderbit rende mais por página.
Melhor prática 4: como evitar bloqueios durante a raspagem
Ninguém pensa em medidas anti-bot até encarar uma barreira de CAPTCHA ou um conjunto de dados vazio. Quando isso acontece, você já gastou tempo — e, possivelmente, créditos.
Defesa proativa é sempre mais barata do que depuração reativa.
Defina limites de taxa e controle o ritmo das requisições
A principal razão para ser bloqueado: bombardear um site com requisições em sequência rápida. Para um servidor web, 50 requisições em 10 segundos vindas de um único IP parecem um ataque, não a ação de um pesquisador curioso.
Regras gerais:
- Adicione de 2 a 5 segundos entre as requisições de página na maioria dos sites comerciais.
- Para alvos sensíveis (marketplaces, sites de avaliações), vá mais devagar — 5 a 10 segundos.
- Se estiver usando a API do Simplescraper, o parâmetro pode ajudar a garantir que as páginas carreguem totalmente antes da extração, o que também desacelera naturalmente o ritmo.
Quando ativar rotação de proxy
A rotação de proxy troca seu endereço IP entre as requisições, fazendo você parecer vários usuários diferentes. Você vai precisar disso para:
- Amazon, Yelp, TripAdvisor, LinkedIn (sistemas anti-bot agressivos)
- Qualquer site que limite taxa por IP
- Trabalhos grandes em lote (centenas de páginas de um mesmo domínio)
A plataforma do Simplescraper , incluindo opções padrão, premium e residencial. Porém, a disponibilidade exata por plano nem sempre fica cristalina na documentação pública — verifique antes de presumir que o plano gratuito cobre alvos difíceis. Proxies residenciais geralmente custam mais, mas têm menor chance de serem sinalizados.
Lidando com sites intensivos em JavaScript
Sites modernos construídos com React, Vue ou Angular renderizam conteúdo depois do carregamento inicial da página. Se o seu raspador agir antes de o JavaScript terminar de executar, você recebe campos vazios.
Estratégias:
- Use o modo de raspagem na nuvem para uma renderização melhor (a nuvem do Simplescraper pode executar JavaScript).
- Role manualmente a página antes de executar uma raspagem no navegador para disparar conteúdo carregado sob demanda.
- Use
waitForSelectorem fluxos baseados em API para pausar até que os elementos-alvo apareçam. - Aceite que alguns aplicativos de página única altamente dinâmicos simplesmente podem estar além do que um raspador visual consegue lidar com confiabilidade.
A alternativa sem intervenção
A lida automaticamente com proteção anti-bot, CAPTCHAs e renderização JavaScript — sem configuração de proxy, sem ajuste de atrasos, sem rolagem manual. Para usuários que não querem virar engenheiros de DevOps amadores só para raspar um catálogo de produtos, isso faz diferença. Os problemas não desaparecem — eles só passam a ser problema de outra pessoa.
Melhor prática 5: saiba quando o Simplescraper chegou ao limite
Eu queria que alguém tivesse escrito esta seção para mim há dois anos.
Chega um ponto em que a ferramenta deixa de economizar tempo e começa a consumi-lo. Reconhecer esse limite cedo evita a armadilha do custo irrecuperável de “já montei 15 receitas, agora não posso trocar”.
Limites práticos do Simplescraper
- Aplicativos de página única dinâmicos que carregam conteúdo via AJAX sem navegação tradicional entre páginas
- Rolagem infinita que exige rolagem contínua para carregar todos os itens (e não paginação padrão por clique)
- Enriquecimento de subpáginas: raspar uma página de listagem e depois visitar cada página de detalhe para obter dados adicionais. O Simplescraper consegue fazer isso com , mas a complexidade da configuração cresce rápido.
- Mudanças de layout que quebram receitas existentes. Quando um site atualiza sua estrutura HTML, seus seletores CSS cuidadosamente ajustados param de funcionar.
Sinais de que a ferramenta já ficou pequena para você
Você provavelmente bateu no teto quando:
- Está ajustando manualmente seletores CSS em toda raspagem porque a detecção automática continua falhando
- As receitas quebram após atualizações do site e precisam ser reconstruídas
- Você precisa raspar dezenas ou centenas de páginas ao mesmo tempo, mas continua esbarrando em limites de créditos ou velocidade
- Os dados de subpáginas exigem cadeias complexas de receitas em várias etapas
- Você passa mais tempo mantendo raspagens do que realmente usando os dados extraídos
Esse último é o sinal mais claro. Quando a manutenção vira o trabalho, o benefício da praticidade sem código desaparece.
Migrando para um fluxo de trabalho com IA
É aqui que vou falar sobre o que minha equipe construiu com o , porque ele foi desenhado especificamente para os modos de falha descritos acima:

- A IA lê cada página do zero a cada execução — sem receitas frágeis ou seletores CSS para manter. Se um site mudar o layout, a IA se adapta na próxima execução.
- A raspagem de subpáginas enriquece sua tabela de dados com um clique. Raspe uma listagem e depois visite automaticamente cada página de detalhe para campos adicionais.
- Raspagem agendada usando linguagem natural (“toda segunda-feira às 9h”) em vez de configurar predefinições de tempo.
- Raspagem na nuvem com 50 páginas simultâneas para mais velocidade em sites públicos.
- Exportações nativas e gratuitas para Google Sheets, Airtable, Notion e Excel, sem configuração de webhook.
Simplescraper vs. Thunderbit: comparação lado a lado
Aqui está tudo em um só lugar:

| Capacidade | Simplescraper | Thunderbit |
|---|---|---|
| Configuração de campos | Seletores CSS manuais / seleção visual | AI Suggest Fields (inglês simples) |
| Enriquecimento de subpáginas | Possível via fluxos em lote (configuração complexa) | Autoenriquecimento com 1 clique |
| Adaptação automática a mudanças de layout | Quebra (requer correção manual) | A IA relê a estrutura da página a cada execução |
| Concorrência de páginas na nuvem | Lote de até 5.000 URLs (varia por plano) | 50 páginas simultaneamente |
| Exportação para Notion/Airtable | Via webhook (planos pagos) | Nativa, grátis |
| Agendamento | Controles de tempo predefinidos + personalizados | Descrição em linguagem natural |
| Anti-bot / CAPTCHA | Modos de proxy disponíveis (dependente do plano) | Automático, sem configuração |
| Plano gratuito | 100 créditos na nuvem + navegador ilimitado + 3 receitas | 6 páginas com recursos completos de IA + exportações grátis |
Em resumo: o Simplescraper brilha em extração simples, visual e com pouca configuração, em que pequenos ajustes manuais ocasionais são aceitáveis. O Thunderbit entra justamente onde esse modelo começa a falhar — lidando com interpretação da página, adaptação de layout e complexidade de fluxo para que você não precise fazer isso.
Nenhuma ferramenta é universalmente melhor. Elas ocupam pontos diferentes na curva de complexidade — e tudo bem.
Referência rápida: checklist de melhores práticas do Simplescraper
Salve isto para sua próxima sessão de raspagem:
- Sempre teste primeiro em uma amostra pequena. Confirme a contagem de linhas e a completude dos campos em 2 ou 3 páginas antes de escalar.
- Role a página antes de raspar para disparar conteúdo carregado sob demanda.
- Use “Include Similar” quando a detecção de listas parecer estreita demais.
- Escolha o modo de raspagem de forma deliberada. Navegador para sites que exigem login; nuvem para páginas públicas e tarefas agendadas.
- Defina atrasos entre requisições — mínimo de 2 a 5 segundos em sites comerciais, mais em alvos com forte anti-bot.
- Entenda a matemática do plano gratuito. 100 créditos na nuvem = 50 páginas com JavaScript. Planeje-se de acordo.
- Salve receitas apenas para páginas estáveis. Se um site muda com frequência, as receitas vão quebrar.
- Aprenda o básico de seletores CSS como plano de contingência. Nomes de classe e atributos de dados são melhores do que seletores posicionais.
- Monitore bloqueios de forma proativa. Se estiver recebendo resultados vazios ou CAPTCHAs, desacelere ou troque de modo.
- Reconheça o limite. Quando o tempo de manutenção ultrapassa o tempo de uso dos dados, avalie alternativas.
Conclusão: faça cada raspagem valer
A grande lição de mais de mil raspagens não tem a ver com uma ferramenta específica. É que a abordagem importa mais do que o software. Entender por que uma raspagem falha — carregamento sob demanda, modo errado, anti-bot agressivo, seletores frágeis — vale mais do que qualquer lista de recursos.
O Simplescraper realmente funciona bem para trabalhos de extração diretos. Se suas páginas são limpas, suas necessidades são modestas e você não se importa com ajustes manuais ocasionais, ele entrega.
Mas, se você começa a lutar contra a ferramenta em vez de usá-la — depurando seletores, reconstruindo receitas quebradas, configurando proxies, rolando páginas manualmente — isso é um sinal, não uma falha pessoal. Significa que você já passou do que a raspagem visual sozinha consegue lidar.
Se isso soa familiar, experimente o — seis páginas com recursos completos de IA, exportações gratuitas para Sheets, Airtable e Notion. Compare com seu fluxo atual e veja o que funciona melhor. Às vezes, a melhor prática é saber quando recorrer totalmente a outra ferramenta.
FAQs
O Simplescraper é gratuito?
Sim, o Simplescraper tem um plano gratuito que inclui raspagem local ilimitada no navegador, , 3 receitas salvas e exportação em CSV/JSON. Páginas na nuvem com JavaScript custam 2 créditos cada, então esses 100 créditos cobrem cerca de 50 páginas no modo nuvem. Os planos pagos começam em US$ 39/mês (Plus) para 6.000 créditos e US$ 70/mês (Pro) para 15.000 créditos.
O Simplescraper consegue lidar com sites pesados em JavaScript?
Às vezes. O modo nuvem do Simplescraper pode renderizar JavaScript, e a ferramenta anuncia suporte para aplicativos de página única. No entanto, SPAs complexos com renderização dinâmica intensa, rolagem infinita ou sistemas anti-bot agressivos ainda podem gerar resultados incompletos. Usar o modo nuvem com tempos de espera adequados melhora a confiabilidade, mas sites muito dinâmicos continuam sendo um desafio para qualquer raspador visual.
Qual é a diferença entre raspagem na nuvem e no navegador no Simplescraper?
A raspagem no navegador roda localmente no seu navegador Chrome — usa sua sessão ativa (ótimo para sites que exigem login), não custa créditos, mas exige que seu computador fique ligado. A roda nos servidores do Simplescraper — é mais rápida, funciona sem supervisão, oferece agendamento e integrações, mas custa créditos por página e não consegue acessar páginas atrás do seu login pessoal.
Quando devo mudar do Simplescraper para uma alternativa como o Thunderbit?
O sinal mais claro é quando o tempo de manutenção ultrapassa o tempo de uso dos dados. Se você está corrigindo seletores quebrados após atualizações de sites, configurando proxies manualmente, reconstruindo receitas ou gastando mais tempo depurando do que analisando os dados extraídos, você já passou do que a raspagem visual manual consegue oferecer de forma eficiente. Ferramentas como o usam IA para interpretar a estrutura da página a cada execução e eliminam a maior parte desse fardo de manutenção.
Como evitar bloqueios ao raspar com o Simplescraper?
Três práticas principais: primeiro, controle o ritmo das requisições com atrasos de 2 a 5 segundos entre páginas (mais para sites com forte anti-bot, como Amazon ou Yelp). Segundo, use o modo navegador como alternativa para sites que bloqueiam agressivamente IPs da nuvem — sua sessão no navegador parece tráfego mais normal. Terceiro, ative a rotação de proxy para lotes grandes em alvos sensíveis, mas verifique quais opções de proxy seu plano inclui antes de depender delas.
Saiba mais