

Deixe-me voltar ao momento em que tentei, pela primeira vez, extrair dados de produtos de um site de e-commerce. Eu estava armado com Python, uma xícara de café e um sonho: criar um rastreador de preços para a Amazon. Algumas horas depois, meu “projeto rápido” tinha virado um emaranhado de seletores XPath, dores de cabeça com paginação e mais depuração do que eu gostaria de admitir. Se você já tentou domar dados da web com código, provavelmente conhece a sensação — uma mistura igual de empolgação e “por que isso é tão complicado?”
A questão é a seguinte: web scraping já não é mais coisa só de cientistas de dados ou engenheiros. Tornou-se uma habilidade indispensável para equipes de vendas, gestores de e-commerce, profissionais de marketing e qualquer pessoa que queira transformar o caos da web em inteligência de negócios. Na verdade, o mercado de software de web scraping alcançou US$ 1,01 bilhão em 2024 e a projeção é chegar a US$ 2,49 bilhões até 2032, e a curva não está desacelerando. Mas, embora Python e frameworks como o Scrapy continuem sendo o padrão ouro para scraping customizado em larga escala, eles não são exatamente amigáveis para iniciantes. Por isso, neste tutorial, vou te guiar pelo Scrapy passo a passo — usando um caso real com a Amazon — e mostrar uma alternativa muito mais fácil, com IA, para quem não programa: Thunderbit.
O que é Scrapy Python? Sua ferramenta de peso para web scraping
Comecemos pelo básico. Scrapy é um framework open source em Python criado especificamente para crawling e scraping de sites. Pense nele como uma caixa de ferramentas completa para criar spiders personalizados (é assim que o Scrapy chama seus rastreadores) que conseguem navegar por sites, seguir links, lidar com paginação e extrair dados estruturados em grande escala.
Em que o Scrapy difere de usar apenas requests e BeautifulSoup no Python? Bem, embora essas bibliotecas sejam ótimas para extrações simples e pontuais, o Scrapy foi pensado para projetos grandes e complexos — aqueles em que você precisa:
- Rastrear milhares de páginas (pense em todos os produtos de um catálogo de e-commerce)
- Seguir links e lidar com paginação automaticamente
- Processar dados de forma assíncrona para ganhar velocidade
- Estruturar, limpar e exportar dados de maneira repetível
Em resumo, o Scrapy é como um canivete suíço para web scraping — poderoso, flexível e, para o bem ou para o mal, um pouco intimidador para quem está começando.
Por que usar Scrapy Python para web scraping?
Então, por que desenvolvedores e equipes de dados continuam recorrendo ao Scrapy? Aqui vai um resumo rápido do que faz ele se destacar:
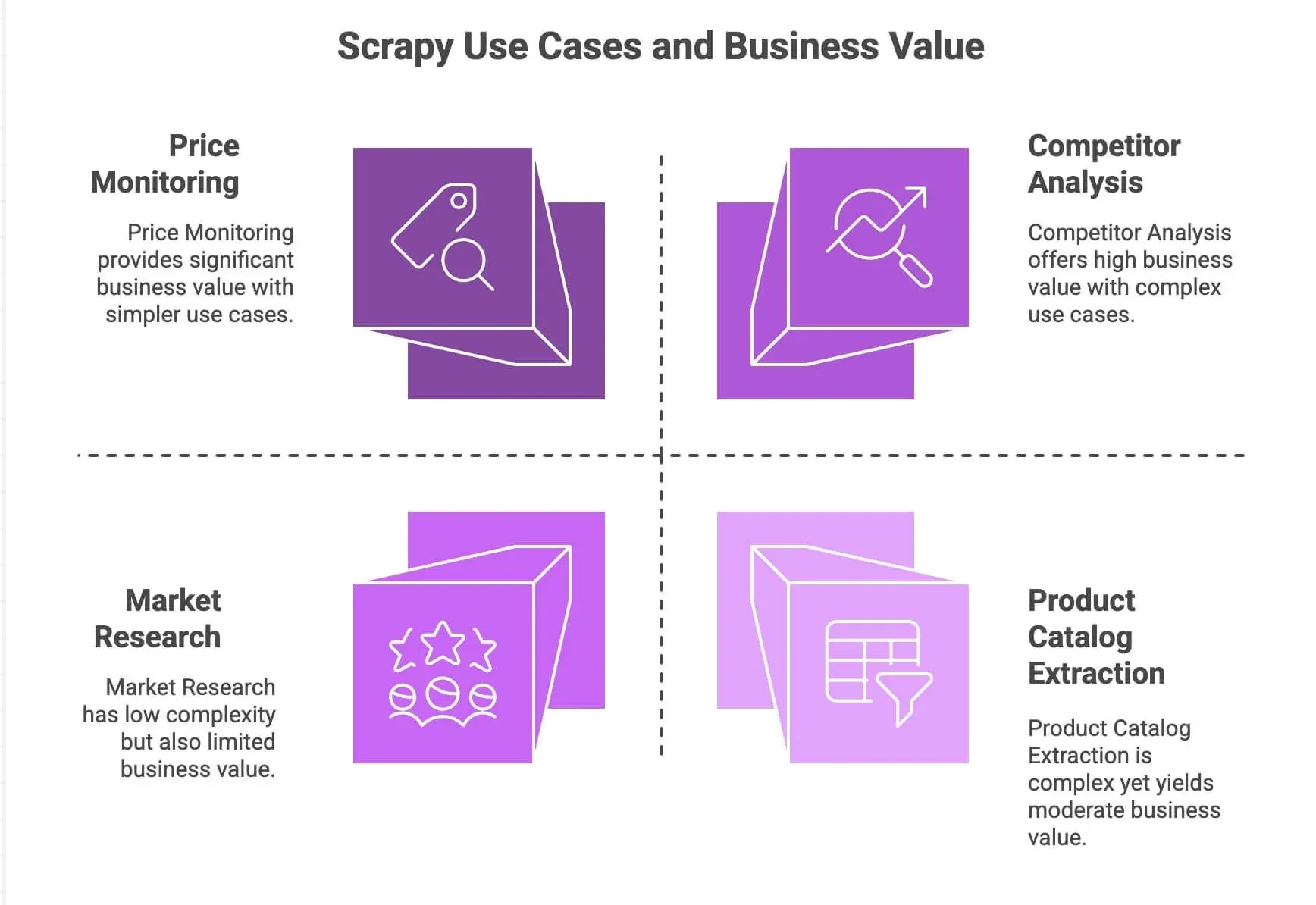
| Caso de uso | Pontos fortes do Scrapy | Valor para o negócio |
|---|---|---|
| Monitoramento de preços | Lida com paginação, requisições assíncronas e agendamento | Fique à frente da concorrência, pratique precificação dinâmica |
| Extração de catálogo de produtos | Segue links, extrai dados estruturados | Monte bases de produtos e abasteça análises |
| Análise da concorrência | Escalável, robusto diante de mudanças no site | Acompanhe tendências, lançamentos e níveis de estoque |
| Pesquisa de mercado | Pipelines modulares para limpar e transformar dados | Agregue avaliações e faça análise de sentimento |
O motor assíncrono do Scrapy (baseado no Twisted) permite buscar várias páginas em paralelo, o que o torna rápido e escalável. Seu design modular permite plugar lógica personalizada, como proxies, user-agents ou etapas de limpeza de dados. E, com pipelines, você pode processar, validar e exportar os dados do jeito que quiser — CSV, JSON, bancos de dados, o que for.
Para equipes com conhecimento em Python, o Scrapy é uma potência. Mas vamos ser sinceros: ele não é exatamente “plug and play” para o usuário de negócios médio.
Configurando seu ambiente de Scrapy Python
Pronto para colocar a mão na massa? Veja como configurar o Scrapy do zero:
1. Instale o Scrapy
Primeiro, verifique se você tem o Python 3.10+ instalado (o Scrapy 2.15.x deixou de oferecer suporte ao 3.9 em 2026). Depois, abra o terminal e execute:
pip install scrapy
Confira a instalação com:
scrapy version
Se você estiver no Windows ou usando Anaconda, talvez valha a pena criar um ambiente virtual para evitar conflitos. O Scrapy funciona no Windows, macOS e Linux.
2. Crie um novo projeto Scrapy
Vamos iniciar um novo projeto chamado amazonscraper:
scrapy startproject amazonscraper
Você vai obter uma estrutura de pastas assim:
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
O que esses arquivos fazem?
scrapy.cfg: configuração do projeto (raramente você mexe nele)items.py: define seus modelos de dados (como um Produto com nome, preço etc.)pipelines.py: onde você limpa, valida e exporta seus dadosmiddlewares.py: recursos avançados (proxies, cabeçalhos personalizados)settings.py: ajusta o comportamento do Scrapy (concorrência, atrasos etc.)spiders/: onde mora a lógica real de scraping
Se você já está se sentindo um pouco sobrecarregado, não está sozinho. É aqui que muita gente sem perfil técnico começa a suar frio.
Criando um Python Scraper: extraindo dados de produtos da Amazon com Scrapy
Vamos ver um exemplo real: extrair dados de produtos dos resultados de busca da Amazon. (Aviso: os termos de uso da Amazon não permitem scraping, e eles usam medidas anti-bot agressivas. Isto é apenas para fins educacionais!)
1. Crie um spider
Dentro da pasta spiders/, crie um arquivo chamado amazon_spider.py:
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
O que está acontecendo aqui?
- Começamos em uma página de resultados de busca da Amazon para “smartphones”.
- Para cada produto, extraímos nome, preço e avaliação usando seletores XPath.
- Procuramos o link da “próxima página” e pedimos ao Scrapy que o siga, coletando mais produtos.
2. Execute seu spider
Na raiz do projeto, rode:
scrapy crawl amazon_example -o products.json
Pronto — o Scrapy vai percorrer os resultados, seguir a paginação e salvar os dados em um arquivo JSON.
Lidando com paginação e conteúdo dinâmico
O suporte nativo do Scrapy para seguir links e lidar com paginação é um dos seus superpoderes. Mas e o conteúdo dinâmico — páginas que carregam dados com JavaScript? Fora da caixa, o Scrapy só enxerga HTML estático. Se você precisar extrair conteúdo carregado por JavaScript (como rolagem infinita ou avaliações em pop-up), terá de integrá-lo com ferramentas como Selenium ou Splash. Isso já é outro buraco de coelho.
Processando e exportando dados com Scrapy Python
Depois de extrair os dados, você provavelmente vai querer limpá-los e exportá-los para algum lugar útil.
- Pipelines: em
pipelines.py, você pode escrever classes em Python para limpar, validar ou enriquecer seus dados (por exemplo, converter preços em números, remover linhas incompletas ou até chamar uma API de tradução). - Exportação: o Scrapy pode exportar diretamente para CSV, JSON ou XML com a flag
o. Para exportações mais avançadas (como enviar para o Google Sheets), você vai precisar escrever código extra ou usar bibliotecas de terceiros.
Quer fazer análise de sentimento ou traduzir descrições de produtos? Vai precisar integrar APIs externas ou bibliotecas Python — nada disso vem pronto.
Os custos ocultos: desafios do Scrapy Python para usuários de negócios
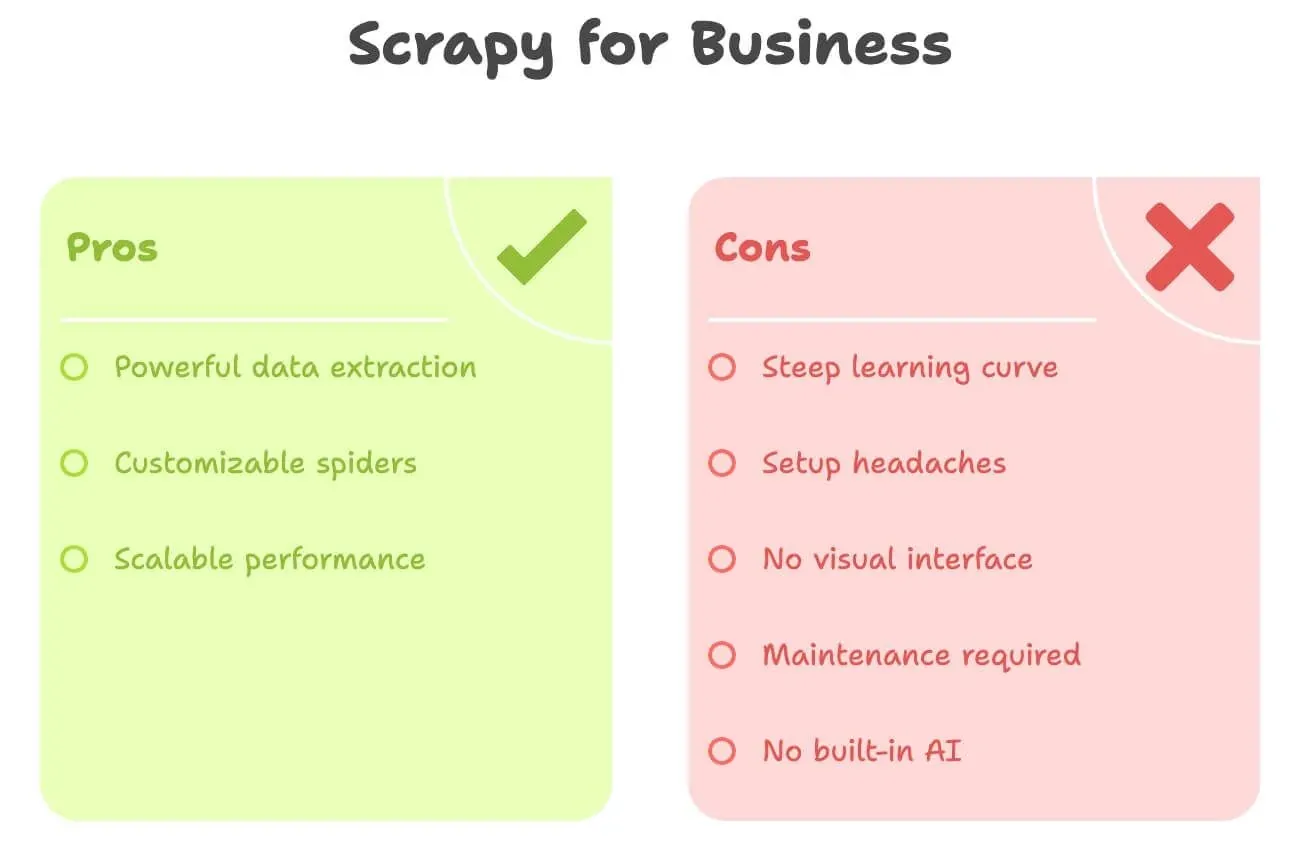
Vamos ser francos: o Scrapy é poderoso, mas não é exatamente amigável para quem não programa. Veja o que mais trava os usuários de negócios:
- Curva de aprendizado íngreme: é preciso conhecer Python, HTML, seletores XPath/CSS e a estrutura de projetos do Scrapy. Pode levar dias ou até semanas para ficar confortável.
- Dor de cabeça na configuração: instalar Python, gerenciar dependências e resolver erros pode ser chato — especialmente no Windows.
- Sem interface visual: tudo é código. Você não pode simplesmente “clicar” numa página para selecionar os dados.
- Manutenção: se o site mudar, seu spider quebra. A responsabilidade de consertar fica com você.
- Sem IA nativa: quer traduzir, resumir ou analisar sentimento? Tudo isso exige código extra.
Aqui vai uma comparação rápida:
| Desafio | Scrapy (Python) | Necessidade do usuário de negócios |
|---|---|---|
| Exige código | Sim | Preferência por sem código |
| Tempo de configuração | Horas (ou dias) | Minutos |
| Manutenção | Contínua (mudanças no site) | Mínima |
| Exportação de dados | CSV/JSON (integração manual) | Direto para Excel/Sheets/Notion |
| Recursos de IA | Nenhum (integração por conta própria) | Tradução/análise de sentimento nativas |
Se você é um profissional de marketing solo, vendedor ou gerente de operações, o Scrapy pode parecer levar uma bazuca para uma guerra de bexigas d’água.
Conheça a Thunderbit: a alternativa sem código ao Scrapy Python
É aqui que a Thunderbit entra. Como alguém que passou anos criando ferramentas de automação, posso dizer: a maioria dos usuários de negócios não quer programar — só quer os dados, e rápido.
A Thunderbit é um raspador web com IA em forma de extensão para o Chrome. Ela foi criada para usuários sem perfil técnico que querem:
- Extrair dados de qualquer site em poucos cliques
- Usar linguagem natural para descrever o que desejam (“Nome do produto, preço, avaliação”)
- Lidar automaticamente com paginação e subpáginas
- Exportar dados diretamente para Excel, Google Sheets, Airtable ou Notion
- Traduzir, resumir ou analisar sentimento na hora
Sem Python. Sem seletores. Sem dor de cabeça com manutenção.
Como extrair dados de qualquer site usando IA Get Started Free
A Thunderbit foi feita para usuários de negócios que querem andar rápido e deixar a IA fazer o trabalho pesado.
Thunderbit vs. Scrapy Python: comparação lado a lado
Vamos colocá-los frente a frente:
| Aspecto | Scrapy (Python) | Thunderbit (ferramenta de IA) |
|---|---|---|
| Habilidade necessária | Python, HTML, seletores | Nenhuma — apontar, clicar e usar linguagem natural |
| Tempo de configuração | Horas (instalar, programar, depurar) | Minutos (instalar extensão do Chrome, entrar) |
| Estruturação dos dados | Manual (definir items, pipelines) | IA detecta colunas automaticamente e sugere campos |
| Paginação/Subpáginas | Exige código | 1 clique (a IA cuida disso) |
| Tradução | Código personalizado ou integração com API | Nativa — basta ativar “Traduzir” |
| Análise de sentimento | Biblioteca/API externa | Nativa — adicione uma coluna “Sentimento” |
| Opções de exportação | CSV/JSON (importação manual para Sheets/Excel) | Exportação com 1 clique para Excel, Google Sheets, Airtable, Notion |
| Manutenção | Manual (atualize o código se o site mudar) | A IA se adapta automaticamente a pequenas mudanças no site |
| Escala | Melhor para projetos grandes e contínuos | Melhor para tarefas rápidas, em escala moderada (centenas ou milhares de linhas) |
| Custo | Grátis (mas consome tempo e recursos de desenvolvimento) | Plano gratuito + planos pagos (a partir de US$ 9/mês, mas economiza muito tempo e dor de cabeça) |
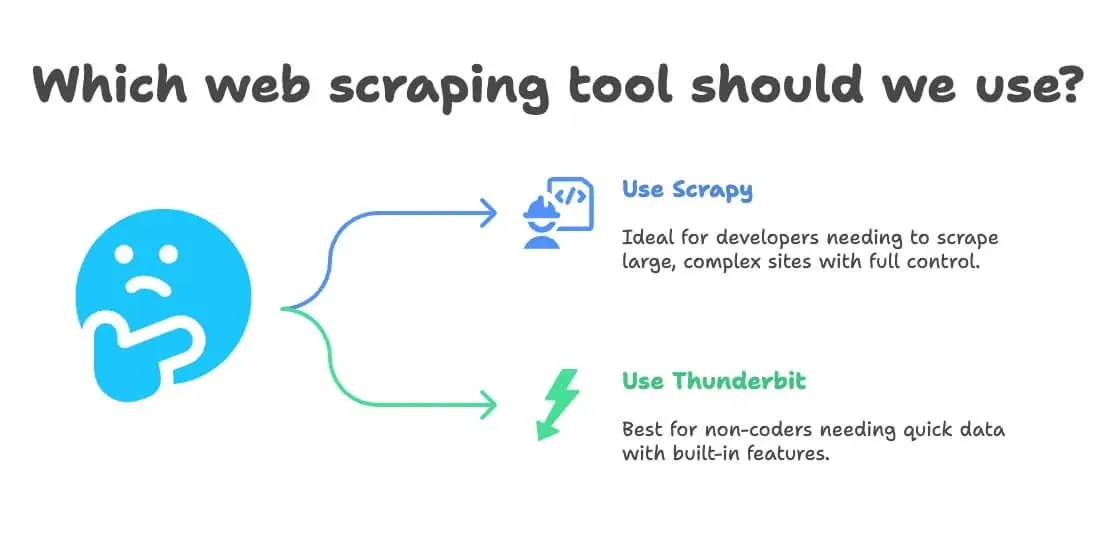
Quando escolher Scrapy Python ou Thunderbit para web scraping
Minha regra prática é esta:
- Use Scrapy se:
- Você é desenvolvedor ou tem um na equipe
- Precisa extrair dezenas de milhares de páginas ou construir um pipeline customizado e contínuo
- O site é muito complexo ou exige lógica avançada
- Você quer controle total (e não se importa com manutenção)
- Use Thunderbit se:
- Você não programa (ou não quer programar)
- Precisa de dados rapidamente, para uma tarefa pontual ou recorrente de negócio
- Quer tradução, sentimento ou enriquecimento de dados nativos
- Valoriza velocidade e flexibilidade mais do que personalização extrema
Aqui vai um fluxo rápido de decisão:
- Você sabe programar em Python?
- Sim → Scrapy ou Thunderbit (para ganhos rápidos)
- Não → Thunderbit
- Seu projeto é grande e contínuo?
- Sim → Scrapy
- Não → Thunderbit
- Você precisa de tradução ou análise de sentimento?
- Sim → Thunderbit
- Não → Tanto faz
Passo a passo: extraindo dados de produtos da Amazon com Thunderbit (sem código)
Vamos refazer nosso exemplo da Amazon — desta vez, do jeito fácil.
1. Instale a Thunderbit
- Baixe a extensão Thunderbit para Chrome
- Crie sua conta (há plano gratuito)
Experimente a extensão da Thunderbit para Chrome grátis
2. Acesse a Amazon e procure seu produto
- Abra Amazon.com e pesquise por “laptops” (ou qualquer produto)
3. Inicie a Thunderbit na página
- Clique no ícone da Thunderbit no navegador
- O painel lateral abre, reconhecendo a página da Amazon
4. Use a sugestão de campos por IA
- Clique em “AI Suggest Fields”
- A IA da Thunderbit analisa a página e sugere colunas como “Nome do produto”, “Preço”, “Avaliação” e “Número de avaliações”
- Adicione ou remova colunas conforme necessário (quer “URL do produto” ou “Elegibilidade para Prime”? É só digitar)
5. Ative a paginação e a extração de subpáginas
- Ative Paginação: a Thunderbit clicará automaticamente em “Next” e extrairá todas as páginas
- Ative Extração de subpáginas: a Thunderbit visitará a página de detalhes de cada produto e coletará informações extras (como descrições ou números ASIN)
6. Execute a extração
- Clique em Extrair
- Veja a Thunderbit coletar os dados em tempo real, página por página
7. Traduza e analise o sentimento (opcional)
- Quer traduzir descrições de produtos? Ative “Traduzir” para essa coluna
- Quer analisar o sentimento das avaliações? Adicione uma coluna “Sentimento” — a IA da Thunderbit vai preencher
8. Exporte seus dados
- Clique em Exportar
- Escolha Excel, Google Sheets, Airtable ou Notion
- Seus dados ficam prontos para uso — sem importação manual, sem dor de cabeça com CSV
9. Programe extrações recorrentes (opcional)
- Configure um agendamento (por exemplo, diariamente às 8h)
- A Thunderbit executará a extração automaticamente e atualizará o destino escolhido
Pronto. Sem código, sem seletores, sem manutenção. Só dados, prontos para o negócio.
Dicas bônus: como aproveitar melhor seus projetos de web scraping
Seja usando Scrapy, Thunderbit ou qualquer outra ferramenta, aqui vão algumas boas práticas que aprendi na marra:
- Valide seus dados: sempre verifique valores ausentes ou estranhos (como preços de $0 ou nomes vazios)
- Mantenha a conformidade: confira os termos de serviço do site, respeite o
robots.txte não sobrecarregue servidores - Automatize com inteligência: use agendamento para manter os dados atualizados, mas não extraia com mais frequência do que o necessário
- Aproveite ferramentas gratuitas: a Thunderbit inclui extratores gratuitos de e-mail, telefone e imagem — ótimos para geração de leads ou curadoria de conteúdo
- Organize para análise: exporte diretamente para Sheets/Excel para filtrar, cruzar e visualizar rapidamente
Para mais dicas, confira o blog da Thunderbit ou o guia para extrair qualquer site usando IA.
Como extrair dados de sites para o Excel usando IA Get Started Free
Para mais dicas, confira o blog da Thunderbit ou o guia para extrair qualquer site usando IA.
Conclusão: web scraping descomplicado — escolha a ferramenta certa para sua equipe
Em resumo: o Scrapy é uma potência para desenvolvedores, mas exagera para a maioria dos usuários de negócios. Se você se sente confortável com Python e precisa criar um scraper customizado e em larga escala, o Scrapy é uma ótima escolha. Mas, se você quer agilidade, dispensar o código e obter dados — com tradução e análise de sentimento já embutidas — a Thunderbit é o caminho certo.
Eu já vi de perto quanto tempo e frustração a Thunderbit economiza para equipes sem perfil técnico. Você sai de “queria ter esses dados” para “eles já estão na minha planilha” em minutos — não em horas ou dias. E, com recursos como AI Suggest Fields, extração de subpáginas e exportação com um clique, nunca foi tão fácil transformar a web em inteligência de negócios.
Então, na próxima vez que precisar extrair dados de produtos, monitorar preços ou montar uma lista de leads, pergunte a si mesmo: você quer escrever Python ou quer resultados? Experimente o plano gratuito da Thunderbit e veja como o web scraping pode ser muito mais simples.
Experimente a Thunderbit grátis
Curioso para saber mais? Confira o site oficial da Thunderbit, baixe a extensão do Chrome ou aprofunde-se nas melhores práticas de web scraping no blog da Thunderbit.
Leituras adicionais:
- O que é data scraping e como fazer isso em 2026
- Como extrair dados de sites para o Excel usando IA
- As melhores ferramentas e softwares de web scraping em 2026
- Relatório sobre o estado do web scraping
Aviso: verifique sempre se suas atividades de web scraping estão em conformidade com os termos do site e com as leis locais. Em caso de dúvida, consulte um advogado — ninguém quer ser o “scraper” que recebe uma notificação de cessar e desistir por causa de uma planilha.
Escrito por Shuai Guan, cofundador e CEO da Thunderbit. Passei anos trabalhando com SaaS, automação e IA — para que você não precise passar.
Experimente o Raspador Web IA Get Started Free




