é uma extensão Chrome de AI Web Scraper que ajuda usuários de negócios a extrair dados de sites com IA. O principal ponto de tensão é este: o que parece barato na página de preços do ScrapingBee pode mudar bastante quando você começa a rodar cargas reais em produção e vê os créditos evaporarem de 5× a 75× acima da taxa base. Esta análise cobre cinco ângulos que a maioria dos artigos deixa de fora: o custo real em escala, extração por seletores versus IA, usabilidade para não desenvolvedores, fluxos de trabalho de dados depois da extração e benchmarks de confiabilidade para 2026. Se você está a avaliar o ScrapingBee para a tua equipa — seja você desenvolvedor, líder de operações de vendas ou fundador — este é o panorama que você precisa.
O que é o ScrapingBee? Visão rápida
ScrapingBee é uma API de web scraping que trata da rotação de proxies, da renderização de JavaScript e da resolução de CAPTCHA para que developers consigam extrair dados de sites sem montar a própria infraestrutura de scraping. Tu envias uma requisição HTTP com parâmetros e recebes HTML de volta (ou JSON em alguns endpoints). Não há interface visual nem fluxo de clique para montar extrações.
Os principais recursos incluem:
- Proxies rotativos e premium (classic, premium, stealth, residential)
- Renderização em navegador headless (Chrome completo, ativada por padrão)
- Bypass automático de CAPTCHA
- Google Search API (JSON estruturado: resultados orgânicos, anúncios, mapas, knowledge graph, People Also Ask, imagens e notícias)
- Captura de screenshot (padrão, página inteira ou focada por seletor CSS)
- Segmentação geográfica via parâmetro
country_code - Regras de extração com CSS/XPath (JSON declarativo, retorna JSON estruturado)
- APIs dedicadas para scraping de Amazon, Walmart, YouTube e ChatGPT
- Extração com IA (adicionada por volta de 2024–2025): parâmetros
ai_query,ai_extract_rules,ai_selector(+5 créditos por requisição) - Ferramenta de CLI (lançada por volta de 2025–2026): processamento em lote, crawling, leitura de sitemap, enriquecimento de CSV, jobs cron agendados, escalonamento de proxy
Fundado em 2019 na França, o ScrapingBee cresceu até cerca de no início de 2026, com mais de 2.500 clientes (SAP, Zapier, Deloitte, Zillow) — tudo isso com uma operação enxuta de 4 a 6 pessoas. Em junho de 2025, o num negócio de oito dígitos. A marca e a liderança seguem independentes, e a equipa de suporte para melhorar a cobertura de fusos horários.
Um ponto importante: o ScrapingBee ainda não oferece um construtor visual nativo, interface de arrastar e largar, nem um agendador integrado no dashboard. O agendamento exige a ferramenta CLI, cron jobs ou automação de terceiros (Zapier, Make, n8n). Os guias “no-code” que eles publicam falam de integrações com Make e Zapier — não de uma interface no-code nativa.
Para quem o ScrapingBee realmente foi feito?
O ScrapingBee foi pensado para developers que se sentem à vontade com Python ou chamadas cURL, leitura de HTML e criação de seletores CSS/XPath. A documentação é bastante técnica, com foco em exemplos em Python e cURL. Um avaliador no observou que eles "não fornecem exemplos em JavaScript", e outro descreveu a documentação como "pesada, leva de um dia a uma semana para ler tudo".
Mas o público que procura "ScrapingBee review" em 2026 é mais amplo do que engenheiros de backend. Inclui gestores de marketing a montar listas de leads, equipas de sales ops a enriquecer dados no CRM, operações de ecommerce a monitorizar preços da concorrência e fundadores a avaliar ferramentas para as suas equipas. Em cada secção abaixo, vou indicar se o ponto afeta developers, utilizadores de negócio ou ambos.
Planos de preços do ScrapingBee em resumo
Estes são os níveis atuais de plano do ScrapingBee (em abril de 2026):
| Plano | Preço mensal | Créditos de API/mês | Requisições simultâneas |
|---|---|---|---|
| Freelance | $49 | 250.000 | 10 |
| Startup | $99 | 1.000.000 | 50 |
| Business | $249 | 3.000.000 | 100 |
| Business+ | $599 | 8.000.000 | 200 |
| Enterprise | Fale com vendas | 41M+ | Personalizado |
A cobrança anual oferece um . Um teste grátis dá 1.000 créditos de API sem necessidade de cartão. A Google Search API foi recentemente por chamada após a aquisição.
À primeira vista, estes números de créditos parecem generosos. Mas não são bem o que parecem.
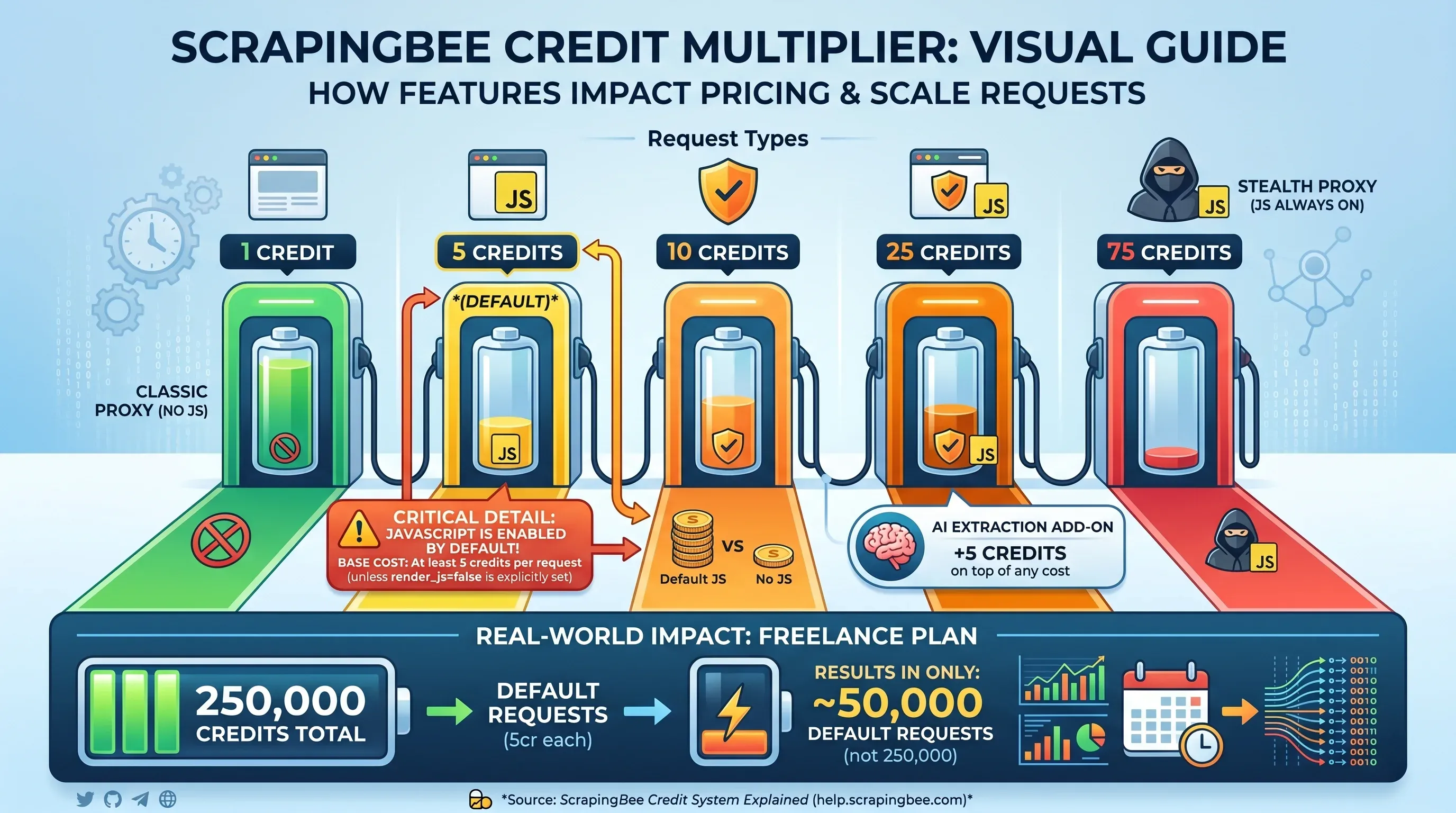
A tabela de multiplicação de créditos
É aqui que o preço do ScrapingBee complica. O total de créditos exibido não é o número de páginas que você consegue raspar — isso depende dos recursos ativados em cada requisição:
| Tipo de requisição | Créditos por requisição |
|---|---|
Proxy classic, sem renderização JS (render_js=false) | 1 crédito |
| Proxy classic, com renderização JS (padrão) | 5 créditos |
| Proxy premium, sem renderização JS | 10 créditos |
| Proxy premium, com renderização JS | 25 créditos |
| Proxy stealth (JS sempre ativado) | 75 créditos |
| Add-on de extração com IA | +5 créditos sobre o total |
Detalhe crítico: a renderização de JavaScript . Se você não definir explicitamente render_js=false, cada requisição custa no mínimo 5 créditos. Isso significa que os 250.000 créditos do plano Freelance, na prática, cobrem apenas 50.000 requisições padrão — não 250.000.
A matemática oculta dos créditos que ninguém mostra
Veja quanto o ScrapingBee realmente custa para 10.000 páginas em diferentes cenários e níveis de plano:
| Cenário | Créditos necessários | Freelance ($49/250K) | Startup ($99/1M) | Business ($249/3M) |
|---|---|---|---|---|
| 10K páginas (HTML estático, 1 cr) | 10.000 | ✅ Coberto ($0,20/1K) | ✅ Coberto ($0,10/1K) | ✅ Coberto ($0,08/1K) |
| 10K páginas (renderização JS, 5 cr) | 50.000 | ✅ Coberto ($0,98/1K) | ✅ Coberto ($0,50/1K) | ✅ Coberto ($0,42/1K) |
| 10K páginas (proxy premium + JS, 25 cr) | 250.000 | ⚠️ Exatamente no limite ($4,90/1K) | ✅ Coberto ($2,48/1K) | ✅ Coberto ($2,08/1K) |
| 10K páginas (proxy stealth, 75 cr) | 750.000 | ❌ Muito acima do limite | ✅ Quase no limite ($7,43/1K) | ✅ Coberto ($6,23/1K) |
As mesmas 10.000 páginas podem custar de $0,20 a $7,43 por mil dependendo da configuração de proxy e renderização. E tu nem sempre descobres qual configuração precisas até testares.
Cenário de orçamento: geração de leads com 10.000 páginas/mês
Uma equipa de vendas a raspar 10.000 páginas de empresas por mês para geração de leads. A maioria dos sites B2B modernos usa React ou Vue, então a renderização JS é necessária:
- Créditos necessários: 50.000 (10K × 5 créditos)
- Plano Freelance ($49): cobre com 200 mil créditos sobrando
- Mas se os alvos exigirem proxies premium: 250.000 créditos — exatamente a cota de um plano Freelance, sem margem
- Se forem necessários proxies stealth: 750.000 créditos — exige o plano Startup por $99/mês
Cenário de orçamento: monitorização de preços em ecommerce com 100.000 páginas/mês
Uma equipa de ecommerce a monitorizar 100.000 páginas de produtos em sites concorrentes:
| Configuração | Créditos necessários | Plano exigido | Custo mensal |
|---|---|---|---|
| HTML estático (1 cr) | 100.000 | Freelance | $49 |
| Renderização JS (5 cr) | 500.000 | Startup | $99 |
| Proxy premium + JS (25 cr) | 2.500.000 | Business | $249 |
| Proxy stealth (75 cr) | 7.500.000 | Business+ | $599 |
O mesmo trabalho vai de $49 a $599 por mês. Isto não é um detalhe — é uma diferença de custo de 12× dependendo da configuração.
"O preço inicial de $49 é o número mais enganador no mercado de APIs de scraping." —
"Os créditos acabam rápido quando se usa renderização de JavaScript ou recursos avançados, o que dificulta justificar para projetos menores ou equipas com volume de scraping imprevisível." — Nick S, Manager, Computer Software,
E os créditos não usados de um mês para o outro.
Como os custos do ScrapingBee se comparam aos concorrentes

Usando planos intermédios para uma comparação justa:
| Cenário (por 1K páginas) | ScrapingBee ($99/1M) | ScraperAPI ($149/1M) | Scrapfly ($100/1M) |
|---|---|---|---|
| HTML estático | $0,10 | $0,15 | $0,10 |
| Páginas renderizadas com JS | $0,50 | $1,64 | $0,60 |
| Premium + JS | $2,48 | $3,73 | $3,00 |
| Stealth/ultra premium + JS | $7,43 | $11,18 | N/A |
O ScrapingBee costuma ser o mais barato ou empatar como o mais barato em páginas estáticas e renderizadas com JS. O é consistentemente o mais caro — a renderização JS custa +10 créditos contra +5 no ScrapingBee e no Scrapfly. Mas testes independentes da contam outra história quando se considera a complexidade real dos sites:
| Serviço | Custo médio por 1K requisições | Taxa de sucesso | Tempo médio de resposta |
|---|---|---|---|
| Scrape.do | $0,80 | 98,19% | 4,7s |
| ScrapingBee | $3,90 | 92,69% | 11,7s |
| Scrapfly | $4,11 | — | — |
| ZenRows | $4,48 | 92,64% | 10,0s |
| ScraperAPI | $8,49 | 92,70% | 15,7s |
Modelo de créditos do Thunderbit: uma abordagem diferente
usa um modelo de preços fundamentalmente mais simples: 1 crédito = 1 linha de saída, sem multiplicadores por renderização JS, tipo de proxy ou domínio de destino. O scraping de subpáginas custa 2 créditos por linha.
| Plano | Preço mensal | Créditos | Custo por linha |
|---|---|---|---|
| Free | $0 | 6 páginas/mês | Grátis |
| Starter | $15 | 500 | $0,030 |
| Pro 1 | $38 | 3.000 | $0,013 |
| Pro 2 | $75 | 6.000 | $0,013 |
| Pro 3 | $125 | 10.000 | $0,013 |
| Pro 4 | $249 | 20.000 | $0,012 |
Um usuário do Thunderbit a raspar 10.000 listas de produtos em sites de ecommerce pesados em JS paga $125/mês, independentemente de esses sites exigirem renderização JavaScript, proxies premium ou bypass anti-bot. Com o ScrapingBee, o mesmo trabalho pode custar de $49 a $599, dependendo da configuração. Previsibilidade de orçamento conta — e muito.
Seletores CSS versus extração com IA: o custo de manutenção que você precisa conhecer
A maioria das análises do ScrapingBee ignora completamente este ponto. E ele talvez seja a consideração mais importante para quem pretende raspar dados em escala durante meses ou anos.
O ScrapingBee usa seletores CSS/XPath para extrair dados do HTML. Tu defines as regras de extração como objetos JSON com seletores CSS, e o ScrapingBee devolve os dados correspondentes. Isto funciona bem no início. O problema é o que vem depois.
O problema de quebra dos seletores
Quando um site-alvo muda o layout — nomes de classes, estrutura do DOM, versão do framework — os teus seletores CSS quebram. Em sistemas maduros de scraping a operar com mais de 2.500 jobs ativos, pesquisas mostram uma , exigindo 30–35 correções por semana só para manter os extratores a funcionar. Para organizações que raspam 50 sites, a manutenção anual chega a 850–1.300 horas, custando $64.000–$156.000 em custo total de engenheiro.
As equipas costumam subestimar isto. As estimativas iniciais geralmente apontam 10–15 horas de manutenção por mês, mas a realidade costuma ser (40–90 horas/mês). Uma única falha silenciosa — quando um seletor quebra, mas continua a devolver dados vazios sem alertar ninguém — custa em média $38.000–$57.000 em vendas perdidas, recuperação de ranking e tempo da equipa.
Causas comuns: renomeação de classes CSS em updates de framework, inserção de novos containers à volta dos alvos, upgrades de versões React/Vue/Angular que reestruturam o DOM, testes A/B com nomes de classe dinâmicos e obfuscação anti-scraping.
Extração com IA reduz a manutenção em 60–80%
Um estudo da DataRobot de 2025 constatou que scrapers com IA exigem do que scrapers tradicionais baseados em seletores após redesigns de site. A proporção de tempo praticamente se inverte:
| Métrica | Tradicional (seletores CSS) | Com IA |
|---|---|---|
| Manutenção após redesigns | Base | 70% menos |
| Divisão de tempo (configuração : manutenção) | 20% : 80% | 5% : 95% usando dados |
| Redução geral de manutenção | Base | 60–80% de redução |
| Velocidade em páginas pesadas em JS | Base | 30–40% mais rápido |
Tempo de configuração: escrever seletores versus campos sugeridos por IA
Configuração no ScrapingBee: inspecionar o código da página → identificar seletores CSS → escrever regras de extração em JSON → testar e depurar → lidar com casos extremos de variação de páginas → monitorizar quebras → corrigir seletores quando o site é atualizado.
Configuração no Thunderbit: abrir a página no Chrome → clicar em "AI Suggest Fields" → a IA lê a página e propõe colunas com tipos de dados adequados → clicar em "Scrape". Sem escrever seletores, sem inspecionar código-fonte. A IA do Thunderbit é alimentada por vários modelos de base (ChatGPT, Gemini, Claude, DeepSeek R1) que leem páginas da web visualmente, como uma pessoa.
Os do Thunderbit acrescentam outra camada: cada coluna pode ter uma instrução personalizada de IA que transforma os dados durante a extração — formatando datas, traduzindo texto, categorizando produtos, separando nomes, normalizando números de telefone. Isso elimina uma etapa separada de pós-processamento que os utilizadores do ScrapingBee têm de construir sozinhos.
Saída estruturada: HTML bruto versus linhas prontas para uso
| Dimensão | ScrapingBee (baseado em seletores) | Thunderbit (com IA) |
|---|---|---|
| Saída padrão | HTML bruto | Linhas estruturadas com colunas tipadas |
| Extração estruturada | Exige regras CSS/XPath ou add-on de IA (+5 créditos) | IA detecta campos automaticamente |
| Tipos de dados suportados | Texto (requer parsing de HTML) | Texto, número, data, URL, e-mail, telefone, imagem |
| Resiliência a mudanças de layout | ⚠️ Exige atualização manual dos seletores | ✅ A IA relê a página do zero a cada vez |
| Conhecimento técnico necessário | Python/cURL, seletores CSS, compreensão de HTML | Nenhum — extensão Chrome com fluxo de 2 cliques |
| Manutenção ao longo do tempo | Contínua (taxa de quebra semanal de 1–2%) | Mínima (a IA adapta-se automaticamente) |
O ScrapingBee adicionou recursos de extração com IA (ai_query, ai_extract_rules) que ajudam parcialmente a resolver o problema de manutenção dos seletores. Mas isso acrescenta +5 créditos por requisição ao custo base, e a ferramenta continua a ser essencialmente API-first, sem interface visual.
ScrapingBee para não desenvolvedores: uma avaliação honesta de usabilidade
O ScrapingBee não foi feito para utilizadores não técnicos. É uma API. Tu escreves código para a usar. Se és gerente de marketing ou líder de sales ops e estás a ler isto, essa já é a resposta.
Vê o que um utilizador sem perfil técnico realmente enfrenta com o ScrapingBee:
- Escrever uma chamada de API em Python, cURL ou outra linguagem
- Entender parâmetros HTTP como
render_js=true,premium_proxy=true,country_code=us - Interpretar respostas em HTML bruto usando uma biblioteca como BeautifulSoup
- Escrever seletores CSS para extrair campos específicos
- Lidar com paginação escrevendo lógica de crawling personalizada (o ScrapingBee trata apenas de requisições de uma página)
- Construir um pipeline de dados para limpar, estruturar e guardar as informações extraídas
Não há construtor de arrastar e largar. Não há interface de clique. Não existe pré-visualização visual do que tu estás a raspar.
"Existe uma curva de aprendizagem. E a documentação é pesada, leva de um dia a uma semana para ler tudo." — Arvind K, Proprietor, Financial Services,
"O sistema deles é bem específico e leva um tempo para aprender os códigos e a estrutura." —
Developers gostam disto. Um avaliador chamou de "totalmente baseado em API: muito moderno e elegante: simplesmente funciona". Mas "facilidade de uso" para um developer a avaliar APIs é muito diferente de "facilidade de uso" para alguém a tentar montar uma lista de leads sem programar.
Quando uma alternativa no-code faz mais sentido
A oferece uma experiência completamente diferente:
- Abre uma página no Chrome com a extensão instalada
- Clica em "AI Suggest Fields" — a IA analisa a página e propõe colunas (Product Name, Price, Rating, URL etc.) com os tipos de dados certos
- Revê e personaliza — adiciona, remove ou renomeia colunas; inclui Field AI Prompts para transformação
- Clica em "Scrape" — os dados são extraídos em linhas estruturadas
- Exporta — com um clique para Google Sheets, Airtable, Notion, Excel, CSV ou JSON (todas as exportações são grátis)
Sem chamadas de API, sem seletores, sem código. O Thunderbit suporta em abril de 2026.
Para sites comuns, o Thunderbit também oferece — templates prontos e mantidos para Amazon, Zillow, Shopify, LinkedIn, Google Maps, Instagram, eBay, Apollo e muito mais. Tu nem precisas esperar que a IA sugira os campos; o template já está pronto.
Além disso, o Thunderbit inclui várias que não exigem plano: extrator de e-mail, extrator de número de telefone e extrator de imagens — úteis para equipas de vendas e marketing que só precisam de extrações rápidas de dados.
Estrutura de decisão: quem deve usar o quê
| Se você é… | Melhor opção |
|---|---|
| Developer confortável com APIs e parsing de HTML | ScrapingBee ou ScraperAPI |
| Utilizador técnico que quer dados estruturados sem trabalhar com seletores | Thunderbit API (endpoint Extract) |
| Utilizador de negócio (vendas, marketing, operações de ecommerce) sem habilidade de programação | Thunderbit Chrome Extension |
| Equipa que precisa de monitorização agendada sem DevOps | Thunderbit Scheduled Scraper (agendamento em linguagem natural) |
| A construir pipelines LLM/RAG que precisam de Markdown limpo | Thunderbit Distill API ou Firecrawl |
| Focado em previsibilidade de orçamento e sem multiplicadores de crédito | Thunderbit (1 crédito = 1 linha) |
Depois da extração: para onde os teus dados realmente vão?
Raspar é só metade do trabalho. A outra metade — levar esses dados para algum lugar útil — é onde a maioria das análises do ScrapingBee se cala.
ScrapingBee: sai HTML bruto, você monta o pipeline
O ScrapingBee devolve HTML bruto por padrão. A partir daí, tu precisas:
- Fazer o parsing do HTML com BeautifulSoup ou lxml
- Remover navegação, rodapés, scripts e estilos (que compõem )
- Extrair campos específicos de dados
- Converter para formatos estruturados
- Lidar com paginação e estados de erro
- Guardar e distribuir os dados
"O ScrapingBee devolve HTML bruto. Agentes de IA precisam de Markdown limpo, busca semântica e webhooks." —
O ScrapingBee oferece return_page_markdown=true e return_page_text=true como alternativas opcionais, e a Google Search API devolve JSON estruturado. Mas o fluxo padrão — e a experiência geral de scraping para usos genéricos — é HTML bruto que tu precisas de processar sozinho.
Normalmente, os utilizadores precisam de ferramentas adicionais: BeautifulSoup/lxml para parsing, Pandas para limpeza de dados, cron/Airflow para agendamento, lógica de crawling personalizada para páginas múltiplas e . É muita engenharia entre "eu raspei" e "já posso usar".
Thunderbit: saída estruturada com exportação integrada
O Thunderbit devolve linhas estruturadas com tipos de dados definidos (texto, número, data, URL, e-mail, telefone, imagem) prontas para exportação. Todas as exportações são grátis em todos os planos:
| Destino de exportação | Custo |
|---|---|
| Excel (.xlsx) | Grátis |
| Google Sheets | Grátis (integração direta) |
| Airtable | Grátis (integração direta) |
| Notion | Grátis (integração direta) |
| CSV | Grátis |
| JSON | Grátis |
Para equipas que já usam Google Sheets ou Airtable como CRM ou centro operacional, isto elimina uma camada inteira de engenharia. Ao exportar para Notion ou Airtable, as imagens vão para a biblioteca de imagens para visualização inline — um detalhe pequeno, mas muito relevante na prática.
Ecossistema de integrações do ScrapingBee
O ScrapingBee oferece integrações de terceiros: (mais de 8.000 conexões de apps), (mais de 3.000 apps), n8n e Microsoft Power Automate. Elas podem fazer a ponte entre o HTML bruto e as tuas ferramentas de destino — mas acrescentam custo, complexidade e mais um ponto de falha.
Para developers: a API aberta do Thunderbit
Para leitores que realmente querem pipelines programáticos, o Thunderbit oferece uma Open API com dois endpoints principais:
- Distill endpoint — converte páginas em Markdown limpo, ideal para pipelines LLM/RAG (1 crédito por chamada)
- Extract endpoint — devolve JSON estruturado de acordo com um schema definido pelo utilizador (20 créditos por chamada)
- Processamento em lote — até 100 URLs por requisição
Isto significa que o Thunderbit atende tanto utilizadores no-code (Chrome Extension) quanto developers (Open API) com o mesmo motor de IA. Não perguntes só "ele consegue raspar?" — pergunta "para onde os dados vão?"
Checagem de confiabilidade em 2026: o ScrapingBee aguenta em produção?
Tópicos antigos no Reddit (2021–2023) trazem reclamações de confiabilidade sobre o ScrapingBee. Isso ainda reflete a realidade em 2026? Analisei dados de seis benchmarks independentes. Os resultados são mistos — e às vezes contraditórios.
Benchmark quinzenal da Scrapeway (abril de 2026)
No geral: — 7.º lugar entre 9 serviços testados.
| Site | Taxa de sucesso |
|---|---|
| Amazon | 48% |
| 41% | |
| Indeed | 38% |
| Etsy | 21% |
| Booking | 17% |
| Realtor | 0% |
| StockX | 0% |
| Twitter/X | 0% |
| Zillow | 0% |
| Walmart | 0% |
| 0% |
Teste direto da Scrapingdog (2025)
| Site | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100% | 100% | 100% |
| Glassdoor | 0% | 100% | 100% |
| eBay | 100% | 100% | 100% |
| Walmart | 40% | 100% | 100% |
| 90% | 100% | 80% |
Benchmark da Proxyway (dezembro de 2025)
- 72,98% de sucesso com 10 requisições/segundo — queda de 12 pontos sob carga
- 25,46s de tempo médio de resposta — o mais lento do grupo no benchmark
Benchmark da Scrape.do (2025–2026)
- Forte em sites individuais: Amazon 99,11%, Indeed 99,29%, GitHub 100%, X/Twitter 99,6%
- Fraco no Capterra: apenas 59% de sucesso com tempos de resposta de 36 segundos
O padrão
Os dados mostram um padrão claro:
- O ScrapingBee funciona bem em sites mainstream com proteção moderada — Amazon, eBay, GitHub e Indeed mostram consistentemente taxas de sucesso de 90–100%
- O ScrapingBee falha completamente em sites fortemente protegidos — 0% consistente em LinkedIn, Zillow, Realtor.com, StockX e Twitter em múltiplos benchmarks
- O desempenho piora bastante sob carga — 84% a 2 req/s cai para 73% a 10 req/s
- Os resultados dos benchmarks variam muito conforme a metodologia — de 33,3% (Scrapeway, mix amplo de sites) a 92,69% (Scrape.do, alvos moderados)
A (137 avaliações) é um sinal positivo, mas avaliações altas de facilidade de configuração inicial nem sempre refletem confiabilidade de produção a longo prazo em escala. Utilizadores que trocam de ferramenta frequentemente citam aumento de falhas e crescimento de custos — não dificuldade inicial de setup.
"Muito positivo. O ScrapingBee tem sido estável, previsível e fácil de integrar em produção." — Verified Reviewer, CEO,
O ScrapingBee apresentou "confiabilidade inconsistente", alcançando especificamente "0% de sucesso no Glassdoor" e "."
Como o scraping com IA lida com a confiabilidade de forma diferente
A IA do Thunderbit lê a página renderizada em tempo real, adaptando-se a medidas anti-bot e mudanças de layout a cada sessão. Dois modos de scraping atendem a desafios diferentes de confiabilidade:
- Cloud scraping — corre nos servidores em nuvem do Thunderbit, processa até 50 páginas por vez e é ideal para grandes tarefas de scraping público em sites como Amazon, Zillow e Shopify
- Browser scraping — corre localmente no Chrome do utilizador, usando a própria sessão autenticada do utilizador — ideal para sites com login (LinkedIn, painéis privados, plataformas SaaS) onde ferramentas baseadas em API como o ScrapingBee não conseguem aceder a conteúdo atrás de autenticação
O Thunderbit também oferece para sites populares, prontos e mantidos para continuarem a funcionar mesmo quando a estrutura dos sites muda. Para os sites em que o ScrapingBee mostra 0% de sucesso (LinkedIn, Zillow), o modo browser scraping do Thunderbit — usando a tua própria sessão com login — é uma abordagem fundamentalmente diferente.
ScrapingBee versus principais alternativas: comparação lado a lado
| Dimensão | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| Tipo | Apenas API | Extensão Chrome + API | Apenas API | Apenas API |
| Preço inicial | $49/mês | Grátis ($0) | $49/mês | $30/mês |
| Modelo de créditos | Multiplicadores (1×–75×) | 1 crédito = 1 linha (sem multiplicadores) | Multiplicadores (1×–75×) | Multiplicadores (1×–30×) |
| Extração com IA | Sim (+5 créditos/requisição) | Integrada (AI Suggest Fields) | Sem IA nativa | Sim |
| Opção no-code | Não (apenas API) | Sim (Extensão Chrome) | Não (apenas API) | Não (apenas API) |
| Saída estruturada | Exige regras CSS ou add-on de IA | Padrão (colunas tipadas) | Endpoints estruturados para sites específicos | Varia |
| Destinos de exportação | HTML/JSON bruto (tu montas tudo) | Excel, Sheets, Airtable, Notion, CSV, JSON (tudo grátis) | HTML/JSON bruto | HTML/JSON bruto |
| Scraping de subpáginas | Manual (escrever lógica de crawling) | Integrado (2 créditos/linha) | Manual | Manual |
| Scraping agendado | Apenas via CLI (sem scheduler no dashboard) | Integrado (linguagem natural) | Não integrado | Não integrado |
| Plano grátis | Teste com 1.000 créditos | 6 páginas/mês (para sempre) | 5.000 créditos (teste de 7 dias) | 1.000 créditos |
| Renderização JS padrão | Ligada (custo 5×) | Incluída (sem custo extra) | Desligada | Desligada |
| Curva de aprendizado | Alta (API + seletores) | Baixa (fluxo de 2 cliques) | Alta (API + seletores) | Alta (API) |
| Melhor para | Devs que querem controlo de proxy | Utilizadores de negócio + developers | Devs + endpoints estruturados | Devs que querem bypass de ASP |
| Nota no Capterra | 4,9/5 (137 avaliações) | — | 4,6/5 (62 avaliações) | 4,9/5 (221 avaliações) |
ScrapingBee versus Thunderbit: diferenças principais
As maiores diferenças resumem-se a arquitetura e público:
- Apenas API versus Extensão Chrome + API: o ScrapingBee exige código em toda interação. O Thunderbit oferece uma para utilizadores no-code e uma Open API para developers — o mesmo motor de IA, duas interfaces.
- Extração baseada em seletores versus extração com IA: o ScrapingBee exige que tu escrevas e mantenhas seletores CSS/XPath. A IA do Thunderbit sugere campos automaticamente e adapta-se quando os sites mudam.
- HTML bruto versus linhas estruturadas com exportação grátis: o ScrapingBee devolve HTML que tu precisas de analisar. O Thunderbit devolve linhas tipadas e rotuladas que podes com um clique.
- Scraping de subpáginas: a IA do Thunderbit visita cada página de detalhe e enriquece a tabela principal — já vem embutido, sem lógica de crawling personalizada. O ScrapingBee exige que tu escrevas essa lógica sozinho.
- Templates instantâneos: o Thunderbit tem templates prontos para sites populares (Amazon, Zillow, Shopify, LinkedIn, Google Maps, eBay) que funcionam logo de início. O ScrapingBee tem APIs dedicadas para Amazon e Walmart, mas tu ainda precisas de escrever código para as usar.
Outras alternativas relevantes
- — menor custo independente, com $0,80/1K requisições e 98,19% de taxa de sucesso; a partir de $29/mês
- Apify — plataforma baseada em actors com mais de 415 avaliações no G2 (4,7/5), mas "Problemas de preço" é a principal reclamação
- — nativo para IA/LLM, devolve Markdown com 67% menos tokens do que HTML bruto; core open-source; a partir de $16/mês
- — nível enterprise com mais de 72 milhões de IPs, a partir de $499/mês; preço fixo
- ZenRows — 55 milhões de IPs residenciais, scrapers prontos para Amazon/Walmart/Zillow, a partir de $69/mês
Qual ferramenta de scraping é a ideal para a tua equipa?
Recomendações por cenário:
- Se você é desenvolvedor e está a criar um pipeline de scraping personalizado, com controlo granular de proxies → ScrapingBee ou ScraperAPI. Tu terás parâmetros HTTP detalhados, seleção de tipo de proxy e controlo total sobre a renderização. Só não te esqueças de prever os multiplicadores de crédito.
- Se você é uma equipa de vendas ou marketing que precisa de leads de sites sem programar → . Dois cliques para obter dados estruturados, um clique para enviar ao Google Sheets. Sem API, sem seletores, sem parsing.
- Se você precisa de dados estruturados de sites populares rapidamente → Thunderbit Instant Templates. Amazon, Zillow, Shopify, LinkedIn — prontos e mantidos, sem necessidade de configurar IA.
- Se você precisa monitorizar preços ou stock num cronograma, sem DevOps → Thunderbit Scheduled Scraper. Descreve o intervalo em linguagem natural ("toda segunda às 9h") e deixa correr.
- Se você está a construir pipelines LLM/RAG e precisa de Markdown limpo em escala → Thunderbit Distill API ou Firecrawl. Ambos devolvem Markdown otimizado para consumo por IA.
- Se a previsibilidade de orçamento importa e você não quer multiplicadores de crédito → Thunderbit. 1 crédito = 1 linha, independentemente de renderização JS ou tipo de proxy.
O custo total de propriedade não é só o preço da API. É tempo de setup + horas de manutenção + engenharia de parsing + fluxo de exportação de dados. O preço de tabela do ScrapingBee é competitivo; o custo real completo, não.
Principais conclusões desta análise do ScrapingBee
Cinco aprendizagens que valem a pena guardar:
- Os custos de crédito escalam muito depressa. O preço inicial de $49 pode virar $599+ quando renderização JS e proxies premium entram na conta. O modelo fixo do Thunderbit, de 1 crédito por linha, elimina essa imprevisibilidade.
- Seletores CSS trazem manutenção contínua, enquanto a extração com IA evita esse peso. Espera com ferramentas com IA, e zero quebra de seletor quando os sites mudam.
- Não developers enfrentam uma curva de aprendizagem alta com o ScrapingBee. É uma ferramenta só de API, que exige código, inspeção de HTML e construção de seletores. Utilizadores de negócio devem olhar para alternativas no-code.
- A exportação de dados exige engenharia personalizada. O ScrapingBee entrega HTML bruto; tu montas o pipeline. O Thunderbit exporta dados estruturados para gratuitamente.
- A confiabilidade é boa para alguns sites, mas inconsistente para outros. O ScrapingBee funciona bem em Amazon e eBay, mas mostra 0% em LinkedIn, Zillow e vários outros alvos fortemente protegidos.
O ScrapingBee continua a ser uma ferramenta capaz para developers que querem acesso HTTP com proxy gerido e controlo fino. Mas o cenário de web scraping em 2026 mudou para ferramentas com IA e no-code — e o foi feito especificamente para essa mudança. Testa o plano grátis (6 páginas grátis, ou mais com o teste gratuito) e vê a diferença por conta própria.
Perguntas frequentes
O ScrapingBee ainda vale a pena em 2026?
Depende das tuas competências técnicas e da escala. Para developers que raspam páginas estáticas em volume moderado, o ScrapingBee oferece uma API sólida, bem documentada, com suporte responsivo e . Para utilizadores de negócio, scraping em alto volume ou equipas que querem dados estruturados sem programar, alternativas com IA como o Thunderbit oferecem melhor valor e um custo total de propriedade significativamente menor.
O ScrapingBee funciona sem programar?
Não. O ScrapingBee é uma ferramenta só de API que exige escrever código (Python, cURL ou algo parecido) e entender parâmetros HTTP. Não existe interface visual para montar extrações. Utilizadores sem perfil técnico devem considerar opções no-code como a , que permite raspar e exportar dados sem escrever uma única linha de código.
Quanto o ScrapingBee realmente custa por página?
Depende dos recursos ativados. Uma página HTML estática custa 1 crédito. Uma página renderizada com JS (o padrão) custa . Uma página com proxy premium + JS custa 25 créditos. Uma página com proxy stealth custa 75 créditos. A extração com IA adiciona +5 créditos. No plano Freelance ($49/250K créditos), isso equivale a $0,20 por 1.000 páginas estáticas ou $14,70 por 1.000 páginas com proxy stealth. Vê as tabelas detalhadas acima para o cálculo completo.
Quais são as melhores alternativas ao ScrapingBee em 2026?
As principais alternativas incluem (com IA, no-code, Extensão Chrome + API, 1 crédito = 1 linha), (API para developers com endpoints estruturados para sites específicos), (API para developers com forte bypass anti-bot), (menor custo por requisição em testes independentes) e (nativo para IA/LLM, devolve Markdown limpo). Cada uma tem o seu ponto forte — Thunderbit para utilizadores de negócio e previsibilidade de orçamento, ScraperAPI e Scrapfly para controlo de proxy, Firecrawl para pipelines LLM.
O ScrapingBee consegue raspar sites pesados em JavaScript?
Sim, mas isso custa 5× os créditos base com proxy rotativo ou 25× com proxy premium. A renderização de JavaScript vem , então já pagas a tarifa 5× a menos que desligues explicitamente. O Thunderbit lida com a renderização JS automaticamente sem multiplicadores de crédito — 1 crédito por linha, independentemente de como a página foi construída.
Saiba mais